1、 数据结构
存储西瓜的数据结构,需要对下列数据执行 添加、删除、修改、查询、导入、导出、复制(整体复制、复制其中一个模式)、版本比对、抽取块参数等操作,以及后续扩展块参数、扩展块参数中具体参数。
数据结构样例:
{
"id":"自增id"
"name": "名称",
"data": {
"version": "版本号",
"Watermelon_name": "QL-1",
"mode_params": [
{
"mode": "麒麟",
"color": "颜色",
"texture": "纹理",
"shape": "形状",
"params": {
"color_params": {
"id": "标识",
"code": "代号"
},
"texture_params": {
"atten": "日光"
},
"shape_params": {
"dev1_params": {
"common_params": {
"work_mode": "椭圆"
},
"common1_params": {
"bit_rate": "生长周期"
}
}
}
}
},
{
"mode": "黑美人",
"color": "颜色",
"texture": "纹理",
"shape": "形状",
"params": {
"color_params": {
"id": "标识",
"code": "代号"
},
"texture_params": {
"atten": "日光"
},
"shape_params": {
"dev1_params": {
"common_params": {
"work_mode": "椭圆"
},
"common1_params": {
"bit_rate": "生长周期"
}
}
}
}
},
{
"mode": "硒砂瓜",
"color": "颜色",
"texture": "纹理",
"shape": "形状",
"params": {
"color_params": {
"id": "标识",
"code": "代号"
},
"texture_params": {
"atten": "日光"
},
"shape_params": {
"dev1_params": {
"common_params": {
"work_mode": "椭圆"
},
"common1_params": {
"bit_rate": "生长周期"
}
}
}
}
},
{
"mode": "早春红玉",
"color": "颜色",
"texture": "纹理",
"shape": "形状",
"params": {
"color_params": {
"id": "标识",
"code": "代号"
},
"texture_params": {
"atten": "日光"
},
"shape_params": {
"dev1_params": {
"common_params": {
"work_mode": "椭圆"
},
"common1_params": {
"bit_rate": "生长周期"
}
