在 Rust 后端开发领域,Workspace Modular Monolith(基于工作空间的模块化单体) 架构正日益流行。这种架构模式巧妙地平衡了开发效率与部署成本:在开发阶段,它提供了类似微服务的物理隔离(crates 分离);而在部署阶段,它保留了单体应用的简单性(单一二进制文件)。
然而,在模块化的高墙之下,往往隐藏着一个难以忽视的架构短板 ------数据库迁移(Database Migrations)。
第一部分:背景与痛点 ------ 代码模块化,数据耦合化的伪装
在一个标准的 Rust Workspace 中,项目通常包含 user、order、payment 等多个独立的 crates。从 Rust 代码的层面看,它们是解耦的;但在数据库层面,传统的实践往往依然维持着"中央集权"的模式。
1.1 "物理代码分离,逻辑数据耦合"的现状
在大多数项目中,无论开发者正在构建哪个业务模块,所有的 SQL 迁移文件都被迫挤在项目根目录的 migrations/ 文件夹下。更糟糕的是,它们共享着同一张 seaql_migrations 表来记录版本历史。这种物理上的混杂,直接导致了逻辑上的强耦合。
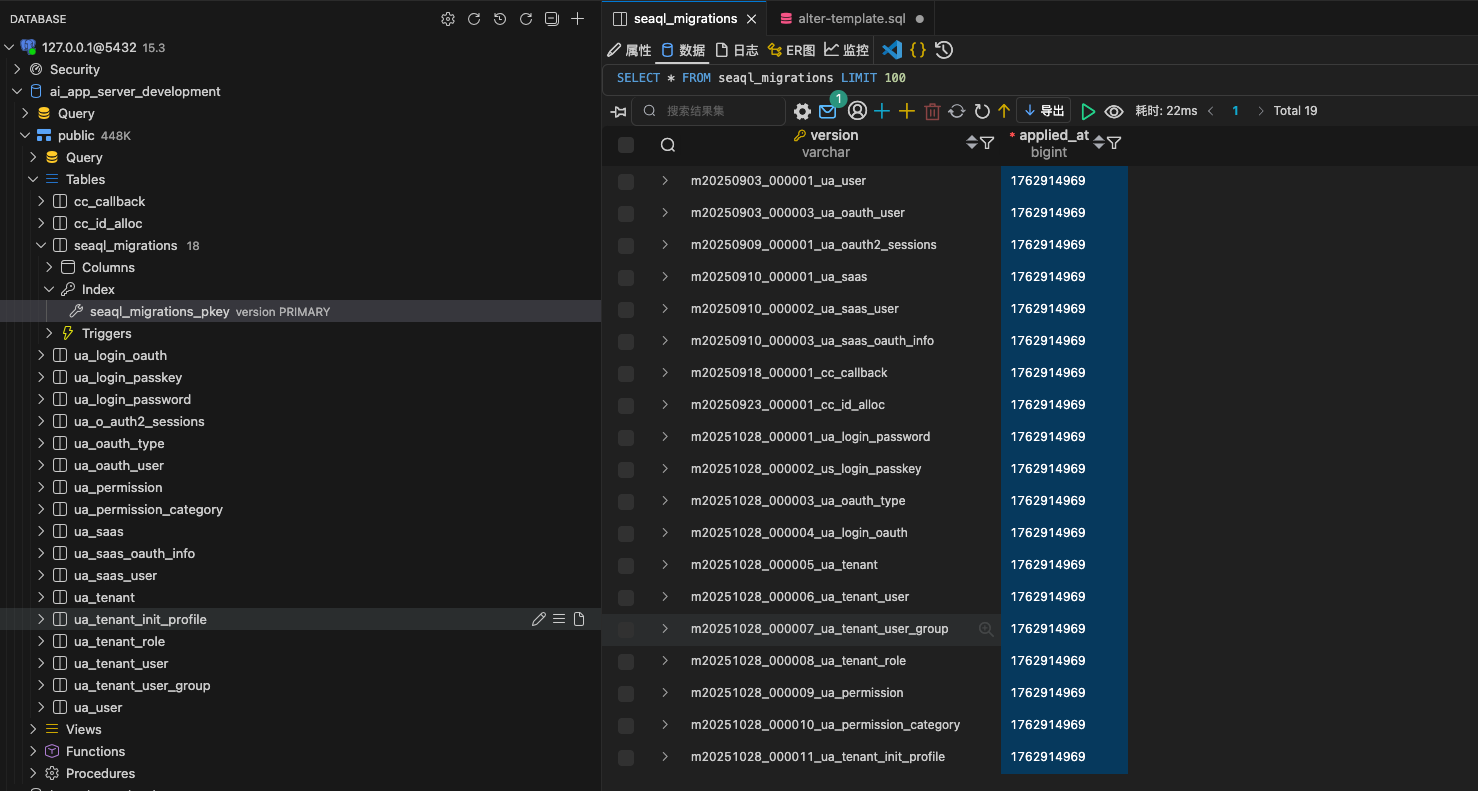
(User Access (ua) 和 Core Callback (cc) 的迁移记录混杂在同一张全局表中,难以区分边界)
1.2 这种架构带来的五大弊端
虽然代码解耦了,但这种"单体"的数据库迁移策略导致了显著的架构坏味道:
-
破坏封装性 (Broken Encapsulation)
业务代码位于
crates/user,但创建表的 SQL 却位于根目录。当需要删除或重构一个模块时,开发者不仅要处理代码,还必须在根目录的数百个 migration 文件中进行"考古",极易导致垃圾 Schema 残留。 -
模块复用性差 (Poor Reusability)
若想将现有的
auth模块复用到另一个 Rust 项目中,无法直接通过复制crates/auth文件夹实现,因为其数据库定义遗留在老项目的根目录下。这直接违背了模块化"即插即用"的设计初衷。 -
协作冲突 (Merge Conflicts)
当团队成员 A 开发订单模块,成员 B 开发用户模块时,他们不得不在同一个
migrations目录下竞争文件命名。在代码合并时,经常出现时间戳冲突或依赖顺序混乱的问题。 -
测试隔离困难 (Hard to Isolate Tests)
进行单元测试时(例如仅测试
user模块),测试脚本往往被迫运行所有的 Migrations,包括不相关的支付表、日志表等。这导致测试速度变慢,且增加了测试环境的脆弱性。 -
认知负担 (Cognitive Load)
开发过程中,思维需要在"业务逻辑"(子模块目录)和"数据结构"(根目录)之间频繁切换,打破了上下文的连贯性。
1.3 破局思路:去中心化
面对上述问题,一个行之有效的解法 是将数据库变更权真正下沉到各个业务模块中。本文将介绍如何利用 SeaORM 结合 inventory 库,设计一套"去中心化"的迁移系统,实现从"中央集权"到"联邦自治"的转变。
第二部分:设计思路 ------ 从集权到联邦
要实现真正的模块自治,需要在架构设计上进行根本性的调整。这不仅仅是移动文件位置,更是对数据管理权限的重新分配。
