第1课:爬虫与广告反欺诈入门
引言:数字世界的"阴影"与技术之光
想象一下,你精心策划的线上推广活动,投入了大量广告预算,却发现大部分点击和展示来自"机器人"或虚假账户,最终转化率惨不忍睹;或者,作为普通用户,你被无休止的诱导性、骚扰性甚至诈骗性广告所困扰。这些现象的背后,正是日益猖獗的"广告欺诈"。广告欺诈不仅让广告主蒙受巨大经济损失,更严重损害了用户体验,甚至破坏了整个数字广告生态的健康发展。
根据《2021年移动广告反欺诈白皮书》的数据,2021年广告主因移动广告欺诈造成的损失高达220亿元人民币,较2020年增加了22%。Juniper Research在2017年估计,广告欺诈每年消耗190亿美元,预计到2022年将达到440亿美元。这些触目惊心的数据告诉我们,广告欺诈已成为仅次于贩毒的第二大有组织犯罪类型。
面对这样的"阴影",我们并非束手无策。作为技术人,我们拥有强大的工具------网络爬虫和机器学习,它们是揭露欺诈、守护数字诚信的利器。本专栏将一步步引导你,从数据采集到智能识别,最终构建起一套能够有效识别并屏蔽恶意广告的系统。
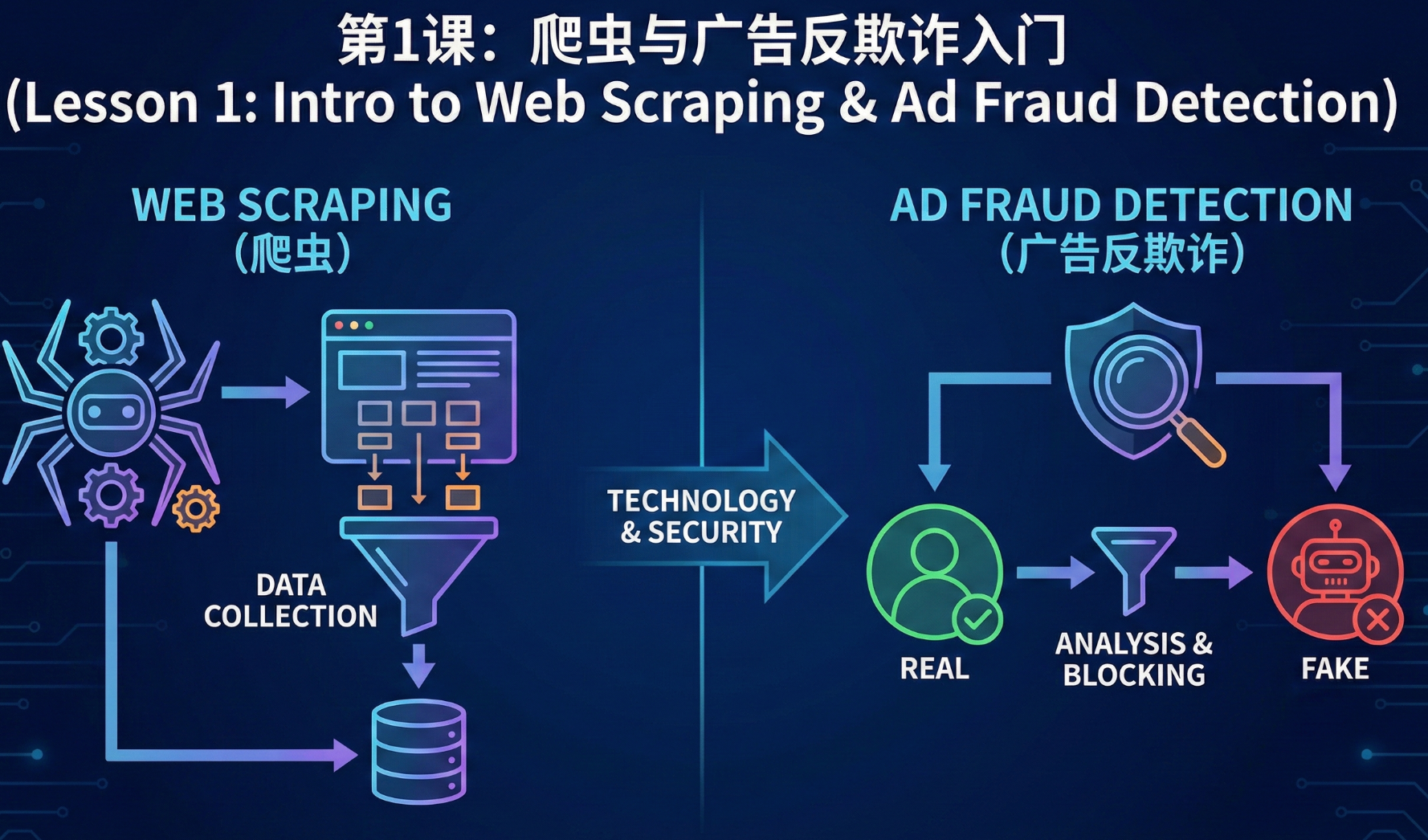
核心知识点
1. 什么是网络爬虫?你的数据获取"小助手"
网络爬虫(Web Crawler),又被称为网页蜘蛛(Web Spider)、网络机器人(Web Robot),是一种按照预设规则,自动地在互联网上抓取大量信息的程序或脚本。你可以把互联网想象成一张巨大的蜘蛛网,而爬虫就像是在这张网上爬行的蜘蛛,它的任务就是访问网页、获取数据。
网络爬虫的基本原理
网络爬虫的工作原理可以概括为以下几个核心步骤:
- 发起请求(Request):爬虫会向目标网站的服务器发送HTTP或HTTPS请求,就像你在浏览器地址栏输入网址并按下回车一样。这个请求包含了你想要访问的页面信息。
- 获取响应(Response):服务器接收到请求后,会返回一个响应,通常是HTML、CSS、JavaScript代码,或者是图片、视频等二进制数据。
- 解析内容(Parse):爬虫接收到响应后,会对其进行解析。如果获取的是HTML页面,爬虫会利用解析库(如BeautifulSoup、lxml等)从中提取出所需的数据,比如文本、图片链接、其他网页的链接等。
- 数据提取与存储(Extract & Store):从解析后的内容中,爬虫会按照预设的规则提取出我们感兴趣的数据,并将其存储到本地文件(如CSV、JSON)或数据库中。
- 循环与深入(Loop & Deepen):在提取数据的同时,爬虫还会发现页面中包含的其他URL链接。它会将这些新链接加入待抓取队列,然后重复上述步骤,不断深入到更多的页面,直到满足停止条件或无法获取新的URL地址为止。
一个简化的网络爬虫工作流程图:
发送HTTP请求 成功获取 提取数据 发现新URL 否 是 设定起始URL 请求URL 获取网页响应 解析网页内容 存储数据 将新URL加入待抓取队列 判断是否满足停止条件 结束
