分区表是什么
分区表就是把一张表的数据,按照设置好的条件,单独存储在磁盘的不同位置,也就是不同分区的数据是独立的,互不影响的。
在没有分区表的情况下,一张表的数据就是存储在一个文件中,用了分区表之后,单张表的数据会在硬盘上分开存储。对表的操作来说,没有什么区别。
分区表的优点
- 更少的数据检索范围
- 拆分超级大的表,将部分数据加载至内存
- 分区表的数据更容易维护
- 分区表数据文件可以分布在不同的硬盘上,并发 IO
- 减少锁的范围,避免大表锁表
- 可独立备份,恢复分区数据
什么时候创建分区表
当单张表的数据量较大,且因为数据量大,导致查询无法满足要求。
不想做分库分表这样大的改动。
未创建分区表的情况
看下如果不创建分区表,查询是怎么样的,可以和创建分区表的情况做对比,这样更好理解。
sql
CREATE TABLE test_partition (
id int(11) NOT NULL,
create_time datetime NOT NULL,
cyear int,
PRIMARY KEY (id,create_time , cyear)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into test_partition values (1,"20130722000000",2013);
insert into test_partition values (2,"20140722000000",2014);
insert into test_partition values (3,"20150722000000",2015);
insert into test_partition values (4,"20160722000000",2016);
insert into test_partition values (5,"20170722000000",2017);
insert into test_partition values (6,"20180722000000",2018);
insert into test_partition values (7,"20190722000000",2019);
insert into test_partition values (8,"20200722000000",2020);
insert into test_partition values (9,"20210722000000",2021);
insert into test_partition values (10,"20220722000000",2022);执行上面的SQL,创建表,并插入记录。
查询年份大于2016的记录,语句如下:
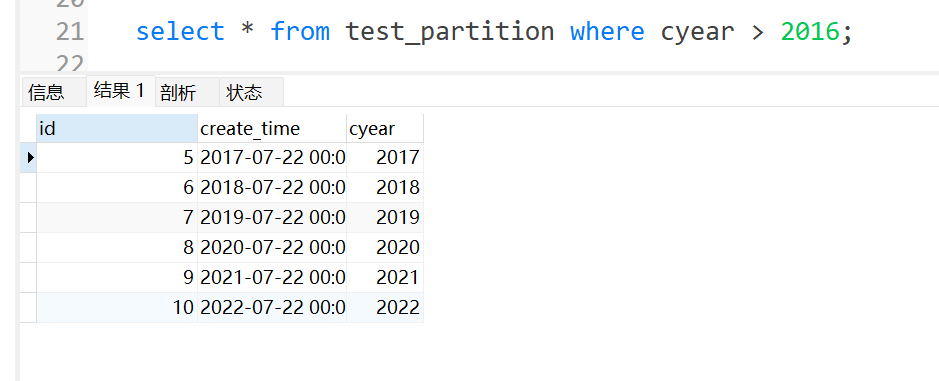
这个查询,如果想优化,首先想到的就是在年份字段上添加索引,因为年份字段作为查询条件的一个字段。
但实际操作就会发现,添加了索引,最终查询并没有使用这个索引,因为MySQL执行器会推断,当结果集的数量占总记录数的比例较大时,不会使用索引,因为无论是否使用索引,扫描的记录总数差不多。
解决方法就是在磁盘的检索范围上进行优化,那就是创建分区表来解决。
分区表的创建
执行下面的语句,可以删除上面创建的表,重新创建带有分区的表。
sql
drop table test_partition;
CREATE TABLE test_partition (
id int(11) NOT NULL,
create_time datetime NOT NULL,
cyear int,
PRIMARY KEY (id,create_time , cyear)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE (cyear)
(
PARTITION y14before VALUES LESS THAN (2014) ,
PARTITION y15 VALUES LESS THAN (2015) ,
