TL;DR
- 场景:电商扣库存并发更新,读-改-写在多线程/多客户端下发生写覆盖
- 结论:ES 用乐观并发控制(seq_no + primary_term)拒绝乱序/并发写,冲突返回 409
- 产出:最小复现请求、409 速查与修复路径、ES5 前后写一致性参数替代对照

版本矩阵
| 项目 | 说明 |
|---|---|
| 乐观锁控制 | 文中更新冲突使用 if_seq_no/if_primary_term 且返回包含 seqNo 与 primary term,这属于 ES 6+ 的 OCC 语义;具体小版本未在正文标注 |
| 版本号概念 | 部分文中提到 _version 作为乐观锁版本号概念成立;工程上以 if_seq_no/if_primary_term 作为条件更新更贴近当前 ES 实践(正文已用该方式复现 409) |
| 分片一致性语义 | ES5.0 前 consistency/quorum、ES5.0 后 wait_for_active_shards 的语义对比在正文给出;未给出实际集群版本与验证截图对应关系 |
详解并发冲突
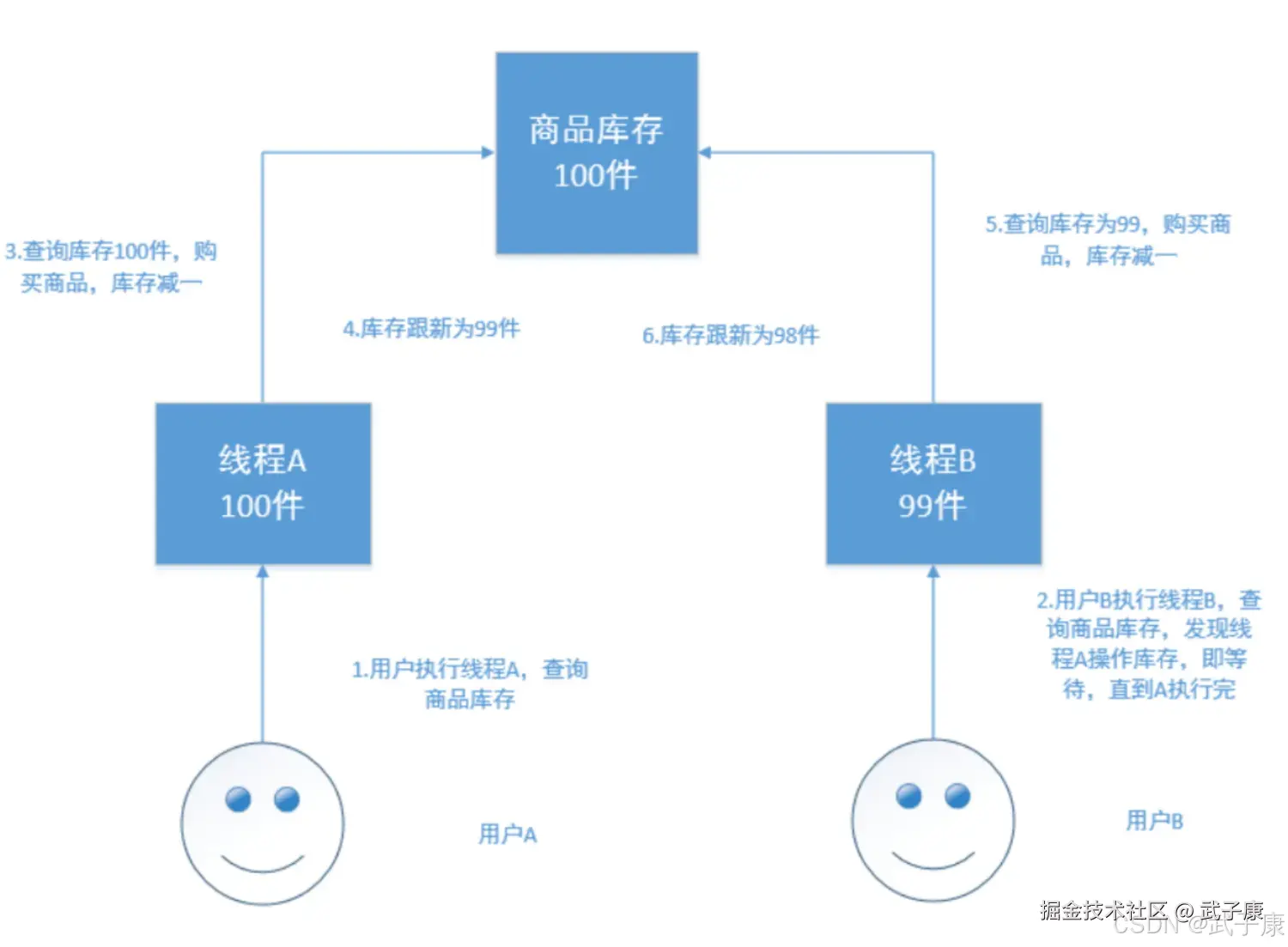
在电商场景下,工作流程为:
- 读取商品信息,包括库存数量
- 用户下单购买
- 更新商品信息,将库存数减一
如果是多线程操作,就可能有多个线程并发的去执行上述的3步骤流程,假如此时有两个人都来读取商品数据,两个线程并发的服务于两个人,同时在进行商品库存数据的修改,假设库存为100件,正确的情况:线程A将库存-1,设置为99件,线程B读取99再-1,设置为98件。但是如果A和B都是读取的99件,那么后续就会出现数量错误的问题。
解决方案
悲观锁