网络爬虫的应用场景
网络爬虫的应用非常广泛,包括:
- 搜索引擎:百度、Google等搜索引擎的核心就是通过爬虫抓取全网信息,构建庞大的索引库。
- 数据分析:企业可以通过爬虫获取市场竞品数据、用户评论、行业报告等,进行商业决策。
- 舆情监控:爬取社交媒体、新闻网站内容,实时了解公众对某一事件或品牌的看法。
- 票务监控:监控火车票、机票、演出票的余量和价格变化。
- 当然,还有我们今天要重点关注的------广告反欺诈中的数据采集!
2. 广告欺诈,你可能没意识到的"隐形盗贼"
广告欺诈(Ad Fraud),也被称为无效流量(Invalid Traffic),指的是通过制造虚假的在线广告曝光(Impression)、点击(Clicks)、转化率(Conversion)或事件(Data event)等指标来获取非法收入的行为。简单来说,就是有人通过不正当手段,骗取广告主为无效的广告行为付费。
广告欺诈的危害性
广告欺诈对广告主、用户和整个行业都造成了巨大的危害:
- 广告主经济损失:这是最直接的危害。广告主支付了高昂的广告费,却只获得了虚假流量和无效数据,导致投资回报率(ROI)直线下降,甚至血本无归。
- 用户体验受损:恶意广告通常伴随着弹窗、重定向、诱导点击等行为,严重干扰用户正常浏览,甚至可能包含病毒、木马,对用户设备造成损害或窃取个人信息。
- 行业生态破坏:欺诈行为扰乱了正常的市场竞争秩序,劣币驱逐良币,使得那些提供真实流量和优质内容的媒体平台难以生存,降低了整个数字广告行业的透明度和信任度。
常见的广告欺诈类型
广告欺诈的形式多种多样,且随着技术发展不断演变,以下是一些主要的类型:
- 点击欺诈(Click Fraud):这是最常见的形式之一,欺诈者通过机器人(Bot)或"点击农场"(Click Farm,即雇佣大量低薪工人进行虚假点击)模拟用户点击广告,以消耗广告主的按点击付费(PPC)预算。
- 曝光欺诈(Impression Fraud):欺诈者通过各种手段制造虚假的广告展示次数,例如将广告放置在用户看不到的像素大小的区域、堆叠多个广告或利用机器人批量访问页面。
- 安装欺诈(Install Fraud):特别是在移动应用领域,欺诈者通过设备农场(Device Farm)或恶意软件伪造应用安装数据,骗取广告主的按安装付费(CPI)费用。
- 僵尸网络(Botnet):攻击者利用被感染的设备组成僵尸网络,这些设备在用户不知情的情况下,自动进行大量的虚假点击、展示和安装,模拟真实用户行为,使其更难被发现。
- 归因劫持(Attribution Hijacking):当真实用户下载应用时,欺诈者通过提前发送虚假点击,窃取该下载的归因,从而获取本应属于合法渠道的佣金。
- 广告注入(Ad Injection):恶意浏览器扩展或恶意软件未经许可,在用户浏览网页时替换或注入其他广告,从而劫持合法广告主的流量。
为什么要识别广告欺诈?
