本期对MCP进行深入解析,MCP的最小应用回顾往期内容:
一、MCP 是什么?------ 从行业痛点看协议价值
在深入技术细节前,我们先明确 MCP 的核心定位:MCP 是一套标准化的协议规范,用于定义 AI 模型上下文的结构化格式、传输规则和交互接口,实现不同模型、系统间的上下文 "无缝互通"。
1.1 为什么需要 MCP?------ 现有上下文交互的 3 大痛点
- 格式碎片化:LLM 的文本上下文、CV 模型的特征图谱、多模态模型的混合数据,各自采用私有格式(如 JSON 嵌套、二进制流、自定义 protobuf),跨模型协作需重复开发适配层;
- 信息丢失严重:模型 A 的输出(含推理过程的中间状态、置信度、依赖数据)传递给模型 B 时,常因格式不兼容被 "简化裁剪",导致协作精度下降;
- 同步效率低下:实时场景(如 AI Agent 协作、云边端模型联动)中,上下文传递需手动处理时序对齐、增量更新,延迟高达数百毫秒,无法满足低延迟需求。
1.2 MCP 的核心价值:标准化 + 高效化 + 兼容化
- 标准化:定义统一的上下文元数据、数据类型和序列化格式,让 "一次适配,多端复用" 成为可能;
- 高效化:支持上下文增量传输、按需加载,减少冗余数据传输,提升交互效率;
- 兼容化:向下兼容主流模型架构(Transformer、CNN、RNN)和部署平台(云原生、边缘设备、端侧终端),无需重构现有模型。
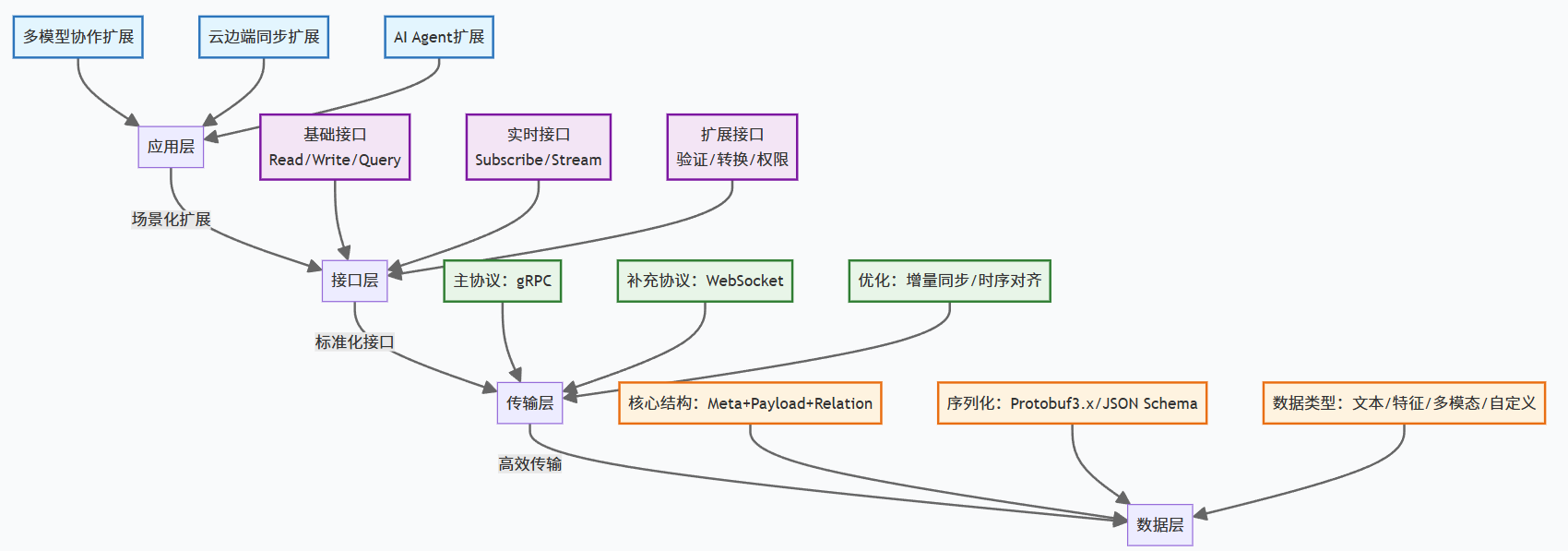
二、MCP 核心技术架构:四层协议栈设计
MCP 的架构设计遵循 "分层解耦" 原则,从下到上分为数据层、传输层、接口层、应用层,每层各司其职且可独立扩展,符合计算机网络协议的经典设计思想。
| 协议层 | 核心功能 | 关键技术选型 |
|---|---|---|
| 数据层 | 定义上下文的结构化格式、数据类型、序列化规则 | Protocol Buffers 3.x、JSON Schema |
| 传输层 | 负责上下文的网络传输、增量同步、时序对齐 | gRPC(主协议)、WebSocket(实时场景) |
| 接口层 | 提供标准化的 API 接口,支持模型/系统的上下文读写、订阅/推送 | RESTful API、gRPC Service |
