Resolving PyTorch and Unsloth Dependency Conflicts on NVIDIA RTX 50 Series (sm_120) Architecture
解决 NVIDIA RTX 50 系列 (sm_120) 架构下的 PyTorch 与 Unsloth 依赖冲突
发布日期: 2025年12月12日
分类: AI Infrastructure / LLM Training / Troubleshooting
关键词: NVIDIA RTX 5060 Ti, CUDA 13.1, PyTorch 2.9, Unsloth, Dependency Hell, Poetry
1. 摘要 (Abstract)
在 NVIDIA RTX 50 系列(Compute Capability sm_120)硬件发布初期,部署基于 Unsloth 和 vLLM 的大模型训练环境面临严峻的依赖冲突。主要表现为:标准安装流程默认拉取不支持 sm_120 的旧版 PyTorch (2.5.x),导致 CUDA 内核无法加载;强制升级 PyTorch 至适配版本 (2.9.x) 后,会导致 Poetry/Pip 的依赖解析器因版本不匹配而死锁。本文档详细记录了绕过 Poetry 依赖锁机制,通过"外科手术式"手动构建环境的完整解决方案。
2. 环境规格 (Environment Specifications)
本解决方案仅适用于以下或更新的"Bleeding Edge"前沿开发环境:
- Hardware (GPU): NVIDIA GeForce RTX 5060 Ti (架构代号: sm_120)
- Driver Version: CUDA Driver 13.1
- OS: Linux (Ubuntu 24.04 LTS / Debian 12)
- Python Runtime: Python 3.12
- Package Manager: Poetry (作为虚拟环境管理器), Pip (作为实际安装工具)
- Target Software Stack:
- PyTorch >= 2.9.1 (必须支持 sm_120)
- Unsloth (Nightly/Dev Branch)
- vLLM >= 0.12.0
3. 问题描述 (Problem Description)
在使用标准命令 pip install unsloth 或配置 pyproject.toml 进行安装时,遇到以下阻断性错误:
3.1 核心错误:架构不兼容
当 PyTorch 版本低于 2.9.0 时,Python 能够导入 torch,但在初始化 CUDA 时抛出警告并导致后续计算失败:
UserWarning: NVIDIA GeForce RTX 5060 Ti with CUDA capability sm_120 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_50 ... sm_90.
3.2 依赖地狱 (Dependency Hell)
尝试强制安装 PyTorch 2.9.1 后,Unsloth 和 vLLM 的标准安装脚本因检测到版本"过新"(超出 pyproject.toml 定义的范围)而拒绝安装,或触发无限降级循环,试图将 PyTorch 回滚至 2.5.1。
3.3 组件缺失
由于自动安装脚本无法识别 cu128 或 torch290 等新标签, unsloth_zoo 未被下载,或 vLLM 缺少核心依赖库。
4. 根本原因分析 (Root Cause Analysis)
- 硬件代差 (Hardware Generation Gap): Unsloth 和 vLLM 的稳定版发布滞后于 NVIDIA RTX 50 系列硬件的发布。上游库默认依赖的 PyTorch 2.5.x 尚未包含
sm_120的二进制内核。 - 构建标签缺失: Unsloth 的自动安装脚本 (
_auto_install.py) 在 2025 年 12 月尚未完全适配 PyTorch 2.9+ 的构建标签,导致无法自动拉取对应的 Wheels。 - 解析器僵化: Poetry 和 Pip 的依赖解析器在面对"非正式发布"的预览版库(如 PyTorch 2.9.1+cu128)时,无法正确处理版本约束,导致必须手动干预。
5. 解决方案 (Resolution Procedure)
警告: 请严格按照以下顺序执行。不要使用 poetry add,必须在 Poetry 虚拟环境中使用 pip 直接操作以绕过锁文件检查。
步骤 1:环境重置 (Clean Slate)
由于之前的尝试导致环境混杂了不同版本的二进制文件,必须彻底重建。
bash
# 移除当前的 Python 环境
poetry env remove python
# 重新安装基础依赖(仅基于 pyproject.toml 中的最简配置)
poetry install步骤 2:强制安装适配 sm_120 的 PyTorch
