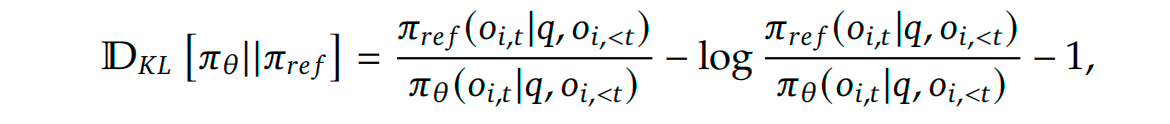文章目录
基础知识
强化学习基础知识
-
enviroment:看到的画面+看不到的后台画面,不了解细节
-
agent:根据策略得到尽可能多的奖励
-
state:当前状态
-
observation:state的一部分(有时候agent无法看全)
-
action:agent做出的动作
-
reward:agent做出一个动作后环境给予的奖励
-
action space:可以选择的动作,如上下左右
-
policy :策略函数,输入state,输出Action的概率分布 。一般用 π π π表示. π ( l e f t ∣ s t ) = 0.1 \pi(left|s_t)=0.1 π(left∣st)=0.1表示策略 π π π给出向左走的概率是0.1
-
Trajectory/Episode/Rollout :轨迹,用 τ \tau τ表示一连串状态和动作的序列。有的状态转移是确定的,也有的是不确定的。 { s 0 , a 0 , s 1 , a 1 . . . } {\{s_0,a_0,s_1,a_1...}\} {s0,a0,s1,a1...},确定 s t + 1 = f ( s t , a t ) {s_{t+1} = f(s_t,a_t)} st+1=f(st,at),随机 s t + 1 = P ( ⋅ ∣ s t , a t ) {s_{t+1} = P(·|s_t,a_t)} st+1=P(⋅∣st,at)
-
Return:回报,从当前时间点到游戏结束的 Reward 的累积和。
数学期望
期望:每个可能结果的概率与其结果值的乘积之和
x x x服从分布 p p p,约等于成立是因为我们从分布 p p p采样来近似期望
E ( x ) x ∼ p ( x ) = ∑ x x ∗ p ( x ) ≈ 1 n ∑ i = 1 n x ( i ) ,其中 x ( i ) ∼ p ( x ) \mathrm{E}(\mathrm{x}){x \sim p(x)}=\sum{x} x * p(x) \approx \frac{1}{n} \sum_{i=1}^{n}x^{(i)} ,其中{x^{(i)} \sim p(x)} E(x)x∼p(x)=x∑x∗p(x)≈n1i=1∑nx(i),其中x(i)∼p(x)
强化学习的目的,就是训练一个Policy神经网络 π \pi π,在所有状态S下,给出相应的Action,使得到Return的期望最大。
推导
下面的公式表示trajectory轨迹 τ \tau τ服从分布 P θ P_\theta Pθ,( θ \theta θ是我们需要训练的策略网络里面的参数),下面的期望就是所有的 τ \tau τ获得的Retrun乘 τ \tau τ的概率的累加。
我们期望在 θ \theta θ的作用下, τ \tau τ所获得的Return最大。
E ( R ( τ ) ) τ ∼ P θ ( τ ) = ∑ τ R ( τ ) P θ ( τ ) E(R(\tau)){\tau \sim P{\theta}(\tau)}=\sum_{\tau} R(\tau) P_{\theta}(\tau) E(R(τ))τ∼Pθ(τ)=τ∑R(τ)Pθ(τ)
如何让期望尽可能的大?
梯度的含义是一个计算出来的值,我们使用这个值去更新 θ \theta θ,目的是让高回报的轨迹在未来更可能发生,低回报的轨迹更不可能发生。
可以采用梯度上升的方法 ,先对 θ {\theta} θ计算梯度:
∇ E ( R ( τ ) ) τ ∼ P θ ( τ ) = ∇ ∑ τ R ( τ ) P θ ( τ ) = ∑ τ R ( τ ) ∇ P θ ( τ ) = ∑ τ R ( τ ) ∇ P θ ( τ ) P θ ( τ ) P θ ( τ ) = ∑ τ P θ ( τ ) R ( τ ) ∇ P θ ( τ ) P θ ( τ ) = ∑ τ P θ ( τ ) R ( τ ) ∇ P θ ( τ ) P θ ( τ ) ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ P θ ( τ n ) P θ ( τ n ) = 1 N ∑ n = 1 N R ( τ n ) ∇ log P θ ( τ n ) \begin{aligned} \nabla E(R(\tau)){\tau \sim P{\theta}(\tau)} & =\nabla \sum_{\tau} R(\tau) P_{\theta}(\tau) \\ & =\sum_{\tau} R(\tau) \nabla