每个系列一本前端好书,帮你轻松学重点。
本系列来自上海交通大学硕士,华为高级算法工程师 靳宇栋 的 《Hello,算法》
你一定不止一次开始学算法,然而,因为很多人都会有的"知难而退"和"持久性差",每次都半途而废,有些算法就因为排在了学习计划中靠后的位置,从来不曾触碰过,既不知道是什么,也不知道可以用来干什么。
本篇文章开始,小匠会带大家一起,用最少的时间,揭开常见"高级"算法的神秘面纱。
什么是"哈希"?
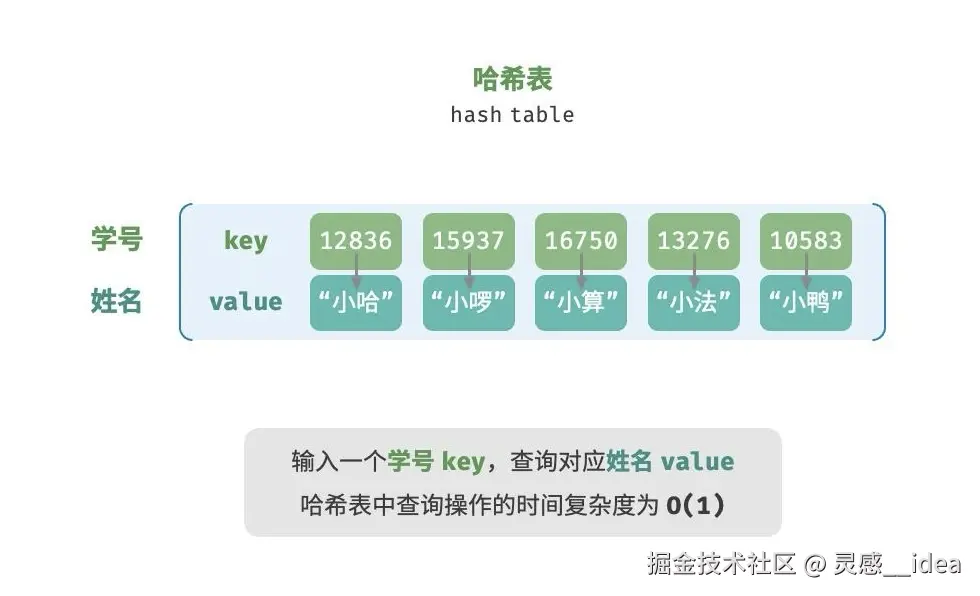
哈希,从萌芽时期到现在已有70多年历史,音译自"hash",原意是"切碎并搅拌"。即将一个任意长度的输入(键 ),通过特定的算法(切碎并搅拌 ),转换成一个固定长度的、看似随机的输出(哈希值) 。
听起来很玄乎,实际想做的,就是能够像数组一样,实现对数据的快速访问,且键可以是非整型数字。
那么在编程语言中,是否包含了这种数据结构呢,答案是:有。
JavaScript的早期版本是没有的,ES6后才加入,它就是Map。
Map
Map大家并不陌生,常用来存储键值对,就像这样:
c
/* 初始化 */
const map = new Map();
// 添加键值对 (key, value)
map.set(12836, '小哈');
map.set(15937, '小啰');
// 根据 key 做查询
let name = map.get(15937);
// 删除
map.delete(12836);看起来并不复杂,而且如果只是存储键值对,还可以用Object,甚至更"方便"。
那为什么要多创造出来一种数据结构,它们的区别是什么?
