
目录
[一、进程优先级:CPU 资源分配的 "交通规则"](#一、进程优先级:CPU 资源分配的 “交通规则”)
[1.1 为什么需要进程优先级?](#1.1 为什么需要进程优先级?)
[1.2 查看进程优先级:从命令行读懂进程 "身份等级"](#1.2 查看进程优先级:从命令行读懂进程 “身份等级”)
[1.2.1 使用ps -l查看进程优先级详情](#1.2.1 使用ps -l查看进程优先级详情)
[1.2.2 使用ps aux查看系统所有进程优先级](#1.2.2 使用ps aux查看系统所有进程优先级)
[1.3 PRI 与 NI:优先级的 "核心参数" 解析](#1.3 PRI 与 NI:优先级的 “核心参数” 解析)
[1.3.1 核心公式:PRI (new) = PRI (old) + NI](#1.3.1 核心公式:PRI (new) = PRI (old) + NI)
[1.3.2 PRI 与 NI 的核心区别](#1.3.2 PRI 与 NI 的核心区别)
[1.4 补充概念:进程的竞争、独立、并行与并发](#1.4 补充概念:进程的竞争、独立、并行与并发)
[1.4.1 竞争性](#1.4.1 竞争性)
[1.4.2 独立性](#1.4.2 独立性)
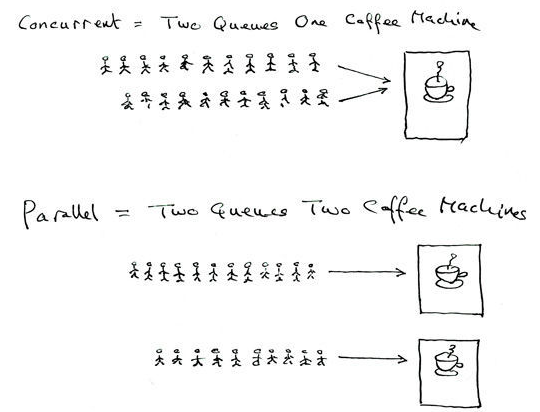
[1.4.3 并行(Parallel)](#1.4.3 并行(Parallel))
[1.4.4 并发(Concurrent)](#1.4.4 并发(Concurrent))
[2.1 查看进程优先级的常用命令](#2.1 查看进程优先级的常用命令)
[2.1.1 使用top命令实时查看优先级](#2.1.1 使用top命令实时查看优先级)
[2.1.2 使用ps -eo自定义查看优先级字段](#2.1.2 使用ps -eo自定义查看优先级字段)
[2.2 修改已运行进程的优先级:top命令](#2.2 修改已运行进程的优先级:top命令)
[2.3 创建进程时指定优先级:nice命令](#2.3 创建进程时指定优先级:nice命令)
[2.4 修改已运行进程的优先级:renice命令](#2.4 修改已运行进程的优先级:renice命令)
[2.5 系统调用接口:getpriority与setpriority](#2.5 系统调用接口:getpriority与setpriority)
[三、进程切换:CPU 上下文的 "快速接力"](#三、进程切换:CPU 上下文的 “快速接力”)
[3.1 进程切换的本质:CPU 上下文的保存与恢复](#3.1 进程切换的本质:CPU 上下文的保存与恢复)
[3.2 进程切换的触发条件](#3.2 进程切换的触发条件)
[3.3 进程切换的开销](#3.3 进程切换的开销)
[四、Linux 2.6 内核 O (1) 调度算法:常数时间调度的奥秘](#四、Linux 2.6 内核 O (1) 调度算法:常数时间调度的奥秘)
[4.1 O (1) 调度算法的核心数据结构:runqueue](#4.1 O (1) 调度算法的核心数据结构:runqueue)
[4.2 双队列设计:活跃队列与过期队列](#4.2 双队列设计:活跃队列与过期队列)
[4.3 优先级分组:queue 数组与 bitmap 位图](#4.3 优先级分组:queue 数组与 bitmap 位图)
[4.3.1 queue 数组:按优先级存储进程](#4.3.1 queue 数组:按优先级存储进程)
[4.3.2 bitmap 位图:快速查找非空队列](#4.3.2 bitmap 位图:快速查找非空队列)
[4.4 O (1) 调度算法的完整流程](#4.4 O (1) 调度算法的完整流程)
[步骤 1:初始化 runqueue](#步骤 1:初始化 runqueue)
[步骤 2:进程加入就绪队列](#步骤 2:进程加入就绪队列)
[步骤 3:选择下一个要执行的进程](#步骤 3:选择下一个要执行的进程)
[步骤 4:进程时间片耗尽](#步骤 4:进程时间片耗尽)
[步骤 5:队列切换](#步骤 5:队列切换)
[步骤 6:进程退出或阻塞](#步骤 6:进程退出或阻塞)
[4.5 O (1) 调度算法的优势与局限性](#4.5 O (1) 调度算法的优势与局限性)
[4.5.1 核心优势:常数时间调度](#4.5.1 核心优势:常数时间调度)
[4.5.2 局限性与后续优化](#4.5.2 局限性与后续优化)
前言
在 Linux 系统中,当数百个进程同时争抢 CPU 资源时,为何有些进程能 "插队" 优先执行?进程切换时 CPU 如何记住上一个任务的执行状态?Linux 2.6 内核的 O (1) 调度算法为何能实现常数时间调度?本文将从进程优先级的核心概念出发,逐步拆解优先级调整机制、进程切换原理,深入剖析 Linux 2.6 内核经典的 O (1) 调度队列架构,结合实战命令带你看透 Linux 进程调度的底层逻辑。下面就让我们正式开始吧!