2.1 核心原则:模块自治
理想的 Modular Monolith 应该遵循 "联邦制(Federation)" 原则。每个模块(Crate)应当被视为一个独立的"邦国",拥有自己的法律(代码)和领土(数据库表结构)。主程序(App Server)仅仅是一个"联邦政府",负责在启动时协调各邦国的运作,而不干涉其内部事务。
2.2 策略对比
通过下表可以清晰地看到新旧架构的区别:
| 特性 | 传统单体模式 (Centralized) | 模块化自治模式 (Decentralized) |
|---|---|---|
| 文件位置 | 根目录 migrations/ |
各模块内 crates/xxx/migrations/ |
| 历史记录表 | 全局唯一 seaql_migrations |
模块独立 seaql_migrations_{module} |
| 版本控制 | 全局时间戳,需严格排序 | 模块内时间戳,模块间无干扰 |
| 启动逻辑 | 硬编码加载全局迁移 | 动态发现,自动注册 |
| 删除模块影响 | 高风险 (需手动清理 SQL) | 零风险 (删除文件夹即可,自动隔离) |
2.3 关键实施路径
为了落地这一设计,需要解决两个关键技术问题:
- 物理隔离 :不再使用一张大表记录所有变更。User 模块的变更记录在
seaql_migrations_ua,Callback 模块的变更记录在seaql_migrations_cc。这确保了模块 A 的回滚或重置绝不会影响到模块 B。 - 服务发现:由于模块是解耦的,主程序不应该硬编码引用各个模块的 Migrator。我们需要一种机制,让各个模块在编译或链接阶段,能够自动将自己的 Migrator "注册"到全局列表中。
第三部分:核心实现 ------ Inventory + Macro
基于上述设计思路,技术落地将依赖 SeaORM 作为 ORM 框架,并配合 inventory crate 实现分布式注册。
3.1 核心机制:Inventory (点名 vs 举手)
inventory 库通过 Rust 的编译期魔法,在链接阶段将散落在各 crate 中的注册项收集到一个全局"登记表"。可以做一个形象的类比:
- 传统方式 (点名) :主程序必须明确知道每个人的名字(
use user::Migrator; use order::Migrator;),并手动调用它们。耦合度极高。 - Inventory 方式 (举手) :各模块在自己内部"举手报到",主程序只需在启动时问一句:"有哪些人到了?"(
inventory::iter())。
这种方式不仅避免了主程序与各模块的硬编码依赖,实现了真正的"即插即用",且由于收集动作发生在链接阶段,运行时开销为零。
3.2 定义标准:ModuleMigration
首先,定义一个标准的结构体用于模块上报信息,并声明 inventory 收集该类型:
rust
use sea_orm_migration::sea_orm::DatabaseConnection;
use sea_orm_migration::DbErr;
// 1. 模块迁移执行器 trait,抹平不同 Migrator 的类型差异