每次去拿数据的时候认为都会被人修改,所有每次拿数据的时候都会加锁,以防止别人修改,直到操作完成后,再释放锁,才会被别人拿去执行。 常见的关系型数据库,就用到了如行锁、表锁、写锁,都是在操作之前的锁。
- 悲观锁优点:方便直接加锁,对外透明,不需要额外的操作。
- 悲观锁缺点:并发能力低,同一时间只能有一个操作。
乐观锁
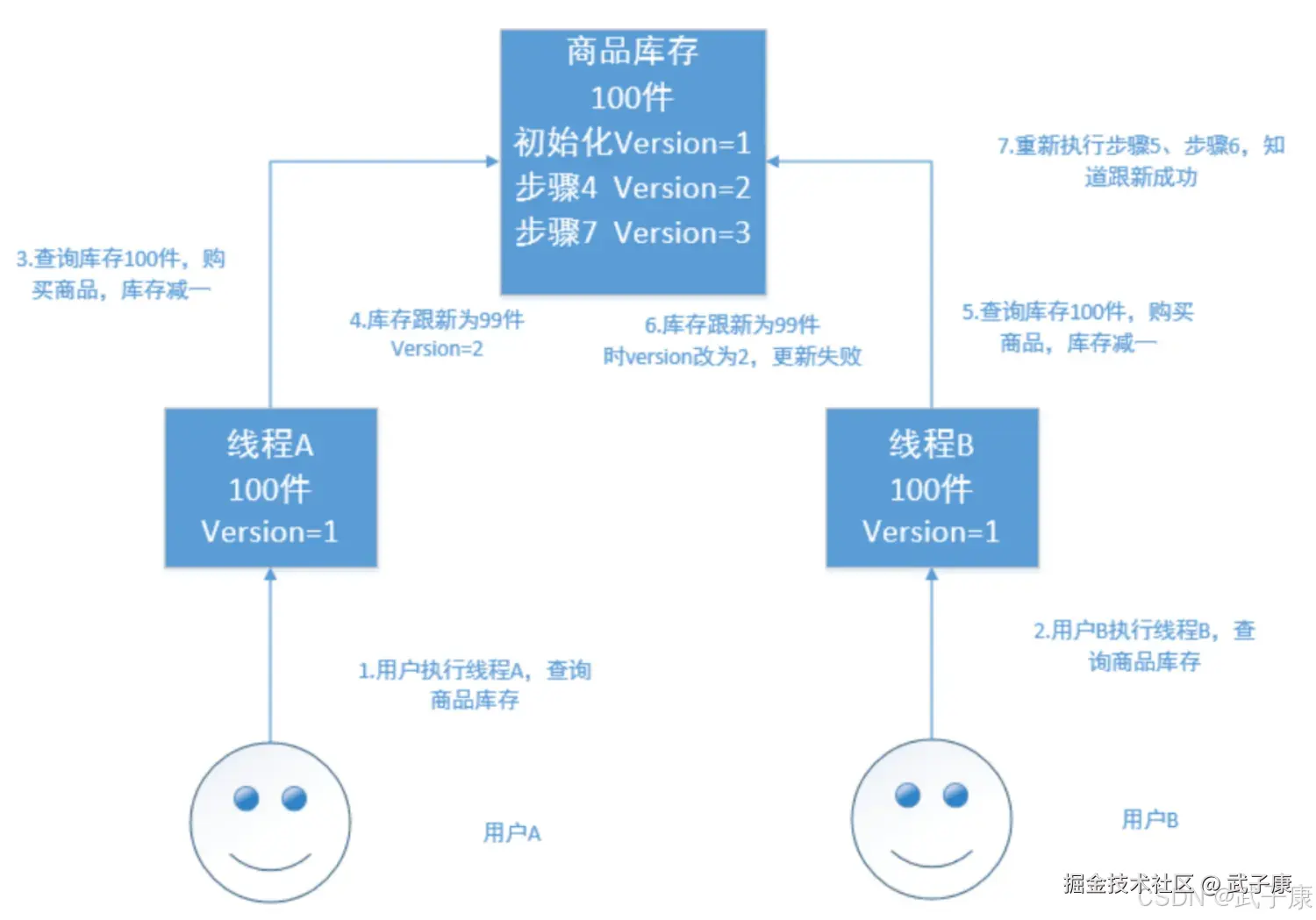
乐观锁不加锁,每个线程都可以任意操作。比如每条文档中都有一个version字段,新建文档后为1,每次修改都进行累加,线程A和B都拿到version为1,等写入时会和ES中的版本号进行比较,如果相等则写入成功,失败则重新读取数据再-1,再进行对比,如果相等则写入成功。
Elasticsearch的乐观锁
Elasticsearch的后台处理机制采用多线程异步架构,这种设计虽然提高了系统吞吐量,但也带来了请求处理的乱序问题。在实际操作中,可能会出现以下场景:用户先发送了修改请求A,紧接着又发送了修改请求B,但由于网络延迟或线程调度原因,请求B可能会先于请求A到达服务端进行处理。
为了应对这种并发修改带来的数据一致性问题,Elasticsearch实现了一套基于版本号(_version)的乐观锁并发控制机制。具体工作原理如下:
-
版本号比较机制:
- 每个文档都有一个递增的版本号字段
- 当后发请求先到达时(请求B),系统会比较请求携带的版本号与当前文档版本号
- 如果版本号匹配(说明没有其他修改),则执行更新并将版本号+1
- 当先发请求后到达时(请求A),由于文档版本号已被请求B更新,此时版本号不匹配,系统会拒绝本次修改
-
冲突解决流程:
- 当修改因版本冲突被拒绝时,系统会自动:
- 重新读取文档最新数据(包含最新版本号)
- 基于最新数据重新应用修改