}
}
}
}
]
}
}2、 MySQL和PostgreSQL处理该数据结构的比对
2.1 当前表结构与 PG数据结构的比对
当前MySQL通过5张表实现上述功能,西瓜版本表、西瓜描述表、西瓜A模式表、西瓜B模式表、西瓜C模式表。
采用PG后采用 西瓜版本表、西瓜内容表。
采用PG的优点在于,
其一 MySQL5张表互有连接,且查询西瓜模式表时,需要先查询西瓜版本表和西瓜描述表才能对后续表做定位,新增、导入等操作也需要执行多条sql,操作复杂。而PG使用JSON操作即可,最多两级查询;
其二 扩展性上 当增加块参数或者增加块参数中的具体参数,需要将数据导出,操作实际的back.sql,再进行导入。而PG执行JSON的插入操作即可。
2.2 MySQL和PG同时使用JSON存储数据结构的比对
1)、查询语法繁琐:要查询数组里的对象,必须使用 JSON_EXTRACT 配合复杂的路径,或者在 8.0+ 使用 JSON_TABLE 把 JSON 展开成虚拟表,SQL 语句会写得非常长且难懂。
2)、性能瓶颈:如果你直接查 JSON_EXTRACT(data, '$.mode_params0.params...'),MySQL 无法使用索引(除非你提前建好虚拟列)。
3)、虚拟列维护噩梦:如果你有几百颗,且查询条件可能变(今天查 黑美人,明天查 麒麟),你无法为每一个可能的路径都创建虚拟列。一旦没建索引,查询就是全表扫描,几百颗星的数据量虽然不大,但 JSON 解析的 CPU 开销会很高。
3、实验环境
python+fastapi+TORTOISE_ORM
4、 PG 对JSON 操作
| `->` | 获取 JSON 对象的值 | `data->'name'` | 结果带引号,仍是 JSON 类型 |
| `->>` | 获取 JSON 对象的文本值 | `data->>'name'` | 结果不带引号,是文本 |
| `#>` | 按路径获取 JSON 对象 | `data#>'{a,b}'` | 等同于 `data->'a'->'b'` |
| `#>>` | 按路径获取文本值 | `data#>>'{a,b}'` | 最常用,用于获取深层嵌套的值 |
| `jsonb_array_elements()` | 展开 JSON 数组 | `jsonb_array_elements(arr)` | 把数组变成多行,用于查询数组内部 |
4.1 查询 json中的字符串
SELECT name, data->>'version' AS a_version FROM student;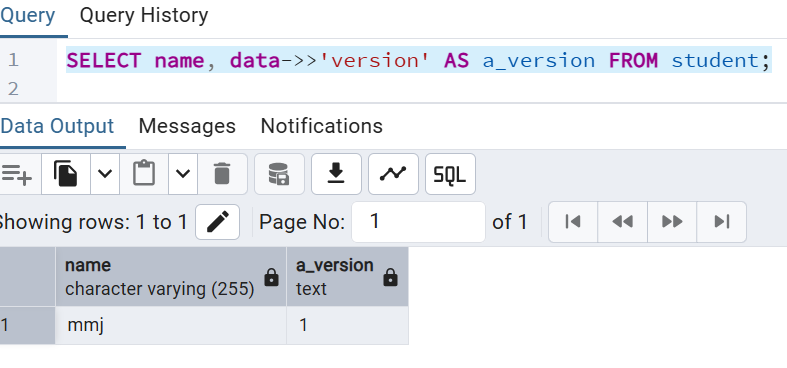
4.2 查询 json中的jsonarry
#单个箭头是取出json
SELECT name, data->'mode_params' AS mode_params FROM student;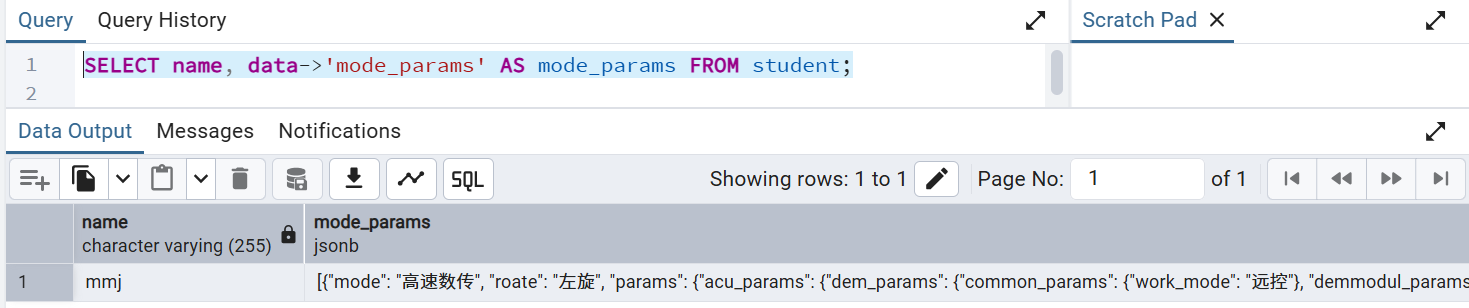
4.3 查询 json中的jsonobject