一、进程优先级:CPU 资源分配的 "交通规则"
1.1 为什么需要进程优先级?
在 Linux 系统中,进程的数量往往远多于 CPU 核心数 ------ 哪怕是普通的个人电脑,后台运行的进程也可能多达数十个。而 CPU 作为核心计算资源,同一时间只能处理有限的任务(单核 CPU 同一时刻仅能运行一个进程)。这就像高速公路上的车辆远超车道数量,必须有一套 "交通规则" 来决定谁先通行,这套规则就是进程优先级。
进程优先级的核心作用的是解决资源竞争问题:通过为不同进程分配不同的优先级,让关键进程(如系统服务、实时任务)优先获得 CPU 时间,确保系统稳定性和响应速度;而普通进程(如后台下载、日志分析)则在空闲时获得资源,避免占用过多系统资源影响整体性能。
举个生活中的例子:操作系统就像一家餐厅的调度员,CPU 是厨师。高优先级进程是 VIP 客户的加急订单,必须优先处理;普通优先级进程是普通顾客的订单,按顺序排队;低优先级进程则是可以延后制作的外卖订单,在厨师空闲时再处理。没有优先级机制,餐厅可能会因为先处理大量普通订单,导致 VIP 客户等待过久,甚至系统服务(如点餐系统)响应迟缓。
1.2 查看进程优先级:从命令行读懂进程 "身份等级"
要理解进程优先级,首先要学会通过命令行查看相关参数。Linux 提供了ps和top等工具,能直观展示进程的优先级信息。
1.2.1 使用ps -l查看进程优先级详情
在终端输入ps -l命令,会输出当前终端相关进程的详细信息,其中与优先级相关的核心字段有PRI和NI:
典型输出如下:
 各字段含义解析:
各字段含义解析:
- PID:进程的唯一标识符,相当于进程的 "身份证号";
- PPID:父进程 ID,标识该进程由哪个进程创建;
- PRI:Process Priority(进程优先级),数值越小,优先级越高,进程越先被 CPU 执行;
- NI:Nice 值(优先级修正值),用于调整进程的实际优先级;
- C:进程占用 CPU 的百分比;
- CMD:进程对应的命令名称。
从输出可以看到,bash和ps进程的默认PRI都是 80,NI都是 0,这是 Linux 系统中普通进程的默认优先级配置。
1.2.2 使用ps aux查看系统所有进程优先级
如果想查看系统中所有进程的优先级(包括其他用户的进程、后台守护进程),可以使用ps aux命令,结合grep过滤特定进程:
bash
# 查看系统中所有进程的优先级,过滤包含"nginx"的进程
ps aux | grep nginx输出示例:
root 123 0.0 0.1 4500 1200 ? Ss 08:00 0:00 nginx: master process /usr/sbin/nginx
www-data 124 0.0 0.2 4700 2400 ? S 08:00 0:01 nginx: worker process
www-data 125 0.0 0.2 4700 2380 ? S 08:00 0:00 nginx: worker process其中,S和Ss是进程状态(睡眠状态),而优先级信息虽未直接显示PRI和NI,但可以通过后续命令进一步查看。
1.3 PRI 与 NI:优先级的 "核心参数" 解析
1.3.1 核心公式:PRI (new) = PRI (old) + NI
在 Linux 中,进程的实际执行优先级由PRI(静态优先级)和NI(Nice 值)共同决定,核心关系为:
PRI(new) = PRI(old) + NI
- PRI(静态优先级):进程的基础优先级,默认值为 80(普通进程),数值越小优先级越高;
- NI(Nice 值) :优先级修正值,取值范围是
-20到19(共 40 个级别),用于调整进程的实际优先级。
举个例子:
- 若一个进程的默认
PRI=80,NI=0,则实际优先级PRI(new)=80+0=80;- 若将
NI调整为-5,则实际优先级PRI(new)=80+(-5)=75,优先级提升;- 若将
NI调整为10,则实际优先级PRI(new)=80+10=90,优先级降低。
这里需要注意:NI的取值范围是固定的(-20~19),这意味着普通进程的PRI范围是60(80-20)到99(80+19)。而实时进程的优先级范围是0~99(高于普通进程的最高优先级 60),但实时进程通常用于特殊场景(如工业控制、音频处理),本文重点讨论普通进程的优先级机制。
1.3.2 PRI 与 NI 的核心区别
很多初学者会混淆PRI和NI,其实二者的本质区别可以总结为:
- PRI 是 "结果":是进程最终用于参与 CPU 调度的优先级数值,直接决定了进程的调度顺序;
- NI 是 "手段" :是用户或系统用来调整
PRI的工具,通过修改NI可以间接改变PRI。
打个比方:PRI就像学生的 "最终考试成绩",NI就像 "加分项 / 减分项"。学生的最终成绩 = 基础成绩(默认 PRI=80)+ 加分项(NI 为负)/ 减分项(NI 为正),最终成绩决定了学生的排名(调度顺序)。
另外需要强调:NI值不能直接改变PRI的本质属性 ------ 它只是 "修正值",而不是优先级本身。例如,不能通过设置NI=-30来让普通进程的PRI低于 60,因为NI的最小值被限制在 - 20,这是 Linux 内核为了防止普通进程抢占实时进程资源而做的限制。
1.4 补充概念:进程的竞争、独立、并行与并发
理解进程优先级的同时,还需要掌握四个核心概念,它们是进程调度的基础:
1.4.1 竞争性
系统中进程数量远多于 CPU 资源,进程之间为了获取 CPU、内存等资源必然存在竞争关系。优先级机制就是为了让竞争更有序 ------ 通过为进程分配不同的优先级,确保关键资源优先分配给重要进程。
例如:系统中的sshd(SSH 服务)进程优先级高于普通的bash进程,这样即使系统负载较高,用户也能正常通过 SSH 登录服务器,而不会因为bash进程占用过多 CPU 导致登录超时。
1.4.2 独立性
多进程运行时,各自独享系统资源(如虚拟地址空间、文件描述符),运行期间互不干扰。一个进程的崩溃不会影响其他进程的正常运行,这是操作系统稳定性的核心保障。
例如:浏览器进程崩溃后,终端进程、编辑器进程依然能正常工作,这就是进程独立性的体现。而进程的独立性,也为优先级调度提供了基础 ------ 每个进程可以独立设置优先级,不会因为其他进程的优先级调整而受到影响。
1.4.3 并行(Parallel)
多个进程在多个 CPU 核心上同时运行,这是真正意义上的 "同时执行"。例如:在 4 核 CPU 的服务器上,同时运行 4 个进程,每个进程占用一个 CPU 核心,这 4 个进程就是并行执行的。
并行的核心是**"多 CPU + 同时执行"**,此时进程之间不存在 CPU 资源的竞争(每个进程独占一个核心),但仍可能竞争内存、磁盘等其他资源。
1.4.4 并发(Concurrent)
多个进程在一个 CPU 核心上,通过 "进程切换" 的方式,在一段时间内轮流执行,让多个进程都能得到推进。例如:在单核 CPU 的电脑上,同时打开浏览器、编辑器、终端,这些进程通过 CPU 快速切换,让用户感觉它们在同时运行,这就是并发。
并发的核心是**"单 CPU + 切换执行"**,此时进程之间的 CPU 竞争最为激烈,优先级机制的作用也最为明显 ------ 高优先级进程会获得更多的 CPU 时间片,执行效率更高。
用一个形象的比喻理解并行与并发:
- 并行:就像多个厨师同时烹饪多个订单,每个厨师(CPU 核心)专注一个订单(进程);
- 并发:就像一个厨师同时处理多个订单,通过快速切换(炒完一道菜的一部分,再炒另一道菜),让所有订单都在推进。
而优先级,就是厨师判断哪个订单需要优先处理的依据 ------VIP 订单(高优先级进程)会被厨师优先翻炒,普通订单(低优先级进程)则在空闲时处理。
二、进程优先级调整实战:命令行操作指南
Linux 提供了多种方式调整进程优先级,包括创建进程时指定优先级、修改已运行进程的优先级,下面结合实战命令详细讲解。
2.1 查看进程优先级的常用命令
2.1.1 使用top命令实时查看优先级
top命令是 Linux 系统中查看进程状态的核心工具,能实时显示进程的PRI、NI值,以及 CPU、内存占用情况:
bash
# 运行top命令,实时查看进程状态
top在top界面中,核心字段解析:
- PR :即
PRI(静态优先级);- NI:即 Nice 值;
- %CPU:进程占用 CPU 的百分比;
- %MEM:进程占用内存的百分比;
- PID:进程 ID;
- COMMAND:进程对应的命令。
在top界面中,按P键可以按 CPU 占用率排序(默认排序方式),按N键按 PID 排序,按M键按内存占用率排序,方便快速定位高优先级或高资源占用的进程。
2.1.2 使用ps -eo自定义查看优先级字段
如果想自定义查看进程的特定字段(如 PID、PRI、NI、命令),可以使用ps -eo命令,指定需要显示的字段:
bash
# 查看进程的PID、PRI、NI、COMMAND字段,按PRI升序排序(优先级越高越靠前)
ps -eo pid,pri,ni,cmd --sort=pri输出示例:
PID PRI NI CMD
1 60 -20 /sbin/init splash
123 70 -10 /usr/sbin/sshd -D
456 80 0 /bin/bash
789 90 10 /usr/bin/dd if=/dev/zero of=/tmp/test bs=1M count=1000从输出可以看到:
init进程(PID=1)的PRI=60,NI=-20,是系统中优先级最高的普通进程;sshd进程(PID=123)的PRI=70,NI=-10,优先级次之;bash进程(PID=456)的PRI=80,NI=0,是默认优先级;dd进程(PID=789)的PRI=90,NI=10,优先级最低。
2.2 修改已运行进程的优先级:top命令
使用top命令可以直接修改已运行进程的NI值,进而调整其PRI,操作步骤如下:
bash
# 1. 运行top命令
top
# 2. 在top界面中,按"r"键(rename priority),进入优先级修改模式
# 3. 输入需要修改的进程PID(例如修改PID=789的dd进程)
# 4. 输入新的NI值(例如输入5,注意NI的范围是-20~19)
# 5. 按回车确认,修改完成修改完成后,可以在top界面中看到该进程的NI值已更新,PRI值也会随之变化(PRI=new=PRI=old+NI=new)。
注意事项:
- 普通用户只能将
NI值调整为0~19(即降低进程优先级或保持默认),不能设置负数(提升优先级);- 只有 root 用户(或具有
sudo权限的用户)才能将NI值调整为-20~19(可以提升或降低优先级);- 如果输入的
NI值超出范围(如 - 25 或 20),系统会自动调整为最接近的合法值(-20 或 19)。
2.3 创建进程时指定优先级:nice命令
nice命令用于在创建新进程时指定其NI值,从而设置初始优先级。语法格式如下:
bash
# nice [选项] [NI值] 命令
nice -n NI值 命令示例 1:创建一个低优先级的dd进程(用于测试磁盘写入),设置NI=19(最低优先级):
bash
# 以NI=19的优先级运行dd命令,避免占用过多CPU资源
nice -n 19 dd if=/dev/zero of=/tmp/test bs=1M count=1000示例 2:root 用户创建一个高优先级的wget进程(用于下载文件),设置NI=-10(提升优先级):
bash
# 以NI=-10的优先级运行wget命令,加快下载速度
sudo nice -n -10 wget https://example.com/large_file.iso创建后,可以通过ps -eo pid,pri,ni,cmd --sort=pri命令验证NI值是否生效。
2.4 修改已运行进程的优先级:renice命令
renice命令与top命令的优先级修改功能类似,但可以直接在命令行中执行,无需进入交互界面,语法格式如下:
bash
# renice [NI值] -p 进程PID
renice NI值 -p PID示例 1:将 PID=789 的dd进程的NI值修改为 10:
bash
# 修改PID=789的进程优先级,NI=10
renice 10 -p 789示例 2:root 用户将 PID=456 的bash进程的NI值修改为 - 5:
bash
# root用户提升进程优先级,NI=-5
sudo renice -5 -p 456执行后,系统会输出修改结果:
456 (process ID) old priority 0, new priority -5注意事项:
- renice命令的权限限制与
top命令一致:普通用户只能提高NI值(降低优先级),root 用户可以任意调整;- 可以同时修改多个进程的优先级,只需在
-p后跟上多个 PID,例如:sudo renice -5 -p 456 789。
2.5 系统调用接口:getpriority与setpriority
除了命令行工具,Linux 还提供了系统调用函数getpriority和setpriority,用于在 C/C++ 程序中获取和设置进程优先级。虽然本文要求代码为 bash,但可以通过awk等工具间接调用(或参考其底层逻辑)。
核心函数原型:
cpp
#include <sys/resource.h>
// 获取进程优先级
int getpriority(int which, int who);
// 设置进程优先级
int setpriority(int which, int who, int prio);在 bash 中,可以通过awk调用系统函数(示例仅供参考,实际开发中更常用 C 语言):
bash
# 使用awk调用getpriority获取PID=1的进程优先级
awk 'BEGIN{
printf("PID=1的优先级:%d\n", getpriority(PRIO_PROCESS, 1));
}'输出示例:
PID=1的优先级:60这与我们之前通过ps命令查看的init进程优先级一致(PRI=60)。
三、进程切换:CPU 上下文的 "快速接力"
当多个进程在 CPU 上并发执行时,Linux 内核需要频繁地在不同进程之间切换 ------ 暂停当前进程的执行,保存其状态,然后加载下一个进程的状态并继续执行。这个过程就是进程切换(也称为上下文切换,Context Switch)。
3.1 进程切换的本质:CPU 上下文的保存与恢复
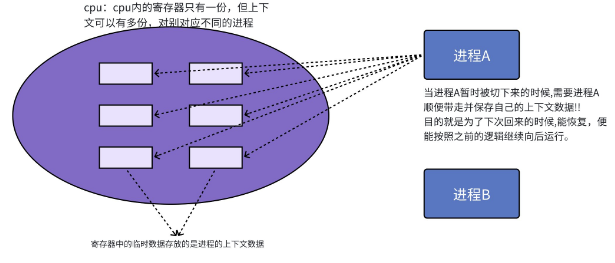
CPU 的寄存器是进程执行的 "临时工作台",保存着进程执行过程中的关键数据(如程序计数器、栈指针、通用寄存器值等)。这些寄存器中的数据统称为CPU 上下文。
进程切换的核心步骤可以概括为**"保存 - 加载 - 执行"**三部曲:
- 保存当前进程的上下文 :当当前进程的时间片耗尽(或被高优先级进程抢占)时,内核会将 CPU 寄存器中的所有数据保存到该进程的
task_struct(PCB)中;- 加载下一个进程的上下文 :内核从就绪队列中选择一个优先级最高的进程,将其
task_struct中保存的上下文数据加载到 CPU 寄存器中;- 执行下一个进程:CPU 根据加载的程序计数器(PC)值,从该进程的下一条指令开始执行。
举个形象的例子:进程切换就像厨师在烹饪多个订单时的 "换锅" 操作 ------
- 保存上下文:厨师将当前炒到一半的菜(当前进程)的状态记下来(比如炒了多久、放了哪些调料);
- 加载上下文:厨师拿出下一个要炒的菜(下一个进程),恢复之前的烹饪状态(比如之前炒到一半,现在继续翻炒);
- 执行:厨师继续烹饪下一个菜,直到时间片耗尽或菜炒好。
进程切换的速度直接影响系统的并发性能 ------ 如果切换速度过慢,会导致大量 CPU 时间浪费在 "换锅" 上,而不是 "炒菜"(进程执行)上。因此,Linux 内核一直在优化进程切换的效率,而task_struct和上下文数据的组织方式是优化的关键。
3.2 进程切换的触发条件
进程切换不会随机发生,只有在特定条件下才会被内核触发,主要包括以下几种情况:
- 时间片耗尽:每个进程都有一个时间片(由内核分配的 CPU 执行时间),当时间片用完时,内核会触发时钟中断,暂停当前进程,切换到下一个就绪进程;
- 进程主动放弃 CPU :进程执行
sleep()、wait()等系统调用时,会主动进入睡眠状态(阻塞状态),内核会切换到其他就绪进程;- 高优先级进程抢占:当一个高优先级进程从阻塞状态被唤醒(如 I/O 完成)时,内核会立即暂停当前运行的低优先级进程,切换到该高优先级进程;
- 进程退出 :进程执行完成(
exit())或被信号终止(如kill -9 PID)时,内核会回收其资源,切换到其他就绪进程。
其中,"时间片耗尽" 和 "高优先级进程抢占" 是最常见的触发条件,也是保证系统响应速度的核心机制。
3.3 进程切换的开销
进程切换虽然很快,但依然会产生一定的系统开销,主要包括:
- 上下文保存 / 加载开销:保存和加载 CPU 寄存器数据需要消耗 CPU 周期;
- 页表切换开销:如果两个进程的虚拟地址空间不同,内核需要切换页表(虚拟地址到物理地址的映射表),这会导致 CPU 的 TLB(快表)缓存失效,后续内存访问需要重新查询页表;
- 调度器决策开销:内核的调度器需要判断哪个进程是下一个要执行的进程,这也需要消耗一定的 CPU 资源。
为了减少切换开销,Linux 内核做了很多优化,例如:
- 优化task_struct的结构,让上下文数据集中存储,减少内存访问次数;
- 使用 TLB 快表缓存常用的页表项,减少页表切换后的缓存失效问题;
- 设计高效的调度算法(如 O (1) 调度算法),减少调度器的决策时间。
内核中相关的源码如下:

四、Linux 2.6 内核 O (1) 调度算法:常数时间调度的奥秘
在 Linux 2.6 内核之前,使用的是 O (n) 调度算法 ------ 调度器需要遍历所有就绪进程,找到优先级最高的进程,调度时间随进程数量增加而线性增长(n 为就绪进程数)。当系统中进程数量较多时,调度开销会显著增加。
而 Linux 2.6 内核引入了O (1) 调度算法,实现了 "常数时间调度"------ 无论系统中有多少个就绪进程,调度器都能在固定时间内找到优先级最高的进程,极大提升了系统的并发性能。
4.1 O (1) 调度算法的核心数据结构:runqueue
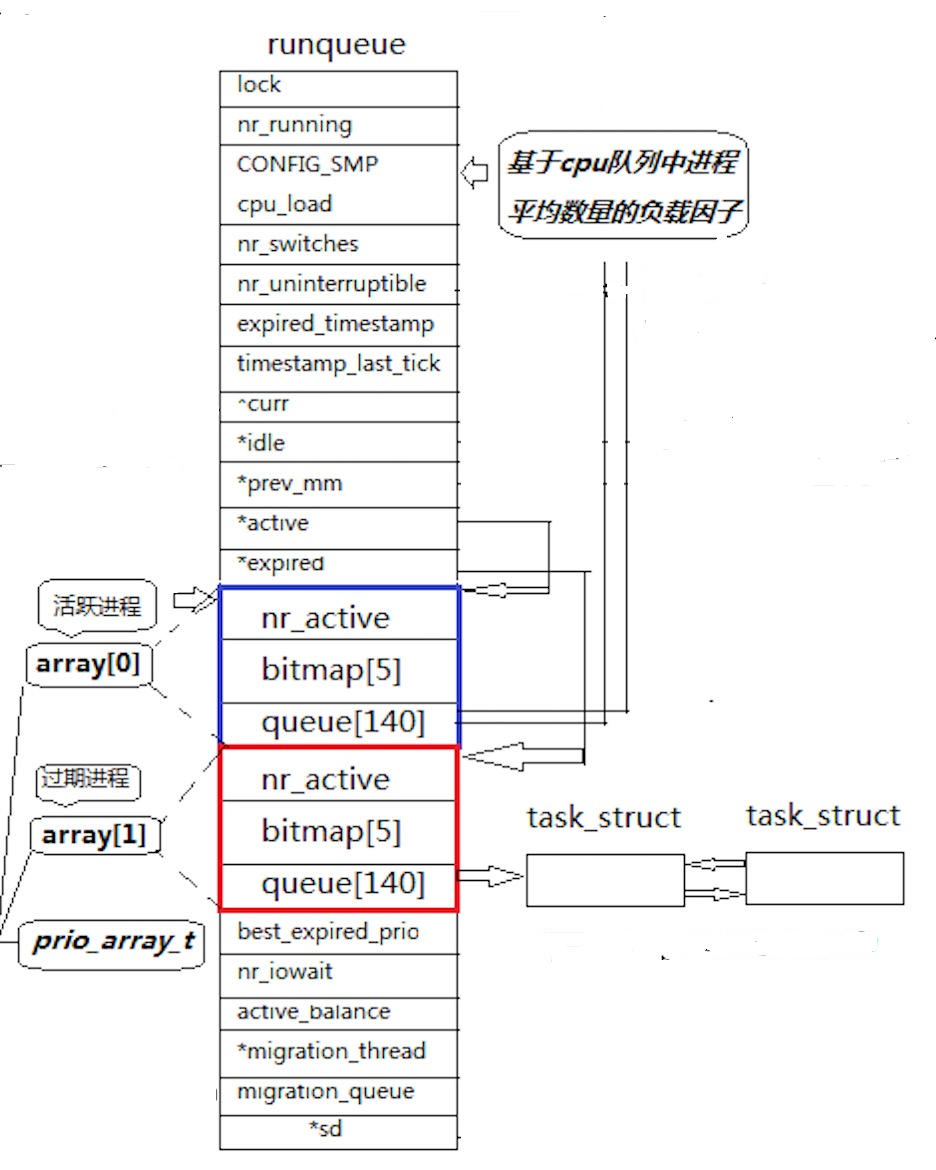
O (1) 调度算法的核心是runqueue(运行队列),每个 CPU 核心都有一个独立的runqueue,用于管理该 CPU 上的所有就绪进程。这样可以避免多个 CPU 核心争抢同一个运行队列,提高调度效率。
runqueue的核心结构定义(简化版)如下:
cpp
struct rq {
spinlock_t lock; // 保护runqueue的自旋锁
unsigned long nr_running; // 就绪进程总数
struct task_struct *curr; // 当前运行的进程
struct task_struct *idle; // 空闲进程(CPU空闲时运行)
struct prio_array *active; // 活跃队列(时间片未耗尽的进程)
struct prio_array *expired; // 过期队列(时间片已耗尽的进程)
struct prio_array arrays[2];// 活跃队列和过期队列的实际存储
// 其他字段...
};
// 优先级数组结构
struct prio_array {
unsigned int nr_active; // 该队列中的进程数
DECLARE_BITMAP(bitmap, MAX_PRIO+1); // 优先级位图(快速查找非空队列)
struct list_head queue[MAX_PRIO]; // 进程链表(按优先级分组)
};从结构中可以看出,runqueue的核心设计是**"双队列 + 优先级分组"**,下面逐一拆解。
4.2 双队列设计:活跃队列与过期队列
runqueue包含两个相互独立的队列:active(活跃队列)和expired(过期队列),它们的功能分工明确:
- 活跃队列(active) :存储时间片未耗尽的就绪进程,这些进程可以被调度执行;
- 过期队列(expired):存储时间片已耗尽的就绪进程,这些进程需要重新分配时间片后才能进入活跃队列。
双队列的工作流程如下:
- 调度器从活跃队列中选择优先级最高的进程执行;
- 当进程的时间片耗尽时,内核将其移动到过期队列,并重新计算其时间片;
- 当活跃队列中的进程全部执行完毕(或时间片耗尽)时,内核交换active和expired指针的指向 ------ 原来的过期队列变为新的活跃队列,原来的活跃队列变为新的过期队列;
- 重复上述过程,实现进程的循环调度。
这种设计的核心优势是:时间片重新计算和队列切换可以在 O (1) 时间内完成,无需遍历所有进程。
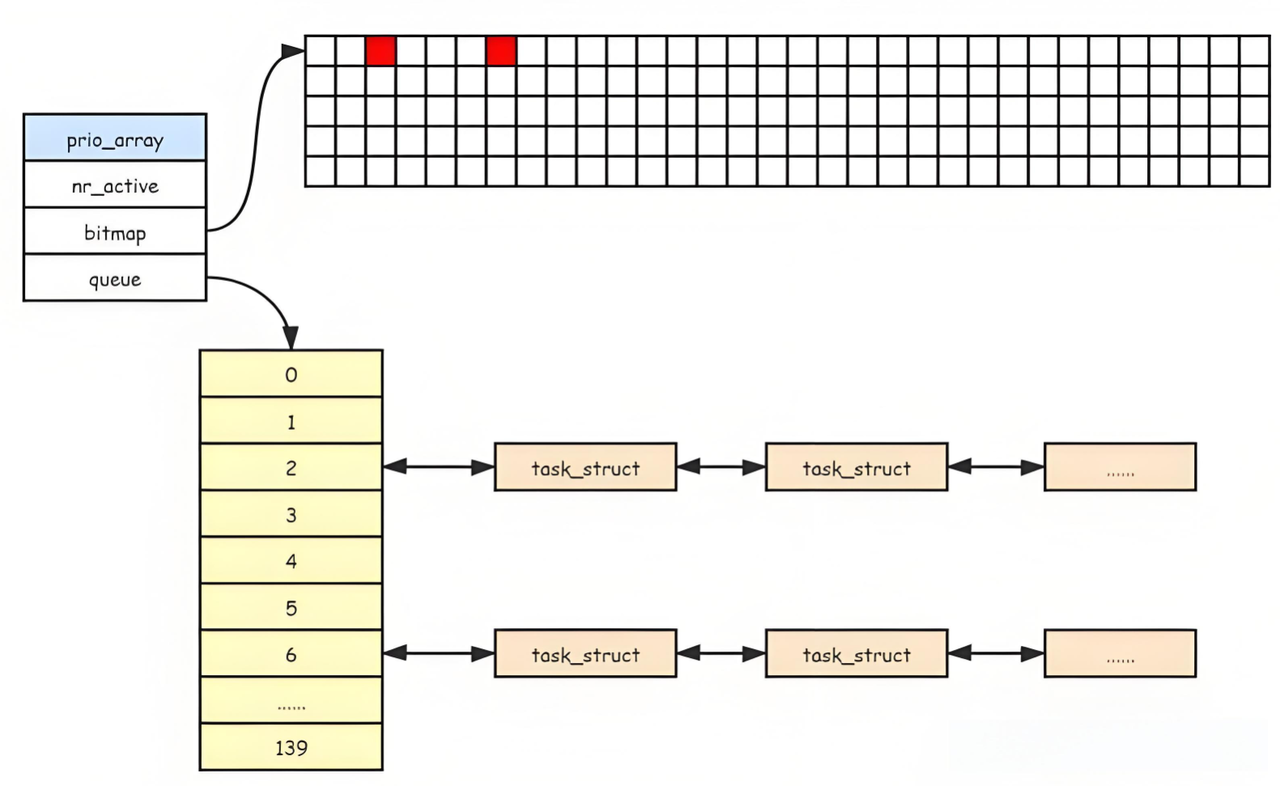
4.3 优先级分组:queue 数组与 bitmap 位图
每个prio_array(优先级数组)中包含两个关键组件:queue数组和bitmap位图,用于实现按优先级分组和快速查找。
4.3.1 queue 数组:按优先级存储进程
queue是一个数组,数组的下标代表进程的优先级(0~139),每个元素是一个链表,存储该优先级的所有进程。例如:
queue[60]:存储PRI=60的进程(NI=-20的普通进程);queue[80]:存储PRI=80的进程(NI=0的默认优先级进程);queue[99]:存储PRI=99的进程(NI=19的低优先级进程)。
同一优先级的进程按**"先进先出"(FIFO)** 的顺序排队,确保公平性。例如,两个PRI=80的进程,先进入队列的会先被调度执行。
4.3.2 bitmap 位图:快速查找非空队列
bitmap是一个位图(bitmap),用于标记哪个优先级的队列中存在进程。位图的每一位对应一个优先级(0~139):
- 若某一位为
1,表示对应的优先级队列中有进程;- 若某一位为
0,表示对应的优先级队列中没有进程。
例如,bitmap的第 60 位为1,表示queue[60]中有进程;第 80 位为1,表示queue[80]中有进程。
位图的核心作用是快速查找优先级最高的非空队列,步骤如下:
- 从位图的第 0 位(最高优先级)开始扫描;
- 找到第一个值为
1的位,对应的下标就是最高优先级;- 从该下标对应的
queue链表中取出第一个进程,调度执行。
由于位图的扫描可以通过 CPU 的位运算指令(如ffs------find first set)实现,整个查找过程只需 O (1) 时间(与进程数量无关),这是 O (1) 调度算法的核心优化。
4.4 O (1) 调度算法的完整流程
结合runqueue的结构和双队列、优先级分组设计,O (1) 调度算法的完整流程如下:
步骤 1:初始化 runqueue
每个 CPU 核心启动时,会初始化一个runqueue,创建active和expired两个队列,初始化queue数组和bitmap位图。
步骤 2:进程加入就绪队列
当一个进程从阻塞状态被唤醒(或新建进程)时,内核会:
- 根据进程的
PRI值,将其加入active队列对应的queue[PRI]链表尾部;- 将
bitmap位图中对应PRI的位设置为1;- 递增
active队列的nr_active计数器(进程数)。
步骤 3:选择下一个要执行的进程
调度器需要选择进程时,会:
- 扫描
active队列的bitmap位图,找到第一个值为1的位(最高优先级);- 从对应的
queue[PRI]链表中取出第一个进程(FIFO 顺序);- 将该进程设置为
curr(当前运行进程),并分配 CPU 时间片。
步骤 4:进程时间片耗尽
当进程的时间片耗尽时,内核会:
- 重新计算该进程的时间片(根据优先级调整,高优先级进程时间片更长);
- 将该进程从
active队列移动到expired队列对应的queue[PRI]链表尾部;- 更新
active和expired队列的nr_active计数器和bitmap位图。
步骤 5:队列切换
当active队列的nr_active计数器变为 0(所有进程时间片耗尽)时,内核会:
- 交换active和expired指针的指向(active = expired
;expired = 原来的active);- 重置expired队列的nr_active计数器和bitmap位图;
- 此时,新的active队列中包含所有重新分配了时间片的进程,调度继续。
步骤 6:进程退出或阻塞
如果进程执行完成 (退出)或进入阻塞状态(如等待 I/O),内核会:
- 将该进程从active队列中移除;
- 更新bitmap位图(若该队列已空,将对应位设为
0);- 递减nr_active计数器,调度器重新选择进程。
4.5 O (1) 调度算法的优势与局限性
4.5.1 核心优势:常数时间调度
O (1) 调度算法的最大优势是调度时间与进程数量无关------ 无论系统中有 10 个还是 1000 个就绪进程,调度器都能在固定时间内找到优先级最高的进程,极大提升了系统在高负载下的性能。
此外,该算法还具有:
- 优先级区分明确:高优先级进程总能被优先调度,确保系统响应速度;
- 公平性:同一优先级的进程按 FIFO 顺序执行,避免饥饿(某进程长期得不到 CPU);
- 扩展性好:每个 CPU 核心独立运行队列,支持 SMP(对称多处理器)架构,适合多核服务器。
4.5.2 局限性与后续优化
O (1) 调度算法虽然高效,但也存在一些局限性:
- 实时性不足:普通进程的优先级范围(60~99)与实时进程(0~99)有重叠,可能导致普通高优先级进程抢占实时进程;
- 负载均衡复杂:多个 CPU 核心的运行队列之间需要进行负载均衡(将进程从繁忙 CPU 迁移到空闲 CPU),增加了内核复杂度;
- 对交互进程优化不足:交互进程(如键盘输入、鼠标操作)需要快速响应,但 O (1) 算法主要基于静态优先级,无法动态调整。
为了解决这些问题,Linux 2.6.23 内核引入了 CFS(完全公平调度器),取代了 O (1) 调度算法。CFS 基于 "完全公平" 原则,通过计算进程的 "虚拟运行时间" 来分配 CPU 资源,更适合现代系统的交互性和实时性需求。但 O (1) 调度算法的设计思想(双队列、位图查找)依然是 Linux 调度器的核心基础,值得我们深入学习。
总结
Linux 进程调度是内核的核心模块之一,其设计思想融合了数据结构、算法和系统优化的精华。希望本文能帮助你看透进程优先级和切换的底层逻辑,在实际工作中更好地优化系统性能。如果有任何疑问或补充,欢迎在评论区交流!