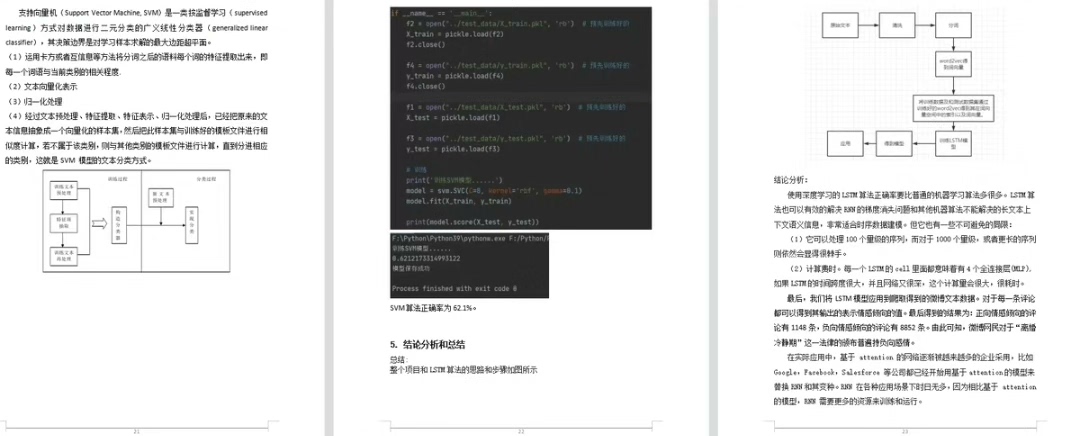
大数据分析项目python--微博文本情感分析 研究思路:基于情感词典基于机器学习LSTM算法支持向量机(SVM) 包含内容:数据集文档代码

在大数据时代,文本数据如同蕴藏丰富信息的宝藏,微博作为海量文本数据的来源之一,对其进行情感分析能挖掘出大众的情绪倾向、意见态度等有价值的信息。今天就来聊聊用 Python 实现微博文本情感分析的大数据分析项目,研究思路主要基于情感词典,同时结合机器学习中的 LSTM 算法与支持向量机(SVM)。
数据集准备
首先得有合适的数据集,通常我们可以从公开的数据平台获取微博文本数据。假设获取到的数据集格式如下:
| 微博文本 | 情感标签(0:负面,1:正面) |
|---|---|
| "今天心情好差,诸事不顺" | 0 |
| "哇塞,今天中大奖啦,超开心" | 1 |
我们可以使用 Python 的 pandas 库来处理这种表格数据,代码如下:
python
import pandas as pd
data = pd.read_csv('weibo_data.csv')
texts = data['微博文本'].tolist()
labels = data['情感标签'].tolist()上述代码通过 pandas 的 read_csv 方法读取存储微博数据的 CSV 文件,然后将文本和标签分别提取成列表,方便后续处理。
基于情感词典的分析
情感词典是一系列带有情感倾向(积极或消极)的词汇集合。利用情感词典分析微博文本情感的核心思路是统计文本中积极词汇和消极词汇的数量,进而判断整体情感倾向。

以哈工大停用词表和情感词典为例,先下载对应的词典文件,然后编写如下代码:
python
# 读取停用词表
stopwords = []
with open('hit_stopwords.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
stopwords.append(line.strip())
# 读取情感词典
positive_words = []
negative_words = []
with open('positive_emotion_words.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
positive_words.append(line.strip())
with open('negative_emotion_words.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
negative_words.append(line.strip())
def sentiment_analysis_by_dict(text):
words = text.split()
positive_count = 0
negative_count = 0
for word in words:
if word not in stopwords:
if word in positive_words:
positive_count += 1
elif word in negative_words:
negative_count += 1
if positive_count > negative_count:
return 1
elif positive_count < negative_count:
return 0
else:
return -1 # 表示情感倾向不明显在这个代码片段中,我们先读取停用词表和情感词典,然后定义了一个函数 sentimentanalysisby_dict。该函数将输入的微博文本进行分词,去除停用词后,统计积极和消极词汇的数量,最后根据数量对比返回情感标签。
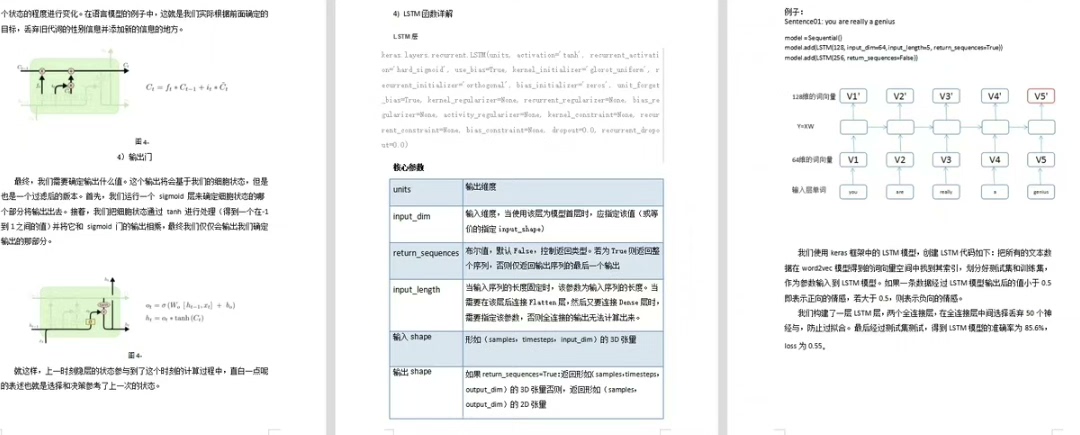
基于 LSTM 算法的情感分析
LSTM(长短期记忆网络)是一种特殊的循环神经网络(RNN),擅长处理序列数据,非常适合文本情感分析。

首先导入所需的库:
python
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
import numpy as np接着对文本数据进行预处理:
python
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
maxlen = 100
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.array(labels)这里使用 Tokenizer 将文本转换为数字序列,并通过 pad_sequences 方法将序列长度统一为 maxlen。

然后构建 LSTM 模型:
python
model = Sequential()
model.add(Embedding(1000, 128, input_length=maxlen))
model.add(LSTM(128))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(data, labels, epochs=10, batch_size=32)上述代码构建了一个简单的 LSTM 模型,包含一个嵌入层、一个 LSTM 层和一个全连接输出层。使用 adam 优化器和 binary_crossentropy 损失函数进行编译,并对模型进行训练。
基于支持向量机(SVM)的情感分析
SVM 是一种强大的二分类算法,在文本分类任务中也表现出色。

先对文本进行特征提取,这里使用词袋模型(Bag of Words):
python
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
y = np.array(labels)然后使用 SVM 进行分类:
python
from sklearn.svm import SVC
svm = SVC(kernel='linear')
svm.fit(X, y)以上代码通过 CountVectorizer 将文本转换为词袋特征矩阵,再使用线性核的 SVM 模型进行训练。
总结
通过以上基于情感词典、LSTM 算法和 SVM 的方法,我们可以有效地对微博文本进行情感分析。每种方法都有其优缺点,情感词典方法简单直观但依赖词典质量;LSTM 能自动学习文本特征但训练成本较高;SVM 在小数据集上可能表现较好且训练速度相对较快。在实际项目中,可以根据具体需求和数据特点选择合适的方法,或者结合多种方法以获得更好的效果。希望大家能从这个大数据分析项目中对 Python 在文本情感分析中的应用有更深入的理解和实践经验。