前言:
上文我们学习到了什么是守护进程以及其原理【Linux网络】深入理解守护进程(Daemon)及其实现原理-CSDN博客
本文我们来认识应用层的协议:HTTP!
HTTP协议
虽然应用层协议通常可由程序员自定义,但在实际开发中,我们通常直接使用业界专家已经定义好且非常成熟的现成协议。**HTTP(超文本传输协议)**就是其中最重要、最好用的应用层协议之一。
HTTP是互联网世界的基石,它定义了客户端 (如浏览器)与服务器之间进行通信的标准方式,主要用于交换或传输超文本数据(例如 HTML 文档)。
HTTP协议遵循标准的请求-响应(Request-Response)模型:
请求: 客户端通过HTTP协议主动向服务器发送请求。
**响应:**服务器收到客户端发来的请求后进行处理,并将结果作为响应返回给客户端。
HTTP协议具有两个显著特点:
无连接: 每一次请求都想要建立一个新的连接,处理完既断开
**无状态:**服务器不会保存客户端的状态信息。这意味着对于服务器而言,每一次请求都是全新的,它不具有记忆功能。
URL
URL(Uniform Resource Locator) 统一资源定位符。
我们常说的链接其实就是URL。

css
https://blog.csdn.net/huangyuchi/article/details/155441819上面的链接由三部分组成:
协议方案名 :http;分隔符://, 是固定的分隔格式。
**服务器地址:**blog.csdn.net。
资源在服务器中的地址: /huangyuchi/article/details/155441819
解释:这其实就是Linux系统下的路径,指向我们想要访问的资源!
注意: 最开头的 '/' 并不会我们以为的Linux根目录!!! 而是一个叫做webroot的目录!所以实际路径会转化为:./webroot/huangyuchi/article/details/155441819
HTTP的请求与响应格式
请求格式
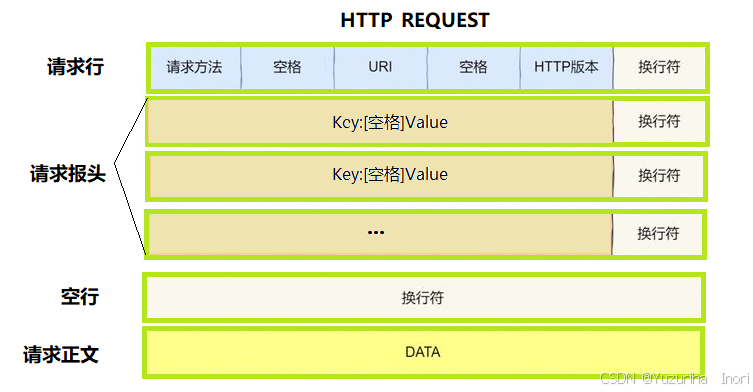
**请求行:**请求方法(GET) 空格 URI(资源地址) 空格 HTTP版本(HTTP/1.1) 换行符(\r\n)
**请求报头:**表示请求的属性。冒号分割的键值对;每组属性之间使用 \r\n 分隔,遇到空行表示Header部分结束。
**请求正文:**空行后面就是请求正文,请求正文允许为空!但如果有内容,在请求报头中就必须有 Content-Length属性的报头来标记正文长度。
响应格式

**状态行:**HTTP版本(HTTP/1.1) 空格 状态码 空格 状态码描述符 换行符(\r\n)
**响应报头:**表示响应的属性。冒号分割的键值对;每组属性之间使用 \r\n 分隔,遇到空行表示结束。
**响应正文:**空行后面就是响应正文,可以为空!但如果有内容,在响应报头中就必须有 Content-Length属性的报头来标记正文长度。
HTTP请求方法
