现象
第1步:创建 FastAPI 服务器 (main.py)
我们将创建一个 FastAPI 应用,包含三个接口:
-
/fast: 一个立即返回的接口,用来测试服务器是否"活着"。
-
/slow-sync: 一个使用 time.sleep() 模拟同步阻塞操作的接口。这是问题的关键。
-
/slow-async: 一个使用 asyncio.sleep() 模拟异步非阻塞等待的接口。用来做对比。
python
import time
import asyncio
from fastapi import FastAPI
import uvicorn
app = FastAPI()
@app.get("/fast")
async def get_fast():
"""一个快速响应的接口"""
return {"message": "I am fast!"}
@app.get("/slow-sync")
async def get_slow_sync():
"""
使用 time.sleep() 模拟一个同步的、CPU密集型或阻塞I/O的任务。
这会阻塞整个事件循环。
"""
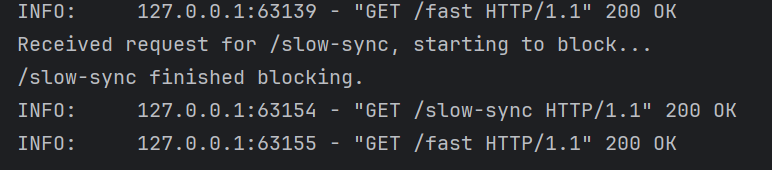
print("Received request for /slow-sync, starting to block...")
time.sleep(5) # 致命的阻塞!
print("/slow-sync finished blocking.")
return {"message": "I am slow and synchronous, I blocked everyone."}
@app.get("/slow-async")
async def get_slow_async():
"""
使用 asyncio.sleep() 模拟一个异步的、非阻塞的I/O等待。
这不会阻塞事件循环,服务器可以处理其他请求。
"""
print("Received request for /slow-async, starting non-blocking wait...")
await asyncio.sleep(5) # 非阻塞等待
print("/slow-async finished waiting.")