P_{\theta}(\tau) \\ & =\sum_{\tau} R(\tau) \nabla P_{\theta}(\tau) \frac{P_{\theta}(\tau)}{P_{\theta}(\tau)} \\ & =\sum_{\tau} P_{\theta}(\tau) R(\tau) \frac{\nabla P_{\theta}(\tau)}{P_{\theta}(\tau)} \\ & =\sum_{\tau} P_{\theta}(\tau) R(\tau) \frac{\nabla P_{\theta}(\tau)}{P_{\theta}(\tau)} \\ & \approx \frac{1}{N} \sum_{n=1}^{N} R\left(\tau^{n}\right) \frac{\nabla P_{\theta}\left(\tau^{n}\right)}{P_{\theta}\left(\tau^{n}\right)} \\ & =\frac{1}{N} \sum_{n=1}^{N} R\left(\tau^{n}\right) \nabla \log P_{\theta}\left(\tau^{n}\right) \end{aligned} ∇E(R(τ))τ∼Pθ(τ)=∇τ∑R(τ)Pθ(τ)=τ∑R(τ)∇Pθ(τ)=τ∑R(τ)∇Pθ(τ)Pθ(τ)Pθ(τ)=τ∑Pθ(τ)R(τ)Pθ(τ)∇Pθ(τ)=τ∑Pθ(τ)R(τ)Pθ(τ)∇Pθ(τ)≈N1n=1∑NR(τn)Pθ(τn)∇Pθ(τn)=N1n=1∑NR(τn)∇logPθ(τn)
其中 τ ∼ P θ ( τ ) \tau \sim P_\theta{(\tau)} τ∼Pθ(τ)
我们认为下一个状态完全由当前状态和当前动作决定的,那么一个轨迹的概率,就是所有State和这个State下给出的Action概率的连乘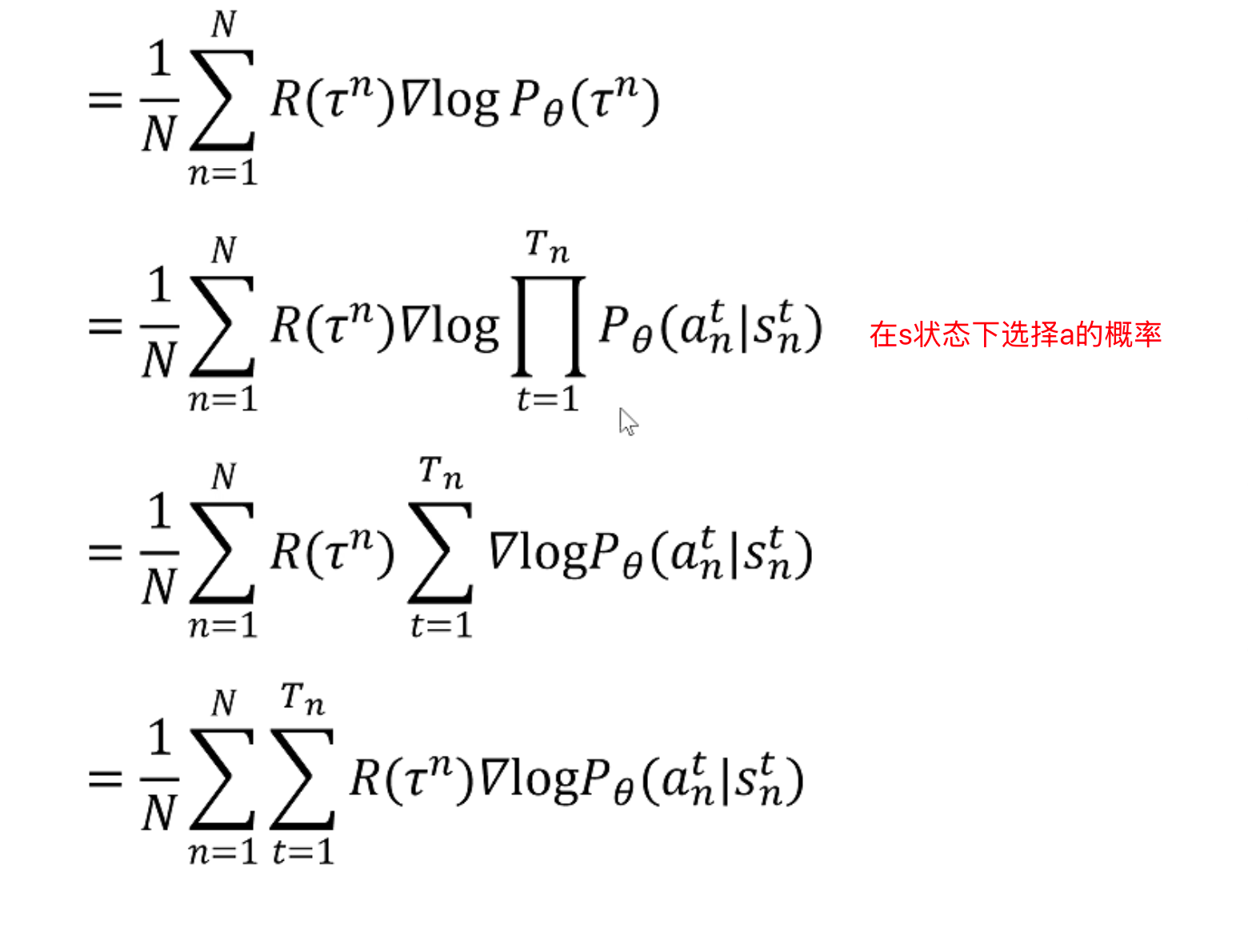
得到最终的表达式,其含义是对所有可能的轨迹期望最大的梯度,用这个梯度乘学习率去更新神经网络的参数,就是Policy Gradient,梯度策略算法
去掉梯度来看表达式
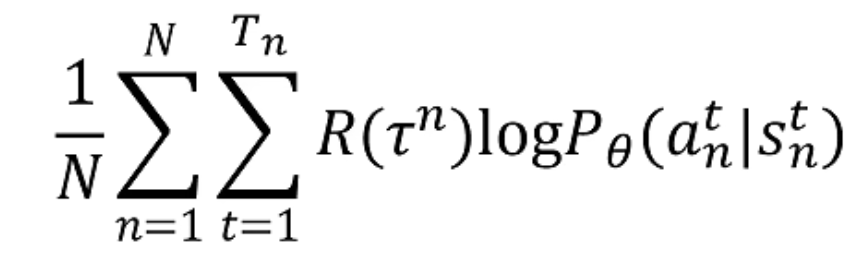
第一部分: R ( τ n ) R(\tau^{n}) R(τn)
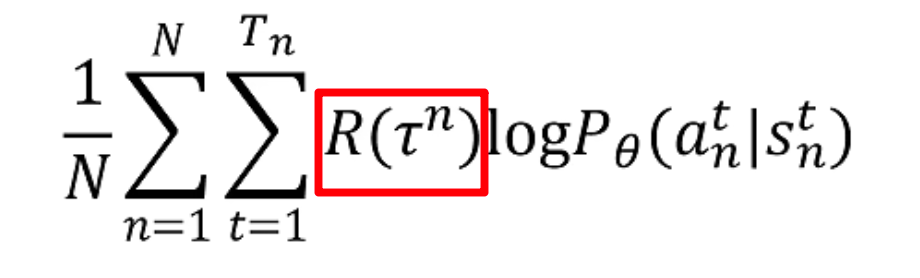
这是一个轨迹得到的Return。
第二部分: log P θ ( a n t ∣ s n t ) \log P_{\theta}\left(a_{n}^{t} \mid s_{n}^{t}\right) logPθ(ant∣snt)
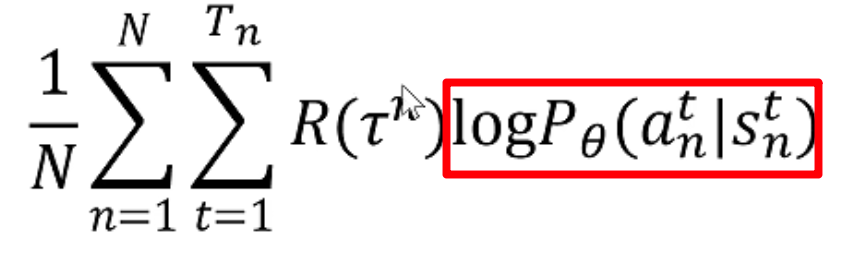
这是每一步根据当前的State做出Action的概率,然后求对数,log的底数是e,所以其是单调递增的。
那么表达式的意义就是如果一个轨迹得到的Return是大于0的,那么就增大这个轨迹里面的所有状态下采取当前Action的概率,如果一个轨迹得到的Return是小于0的,那么就减小这个轨迹里面的所有状态下采取当前Action的概率。
实际训练的数学过程
定义Loss函数,在需要最大化的目标函数前面加个负号,因为Loss是损失:
Loss = − 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) log P θ ( a n t ∣ s n t ) \operatorname{Loss}=-\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_{n}} R\left(\tau^{n}\right) \log P_{\theta}\left(a_{n}^{t} \mid s_{n}^{t}\right) Loss=−N1n=1∑Nt=1∑TnR(τn)logPθ(ant∣snt)
为什么在这里去掉梯度了,因为我们是在优化Loss,而梯度是做数学变换。
定义一个卷积神经网络的输入是当前游戏画面State,输出层是动作的概率值
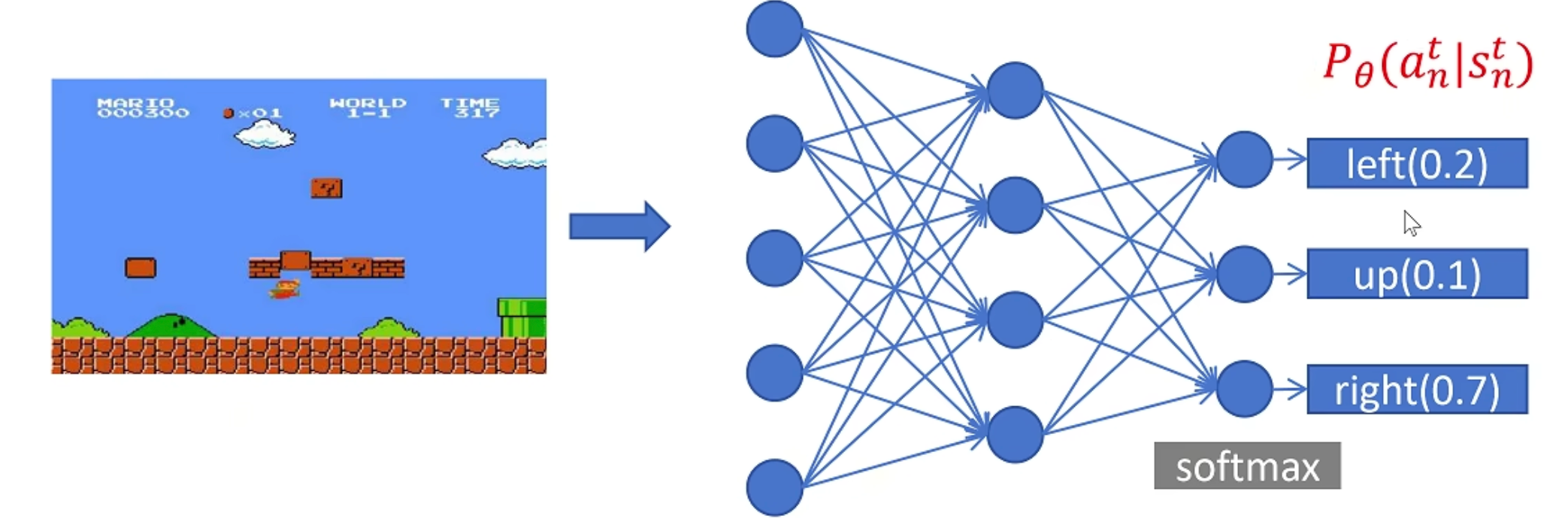
然后让该神经网络连续玩N场游戏

得到N个轨迹和N个Return值。
然后进行训练就是不断更新网络,然后采集数据,这种更新策略叫On Policy,采集数据的Policy和我们训练的Policy是一个,这样的方式存在一个问题就是采集数据时间太久了。
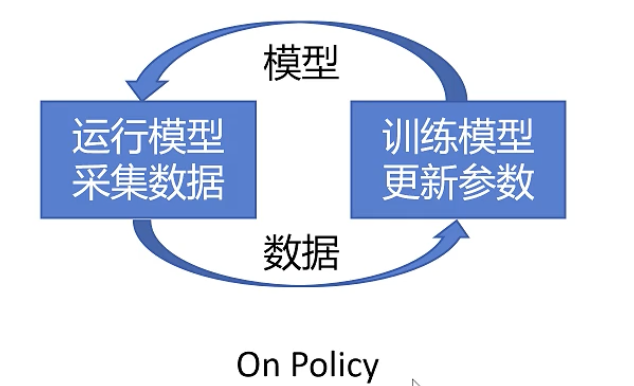
如何优化这个公式?