- 再次尝试提交更新
- 这个过程会循环执行,直到修改成功或达到重试上限
- 当修改因版本冲突被拒绝时,系统会自动:
-
删除操作的特殊处理:
- 删除操作也会触发版本号递增(+1)
- 删除后文档并非立即物理删除,而是进入"逻辑删除"状态
- 这种设计带来两个重要特性:
- 版本号信息会被保留一段时间
- 重新创建同名文档时,新文档版本号会在删除版本基础上继续递增
应用场景示例: 假设有一个商品库存文档(ID:123,version:5,stock:100):
- 请求A(减库存10):期望version=5→6,stock=90
- 请求B(减库存20):期望version=5→6,stock=80 如果请求B先到达:
- 请求B成功(version=6,stock=80)
- 请求A到达时发现version已变为6(与携带的5不匹配)
- 系统重新读取数据(version=6,stock=80)
- 基于新数据执行减10操作(version=7,stock=70)
这种机制确保了在高并发环境下,数据修改的最终一致性,同时避免了传统锁机制带来的性能损耗。
Elasticsearch的乐观锁测试
新建一条数据:
json
PUT /wzk_lock_index/_doc/1
{
"test_field": "wzkicu"
}执行结果如下图所示,可以看到 _version 是1。 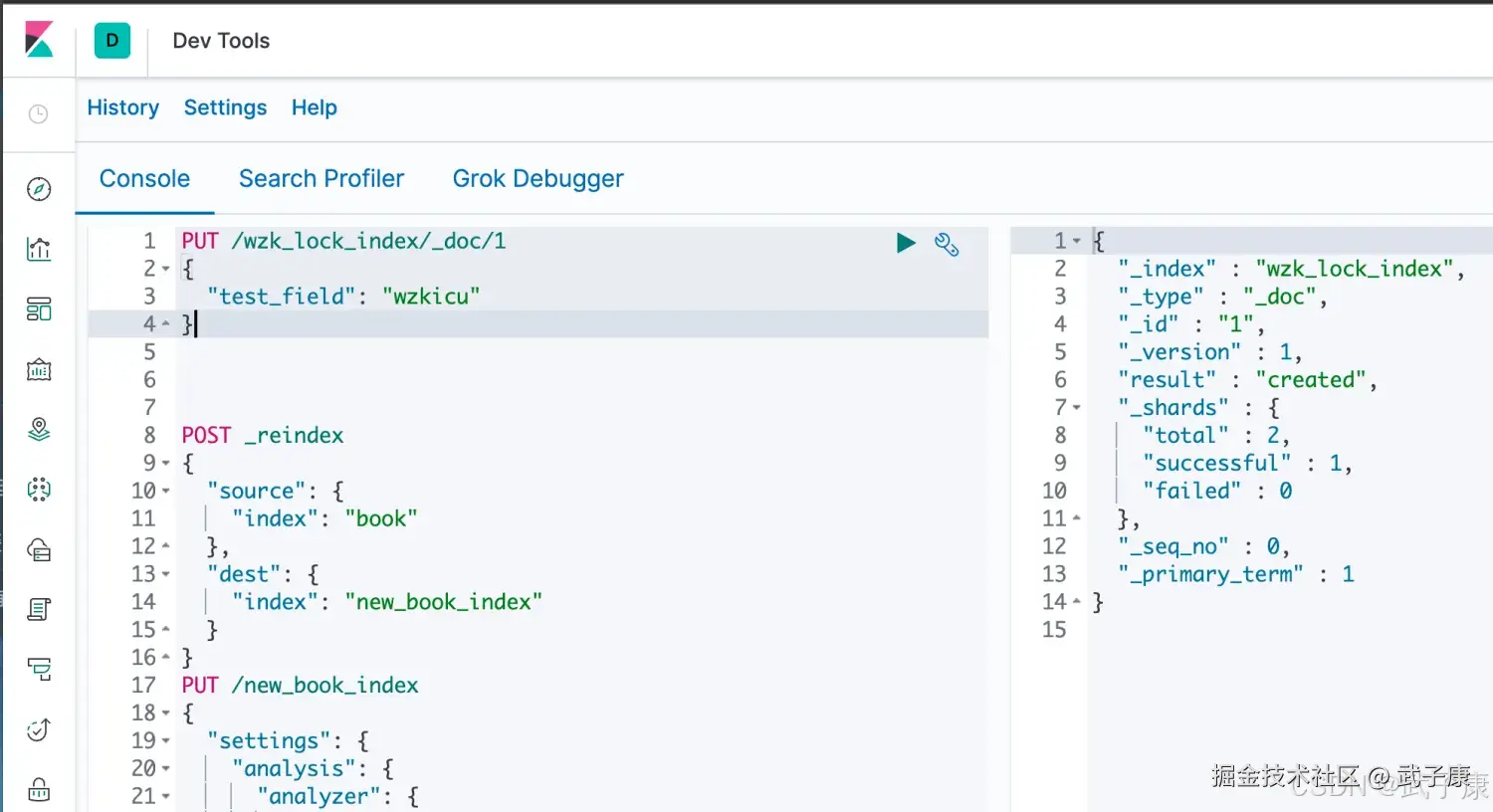
假设我们现在有A和B两个客户端同时拿到了数据,想要进行更新:
json
# A 更新
PUT /wzk_lock_index/_doc/1
{
"test_field": "client1 update"
