在云原生技术飞速发展的当下,Kubernetes(简称K8s)已成为容器编排领域的事实标准。无论是互联网大厂的大规模微服务集群,还是中小企业的轻量化应用部署,K8s都凭借其强大的自动化管理能力、高可扩展性和高可用性,成为连接开发与运维的核心桥梁。对于技术学习者、开发人员和运维从业者而言,掌握K8s不仅是职业技能的核心加分项,更是顺应云原生技术浪潮的必然要求。本文将以"由浅入深、理论+实操"的逻辑,从基础概念到架构原理,再到实战部署,全方位拆解K8s的知识体系,辅以原理图清晰呈现核心流程,帮助读者构建完整的K8s知识框架。
一、初识K8s:从容器管理痛点到核心价值
1.1 容器技术的"瓶颈":为什么需要K8s?
在K8s诞生之前,Docker等容器技术已经解决了"应用环境一致性"的核心问题------通过将应用及其依赖打包成容器镜像,实现了"一次构建、到处运行"。但随着容器数量的增多,运维人员逐渐面临一系列棘手难题:
• 手动管理效率低:当容器规模达到数十、数百个时,手动启停、配置、监控容器的操作会变得繁琐且极易出错;
• 服务高可用无保障:单个容器故障后,无法自动重启或切换到其他节点,易导致业务中断;
• 资源调度无章法:容器对服务器资源的占用缺乏统一管控,可能出现部分节点资源过载、部分节点资源闲置的浪费情况;
• 服务发现与负载均衡复杂:多容器实例之间的通信、流量分发需要手动配置反向代理或负载均衡器,运维成本极高。
这些痛点的存在,催生了对容器编排工具的需求。早期的容器编排工具包括Docker Swarm、Mesos等,但K8s凭借更强大的功能、更灵活的架构和更活跃的社区生态,逐渐成为行业主流。
1.2 K8s的核心价值:自动化与智能化的容器管理
Kubernetes是由Google开源的容器编排平台,其设计理念源于Google内部的Borg系统,核心目标是让容器化应用的部署、运维、扩展和自愈实现全自动化。具体而言,K8s的核心价值体现在以下5个方面:
-
自动化运维:支持容器的自动部署、自动重启、自动扩缩容和自动故障转移,大幅减少人工干预;
-
资源智能调度:根据容器的资源需求和节点的资源状态,自动将容器调度到最优节点,实现资源利用率最大化;
-
服务发现与负载均衡:内置服务发现机制,可自动为容器分配网络地址,并通过负载均衡实现流量的均匀分发;
-
存储编排:支持对接本地存储、云存储等多种存储方案,可根据应用需求自动挂载存储卷,实现数据持久化;
-
可扩展架构:通过插件化机制支持自定义资源和控制器,可适配不同的业务场景和技术栈,满足个性化需求。
对于开发人员而言,K8s可以让应用部署摆脱环境限制,实现快速上线;对于运维人员而言,K8s将复杂的集群管理转化为声明式配置,降低了运维门槛;对于企业而言,K8s则是构建云原生架构、实现业务敏捷迭代的核心基础设施。
二、K8s核心概念:零基础也能懂的基础术语
要掌握K8s,首先需要理解其核心概念。这些概念是K8s架构和功能的基础,也是后续实操的前提。以下是K8s最核心的10个基础概念,本文将用通俗语言逐一拆解:
2.1 核心抽象:Pod
Pod是K8s中最小的部署和调度单元,也是K8s的核心抽象。很多初学者会将Pod与容器混淆,实际上Pod可以理解为"容器的封装体",一个Pod内部可以包含一个或多个容器。
• Pod的本质:Pod是一组紧密关联的容器的集合,这些容器共享网络命名空间、存储卷等资源,在逻辑上属于一个"应用单元"。例如,一个Web应用Pod可能包含一个Web容器和一个日志收集容器,二者共享存储卷来实现日志的实时采集。