识别广告欺诈至关重要,它不仅能帮助广告主止损,更在于提升广告投放的真实效果,维护健康的互联网广告生态。通过有效的反欺诈机制,我们可以:
- 保护广告预算:确保每一分钱都花在真实的、有价值的流量上。
- 优化投放策略:基于真实数据分析广告效果,制定更精准的营销策略。
- 提升用户体验:减少恶意广告对用户的骚扰,建立用户对广告的信任。
- 维护行业秩序:打击黑灰产,促进行业的良性发展。
3. 本专栏将带你走向何方?我们的学习路径
本专栏旨在为零基础的读者提供一套系统化的学习路径,从掌握基础技术到实战应用,最终让你能够独立构建恶意广告识别与屏蔽系统。我们的目标是:利用网络爬虫技术采集广告数据,结合机器学习算法识别恶意广告行为,并最终实现自动化的广告反欺诈能力。
以下是我们将要探索的学习路径概览:
- 阶段一:网络爬虫基础与进阶(数据采集篇)
- 课程内容 :我们将从Python语言基础开始,逐步深入到HTTP/HTTPS协议、网页结构(HTML/CSS/JavaScript)。学习如何使用
requests库发送请求,BeautifulSoup和lxml解析HTML,以及Selenium处理动态网页。 - 目标:掌握各种数据采集技术,能够从不同类型的广告平台、网站或应用中高效、稳定地获取广告的展示数据、点击数据、落地页内容、用户行为数据等。
- 课程内容 :我们将从Python语言基础开始,逐步深入到HTTP/HTTPS协议、网页结构(HTML/CSS/JavaScript)。学习如何使用
- 阶段二:数据清洗与特征工程(数据预处理篇)
- 课程内容:爬取到的原始数据往往是杂乱无章的,我们需要学习如何进行数据清洗(去重、缺失值处理、格式统一),并从中提取出有用的特征(如IP地址、设备指纹、点击频率、用户行为序列等),为机器学习模型的训练做好准备。
- 目标:将原始数据转化为高质量、可用于机器学习的结构化特征。
- 阶段三:机器学习模型选择与训练(智能识别篇)
- 课程内容:介绍机器学习的基本概念,包括监督学习、无监督学习。我们将学习常见的分类算法(如逻辑回归、决策树、随机森林、XGBoost、神经网络)和异常检测算法,并实际操作如何选择、训练、评估和优化模型,以识别出广告欺诈行为。
- 目标:构建准确、高效的机器学习模型,对广告流量进行实时或离线欺诈识别。
- 阶段四:系统集成与部署(实战应用篇)
- 课程内容:学习如何将爬虫模块、数据处理模块和机器学习预测模块整合到一个完整的反欺诈系统中。可能涉及API接口开发、数据库设计、消息队列、实时处理框架等。
- 目标:开发一个可实际运行的恶意广告识别与屏蔽系统,能够自动化地发现并处理欺诈广告。
- 阶段五:挑战与未来(持续对抗篇)
- 课程内容:探讨广告反欺诈领域的最新技术和面临的挑战(如黑灰产技术升级、隐私法规限制),以及如何持续优化和迭代反欺诈系统。
- 目标:形成对广告反欺诈更深层次的理解,为未来的技术发展做好准备。
代码/案例演示:你的第一个Python爬虫
为了让你对网络爬虫有一个直观的感受,我们来写一个最简单的Python爬虫程序,它将访问一个网站,并打印出该网页的标题。
首先,你需要安装requests库。在你的终端或命令提示符中运行:
pip install requests
然后,是我们的第一个爬虫代码:
python
import requests # 导入requests库,用于发送HTTP请求
def simple_crawler(url):
"""
一个简单的网络爬虫函数,用于获取指定URL网页的标题。
Args:
url (str): 目标网页的URL。
Returns:
str: 网页的标题,如果获取失败则返回None。
"""
try:
# 1. 发起请求:向目标URL发送GET请求
print(f"正在请求:{url}")
response = requests.get(url, timeout=5) # 设置超时时间为5秒
response.raise_for_status() # 检查HTTP请求是否成功(状态码200),如果不成功则抛出异常
# 2. 获取响应:响应内容通常包含在response.text中
# 实际的网页标题在HTML的<title>标签中,这里我们为了简化,直接假设网页内容包含可识别的标题
# 更复杂的解析需要BeautifulSoup或lxml,我们后续课程会详细讲解。
# 3. 解析内容与提取:这里我们模拟一个非常简单的提取过程,寻找<title>标签
# 注意:这是一个非常简化的处理,实际HTML解析会使用库
title_start_index = response.text.find('<title>')
