Text-to-3D生成,现有方法常常难以将生成内容与人类偏好对齐,限制了其适用性和灵活性。DreamDPO通过直接偏好优化将人类偏好整合进三维生成过程。
实际上,DreamDPO 首先构建两对示例,然后用奖励模型或大型多模模型比较其与人类偏好的对齐情况,最后用偏好驱动的损失函数优化三维表示。通过利用成对比较反映偏好,DreamDPO 减少了对精确点数质量评估的依赖,同时通过偏好引导优化实现细粒度的可控性。实验表明,DreamDPO 在竞争中取得了更高质量、更易控制的 3D 内容
0. 快速导航
- [研究背景:3D 内容生成的痛点](#研究背景:3D 内容生成的痛点)
- [DreamDPO 框架:三步优化流程](#DreamDPO 框架:三步优化流程)
- 算法细节:成对样本构建与偏好引导优化
- [实验结果:超越 SOTA 方法](#实验结果:超越 SOTA 方法)
- 结论与展望
- 代码与数据
1. 研究背景:3D 内容生成的痛点
1.1 3D 内容生成的重要性与挑战
3D 内容生成在产品设计、医学成像、科学可视化以及虚拟现实和增强现实等领域发挥着关键作用。然而,高质量 3D 内容的创建需要大量时间和精力,即使是专业人士也面临挑战。因此,文本到 3D(text-to-3D)生成应运而生,通过从文本描述自动生成 3D 内容,取得了显著进展。但现有方法在与人类偏好对齐方面存在不足,限制了其应用性和灵活性。
1.2 现有方法的局限性
- 依赖奖励模型的精确评分:现有方法通过奖励模型对生成内容进行点质量评估,但这种方法对奖励模型的精确性要求过高,且无法从其他角度提供可控性。
- 缺乏灵活性:由于奖励模型只能提供质量相关评分,缺乏从其他角度控制生成过程的能力,难以满足多样化需求。
2. DreamDPO 框架:三步优化流程
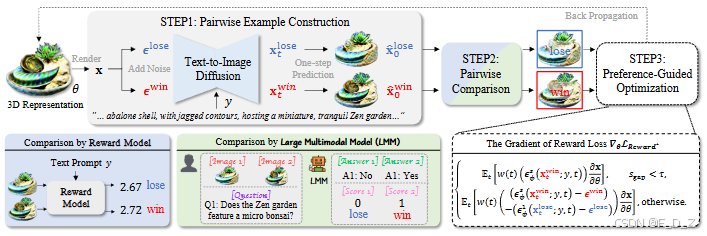
2.1 框架概述
DreamDPO 是一种基于优化的文本到 3D 生成框架,通过直接偏好优化将人类偏好融入 3D 生成过程。其核心在于利用成对比较来反映偏好,减少对精确点质量评估的依赖,同时通过偏好引导优化实现细粒度可控性。具体而言,DreamDPO 包括以下三个关键步骤:
- 成对样本构建:通过在扩散过程中添加不同的高斯噪声,动态生成成对样本。
- 成对样本比较:利用奖励模型或大型多模态模型(LMM)根据与输入文本提示的匹配程度对成对样本进行比较。
- 偏好引导优化:基于成对比较结果计算偏好驱动的损失函数,更新 3D 表示。
2.2 框架优势
- 降低对精确评分的依赖:通过成对比较,DreamDPO 只需区分相对偏好,无需精确评分。
- 增强可控性:通过利用 LMM 提供的偏好,DreamDPO 可以根据具体指令优化生成内容,满足多样化需求。
3. 算法细节:成对样本构建与偏好引导优化
3.1 成对样本构建
给定一个采样的相机姿态,从 3D 表示中渲染出 RGB 图像 x x x。然后在时间步 t t t为 x x x添加两种不同的高斯噪声 ϵ 1 \epsilon_1 ϵ1 和 ϵ 2 \epsilon_2 ϵ2,得到成对的噪声图像 x t 1 x^1_t xt1和 x t 2 x^2_t xt2:
x t 1 = α t x + σ t ϵ 1 , x t 2 = α t x + σ t ϵ 2 x^1_t = \alpha_t x + \sigma_t \epsilon_1, \quad x^2_t = \alpha_t x + \sigma_t \epsilon_2 xt1=αtx+σtϵ1,xt2=αtx+σtϵ2
其中 x 0 = x x_0 = x x0=x, α t \alpha_t αt和 σ t \sigma_t σt 是满足 α 0 ≈ 1 , σ 0 ≈ 0 , α T ≈ 0 , σ T ≈ 1 \alpha_0 \approx 1, \sigma_0 \approx 0, \alpha_T \approx 0, \sigma_T \approx 1 α0≈1,σ0≈0,αT≈0,σT≈1 的超参数。随后,将成对噪声图像输入预训练的文本到图像扩散模型 ϵ ϕ \epsilon_\phi ϵϕ,生成对应的预测:
x ^ 0 1 = x t 1 − 1 − α t ϵ ϕ ( x t 1 ; y , t ) / α t , x ^ 0 2 = x t 2 − 1 − α t ϵ ϕ ( x t 2 ; y , t ) / α t \hat{x}^1_0 = x^1_t - \sqrt{1 - \alpha_t} \epsilon_\phi(x^1_t; y, t) / \sqrt{\alpha_t}, \quad \hat{x}^2_0 = x^2_t - \sqrt{1 - \alpha_t} \epsilon_\phi(x^2_t; y, t) / \sqrt{\alpha_t} x^01=xt1−1−αt ϵϕ(xt1;y,t)/αt ,x^02=xt2−1−αt ϵϕ(xt2;y,t)/αt
