导读
在现实世界中,让 AI 通过一张照片理解物体的完整三维结构,长期被视为计算机视觉最硬的难题之一。
因为自然图像中,遮挡、远景、小物体、复杂背景几乎随处可见------要从有限的像素信息"还原出"一个完整的 3D 模型,难度不亚于让人蒙着眼拼乐高。然而,人类视觉并不依赖多视角。心理学研究早就发现:
人类可以依靠"熟悉物体线索"、纹理变化、阴影和上下文,从单张图像推断立体结构。
识别,就是重建的开始。
这一次,Meta Superintelligence Labs 把这一洞察转化成了真正可落地的模型:
他们提出 SAM 3D ------ 一个能够从单张自然图像中重建物体形状、纹理与布局的生成模型,并且在遮挡严重、场景复杂的真实图片中依然表现稳健。
在大规模"人类 + 模型"协作的数据引擎支持下,他们"打破了 3D 数据壁垒",让单图 3D 真正走向现实。
最终效果如图 1 所示:不仅能复原物体,还能直接生成可编辑、可组合的 3D 场景。他们用 SAM 3D,让"从图到三维"成为可能**。**
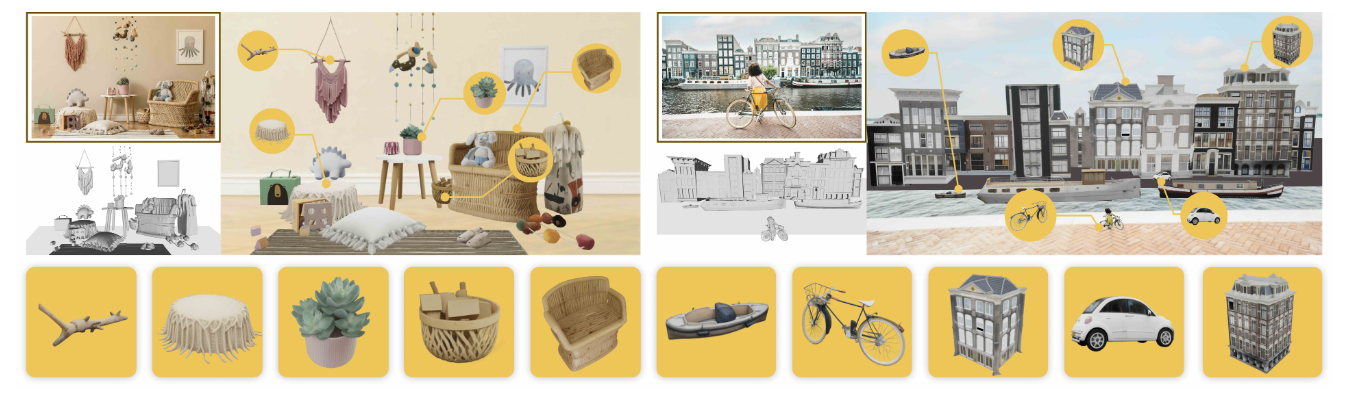
图1|SAM 3D 能将单张图像转化为可编辑的 3D 场景,每个物体都具备独立的几何、纹理与空间布局。下方展示的是模型为各个物体恢复出的高质量 3D 资产
*论文出处:*arXiv
*论文标题:*SAM 3D: 3Dfy Anything in Images
*论文作者:*SAM3D TEAM
论文链接:**https://ai.meta.com/research/publications/sam-3d-3dfy-anything-in-images/

研究团队发现,传统单图 3D 模型的瓶颈不在模型本身,而在数据。
真实世界里的 3D 数据极度稀缺,尤其是"自然图像 + 真实物体完整三维结构"的配对数据------几乎不存在。