}可以看到执行结果,顺利更新了,_version变成了2: 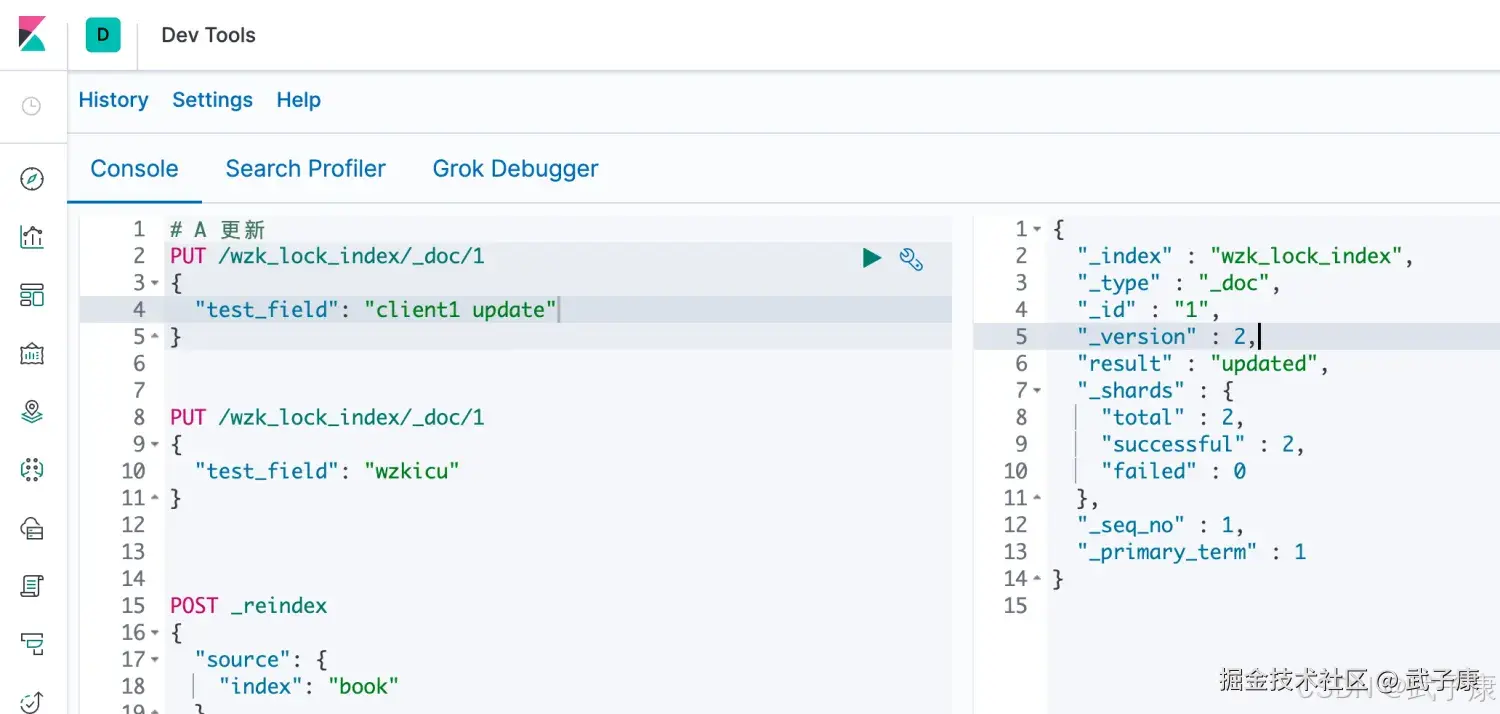
此时B在同一时间要进行更新:
json
# B 更新
PUT /wzk_lock_index/_doc/1?if_seq_no=0&if_primary_term=1
{
"test_field": "client2 update"
}可以看到,此时报错了:
json
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [0], primary term [1]. current document has seqNo [1] and primary term [1]",
"index_uuid": "BBxoVVVqSw2TxtU-vPd-NA",
"shard": "0",
"index": "wzk_lock_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [0], primary term [1]. current document has seqNo [1] and primary term [1]",
"index_uuid": "BBxoVVVqSw2TxtU-vPd-NA",
"shard": "0",
"index": "wzk_lock_index"
},
"status": 409
}对应的截图如下所示: 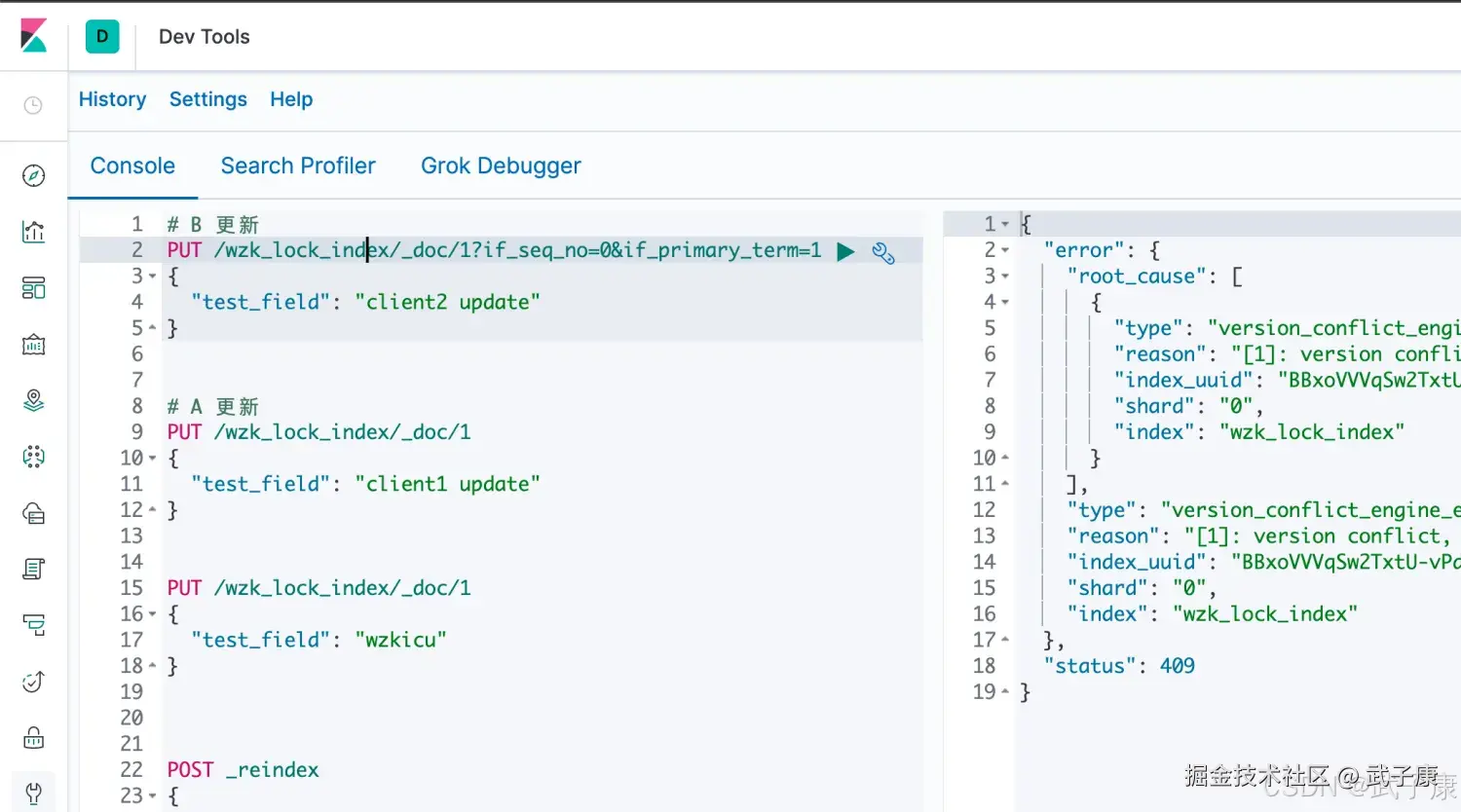
这说明我们的乐观锁是生效的,阻止了并发的问题。 我们需要重新 GET请求获取当前的版本信息:
shell