此公式的含义是:如果一个轨迹得到的Return是大于0的,就增大这个轨迹在所有状态下,采取当前Action的概率,如果一个轨迹得到的Return是小于0的,就增大这个轨迹在所有状态下,减小当前Action的概率。
第一点优化:我们是否要增大在状态S下做A的概率,应该看做这个动作之后到游戏结束所累积的Reward,而不是整个轨迹所累积的Reward因为一个动作只能影响其做了之后的Reward而不能影响做之前的。
第二点优化:一个动作A可以对接下来的几步产生影响,且影响只会持续几步不会一直对下面一直到结束的Reward产生影响,后面的Reward更多是由当前的Action影响。
针对这两点,我们修改公式:
R ( τ n ) → ∑ t ′ = t T n y t ′ − t r t ′ n = R t n R\left(\tau^{n}\right) \rightarrow \sum_{t^{\prime}=t}^{T_{n}} y^{t^{\prime}-t} r_{t^{\prime}}^{n}=R_{t}^{n} R(τn)→t′=t∑Tnyt′−trt′n=Rtn
第一个修改是求和公式的开始,原来是对整个轨迹的Reward求和,现在是当前步 t t t到轨迹结束求和
第二个修改是引入了衰减因子 γ \gamma γ, γ \gamma γ小于1,表示距离当前动作越远,当前动作对于Reward的影响越小,呈现指数级衰减。
此外还有一个问题,根据之前的公式:
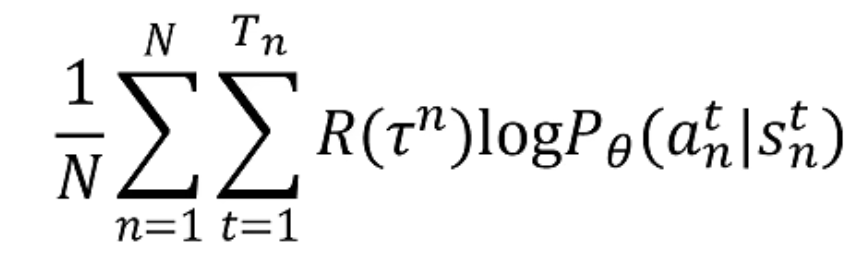
我们注意到 R ( τ n ) R(\tau^n) R(τn)的正负会影响整个世子的正负,也就是说在好的情况下,无论做什么动作,所有的Reward都是正,那么算法就会增加所有动作的概率,Reward大的动作概率会增加的大一些。
反之,在坏的情况下,无论做什么动作,所有的Reward都是负,那么算法就会减小所有动作的概率。
这样的问题会让训练变得很慢,我们希望让相对好的动作概率增加,让相对差的动作概率减小。
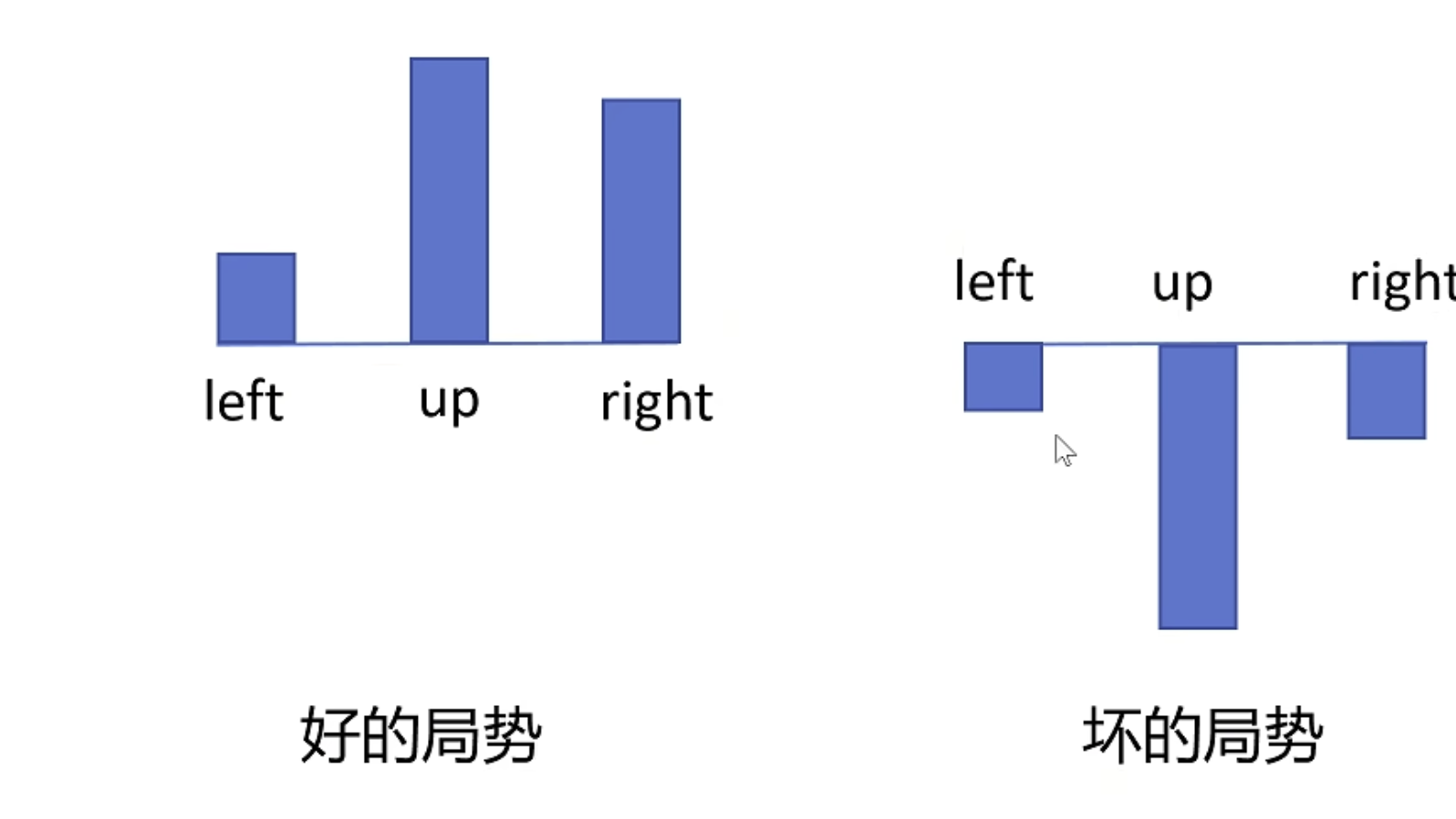
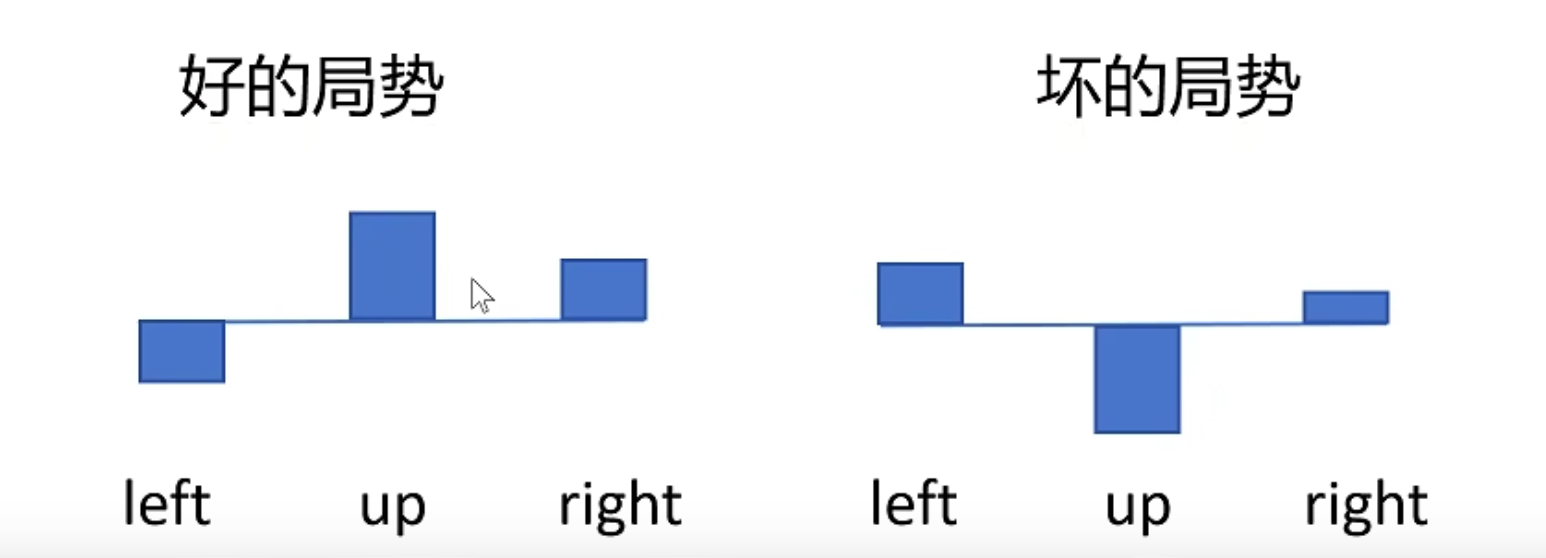
如何解决上述问题?