简单介绍两个常用方法
GET方法
用途:用于URL指定的资源
例如:GET /index.html HTTP/1.1
特点:将指定资源解析后,由服务器返回响应内容给客户端
POST方法
用途:传输数据,其数据存放在请求正文中。常用于传输表单数据。
例如:POST /submit.cgi HTTP/1.1
特点:可以发送大量数据给服务器,并且数据都在请求体中。
状态码
响应格式状态行中表示当前状态的数字。
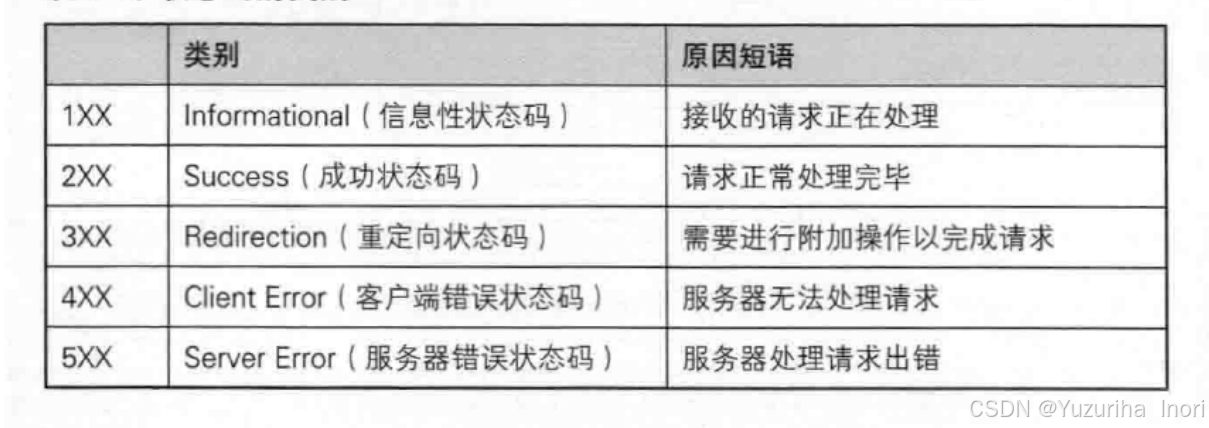
最常用:200 表示成功;404 表示资源不存在;302 表示重定向;
常用具体状态码速查表
|---------|---------------------------|-------------|-----------------------------------------------------|
| 状态码 | 英文名称 | 含义(通俗版) | 常见场景 |
| 200 | OK | 成功 | 最常见的,表示你的请求服务器收到了,也没出问题,东西给你拿回来了。 |
| 301 | Moved Permanently | 永久重定向 | 比如网站换网址了,收藏夹里的旧链接会自动跳到新链接。 |
| 302 | Found | 临时重定向 | 比如你点"我的订单",因为没登录,系统把你暂时跳到"登录页"。 |
| 304 | Not Modified | 资源未修改 | 这是一个缓存机制。服务器告诉你:"你本地存的那张图片没变,不用重新下载了,直接用吧"。 |
| 400 | Bad Request | 请求错误 | 通常是参数写错了。比如服务器要数字,你传了个字符串。 |
| 401 | Unauthorized | 未授权 | "你是谁?" 表示你没登录,或者 Token 过期了。 |
| 403 | Forbidden | 禁止访问 | "我知道你是谁,但我不让你进"。比如普通用户想进管理员后台。 |
| 404 | Not Found | 未找到 | 这个最出名。要么是你网址输错了,要么是那个页面被删了。 |
| 500 | Internal Server Error | 服务器内部错误 | 后端代码抛异常了(Bug),比如空指针、数据库连不上。完全是服务器的锅。 |
| 502 | Bad Gateway | 网关错误 | 通常是中间件(如 Nginx)虽然是好的,但后端的服务(如 Tomcat/Python)挂了或没响应。 |
理解重定向
重定向分为:302临时重定向 301永久重定向
重定向
首先,我们先理解一下什么叫做重定向。
重定向:简单来说,就是让客户端访问指定的地址时,转头访问另一个地址!
重定向主要用于:当一个资源更换位置的时候,为了保证之前的旧地址依然可以有效。对旧地址进行重定向到新地址。
临时重定向(302)
资源的临时转移,使用临时重定向!