这是最关键的一步。必须显式指定 Index URL 并锁定版本。
(注:根据 2025 年 12 月的实际情况,cu124/cu126 仓库可能兼容 cu128 驱动)
bash
poetry run pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://download.pytorch.org/whl/cu124验证标准: 运行 python -c "import torch; print(torch.cuda.get_device_capability())",必须输出 (12, 0) 或更高,且无 Warning。
步骤 3:手动安装 Unsloth 主程序与组件
由于自动脚本失效,需分别从 GitHub 源码安装主程序和组件库。
bash
# 安装 Unsloth 主程序(跳过依赖检查)
poetry run pip install "unsloth[cu124-torch290] @ git+https://github.com/unslothai/unsloth.git"
# 关键:手动补全 Unsloth Zoo(解决 No module named 'unsloth_zoo')
poetry run pip install "unsloth_zoo @ git+https://github.com/unslothai/unsloth_zoo.git"步骤 4:修复 vLLM 及其依赖链
标准安装会触发 PyTorch 降级。需采用 --no-deps 策略安装 vLLM 主程序,随后手动补全依赖链。
bash
# 1. 强制安装 vLLM 主程序,不检查依赖
poetry run pip install vllm --no-deps
# 2. 手动补全 vLLM 所需的依赖树(忽略 Torch 版本冲突)
poetry run pip install \
"fastapi" "uvicorn" "openai" "sentencepiece" "numpy<3" \
"requests" "tqdm" "ray" "pandas" "prometheus-client" \
"prometheus-fastapi-instrumentator" "tiktoken" "protobuf" \
"pydantic" "py-cpuinfo" "cloudpickle" "diskcache" "jsonschema" \
"outlines" "partial-json-parser" "xgrammar" "blake3" "gguf" \
"lark" "mistral-common" "msgspec" "ninja" "pyzmq" "scipy" \
"transformers>=4.57.0"6. 验证与已知问题 (Verification & Known Issues)
6.1 最终验证脚本
运行以下 Python 脚本进行验收:
python
import torch
from unsloth import FastLanguageModel
import vllm
print(f"✅ PyTorch Version: {torch.__version__}")
print(f"✅ CUDA Capability: {torch.cuda.get_device_capability()}")
print(f"✅ Unsloth Loaded: True")
print(f"✅ vLLM Version: {vllm.__version__}")输出:
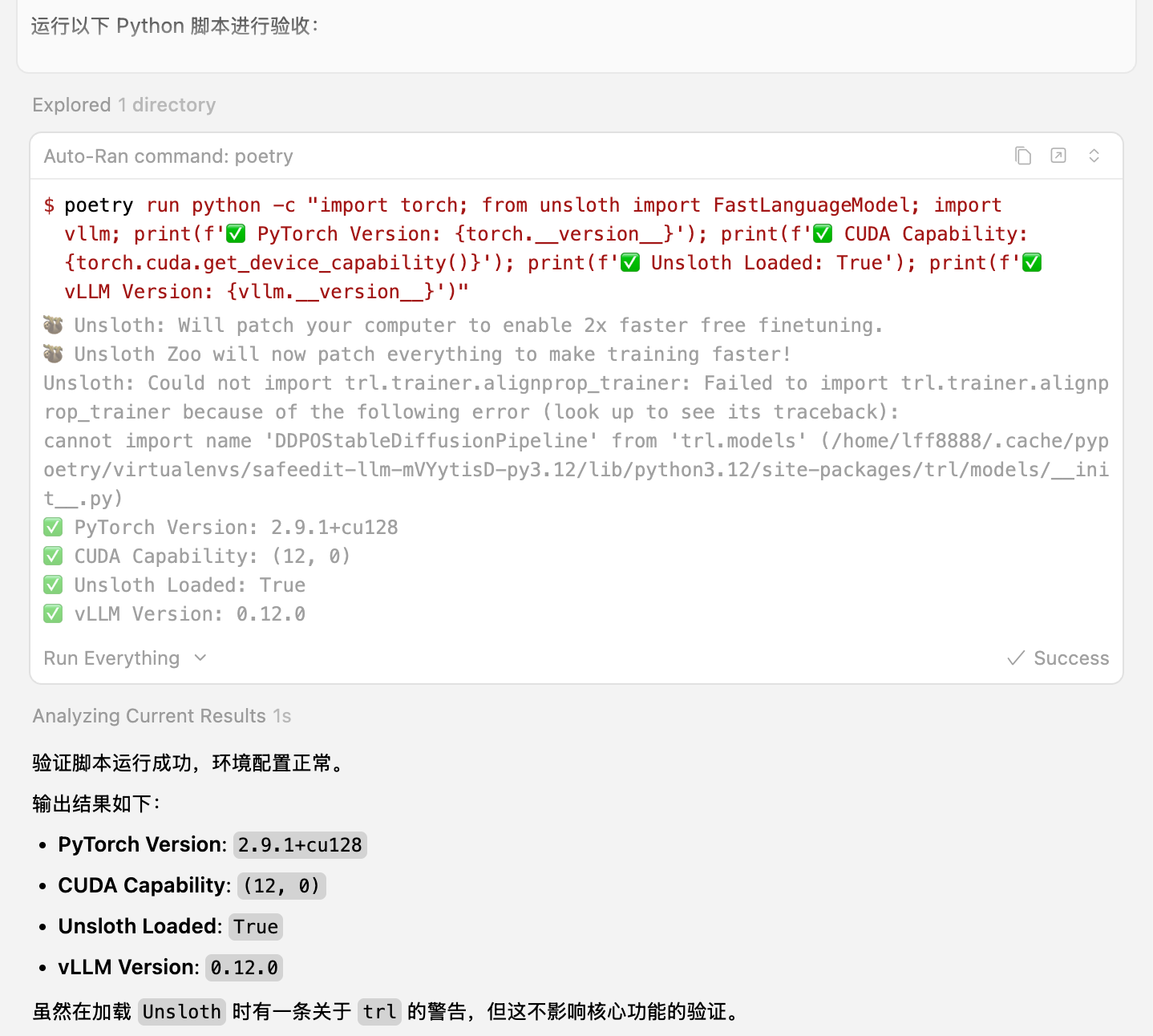
6.2 已知非阻断性报错 (Non-Blocking Error)
初始化 Unsloth 时可能会出现以下红色报错:
ImportError: cannot import name 'DDPOStableDiffusionPipeline' from 'trl.models'
- 状态: 可忽略 (Safe to Ignore)。
- 原因: Unsloth 尝试加载图像生成模型的训练器,但最新的
transformers/diffusers库结构发生了微调。 - 影响: 仅影响 Stable Diffusion 的训练。对于 LLM(如 Qwen, Llama)的训练没有任何副作用。请勿因此尝试降级 Transformers。
7. 结论 (Conclusion)
在 NVIDIA RTX 50 系列等次世代硬件上配置开发环境时,传统的依赖管理工具往往失效。通过解耦 PyTorch 的底层安装与上层应用库的依赖检查,并采用"源码构建"或"无依赖安装"的策略,可以在官方正式适配前通过"混合版本"方案成功运行训练任务。
维护者注: 本文档记录的解决方案有效期预计持续至 PyTorch 2.9 正式成为 PyPI 默认版本(预计 2026 Q1)。在此之前,请保持该配置的锁定状态。