title_end_index = response.text.find('</title>')
if title_start_index != -1 and title_end_index != -1:
title = response.text[title_start_index + len('<title>'):title_end_index]
return title.strip() # 移除首尾空白字符
else:
return "未找到标题"
except requests.exceptions.RequestException as e:
# 处理请求过程中可能发生的各种异常,例如网络连接问题、DNS解析失败、超时等
print(f"请求发生错误:{e}")
return None
except Exception as e:
# 处理其他未知异常
print(f"发生未知错误:{e}")
return None
if __name__ == "__main__":
# 我们以一个知名的技术博客网站为例
target_url = "https://www.csdn.net/"
page_title = simple_crawler(target_url)
if page_title:
print(f"网页标题是:{page_title}")
else:
print(f"无法获取 {target_url} 的标题。")
print("\n----------------------------------\n")
# 尝试一个可能不存在的URL,演示错误处理
error_url = "https://www.nonexistentwebsite12345.com/"
print(f"尝试请求一个不存在的URL: {error_url}")
error_page_title = simple_crawler(error_url)
if not error_page_title:
print(f"成功捕获到 {error_url} 的请求异常。")代码解析:
import requests:导入Python中用于发送HTTP请求的requests库,它简化了HTTP操作。requests.get(url, timeout=5):向指定url发送一个GET请求。timeout=5表示如果5秒内没有收到服务器响应,就停止等待并抛出异常。response.raise_for_status():这是requests库提供的一个便捷方法,如果HTTP响应状态码不是200(表示成功),它会自动抛出一个HTTPError异常,帮助我们快速发现请求失败的情况。response.text:获取服务器返回的响应内容,通常是HTML页面的文本。response.text.find('<title>'):这是一个字符串方法,用于查找<title>标签在HTML文本中第一次出现的位置。我们通过这种简单方式来模拟提取网页标题。在后续课程中,我们将学习更健壮的HTML解析方法。try...except:这是一个非常重要的错误处理机制。网络爬虫在运行时可能会遇到各种问题,如网络连接中断、目标网站宕机、URL错误等。try块中的代码是可能发生错误的部分,而except块则用于捕获并处理这些错误,防止程序崩溃。
运行这段代码,你将看到它成功获取并打印出CSDN网站的标题。当你尝试访问一个不存在的URL时,它也能优雅地处理错误。这只是爬虫世界的冰山一角,但在接下来的课程中,我们将在此基础上构建更强大、更智能的系统!
总结:迈出反欺诈的第一步
恭喜你,完成了本专栏的第一节课!今天我们学习了:
- 网络爬虫:你的数据获取小助手,了解了它的基本原理和广泛应用。
- 广告欺诈:这个数字世界的"隐形盗贼"带来了巨大的危害,我们认识了它的各种常见类型以及识别它的重要性。
- 学习路径:我们展望了整个专栏的学习旅程,从爬虫到机器学习,再到系统构建,让你对即将学习的内容有了清晰的认识。
在本节课的最后,你还亲手运行了第一个Python爬虫,迈出了实践的第一步。是不是觉得技术的世界充满了无限可能?
在下一节课中,我们将深入探讨Python爬虫的更多细节,包括HTTP协议、更强大的HTML解析技术以及如何处理反爬机制。敬请期待!