举个例子:一个店面由于装修等缘故临时搬到另一个地方,在店门口贴上公告"由于装修,本店暂时搬到xxxx"。
对于临时重定向,客户端都是默认先访问旧地址,再根据新地址去访问对于资源。
永久重定向(301)
资源的永久转移,使用永久重定向!
再举个例子:一个店面由于要扩大直接搬到了一个更大的店面!在店门口贴上公告"本店从今日起,永久搬到xxxx"。
对于永久重定向来说,客户端会直接访问最新的地址!
HTTP报头
常用的报头如下
Content-Type:数据的格式(JSON 还是表单?)
Content-Length:数据的大小
Host:你要访问的域名(区分虚拟主机)
Cookie / Set-Cookie:登录状态和身份识别
User-Agent:你是手机还是电脑,是谷歌浏览器还是 IE
关于Connection报头
HTTP中的 Connection 字段是HTTP报头的⼀部分,它主要用于控制和管理客户端与服务器之间的连接状态。
核心作用:
管理持久连接:connect字段用于管理持久连接(长连接)。持久连接允许客户端和服务器在请求/响应完成后不立即关闭TCP连接,以便于在同一连接上发送发送多个请求和接收多个响应。
持久链接:
**在HTTP/1.1中,默认使用持久连接。**当客户端和服务器都不明确关闭连接的时候,连接将保持打开状态。以便于后续请求和响应可以复用同一个连接。
在HTTP1.0中,默认使用的是非持久连接。 如果想要实现持久连接,这想要在报头中显式的设置 Connect: keep-alive
Connect: keep-alive:表示希望进行持久连接。
Connect: close:表示请求or响应完成后,应该关闭TCP连接。
代码实现
首先,我们要知道HTTP协议的实现是基于TCP协议的。所以我们想要接收客户端的信息,就必要要通过TCP协议来接收信息。
前提代码
InetAddr.hpp
cpp
#pragma once
#include <iostream>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <string>
#include <cstring>
// 实现网络地址与主机地址的转换
class InetAddr
{
public:
InetAddr() {}
// 网络转主机
InetAddr(struct sockaddr_in &addr)
: _addr(addr)
{
_prot = ntohs(_addr.sin_port); // 网络地址转主机地址
char buff[1024];
inet_ntop(AF_INET, &addr.sin_addr, buff, sizeof(buff)); // 将4字节网络风格的IP -> 点分十进制的字符串风格的IP
_ip = std::string(buff);
}
// 主机转网络(客户端)
InetAddr(std::string ip, uint16_t prot)
: _ip(ip),
_prot(prot)
{
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET;
//&addr.sin_addr 是一个指向 struct in_addr 的指针,其内存地址等价于 &(addr.sin_addr.s_addr)(因为结构体的起始地址就是第一个成员的起始地址)
inet_pton(AF_INET, _ip.c_str(), &_addr.sin_addr);
_addr.sin_port = htons(_prot);
}
// 主机转网络(服务端)
InetAddr(uint16_t prot)
: _prot(prot)
{
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET;
_addr.sin_port = htons(prot);
_addr.sin_addr.s_addr = INADDR_ANY; // 任意ip地址
}
// 直接获取sockaddr_in
struct sockaddr *Getaddr()
{
return (struct sockaddr *)&_addr;
}
socklen_t Len()
{
socklen_t len = sizeof(_addr);
return len;
}
uint16_t prot()
{
return _prot;
}
std::string ip()
{
return _ip;
}
// 运算符重载
bool operator==(InetAddr &addr)
{
return _prot == addr._prot && _ip == addr._ip;
}
std::string Getname()
{
return _ip + ':' + std::to_string(_prot);
}
private:
struct sockaddr_in _addr;
uint16_t _prot;
std::string _ip;
};Log.hpp
cpp
// 实现日志模块
#pragma once
#include <iostream>
#include <sstream> // 包含stringstream类
#include <filesystem> //C++17文件操作接口库
#include <fstream>
#include <sys/types.h>
#include <unistd.h>
#include "Mutex.hpp"
using namespace std;
using namespace MutexModule;
// 补充:外部类只能通过内部类的实例化对象,来访问内部类中的方法与成员,且受修饰符限制
// 内部类可以直接访问外部类的方法以及成员,没有限制
namespace LogModule
{
const string end = "\r\n";
// 实现刷新策略:a.向显示器刷新 b.向指定文件刷新
// 利用多态机制实现
// 包含至少一个纯虚函数的类称为抽象类,不能实例化,只能被继承
class LogStrategy // 基类
{
public:
//"=0"声明为纯虚函数。纯虚函数强制派生类必须重写该函数
virtual void SyncLog(const string &message) = 0;