我们引入一个baseline,就是给所有的reward都减去一个baseline,减去baseline的结果变成了这样。
其公式修改如下:
红框内就是需要减去的baseline
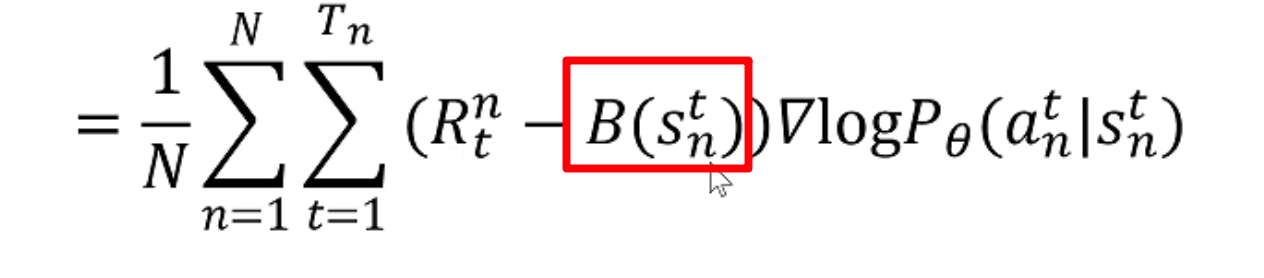
这就是A2C算法。
基础知识第二次补充
Action-Value Function
R t n R^{n}_t Rtn每次都是一次随机采样,方差大,训练很不稳定,一次随机采样可能出现同一个动作,得到的Reward却天差地别,所以需要无限多次的采样,才能得到相对准确的Reward。
所以引入了Action-Value Function:
Q θ ( s , a ) Q_\theta(s,a) Qθ(s,a)表示在state s下,做出action a,期望的回报,反映了一个动作的价值。
State-Value Function
V θ ( s ) V_\theta(s) Vθ(s)表示在State S下,不论做任何动作得到的Return的期望值,表示状态价值函数。
Advantage Function
A θ ( s , a ) = Q θ ( s , a ) − V θ ( s ) A_\theta(s,a) =Q_\theta(s,a)- V_\theta(s) Aθ(s,a)=Qθ(s,a)−Vθ(s)表示在state s下,做出Action a,比其他动作能带来多少优势。
原来我们的函数是
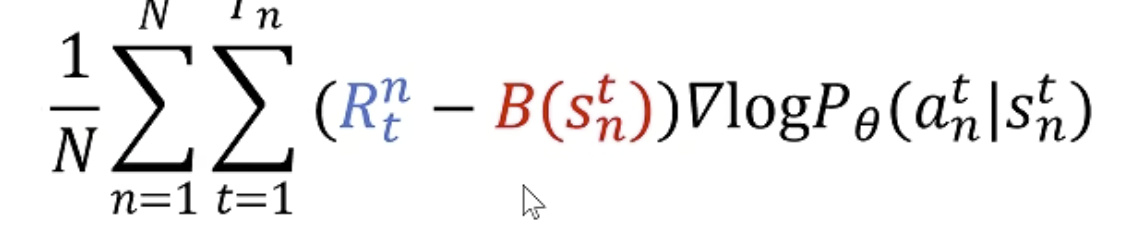
Reward减去的baseline实际上就是想表达优势函数的意思,现在我们有了优势函数的定义,上述公式就可以替换为:
如何计算优势函数?
先看下面的等式
上述含义是对于 s t s_t st时刻做出动作 a a a期望得到的Return的值,等于这一步得到的reward r t r_t rt加上衰减系数乘下一个状态 s t + 1 s_{t+1} st+1的状态价值函数。
然后把这个等式带入优势函数:
这样的优势函数就由原来需要训练两个神经网络(一个动作价值,一个状态价值),变成了只需要一训练个状态价值的网络了。
下面我们想对状态价值函数也进行action和reward的采样,那么对轨迹的下一步进行采样:
那么我们就可以对优势函数进行多步采样了:
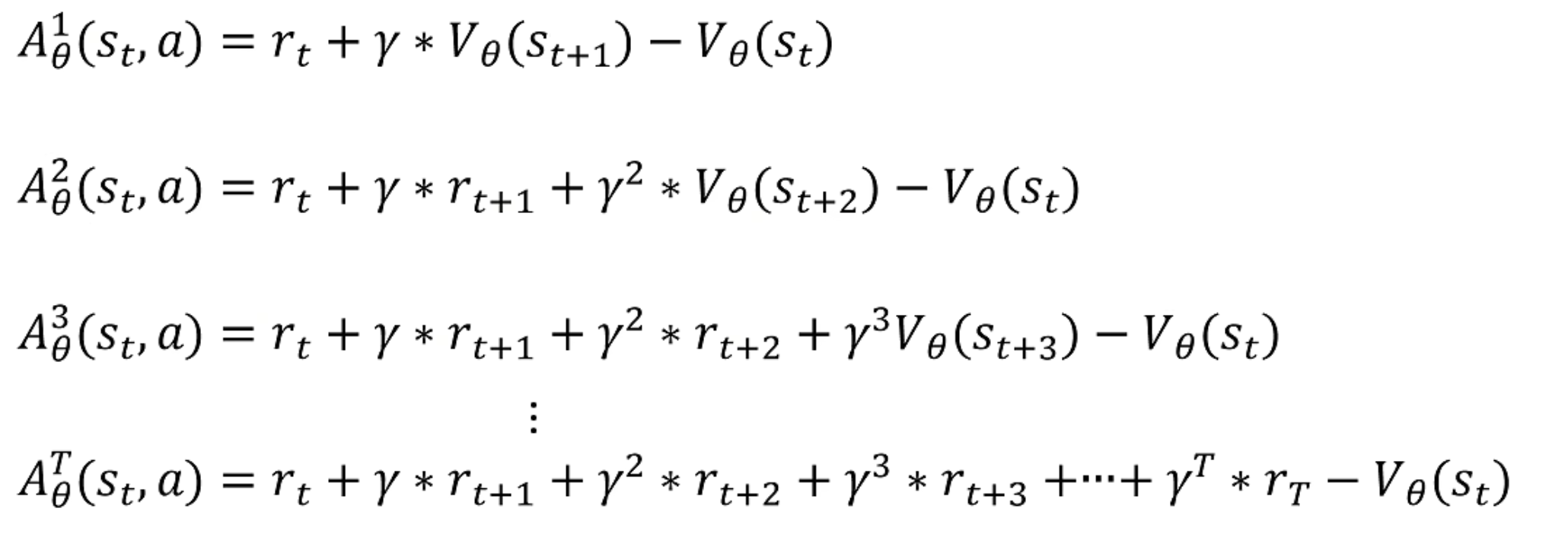
采样的步越多,方差越大,偏差越小,采样的步越小,方差越小,偏差越大。
为了方便表示,引入 δ t \delta_t δt,其表示在t步执行特定动作带来的优势
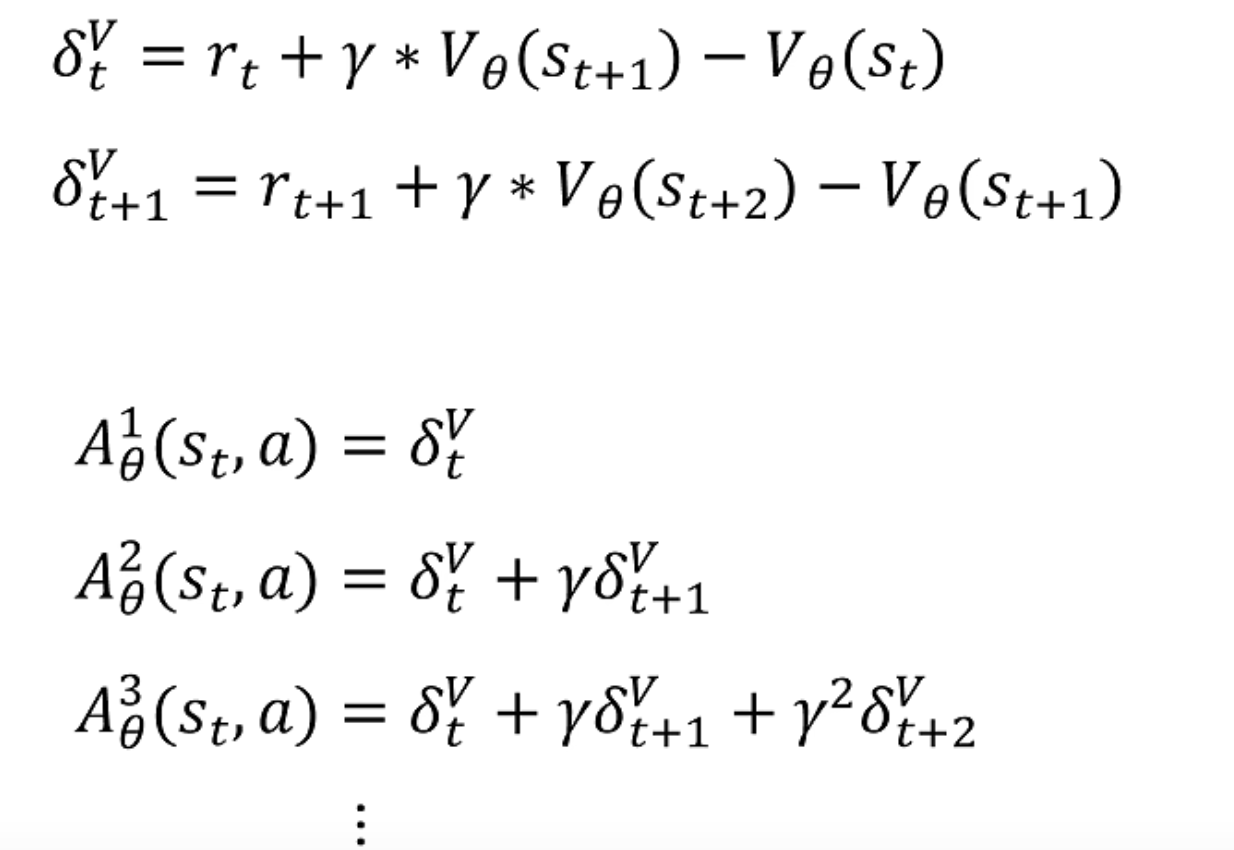
那么我们需要采样几步呢?