• Pod的特点:
-
共享网络:Pod内的所有容器共用一个IP地址和端口空间,容器之间可通过localhost直接通信;
-
共享存储:可通过Volume为Pod挂载存储卷,Pod内所有容器均可访问该存储卷,实现数据共享;
-
生命周期短暂:Pod是临时性的,一旦被删除或节点故障,K8s会重新创建新的Pod,而非修复原Pod。
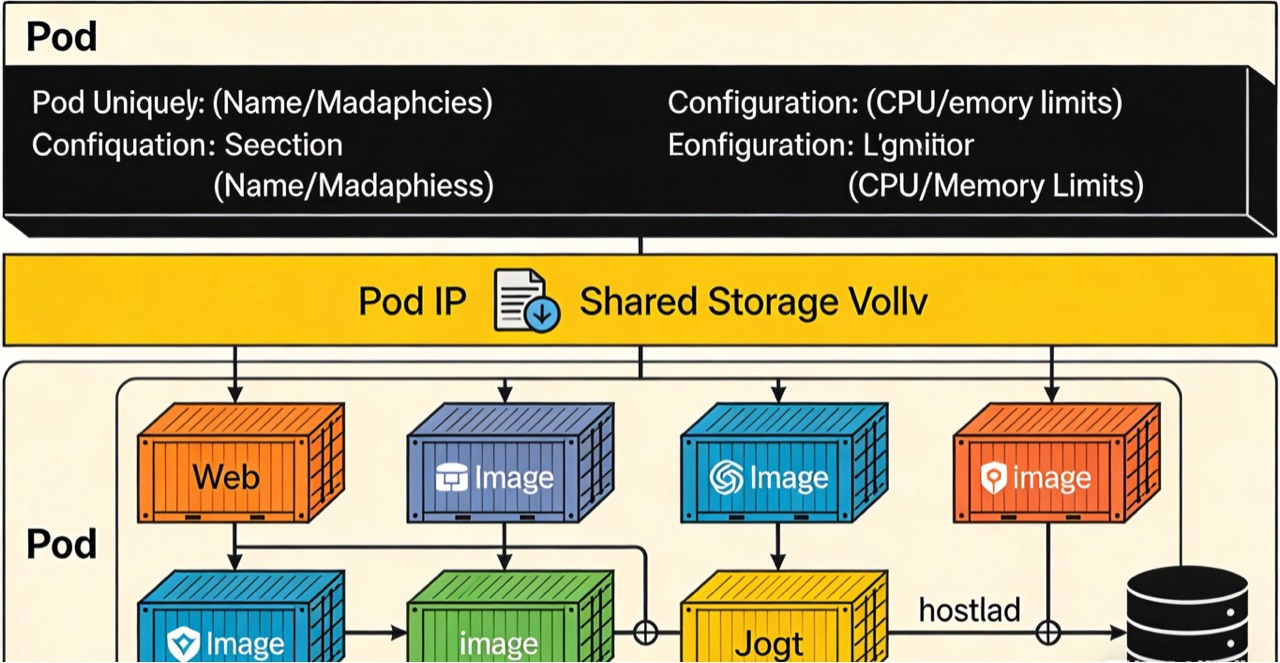
原理图1:Pod结构示意图
(注:以下为原理图文字描述,实际绘图可采用分层结构)
顶层为Pod,包含Pod唯一标识(Name/Namespace)和资源配置(CPU/内存限制);中间层为Pod的共享资源,包括Pod IP、共享存储卷;底层为Pod内的多个容器,每个容器标注镜像名称和功能(如Web容器、日志容器),容器之间通过localhost连通,且共用Pod的存储卷。
2.2 服务入口:Service
Pod的IP是临时的(Pod重建后IP会变化),如果直接通过Pod IP访问应用,会出现"IP失效导致服务不可用"的问题。Service的作用就是为一组Pod提供稳定的访问入口,相当于Pod集群的"固定网关"。
• Service的工作原理:Service会为一组具有相同标签的Pod分配一个固定的ClusterIP(集群内部IP),并通过标签选择器(Label Selector)关联Pod。当客户端访问ClusterIP时,Service会通过负载均衡将请求转发到后端的Pod实例。
• Service的类型:
◦ ClusterIP:仅集群内部可访问,适用于集群内微服务之间的通信;
◦ NodePort:将Service端口映射到集群节点的固定端口,外部可通过"节点IP+节点端口"访问,适用于测试环境;
◦ LoadBalancer:对接云厂商的负载均衡器,自动分配公网IP,适用于生产环境的公网服务;
◦ ExternalName:通过DNS别名访问外部服务,无需创建转发规则。
2.3 声明式配置:Deployment
Deployment是K8s中最常用的控制器,用于管理Pod的创建、更新和扩缩容。其核心特点是"声明式配置"------用户只需定义"应用最终要达到的状态",K8s会自动将当前状态调整为目标状态。
• Deployment的核心能力:
-
Pod副本管理:可指定Pod的期望副本数,K8s会确保集群中始终运行该数量的Pod实例;
-
滚动更新:更新Pod镜像时,会逐步替换旧Pod(先启动新Pod,再删除旧Pod),实现应用无感知升级;
-
版本回滚:若更新后的应用出现故障,可快速回滚到之前的稳定版本;
-
自愈能力:当Pod因故障终止时,Deployment会自动重建新的Pod,保障服务可用性。
2.4 数据持久化:Volume与PVC/PV
容器本身是无状态的(容器删除后数据会丢失),而很多应用(如数据库)需要持久化存储。K8s通过Volume和PV/PVC机制解决数据持久化问题。
• Volume:是Pod级别的存储,可理解为Pod的"数据盘",支持多种存储类型(如emptyDir、hostPath、NFS、云存储等)。但Volume与Pod生命周期绑定,Pod删除后,emptyDir类型的Volume数据会丢失,hostPath数据会保留在节点本地。
• PV(PersistentVolume):是集群级别的持久化存储,由运维人员提前创建,独立于Pod生命周期,支持NFS、Ceph、云盘等多种存储后端。