GET /wzk_lock_index/_doc/1获取到当前的 version 是 2、seq_no是1,primary_term是1: 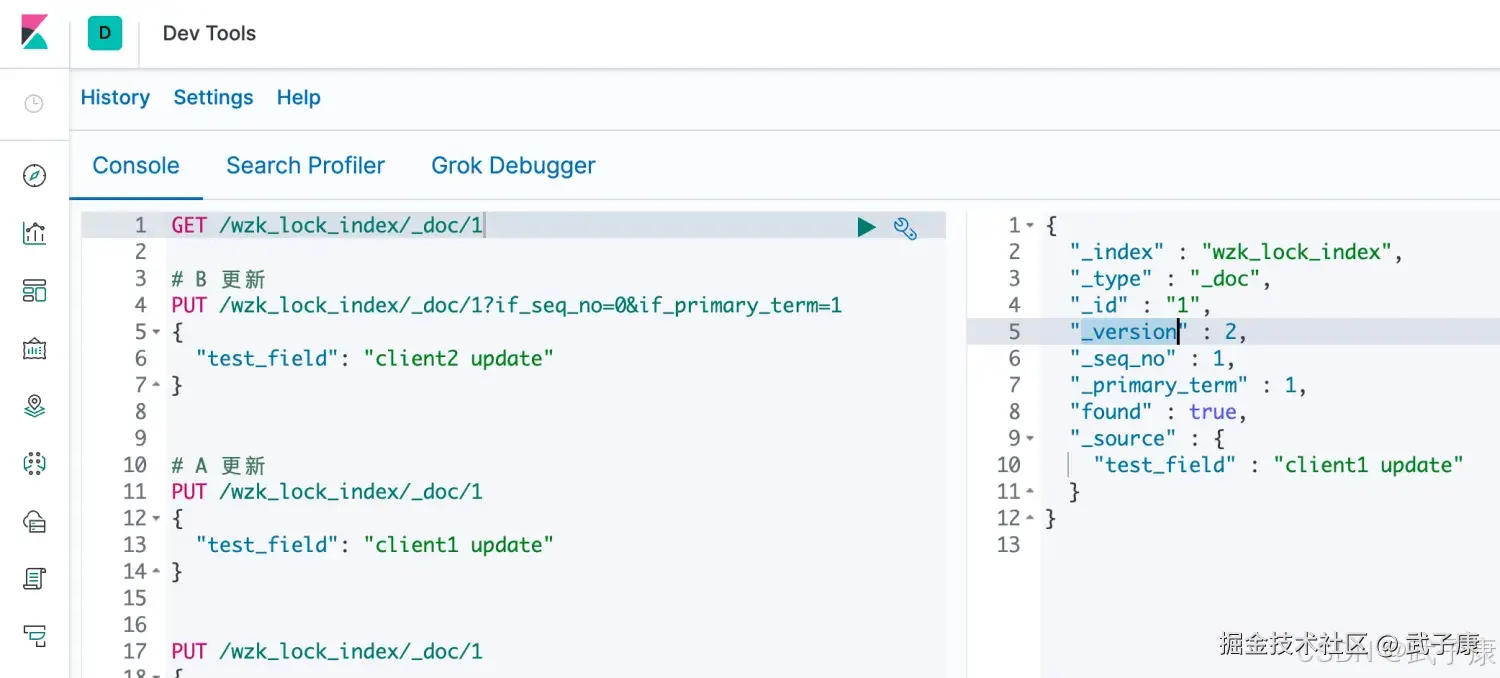
B客户端重新发起更新:
json
# B 再次更新
PUT /wzk_lock_index/_doc/1?if_seq_no=1&if_primary_term=1
{
"test_field": "client2 update"
}我们可以看到执行成功了: 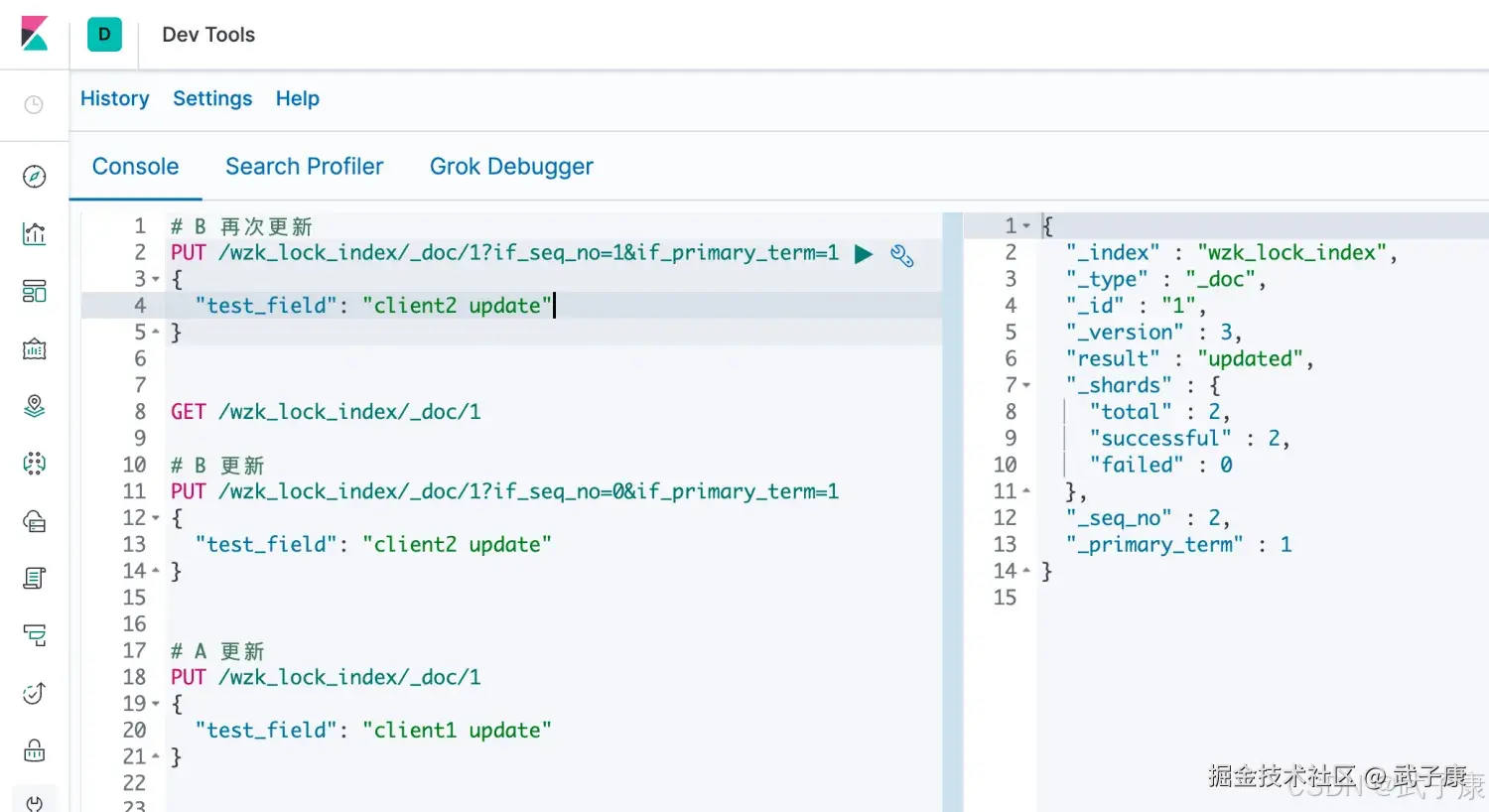
分布式数据一致性
在分布式环境下,一致性指的是多个数据副本是否能保持一致的特性。在一致性条件下,系统在执行数据更新操作之后能够从一致性状态到另一个一致性状态,对系统的一个数据更新成功之后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
ES5.0以前的一致性
- consistency
- one(primary shard)
- all(all shard)
- quorum(default)
我们在发送任何一个增删改查的时候,比如PUT时,都可以带上一个consistency参数,指明我们想要的写一致性是什么?比如:
shell
PUT /index/indextype/id?consistency=quorumquorum机制
基本概念
quorum机制是分布式系统中常用的一致性保障机制,主要用于确保数据写入操作的正确性。在Elasticsearch中,quorum机制用于控制写操作前必须满足的最小可用分片数量要求。
工作原理
写操作执行前,系统需要确认足够数量的分片副本处于可用状态,计算公式如下:
shell
# 当num_of_replicas > 1时才生效
int((primary shard + number_of_replicas) / 2) + 1详细说明