};
// 向显示器刷新:子类
class ConsoleLogStrategy : public LogStrategy
{
public:
void SyncLog(const string &message) override
{
// 加锁,访问显示器,显示器也是临界资源
LockGuard lockguard(_mutex);
cout << message << end;
}
private:
Mutex _mutex;
};
// 向指定文件刷新:子类
const string defaultpath = "./log";
const string defaultfile = "my.log";
class FileLogStrategy : public LogStrategy
{
public:
FileLogStrategy(const string &path = defaultpath, const string &file = defaultfile)
: _path(path), _file(file)
{
LockGuard lockguard(_mutex);
// 判断路径是否存在,如果不存在就创建对应的路径
if (!(filesystem::exists(_path)))
filesystem::create_directories(_path);
}
void SyncLog(const string &message) override
{
// 合成最后路径
string Path = _path + (_path.back() == '/' ? "" : "/") + _file;
// 打开文件
ofstream out(Path, ios::app);
out << message << end;
}
private:
string _path;
string _file;
Mutex _mutex;
};
//
// 日志等级
// enum class:强类型枚举。1.必须通过域名访问枚举值 2.枚举值不能隐式类型转化为整型
enum class LogLevel
{
DEBUG, // 调试级
INFO, // 信息级
WARNING, // 警告级
ERROR, // 错误级
FATAL // 致命级
};
//
// 将等级转化为字符串
string LevelToStr(LogLevel level)
{
switch (level)
{
case LogLevel::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "DEBUG";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
default:
return "UNKOWN";
}
}
// 获取时间
string GetTime()
{
// time函数:获取当前系统的时间戳
// localtime_r函数:将时间戳转化为本地时间(可重入函数,localtime则是不可重入函数)
// struct tm结构体,会将转化之后的本地时间存储在结构体中
time_t curr = time(nullptr);
struct tm curr_time;
localtime_r(&curr, &curr_time);
char buffer[128];
snprintf(buffer, sizeof(buffer), "%04d-%02d-%02d %02d:%02d:%02d",
curr_time.tm_year + 1900, // 年份是从1900开始计算的,需要加上1900才能得到正确的年份
curr_time.tm_mon + 1, // 月份了0~11,需要加上1才能得到正确的月份
curr_time.tm_mday, // 日
curr_time.tm_hour, // 时
curr_time.tm_min, // 分
curr_time.tm_sec); // 秒
return buffer;
}
//
// 实现日志信息,并选择刷新策略
class Logger
{
public:
Logger()
{
// 默认选择显示器刷新
Strategy = make_unique<ConsoleLogStrategy>();
}
void EnableConsoleLogStrategy()
{
Strategy = make_unique<ConsoleLogStrategy>();
}
void EnableFileLogStrategy()
{
Strategy = make_unique<FileLogStrategy>();
}
// 日志信息
class LogMessage
{
public:
LogMessage(const LogLevel &level, const string &name, const int &line, Logger &logger)
: _level(level),
_name(name),
_logger(logger),
_line_member(line)
{
_pid = getpid();
_time = GetTime();
// 合并:日志信息的左半部分
stringstream ss; // 创建输出流对象,stringstream可以将输入的所有数据全部转为为字符串
ss << "[" << _time << "] "
<< "[" << LevelToStr(_level) << "] "
<< "[" << _pid << "] "
<< "[" << _name << "] "
<< "[" << _line_member << "] "
<< " - ";
// 返回ss中的字符串
_loginfo = ss.str();
}
// 日志文件的右半部分:可变参数,重载运算符<<
// e.g. <<"huang"<<123<<"dasd"<<24
template <class T>
LogMessage &operator<<(const T &message) // 引用返回可以让后续内容不断追加
{
stringstream ss;
ss << message;
_loginfo += ss.str();
// 返回对象!
