hello~ 很高兴见到大家! 这次带来的是Linux系统中关于进程这部分的一些知识点,如果对你有所帮助的话,可否留下你宝贵的三连呢?
个 人 主 页 : 默|笙

文章目录
- 一、进程优先级
-
-
- [1.1 概念](#1.1 概念)
- [1.2 查看系统进程、认识PRI和NI](#1.2 查看系统进程、认识PRI和NI)
- [1.3 更改系统优先级](#1.3 更改系统优先级)
- [1.4 竞争、独立、并行和并发](#1.4 竞争、独立、并行和并发)
-
- 二、进程切换
- 三、进程调度
-
-
- [3.1 组织进程](#3.1 组织进程)
-
- [1. c语言变量的地址](#1. c语言变量的地址)
- [2. Linux调度算法重新设计双链表](#2. Linux调度算法重新设计双链表)
- [3.2 认识runqueue](#3.2 认识runqueue)
-
- [1. prio_array_t 结构体三成员变量讲解](#1. prio_array_t 结构体三成员变量讲解)
- [2. 活跃进程和过期进程](#2. 活跃进程和过期进程)
-
一、进程优先级
1.1 概念
- 什么是优先级?相对于权限,权限是一件事能不能够做的问题,而优先级是你能够做这件事,但分先后顺序。
- 进程的优先级就是cpu资源分配的先后顺序,优先级高的可以先享受cpu提供的资源先执行。
- 也就是进程在已经能够得到某种资源的情况下,得到这种资源的先后顺序。
1.2 查看系统进程、认识PRI和NI
- 使用ps -l来查看系统进程。

- UID:代表执行者的身份。执行当前两个进程bash和ps的之性质是mosheng这个用户,可以用 id -u 用户名 来查看用户的uid。
- PRI:也就是优先级,数字越小,代表优先级越高,就越早被执行。top工具显示的优先级的默认值是80。
- NI:代表这个进程的nice值,它用于修改进程的优先级。
- PRI(新)= PRI(旧)+ nice值。注意这里的PRI(旧)指的是优先级的默认值。
- 当nice值为负值时,进程的优先级会变高;当nice值为正数时,优先级会变低。
- nice的取值范围是-20至19,一共40个级别。这代表优先级的范围也是有限的。
1.3 更改系统优先级
- 我们可以通过top命令更改已经存在的进程的nice值:进入top后,按 "r" 之后输入进程PID之后再输入进程的新的nice值,便可以完成更改。

- 但一般都不用修改一个进程的优先级,因为容易出现问题,操作系统也不会允许非root用户权限的用户频繁修改进程的优先级。
1.4 竞争、独立、并行和并发
- 竞争:一般的计算机都只有少量甚至一个cpu,这就代表着资源有限,而进程可以n个,不同的进程之间定然存在着竞争。而优先级的出现,就可以减少一定的竞争,可以更加合理地分配资源,提升效率。
- 独立:进程之间是相互独立的,即便是父进程和子进程之间也是相互独立的(但不绝对,比如僵尸进程和孤儿进程)。子进程掉线不会干扰父进程的执行,父进程同理。我们知道:进程 = PCB(task_struct) + 进程的代码和数据。子进程的创建一定会伴随着新的PCB的创建,虽然父子进程代码共享,但由于是只读,所以它们之间也是互不影响的。要实现它们之间的独立性,就要保证它们之间的数据是独立的,这个依赖于写时复制,之后的博客里会讲到。
- 并行 :多个进程在多个cpu下面同时运行,一个cpu还是只运行一个进程。这叫做并行。核心是硬件的支持。
- 并发:一个cpu采用进程切换的方式在一定时间里运行多个进程,使这些进程都能得到推进。
二、进程切换
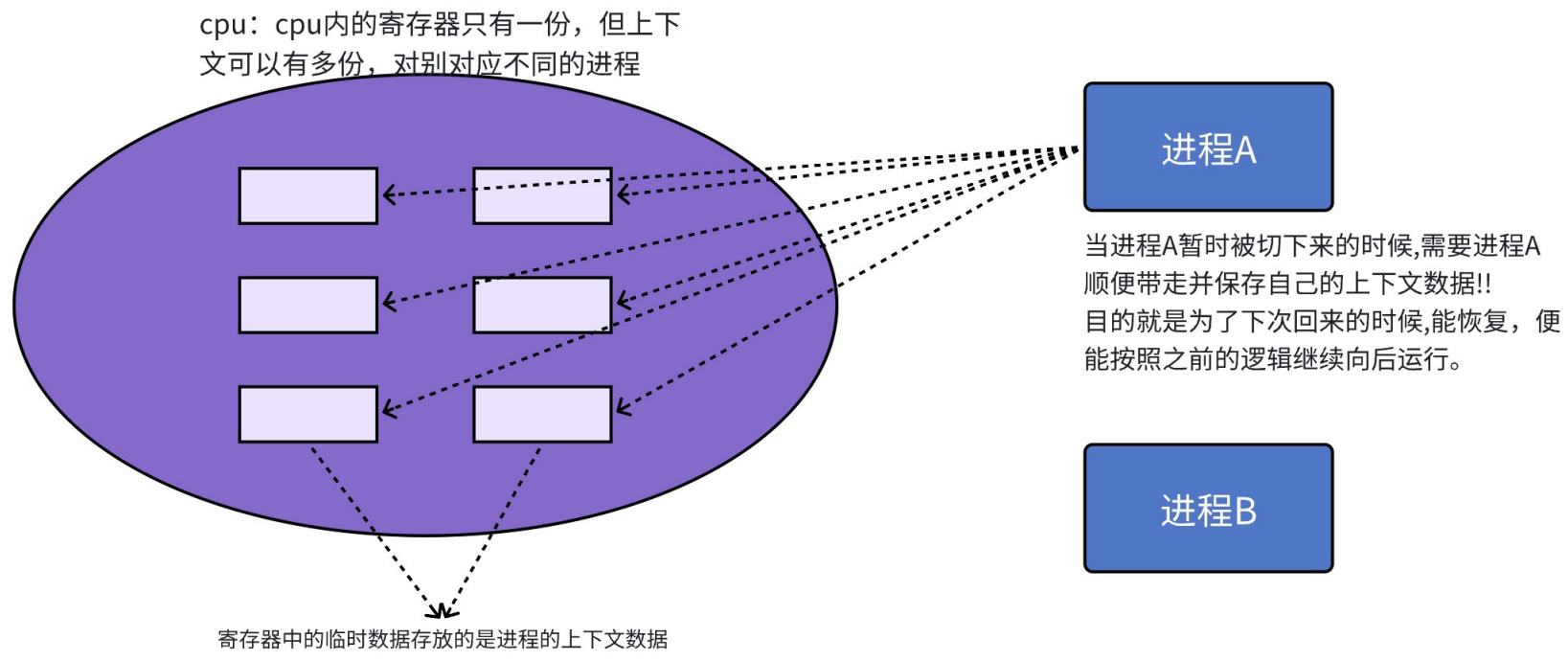
- 进程切换的本质是cpu上下文数据的切换和地址空间切换。一个cpu只有一套寄存器,这是硬件,所以寄存器在一个时刻只能够存储一个进程的上下文数据。但上下文数据是有多套的,一个进程对应一套独立的上下文数据。
- 我们当前接触到的大多数系统都是分时系统,它的目标是让所有进程在一定时间内都能执行一遍,实现相对公平。每一个进程都会有一个时间片,当这个时间片时间到了之后,cpu就会切换下一个优先级最高的进程,同时把这个进程的上下文数据打包让其带走(写入其PCB上下文保存区),同时读取新进程的上下文数据加载到寄存器。
- 时间片的长短或者是获取到时间片的概率会根据优先级有所不同,所以这也是为什么优先级的范围是有限的原因。想要实现相对公平,让所有进程在一定时间内都有获取cpu资源的机会,优先级的范围就不能太大,否则就很可能会出现一个进程疯狂执行,而其他的进程没有机会执行得到推进的情况。
- 虽然cpu一次只能处理一个进程,但进程切换的速度非常快(通常为毫秒甚至微秒级),在很短的时间里面就能够把几乎所有的进程都给执行一遍,因为速度太快,远超人类的感知阈值,所以我们是感受不到的,这就造成了所有进程都在同时运行的假象。
- 至于为什么现在的大多数系统都是分时系统的原因是因为用户和互联网的需求,比如我们在玩手机时,就可能会打开多个进程加载到内存,在下载软件的同时我们也在打游戏,我们当然希望这两个任务能够同时进行,而不是必须要等软件下载完了之后才能去打游戏,或者是打游戏时这个软件就没办法下载的情况。与分时系统对应的是实时系统,它一般会应用在工业领域。
三、进程调度
那么系统具体是如何做到分时系统的进程切换的呢?接下来我们就以Linux优秀的调度算法O(1)时间复杂度来认识认识原理。
3.1 组织进程
1. c语言变量的地址
-
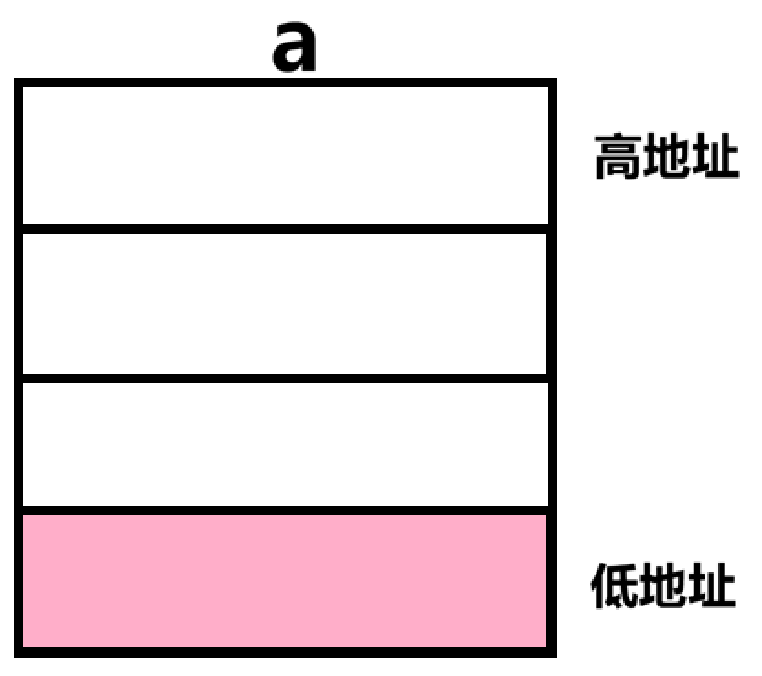
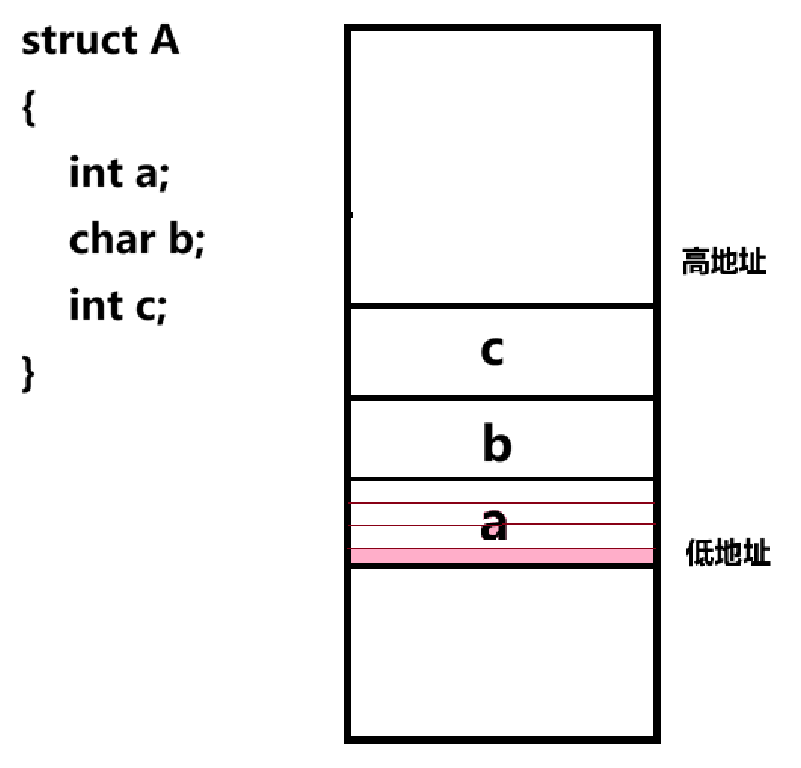
在c语言里,一个int类型的变量a是哪一个呢?我们知道,int类型它拥有4个字节且每个字节都有一个地址。一个变量的地址永远都是地址数据最小的那一个,结构体变量也是如此。
-
设想一个情境,如果我们只知道某个结构体变量中成员c的地址,我们应该如何获得这一整个结构体变量的地址也就是成员a的地址?首先就是必须要知道从成员c到成员a之间的偏移量,之后用c成员变量的地址减去这个偏移量就能够得到成员a的地址。也就是当前c地址 - &(struct A*)0->c,先将0强转为struct A*类型的指针,之后指向c,再取这个成员c的地址也就得到了偏移量,最后用当前c成员变量的地址减去这个偏移量就大功告成了。
2. Linux调度算法重新设计双链表
- 在之前的博客里面我们了解到Linux系统里面它是通过双链表来进行PCB的管理。那么这个双链表它究竟是怎样的呢?
- 首先它设计了一个新的结构体(这里写作link,但源代码里面它的名字不是这个,而是list_head),能够极大的实现复用。
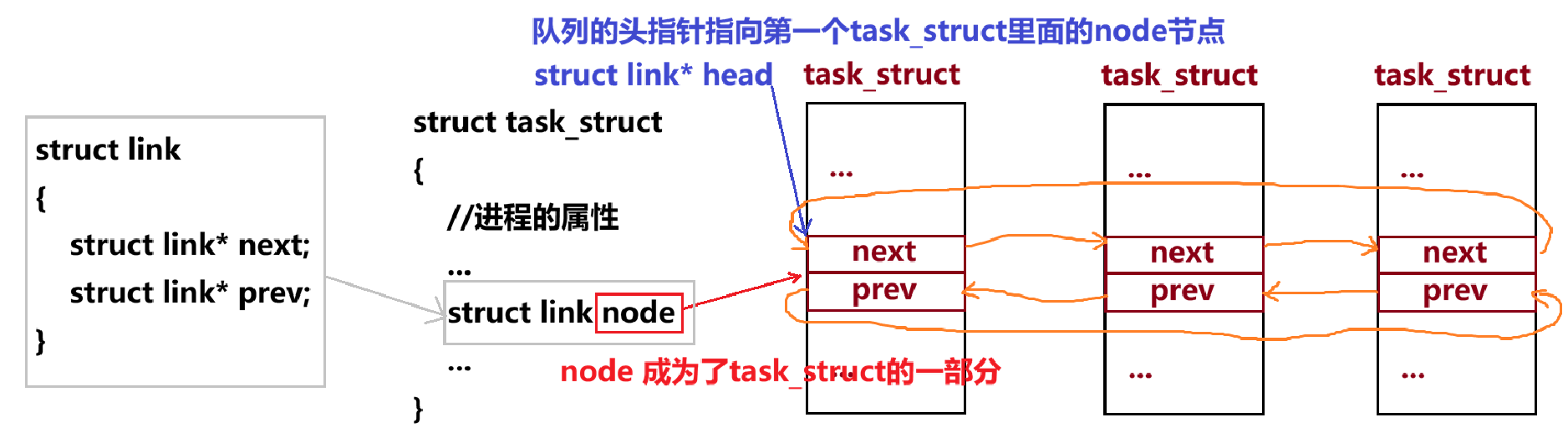
- 这个link里面有两个指针,一个指向下一个link类型结构体,一个指向上一个link类型结构体。然后每个task_struct里面都会有一个struct link 类型的node变量,我们通过这些node变量来把这些task_struct组织在一起。与传统双链表不同的是,它不是指向task_struct这个整体,而是指向这个整体里面的一个成员变量。
- 我们只知道这个link类型node成员变量的地址,该如何获得该task_struct类型变量的地址?这也就是之前c语言变量地址部分所探讨的。原理都是一样的,所以获取task_struct类型变量这个整体的地址不是问题。
- 为什么要这样设计?它具有什么优势?
- 首先,我们这个link类型它是什么结构体里面都能插入一个的,无论是管理进程的PCB,亦或是管理硬件的结构体,都可以通过插入一个link类型的结构体变量来完成组织。这样就增加了链式管理的扩展性。理论上,我们是能够将不同类型的结构体如此串联起来的,传统的链式结构是绝对做不到的。而且也不只是能够实现双链表、二叉树、哈希表的数据结构的实现也完全没有问题。
- 基于这种通用link节点的设计,链表的核心管理逻辑(如节点插入、删除、遍历、查找)只需编写并维护一份通用代码。无需为PCB链表、硬件结构体链表重复实现增删查改逻辑。

- Linux内核中,会把所有的进程都放在同一张双链表里。但同时进程也需要链接到运行队列等其他的链式结构中,而link结构体的发明完美解决了这个问题,毕竟link结构体变量是可以嵌入多个的,它们分别对接上不同的链式结构。这就是这个设计的第三个优点。
3.2 认识runqueue
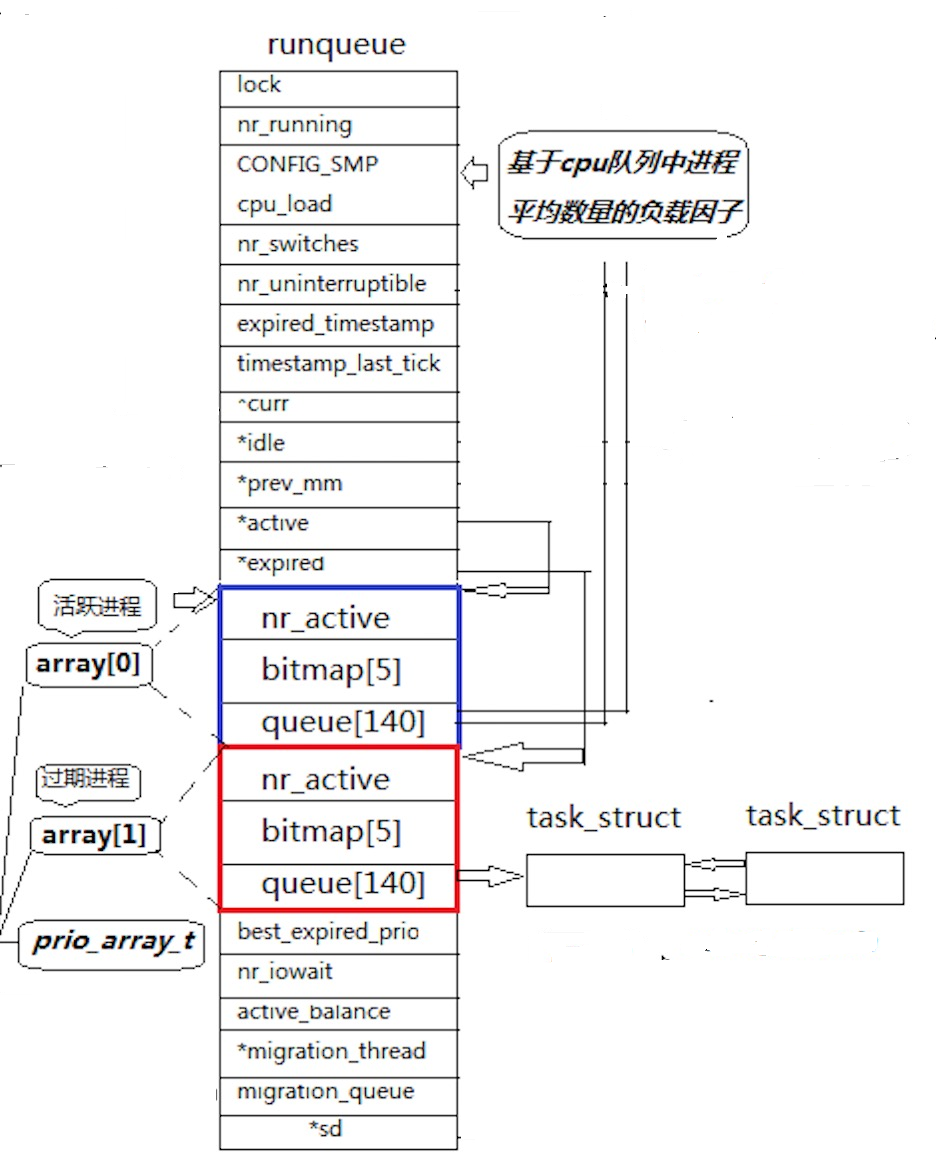
- 每一个cpu都有一个调度队列,这个调度队列是一个结构体,里面包含了很多成员变量,接下来我会讲圈出来的部分和两个指针active和expired来更深刻的了解Linux的调度逻辑。
1. prio_array_t 结构体三成员变量讲解
cpp
struct prio_array_t
{
int nr_active;//3
unsigned long bitmap[5];//2
struct list_head queue[140];//1
}queue140进程优先级队列---本质数组
-
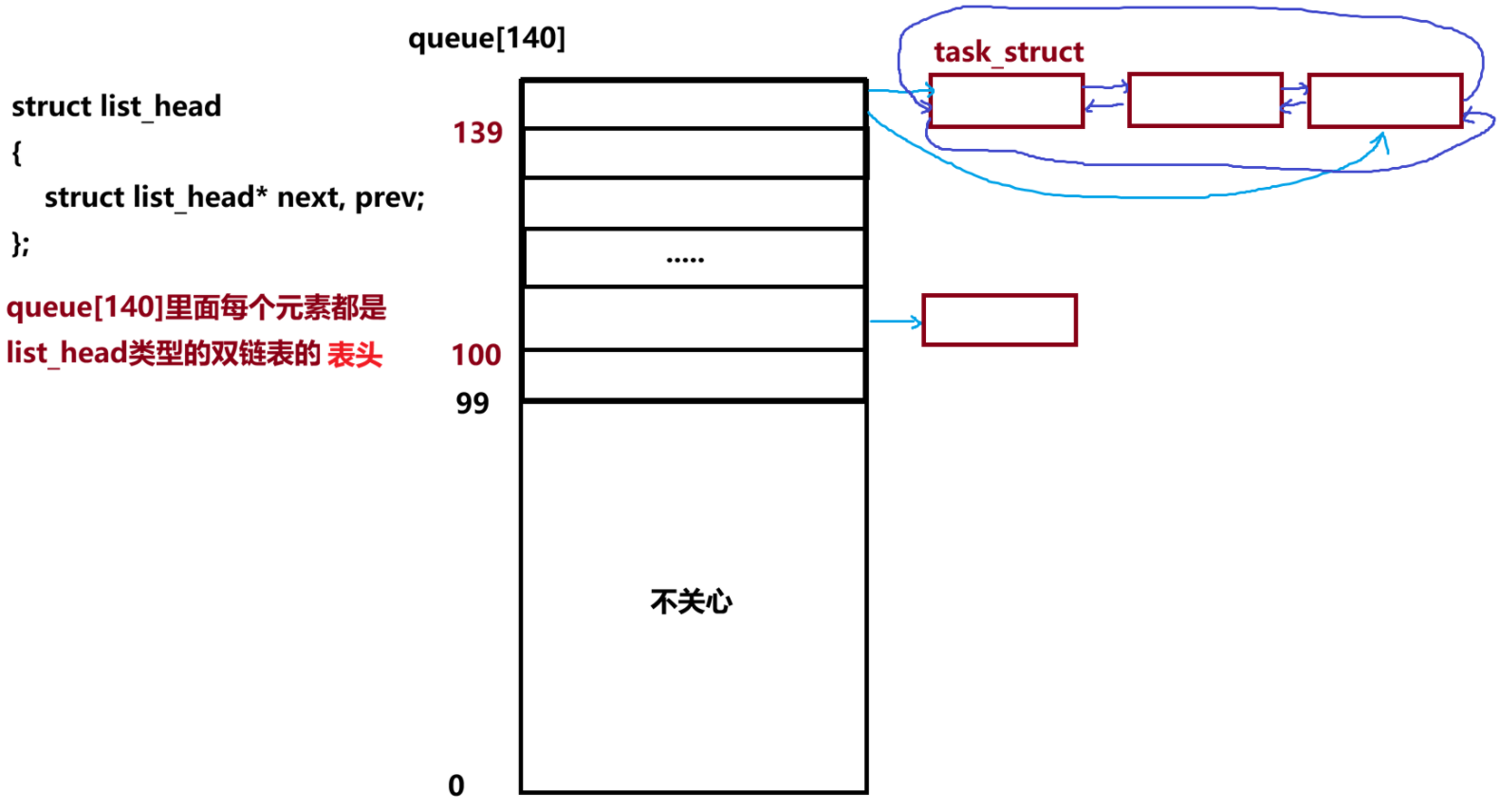
queue 140 是长度 140 的数组,每个元素是struct list_head类型的双链表表头;list_head的next指向该优先级下第一个进程的run_list(list_head类型变量),prev指向最后一个进程的run_list;无进程时,next和prev都指向自己。
-
queue140里面有两种不同的优先级,索引~99对应的是实时优先级,这部分我们暂不关心;索引100~139对应的是普通优先级,共40个等级,数字越小优先级越高,与我们之前讲到的优先级等级NI取值范围一样。
-
每一个进程都有对应的优先级,进程要进入这个优先级队列时,会根据自己的优先级直接映射到queue对应的下标,之后再链接到对应双链表的后面。
-
当一个进程时间片耗尽或主动让出cpu资源,这个时候cpu就会在优先级队列里面选择一个优先级最高的进程执行。这本质上就是一个类似hash的过程,根据下标找到符合要求的进程链,之后就是FIFO的操作了,毕竟这个高优先级可能不止一个。
- pri默认80是用户层工具的显示规则,但是调度优先级(prio)的默认值是120,与优先级队列下标一一对应。优先级数字,本质上就是数组的下标。
bitmap5---本质位图
cpu要找到优先级最高的进程,是否需要遍历一遍queue140这个优先级队列?如果这样做,那么效率会十分低下,而bitmap5就可以很好地解决这个问题。
- 我们知道,一个字节 8个比特位,一个 long 类型是4个字节即32个比特位。O (1) 调度器用比特位标记 queue 每个下标是否有进程(1代表有,0则没有),140 个下标就需要140个比特位,而5个long(5×32=160 位)足以完全覆盖这些下标,因此仅需5个 long 大小的位图即可。
- 在寻找目标进程时,无需逐位遍历,而是按优先级顺序检查位图的 5 个 long 值:为 0 则跳过,不为 0 则通过专用函数直接找到该 long 内第一个非 0 的 bit 位,结合 long 序号算出对应的 queue 下标(最高优先级队列)。
nr_active---int类型变量
- 如果一个优先级对列里面压根没有进程,那么寻找目标进程到bitmap里面去遍历5个long值效率就有点低下了。如果我们先用一个变量记录一下优先级队列里面进程的个数,在遍历bitmap之前先检查这个变量,如果不为0再去bitmap里去找,这样就可以提升效率。而这个变量就是nr_active。
2. 活跃进程和过期进程
介绍
- 有没有想过,那些时间片耗尽但任务还未完成的进程cpu会将它们如何处理呢:1. 因为之后还要执行,所以直接取下来之后放在该优先级对应的链表后面,可是这样优先级低的进程将永远不会被执行,这有违分时系统的公平性。2. 执行完之后降低进程的优先级,可是这样不仅逻辑混乱,还会极大地降低效率。以上两种办法都不够好,于是活跃进程和过期进程就出现了。
- 活跃进程和过期进程它们的本质是两个独立的prio_array_t类型实例,它们的结构一模一样。过期进程里面存放的是时间片耗尽的进程,它们的优先级不改变。
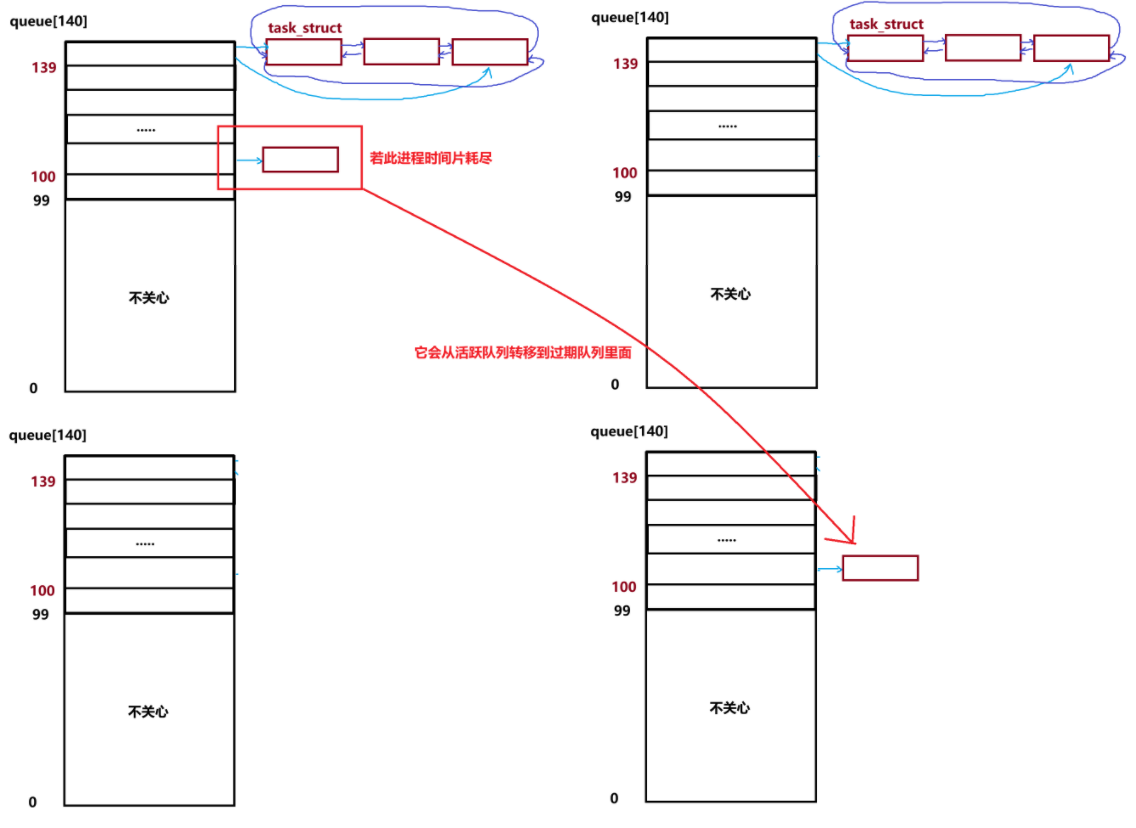
- 上面的是活跃队列,下面的是过期队列。当进程时间片耗尽且还需继续执行时,会被转移到过期队列中。随着 CPU 执行,活跃队列的进程数量越来越少,过期队列的进程数量越来越多。当活跃队列没有进程时,只需交换两个队列的指针,过期队列就变成新的活跃队列,之前的活跃队列变为过期队列,这样不仅低优先级进程都能得到执行,还能保证调度效率不降低。
active和expired指针
- 两个队列的交换这就离不开active和expired指针了,active指针指向的就是活跃队列,而expired指针指向的就是过期队列。
- 关于NI值的最后一点介绍:**改变优先级不是直接改变一个进程的prio,而是通过改变nice值来间接达到目的,这是因为如果直接改变 prio 的话,进程就需要从原优先级的链表中移除、再插入进新的优先级队列链表,既增加开销又易突破优先级范围(可能会让其跑到实时优先级区域也就是越界);而改nice值,系统会在该进程时间片耗尽未执行完即将进入到过期队列时根据规则改变prio,让进程插入到过期队列里新的优先级队列对应的链表里,这样既不会降低效率,也不用担心prio的值超过范围,因为nice值也是有范围的。**怎么样?nice值是不是很nice?
今天的分享就到此结束啦,如果对读者朋友们有所帮助的话,可否留下宝贵的三连呢~~
让我们共同努力, 一起走下去!