-
参数解释:
primary shard:主分片数量,固定为1number_of_replicas:副本分片数量int():向下取整函数
-
生效条件 : 该机制仅在配置了副本(即
number_of_replicas > 1)时才会生效。如果只有主分片(number_of_replicas = 0),则不需要quorum检查。 -
计算示例:
- 当有1个主分片和2个副本时:
int((1 + 2)/2) + 1 = 2,即需要至少2个分片可用 - 当有1个主分片和3个副本时:
int((1 + 3)/2) + 1 = 3,即需要至少3个分片可用
- 当有1个主分片和2个副本时:
应用场景
该机制主要用于以下情况:
- 写入新文档时
- 更新现有文档时
- 执行批量操作时
注意事项
- 该机制确保了大多数分片副本可用,从而防止脑裂问题
- 如果可用分片数不满足quorum要求,写操作将被拒绝并返回错误
- 可以通过设置
write_consistency参数来调整quorum要求
比如:1个primary shard,3个replica,那么quorum=((1 + 3 ) / 2) + 1 = 3。 如果这时只有两台机器的话: 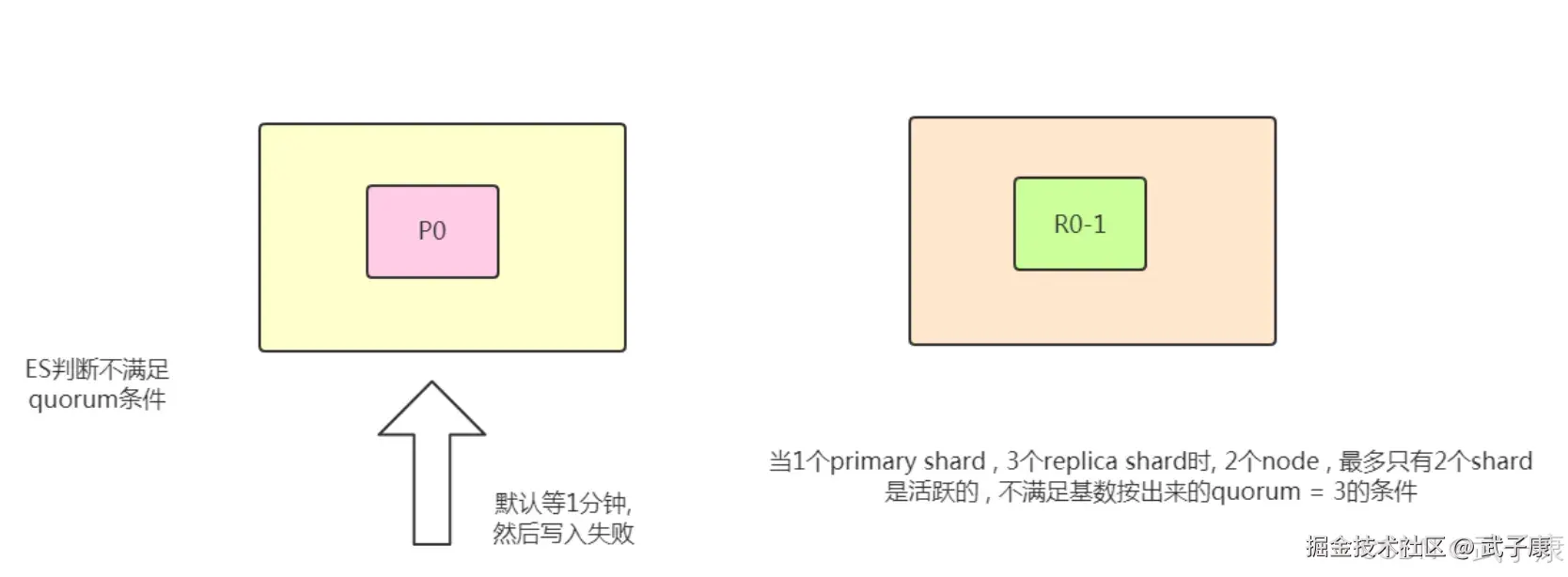
Timeout机制
quorum不齐全时,会wait(等待)1分钟 默认是1分钟,但是可以通过timeout去手动调整,默认单位是毫秒。 等待期间,期望活跃的shard数量可以增加,最后无法满足shard数量就timeout。 我们在写操作的时候,可以加一个timeout参数,比如:
shell