| 应用层 | 针对特定场景的协议扩展(如多模型协作、云边端同步) | 插件化扩展机制 |
2.1 数据层:上下文的 "统一语言"
数据层是 MCP 的核心,定义了上下文的结构化规范,解决 "怎么描述上下文" 的问题。
2.1.1 核心数据结构
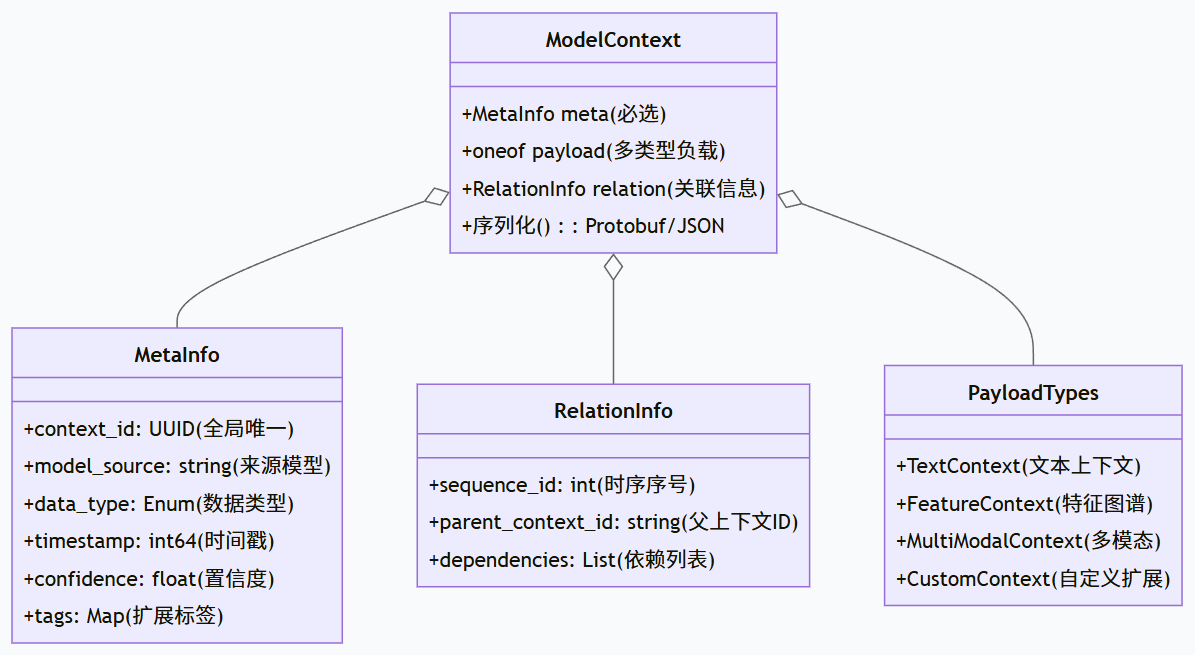
MCP 的上下文数据结构采用 "元数据 + 负载数据" 的设计,通过 Protocol Buffers 序列化(兼顾效率与兼容性):
bash
// MCP上下文核心结构定义(简化版)
message ModelContext {
// 元数据:上下文基本信息(必选)
MetaInfo meta = 1;
// 负载数据:模型输出/输入的核心内容(支持多类型)
oneof payload {
TextContext text = 2; // 文本上下文(LLM场景)
FeatureContext feature = 3; // 特征图谱(CV/NLP特征场景)
MultiModalContext multimodal = 4; // 多模态上下文
CustomContext custom = 5; // 自定义扩展(兼容私有格式)
}
// 关联信息:上下文依赖、时序戳(支持协作溯源)
RelationInfo relation = 6;
}
// 元数据详情(含标准化字段)
message MetaInfo {
string context_id = 1; // 全局唯一ID(UUID v4)
string model_source = 2; // 上下文来源模型(如"gpt-4o"、"resnet-50")
DataType data_type = 3; // 数据类型(枚举:TEXT/FEATURE/MULTIMODAL/CUSTOM)
int64 timestamp = 4; // 生成时间戳(毫秒级)
float confidence = 5; // 来源模型输出置信度(0-1)
map string> tags = 6;// 扩展标签(如"task_type:classification")
}
- 核心设计亮点:采用
oneof类型支持多场景适配,同时通过MetaInfo标准化关键元数据,确保上下文 "可溯源、可解析"; - 序列化选择:优先使用