return *this;
}
// 销毁时,将信息刷新
~LogMessage()
{
// 日志文件
_logger.Strategy->SyncLog(_loginfo);
}
private:
string _time;
LogLevel _level;
pid_t _pid;
string _name;
int _line_member;
string _loginfo; // 合并之后的一条完整信息
// 日志对象
Logger &_logger;
};
// 重载运算符(),便于创建LogMessage对象
// 这里返回临时对象:当临时对象销毁时,调用对应的析构函数,自动对象中创建好的日志信息进行刷新!
// 其次局部对象也不能传引用返回!
LogMessage operator()(const LogLevel &level, const string &name, const int &line)
{
return LogMessage(level, name, line, *this);
}
private:
unique_ptr<LogStrategy> Strategy;
};
// 为了用户使用更方便,我们使用宏封装一下
Logger logger;
// 切换刷新策略
#define Enable_Console_LogStrategy() logger.EnableConsoleLogStrategy();
#define Enable_File_LogStrategy() logger.EnableFileLogStrategy();
// 创建日志,并刷新
//__FILE__ 和 __LINE__ 是编译器预定义的宏,作用是获取当前代码所在的文件名、行号
#define LOG(level) logger(level, __FILE__, __LINE__) // 细节:不加;
};Comment.hpp
cpp
#pragma once
// 禁止拷贝类
class NoCopy
{
public:
NoCopy() {};
// 拷贝构造
NoCopy(const NoCopy &nocopy) = delete;
// 赋值重载
const NoCopy &operator=(const NoCopy &nocopy) = delete;
};
enum EXIT
{
OK = 0,
SOCK_ERR,
BIND_ERR,
LISTEN_ERR,
ACCP_ERR,
TCPSERVER_ERR,
TCPCLIENT_ERR,
CONN_ERR
};Mutex.hpp
cpp
// 封装锁接口
#pragma once
#include <pthread.h>
namespace MutexModule
{
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&mutex, nullptr);
}
~Mutex()
{
pthread_mutex_destroy(&mutex);
}
void Lock()
{
pthread_mutex_lock(&mutex);
}
void Unlock()
{
pthread_mutex_unlock(&mutex);
}
pthread_mutex_t *Get()
{
return &mutex;
}
private:
pthread_mutex_t mutex;
};
class LockGuard
{
public:
LockGuard(Mutex &mutex)
: _Mutex(mutex)
{
_Mutex.Lock();
}
~LockGuard()
{
_Mutex.Unlock();
}
private:
// 为了保证锁的底层逻辑,锁是不能够拷贝的,并且也是没有拷贝构造函数的
// 避免拷贝,应该引用
Mutex &_Mutex;
};
}Socket.hpp
cpp
#pragma once
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <memory>
#include "InetAddr.hpp"
#include "Log.hpp"
#include "Comment.hpp"
using namespace LogModule;
const int BACK = 16;
namespace SocketModule
{
// 模板方法模式
// 基类大部分函数都是虚函数
class Socket
{
public:
virtual void SocketOrDie() = 0;
virtual void BindOrDie(uint16_t prot) = 0;
virtual void ListenOrDie(int backlog) = 0;
virtual std::shared_ptr<Socket> Accept(InetAddr *client) = 0;
virtual void ConnectOrDie(InetAddr &addr) = 0;
virtual ssize_t Recv(string &buffer) = 0;
virtual int Send(const std::string &message) = 0;
virtual void Close() = 0;
void BuildTcpSocket(uint16_t prot, int backlog = BACK)
{
SocketOrDie();
BindOrDie(prot);
ListenOrDie(backlog);
}
};
class TcpSocket : public Socket
{
public:
TcpSocket() {}
TcpSocket(int fd)
: _sockfd(fd)
{
}
void SocketOrDie() override
{
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
LOG(LogLevel::ERROR) << "socket error";
exit(SOCK_ERR);
}
}