#[async_trait::async_trait]
pub trait MigrationExecutor: Send + Sync {
async fn execute_up(&self, db: &DatabaseConnection, steps: Option<u32>) -> Result<(), DbErr>;
async fn execute_down(&self, db: &DatabaseConnection, steps: Option<u32>) -> Result<(), DbErr>;
}
// 2. 模块注册项结构体
pub struct ModuleMigration {
pub module_name: &'static str,
pub get_migration_table_name: fn() -> String, // 关键:获取该模块独立的表名
pub executor: &'static dyn MigrationExecutor,
}
// 3. 告诉 inventory 开始收集这种对象
inventory::collect!(ModuleMigration);3.3 魔法胶水:module_migrator! 宏
这是整个方案的枢纽。通过定义一个过程宏,自动完成"生成样板代码"和"注册"两项繁琐工作,对开发者屏蔽底层复杂度。
宏的核心实现如下:
rust
#[macro_export]
macro_rules! module_migrator {
// 接收模块名和一系列 migration 模块标识符
($module_name:expr, $($migration:ident),+ $(,)?) => {
use $crate::*;
// 1. 自动生成所有迁移模块的 pub mod 声明
$(
pub mod $migration;
)+
/// 模块的独立 Migrator
#[derive(Clone, Debug, Default)]
pub struct ModuleMigrator;
#[async_trait::async_trait]
impl MigratorTrait for ModuleMigrator {
/// 2. 关键:重写迁移表名,使用模块特定的迁移历史表
/// 例如:seaql_migrations_ua
fn migration_table_name() -> DynIden {
SeaRc::new(Alias::new(concat!("seaql_migrations_", $module_name)))
}
/// 3. 返回该模块的所有迁移文件
fn migrations() -> Vec<Box<dyn MigrationTrait>> {
sort_migrations(vec![
$(
Box::new($migration::Migration),
)+
])
}
}
// 4. 最后,利用 inventory 自动注册该模块
$crate::register_migrator!($module_name, ModuleMigrator);
};
}3.4 总指挥:MultiModuleMigrator
最后,系统需要一个全局的 Migrator 来调度执行。
⚠️ 关键设计细节 :