答案是全部采样
GAE:Generalized Advantage Estimation
我全都给优势函数进行一步采样,通过分配不同的权重:
A θ G A E ( s t , a ) = ( 1 − λ ) ( A θ 1 + λ ∗ A θ 2 + λ 2 A θ 3 + ⋯ ) λ = 0.9 : A θ G A E = 0.1 A θ 1 + 0.09 A θ 2 + 0.081 A θ 3 + ⋯ A_{\theta}^{G A E}\left(s_{t}, a\right)=(1-\lambda)\left(A_{\theta}^{1}+\lambda * A_{\theta}^{2}+\lambda^{2} A_{\theta}^{3}+\cdots\right) \quad \lambda=0.9: \quad A_{\theta}^{G A E}=0.1 A_{\theta}^{1}+0.09 A_{\theta}^{2}+0.081 A_{\theta}^{3}+\cdots AθGAE(st,a)=(1−λ)(Aθ1+λ∗Aθ2+λ2Aθ3+⋯)λ=0.9:AθGAE=0.1Aθ1+0.09Aθ2+0.081Aθ3+⋯
将 δ t \delta_t δt带入表达式并化简:
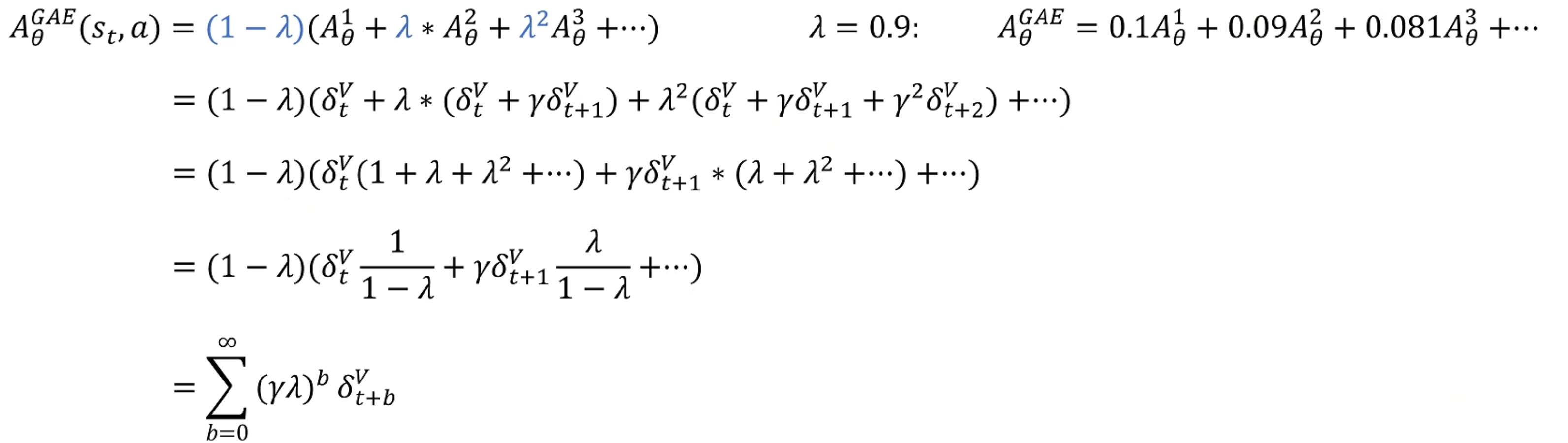
最后得到的含义是在状态 s t s_t st时做动作 a a a的优势,并且改善了采样的问题。
这样最后的策略梯度的优化目标函数变成了:
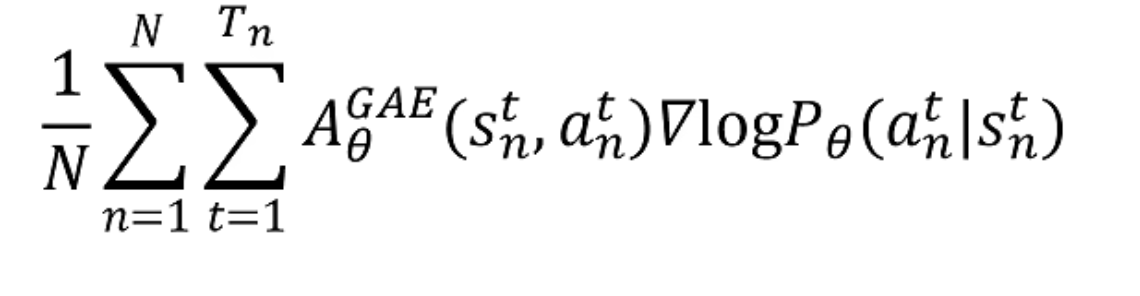
状态价值函数 V θ ( s t ) V_\theta(s_t) Vθ(st)需要用一个神经网络来拟合。
经过上面这些基础的学习,终于可以进去PPO算法了。
PPO(Proximal Policy Optimization)
On Policy每次采集数据用的策略和训练用的策略是同一个,重新采集数据很慢

- On-policy :
用当前策略生成的数据,更新同一个策略
→ "自己实践,自我改进"
(例:SARSA, A2C, TRPO) - Off-policy :
用其他策略(历史/随机策略)生成的数据,更新目标策略
→ "从别人的经验中学习"
(例:Q-learning, DQN, SAC) - off-policy 的最简单解释: the learning is from the data off the target policy。
- on-policy 方法要求使用当前策略生成的数据来更新策略。
- on/off-policy的概念帮助区分训练的数据来自于哪里。
目标:计算 E x ∼ p ( x ) f ( x ) = ∑ x f ( x ) ⋅ p ( x ) (但我们无法从 p ( x ) 采样,或者采样成本太高) = ∑ x f ( x ) ⋅ p ( x ) ⋅ q ( x ) q ( x ) (乘以 q ( x ) q ( x ) = 1 ,不改变值,只为引入一个新分布 q ( x ) ) = ∑ x f ( x ) ⋅ p ( x ) q ( x ) ⋅ q ( x ) (把 q ( x ) 拆出来,准备把它当作"新的采样分布") = E x ∼ q ( x ) f ( x ) ⋅ p ( x ) q ( x ) (现在整个求和式变成了:对 x 从 q ( x ) 采样时的期望) ≈ 1 N ∑ n = 1 N f ( x ( n ) ) ⋅ p ( x ( n ) ) q ( x ( n ) ) (用蒙特卡洛方法:从 q ( x ) 采 N 个样本 x ( n ) 来近似期望) 其中 x ( n ) ∼ q ( x ) \begin{array}{l} \textbf{目标:计算 } \mathbb{E}{x \sim p(x)}f(x) = \sum{x} f(x) \cdot p(x) \\ \quad \text{(但我们无法从 } p(x) \text{ 