void BindOrDie(uint16_t prot) override
{
InetAddr addr(prot);
int ret = bind(_sockfd, addr.Getaddr(), addr.Len());
if (ret < 0)
{
LOG(LogLevel::ERROR) << "bind error";
exit(BIND_ERR);
}
}
void ListenOrDie(int backlog) override
{
int ret = listen(_sockfd, backlog);
if (ret < 0)
{
LOG(LogLevel::ERROR) << "listen error";
exit(LISTEN_ERR);
}
}
// 客户端
std::shared_ptr<Socket> Accept(InetAddr *client) override
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int fd = accept(_sockfd, (struct sockaddr *)&peer, &len);
if (fd < 0)
{
LOG(LogLevel::ERROR) << "accept error";
exit(ACCP_ERR);
}
// 将客户端信息带出
InetAddr addr(peer);
client = &addr;
// accept成功后返回一个新的套接字,用于服务
// 可以直接返回fd,也可以返回新对象(的指针)
return std::make_shared<TcpSocket>(fd);
}
void ConnectOrDie(InetAddr &addr) override
{
int ret = connect(_sockfd, addr.Getaddr(), addr.Len());
if (ret < 0)
{
LOG(LogLevel::ERROR) << "connect error";
exit(CONN_ERR);
}
}
ssize_t Recv(string &buffer) override
{
char str[4096 * 3];
ssize_t n = recv(_sockfd, str, sizeof(str), 0);
if (n)
{
// 首先,str并不是空白的,其空间可以被其他函数使用过,保存有垃圾数据
// 其次,revc函数读取后,并不会主动的为我们读取到的信息末尾加上'\0'
// 所以,我们必须自己显示的加上!
// 不然当buffer+=的时候,str作为C风格的字符串,遇到'\0'才会停止
// 导致程序就会不知道读到哪停,把后面的内存垃圾也一并收进去了!
// 最终导致json串解析的时候失败!
str[n] = 0;
buffer += str; // 一定是+=,缓冲区信息是累加,而不是覆盖
}
return n;
}
int Send(const std::string &message) override
{
return send(_sockfd, message.c_str(), message.size(), 0);
}
void Close() override
{
close(_sockfd);
}
int Sockfd()
{
return _sockfd;
}
private:
int _sockfd;
};
}TcpServer.hpp
cpp
#pragma once
#include <sys/types.h>
#include <sys/wait.h>
#include <functional>
#include "Socket.hpp"
using namespace SocketModule;
class TcpServer
{
using Func_t = function<void(shared_ptr<Socket>, InetAddr &)>;
public:
TcpServer(uint16_t prot)
: _prot(prot),
_isrunning(false)
{
// 完成tcp套接字的创建、绑定、监听
ts.BuildTcpSocket(_prot);
}
void Start(Func_t func)
{
_func = func;
_isrunning = true;
while (_isrunning)
{
auto sock = ts.Accept(&_client);
if (sock == nullptr)
continue;
pid_t pid = fork();
if (pid == 0)
{
// 关闭不需要的描述符
ts.Close();
// 子进程
if (fork() > 0)
return;
// 孙子进程执行任务
_func(sock, _client);
return;
}
else if (pid > 0)
{
// 父进程
// 关闭不需要的描述符
sock->Close();
// 子进程会立刻退出,不会阻塞等待
wait(&pid);
}
else
{
ts.Close();
LOG(LogLevel::ERROR) << "fork error";
return;
}
}
_isrunning = false;
}
private:
uint16_t _prot;
TcpSocket ts;
bool _isrunning;
InetAddr _client;
Func_t _func;
};HTTP服务器模拟代码
HTTP.hpp
cpp
#pragma once
#include "TcpServer.hpp"
#include <memory>
#include "Tool.hpp"
const string space = " ";
const std::string linesep = ": ";
const string webroot = "./wwwroot";
const string homepage = "index.html";
class HttpRequest
{
public:
// 不重要,请求的序列化由客户端实现:浏览器!