Object,意为对象,面向对象编程的精髓是将数据做抽象 ,定义它所具备的属性 和能力。
Map,意为映射,主要用于存储、查找数据,单从这点就很容易区分了。
同时,Map有专门的增、删、迭代方法,且严格按照插入顺序迭代。
此外,Object的优化倾向是静态存储和快速访问。Map的优化倾向是频繁增删。
这样对比下来,它们的特点和应用场景差异还是挺大的。
接下来,深入介绍一下哈希表有哪些特点、用途和痛点。
用数组实现哈希
了解一种数据结构的最佳途径就是亲手实现它。
通常,笔者在这个节点都会比较慌:一来不知从何下手,二来涉及逻辑细节就发懵。
但这次不用慌,我们只看最简的"数组实现"。
映射关系的建立
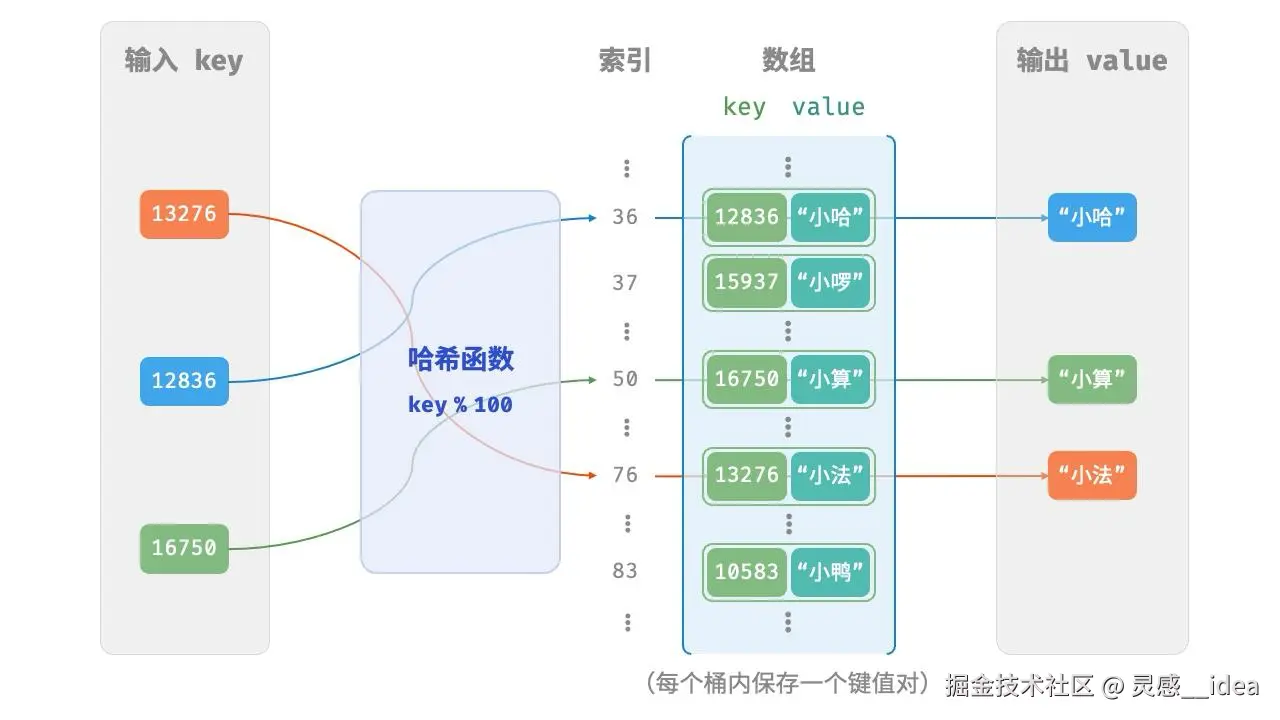
我们知道,数组本身自带索引位,本书作者将这些索引位称为"桶"(bucket),你想叫别的也行,本质就是容器。
每个桶可存储一个键值对(记住这里的"一个"),因此,查询操作就是找到 key 对应的桶,并在桶中获取 value 。
前面提到,哈希表需要实现的是"非整型数字"作为 key,既然要放弃天然的数字索引,兼容其他类型,如何基于 key 定位对应的桶呢?这就要涉及它的核心能力---哈希函数(hash function)。
哈希函数的作用是将一个较大的输入空间映射到一个较小的输出空间。
为什么这么做?因为哈希表的输入是不确定的,但能使用的存储空间是有限的。
本次实现中,输入一个 key ,哈希函数的计算过程有两步:
-
通过哈希算法 hash() 计算得到哈希值。
-
将哈希值对桶数量(数组长度)capacity 取模,从而获取该 key 对应的桶(数组索引)index
index = hash(key) % capacity
随后,就可以利用 index 在哈希表中访问对应的桶,从而获取 value 。
实现逻辑如下。
准备好一个创建键值对的类:
kotlin
/* 键值对 Number -> String */
class Pair {
constructor(key, val) {
this.key = key;
this.val = val;
}
}创建哈希类:
javascript
/* 基于数组实现的哈希表 */
class ArrayHashMap {
#buckets;
constructor() {
// 初始化数组,包含 100 个桶
this.#buckets = new Array(100).fill(null);
}
}计算 value 的哈希函数:
javascript
/* 哈希函数 */
#hashFunc(key) {