SELECT name, data->'mode_params'->0->'params' AS params FROM student;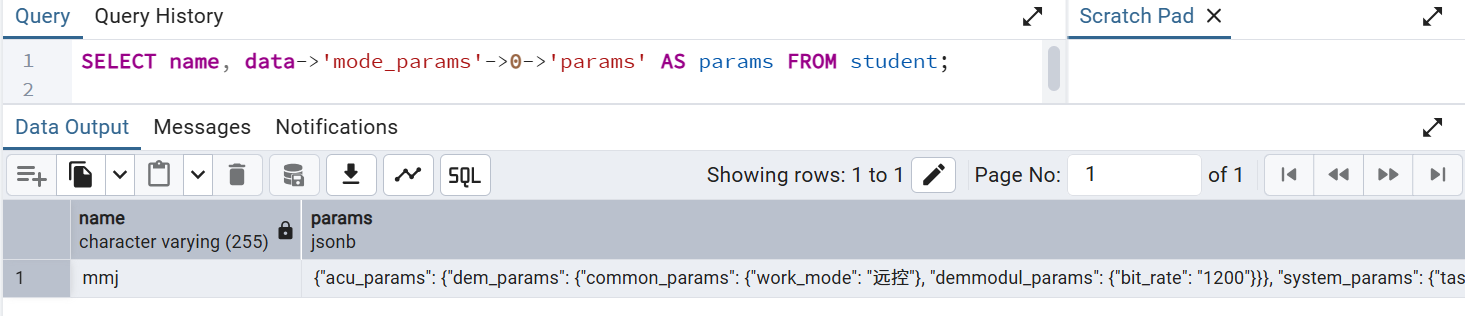
4.4 查询 json中的jsonobject中的字符串
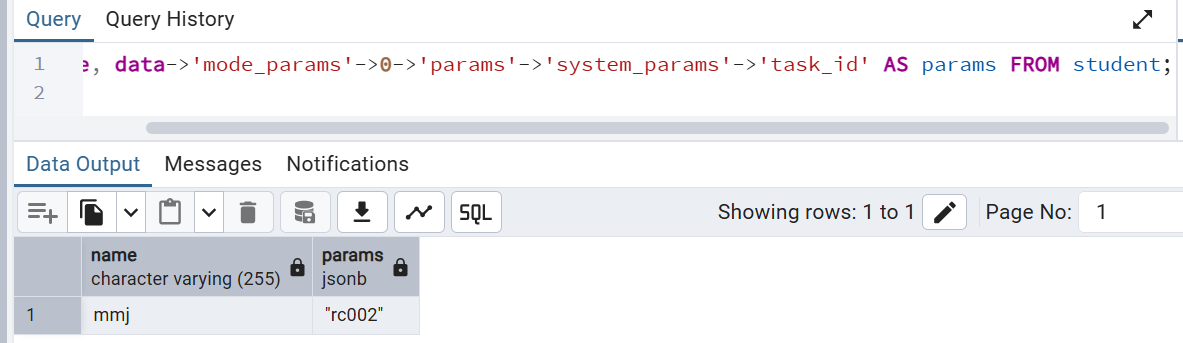
SELECT name, data->'mode_params'->0->'params'->'system_params'->'task_id' AS params FROM student;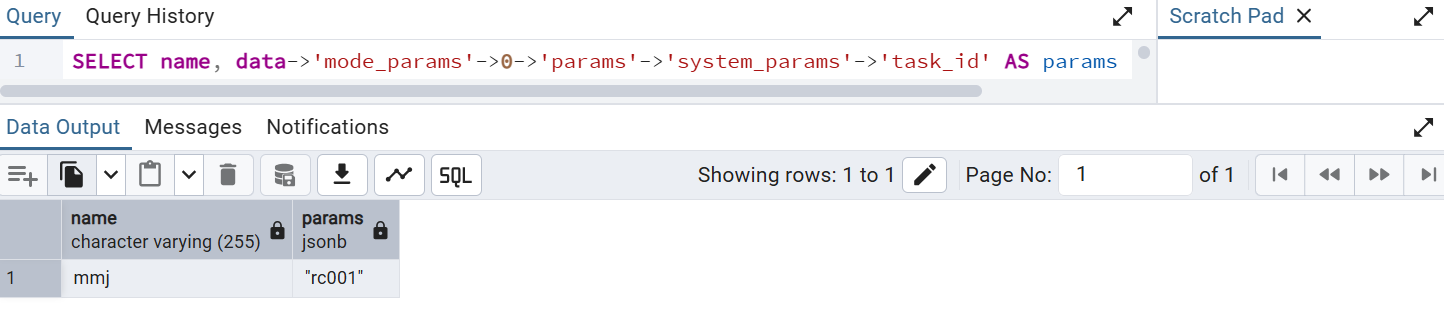
4.5 修改参数
postgresql 通过mode = 高速数传 freBand = x 去匹配修改system_params中的task_id 为rc002
UPDATE satellites
SET data = jsonb_set(
data,
'{mode_params}', -- 路径:我们要替换整个 mode_params 数组
(
SELECT jsonb_agg(
-- 3. 重新将处理后的元素聚合成一个新的 JSON 数组
CASE
-- 1. 找到符合条件的元素(mode=高速数传 且 freBand=X)
WHEN elem->>'mode' = '高速数传' AND elem->>'freBand' = 'X' THEN
-- 2. 修改这个元素:更新其内部的 system_params.task_id
jsonb_set(
elem,
'{params,system_params,task_id}',
'"rc002"' -- 这里填你要更新的值,注意必须是 JSON 格式(带引号)
)
ELSE
-- 不符合条件的元素,保持不变
elem
END
)
FROM jsonb_array_elements(data->'mode_params') AS elem
-- 从原数据中取出 mode_params 数组并展开
)
)
-- 可选:加一个 WHERE 条件,确保该数组中确实包含我们要找的对象,提高效率
WHERE data @> '{"mode_params": [{"mode": "高速数传", "freBand": "X"}]}';//查询 结果
4.6 扩展参数
UPDATE student
SET data = jsonb_set(
data,
'{mode_params}',
(
SELECT jsonb_agg(
elem || '{"new_key": "new_value"}' -- 使用 || 操作符合并 JSON
)
FROM jsonb_array_elements(data->'mode_params') AS elem
)
)5、 PG 总结
对于新手来说,PG修改SQL比较难上手,需要有一定的基础,并且使用时需要注意使用GIN以提高索引效率。
但对于本类数据结构,PG在查询块参数,扩展方面有绝对优势,针对修改局部参数SQL情形复杂的问题,采用前台发过来的数据整体覆盖旧JSON方式解决。