std::string Serialize()
{
return std::string();
}
// 实现,将客户端发送过来的http字符串,反序列化,得到url
bool Deserialize(std::string &reqstr)
{
// 1.获取请求行
string req = Tool::ReadOneLine(reqstr);
// 2.将请求行序列化
ParseReqLine(req);
// 3.合成正确的uri路径
if (_uri == "/")
_uri = webroot + _uri + homepage;
else
_uri = webroot + _uri;
// bebug
cout << "_method: " << _method << endl;
cout << "_uri: " << _uri << endl;
cout << "_version: " << _version << endl;
return true;
}
// 将请求行按照空格分隔
void ParseReqLine(std::string &reqline)
{
// GET / HTTP/1.1
std::stringstream ss(reqline);
ss >> _method >> _uri >> _version;
}
string Uri()
{
return _uri;
}
private:
std::string _method;
std::string _uri;
std::string _version;
};
class HttpResponse
{
public:
HttpResponse()
: _version("HTTP/1.1")
{
}
// 不重要,应答的反序列化由客户端实现:浏览器!
bool Deserialize(std::string &reqstr)
{
return true;
}
// 实现,将对应的资料序列化后,返回给客户端
std::string Serialize()
{
std::string status_line = _version + space + std::to_string(_code) + space + _desc + Separator;
std::string resp_header;
for (auto &str : _headers)
{
resp_header += str.first + linesep + str.second + Separator;
}
return status_line + resp_header + _blankline + _text;
}
// 获取资源,添加报头
void MakeResponse(string uri)
{
// 顺便设置状态行信息
if (Tool::ReadFileContent(uri, _text))
{
// 获取资源成功
SetCode(200);
}
else
{
// 获取资源失败
SetCode(404);
uri = "./wwwroot/404.html";
Tool::ReadFileContent(uri, _text);
}
// 添加报头
// 正文长度
string filesize = to_string(Tool::FileSize(uri)); // 当以二进制方式读取时,不会存在'\n'没有被读取的情况。
// string filesize = to_string(_text.size()); // 以字符串方式读取,会少读取一部分'\n',与FileSize()的返回值不一致
_headers.insert(make_pair("Content-Length", filesize));
// 正文类型
string Suffic = Tool::Uri2Suffix(uri);
_headers.insert(make_pair("Content-Type", Suffic));
}
void SetCode(int code)
{
// 设置状态码
_code = code;
switch (code)
{
case 200:
_desc = "OK";
break;
case 404:
_desc = "NOT FOUND";
break;
default:
break;
}
}
string text()
{
return _text;
}
public:
std::string _version;
int _code; // 404
std::string _desc; // "Not Found"
string _text; // 资源
unordered_map<std::string, std::string> _headers; // 报头
string _blankline = "\r\n";
};
class HTTP
{
public:
HTTP(uint16_t prot)
: _tsp(make_unique<TcpServer>(prot))
{
}
void HandlerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client)
{
// 接收浏览器发送来的http请求字符串
string str;
sock->Recv(str);
// 反序列化:http字符串
HttpRequest req;
req.Deserialize(str);
// 序列化:将客户端要访问的资源返回
HttpResponse rep;
rep.MakeResponse(req.Uri());
string ret = rep.Serialize();
sock->Send(ret);
}
void Run()
{
_tsp->Start([this](std::shared_ptr<Socket> sock, InetAddr &client)
{ this->HandlerHttpRquest(sock, client); });
}
private:
unique_ptr<TcpServer> _tsp;
};Tool.hpp
cpp
#pragma once
// 工具类
#include <string>
#include <fstream>
const string Separator = "\r\n";
struct Tool
{
// 将资源写入 text
static bool ReadFileContent(std::string uri, std::string &text)
{
// version1:以字符串方式读取
// std::fstream in(uri);
// if (in.is_open())
// {
// std::string str;
// // getline 会自动去掉每一行的换行符 (\n)
// // 这会导致最终发送的信息的数量会少一点
// while (getline(in, str))
// {
// text += str;
// }
// in.close();
// return true;
// }
// return false;
// version2:以二进制方式读取,更好!