采样,或者采样成本太高)} \\ \\ = \sum_{x} f(x) \cdot p(x) \cdot \frac{q(x)}{q(x)} \\ \quad \text{(乘以 } \frac{q(x)}{q(x)} = 1 \text{,不改变值,只为引入一个新分布 } q(x)) \\ \\ = \sum_{x} f(x) \cdot \frac{p(x)}{q(x)} \cdot q(x) \\ \quad \text{(把 } q(x) \text{ 拆出来,准备把它当作"新的采样分布")} \\ \\ = \mathbb{E}{x \sim q(x)}\!\left f(x) \\cdot \\frac{p(x)}{q(x)} \\right \\ \quad \text{(现在整个求和式变成了:对 } x \text{ 从 } q(x) \text{ 采样时的期望)} \\ \\ \approx \frac{1}{N} \sum{n=1}^{N} f(x^{(n)}) \cdot \frac{p(x^{(n)})}{q(x^{(n)})} \\ \quad \text{(用蒙特卡洛方法:从 } q(x) \text{ 采 } N \text{ 个样本 } x^{(n)} \text{ 来近似期望)} \\ \\ \text{其中 } x^{(n)} \sim q(x) \end{array} 目标:计算 Ex∼p(x)f(x)=∑xf(x)⋅p(x)(但我们无法从 p(x) 采样,或者采样成本太高)=∑xf(x)⋅p(x)⋅q(x)q(x)(乘以 q(x)q(x)=1,不改变值,只为引入一个新分布 q(x))=∑xf(x)⋅q(x)p(x)⋅q(x)(把 q(x) 拆出来,准备把它当作"新的采样分布")=Ex∼q(x)f(x)⋅q(x)p(x)(现在整个求和式变成了:对 x 从 q(x) 采样时的期望)≈N1∑n=1Nf(x(n))⋅q(x(n))p(x(n))(用蒙特卡洛方法:从 q(x) 采 N 个样本 x(n) 来近似期望)其中 x(n)∼q(x)$
经过上述的推导,我们就可以把On Policy的训练转变成Off Policy的训练

关于上述公式的参数解释如下:
-
1 N ∑ n = 1 N \frac{1}{N} \sum_{n=1}^{N} N1∑n=1N:对 N N N 条轨迹(采样的样本)取平均值。这里的 N N N 表示采样轨迹的总数,通过对多个轨迹求平均来估计梯度,以获得更稳定的更新。
-
∑ t = 1 T n \sum_{t=1}^{T_n} ∑t=1Tn:对每条轨迹 n n n 中的 T n T_n Tn 个时间步求和,表示对单条轨迹中的所有时间步的累积。
-
A θ ′ G A E ( s n t , a n t ) A_{\theta'}^{GAE}(s_n^t, a_n^t) Aθ′GAE(snt,ant):广义优势估计(Generalized Advantage Estimation, GAE),由参数 θ ′ \theta' θ′ 估计,用于计算在状态 s n t s_n^t snt 下采取动作 a n t a_n^t ant 的优势。
-
∇ P θ ( a n t ∣ s n t ) P θ ′ ( a n t ∣ s n t ) \frac{\nabla P_\theta(a_n^t | s_n^t)}{P_{\theta'}(a_n^t | s_n^t)} Pθ′(ant∣snt)∇Pθ(ant∣snt):表示策略的梯度,其中分母 P θ ′ ( a n t ∣ s n t ) P_{\theta'}(a_n^t | s_n^t) Pθ′(ant∣snt) 是旧策略(或目标策略),分子 ∇ P θ ( a n t ∣ s n t ) \nabla P_\theta(a_n^t | s_n^t) ∇Pθ(ant∣snt) 是新策略的梯度。这个比值反映了新旧策略在同一状态-动作对上的相对概率密度,利用这一比值来更新策略参数 θ \theta θ。
