应机械工业出版社的邀请,围绕《搜索架构之道:App中的搜索系统设计与优化实践》这本书内容进行一次直播。


直播内容基于App中的搜索系统的架构展开,主要分为四个部分,第一部分主要介绍搜索客户端的组成、价值及技术趋势。第二部分介绍搜索系统中需求表达支持的技术模型,并重点说明语音搜索过程实现。第三部分介绍网页能力扩展的必要性,并重点说明浏览内核的基本使用及如何在NA侧扩展网页侧的能力。第四部分主要介绍App复用与模块复用的区别及如何低成本实现可App复用的技术支持框架。
本书的内容主要以iOS&Android平台的经验为基础,因HarmonyOS NEXT于2024年10月正式发布,个人也在该领域进行了研究。故直播的内容中增加了HarmonyOS NEXT系统的相关内容,和大家一起交流学习一下。
《搜索架构之道:App中的搜索系统设计与优化实践》
《精通HarmonyOS NEXT :鸿蒙App开发入门与项目化实战》
直播时间预计一个小时,先在公众号号提前把一些干货分享出来,同学们有问题也可以提前交流,部分内容在直播时也会重点说明。
直播的入口如上,感兴趣的同学可以预约直播,当天直播间的福利是5折限购《搜索架构之道:App中的搜索系统设计与优化实践》这本书。
直播的内容主要偏重于架构层面的实现,偏重于技术实现思想,但不会过多的讨论技术实现细节,因为内容较长(1W字+)请您知晓,并结合自身的需要选择性的阅读。

目录

01.搜索客户端简介

提到搜索客户端,你会想到什么?
搜索App?还是浏览器?
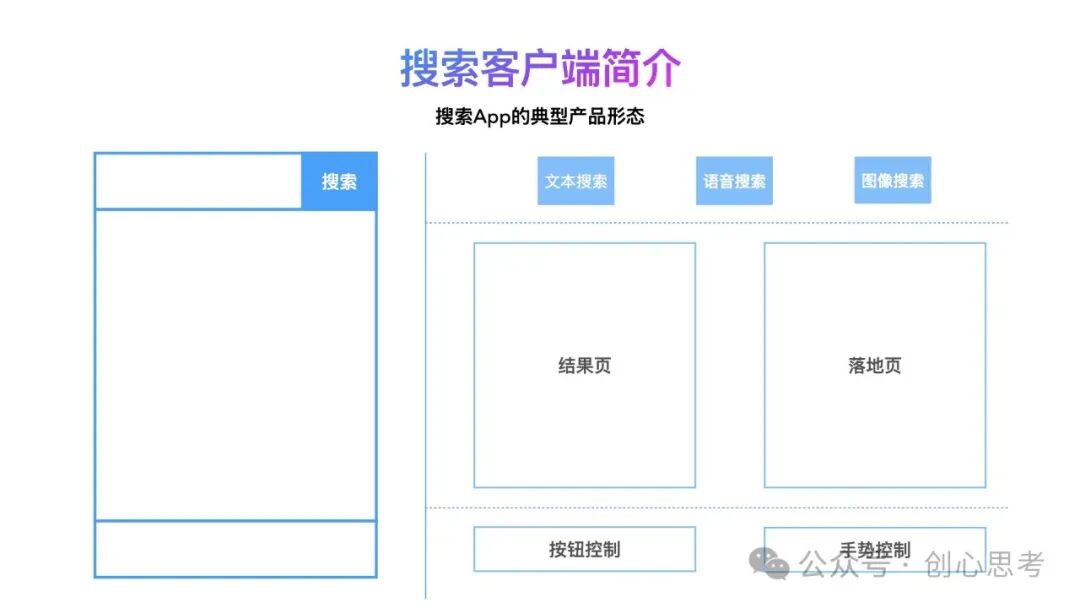
先从搜索App聊起,典型的搜索App的产品形态如下图所示。用户在使用搜索App时,通常是通过文本、语音或图像等方式进行需求输入。之后进入结果页进行结果的浏览,点击某条结果后进入落地页浏览每一条结果的详细内容。在这个过程中用户可以通过按钮或者手势控制页面浏览过程。
在这个过程中,用户也可以再通过文本、语音或图像等方式发起搜索,之后再进入结果页进行结果的浏览。。。直到找到所需,本次搜索需求才算是被满足。
这看起来和浏览器没有什么区别,为什么还需要搜索App?
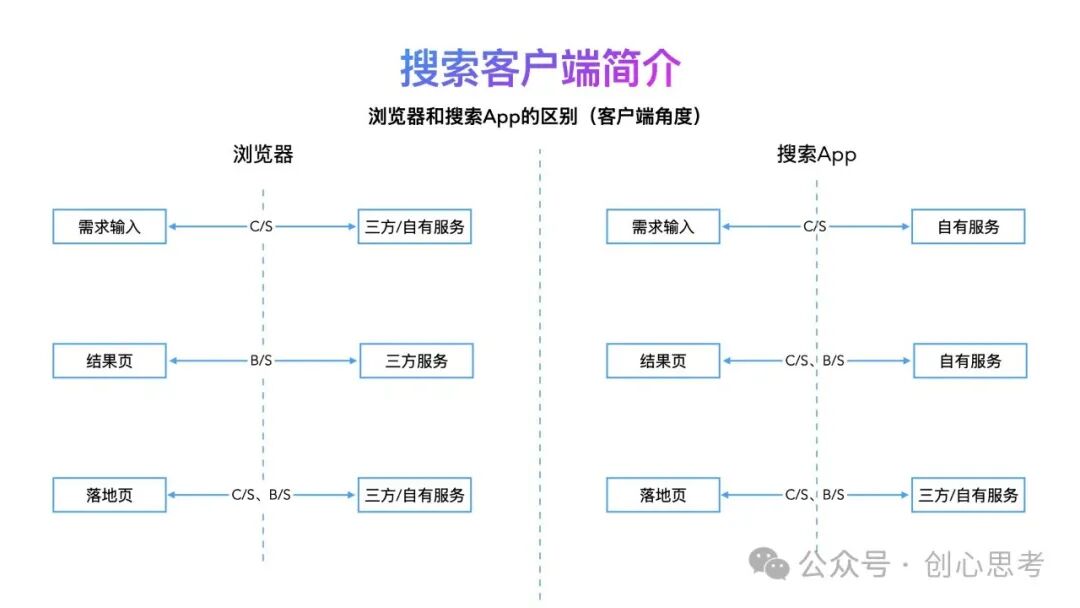
从客户端的角度来看,搜索App有自有搜索服务支持,浏览器不一定会有自有服务支持。
-
这在需求输入这个场景,浏览器作为客户端对接的是三方/自有服务,而搜索App作为客户端对接的是自有服务。搜索App可支持用户正确表达搜索需求,使用系统API提供的文本、语音、图像、视频等数据,通过网络与服务端通信,展示在App中处理的数据结果及交互进入下一个业务场景。
-
在结果页这个场景:浏览器作为客户端主要对接的是三方服务,而搜索要App作为客户端对接的是自有服务。搜索App可与服务端协同实现结果的差异化定制。结果页通常是网页格式,在自有客户端的支持下,也可使用非网页的格式或网页+非网页的复合格式,甚至在客户端中可以对结果页进行业务扩展。
-
在落地页场景中:浏览器和搜索App作为客户端均可对接三方服务和自有服务。区别在于自有服务的内容可控性(质量,效果、体验等)。落地页主要是网页格式,在自有客户端的支持下,也可使用非网页的格式或网页+非网页的复合格式,同样在客户端中也可以对落地页进行业务扩展。
从搜索服务的角度来看
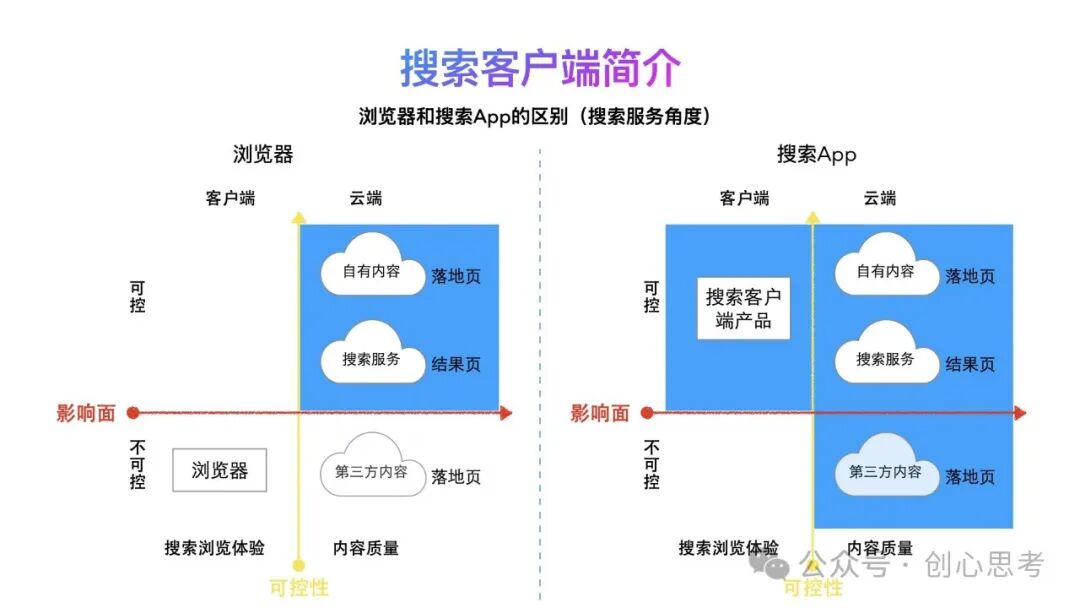
搜索引擎的核心能力是信息检索,当用户在浏览器中进行搜索时,搜索引擎会通过算法和策略检索出更符合用户需求的结果。当用户点击搜索结果中的某个条目时,打开一个第三方的落地页,这个过程的浏览体验与浏览器产品设计有关,是不受搜索引擎控制的。落地页中大部分结果是第三方页面,但因为这些结果是由搜索引擎检索得到的,当用户发现所浏览的内容质量不好时,基于页面打开的先后关系,部分用户也会认为是搜索引擎的问题。总结来说就是在浏览器中使用搜索服务,在搜索浏览体验方面是不可控的,对第三方的内容质量也无法干预,只有搜索服务和自有内容是可控的。
而当搜索引擎的服务有了自建客户端的支持,搜索及浏览的体验就是可控的,第三方的内容质量问题可以识别并可干预,这时相当于搜索全流程是可控的,同时,在搜索客户端中,从用户输入到展现结果页,再到打开落地页,整个过程都可以定向优化,也就是说从用户打开客户端到搜索需求满足均可进行定制和优化,这拉开了与其他搜索产品的差距。这一切都因为有搜索客户端产品的支持。
那么,搜索App的核心价值是什么?
总结成一句话,"以搜索业务为核心,客户端与服务端的协同,端云一体化的实现搜索全流程的差异化定制。"