3.2 成对样本比较
在每一步 t t t,利用排名模型 r ( ⋅ ) r(\cdot) r(⋅)对 x t 1 x^1_t xt1和 x t 2 x^2_t xt2进行比较,基于它们与输入文本提示的匹配程度,得到更优预测 x t win x^{\text{win}}_t xtwin和较劣预测 x t lose x^{\text{lose}}_t xtlose。
3.3 偏好引导优化
为了将成对比较结果融入优化过程,需要一个可微分的损失函数,使得更优图像损失低,较劣图像损失高。为此,受相关工作启发,我们重新构建 SimPO,消除对参考模型的需求,推导出可微分目标:
L Reward = − E t w ( t ) ( ∥ ϵ win − ϵ ϕ ( x t win ; y , t ) ∥ 2 2 − ∥ ϵ lose − ϵ ϕ ( x t lose ; y , t ) ∥ 2 2 ) L_{\text{Reward}} = -\mathbb{E}_t \left w(t) \\left( \\\|\\epsilon\^{\\text{win}} - \\epsilon_\\phi(x\^{\\text{win}}_t; y, t)\\\|\^2_2 - \\\|\\epsilon\^{\\text{lose}} - \\epsilon_\\phi(x\^{\\text{lose}}_t; y, t)\\\|\^2_2 \\right) \\right LReward=−Etw(t)(∥ϵwin−ϵϕ(xtwin;y,t)∥22−∥ϵlose−ϵϕ(xtlose;y,t)∥22)
其中 ϵ win \epsilon^{\text{win}} ϵwin和 ϵ lose \epsilon^{\text{lose}} ϵlose 分别表示 x t win x^{\text{win}}t xtwin和 x t lose x^{\text{lose}}t xtlose的高斯噪声。直观上, L Reward L{\text{Reward}} LReward鼓励 ϵ ϕ \epsilon\phi ϵϕ将 x t win x^{\text{win}}_t xtwin拉近,将 x t lose x^{\text{lose}}_t xtlose推远。
然而,在实际操作中,直接使用上述梯度可能导致生成结果不理想。经过深入分析优化过程,我们发现成对比较结果可能过于相似,导致分数接近。在这种情况下,直接将 x t lose x^{\text{lose}}t xtlose推远会产生混乱的梯度。为解决这一问题,我们引入分段优化损失,仅在偏好分数差距 s gap s{\text{gap}} sgap 超过阈值 τ \tau τ时才对 x t lose x^{\text{lose}}t xtlose进行优化。最终损失的梯度定义为:
∇ θ L Reward ∗ : = { E t w ( t ) ( ϵ win − ϵ ϕ ( x t win ; y , t ) ) ∂ x ∂ θ , if s gap < τ , E t w ( t ) ( Δ t win − Δ t lose ) ∂ x ∂ θ , otherwise . \nabla\theta L_{\text{Reward}}^* := \begin{cases} \mathbb{E}t \left w(t) \\left( \\epsilon\^{\\text{win}} - \\epsilon_\\phi(x\^{\\text{win}}_t; y, t) \\right) \\frac{\\partial x}{\\partial \\theta} \\right, & \text{if } s{\text{gap}} < \tau, \\ \mathbb{E}_t \left w(t) \\left( \\Delta\^{\\text{win}}_t - \\Delta\^{\\text{lose}}_t \\right) \\frac{\\partial x}{\\partial \\theta} \\right, & \text{otherwise}. \end{cases} ∇θLReward∗:={Etw(t)(ϵwin−ϵϕ(xtwin;y,t))∂θ∂x,Etw(t)(Δtwin−Δtlose)∂θ∂x,if sgap<τ,otherwise.