// 更兼容照片、视频等资源
std::ifstream in(uri, std::ios::binary); // 以二进制模式打开文件
int filesize = FileSize(uri);
if (filesize < 0)
return false;
if (in.is_open())
{
text.resize(filesize);
in.read(&text[0], filesize);
return true;
}
return false;
}
// 获取请求行
static string ReadOneLine(string &reqstr)
{
int pos = reqstr.find(Separator);
string ret = reqstr.substr(0, pos);
reqstr.erase(0, pos + Separator.size());
return ret;
}
// 获取文件大小
// 该读取方式是不会忽略掉'\n'的
// 当ReadFileContent使用字符串发的方式读取时,其读取上来的大小会与下面得到的大小不一致,导致网页无法加载!
static int FileSize(string filename)
{
std::ifstream in(filename, std::ios::binary); // 以二进制模式打开文件
if (!in.is_open())
return -1;
in.seekg(0, in.end); // 将读取指针直接跳转到文件的最末端
int filesize = in.tellg(); // 获取当前读取指针的位置,既变相的获取文件大小
in.close();
return filesize;
}
// 获取资源后缀,返回对应类型
static std::string Uri2Suffix(const std::string &targetfile)
{
// ./wwwroot/indext.html
auto pos = targetfile.find('.');
if (pos == string::npos)
{
return "text/html";
}
string ret = targetfile.substr(pos);
if (ret == ".html" || ret == ".htm")
{
return "text/html";
}
else if (ret == ".png")
{
return "image/png";
}
else if (ret == ".jpg")
{
return "image/jpg";
}
else if (ret == ".mp4")
{
return "video/mp4";
}
else
{
return "";
}
}
};Main.cc
cpp
#include "HTTP.hpp"
int main(int args, char *argv[])
{
if (args != 2)
{
cout << "Please use: " << argv[0] << " prot";
return 0;
}
int prot = stoi(argv[1]);
unique_ptr<HTTP> up = make_unique<HTTP>(prot);
up->Run();
}代码实现注意要点
代码模拟http协议中,客户端:既浏览器。自己实现服务器端!
实现要点:
http协议的基于Socket的,所以我们可以直接复用之前封装好了的Socket.hpp
一. 实现反序列化:
客户端发送来的请求,需要我们自己来进行反序列化。反序列化后得到:uri(要访问资源的路径!)
判断uri合成可以正确找到资源的路径。当**uri == ``/** (web根目录:wwwroot)时访问默认页面:index.html ,将uri合成为 ./wwwroot/index.html
当**uri != ``/** 时,将uri合成为指定路径 ./wwwroot/uri
二.实现序列化
当我们通过uri地址,找到并获取到了对应资源,要将资源返回给客户端,这样客户端才能够访问到对应的资源。而想要对客户端进行回应,要遵守响应结构。
其中实现过程中注意以下要点:
1.如果请求的资源中不仅包含网页资源,还是包含了图片、视频等资源。那么浏览器将会进行多次请求:第一次请求网页资源、第二次请求图片资源、第三次.....。依次请求请求资源知道请求完毕!
2.在MakeResponse中,对浏览器进行响应时。要添加两个报头:Content-Length ,表示正文长度;Content-Type,表示正文的数据类型(html、png、MP4等)
3.在读取对应资源时,如果使用字符串方式读取不妥!因为无法正确读取:图片、视频等资源。应该使用二进制方式读取!
4.注意读取资源的缓冲区大小,如果太小会导致数据不完整,客户端无法解析!
5.当要访问的资源不存在,应该构建404页面!