Protocol Buffers(二进制格式,压缩率高、解析快),同时支持JSON Schema(用于需人类可读的场景,如调试、接口文档)。
2.1.2 数据类型扩展机制
MCP 支持 "基础类型 + 自定义扩展",基础类型覆盖主流场景(文本、特征、多模态),自定义类型通过CustomContext支持私有格式封装(需在元数据中声明解析规则),兼顾标准化与灵活性。
2.2 传输层:高效低延迟的 "上下文通道"
传输层解决 "怎么传递上下文" 的问题,核心目标是低延迟、低带宽占用、高可靠性。
2.2.1 核心传输协议:gRPC 为主,WebSocket 为辅
- 主协议:gRPC(基于 HTTP/2)------ 支持双向流、头部压缩、多路复用,适合高并发、大体积上下文传输(如特征图谱、多模态数据),延迟比 RESTful API 低 30%-50%;
- 补充协议:WebSocket------ 用于实时协作场景(如 AI Agent 对话、云边端实时同步),支持全双工通信,减少连接建立开销,时序对齐精度达 10 毫秒级。
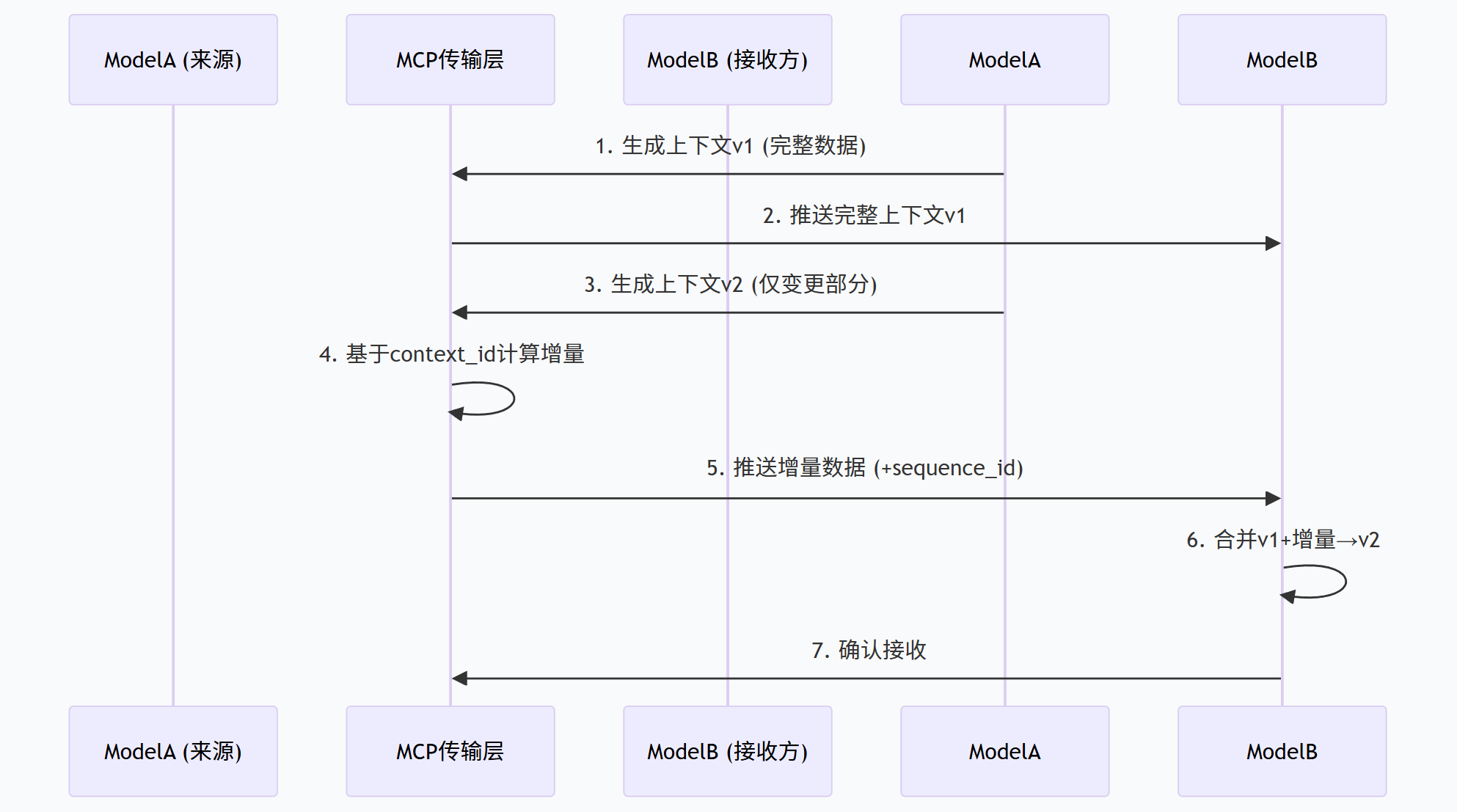
2.2.2 关键优化:增量同步与时序对齐
- 增量同步:通过context_id追踪上下文版本,仅传输变更部分(如 LLM 对话中新增的轮次内容、CV 模型更新的特征向量),带宽占用降低 60% 以上;
- 时序对齐:在RelationInfo中加入sequence_id(时序序号)和parent_context_id(父上下文 ID),解决多模型并行协作时的上下文顺序错乱问题。
2.3 接口层:标准化的 "交互入口"
接口层提供统一的 API 接口,让模型 / 系统无需关注底层传输和数据格式,只需调用接口即可完成上下文读写。核心接口分为 3 类:
2.3.1 基础接口(同步场景)
bash
// 上下文写入接口
rpc WriteContext(WriteContextRequest) returns (WriteContextResponse);
// 上下文读取接口(按ID查询)
rpc ReadContext(ReadContextRequest) returns (ModelContext);