最后得到的Loss如下,这就是PPO的loss函数:
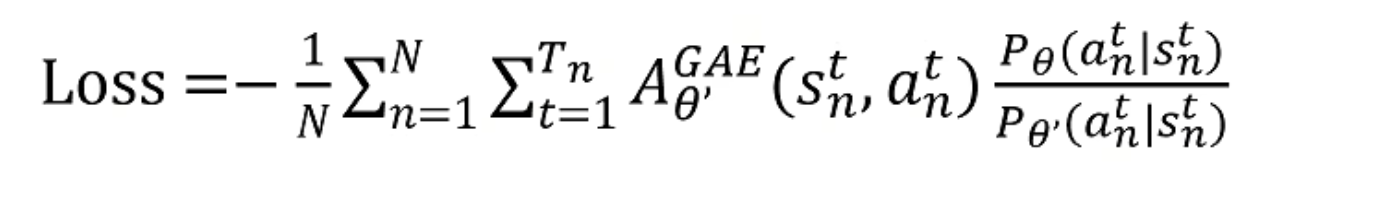
我们理解 θ ′ \theta' θ′是旧策略, θ \theta θ是新策略,可以看到其是用 θ ′ \theta' θ′做数据采样,然后 θ \theta θ来调整优势函数。
PPO-KL
还有一点限制,我们训练的新策略,不能和旧策略差别过大,所以引入了KL散度。
KL散度就是描述两个概率分布相似程度的指标,分布越不一致,KL散度越大。
这样的话,Loss就成为了:
L o s s k l = − 1 N ∑ n = 1 N ∑ t = 1 T n A θ ′ G A E ( s n t , a n t ) P θ ( a n t ∣ s n t ) P θ ′ ( a n t ∣ s n t ) + β K L ( P θ , P θ ′ ) Loss_{kl} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t | s_n^t)}{P_{\theta'}(a_n^t | s_n^t)} + \beta KL(P_\theta, P_{\theta'}) Losskl=−N1n=1∑Nt=1∑TnAθ′GAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt)+βKL(Pθ,Pθ′)
这就是PPO-KL。
其中
- β K L ( P θ , P θ ′ ) \beta KL(P_\theta, P_{\theta'}) βKL(Pθ,Pθ′):这是KL散度项,用于限制新旧策略之间的距离,其中 K L ( P θ , P θ ′ ) KL(P_\theta, P_{\theta'}) KL(Pθ,Pθ′) 表示策略 P θ P_\theta Pθ和旧策略 P θ ′ P_{\theta'} Pθ′之间的KL散度。超参数 β \beta β控制KL散度项的权重,从而调节新旧策略之间的差异,防止策略更新过大导致不稳定。
整个PPO-KL损失函数的目的是通过限制新旧策略的差异(使用KL散度项)来优化策略,使其更稳定地朝着优势更高的方向进行更新。
PPO-CLIP
PPO截断(PPO-Clipped)是 PPO 的另一种变体,它通过对比新旧策略的比值,来限制策略更新的幅度,从而保证策略的稳定性。具体来说,PPO-Clipped 的目标函数为:
L o s s c l i p = − 1 N ∑ n = 1 N ∑ t = 1 T n min ( A θ ′ G A E ( s n t , a n t ) P θ ( a n t ∣ s n t ) P θ ′ ( a n t ∣ s n t ) , clip ( P θ ( a n t ∣ s n t ) P θ ′ ( a n t ∣ s n t ) , 1 − ϵ , 1 + ϵ ) A θ ′ G A E ( s n t , a n t ) ) Loss_{clip} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} \min \left( A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t | s_n^t)}{P_{\theta'}(a_n^t | s_n^t)}, \, \text{clip} \left( \frac{P_\theta(a_n^t | s_n^t)}{P_{\theta'}(a_n^t | s_n^t)}, 1 - \epsilon, 1 + \epsilon \right) A_{\theta'}^{GAE}(s_n^t, a_n^t) \right) Lossclip=−N1n=1∑Nt=1∑Tnmin(Aθ′GAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt),clip(Pθ′(ant∣snt)Pθ(ant∣snt),1−ϵ,1+ϵ)Aθ′GAE(snt,ant))