其中 τ = 0.001 \tau = 0.001 τ=0.001是预定义的阈值, Δ t win = ϵ win − ϵ ϕ ( x t win ; y , t ) \Delta^{\text{win}}t = \epsilon^{\text{win}} - \epsilon\phi(x^{\text{win}}_t; y, t) Δtwin=ϵwin−ϵϕ(xtwin;y,t), Δ t lose = ϵ lose − ϵ ϕ ( x t lose ; y , t ) \Delta^{\text{lose}}t = \epsilon^{\text{lose}} - \epsilon\phi(x^{\text{lose}}t; y, t) Δtlose=ϵlose−ϵϕ(xtlose;y,t)。 s gap = r ( x t win , y ) − r ( x t lose , y ) s{\text{gap}} = r(x^{\text{win}}_t, y) - r(x^{\text{lose}}_t, y) sgap=r(xtwin,y)−r(xtlose,y)表示 x t win x^{\text{win}}_t xtwin和 x t lose x^{\text{lose}}_t xtlose 之间的偏好分数差异。
4. 实验结果:超越 SOTA 方法
4.1 实验设置
- 基线方法:与 13 种现有方法进行对比,包括 DreamFusion、Fantasia3D、Instant3D 等。
- 实现细节:基于 PyTorch 和 threestudio 实现,以 MVDream 为框架。使用 HPSv2 作为默认奖励模型,优化过程在单个 NVIDIA RTX A6000 上耗时约两小时。
4.2 定性比较
基于 GPTEval3D 基准的定性比较。现有方法在文本匹配方面存在困难,如红色标注。DreamDPO 改进文本匹配,从而提供更佳的人类偏好效果。从图可以看出,现有方法在文本对齐方面存在不足,如在描述"一个坐落在宁静雪地森林中的小木屋"时,多数方法遗漏了森林元素或小木屋元素。而 DreamDPO 准确捕捉到了这些关键元素,显著提升了文本对齐效果。

与 MVDream 的对比进一步表明,DreamDPO 在短到长提示中表现良好,提供了更佳的人类偏好效果,生成的 3D 资产在纹理和几何细节上也更为精细。虽然 MVDream 能够生成多视角一致的 3D 素材,但它在处理短提示时表现不佳(例如图 中的第二和第四行):

与 DreamReward 的定性比较显示,DreamDPO 提升了文本匹配(红色标注)和几何/纹理细节。例如第一行文本强调"留下一条花路":

下图展示了DreamDPO 在大型多模态模型(LMM)下的生成结果。探讨了DreamDPO 利用 LMMs(如 QwenVL)在纠正三维资产数量和属性时提供明确指导的潜力。左角显示了使用 LMM 进行的两两比较细节,包括问题和胜负标准。通过精心设计问题,DreamDPO 可以利用胜负案例来指导优化。

4.3 定量比较
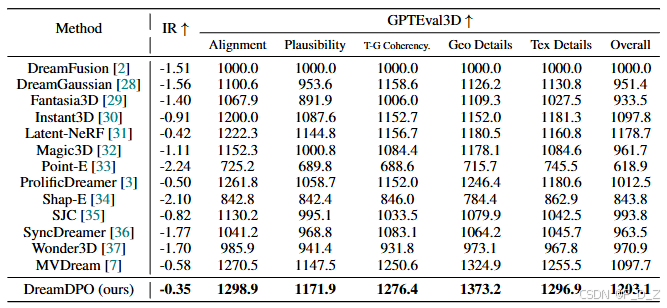
在 ImageReward (IR)评估中,DreamDPO 的人类偏好评分优于多数现有方法。在 GPTEval3D 全面三维质量综合评估中,DreamDPO 优于以往最先进的(SOTA)方法,并在所有指标中排名第一。具体来说,DreamDPO 在文本-资产对齐度(+28.4)、三维可信度(+24.4)、文本-几何对齐度(+25.8)、纹理细节(+48.4)、几何细节(+41.4)和整体性能(+24.4)方面取得了提升。它展示了该方法在增强文本和几何细节同时保持三维一致性方面的优越性。具体表现为:
5. 结论与展望
DreamDPO 作为一种基于优化的 3D 生成方法,通过直接偏好优化将人类偏好融入生成过程,显著提升了生成 3D 资产与输入文本的对齐效果,同时增强了纹理和几何质量。实验结果表明,DreamDPO 在输出质量和可控性方面均超越了现有 SOTA 方法。未来的研究方向可能包括:
- 增强生成模型:通过引入图像提示以提供更详细的上下文,可以通过提供更详细的生成上下文来提升与用户期望的契合度。
- 提高成对比较的鲁棒性:探索无需提示设计的方法,如利用目标检测模型或定位模型进行数量和属性校正,或使用扩散模型本身作为成对比较模型,以提高生成和比较的一致性。
6. 代码与数据
- 开源代码 :https://github.com/DreamDPO/DreamDPO
- 数据集下载 :https://huggingface.co/datasets/DreamDPO/GPTEval3D
- 预训练权重:支持多种骨干网络,单卡 RTX A6000 推理。