这次带来一个基于 Qwen Image Edit Plus 的 ComfyUI 多镜头一致性编辑工作流。它利用同一套模型与一组原始参考图,通过多次条件编码与采样,生成八个视角保持一致的人像照片。

整个流程依靠 CLIP、VAE 与多路 TextEncode 编辑节点协同工作,实现从输入图像提取语义、编码潜空间、分镜头生成、再合成输出的完整图像编辑能力。无论是想要批量产出写真人像、固定模特、多场景镜头切换,这套工作流都能提供稳定的输出效果。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [TextEncodeQwenImageEditPlus 多镜头语义控制核心节点](#TextEncodeQwenImageEditPlus 多镜头语义控制核心节点)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这个工作流以 Qwen Image Edit Plus 为核心,通过加载 CLIP 编码器与专用 VAE,将输入图像编码为潜空间后,依靠多路文本提示与图像输入执行镜头重拍。在结构上,通过大量的 GetNode 与 SetNode 保持状态传递,结合多个采样器 KSampler 负责不同镜头角度的图像再生成,再以 VAE 解码输出最终的成片。整个体系围绕"保持人物与视觉风格一致,同时切换镜头角度"展开,因此无论处理几张图,都能稳定地输出统一风格的结果。
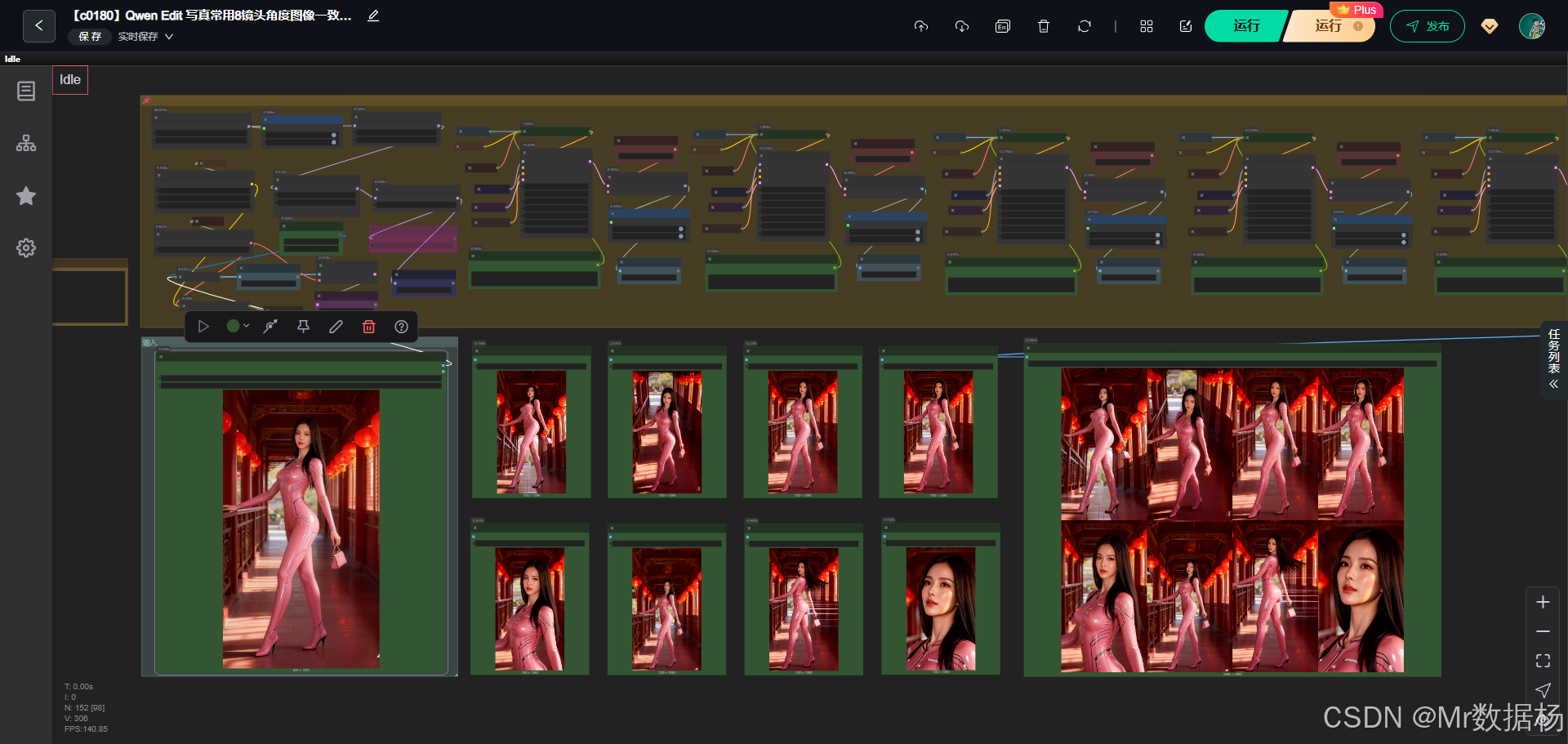
核心模型
本工作流围绕 Qwen 图像编辑模型展开。CLIP 负责文本与图像语义编码,VAE 负责图像与潜变量互转,整体构成"输入参考图 -> 文本编辑提示 -> 多镜头输出"的统一结构。模型的组合让图像特征在潜空间中被准确捕捉,从而支持稳定的人物一致性重拍。
| 模型名称 | 说明 |
|---|---|
| qwen_2.5_vl_7b_fp8_scaled.safetensors | 作为 CLIP 文本与视觉编码器,负责提取输入图语义并支持编辑提示 |
| qwen_image_vae.safetensors | VAE 模型,负责图像与 latent 之间的互相转换,用于压缩与重建 |
Node节点
这个工作流包含大量用于状态管理的 GetNode 与 SetNode,用于在不同生成阶段传递 clip、vae、latent、image1、image2 等关键变量。TextEncodeQwenImageEditPlus 节点是整个系统的灵魂,用于根据输入图像与文字指令生成不同镜头的 Conditioning 信息。KSampler 负责在指定条件下生成 latent,再由 VAEDecode 得到镜头成片。整体节点结构清晰,职责分明,共同确保镜头一致性的编辑能力。
| 节点名称 | 说明 |
|---|---|
| CLIPLoader | 加载 CLIP 模型,负责文本与图像编码 |
| VAELoader | 加载 VAE 模型,执行图像编码与解码的基础模块 |
| TextEncodeQwenImageEditPlus | 核心编辑节点,结合文本提示与图像输入生成编辑条件 |
| KSampler | 根据条件生成 latent,实现不同镜头的图像再生成 |
| VAEDecode / VAEEncode | latent 解码成图像或将图像编码为 latent |
| GetNode / SetNode | 存储与传递 CLIP、VAE、latent、image 等数据 |
| ImageResizeKJv2 | 统一输入图尺寸,提升一致性 |
| SaveImage | 输出最终图像结果 |
