环境需求:
- 服务器:AutoDL
- PyTorch 2.1.0
- Python 3.10 (Ubuntu 22.04)
- Cuda 12.1
- 4090(24GB)
1. 下载llamafactory
- 创建虚拟环境
bash
conda create -n llamafactory python=3.10 -y
conda activate llamafactory - 下载到数据盘
bash
cd ./autodl-tmp/
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .- 将数据集拷贝至:
/root/autodl-tmp/LLaMA-Factory/data,煮饱这里自己准备了名称为llamafactory_style_data的数据集
并将data_info.json中添加数据集:
bash
# 这里使用相对路径就可以了
"llamafactory_style_data": {
"file_name": "llamafactory_style_data.json"
},2. 模型微调
- 下载模型,没有vpn的同学可以使用魔塔社区:魔塔社区模型库
有vpn的同学可以使用huggingface:huggingface模型库
这里演示选择了qwen1.5-4B-Chat模型
python
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen1.5-4B-Chat',cache_dir="/root/autodl-tmp/models")- 启动 Web UI:
bash
cd LLaMA-Factory
llamafactory-cli webui- 模型微调,需要调整的参数:
- 模型名称:Qwen1.5-4B-Chat
- 模型路径:/root/autodl-tmp/models/Qwen/Qwen1.5-4B-Chat
- 量化等级:8(可不开,缩小模型加速训练的)
- 训练轮次:300(建议给大点,反正能随时停)
- 最大样本数:1000
- 截断长度:512(我的文本没那么大,这个看自己情况)
- batch_size:12(看自己cpu,别cuda out of memory就行)
- 验证集比例:0.02(也是看个人)
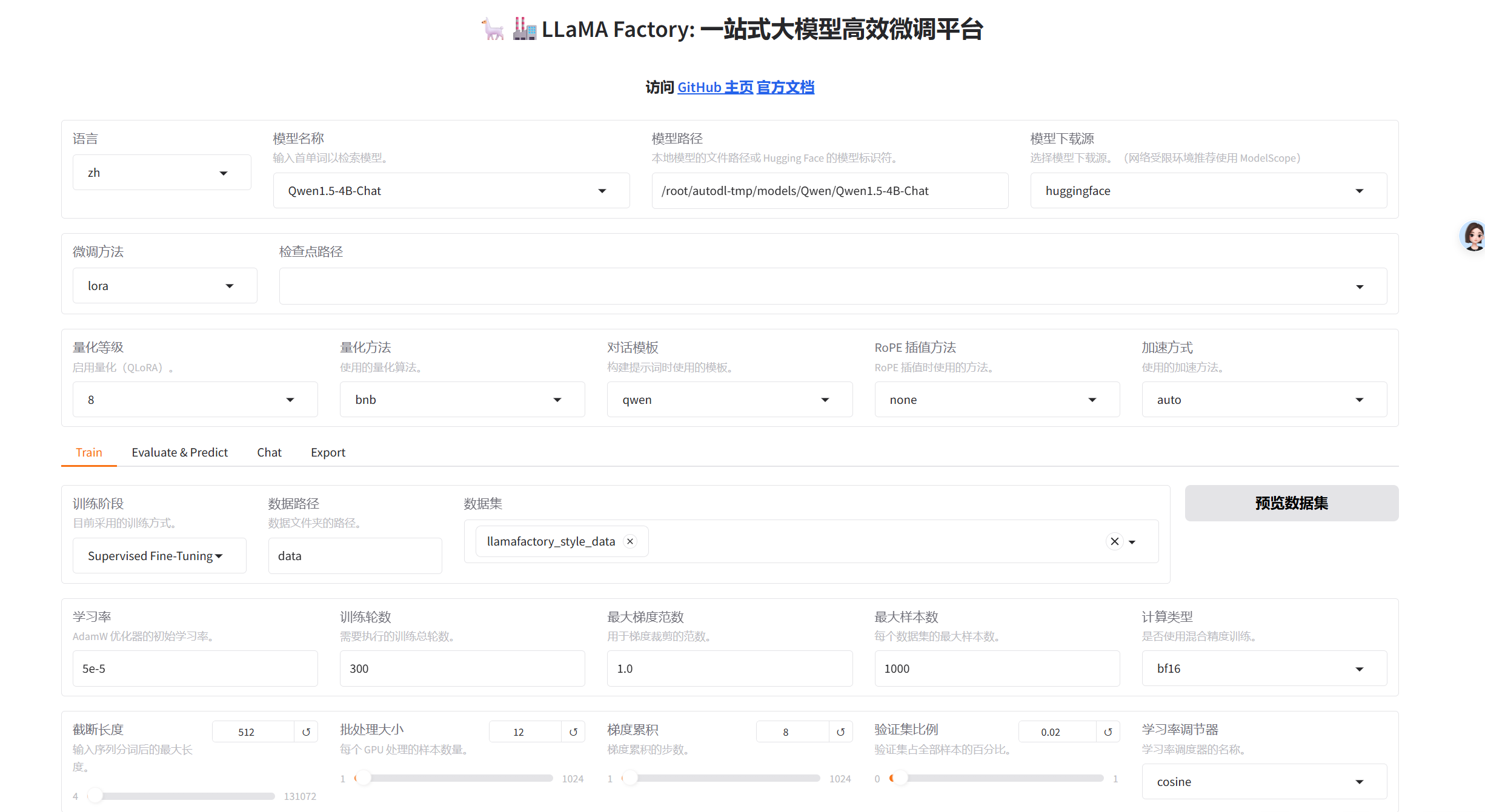
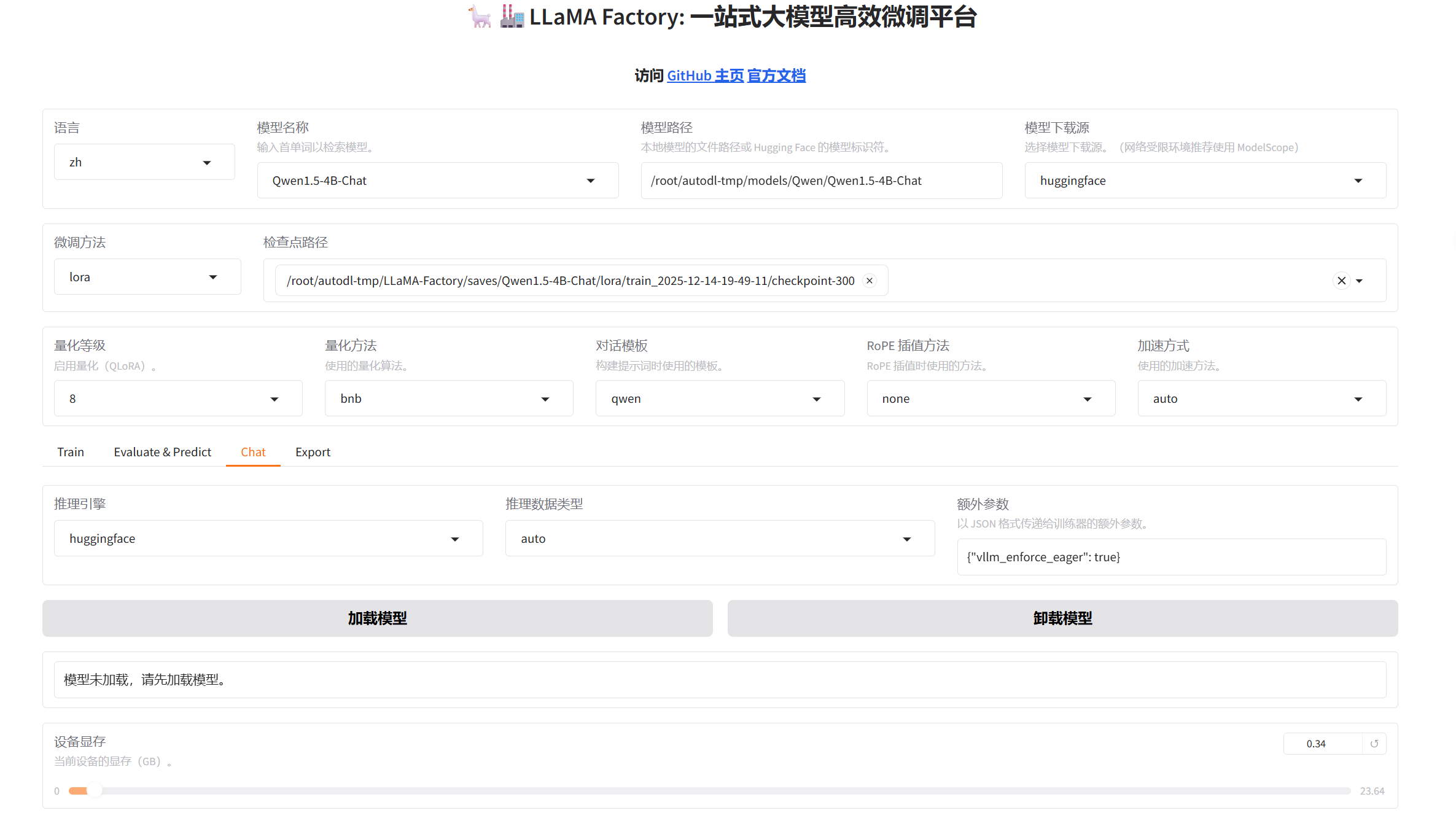
- 模型对话:
选择刚训练出的权重/root/autodl-tmp/LLaMA-Factory/saves/Qwen1.5-4B-Chat/lora/train_2025-12-14-19-49-11/checkpoint-300,放在检查路径,推理模型选择huggingface
(注:如果推理模型选择vllm,需要和llamafactory装在同一虚拟环境中,并且指定vllm==0.11.0 )
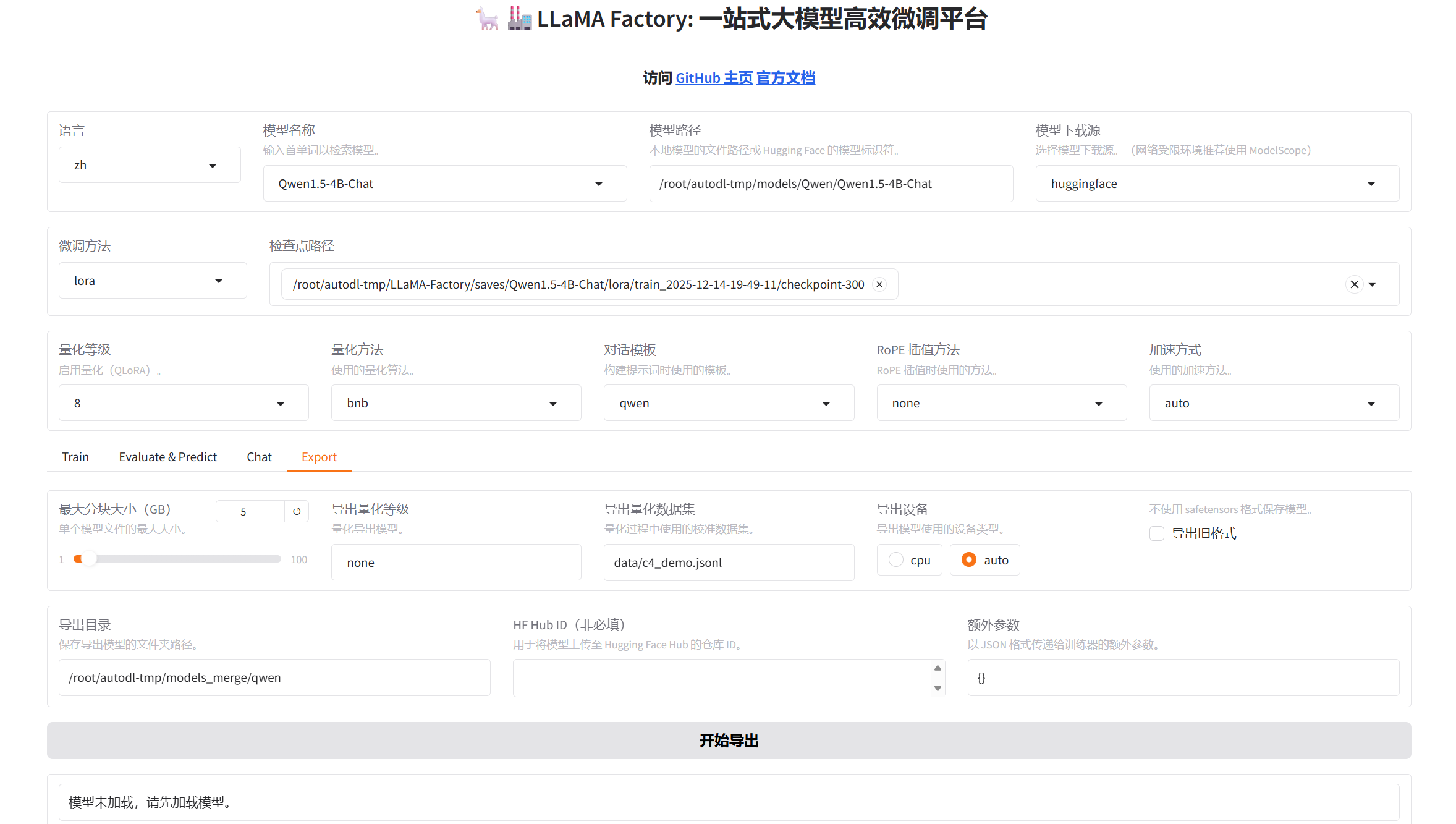
- 模型导出
自创导出目录/root/autodl-tmp/models_merge/qwen,导出设备选择auto可以加快导出
3. vllm部署
- 下载vllm
bash
pip install vllm==0.11.0- 部署,这里很容易出现显存不足的情况,本质是vllm在启动时会预分配显存用于 KV Cache(键值缓存),导致启动失败,此时最佳解决方案就是稍微调小最大序列长度
bash
# vllm默认端口为 8000
vllm serve /root/autodl-tmp/models_merge/qwen --max-model-len 32000
- 写一个app.py进行验证
(注意:response中的model需要指定你merge后的模型绝对路径,不然在使用streamlit对话框时会报错:
Error code: 404 - {'error': {'message': 'The model Qwen1___5-1___8B-Chatdoes not exist.', 'type': 'NotFoundError', 'param': None, 'code': 404}})
python
import streamlit as st
from openai import OpenAI
st.set_page_config(page_title="VLLM Chat Demo", page_icon="🤖")
st.title("VLLM Chat Demo")
# 初始化 OpenAI 客户端连接到 VLLM
@st.cache_resource
def init_client():
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed" # VLLM 通常不需要 API 密钥
)
return client
# 初始化 VLLM 客户端
if "client" not in st.session_state:
st.session_state.client = init_client()
# 初始化聊天历史
if "messages" not in st.session_state:
st.session_state.messages = [{"role": "assistant", "content": "你好,我是AI助手,有什么我可以帮助你的吗?"}]
# 显示聊天历史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# 清空聊天历史函数
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是AI助手,有什么我可以帮助你的吗?"}]
# 侧边栏清空按钮
st.sidebar.button('清空聊天历史', on_click=clear_chat_history)
# 生成回复函数
def generate_response(prompt_input):
try:
# 构建消息历史
messages = st.session_state.messages.copy()
# 调用 VLLM API
response = st.session_state.client.chat.completions.create(
model="/root/autodl-tmp/models_merge/qwen", # 模型名称,应与 VLLM 启动时的名称一致
messages=messages,
temperature=0.7,
max_tokens=512,
stream=False # 设置为 True 可以启用流式输出
)
return response.choices[0].message.content
except Exception as e:
return f"请求出错: {str(e)}"
# 处理用户输入
if prompt := st.chat_input("请输入您的问题:"):
# 添加用户消息到历史
st.session_state.messages.append({"role": "user", "content": prompt})
# 显示用户消息
with st.chat_message("user"):
st.write(prompt)
# 生成并显示助手回复
with st.chat_message("assistant"):
with st.spinner("正在思考..."):
response = generate_response(prompt)
st.write(response)
# 添加助手回复到历史
st.session_state.messages.append({"role": "assistant", "content": response})
# 侧边栏信息
st.sidebar.markdown("### 配置信息")
st.sidebar.info(f"模型: Qwen1.5-4B-Chat")
st.sidebar.info(f"API端点: http://localhost:8000/v1")- 验证微调效果:
bash
streamlit run ./app.pystreamlit默认端口为http://localhost:8501/
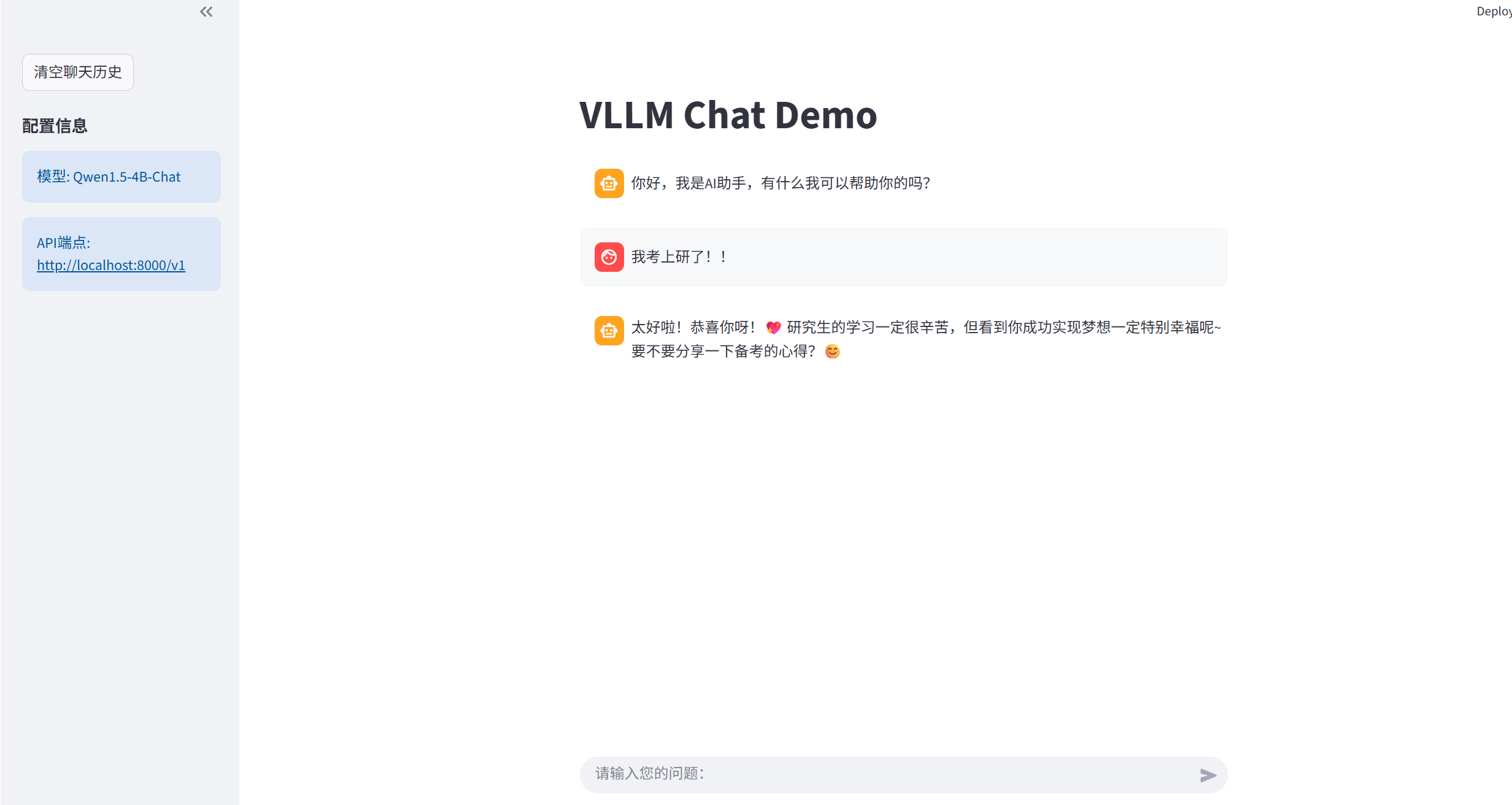
貌似效果一般。。。训练的时候可以多训练两轮!