PARTITION y16 VALUES LESS THAN (2016) ,
PARTITION y17 VALUES LESS THAN (2017) ,
PARTITION y18 VALUES LESS THAN (2018) ,
PARTITION y19 VALUES LESS THAN (2019) ,
PARTITION y20 VALUES LESS THAN (2020) ,
PARTITION y20after VALUES LESS THAN maxvalue );PARTITION BY RANGE 表示根据字段进行范围分区。
PARTITION就是分区表的关键字,y15代表分区的名称,LESS THAN条件。
当进行数据插入时,年份为2015年的数据,就会存储在y15这个分区中。年份为2016的数据就会存储在y16这个分区中。以此类推。
分区表的使用
插入数据
sql
insert into test_partition values (1,"20130722000000",2013);
insert into test_partition values (2,"20140722000000",2014);
insert into test_partition values (3,"20150722000000",2015);
insert into test_partition values (4,"20160722000000",2016);
insert into test_partition values (5,"20170722000000",2017);
insert into test_partition values (6,"20180722000000",2018);
insert into test_partition values (7,"20190722000000",2019);
insert into test_partition values (8,"20200722000000",2020);
insert into test_partition values (9,"20210722000000",2021);
insert into test_partition values (10,"20220722000000",2022);可以看到在数据库安装目录的data目录中,test这个文件夹下面有这样一些文件,这就是test数据库中test_partition表的不同分区数据。文件名称对应的就是表名称+分区的名称。
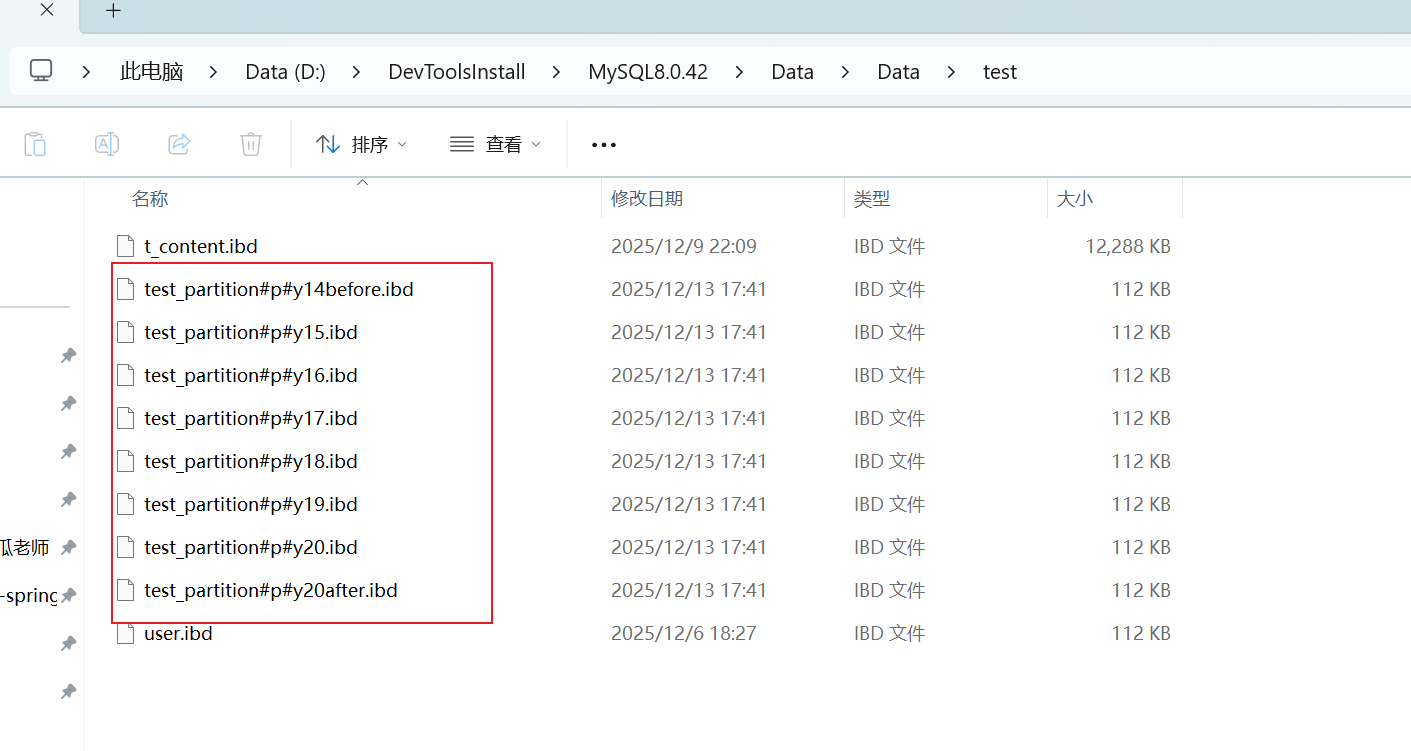
在进行查询时,MySQL会根据查询条件,从指定的分区表中获取数据。这样就缩小了数据的检索范围。

查询这个执行计划,可以看到partitions字段值就是数据涉及到的分区名称。MySQL只去查找涉及到的分区,然后从中获取数据,并不会把所有表数据全部去扫描,从物理层面减少扫描范围。
因为查询条件是年份大于2016,所以只查询2017及其之后年份的数据,2017年的数据存储在y18的分区中,所有就可以看到y18,y19,y20after,这三个分区。
分区表数据统计
通过下面的查询,可以看到表的每个分区中数据分布情况:
sql
select
PARTITION_NAME as "分区",
TABLE_ROWS as "行数"
from information_schema.partitions
where table_schema="test" #数据库名称
and table_name="test_partition"; #表名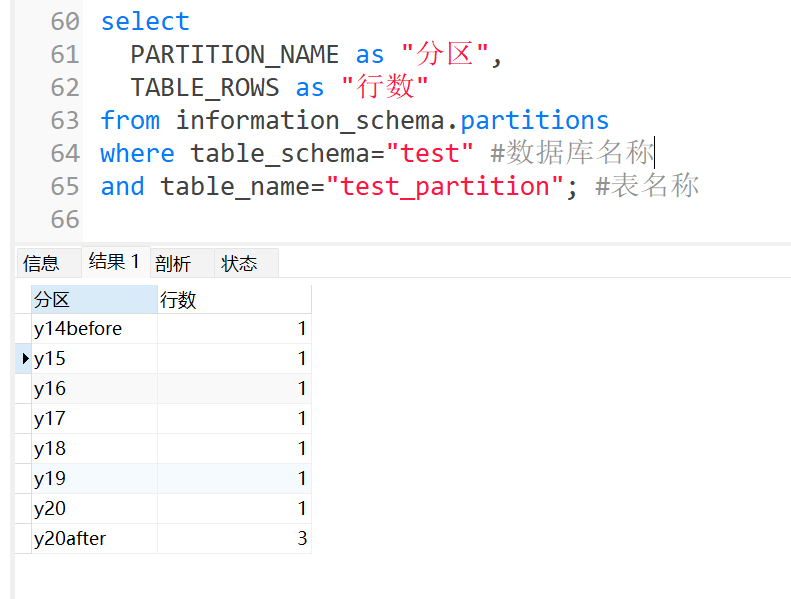
分区表的使用限制
-
查询必须包含分区列(上面例子中的cyear列),不允许对分区列进行计算。
-
分区列必须是数字类型。
-
分区表不支持建立外键索引。
-
建表时主键必须包含所有的列(上面例子中,PRIMARY KEY (id,create_time , cyear))。
-
最多1024个分区。