return {"message": "I am slow but asynchronous, I did not block anyone."}
if __name__ == "__main__":
uvicorn.run("main:app", host="127.0.0.1", port=8000, reload=True)第2步:启动服务器 和 进行测试并观察现象
在终端运行下面命令,启动应用:
bash
python main.py实验A:证明同步阻塞问题
打开两个新的终端窗口:
1.在第一个终端,立即访问 /slow-sync 接口。这个请求将需要5秒才能完成。你会看到这个终端卡住了,等待响应。
bash
Measure-Command {curl http://localhost:8000/slow-sync}
或
time curl http://localhost:8000/slow-sync2.在它卡住的这5秒内 ,立即切换到第二个终端,访问 /fast 接口。
bash
Measure-Command {curl http://localhost:8000/fast}
或
time curl http://localhost:8000/fast你会观察到以下现象:
两个终端:
应用服务:
-
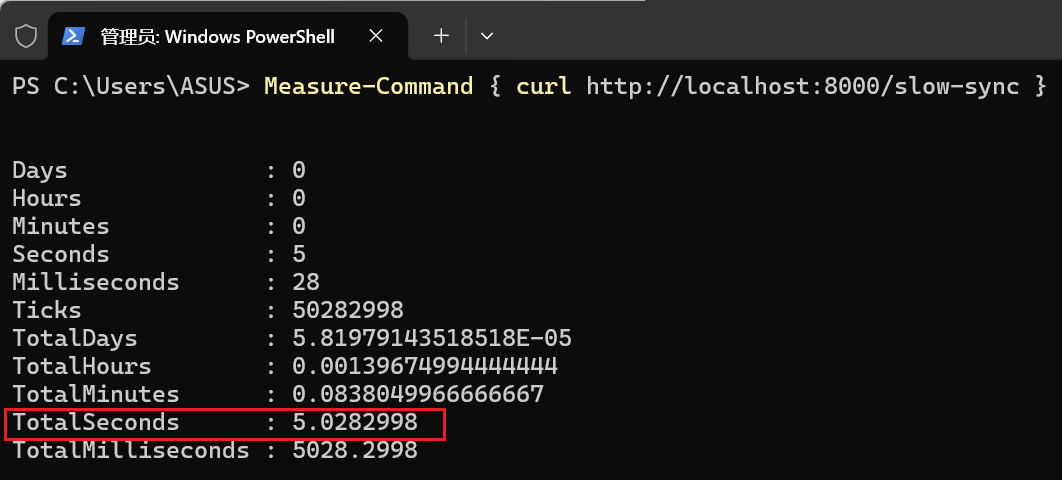
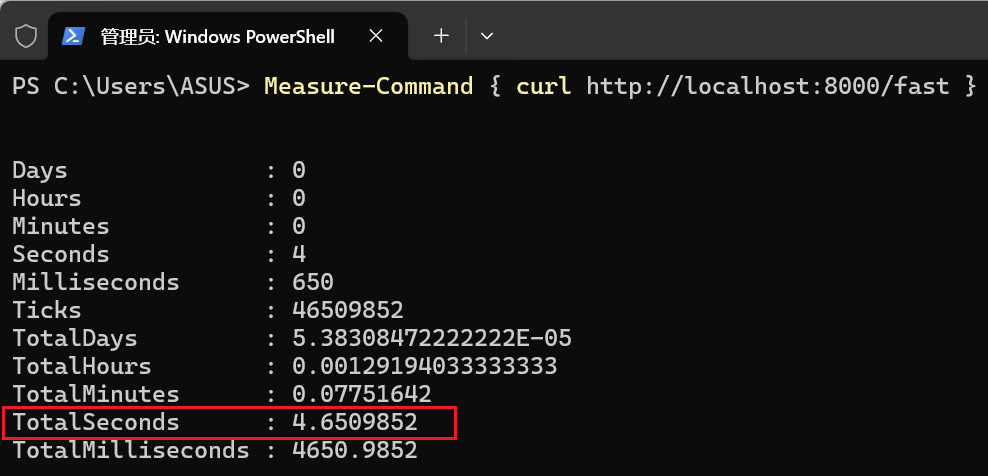
终端1 的 curl 命令会在大约 5 秒后完成,并打印出 /slow-sync 的响应。
-
终端2 的 curl 命令并不会立即返回!它也会被卡住,直到终端1的请求完成后,它才能被服务器处理,然后几乎立刻返回。它的总耗时也会接近 5 秒!
实验B:对比异步非阻塞行为
现在我们用 /slow-async 重复这个实验。
1.在第一个终端,立即访问 /slow-async 接口。
bash
Measure-Command {curl http://localhost:8000/slow-async}
或
time curl http://localhost:8000/slow-async2.在它等待的5秒内 ,立即切换到第二个终端,访问 /fast 接口。
bash
Measure-Command {curl http://localhost:8000/fast}
或
time curl http://localhost:8000/fast你会观察到以下现象:
两个终端:
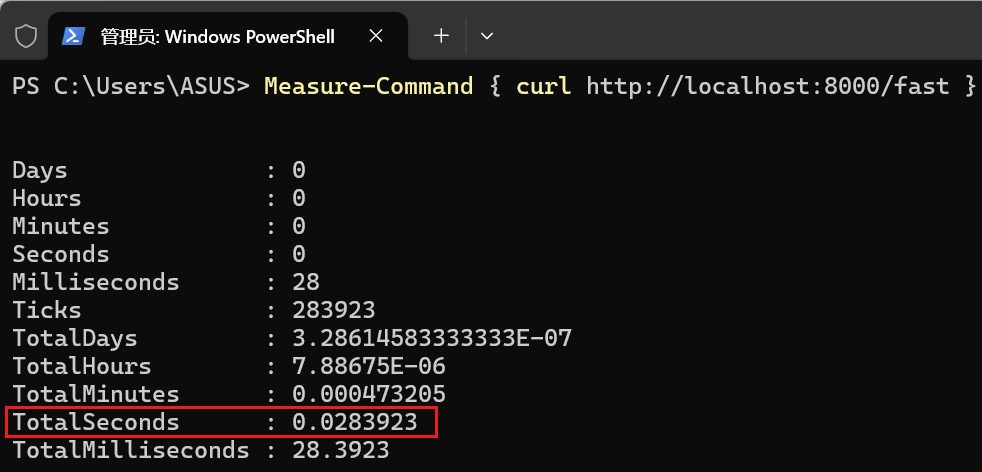
应用服务:

-
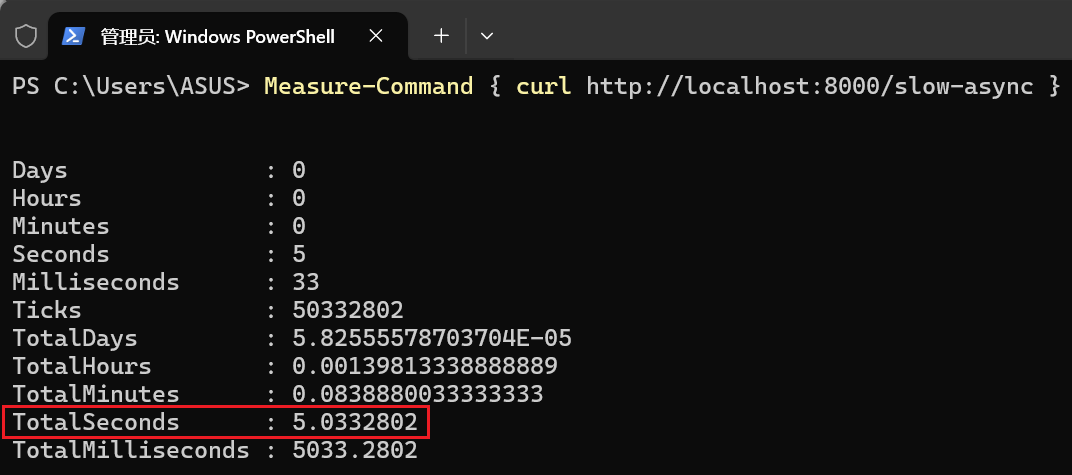
终端1 的 curl 命令仍然需要约 5 秒才能完成。
-
终端2 的 curl 命令几乎是瞬间完成的!它的总耗时远小于1秒。
结论:
这就是典型的 FastAPI 单进程阻塞问题。其根本原因在于,默认配置下的 Uvicorn 服务器只启动了一个工作进程,而这个进程依赖一个单线程的事件循环以异步协程的方式来处理所有请求。
所以,当一个请求触发了同步阻塞操作时,它会霸占整个事件循环,导致前一个请求没有处理结束,后续的所有新请求都只能排队等待,整个服务陷入"假死"状态。
这个问题的核心是**"同步阻塞"破坏了"异步协同"**的模式。事件循环就像一个忙碌但合作的调度员,只有当每个任务(请求处理)都遵守规则,在需要等待时(如I/O操作)通过 await 主动让出控制权,它才能高效地在多个任务间切换。而同步阻塞操作(如 time.sleep() 或一个耗时的 CPU 计算)则像一个不守规矩的霸道任务,它拿到了控制权就不放手,直到自己完成为止,导致调度员无法服务其他任何人。
可能有时候可以通过代码上的注意,来避免这个问题,但是针对响应是一个耗时任务时,这种阻塞就是必然发生的问题。该怎么处理呢?
解决方法
方法一:
水平扩展,通过运行多个独立的 Web Worker 进程来隔离阻塞的影响。
将main.py文件中的uvicorn.run的代码由
python
uvicorn.run("main:app", host="127.0.0.1", port=8000, reload=True)改为,应该去掉 reload=True,并添加 workers 参数来设置并发的数量
python
uvicorn.run("main:app", host="127.0.0.1", port=8000, workers=4)为什么 reload 和 workers 不兼容?
-
reload=True 的工作原理: Uvicorn 会启动一个特殊的监控进程。这个监控进程负责观察你的代码文件是否有变动。当文件变动时,它会停止当前正在运行的那个单个 worker 进程,然后重新启动一个新的 worker 进程来加载新代码。
-
workers > 1 的工作原理: Uvicorn 会启动一个主进程,由这个主进程来生成和管理多个子 worker 进程。
-
冲突点: 这两种模式都依赖于一个"父进程"来管理"子进程",它们的管理逻辑是完全不同的,无法共存。因此,你必须二选一。
其中,Uvicorn 官方文档推荐在生产中使用 Gunicorn 这样的专业进程管理器。让Gunicorn 就能管理 FastAPI 应用,需要安装一个gunicorn新包,对应的命令如下:
bash
gunicorn -w 4 -k uvicorn.workers.UvicornWorker main:app局限性:
-
没有解决根本问题。当并发的阻塞请求数等于 Worker 数时,整个应用依然会饱和并停止响应。
-
进程间状态不共享(需要引入其他机制或方法实现共享),相对而言,内存消耗较大,利用率不高。
方法二:
将计算任务从 Web Worker 进程卸载到本地的计算进程池中,实现真正的并行计算。
python
import time
import os
import asyncio
from concurrent.futures import ProcessPoolExecutor
from fastapi import FastAPI
def cpu_bound_task(number: int) -> int:
"""
一个模拟 CPU 密集型任务的函数。
它将在一个独立的进程中运行。
"""
# 打印当前进程的 ID,以证明它和主 Web 服务器进程不同
print(f"Executing in Process ID: {os.getpid()}")
total = sum(i for i in range(number))
time.sleep(5) # 模拟一个耗时5秒的计算
print(f"Process {os.getpid()} finished computation.")
return total
# 创建 FastAPI 应用实例
app = FastAPI()
# 应用启动时执行的事件
@app.on_event("startup")
def startup_event():
# 创建一个进程池,并将其存储在 app.state 中,以便在整个应用中访问
# max_workers 默认是 CPU 核心数,通常无需指定
app.state.process_pool = ProcessPoolExecutor()
print(f"Main App Process ID: {os.getpid()}. Process Pool created.")
# 应用关闭时执行的事件
@app.on_event("shutdown")
def shutdown_event():
# 优雅地关闭进程池
app.state.process_pool.shutdown(wait=True)
print("Process Pool shut down.")
@app.get("/fast")
async def get_fast():
"""一个应该总是能立即响应的接口"""
return {"message": "I am fast and responsive!"}
@app.get("/compute/{number}")
async def compute(number: int):
"""
将 CPU 密集型任务卸载到进程池的接口
"""
# 1. 获取当前正在运行的 asyncio 事件循环
loop = asyncio.get_running_loop()
# 2. 从 app.state 中获取我们创建的进程池
pool = app.state.process_pool
# 3. 使用 loop.run_in_executor() 将任务提交到进程池
# - 第一个参数是执行器 (我们的进程池)
# - 第二个参数是要执行的函数 (cpu_bound_task)
# - 后续是传递给该函数的参数 (number)
# 这个调用会立即返回一个 future 对象,然后我们 await 它
print(f"Submitting task for number {number} to process pool...")
result = await loop.run_in_executor(
pool, cpu_bound_task, number
)
return {"number": number, "sum": result}
if __name__ == "__main__":
uvicorn.run("main:app", host="127.0.0.1", port=8080, reload=True)局限性:
-
进程创建和通信有开销,数据在进程间传递需要序列化。
-
计算资源和 Web 资源仍在同一台机器上,相互竞争。
方法三:
将计算任务作为消息发送到消息中间件 (如 Redis),由独立的计算 Worker 在后台异步处理,实现完全解耦。
接口端:
fastapi中的接口,通过和redis的异步连接发生特定请求,并订阅任务的结果:
python
from app.sessions_manger.async_redis_pool import AsyncRedisManager
from fastapi import WebSocket, WebSocketDisconnect, APIRouter
from app.services.worker import celery_app # 导入 celery 实例用来发送任务
import uuid
# 创建 APIRouter 实例
router = APIRouter()
# 获取 Redis 异步客户端 ------ 单例模式
redis_pool = AsyncRedisManager() # 通过get_client调用获取连接,用完会自动回收
@router.websocket("/ws/calculate")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
# 1. 生成唯一的频道 ID (Channel ID)
# 这就像给这次计算开了一个专属的"直播间"
task_id = str(uuid.uuid4())
channel_id = task_id
try:
# 2. 告诉 Celery 开始干活
# 使用 delay() 异步发送任务,不会阻塞
# 我们把 channel_id 传给 worker,让它知道往哪里发消息
celery_app.send_task("heavy_task", args=[channel_id, 100], task_id=task_id)
await websocket.send_text(f"任务已提交 ID: {task_id},等待计算...")
# 3. 订阅 Redis 频道 (监听直播间)
r = redis_pool.get_client()
pubsub = r.pubsub()
await pubsub.subscribe(channel_id)
# 4. 循环监听 Redis 消息并转发给 WebSocket
# 这个循环是异步的,async for 会在没消息时挂起,不占 CPU
async for message in pubsub.listen():
# listen() 会收到订阅成功的消息,我们要过滤掉,只看 data 消息
if message["type"] == "message":
data = message["data"]
# 收到结束信号
if data == "DONE":
await websocket.send_text("计算完成!")
break
# 实时转发数据
await websocket.send_text(data)
except WebSocketDisconnect:
print("用户断开了连接")
# 这里执行终止逻辑
# terminate=True 会发送 SIGTERM 信号给 worker 进程
# celery_app.control.revoke(task_id, terminate=True)
# 如果任务特别顽固(死循环),可以使用更暴力的 SIGKILL:
celery_app.control.revoke(task_id, terminate=True, signal='SIGKILL')
except Exception as e:
await websocket.send_text(f"Error: {str(e)}")
finally:
# 清理资源
if 'pubsub' in locals():
await pubsub.unsubscribe(channel_id)
if 'r' in locals():
await r.close()任务端:
基于celery的分布式任务管理工具,从redis中获取相应任务来执行。任务中通过和redis的同步连接,实时发布订阅结果,方便实时给接口端提供数据。
针对任务急剧上升的场景,可以实现在不同不服务器上运行celery,和同一个redis通信,实现分布式。
python
import time
from celery import Celery
import redis
# 1. 配置 Celery
# broker: 任务队列存哪里
# backend: 任务最终结果存哪里
celery_app = Celery(
"worker",
broker="redis://localhost:6379/0",
backend="redis://localhost:6379/1"
)
# 2. 建立一个同步的 Redis 连接,用于发布(Publish)实时进度
# 注意:这里不需要 async,因为 Celery worker 本身通常是同步运行的
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0, decode_responses=True)
@celery_app.task(name="heavy_task")
def heavy_task(channel_id: str, complexity: int):
"""
channel_id: 用作 Redis Pub/Sub 的频道名,通常用 task_id 或 session_id
complexity: 模拟计算复杂度
"""
print(f"开始处理任务,频道: {channel_id}")
for i in range(1, complexity + 1):
# --- 模拟密集计算 (CPU 密集) ---
# 实际场景可能是复杂的矩阵运算、AI推理等
time.sleep(1)
result = i * i
# --- 关键步骤:通过 Redis 发布实时消息 ---
message = f"进度: {i}/{complexity} | 当前结果: {result}"
redis_client.publish(channel_id, message)
# --- 发送结束信号 ---
# 告诉 FastAPI 我们可以关闭 WebSocket 了
redis_client.publish(channel_id, "DONE")
return "Task Complete"注意,celery代码需要通过下面命令单独启动。
bash
# -A tasks 指定了 Celery 实例在 tasks.py 文件中
# worker 是启动 worker 进程
# --loglevel=info 是日志级别
celery -A tasks.celery_app worker --loglevel=info局限性:
- 架构最复杂,需要引入和维护额外的组件。