或许有读者会问,为什么这本书讲的是App中的搜索?
这个问题我问过自己很多次,在之前工作期间也曾经多次思考在App中构建搜索业务相关能力的价值及意义。因为在传统的观念中,搜索业务的核心技术在服务端体现,客户端只是搜索结果的展现,并且有浏览器可以替代,为什么还需要实现一个单独的App来支持搜索业务。
实际上,搜索业务并不限于传统的搜索引擎,任何一款App中都可以构建搜索业务相关的能力。当App中的信息达到一定规模、差异化及复杂度,则需要提供搜索的能力。当用户知道在那个App中来找信息,这时就会使用某个App中的搜索功能。
故在当今数字化、信息化浪潮中,每一款App都有可能涉足搜索业务领域,构建搜索能力、实现搜索流程、搭建技术架构。而《搜索架构之道:App 中的搜索系统设计与优化实践》这本书,正如副标题所描述的,聚焦于 App中搜索系统的设计思考与优化策略,为读者深度剖析这一领域所面临的问题及解题思路。

如何看待技术趋势对App中的搜索系统影响,
-
0-1的阶段:即系统从无到有的阶段,当有新的平台出现、新场景的出现时。比如鸿蒙NEXT系统眼镜、音箱等其它智能设备中搜索系统的实现。这时现有的搜索系统架构需要重新建设,以适应于不同的平台及技术场景。当下比较热门的是在鸿蒙NEXT系统。
-
1-n的阶段:即基于现有的系统进行优化,当某一技术得到突破、战略目标调整时,如内容、交互及流程层面的变化。这时现有的搜索系统需要重构以满足搜索全流程的需要。当下比较热门的技术是AIGC,个人观点为用户输入的内容从之前的短语句变为长语句,原本的搜索框应该具备更多的交互方式及空间。

02.需求表达的支持

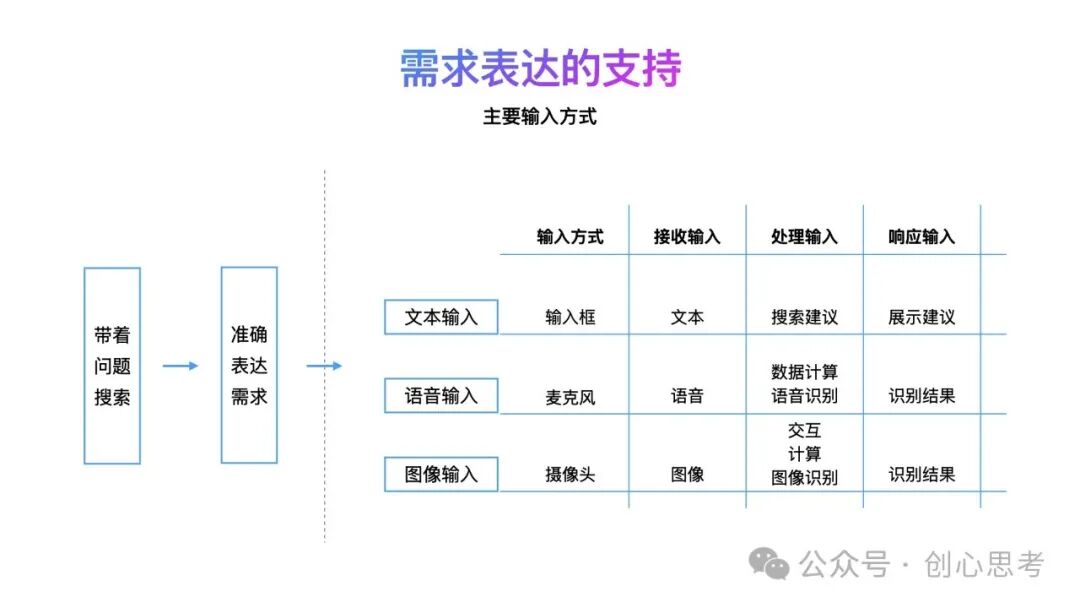
需求表达是搜索系统最关键的一个场景,通常用户带问题使用搜索功能的,这时能够帮助用户准确的表达需求是搜索系统的一个关键能力,在这个场景中,搜索系统主要接收用户的输入、处理用户的输入及响应的用户的输入。
在App中,可以构建与需求表达有关的多种方式,包括文本输入、语音输入及图像输入。
-
文本输入方式主要通过输入框来接收用户的输入,输入的内容为文本,在这个过程中,搜索系统主要提供搜索建议的支持,即根据用户的输入推理出有可能要输入及搜索的内容,并以列表的形式展现给用户,用户点击其中的某个条目,发起搜索。
-
语音输入方式主要通过麦克风来接收用户的输入,输入的内容为语音,在这个过程中,搜索系统主要对语音数据时行计算,及与语音识别服务通信进行语音识别,同时为用户展示识别结果及音波动效等。
-
图像输入方式主要通过摄像头来接收用户的输入,输入的内容是图像或图像流,在这个过程中,搜索系统主要提供图像的圈选交互、对焦、图像计算及识别的支持,同时展现识别结果等。
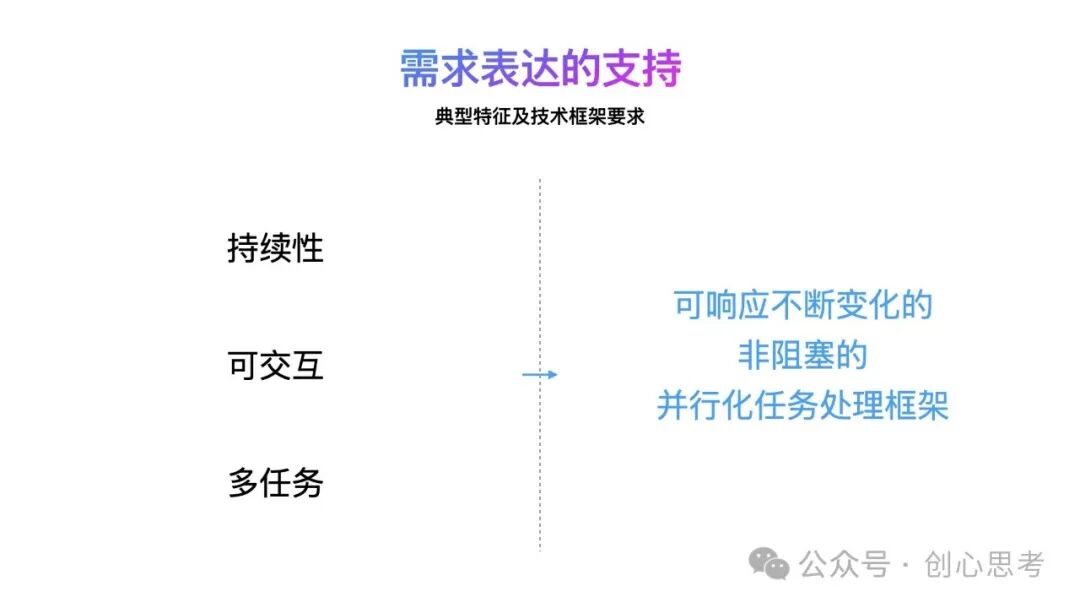
在需求表达场景中,典型的特征就是持续性、可交互及多任务。
-
持续性体现在,输入过程会持继一段时间,且这输入的内容会变化。
-
可交互体现在,输入过程用户会参与其中,使其输入的内容更精确。
-
多任务体现在,输入的过程中,在搜索系统中会有多个任务在执行。
这对于技术框架的要求就是实现可响应、不断变化的、非阻塞的并行化任务处理框架。即可及时的响应用户的输入,不block用户的输入的进行多任处理。
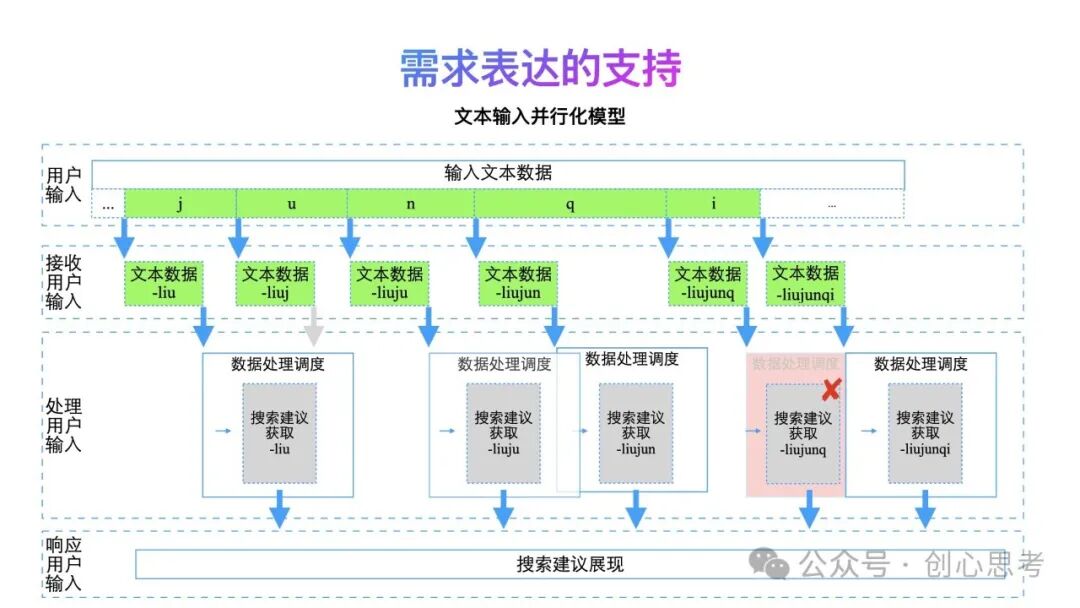
下面介绍一下这三种方式的并行化模型。先说一下文本输入时的并行化模型。
在文本输入时,用户在持续的输入,搜索系统接收输入的文本内容,获取搜索建议,并为用户展示。因任务的执行需要时间,存在新任务需要执行时,原任务还没有完成的情况。这时在任务的调度分为三种情况。
- 保持当前任务执行,忽略最新的输入:收到新的文本输入事件时,判断当前搜索建议获取的任务是否在运行,如在运行,忽略最新的输入。如是空闲,则使用最新的输入内容发起搜索建议获取任务。如下图所示用户输入j,这时输入框中的内容为liuj,当前正有任务(文本数据-liu)执行,继续执行当前任务,忽略新输入的事件。
- 保持当前任务执行,启动新任务:收到新的文本输入事件时,创建新任务使用最新的输入内容获取搜索建议数据,接收到服务端返回的数据时,匹配最近输入的内容进行展示。如下图用户输入n,这时输入框中的内容为liujun,当前正有任务(文本数据-liuju)执行,继续执行当前任务,同时基于文本数据-liujun创建新的搜索建议获取任务。
- 取消当前任务执行,启动新任务:收到新的文本输入事件时,判断当前搜索建议获取的任务是否在运行,如在运行,取消当前的任务,使用最新的输入内容发起搜索建议获取的任务。如是空闲,直接使用最新的输入内容发起搜索建议获取的任务。如下图用户输入i,这时输入框中的内容为liujunqi,当前搜索建议获取-liujunq正在执行,取消执行当前任务,同时基于文本数据-liujunqi创建新的搜索建议获取任务。
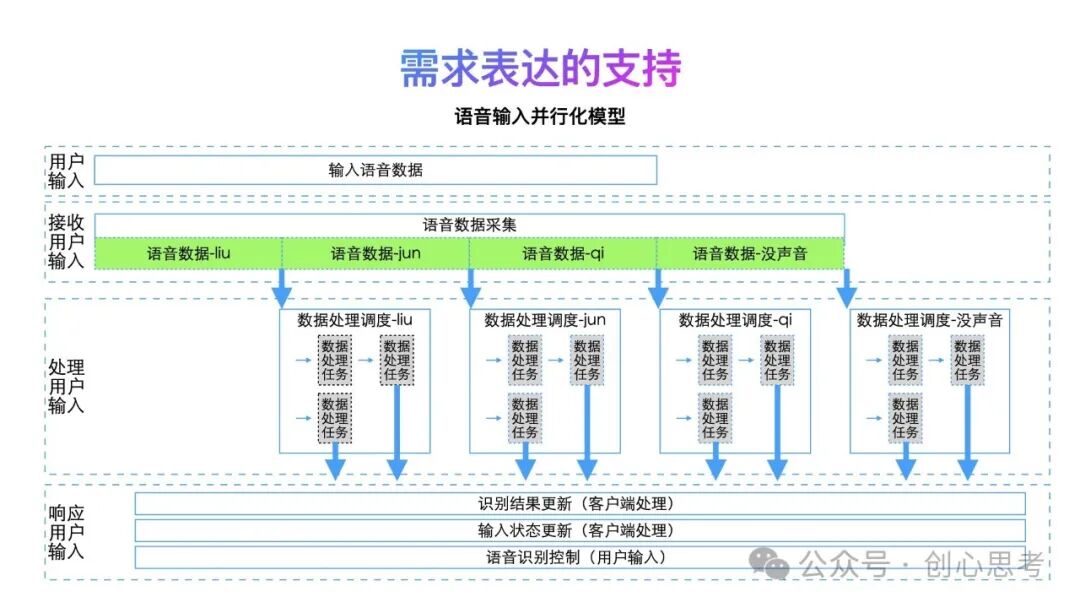
在语音输入时,用户在持续的输入,搜索系统接收语音数据,在本机预处理后,请求语音识别服务进行语音识别。
在处理用户输入的层面,会划分为多个数据处理任务,比如VAD检测、音频计算、数据压缩等。这些任务可按照任务调度的标准执行并同步结果。
在响应用户输入的层面,通常在客户端展现本次语音输入的识别结果及用户当前语音输入的状态。用户可以控制语音输入的结束,也可以是系统在检测到一段时间没有声音后自动结束语音输入。
在图像输入时,用户通过摄像头持续的捕获图像数据,搜索系统接收图像数据,在本机进行预处理后,根据图像的类型使用不同的算法或模型识别。
在处理用户输入的层面,同样也会划分为多个数据处理任务,比如有效内容区裁剪、模糊识别、光线明暗度计算、内容分类、预处理及识别等。这些任务可按照任务调度的标准执行并同步结果。
在响应用户输入的层面,通常在客户端展现实时的图像数据流、相机配置入口,识别结果等。用户可以控制图像输入的结束,也可以是系统识别到确定的内容后结束输入。
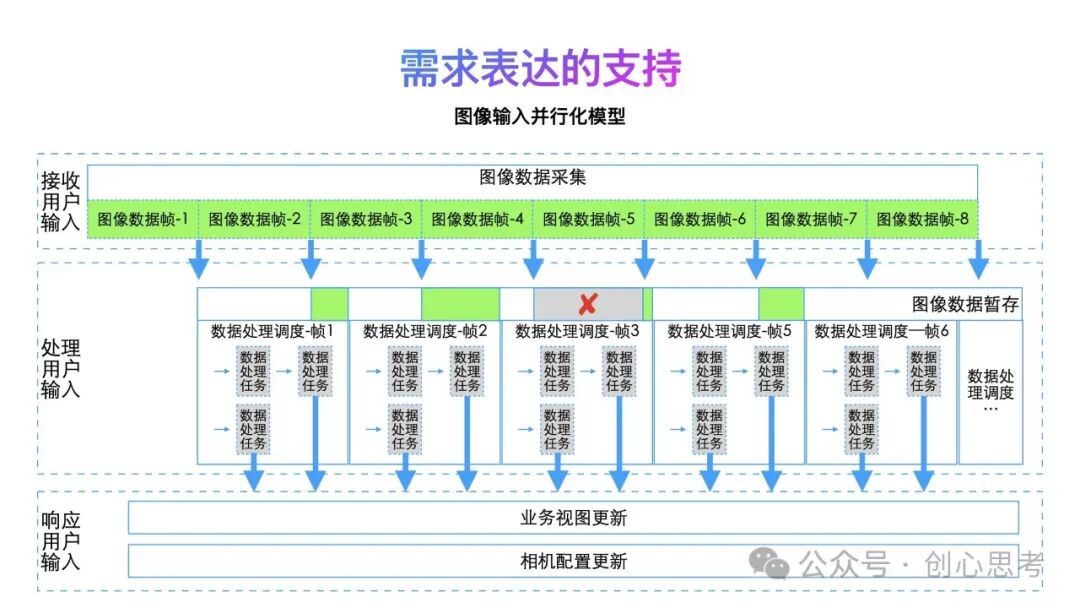
前面的内容介绍了三种输入方式的并行化模型,之前也有读者问到这个问题,因为在需求表达这个场景中,是用户主动输入的场景,在搜索系统中需要基于用户的输入,理解并帮助用户输入正确的内容。同时也需要对用户下一步的行为进行支持,这个过程会有很多任务执行,也需要对整体的效果进行调优。
并行化模型可以很好的支持业务流程与策略优化的分离,实现任务的统一调度,每个任务是流水线中的一环,可以增减,也可以独立调优。在策略的优化同时,具备较好的扩展性,可以极大地保证业务流程的稳定性。

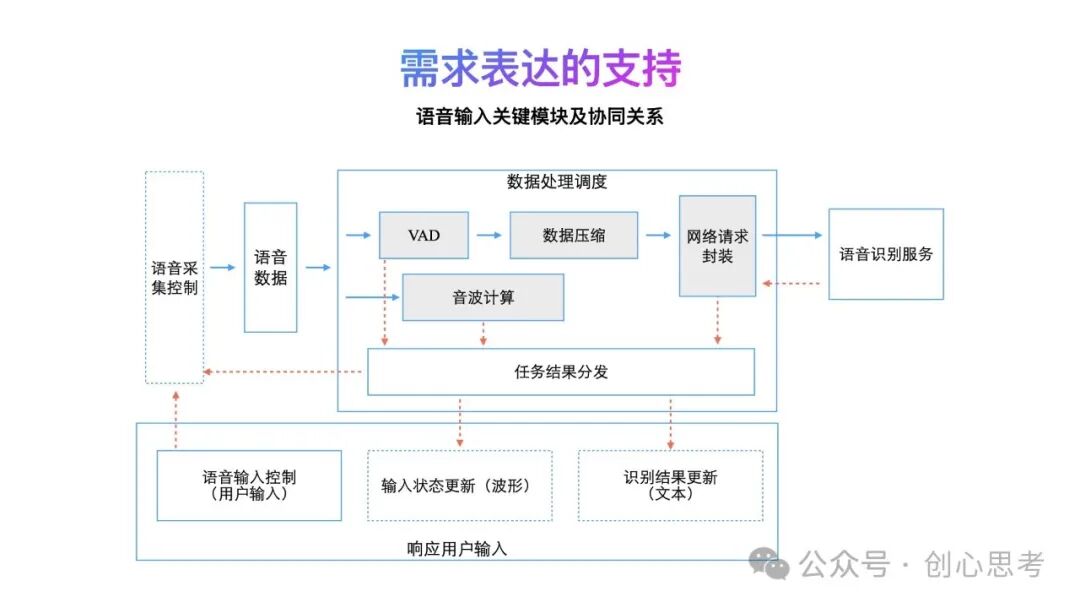
下面以语音输入的过程,介绍一下关键的模块及协同关系。如下图所示,在用户开始语音输入后,搜索系统一直在接收语音数据,数音数据的处理会为两条流水线,一条实现vad检测、数据压缩、网络请求及识别,一条进行音波计算。
在第一条流水线中,vad结果会向用户反馈、识别结果也会向用户反馈。第二条流水线中,音波计算的结果也会向用户反馈。
在交互层面,为用户提供语音输入的控制能力、显示输入状态及识别结果。以响应用户的输入。
对应的技术实现在鸿蒙系统中均有支持。
-
在音频数据采集层面,提供了AudioCaputurer,支持音频的录制。
-
在音频数据处理层面,提供了zlib支持数据压缩、JSON支持数据的封装及解析。
-
在网络请求层面,提供了http、socket等多种数据传输方式。
-
在语音识别服务层面,系统提供了SpeechRecognitionEngine支持语音识别。
-
在UI交互及展现层面,提供文本、按钮、状态管理及动画等组件及机制,支持语音输入过程的交互。
相关内容在本书的第4章中介绍。
一本书的故事《搜索架构之道:App中的搜索系统设计与优化实践》-微信读书中的热门划线(第四章)

在咱们的这本书中,主要以使用自研的语音识别服务支持语音输的过程作介绍。也就是说从录音到识别的全流程均需要实现,先介绍下录音模块在鸿蒙系统中的实现,如下图所示。
在开始录音之前,需要创建AudioCapturer,创建AudioCapturer需要指定参数,包括语音的采样率、声道数、采样位数、编码类型、音源等信息(如下图的左侧)。
基于这些配置,使用audio.createAudioCapturer方法可创建AudioCapturer实例,之后订阅AudioCapturer实例的readData事件,用于接收录制的音频信息。
最后调用AudioCapturer实例的start方法启动录音。
要实现语音识别能力,调用方在使用录音模块启动录音后,需要接收录制的音频数据,故启动录音的接口需要指定callback,当在录音模块中收到readData事件时,通过callback将产生的音频数据同步至调用方。

对于调用方来讲(识别模块),启动录音并接收音频数据,将数据交给任务管理模块,任务管理模块将数据进行分发。
介于VAD算法及音波计算算法,使用C/C++或AtkTS语言的基本特性就可实现,通常以异步或多线程的方式执行,在这里不作过多的介绍。
语音数据在本地处理完之后,以分包的方式上传到语音识别服务端,并接收识别结果,在这个过程中客户端需要保证数据的有序性,展现语音识别的结果及用户输入状态。

在鸿蒙系统中提供了语音识别引擎,支持在线识别及离线识别。研发人员在使用该服务时,可指定语言、识别模式(长语句、短语句)等。
同时也为该引擎设定Listener,以监听识别过程的不同事件。包括onStart(开始识别时,回调此方法)、onEvent(识别过程中的事件都通过此方法回调,例如音频开始、音频结束、vad start或vad end时触发)、onResult(识别的中间结果和最终结果都回调此方法)、onComplete(识别结束或者调用finish方法主动结束识别时回调此方法)、onError(识别过程中,出现错误时回调),当收到引擎的回调时。
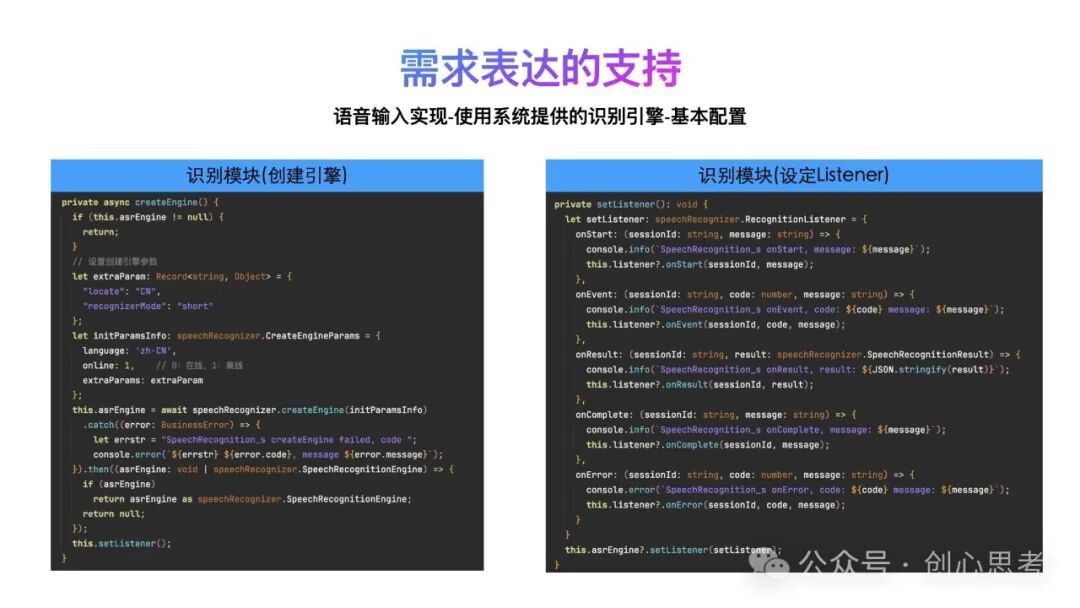
在启动该引擎时,同样也需要指定参数,与录音的参数相似,包括语音的类型、采样率、声音通道数、采样位数等。同时也支持扩展参数的设定,包括识别的模式、vad前端点和后端点、最长语音时长等。
对应着在识别模块中封装整体识别操作,主要分为三部分
-
记录Listener用于回调UI交互识别结果
-
创建识别引擎并设定引擎的Lister
-
启动引擎
这种方式,对于个人开发者比较友好,实现成本低,且很容易的就把语音识别接入到App中。

但系统提供的语音识别引擎,并没有提供音波计算相关的事件或获取方法。如果在使用系统提供的语音识别引擎时需要实现音波计算的能力,可以使用录音模块进行音频录制,在启动识别引擎时,指定识别模式为实时音频转文字识别,这时语音识别引擎可接收音频数据进行语音识别。
对应着整体识别流程也有一定的变化,主要分为三部分:
-
记录Listener用于回调UI交互识别结果
-
创建识别引擎并设定引擎的Lister
-
启动引擎
-
启动录音
-
接收录音产生的音频数据,对该音频数据进行音波计算、将该音频数据写入识别引擎。
这种方式,实现了使用系统提供的语音识别能力,也实现了任务处理及交互层面的定制。

03.网页功能扩展支持

在前面的内容中提到了搜索业务中的三个核心场景,需求输入、结果页及落地页。在技术实现的层面来看,需求输入场景中主要基于NA代码实现、结果页和落地页场景主要基于浏览内核实现,也有部分场景是基于NA代码实现。
这意味着,在App中构建与搜索业务有关的能力,通过NA实现功能及通过浏览内核支持网页浏览均是必不可少。但是从技术支持的层级来看,网页功能的能力受限于浏览内核所提供的能力,NA功能所实现的能力受限于系统的API所提供的能力。因浏览内核也同基于系统API构建,不会提供超过系统API的能力,故网页功能所实现的能力要差于NA功能所实现的能力,网页功能需要通过NA功能的扩展,才可能实现网页功能的差异化。
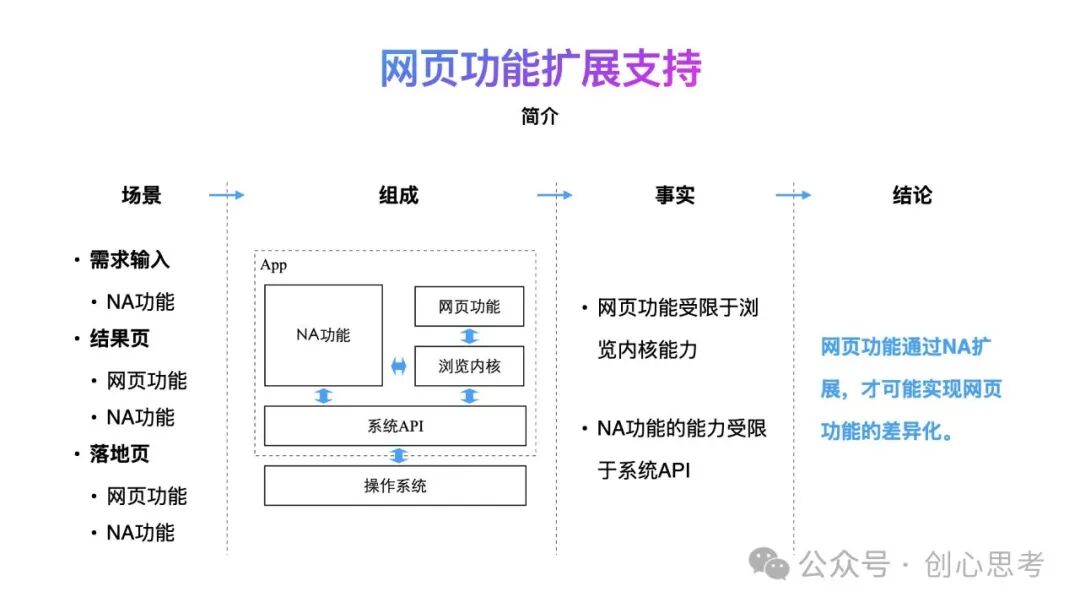
那么如何在鸿蒙系统中实现网页功能的扩展呢?
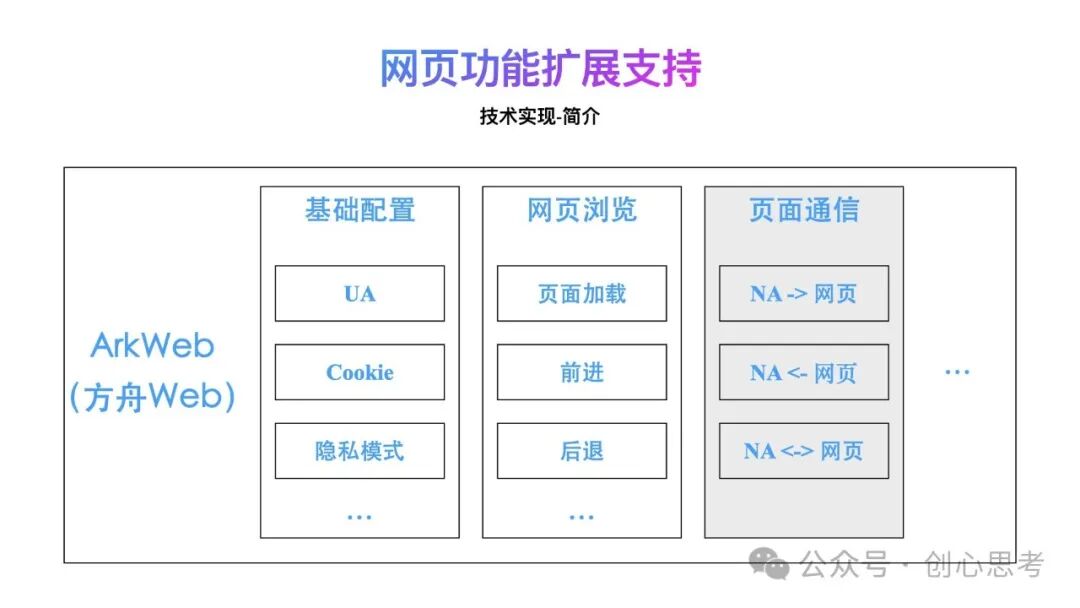
在鸿蒙系统中有提供供ArkWeb(方舟Web)支持网页功能的浏览。并公开了一系列有关的API,为开发者使用。
-
在基础配置层面提供了UA、Cookie、隐私模式等。
-
在网页浏览层面提供了页面加载、前进、后退等。
-
在页面通信层面提供了 NA与网页单向通信、网页与NA单向通信及NA与网页的双向通信。
-
同时也提供了页面交互,加载过程等事件的监听,支持研发人员实现与网页展示、浏览过程的功能定制。
下面的内容,重点介绍页面通信及实现自定义Scheme扩展。
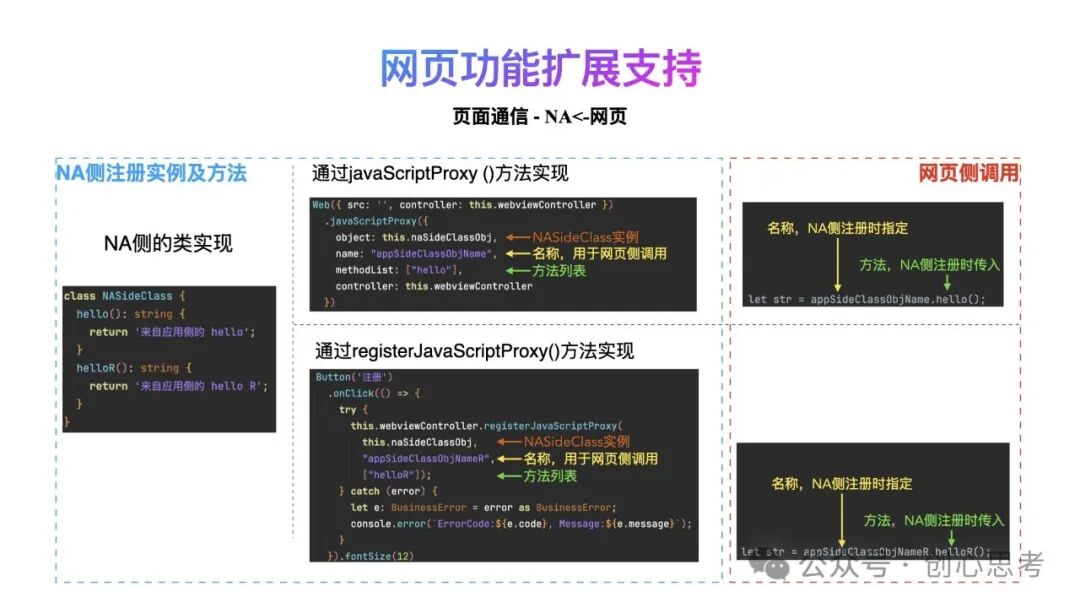
在鸿蒙系统中,除了系统提供的相关API之外,NA侧通常借助于JS与网页侧通信,方式有两种。
第一种为调用网页中的JS代码,比如调用网页中的函数,当网页中实现了某个函数,在NA侧通过runJavaScript API,传入对应的函数名可执行该函数。
第二种为向网页中传递JS代码,比如向网页中注入一个函数,可由网页侧调用。同样也是在NA侧通过runJavaScript API,但传入的是函数体,之后由网页侧调用。

如需要在NA侧响应网页侧的调用,在鸿蒙系统中,支持网页侧直接调用NA侧的类实例方法,也提供了两种方式。
第一种为在ArkWeb组件创建时,使用javaScriptProxy()方法向ArkWeb组件注册类实例、类实例名称及方法列表。在网页侧通过类实例名称及方法名进行调用。
第二种为在ArkWeb组件创建之后,使用registerJavaScriptProxy()方法向ArkWeb组件注册类实例、类实例名称及方法列表。在网页侧通过类实例名称及方法名进行调用。
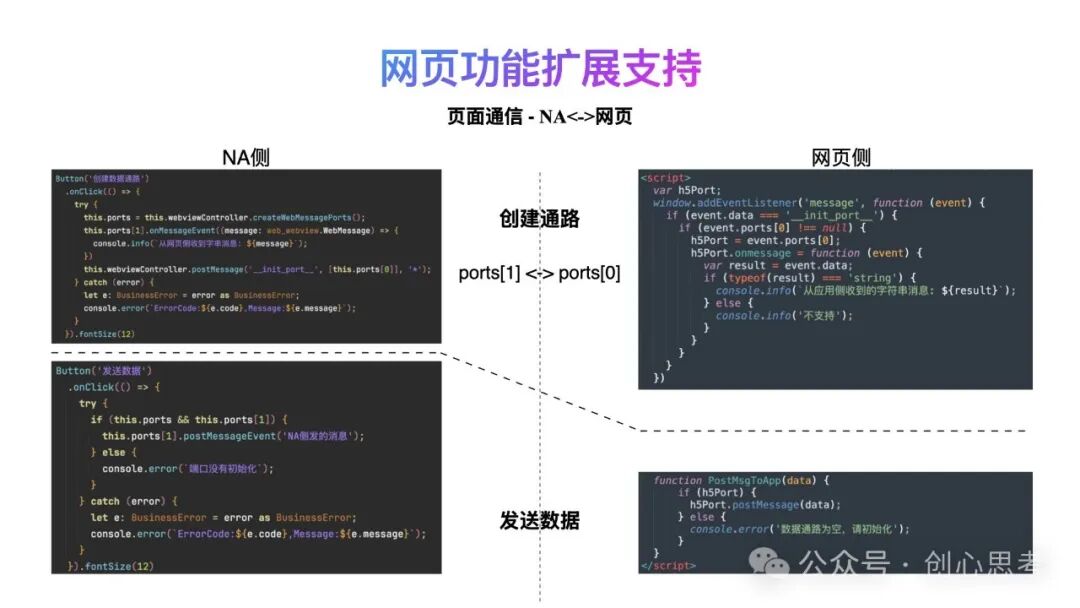
如果希望NA侧与网页侧进行双向的通信,鸿蒙系统中可使用数据通道机制。在使用该机制进行通信之前,先创建数据通道,之后再基于该数据通道进行数据的发送及接收。具体的做法如下。
在NA侧使用createWebMessagePorts()创建数据通道,该API接口可创建两个消息端口,其中一个端口用于NA侧发送及接收消息,另外一个消息端口由NA侧发送至网页侧保存,网页侧使用该接口发送及接收消息。
基于数据通道,NA侧与网页侧实现了双向的数据通信,可适用于大部分的业务场景中。
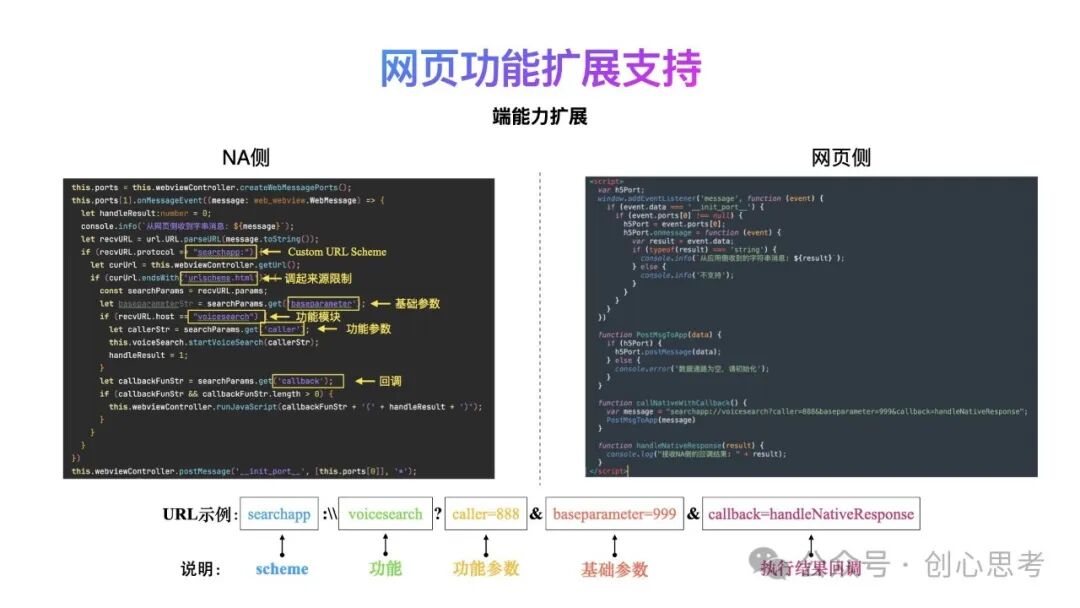
下面的代码中,基于数据通道,实现网页侧调起NA侧语音搜索的自定义端能力扩展,在网页侧调起NA侧端能力时,向NA侧发送的消息为URL格式。
先看一下整体的URL示例,该URL描述了网页侧调起NA侧语音搜索端能力的基本信息,其中包括scheme、功能(客户端能力)、功能参数、基础参数及执行结果回调等字段,在NA侧,收到网页侧的消息后,先判断scheme是否为自定义的URL Scheme,之后再判断调起来源,来源的判断用于区别一些非预期的页面调起。
如果调起来源符合预期,则进行下一步的数据解析,这目的是防止一些非预期的调用产生。之后再解析基础参数,与安全效验相关的数据也可以放在该参数中或扩展新参数。
再之后才是对端能力模块及参数的解析,执行对应的功能模块,传入参数。当端能力模块执行完后之后。再解析回调字段数据,如有数据则以JS函数调用的方式执行,传入客户端执行的结果。
在实际的研发过程,端能力模块,通常会有多个,为了便于管理及具备较好的扩展性,NA侧应该实现端能力管理模块,统一的管理端能力的事件分发。同时端能力模块应该遵循统一的标准,接入到管理模块中响应调用。
相关内容在本书的第5章中介绍。
一本书的故事《搜索架构之道:App中的搜索系统设计与优化实践》-微信读书中的热门划线(第五章)
04.App复用技术框架支持

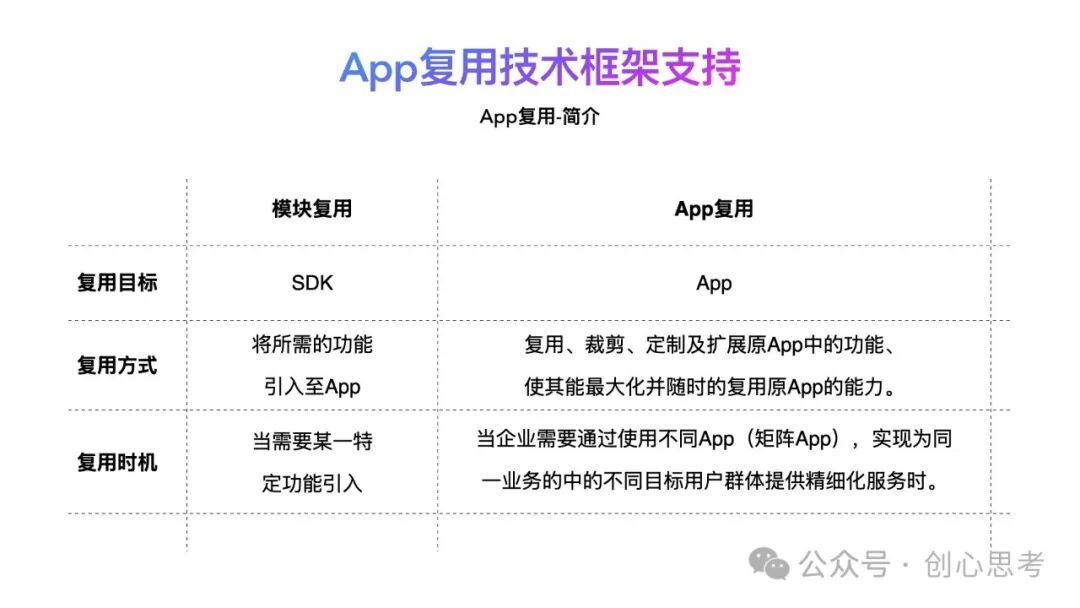
在介绍App复用技术框架之前,先简单的对App复用这个概念进行介绍,在传统的软件研发过程中,常见的复用方式为模块复用。
模块复用通常在于App在需要构建某一个具体的功能时(比如微信分享),将该SDK引入到App中,调用SDK提供的接口实现特定的功能。
而App复用,则是以App作为一个整体,被另外一个App复用(可以理解为是App的变体发布),在这个过程中,原App(主线App)中的功能模块可被直拉的复用、裁剪或定制,目标App也可以基于原App的技术架构进行功能的扩展。使其能够最大化的并随时时的复用原App中的功能能力。
但App复用是有成本的,大部分的场景不适全。当企业需要通过使用不同的App(矩阵App),实现为同一业务中的不同目标用户群体提供精细化服务时才会使用App复用的方案。
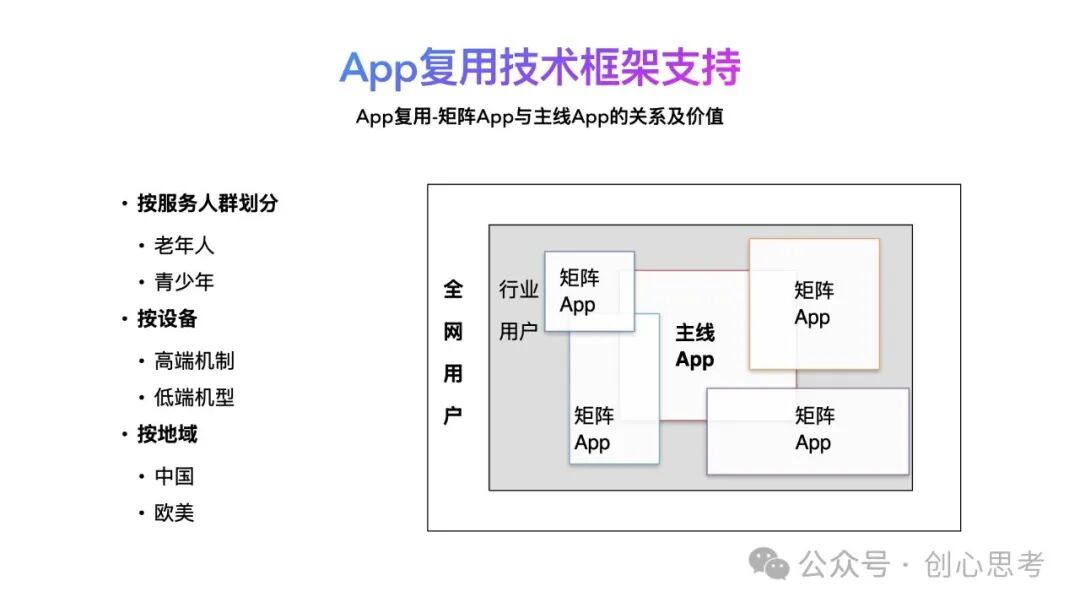
如下图所示,整个行业中,主线App能覆盖大部分用户群体,但是对于一些特定人群、设备或地域中的用户的需求需要重新定制,这样才可以更好服务这些用户。比如对老年人整体的字体变大,对于低端设备只保留核心功能,对于一些地区生态、民俗及政策也有所不同等等。
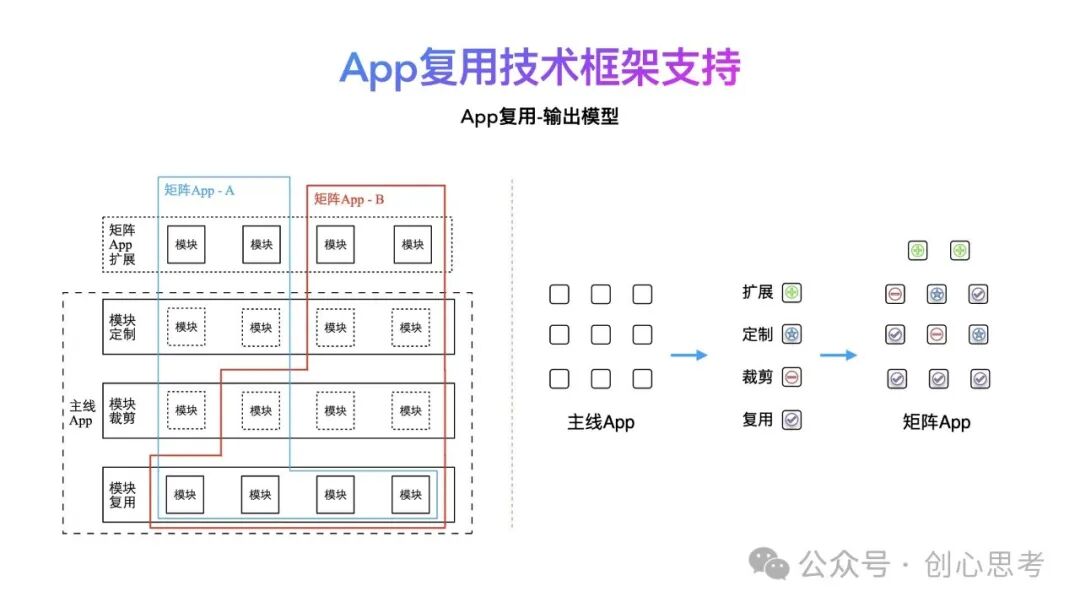
整个App复用的输出模型如下图左侧所示,主线App中的模块可被多个矩阵App复用,但是每个App均有一个独立的工程配置。
对应着矩阵App在复用主线App的过程,矩阵App工程单独配置,直接复用、裁剪及定制主线App中的模块,并基于主线App的技术架构进行功能的扩展。
这样做有两个明显的优势,1)多个App之间可以复用基础能力,2)单一App中的迭代产出可以被其它App及时的复用(包括客户端侧及服务端侧)。
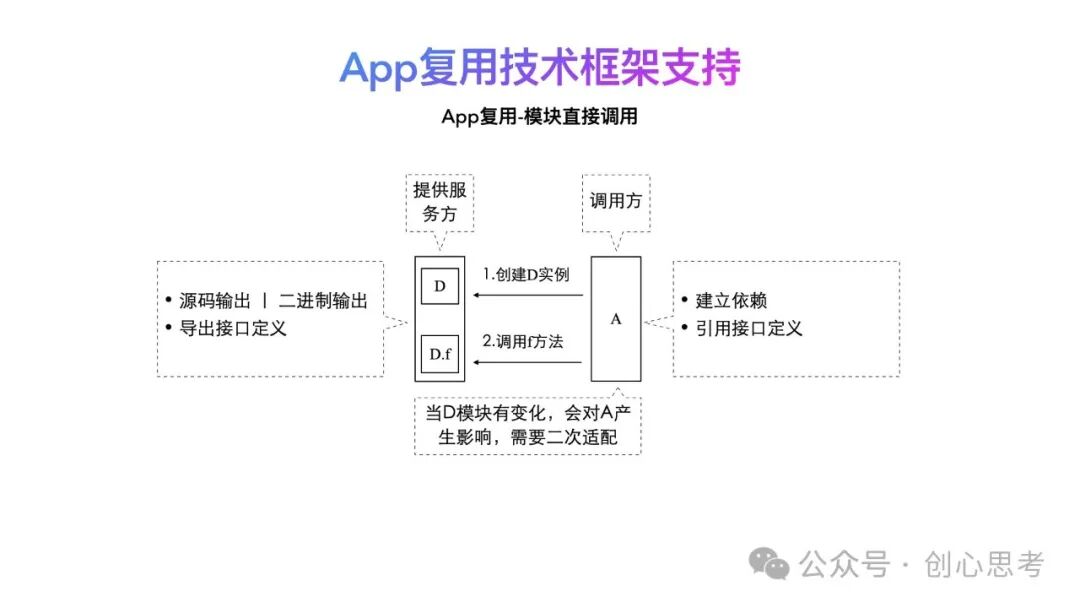
相对于模块复用来讲,App复用还得需要支持模块的裁剪及定制,这意味着模块之间的依赖关系是不稳定的,被调用方的变动会影响调用方的实现。以下图为例,模块A是调用方,模块D是服务提供方。模块D以源码或二进制方式输出,并导出公开的接口定义。当模块A调用模块D中的能力时,先要在建立对模块D的依赖、之后引用模块D公开的接口,最后才是创建模块D的实例调用对应的方法。
当模块D在矩阵App中不被需要,需要删除时,这时需要删除对模块D的依赖、接口关系,及所有与模块D相关的调用代码。对于模块D依赖的模块越多,修改的代码处越多,出现异常的可能性越高,投入的资源成本也越高。
对于矩阵App来说,这些成本每同步一次主线功能,都需要产生。如何降低复用主线App时,因App之间的差异而产生的额外成本呢?
业界公开的方式即使用控制反转服务,即模块D在输出时,将接口层及实现层拆分,在控制反转服务中建立与模块D的关系,模块A在使用模块D时,向控制反转服务获取,模块A仅依赖于模块D的实现层,当模块D被裁剪时,模块A不需要修改,产生的异常也会降低,投入的资源成本也降低。
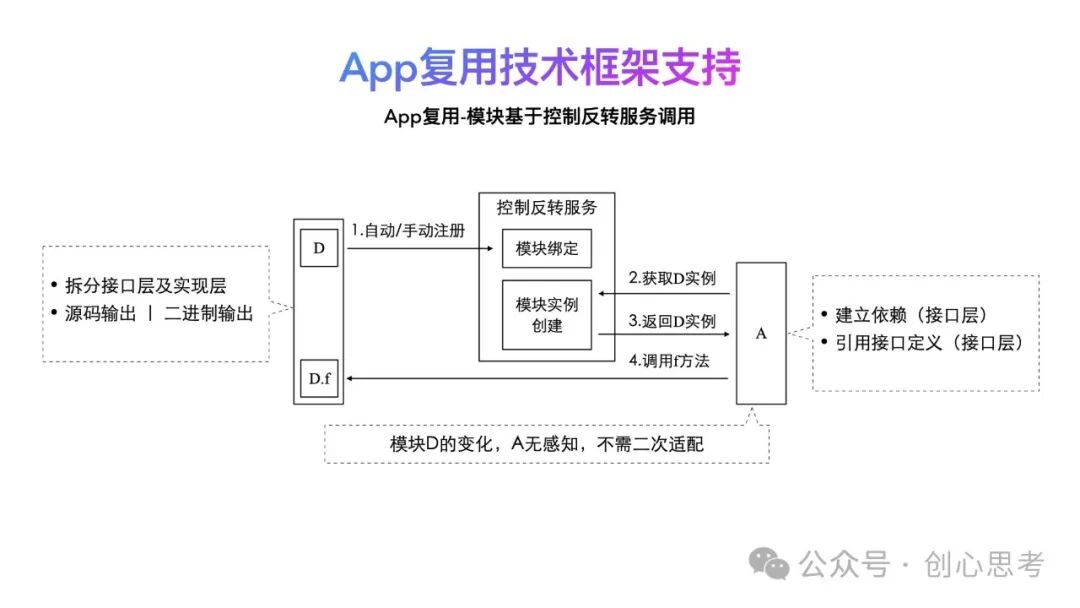
具体的实现如下图所示:
首先,模块D实现了接口层和实现层,均可以以独立组件(源码或二进制)的形式被复用。
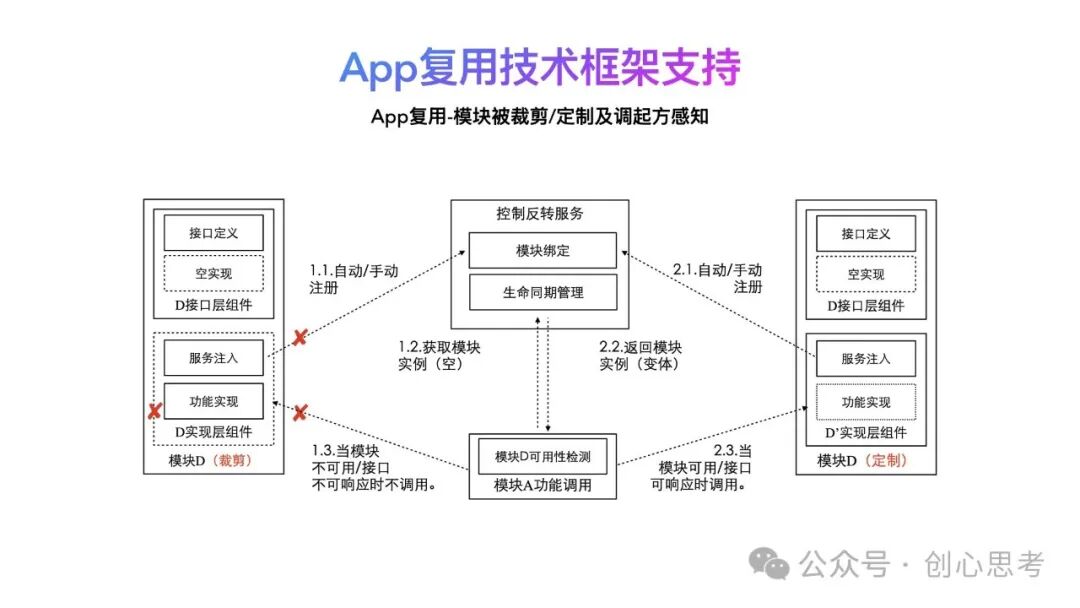
当模块D需要被裁剪时,模块D的实现层不参与打包,也不会向控制反转服务注册自己,当模块A需要使用模块D时,向控制反转服务申请创建模块D的实例,这时返回空,说明模块D不可用,后续的功能调用也不需要执行。
当模块D被修改时,模块D的实现层应该按照接口层的定义而实现(如果必须要修改接口层,应该与主线App确定是否需要由主线来更改,以确定接口的多App的稳定性)。之后向控制反转服务注册自己(模块D'),当模块A需要使用模块D时,向控制反转服务申请创建模块D的实例,这时返回D'的实例,调用相关功能。
在鸿蒙系统中,ArkTS 语言支持动态导入模块以及反射机制,ArkTS 支持动态导入 HSP(HarmonyOS Style Package)、HAR(HarmonyOS Ability Resources)以及 Native 等类型的模块。基于这两个机制,可以构建控制反转服务的关键能力。即与模块之间无直接的耦合。
如下图所示,使用import可动态指定模块名导入该模块,并通过反射机制创建类实例返回给调用方,在调用方模块中该类实例可按照接口层的定义进行功能调用。

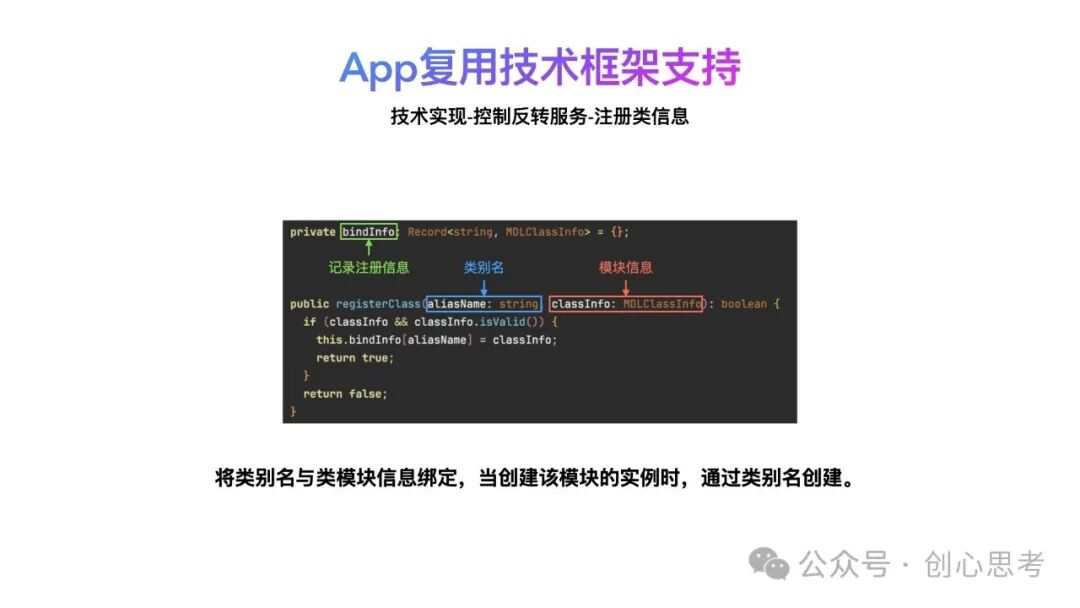
这样,每个类只需要提供所属的模块名及类名,就可以在鸿蒙系统中实例化。将这模块名及类名封装到一个基础类中,用于向控制反转服务注册时使用。如下图所示,MDLClassInfo类中,包含libraryName和className这两个属性。

当该模块可被复用时,即调用方可通过控制反转服务,加载该模块,创建对应的类实例。
如下图所示,控制反转服务提供注册的接口。同一个模块中存在有多个公开类的情况,需要为每个公开类单独注册,每个类指定一个别名(参数aliasName),并绑定对应的模块信息(参数classInfo)。调用方可以通过aliasName创建该类的实例。
对应的服务方模块的实现,需要拆分为接口层及实现层。以ModuleA为例,如下图所示,在鸿蒙系统中,ModuleA的接口层及实现层的代码,实际的研发过程中代码的实现要比这个复杂。
接口层及实现层的代码将会在不同的模块中实现、可按需输出源码或二进制产物,方便在矩阵App中复用。

当服务方模块在矩阵App中是被需要的,在使用该模块之前,需要注册该模块的信息,如服务方模块在矩阵App中是不被需要(需要裁剪)的,则不用注册该模块。
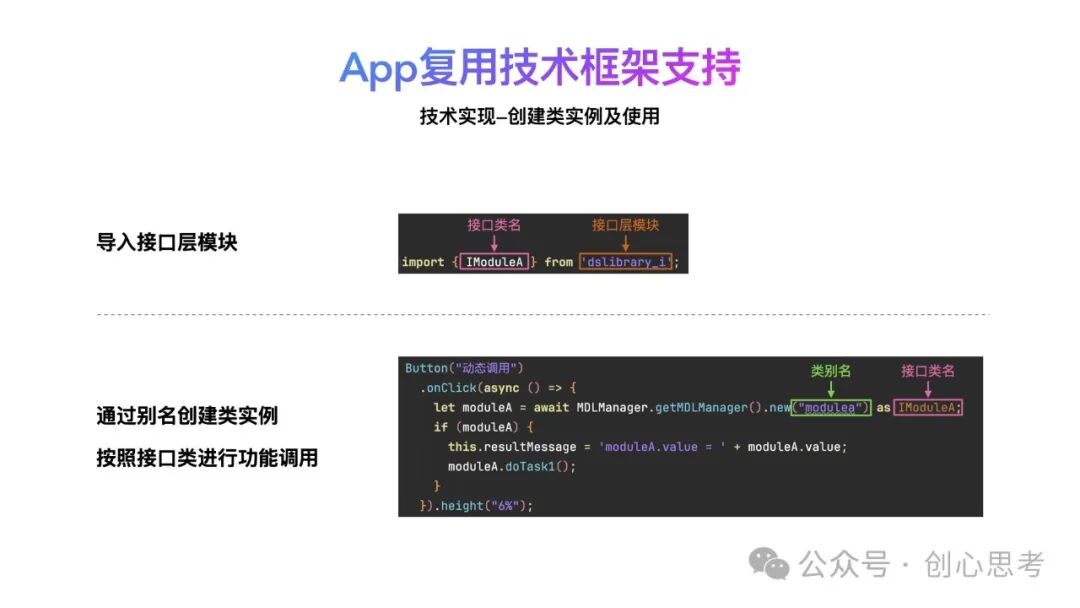
下图的代码中,实现了将ModuleA模块信息注册至控制反转服务中,模块名为实现层的模块名称,类名为实际要创建的类名称,类别名为自定义,但创建ModuleA时需要用到。

在调用方需要使用服务方模块时,需要导入接口层模块,通过控制反转服务创建实现层的类实例,将按照接口层的约定进行功能调用。
这块实现看起来有一些绕,但做到了调用方模块对服务方模块实现层的无依赖,无论服务方模块的实现层是否在矩阵App中使用(参与编译),调用方模块的代码均不需要改动,依赖关系也不需要必动。
回到依赖层级的层面,在App中,调用方处于依赖层的最顶层,直接依赖控制反转服务和服务方接口层。服务提供方的实现层被控制反转服务依赖,当服务提供方需要裁剪时,从控制反转服务中,将对服务提供方实现层的依赖移除。
基于这样的依赖关系,接口层的变化实现了可控。对于调用方的依赖是稳定的,不需要二次的适配,调用方越多收益越大。
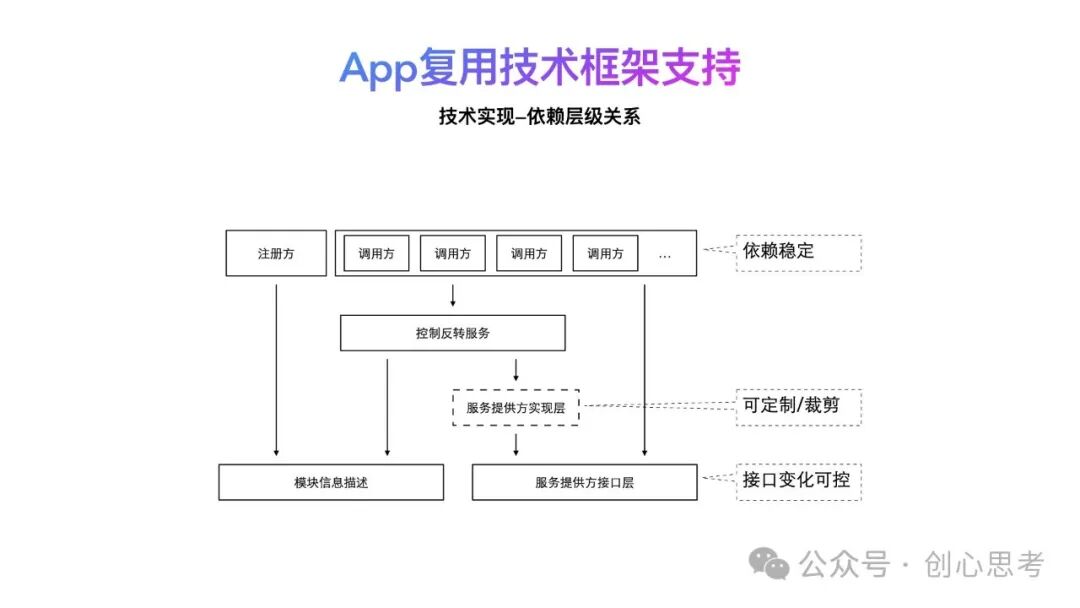
相关内容在本书的第11章中介绍。
一本书的故事《搜索架构之道:App中的搜索系统设计与优化实践》-微信读书中的热门划线(第十一章)
前面的内容中说明如何在鸿蒙系统中实现控制反转服务,并基于控制反转服务,以较低的成本实现了对服务方的复用、裁剪及定制。
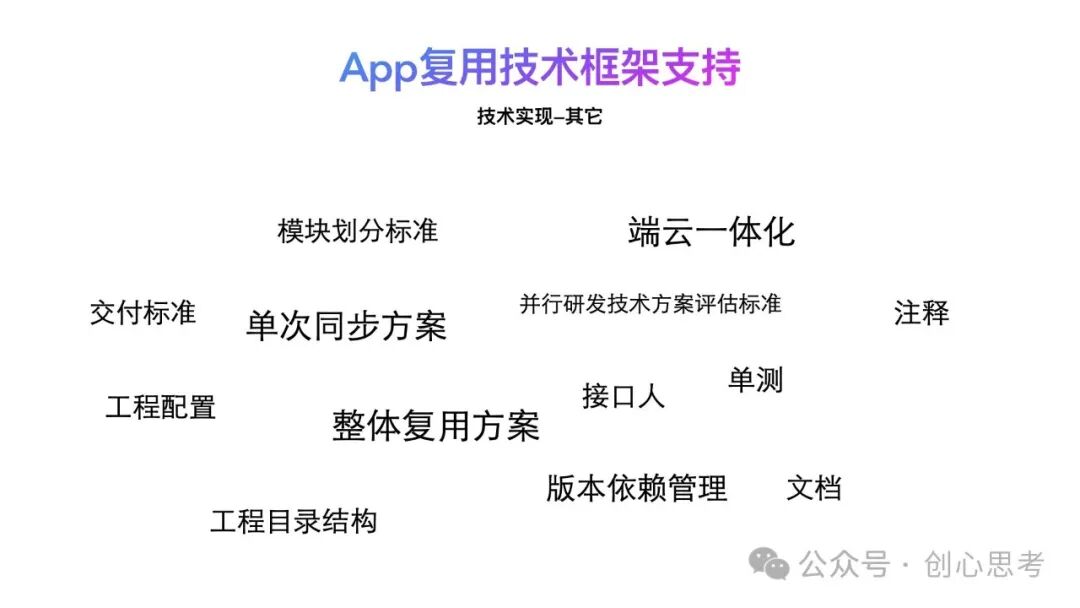
在实际的实施过程,除了技术架构的支持,还需要一些与其相关的标准及方案,支持整体技术方案的可以有效的实施。
比如,App侧的模块如何划分才能实现有效的复用,客户端的变化服务端如何知晓而提供差异化的服务,整体复用及单次同步的方案,工程配置、工程目录、版本依赖、代码、注释及单测的标准,接口人及并行研发方案评估标准等等。
这一系列的方案、流程及规范,才实现了最终的可持续的低成本的App级复用。