• PVC(PersistentVolumeClaim):是用户对存储的"申请单",开发人员通过PVC声明所需的存储大小、访问模式等,K8s会自动匹配符合条件的PV并绑定,实现存储资源的按需分配。
2.5 其他核心概念
-
Namespace:集群的"虚拟隔离空间",可将集群资源划分为不同的命名空间(如开发、测试、生产),实现资源隔离和权限管控;
-
Label与Selector:Label是键值对形式的标签,用于标记资源(如Pod、Service);Selector是标签选择器,用于筛选具有特定Label的资源,实现资源之间的关联;
-
ConfigMap与Secret:ConfigMap用于存储非敏感的配置信息(如配置文件、环境变量),Secret用于存储敏感信息(如密码、令牌),二者均可挂载到Pod中,实现配置与应用的解耦;
-
StatefulSet:用于管理有状态应用(如数据库、分布式集群),确保Pod的名称、网络标识、存储卷稳定且有序,支持有序部署和扩缩容;
-
Namespace:用于实现集群资源的逻辑隔离,不同Namespace内的资源名称可重复,且可通过RBAC(基于角色的访问控制)实现不同Namespace的权限管控。
三、K8s整体架构:控制平面与数据平面的协同
K8s集群采用主从架构,分为控制平面(Control Plane)和数据平面(Data Plane,又称节点/Node)两部分。控制平面负责集群的全局决策(如调度、资源管理),数据平面负责运行实际的应用容器。二者通过APIServer通信,实现集群的统一管控。
3.1 控制平面组件
控制平面是K8s集群的"大脑",通常部署在一个或多个主节点(Master Node)上,包含以下核心组件:
3.1.1 API Server(kube-apiserver)
API Server是K8s集群的统一入口和通信枢纽,所有组件的交互都需通过API Server完成,同时它也是用户操作集群的唯一接口(如kubectl命令、客户端SDK)。其核心功能包括:
• 提供RESTful API,支持资源的增删改查和监听;
• 实现认证、授权和准入控制,确保集群访问安全;
• 作为集群状态的"统一数据源",所有组件通过API Server获取集群状态。
3.1.2 etcd
etcd是K8s集群的分布式数据库,用于存储集群的所有配置和状态信息(如Pod、Service的定义,节点状态等)。其特点是强一致性、高可用,采用Raft共识算法确保数据的可靠性。
etcd是集群的"核心数据仓库",一旦etcd数据丢失或损坏,整个集群将无法正常运行,因此生产环境中通常会部署etcd集群(3个或5个节点)以实现高可用。
3.1.3 Controller Manager(kube-controller-manager)
Controller Manager是K8s的"控制器中枢",包含多种内置控制器(如Deployment控制器、Node控制器、Service控制器等),其核心作用是确保集群的实际状态与期望状态一致。
例如,当Deployment指定Pod副本数为3,但集群中实际只有2个Pod时,Deployment控制器会检测到这种差异,并自动创建1个新Pod;当某个节点故障时,Node控制器会将该节点上的Pod标记为不可用,并触发Pod的重新调度。
3.1.4 Scheduler(kube-scheduler)
Scheduler是K8s的"调度器",其核心任务是为新创建的Pod选择最优的工作节点。调度过程分为两个阶段:
-
预选阶段:筛选出满足Pod资源需求和调度策略的节点(如节点必须有足够的CPU/内存、符合亲和性规则等);
-
优选阶段:对预选节点进行打分,选择得分最高的节点(如优先选择资源利用率低的节点、优先选择同区域节点等)。
Scheduler的调度策略可通过配置自定义,以适配不同的业务场景(如高性能应用优先调度到GPU节点)。
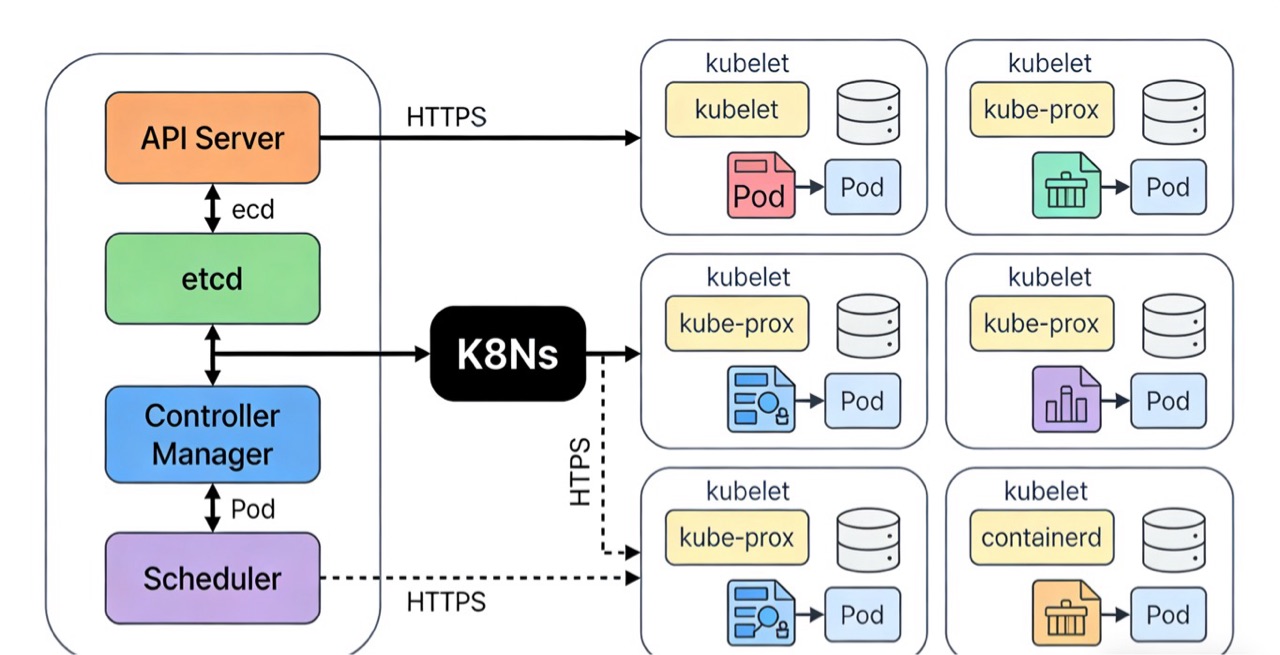
原理图2:K8s集群架构示意图
(注:以下为原理图文字描述)
左侧为控制平面,包含API Server、etcd、Controller Manager、Scheduler四个核心组件,标注各组件的功能和数据流向(如etcd与API Server双向通信,Controller Manager和Scheduler通过API Server读写数据);右侧为多个数据平面节点(Node),每个Node包含kubelet、kube-proxy和容器运行时(如containerd),以及运行在节点上的Pod;控制平面与数据平面通过API Server建立连接,标注通信协议(如HTTPS)。
3.2 数据平面组件
数据平面由多个工作节点(Worker Node)组成,每个节点负责运行Pod和提供容器运行环境,包含以下核心组件:
3.2.1 kubelet
kubelet是节点上的"代理",运行在每个工作节点上,是控制平面与节点之间的通信桥梁。其核心功能包括:
• 接收API Server的指令,管理节点上的Pod(如创建、启动、停止Pod);
• 监控Pod和容器的状态,定期向API Server上报节点和Pod的健康状态;
• 确保容器的运行状态符合Pod的定义(如资源限制、健康检查规则)。
如果kubelet检测到容器故障(如健康检查失败),会根据重启策略自动重启容器,保障Pod的可用性。
3.2.2 kube-proxy
kube-proxy是节点上的"网络代理",运行在每个工作节点上,负责实现Service的负载均衡和服务发现功能。其工作模式主要有两种:
• iptables模式:通过在节点上配置iptables规则,实现流量到后端Pod的转发,是默认模式;
• IPVS模式:基于Linux内核的IPVS模块实现负载均衡,支持更多的负载均衡算法,性能优于iptables,适用于大规模集群。
kube-proxy会实时监听API Server中Service和Endpoint的变化,并动态更新转发规则,确保Service的访问始终有效。
3.2.3 容器运行时(Container Runtime)
容器运行时是负责运行容器的软件,K8s支持多种容器运行时(如containerd、CRI-O等),早期曾依赖Docker,但自K8s 1.24版本起已移除对Docker的直接支持。
容器运行时的核心功能是拉取容器镜像、创建和管理容器,kubelet通过CRI(容器运行时接口)与容器运行时通信,实现对容器的统一管控。
四、核心组件交互:关键流程的原理图解析
理解K8s组件的交互流程,是掌握K8s工作原理的关键。本节将拆解两个核心流程------Pod创建流程和Service访问流程,并通过原理图清晰呈现组件间的协同逻辑。
4.1 Pod创建流程:从声明到运行的全链路
当用户通过kubectl或API创建一个Deployment时,K8s会触发一系列组件交互,最终完成Pod的创建。完整流程如下:
-