return key % 100;
}增、删、查方法:
kotlin
/* 查询操作 */
get(key) {
let index = this.#hashFunc(key);
let pair = this.#buckets[index];
if (pair === null) return null;
return pair.val;
}
/* 添加操作 */
set(key, val) {
let index = this.#hashFunc(key);
this.#buckets[index] = new Pair(key, val);
}
/* 删除操作 */
delete(key) {
let index = this.#hashFunc(key);
// 置为 null ,代表删除
this.#buckets[index] = null;
}遍历方法:
csharp
/* 获取所有键值对 */
entries() {
let arr = [];
for (let i = 0; i < this.#buckets.length; i++) {
if (this.#buckets[i]) {
arr.push(this.#buckets[i]);
}
}
return arr;
}
/* 获取所有键 */
keys() {
let arr = [];
for (let i = 0; i < this.#buckets.length; i++) {
if (this.#buckets[i]) {
arr.push(this.#buckets[i].key);
}
}
return arr;
}
/* 获取所有值 */
values() {
let arr = [];
for (let i = 0; i < this.#buckets.length; i++) {
if (this.#buckets[i]) {
arr.push(this.#buckets[i].val);
}
}
return arr;
}整体比较容易理解,一个是基于哈希函数的value计算,一个是数组遍历。
可以看出,哈希函数是整个过程的关键点,但,也是"痛点"。
哈希的痛
在哈希表中,键的存储不是挨个放的,是经过哈希函数计算得来。
前面提到,哈希表的输入远大于输出,且一个key对应的位置只存放一个value,那么有可能发生什么情况?
不同的 key 经过计算落到了同一个位置上,就与预期相违背了,这种情况称作"哈希冲突"。
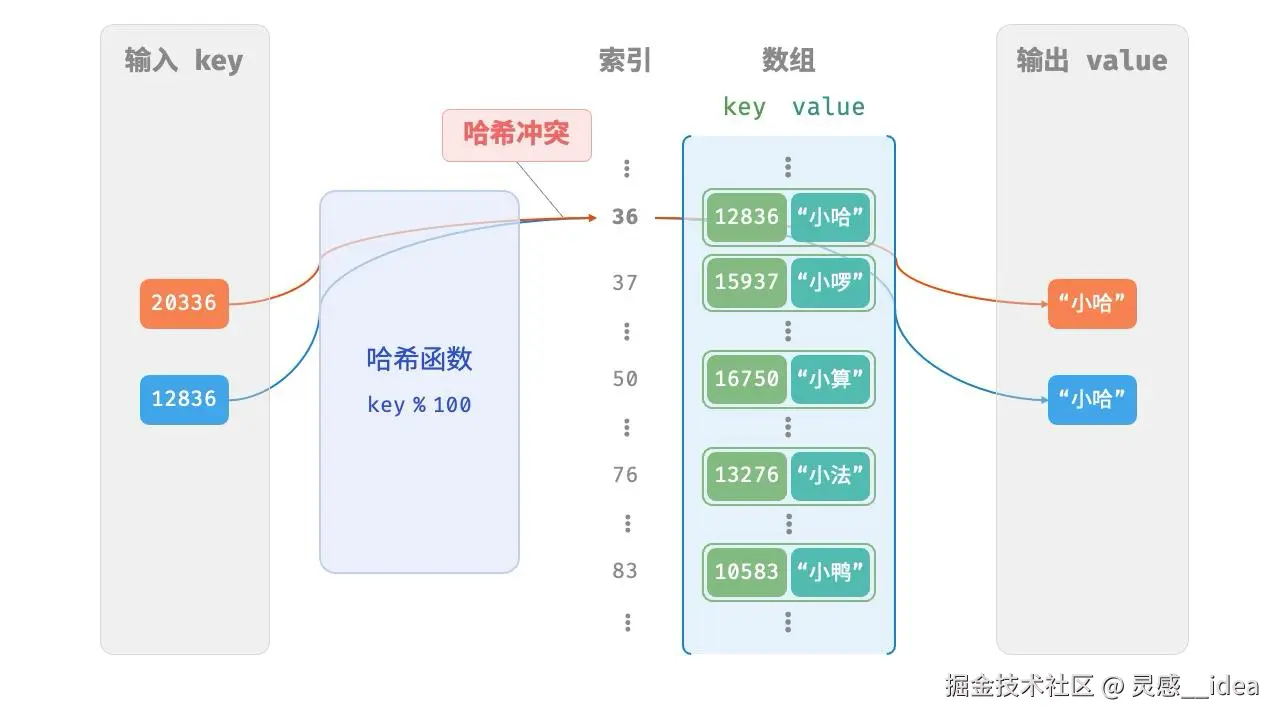
产生冲突后,会对操作产生直接影响,哈希表的优势就大打折扣。怎么办?
比较容易想到的是,哈希表容量越大,不同 key得到同一个结果的概率就越低,冲突就越少,所以,可以通过扩容来减少冲突。
但是这种方法不提倡轻易使用,因为哈希表扩容需要进行大量的数据搬运与值计算,效率太低。
需要采取一些策略来弥补效率上的损失:
1、仅在必要的时候进行扩容。
2、改良数据结构,使哈希表在出现冲突时仍能正常工作。
问题来了,什么是必要的时候?
负载因子与动态扩容
负载因子(load factor)的定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度。
简单理解:当负载因子超过某个阈值(通常是 0.5 到 0.8 之间),表示哈希表要"超重 "了,需要创建一个更大的哈希表(通常是当前大小的 2 倍),然后重新插入所有现有的键值对,这个过程称为 "重哈希" 。
这种方式相比"立即扩容"进行了一定的优化,不过结果还是造成了内存占用的增加。 那有没有可以不扩容,原地优化的方法?
链式地址与开放寻址
听起来高大上,其实简单,想想日常,我们有东西要存到柜子里,但柜子不是空的,怎么办?
1、放得下就继续放,一个柜子塞多个
2、从它旁边再找一个空柜子
链式地址对应方法1,将原本一个位置只存储一个值的方式,改为一个地址存储一串值,即一个"链表"。
开放寻址对应方法2,不引入新的数据结构,而是开放整个存储空间,发现冲突后重新找一个能存放的地址。
这两种方案都有多种实现策略,但它们也不是完美的,有各自的优缺点,同时,它们的存在是为了保证哈希表在发生冲突时仍正常工作,其实是"绕开"了问题,而不是解决问题。
那么,怎样能解决?
哈希算法
既然冲突的来源是"计算",解决问题的根本也就是"计算"。
优秀的哈希算法,应具备以下特点:
- 确定性:相同的输入始终产生相同的输出。
- 效率高:计算过程足够快,开销足够小。
- 均匀分布:键值对尽可能地均匀分布。
在实际中,我们通常不会自己再开发一套哈希算法,而是用一些标准算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等。它们可以将任意长度的输入数据映射到恒定长度的哈希值。
MD5 常用于校验文件完整性,比如软件安装包的哈希值;SHA-2 常用于安全应用与协议,比如生成数字签名;Git使用SHA-1哈希来唯一标识每一次提交。
近一个世纪以来,研发人员都在对哈希算法进行不断地升级优化,要么提升性能,要么提升安全性,那么编程语言都是怎么选择的呢。
编程语言的选择
各种编程语言采取了不同的哈希表实现策略。
- Python 采用开放寻址。字典
dict使用伪随机数进行探测。 - Java 采用链式地址。当
HashMap内数组长度达到 64 且链表长度达到 8 时,链表会转换为红黑树以提升查找性能。 - Go 采用链式地址。规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
- JavaScript 引擎 V8 中的
Map并非使用简单的传统哈希表,而是使用了一个称为OrderedHashMap的数据结构。
小结
越高级的算法,涉及的细节就越多,同时离实际应用场景也越近。
笔者本文所述尽量全面易懂,但不一定全部准确,需要注意,这是你学习哈希算法的起点,而不是终点,欢迎留言交流探讨。
更多好文第一时间接收,可关注公众号:"前端说书匠"