// 上下文查询接口(按条件过滤)
rpc QueryContext(QueryContextRequest) returns (stream ModelContext);2.3.2 实时接口(异步场景)
bash
// 上下文订阅接口(推送模式)
rpc SubscribeContext(SubscribeRequest) returns (stream ModelContext);
// 上下文双向流接口(协作场景)
rpc StreamContext(stream StreamContextRequest) returns (stream StreamContextResponse);2.3.3 扩展接口(场景化需求)
支持插件化扩展,如:
- 上下文验证接口(校验格式合法性);
- 上下文转换接口(自动将自定义格式转为 MCP 标准格式);
- 权限控制接口(基于 OAuth 2.0 的上下文访问权限管理)。
2.4 应用层:场景化的 "协议扩展"
应用层基于核心协议栈,针对特定场景提供扩展规范,无需修改底层协议即可适配不同需求。目前主流扩展场景包括:
-
多模型协作扩展:定义上下文分发规则(如 "一主多从""并行协作");
-
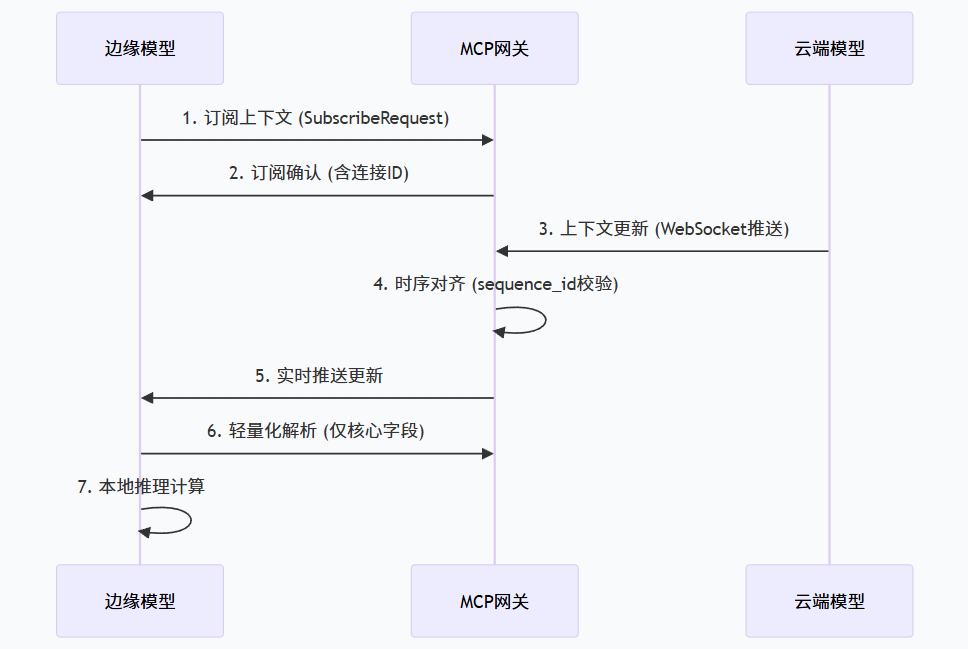
云边端同步扩展:优化边缘设备的轻量化解析、低带宽传输;
-
AI Agent 扩展:支持 Agent 间的上下文共享、任务协作(如工具调用结果传递)。
三、MCP 关键技术:解决上下文互通的核心难题
3.1 上下文标准化:平衡通用性与灵活性
MCP 的核心挑战之一是 "如何让标准化不限制场景适配"。其解决方案是:
- 核心字段强制标准化:如context_id、timestamp、model_source等必须遵循协议规范,确保基础互通;
- 扩展字段灵活配置:通过tags(键值对)和custom(自定义结构)支持场景化需求,如 CV 模型可添加feature_dim(特征维度)、input_shape(输入形状)等扩展字段;
- 格式校验机制:提供标准化的校验器,确保自定义扩展字段不破坏整体结构,同时支持自定义校验规则。
3.2 高效序列化:兼顾速度与兼容性
MCP 选择 Protocol Buffers 3.x 作为默认序列化格式,原因如下:
- 二进制格式:比 JSON 小 30%-50%,传输速度提升 2-3 倍;
- 强类型定义:避免类型转换错误,降低跨语言协作成本(支持 Java、Python、Go、C++ 等主流语言);
- 向后兼容:支持字段新增 / 废弃,无需修改旧版本解析逻辑,适配模型迭代需求。
同时,MCP 支持 JSON Schema 作为辅助格式,用于调试、日志打印等需要人类可读的场景,通过转换器实现两种格式的无缝切换。
3.3 跨平台兼容:适配异构模型与系统
MCP 的兼容性设计体现在两个层面:
- 模型架构兼容:支持 LLM(文本上下文)、CV(特征图谱)、多模态(混合数据)、传统机器学习模型(向量 / 矩阵)等不同类型模型的上下文格式;
- 部署平台兼容:适配云原生(K8s、Docker)、边缘设备(嵌入式系统、IoT 设备)、端侧终端(手机、PC),针对边缘 / 端侧优化轻量化解析逻辑(减少内存占用 30%)。
3.4 安全与隐私:上下文传输的风险控制
上下文可能包含敏感数据(如用户输入、模型参数片段),MCP 通过三层防护保障安全:
- 传输加密:基于 TLS 1.3 加密传输通道,防止中间人攻击;
- 权限控制:通过接口层的AuthInfo字段集成 OAuth 2.0/API Key 认证,限制上下文访问权限;
- 数据脱敏:支持配置脱敏规则(如隐藏用户手机号、模糊化敏感特征),满足合规需求(GDPR、等保 2.0)。
四、MCP 典型应用场景:从技术到落地
MCP 的价值最终体现在落地场景中,以下是 3 个核心应用场景,展现其如何解决实际问题:
4.1 多模型协同推理
- 场景:某智能驾驶系统中,CV 模型(识别路况)、LLM(理解导航指令)、决策模型(输出驾驶动作)协同工作;
- 痛点:CV 模型的路况特征(二进制向量)与 LLM 的文本指令(JSON 格式)无法直接传递给决策模型,需开发多个适配层,且延迟高;
- MCP 解决方案:
- CV 模型输出的特征向量按 MCPFeatureContext格式序列化,LLM 的指令按TextContext格式序列化;
- 决策模型通过 MCP 的QueryContext接口批量读取两个模型的上下文,无需适配层;
- 传输层采用增量同步,仅传递路况变化的特征片段,延迟从 200ms 降至 50ms 以内。