-
clip ( P θ ( a n t ∣ s n t ) P θ ′ ( a n t ∣ s n t ) , 1 − ϵ , 1 + ϵ ) \text{clip} \left( \frac{P_\theta(a_n^t | s_n^t)}{P_{\theta'}(a_n^t | s_n^t)}, 1 - \epsilon, 1 + \epsilon \right) clip(Pθ′(ant∣snt)Pθ(ant∣snt),1−ϵ,1+ϵ):裁剪函数,将概率比裁剪到 1 − ϵ , 1 + ϵ 1 - \\epsilon, 1 + \\epsilon 1−ϵ,1+ϵ 区间,防止策略的更新步长过大。这里 ϵ \epsilon ϵ 是一个超参数,控制裁剪的范围。
-
min ( ⋅ , ⋅ ) \min(\cdot, \cdot) min(⋅,⋅):在
未裁剪的概率比项和裁剪后的项之间取最小值。这一操作的目的在于限制策略更新幅度,以防止策略偏离旧策略过远,从而导致不稳定的学习过程。
整个PPO-clip损失函数的作用是通过裁剪操作约束策略的变化幅度,使策略更新不会过于激进。这种方式相比于传统策略梯度方法更为稳定,并且在优化过程中能够有效平衡探索和利用。
DPO
DPO是Direct Performance Optimization (直接偏好优化),其可以直接从用户的偏好数据中学习
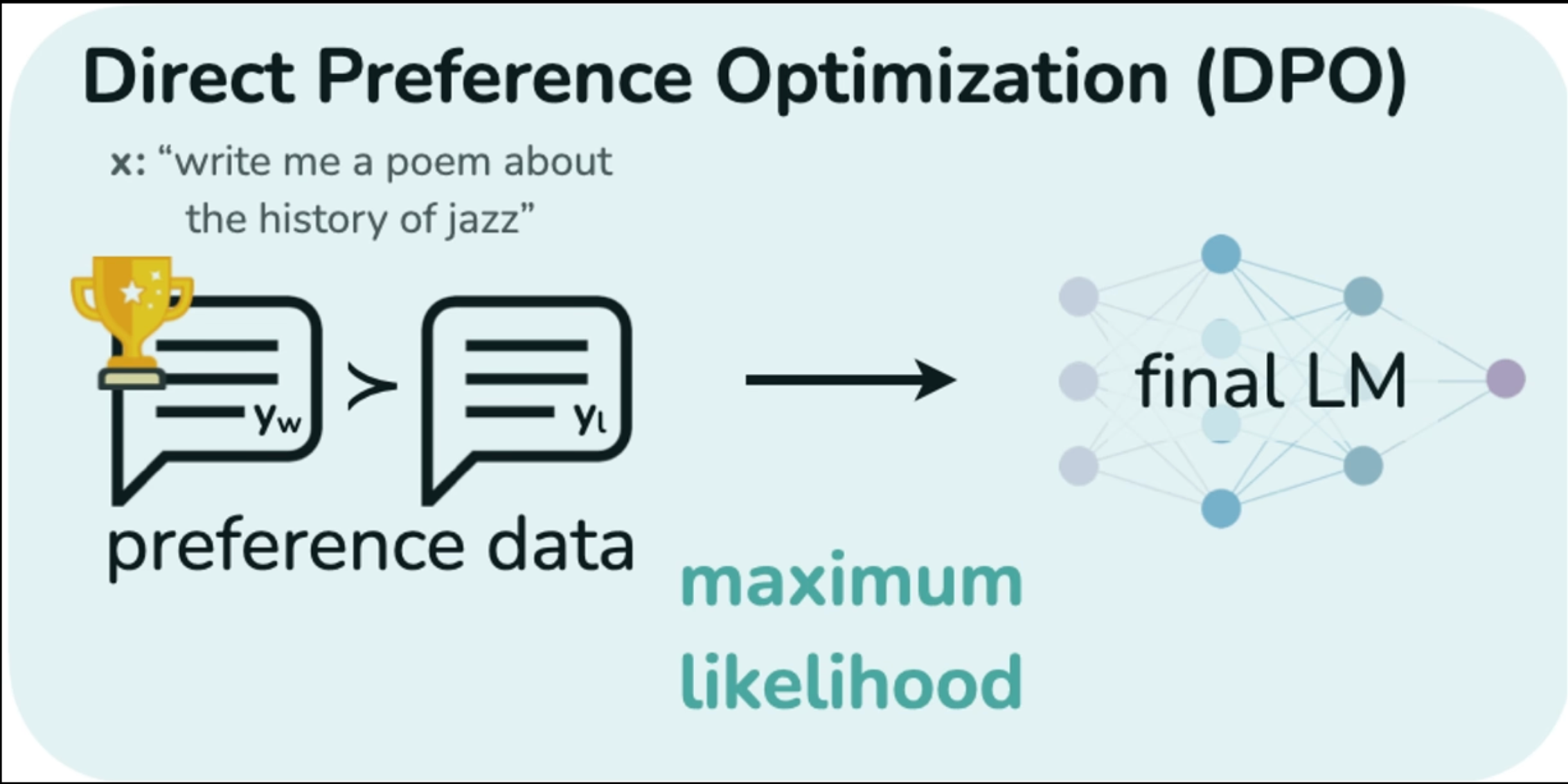
这里有一个概念很关键,叫Bradley-Terry模型,其可以对比较关系进行建模


所以可以用此公式来建模,比较y1和y2的好坏,为了防止其返回负数,需要加上指数函数。
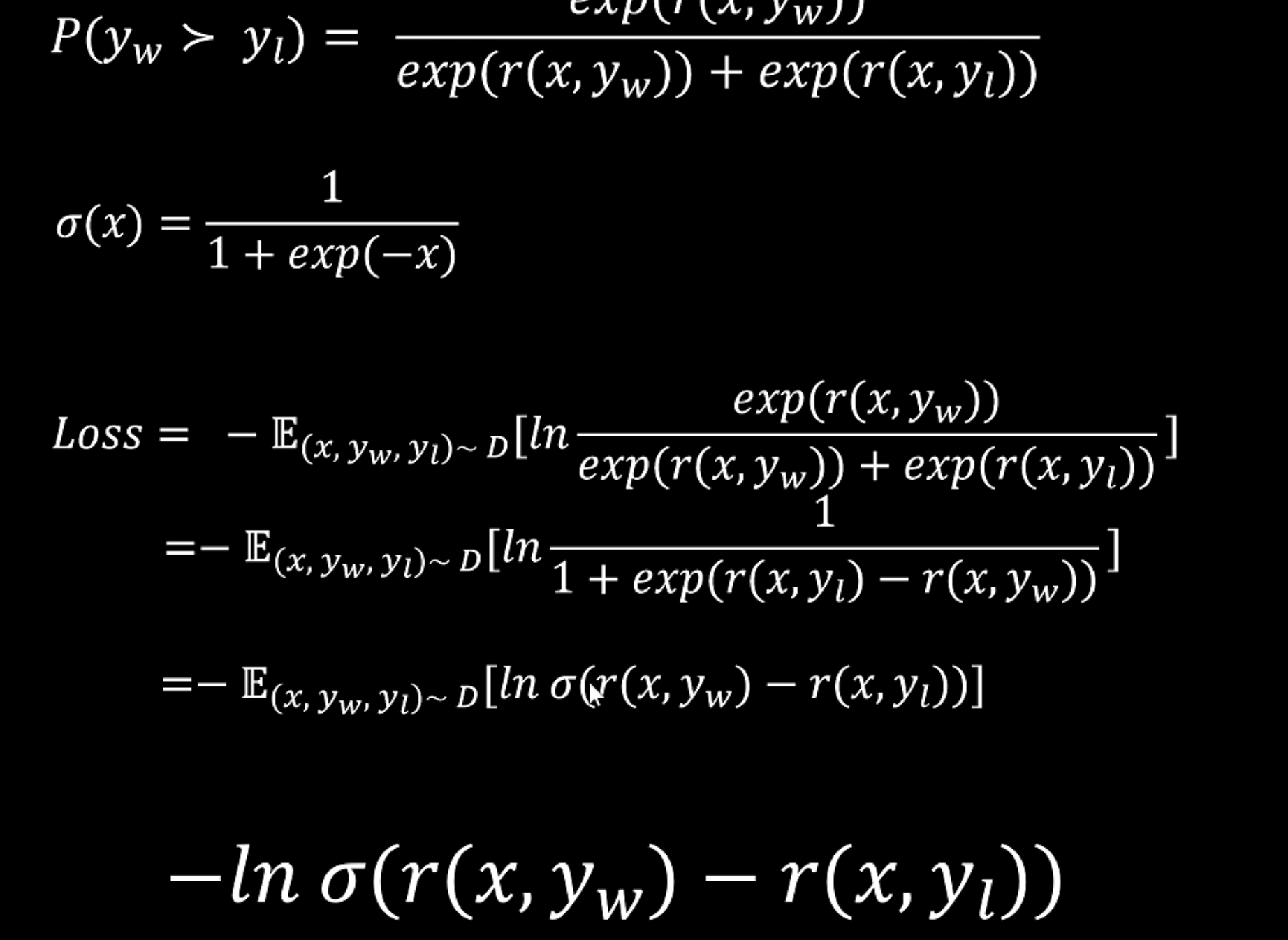
其得到的loss就是优化 y w y_w yw大于 y l y_l yl。
那么DPO的训练目标如下:

经过推导后得到
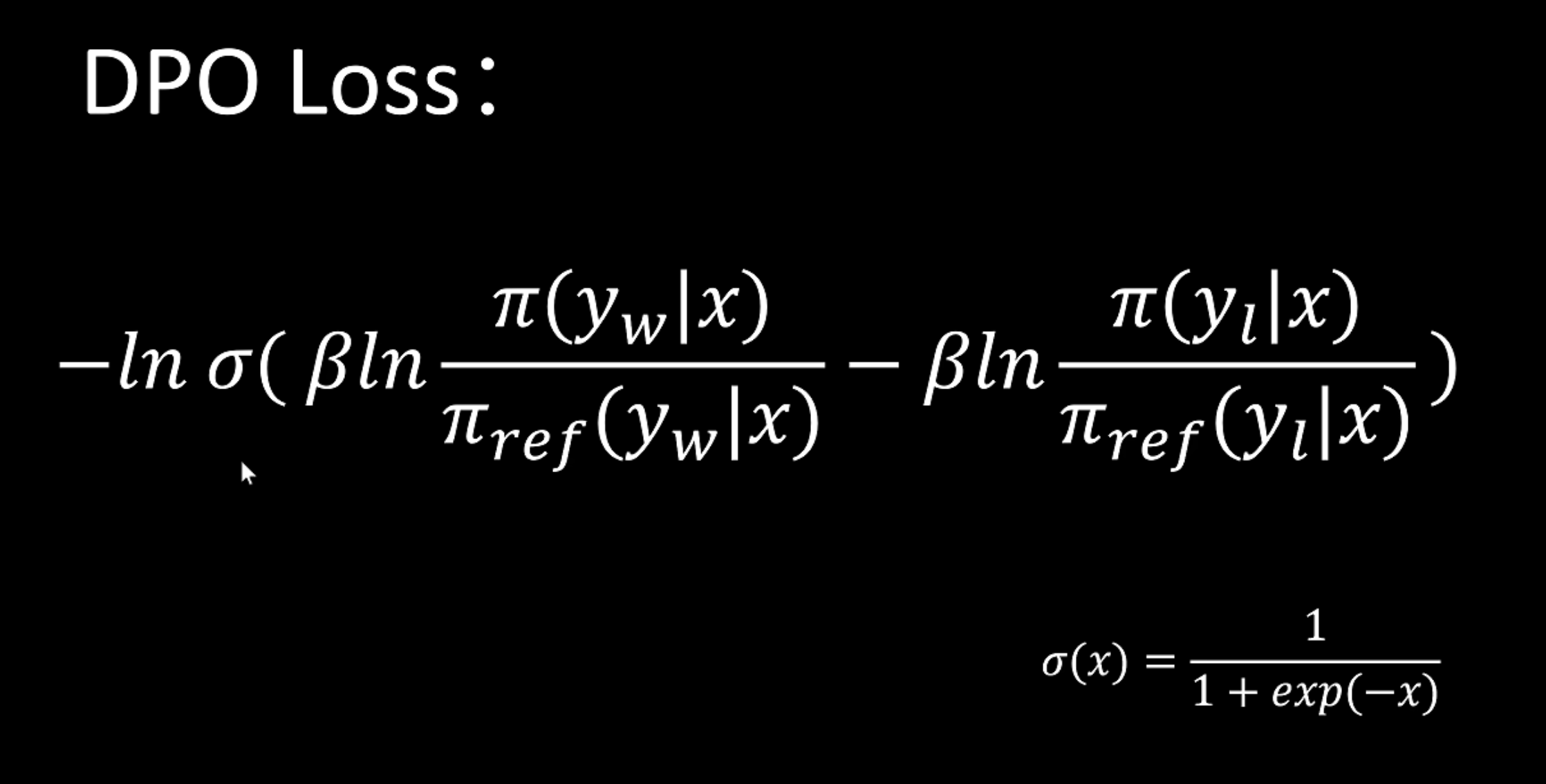
PPO的奖励是显式奖励模型,而DPO是隐式奖励。

GRPO
如果上面的内容都理解的话,那么理解起来GRPO就会很容易了。
GRPO出自《DeepSeekMath: Pushing the Limits of Mathematical
Reasoning in Open Language Models》原文下载链接:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
先看一下在原文中提出的PPO公式,看起来好像和我们推导的有一些区别,实际上我们将前面的期望进行重要性采样之后,就和我们所推导的公式长得一样了

下面是原论文中PPO与GRPO的区别
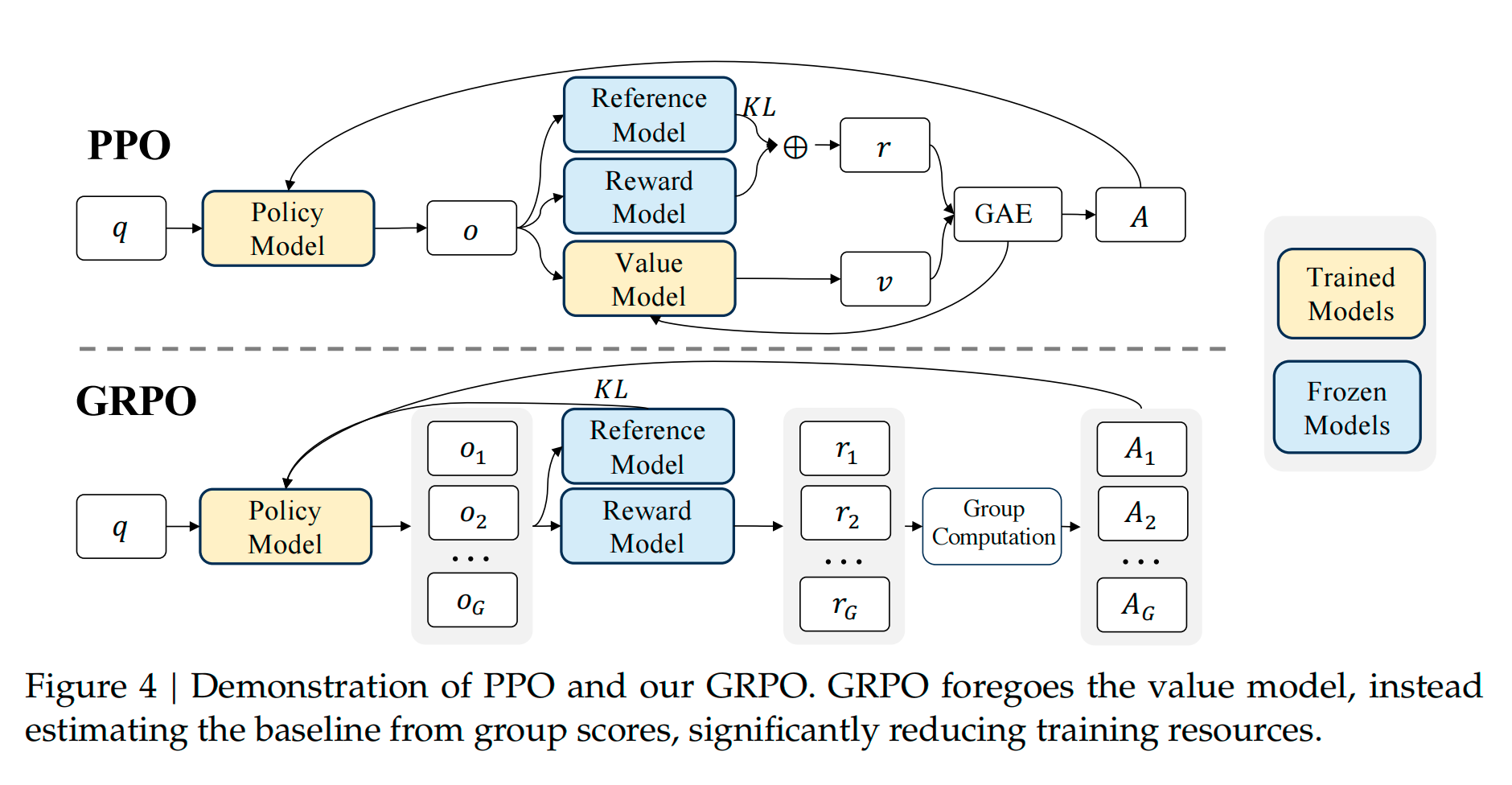
首先我们看左侧的output,也就是o,PPO只有一个o但是GRPO是G个o。也就是说对于一个问题 q q q,GRPO会生成G个输出o,然后通过组内比较,来计算其相对优势。
其组内均值和标准差就是:
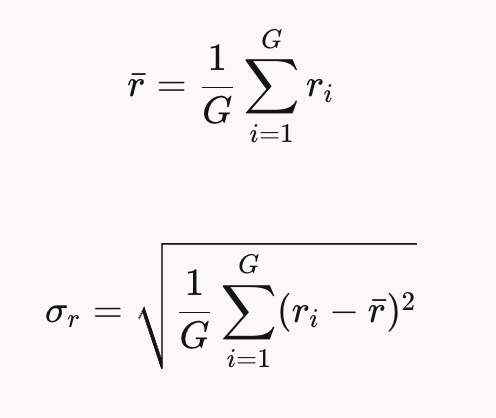
然后归一化组内的相对优势,对 i i i个输出的第 t t t个token
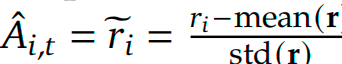
相比于PPO,GRPO的优势函数无需价值网络 ,是基于同一个prompt的多个样本进行相对比较,去掉了价值网络使GRPO减少了很大的内存占用。
所以GRPO的公式就变成了:
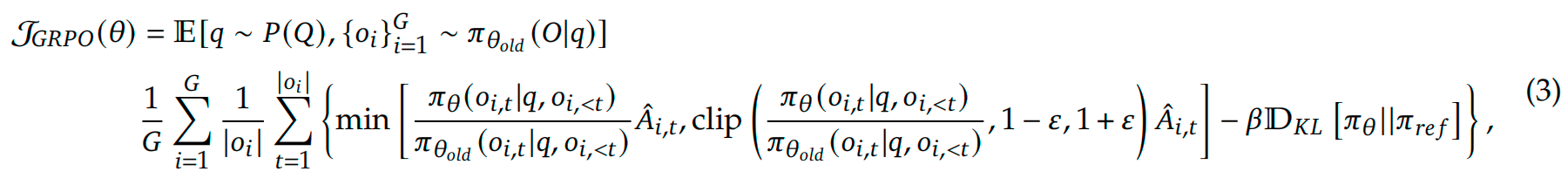
此外,GRPO 通过直接在损失函数中加入策略模型和参考模型之间的 KL 散度来正则化,而不是在奖励中加入 KL 惩罚项,从而简化了训练过程。
GRPO的KL散度公式如下: