📖标题:d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
🌐来源:arXiv, 2512.09675
🌟摘要
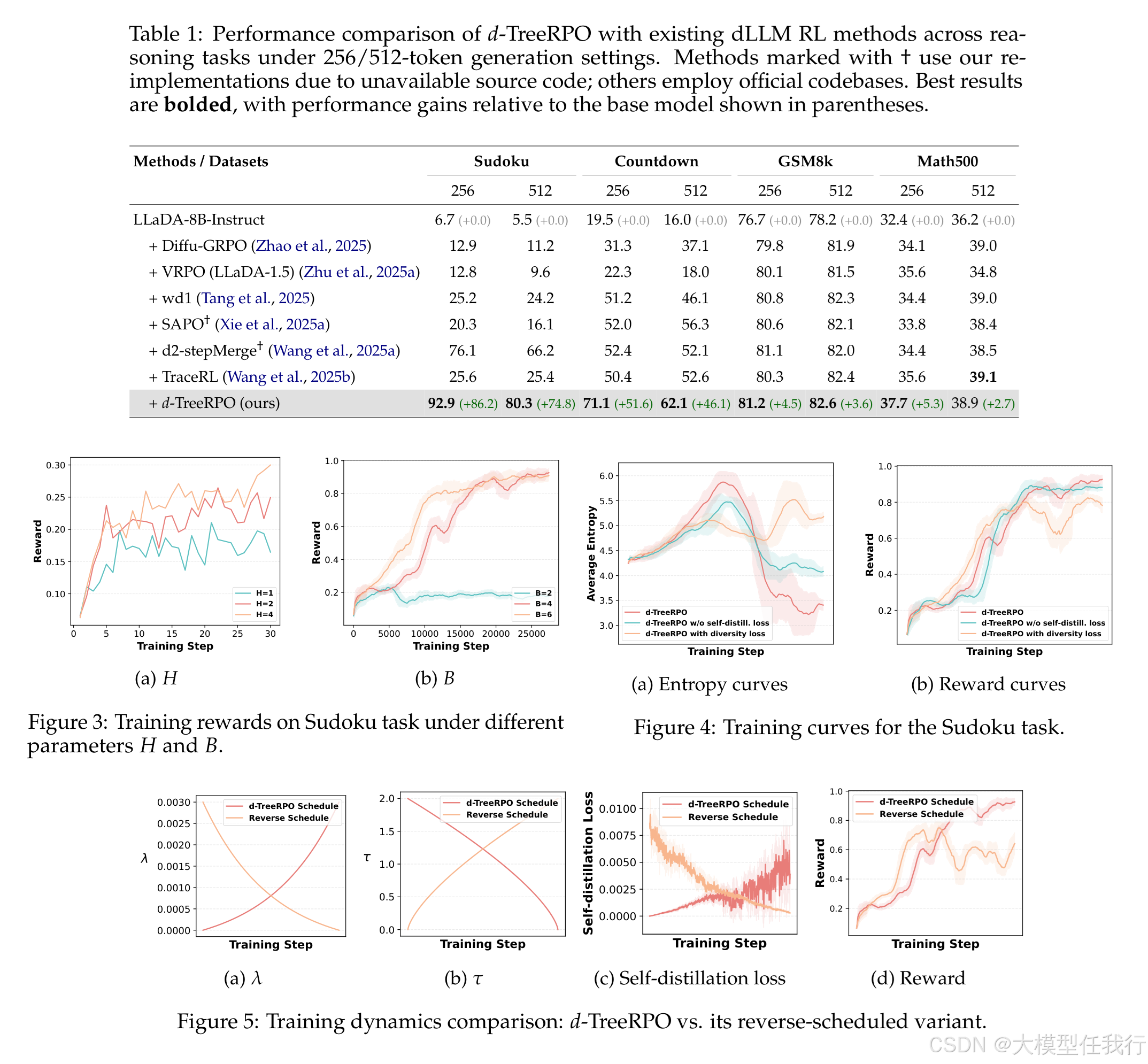
用于扩散大型语言模型 (dLLM) 的可靠强化学习 (RL) 需要准确优势估计和预测概率的精确估计。现有的 dLLM 的 RL 方法在两个方面都很短:它们依赖于粗略或不可验证的奖励信号,并且它们在不考虑相对于正确集成所有可能的解码顺序的真实无偏预期预测概率的偏差的情况下估计预测概率。为了缓解这些问题,我们提出了 d-TreeRPO,这是一种可靠的 dLLM RL 框架,它利用基于可验证结果奖励的树结构推出和自下而上的优势计算来提供细粒度和可验证的逐步奖励信号。在从父节点估计条件转移概率到子节点时,我们从理论上分析了无偏期望预测概率与通过单次前向传递获得的估计之间的估计误差,发现较高的预测置信度会导致较低的估计误差。在该分析的指导下,我们在训练期间引入了一个时间调度的自蒸馏损失,以增强后期训练阶段的预测置信度,从而实现更准确的概率估计和改进的收敛性。实验表明,d-TreeRPO 优于现有的基线,并在多个推理基准上获得了显着的收益,包括 Sudoku 上的 +86.2、Countdown 上的 +51.6、GSM8K 上的 +4.5 和 Math500 上的 +5.3。消融研究和计算成本分析进一步证明了我们设计选择的有效性和实用性。
🛎️文章简介
🔸研究问题:如何提高扩散语言模型(dLLM)在强化学习中的策略优化的可靠性?
🔸主要贡献:论文提出了d-TreeRPO,一个更可靠的策略优化算法,通过提供细粒度的可验证奖励和更准确的概率估计,提高了扩散语言模型的表现。
📝重点思路
🔸引入树结构的强化学习机制,将去噪过程分解为层次化的步骤,以便实现可验证的过程奖励。
🔸通过单次前向传播估计父子节点之间的条件转移对数概率,以提高计算效率。
🔸设计时间调度的自蒸馏损失机制,随着训练的进展,逐步增强模型的确定性,降低估计误差。
🔸实现了完整的d-TreeRPO损失函数和端到端的训练工作流程。
🔎分析总结
🔸d-TreeRPO在多个推理基准上显著优于现有的dLLM RL方法,具体包括在数独等任务上提高了多达86.2%。
🔸细粒度奖励设计有效减少了奖励黑客风险,使得强化学习的优势估计更加可靠。
🔸实验结果表明,自蒸馏损失在训练过程中显著加速了模型的收敛过程,提高了最终的性能和稳定性。
🔸对比分析显示,d-TreeRPO在计算成本和性能之间提供了良好的平衡,相较于其他方法具备实用性。
💡个人观点
论文的创新点在于将树结构与时间调度的自蒸馏机制结合,建立可验证的奖励信号和精准的转移概率估计。
🧩附录