4.2 云边端模型联动
- 场景:某工业质检系统中,云端大模型(高精度特征提取)与边缘设备模型(实时推理)联动,边缘模型需实时获取云端模型的上下文更新;
- MCP 解决方案:
- 云端模型按 MCP 格式输出特征上下文,通过 WebSocket 推送到边缘设备;
- 边缘设备采用 MCP 轻量化解析器(仅解析核心字段),减少内存占用;
- 利用 MCP 的时序对齐机制,确保边缘模型使用最新的云端上下文,质检准确率提升 15%。
4.3 AI Agent 生态协作
- 场景:多个 AI Agent(如问答 Agent、工具调用 Agent、总结 Agent)协作完成复杂任务,需共享用户对话历史、工具调用结果等上下文;
- MCP 解决方案:
- 所有 Agent 通过 MCP 的SubscribeContext接口订阅共享上下文,新的对话轮次、工具结果自动同步;
- 通过relation字段追踪上下文依赖(如 "总结 Agent 的输入依赖问答 Agent 的输出"),避免协作混乱;
- 支持上下文版本回溯,当协作出错时可恢复到历史版本重新执行。
五、MCP 技术挑战与未来趋势
5.1 当前核心挑战
- 上下文压缩:大体积上下文(如 4K 分辨率图像特征、超长文本对话)的传输效率仍需优化;
- 异构模型深度适配:传统机器学习模型(如 SVM、决策树)的上下文格式与深度学习模型差异较大,适配难度高;
- 标准化生态:不同厂商对 MCP 的扩展存在差异,需建立统一的扩展规范避免 "二次碎片化"。
5.2 未来发展趋势
- 轻量化演进:针对端侧设备(如手机、IoT 传感器)推出 MCP Mini 版本,进一步降低解析成本;
- 智能同步:引入 AI 算法自动优化上下文传输策略(如根据网络状况调整压缩比、根据任务优先级调整同步频率);
- 行业标准化:由开源社区或行业组织(如 IEEE、W3C)主导,推动 MCP 成为跨行业的通用协议;
- 与大模型原生集成:未来 LLM、多模态模型将直接内置 MCP 接口,无需额外适配即可实现协作。
六、总结
MCP 的本质是 AI 模型上下文交互的 "通用语言",通过四层协议栈设计,解决了格式碎片化、信息丢失、同步低效三大核心痛点。其核心价值不在于技术创新的颠覆性,而在于 "标准化" 带来的生态协同效应