工作流程
整个流程围绕"输入参考图像 生成潜空间 多镜头编辑 输出结果"展开。工作流首先通过 VAE 对输入图像进行编码,再交由多个 TextEncodeQwenImageEditPlus 节点根据设定的镜头提示生成对应的正向条件。不同阶段的 KSampler 会依照这些条件输出对应镜头的 latent,随后通过 VAEDecode 转为成片。中途大量使用 GetNode 与 SetNode 传递模型、图像、latent、负向条件等数据,使所有镜头保持稳定一致。最终输出的多镜头结果通过 SaveImage 顺序保存。整个结构相互独立又互相协作,让每个镜头能在一致性的基础上呈现不同视觉表现。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 图像预处理与编码 | 统一输入图像尺寸并编码为 latent | ImageResizeKJv2、VAEEncode |
| 2 | 基础模型装载 | 装载 CLIP、VAE 并分发给后续节点 | CLIPLoader、VAELoader、GetNode、SetNode |
| 3 | 条件生成阶段 | 使用参考图像与提示生成不同镜头的编辑条件 | TextEncodeQwenImageEditPlus |
| 4 | 多镜头采样阶段 | 针对每个镜头执行独立采样 | KSampler |
| 5 | 图像解码 | 将采样得到的 latent 解码成最终成片 | VAEDecode |
| 6 | 状态更新与镜头链路传递 | 通过 SetNode 固定镜头序列输入,为下一级镜头生成做准备 | SetNode、GetNode |
| 7 | 多图保存 | 将完整镜头序列导出 | SaveImage |
大模型应用
TextEncodeQwenImageEditPlus 多镜头语义控制核心节点
这个节点是整个工作流的语义驱动核心,它负责把用户输入的 Prompt 转换成可被模型理解的编辑条件。它会结合参考图像、VAE 编码的潜空间特征与 CLIP 的语义嵌入,将"镜头角度""拍摄方式""距离感"等抽象描述落实为明确的图像编辑方向。所有镜头风格一致性的根源都来自这里,因此 Prompt 的质量直接决定画面效果。每个镜头的特性变化,例如特写、俯拍、广角,都是由此节点的 Prompt 决定的。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEditPlus | 将镜头转为特写镜头 | 将用户的镜头提示转化为具体的语义控制向量,影响后续采样阶段的镜头构图与拍摄距离。 |
| TextEncodeQwenImageEditPlus | 将镜头向前移动(Move the camera forward.) 将镜头向左移动(Move the camera left.) 将镜头向右移动(Move the camera right.) 将镜头向下移动(Move the camera down.) 将镜头向左旋转45度(Rotate the camera 45 degrees to the left.) 将镜头向右旋转45度(Rotate the camera 45 degrees to the right.) 将镜头转为俯视(Turn the camera to a top-down view.) 将镜头转为广角镜头(Turn the camera to a wide-angle lens.) 将镜头转为特写镜头(Turn the camera to a close-up.) | 为不同镜头提供可选的拍摄方式模板,所有语义都能驱动模型重建视角与镜头焦段,实现写真级角度切换。 |
| TextEncodeQwenImageEditPlus | 将镜头转为特写镜头 | 同一提示用于多个镜头节点,以确保多镜头一致性生成时维持统一的语义风格基础。 |
| TextEncodeQwenImageEditPlus | 将镜头转为特写镜头 | 用于镜头 5 相关链路中的编辑控制,确保镜头间过渡自然。 |
| TextEncodeQwenImageEditPlus | 将镜头转为特写镜头 | 负责镜头 6 的语义指令,保持构图风格稳定。 |
| TextEncodeQwenImageEditPlus | 将镜头转为特写镜头 | 驱动镜头 7 的生成语义,使该镜头在一致性潜空间上构建独立画面。 |
| TextEncodeQwenImageEditPlus | 将镜头转为特写镜头 | 镜头 8 所使用的语义提示,与其他镜头保持同一风格体系。 |
使用方法
在整个工作流里,用户只需要替换输入的角色图与可选的辅助图(动作、背景等),并填写想要的 Prompt,系统就会自动走完"编码、语义生成、八镜头采样、解码与保存"的完整链路。每当用户换一张原始图像,所有镜头节点都会基于同一潜空间重新生成一套八视角成片,因此只需一次设置就能批量输出统一风格的多镜头图像。
角色图用于确定基础外观,动作图与辅助图用于补充分镜信息,而 Prompt 控制拍摄风格、镜头角度、构图距离,是影响画面最关键的输入。只要改 Prompt 就能让镜头从远景变成特写,从平拍变成俯拍,从正常镜头变成广角镜头。整个过程自动化程度高,替换素材后无需人工调整节点。
| 注意点 | 说明 |
|---|---|
| Prompt 必须明确 | 镜头距离、方向、构图方式都需要用清晰语句表达,否则模型无法准确执行。 |
| 输入图尺寸要统一 | 工作流有图像 Resize 节点,输入图比例过于极端会影响一致性。 |
| 多镜头共享同一语义空间 | 若想显著改变某个镜头风格,需要单独调整对应镜头的 Prompt。 |
| 参考图决定人物一致性 | 若参考图噪点多或脸部模糊,会影响所有镜头效果。 |
| 不建议使用过长 Prompt | 过度堆叠描述可能导致镜头语义冲突,影响稳定性。 |
| 保持素材干净 | 强干扰背景和极端光比会降低潜空间一致性重建能力。 |
应用场景
这套工作流最适合用于需要保持人物一致性的多镜头产出,例如八镜头写真、多角度模特展示、角色形象统一输出等。依靠模型的强一致性语义编码,不同镜头的视觉风格、人物特征、光影关系都能被稳定继承。无论是电商模特拍摄替代、个人写真生成、画面分镜草图、角色定妆照批量生产,这条工作流都能精准完成。通过一次输入即可获得多视角成片,极大减少重复工作量。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 八镜头写真生成 | 同一人物多视角稳定输出 | 摄影师、自媒体创作者 | 近景、中景、特写等不同镜头画面 | 人物特征统一、风格稳定 |
| 电商模特替代拍摄 | 批量生成模特多角度展示图 | 商家、服装品牌 | 穿搭展示、不同站姿镜头 | 省时省成本,人物一致性高 |
| 角色定妆照制作 | 为角色构建多个镜头定妆资料 | 二创作者、游戏概念设计师 | 正脸、侧脸、俯视等固定镜头 | 风格连续,角色识别度高 |
| 分镜预演 | 快速生成故事分镜的角色镜头 | 编剧、导演、分镜师 | 不同景别的镜头参考图 | 输入少量素材即可完成分镜预览 |
| AI 人像合集生成 | 多角度生成社交头像、作品集 | 普通用户、设计师 | 多风格多角度写真 | 输出一致、构图统一、成片速度快 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用