MultiModuleMigrator的migrations()方法故意返回空列表。因为它不直接管理迁移文件,而是通过重写up()和down()方法,充当"调度者"的角色,动态遍历 inventory 注册表来调用各模块的 executor。
rust
pub struct MultiModuleMigrator;
#[async_trait::async_trait]
impl MigratorTrait for MultiModuleMigrator {
// 关键:这里返回空,因为具体的 migration 文件归各模块管理
fn migrations() -> Vec<Box<dyn MigrationTrait>> {
Vec::new()
}
// 重写 up 方法,接管迁移流程
async fn up<'c, C>(db: C, steps: Option<u32>) -> Result<(), DbErr>
where C: IntoSchemaManagerConnection<'c> {
// 1. 收集所有注册模块
let modules: Vec<_> = inventory::iter::<ModuleMigration>().collect();
// 2. 依次触发每个模块的 executor
for module in modules {
tracing::info!("执行模块迁移: {}", module.module_name);
match &db_conn {
SchemaManagerConnection::Connection(conn) => {
// 每个模块维护自己的 version history
module.executor.execute_up(conn, steps).await?;
}
_ => panic!("不支持事务嵌套")
}
}
Ok(())
}
}3.5 当前限制与注意事项
在实施此方案时,需注意以下几点:
- 事务限制 :由于 SeaORM 迁移内部可能包含事务操作,
MultiModuleMigrator暂不支持在外部事务上下文中执行(如代码所示,遇到 Transaction 会报错)。所有迁移将在数据库连接上直接执行。 - 执行顺序 :模块间的迁移顺序默认由
inventory的收集顺序决定(通常依赖于链接顺序)。如果存在模块间的严格依赖(如外键),建议通过 Cargo 的依赖关系控制,或在代码层面增加优先级排序逻辑。 - Fail-fast 策略:迁移执行是同步顺序的,若某个模块迁移失败,后续模块将不会执行,确保数据库状态不会进一步恶化。
第四部分:开发体验与成果
经过底层的改造,顶层的开发体验得到了质的飞跃,代码变得极致简洁且具备高度的内聚性。
4.1 声明式的模块定义与命名规范
现在,在各个模块内部,开发者只需编写几行声明式代码即可完成迁移配置。
命名规范建议:
- 模块前缀 :与 crate 名称或业务缩写对应(如
user_access->ua,core_callback->cc)。- 表名格式 :自动生成为
seaql_migrations_{prefix}。- 文件命名 :建议迁移文件包含前缀,避免混淆(如
m20250903_000001_ua_user.rs)。
来看两个不同模块的实际配置示例:
User Access (ua) 模块
rust
// crates/user_access/src/migrations/mod.rs
core_common::core_migration::module_migrator!(
"ua", // 生成表名 seaql_migrations_ua
m20250903_000001_ua_user,
m20250903_000003_ua_oauth_user,
m20250909_000001_ua_oauth2_sessions,
m20250910_000001_ua_saas,
// ... 更多文件
);Core Callback (cc) 模块
rust
// crates/core_callback/src/migrations/mod.rs
core_common::core_migration::module_migrator!(
"cc", // 生成表名 seaql_migrations_cc
m20250918_000001_cc_callback,
m20250923_000001_cc_id_alloc,
);4.2 最终效果:物理隔离
运行迁移后,数据库中呈现出清晰的隔离视图。每个模块拥有独立的迁移历史表,互不干扰。
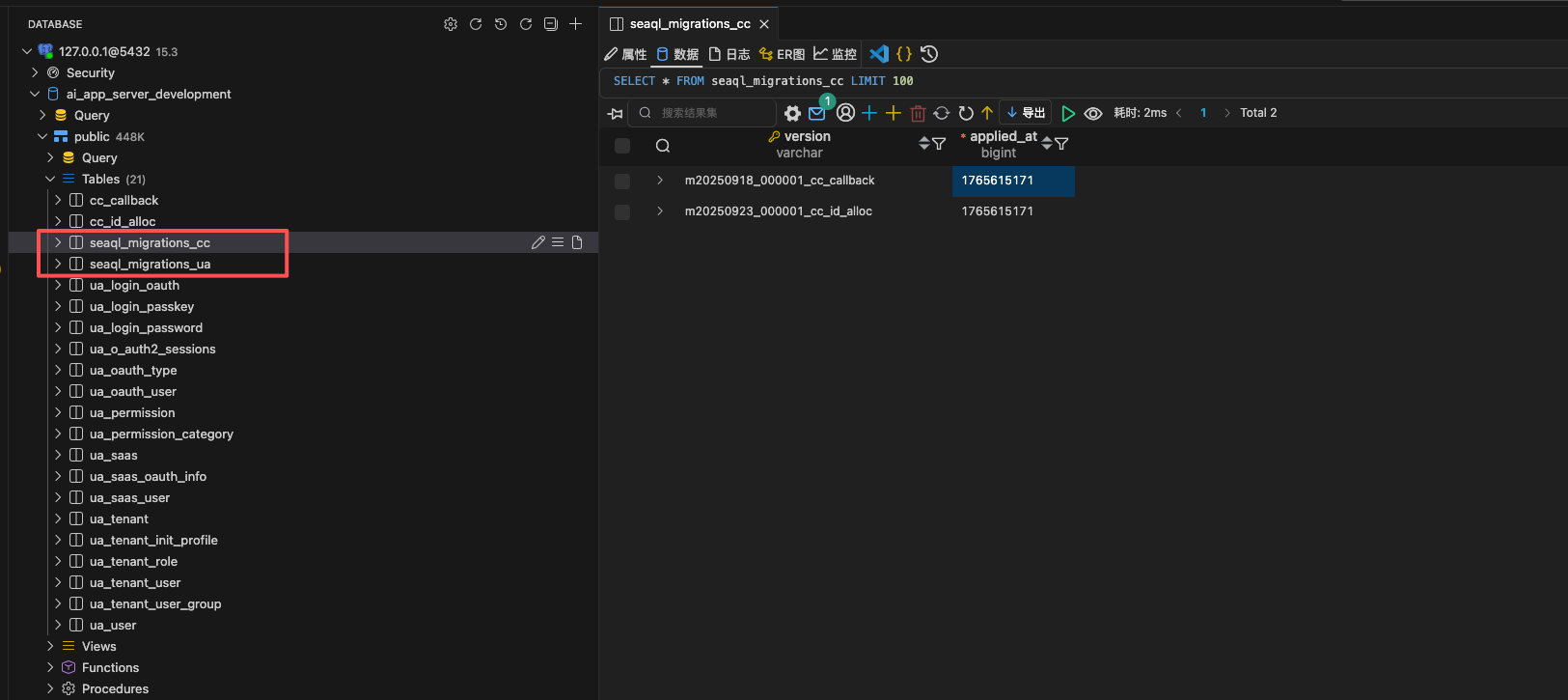
(改革后。User Access 和 Core Callback 拥有了各自独立的 seaql_migrations_xx 表)
4.3 收益总结
通过实施这套方案,项目成功实现了:
- 真正的物理隔离 :若需删除
ua模块,只需删除crates/user_access文件夹。相关的 Migration 代码和定义将随之消失,干净利落。 - 独立的历史记录 :如上图所示,
cc模块只记录了两条变更,而ua模块记录了几十条。它们的时间戳无需全局协调,彻底消除了版本冲突。
4.4 主程序集成
最后,在应用入口(App Server)集成这套系统非常简单,实现了真正的"零配置启动"。只需声明使用 MultiModuleMigrator 作为全局迁移器:
rust
// src/app.rs - 主程序中的类型声明
use core_common::core_migration::MultiModuleMigrator;
// 将 MultiModuleMigrator 泛型注入到 App 配置中
pub type App = BaseApp<AiAppServerConfig, MultiModuleMigrator>;当框架启动时,会自动调用 MultiModuleMigrator::up()。此时,inventory 机制已在后台静默地完成了所有模块的收集工作,整个过程无需任何手动注册代码。
第五部分:总结
通过引入 SeaORM 的灵活性与 inventory 的分布式注册能力,成功填补了 Modular Monolith 架构中关于数据治理的最后一块拼图。
这套去中心化的迁移机制,不仅解决了代码管理上的物理耦合,更在逻辑层面赋予了每个模块完整的生命周期自主权。现在,开发团队可以自信地添加、移除或重构任何业务模块,而无需担心触碰那张曾经令人头疼的全局迁移网。这正是 Rust 项目从"能跑"迈向"好维护"的关键一步。