# 当quorum不齐全的时候 ES的timeout时长
PUT /index/_doc/id?timeout=30sES5.0以后的一致性
在ES5.0以后,原先执行PUT带consistency=all/quorum参数的,都会报错,提示语法错误。 原因是consistency检查是在PUT之前做的,然而,虽然检查的时候,shard满足quorum,但是真正primary shard写到replica之前,仍然会出现shard挂掉,但Update API也会返回Successd,因此,这个检查不能保证replica成功写入,甚至这个primary shard是否能成功写入也未必能保证。 因此,修改了语法,用了 wait_for_active_shards,这个更加清楚一些:
json
PUT /index/_doc/1?wait_for_active_shards=2&timeout=10s
{
"xxx": "xxx"
}错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
更新返回 409:version_conflict_engine_exception,提示 required seqNo [x] ... current document has seqNo [y] |
使用旧的 if_seq_no / if_primary_term 条件写入;文档已被其他请求更新,序列号已前进 |
读响应/报错中的 required seqNo 与 current ... seqNo;GET 文档查看最新 _seq_no 与 _primary_term |
重新 GET /index/_doc/id 获取最新 _seq_no、_primary_term,再带上 ?if_seq_no=...&if_primary_term=... 重试写入 |
| 并发扣库存后出现"少扣/多扣/回写覆盖" | 业务侧做了读-改-写,但写入不是条件写入;后到请求覆盖先到请求的结果 | 对比并发请求的读取值与最终写入值;检查是否无条件 PUT/UPDATE |
将更新改为条件更新(携带 if_seq_no/if_primary_term);冲突时按"读取最新→重新计算→重试"闭环处理 |
| 连续两次更新顺序被打乱,最终状态不符合客户端发送顺序 | ES 后端多线程异步处理导致乱序到达/执行;无条件写会让"后到的旧请求"覆盖新状态 | 记录请求时间戳与服务端实际写入顺序;观察冲突是否被触发 | 用 OCC 让旧请求在版本不匹配时失败(409),由客户端或应用层按策略重试/放弃 |
| 写请求长期等待后失败(涉及写入门槛) | wait_for_active_shards 未满足(可用分片副本不足),直到 timeout 超时 |
看请求参数是否带 wait_for_active_shards/timeout;结合集群 shard 分配与节点健康 |
调整 wait_for_active_shards 为可达值;修复分片分配/节点健康;必要时延长 timeout 或降低门槛 |
ES5.0 以后 consistency=quorum/all 报语法/参数错误 |
旧参数已废弃;写一致性检查语义迁移到 wait_for_active_shards |
看请求 URL 是否仍带 consistency |
用 wait_for_active_shards + timeout 替代;将"写入前门槛"与"写入成功语义"区分配置 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解