用户提交请求:用户通过kubectl执行kubectl apply -f deployment.yaml命令,该请求会被转化为RESTful API调用,发送至API Server;
-
API Server验证与存储:API Server对请求进行认证、授权和准入控制,验证通过后,将Deployment的配置信息存储到etcd中;
-
Controller Manager触发Pod创建:Deployment控制器通过API Server监听Deployment资源的变化,检测到新的Deployment后,根据其定义创建对应的ReplicaSet(副本集),并将ReplicaSet信息写入etcd;
-
Scheduler进行Pod调度:Scheduler通过API Server监听未调度的Pod(由ReplicaSet创建),对Pod执行预选和优选流程,确定目标节点后,将Pod的调度结果(绑定到目标节点)写入etcd;
-
kubelet启动Pod:目标节点的kubelet通过API Server监听Pod的绑定信息,接收到指令后,通过CRI调用容器运行时,拉取容器镜像并创建容器;
-
状态上报与确认:kubelet启动Pod后,会定期将Pod的状态上报给API Server,API Server更新etcd中的Pod状态,至此Pod创建完成。
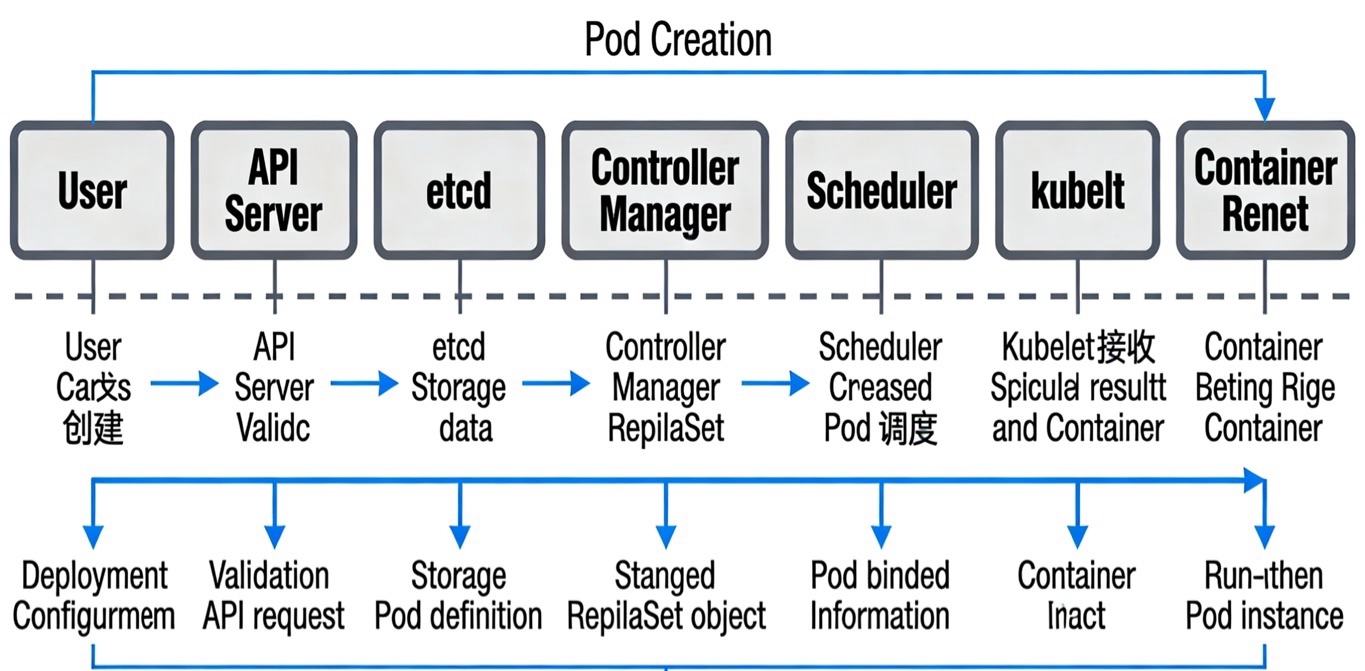
原理图3:Pod创建流程时序图
(注:以下为原理图文字描述)
按时间轴排列组件:用户→API Server→etcd→Controller Manager→Scheduler→kubelet→容器运行时;标注每个阶段的交互动作(如用户发送创建请求→API Server验证→etcd存储→Controller Manager创建ReplicaSet→Scheduler调度→kubelet启动容器),并标注每个步骤的输出结果(如Deployment配置、ReplicaSet、Pod绑定信息、运行中的Pod)。
4.2 Service访问流程:从请求到Pod的转发链路
当客户端访问Service的ClusterIP时,K8s会通过kube-proxy的转发规则,将请求分发到后端Pod。完整流程如下:
-
Service与Endpoint创建:用户创建Service后,API Server将Service信息存储到etcd,同时Endpoint控制器会根据Service的Label Selector筛选出符合条件的Pod,创建Endpoint(包含Pod的IP和端口)并存储到etcd;
-
kube-proxy更新转发规则:节点上的kube-proxy监听Service和Endpoint的变化,在节点上生成对应的iptables或IPVS规则;
-
客户端发送请求:集群内客户端向Service的ClusterIP发送请求,请求先到达节点的网络栈;
-
规则匹配与转发:节点的iptables/IPVS规则匹配到该请求,将其转发到后端某个Pod的IP和端口;
-
Pod响应请求:目标Pod接收请求并处理,将响应结果返回给客户端,完成一次访问。
五、实操案例:从零搭建一个K8s应用部署环境
理论知识需要结合实操才能落地,本节将以"部署一个Nginx应用"为例,带领读者完成从集群搭建到应用部署、扩缩容、更新和回滚的全流程实操。
5.1 环境准备
本次实操采用Minikube搭建单节点K8s集群(适合学习和测试),环境要求如下:
• 操作系统:Linux/macOS/Windows(需开启虚拟化);
• 软件依赖:安装Docker或其他容器运行时;
• 安装Minikube:参考Minikube官方文档完成安装;
• 安装kubectl:kubectl是K8s的命令行工具,用于与集群交互,参考官方文档安装。
5.2 启动Minikube集群
- 启动Minikube集群:
minikube start --driver=docker
该命令会创建一个单节点K8s集群,包含控制平面和数据平面组件。
- 验证集群状态:
查看集群节点
kubectl get nodes
查看控制平面组件状态
kubectl get pods -n kube-system
若节点状态为Ready,且kube-system命名空间下的组件均为Running,则集群启动成功。
5.3 部署Nginx应用
- 创建Deployment配置文件(nginx-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3 # 期望3个Pod副本
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.23 # 容器镜像
ports:
- containerPort: 80 # 容器端口
resources:
limits:
cpu: "0.5" # CPU限制
memory: "512Mi" # 内存限制
requests:
cpu: "0.2"
memory: "256Mi"
- 应用配置文件,创建Deployment:
kubectl apply -f nginx-deployment.yaml
- 验证Deployment和Pod状态:
查看Deployment
kubectl get deployments
查看Pod
kubectl get pods
若Pod数量为3且状态为Running,则应用部署成功。
5.4 创建Service暴露应用
- 创建Service配置文件(nginx-service.yaml):
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx # 关联标签为app=nginx的Pod
ports:
- protocol: TCP
port: 80 # Service端口
targetPort: 80 # Pod容器端口
type: NodePort # 采用NodePort类型,暴露到集群外
- 应用配置文件,创建Service:
kubectl apply -f nginx-service.yaml
- 查看Service信息:
kubectl get services
执行minikube service nginx-service命令,Minikube会自动打开浏览器,访问暴露的Nginx服务,验证应用是否可正常访问。
5.5 应用扩缩容
- 手动扩缩容:将Pod副本数从3调整为5
kubectl scale deployment nginx-deployment --replicas=5
- 验证扩缩容结果:
kubectl get pods
此时Pod数量会增加到5个,实现应用的水平扩展。
5.6 应用更新与回滚
- 更新Nginx镜像版本(从1.23更新为1.24):
kubectl set image deployment/nginx-deployment nginx=nginx:1.24
- 查看更新状态:
kubectl rollout status deployment/nginx-deployment
- 若更新后应用出现故障,执行回滚操作:
查看更新历史
kubectl rollout history deployment/nginx-deployment
回滚到上一个版本
kubectl rollout undo deployment/nginx-deployment
- 验证回滚结果:
kubectl describe pod <pod-name> | grep Image
可看到Pod的镜像已回滚到nginx:1.23。
5.7 清理资源
实操完成后,可清理集群资源:
删除Service
kubectl delete service nginx-service
删除Deployment
kubectl delete deployment nginx-deployment
停止Minikube集群
minikube stop
删除Minikube集群(可选)
minikube delete
六、K8s进阶:核心能力与生产级实践
6.1 核心进阶能力
-
自动扩缩容(HPA):基于CPU利用率、内存使用率或自定义指标,实现Pod的自动扩缩容,应对流量波动;
-
RBAC权限管控:通过Role、ClusterRole、RoleBinding等资源,实现对集群资源的精细化权限控制,保障集群安全;
-
Ingress网关:替代NodePort和LoadBalancer,实现HTTP/HTTPS流量的路由、SSL证书管理和域名转发,是生产环境暴露服务的首选方案;
-
容器健康检查:通过存活探针(livenessProbe)、就绪探针(readinessProbe)和启动探针(startupProbe),监控容器状态,确保应用健康运行;
-
多集群管理:通过Kubefed等工具实现多K8s集群的统一管控,适用于跨地域、跨云厂商的集群部署。
6.2 生产级实践注意事项
-
高可用集群部署:控制平面组件需部署多个实例(如3个Master节点),etcd采用集群模式,避免单点故障;
-
资源规划与隔离:通过ResourceQuota限制Namespace的资源使用,通过LimitRange限制Pod的默认资源,防止资源抢占;
-
监控与日志:部署Prometheus+Grafana实现集群监控,部署ELK或EFK实现日志收集,确保集群可观测性;
-
安全加固:启用PodSecurityPolicy(PSP)或PodSecurity标准,限制Pod的特权操作;启用网络策略(NetworkPolicy),实现Pod间的网络隔离;
-
备份与恢复:定期备份etcd数据,制定集群故障恢复预案,确保数据不丢失。
七、总结与未来展望
K8s作为云原生技术的核心,已成为容器编排领域的事实标准。本文从基础概念切入,逐步深入架构原理、组件交互和实操案例,帮助读者构建了完整的K8s知识体系。对于技术学习者而言,掌握K8s是进入云原生领域的关键一步;对于开发和运维从业者而言,K8s是实现业务敏捷迭代和集群自动化管理的核心工具。
未来,K8s将持续向轻量化、智能化方向演进:一方面,随着K3s、Kind等轻量级K8s发行版的普及,K8s的部署门槛将进一步降低;另一方面,AI技术与K8s的结合(如AI驱动的智能调度、故障预测)将成为新的发展趋势,进一步提升集群的自动化和智能化水平。
云原生技术的浪潮已至,掌握K8s不仅是职业技能的提升,更是拥抱技术变革、实现业务创新的必经之路。