📋 前言
各位伙伴们,大家好!今天,Day 20,我们来聊一个在机器学习领域绕不开的终极话题:模型可解释性 (Interpretability)。我们已经能熟练地构建和调优各种复杂的"黑箱"模型,但一个灵魂拷问始终萦绕心头:
- "模型为什么会做出这样的预测?"
- "我该如何信任一个我无法理解的模型?"
今天,我们将学习打开这个黑箱的"钥匙"------SHAP (SHapley Additive exPlanations) 。但这不仅仅是一篇 SHAP 的入门教程。我们将从一个更根本的问题出发:为什么别人的代码我总是跑不通? 并以此为切入点,深度理解 shape 的重要性,最终掌握 SHAP 的思想精髓和实战应用。
一、万恶之源:你真的理解"数据形状(Shape)"吗?
在入门机器学习后,日常报错中最常见的两个问题是什么?
- 输入维度不对 :
ValueError: X has n_features, but this model is expecting m_features - 函数/方法不存在 :
AttributeError: module 'xxx' has no attribute 'yyy'
第二个问题通常是环境问题(库没装、版本不对)。但第一个问题,以及无数衍生问题(比如 SHAP 跑不通),其根源往往在于我们对数据形状 shape 的理解出现了偏差。
1.1 破除思维定式:torch.randn(3, 4, 5) 是什么?
我们习惯于将高维数据与三维物理空间联系起来。看到 (3, 4, 5),脑中浮现的是一个长宽高为 3、4、5 的立方体。
这是错误的!
在 NumPy/PyTorch/TensorFlow 中,shape 描述的是数组的嵌套结构,与物理空间无关。
torch.randn(5): 一个包含 5 个元素的一维数组。[e1, e2, e3, e4, e5]torch.randn(4, 5): 4 个"一维数组"打包在一起。[[...], [...], [...], [...]]torch.randn(3, 4, 5): 3 个"二维数组(4x5的矩阵)"打包在一起。[[[...]], [[...]], [[...]]]
这个维度的意思是"你处在第几层",而不是空间维。 理解了这一点,你就掌握了处理复杂数据输入(如图像、时间序列)的钥匙。
1.2 编程的"核心体感":关注函数的输入与输出
为什么很多人的代码不好复现?
- 假代码、伪代码泛滥。
- 没有固定的运行环境 (
requirements.txt的缺失)。 - 对库的底层实现做了修改但你不知道。
这些问题的本质,都指向了一个被忽视的编程核心素养:彻底搞懂一个函数的输入(Input)和输出(Output)。
当你遇到报错时,最高效的解决方案不是无脑复制粘贴错误信息去搜索,而是:
- 打印出输入数据的
shape和type。 - 查阅官方文档,看这个函数到底期望接收什么样
shape和type的输入。 - 打印出函数的输出,看它返回了什么。
这个习惯,能帮你解决 80% 的程序问题,尤其是在使用像 SHAP 这样因版本迭代导致输出结构变化的库时。
二、SHAP 值到底是什么?------从"分蛋糕"说起
我们知道了理解 I/O 的重要性,现在可以正式进入 SHAP 的世界。
对于一个信贷模型,我们不仅想知道小明会不会违约,更想知道是哪个因素、在多大程度上导致了这个判断。
年收入+0.15(加分项),负债率-0.30(减分项),信用评分-0.25(减分项)...
这看起来很像线性回归的系数 y = w1*x1 + w2*x2 + ...,但它远比线性回归强大。
-
线性回归:
- 全局解释:所有人的"年收入"权重都是固定的(如 0.15)。
- 简单,但有缺陷:它假设了特征与目标是线性关系。但现实中,年收入从 5 万到 30 万的影响,和从 100 万到 500 万的影响,是完全不同的(边际效应递减)。
-
SHAP:
- 局部解释 :因人而异。张三的"年收入"贡献可能是+0.15,李四的可能是+0.08。
- 复杂,但更真实:它能捕捉这种非线性关系和特征间的交互作用(如"性别"和"年龄"共同产生的影响)。
2.1 "奶茶店分钱"的比喻
SHAP 的核心思想源于博弈论中的"夏普利值"。我们可以用一个简单的例子来理解:
小王(研发)、小李(营销)、小张(运营)三人合伙开了家奶茶店,年底赚了 100 万。这 100 万该怎么分?
直接平分显然不公平。夏普利值的做法是:计算每个成员加入团队时,带来的边际贡献 ,并对所有可能的加入顺序取平均。
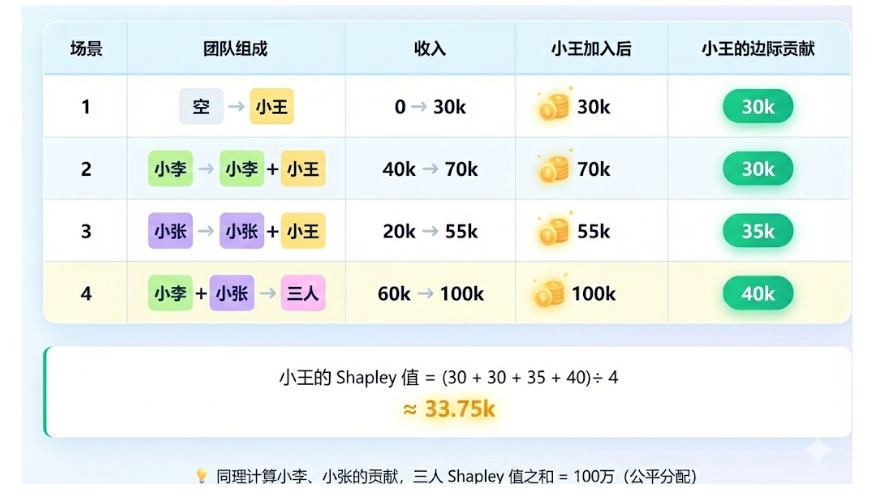
在机器学习中:
- 开店赚钱 = 模型预测
- 合伙人 = 模型特征
- 总收入 (100万) = 模型最终预测值 - 基准值
- 每个人的贡献 = 每个特征的 SHAP 值
核心公式 :
模型预测值 = 基准值 (base_value) + 所有特征的SHAP值之和
这里的 base_value 就是当模型"什么都不知道"(没有输入任何特征)时的"默认"预测,通常是训练集上所有样本预测值的平均值。
三、实战演练:用 SHAP 解释回归模型
理论讲完,我们来动手实践!我们将使用加州房价数据集,训练一个梯度提升回归模型,并用 SHAP 来解释它。
【我的代码】
python
# 【我的代码】
# 本部分代码为Day20作业的完整实现
# 包含了数据加载、模型训练、以及SHAP分析与可视化的全过程
import pandas as pd
import numpy as np
import shap
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.datasets import fetch_california_housing
import matplotlib.pyplot as plt
# --- 1. 数据准备 ---
# 加载数据
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# --- 2. 模型训练 ---
# 训练一个梯度提升回归模型(一个典型的"黑箱")
model = GradientBoostingRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
print("模型训练完成!")
# --- 3. SHAP 分析 ---
print("开始进行 SHAP 分析...")
# 创建一个解释器
# 对于树模型,使用 shap.TreeExplainer 效率更高
explainer = shap.TreeExplainer(model)
# 计算测试集的 SHAP 值
# 注意:explainer(X) 返回的是一个 Explanation 对象
shap_values = explainer(X_test)
print("SHAP 值计算完成!")
# --- 4. SHAP 可视化与解读 ---
# 设置 matplotlib 使用支持中文的字体,以防图例乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 图一:SHAP Summary Plot (bar) - 全局特征重要性
print("\n正在生成:全局特征重要性图...")
plt.figure()
shap.summary_plot(shap_values, X_test, plot_type="bar", show=False)
plt.title("全局特征重要性 (Bar)")
plt.show()
# 图二:SHAP Summary Plot (beeswarm) - 特征影响分布
print("\n正在生成:特征影响分布图 (Beeswarm)...")
plt.figure()
shap.summary_plot(shap_values, X_test, show=False)
plt.title("特征影响分布图")
plt.show()
# 图三:SHAP Force Plot - 单个样本的局部解释
# 解释测试集中的第一个样本
print("\n正在生成:第一个测试样本的力图 (Force Plot)...")
# 需要加载JS库,确保在Jupyter环境中能正确显示
shap.initjs()
# shap.force_plot(base_value, shap_values_for_one_sample, features_for_one_sample)
force_plot = shap.force_plot(explainer.expected_value, shap_values.values[0,:], X_test.iloc[0,:])
# force_plot # 在 notebook 中直接显示
# 如果不在notebook中,可以保存为html
# shap.save_html("force_plot_sample_0.html", force_plot)
# print("力图已保存为 'force_plot_sample_0.html'")
print("\n--- SHAP 值数据结构探索 ---")
print(f"explainer.expected_value (基准值): {explainer.expected_value}")
print(f"shap_values 对象的类型: {type(shap_values)}")
print(f"SHAP 值的形状 (shap_values.values.shape): {shap_values.values.shape}")
print(f"测试集的形状 (X_test.shape): {X_test.shape}")
print("结论:SHAP 值的形状 (样本数, 特征数) 与测试集完全对应!")【代码与结果解读】
点击展开/折叠:查看详细注释与结果分析
1. 全局特征重要性 (Bar Plot)
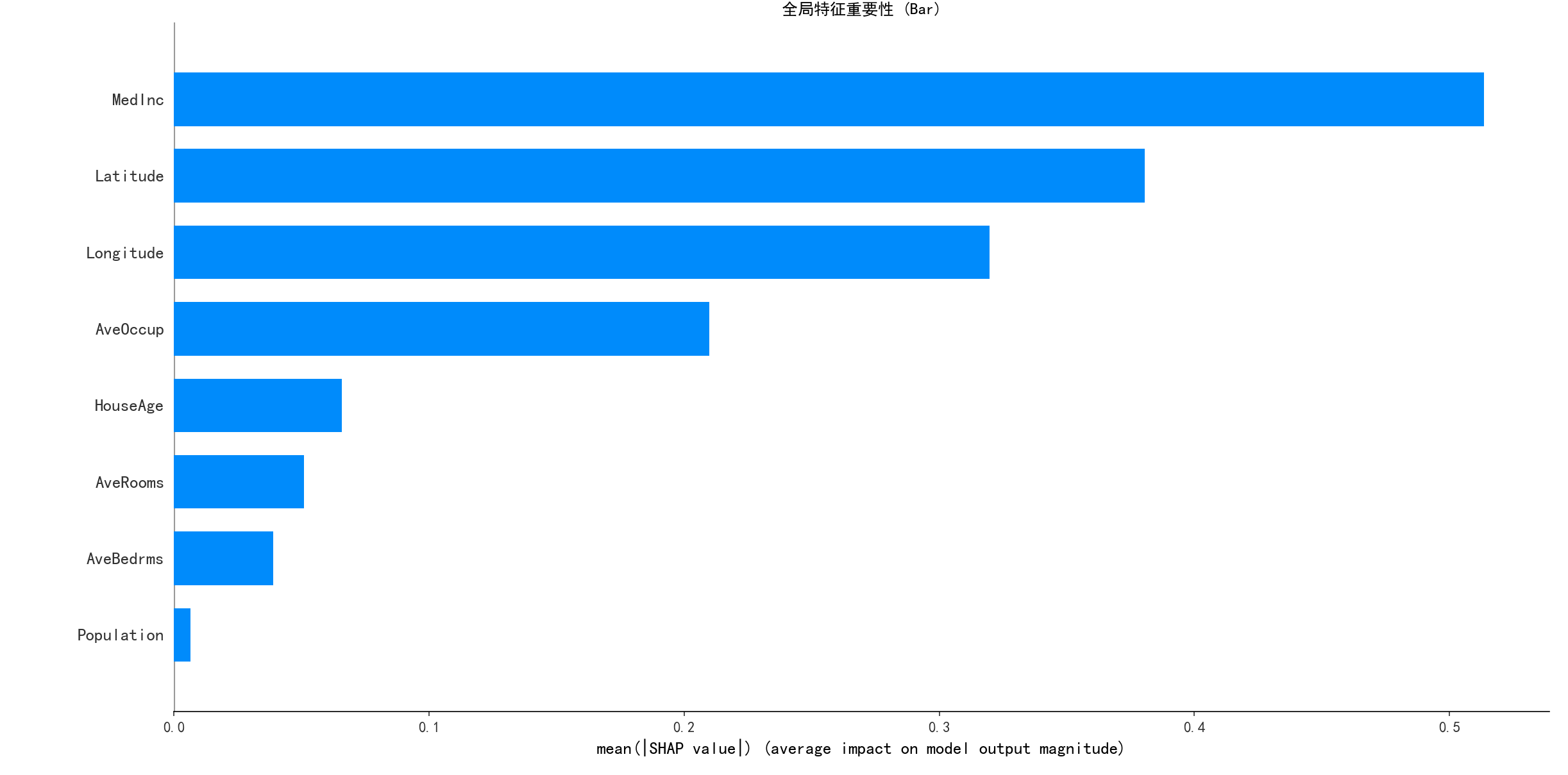
- 解读 : 这张图告诉我们,在全局 来看,哪个特征对模型的贡献最大。它将每个特征在所有样本上的 SHAP 值的绝对值 取平均。从图中可知,
MedInc(收入中位数) 是最重要的特征,其次是AveOccup(平均入住人数)。
2. 特征影响分布 (Beeswarm Plot)
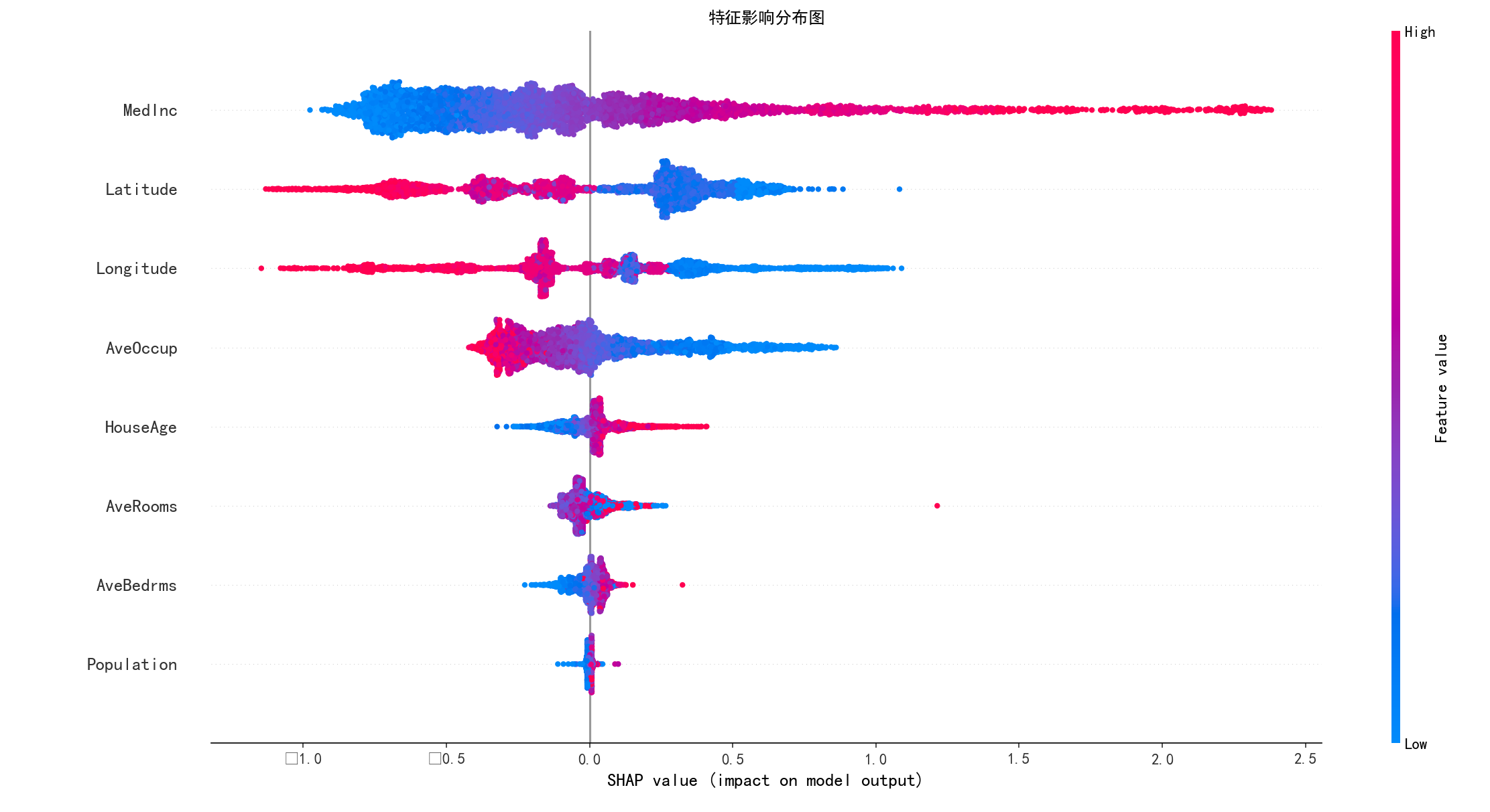
- 解读 : 这是 SHAP 最强大、信息量最丰富的图!
- 垂直方向: 特征的重要性排序,与 Bar Plot 一致。
- 水平方向 : SHAP 值。正值表示该特征将预测结果推高 ,负值表示推低。
- 点的颜色: 特征的原始值大小。红色表示值高,蓝色表示值低。
- 综合分析 : 以
MedInc为例,红色的点(高收入)基本都在 SHAP 值的正半轴,说明收入越高,房价预测越高 ,这符合常识。而AveOccup则相反,红色的点(高入住人数)多在负半轴,说明平均入住人数越多,房价预测越低。
3. 局部解释 (Force Plot)
- 解读 : 这张图精妙地展示了对于单个样本 ,模型是如何做出决策的。
base value(基准值): 2.069,是所有训练样本预测的平均房价。output value(预测值): 0.69,是模型对这个样本的最终预测房价。- 红色部分 : 将预测推高 的特征。如
Latitude、HouseAge。 - 蓝色部分 : 将预测推低 的特征。如
MedInc、AveRooms。 - 综合分析 : 对于这个样本,虽然它的
MedInc很低(蓝色,拉低房价),但由于其他特征(如Latitude)的综合作用,最终预测值比基准值要低。所有红色和蓝色力量的"合力",将预测从base_value推到了最终的output value。
四、总结与心得
今天的学习,是一次从"术"到"道"的深刻体验,收获巨大:
- 编程的"第一性原理" : 我深刻地认识到,与其在报错的海洋里挣扎,不如回归本源,理解数据的
shape和函数的 I/O。这个看似简单的习惯,是串起所有复杂技术、解决未知问题的万能钥匙。 - 解释性的力量: SHAP 让我第一次"看清"了黑箱模型的内部世界。它不仅给出了"哪个特征重要"的全局视图,更能"因人而异"地给出每个预测的详细归因,这在金融风控、医疗诊断等高风险领域是无价的。
- 从抽象到具象的智慧: "奶茶店分钱"的比喻,将高深的博弈论思想变得触手可及。这让我明白,掌握一个复杂概念最好的方式,就是找到一个恰当的、生活化的类比。
- 对错误的敬畏与利用: 课程中反复强调的"代码跑不通"问题,让我不再视错误为洪水猛兽,而是将其看作一次深入理解库版本、环境差异和代码内在逻辑的绝佳机会。
感谢 @浙大疏锦行 老师带来的精彩一课!这不仅是关于 SHAP 的课程,更是关于如何成为一个更优秀的思考者和问题解决者的课程。