图2|SAM 3D 使用的数据示例。绿色框标出目标物体,右下角给出对应的 3D 艺术家标注的真实 mesh。数据被分为四类:其中 Art-3DO 不含纹理,其余样本根据原始资产来源(Iso-3DO、RP-3DO)或是否被标注过纹理(MITL-3DO),可能带有纹理或不带纹理
这让以往方法不得不主要依赖孤立的、干净的、单物体 synthetic 数据,在真实复杂场景里往往失效。于是团队做了件大胆的事情:
第一步:用识别能力作为 3D 的"入口"
如果 AI 能先识别物体,那么它就能选出可能的 3D 形状并生成对应布局。
这和心理学中的"熟悉物体线索"完全一致:认出来什么,它就能推断其三维结构。
第二步:打造一个"模型与人类循环协作"的数据引擎
他们构建了一个前所未有的三阶段训练流程:
阶段 1:大规模 synthetic 预训练,让模型从海量渲染物体中学会"3D 词汇表"。
阶段 2:半合成场景 mid-training,将渲染模型"贴"到真实图片里,补齐真实世界的上下文感知。
阶段 3:人类 + 模型的 MITL(model-in-the-loop)后训练模型给出多个 3D 方案 →人类从中选择最像的一个 →硬例交给专业 3D 艺术家 →再喂回模型 →模型更强 →再生成更好的候选形状......一个闭环数据工厂就此建立。
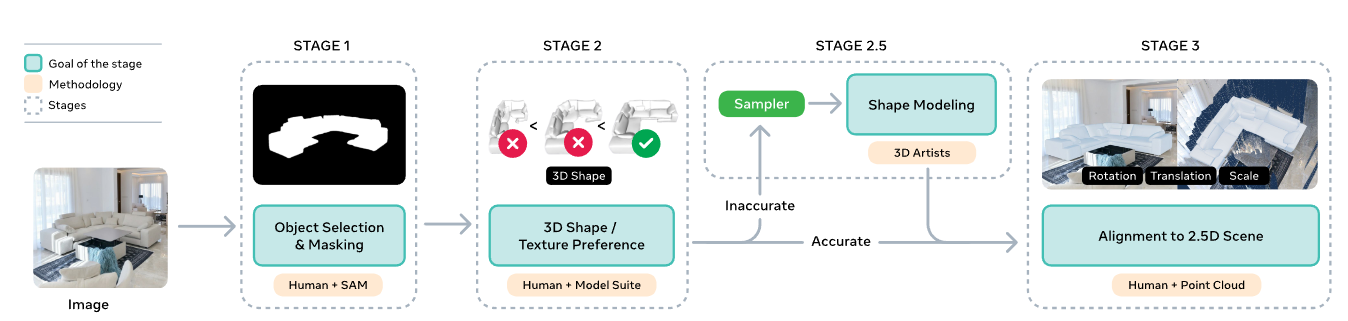
图3|数据引擎中一个样本的完整处理流程。团队将标注工作拆成多个子任务:首先选择目标物体(阶段 1),再由模型生成候选 3D 形状供人类排序与挑选(阶段 2),最后在 2.5D 场景中为物体调整姿态(阶段 3)。阶段 2 和 3 均采用 model-in-the-loop 协作方式
第三步:多阶段训练让模型逐步接近"专家人类"表现
最终,SAM 3D 能从单张自然图像推断出:
● 完整三维几何
● 物体纹理
● 真实场景中的相对布局(translation + scale + rotation)
并且可以自由重新渲染、组合成全新 3D 场景。
这就是 SAM 3D 的故事:
用识别驱动重建,靠人类与模型共同进化**。**

大规模 MITL 数据引擎,真正攻克"3D 数据缺乏"
以往单图 3D 最大的难点,是自然图像缺少对应 3D GT。
SAM 3D 的解决方式是构建一个"会自己变强的数据引擎"。
● 模型先生成多个可能的 3D 候选。
● 人类选择最像的一个,并微调其姿态。
● 难例交给 3D 艺术家精修,形成高质量标签。
● 新标签再喂回模型,使下一轮预测更稳定。
这种循环方式让数据质量与数量同步增长,"越标越准",打破了行业长期卡在小规模 3D 数据集的瓶颈。
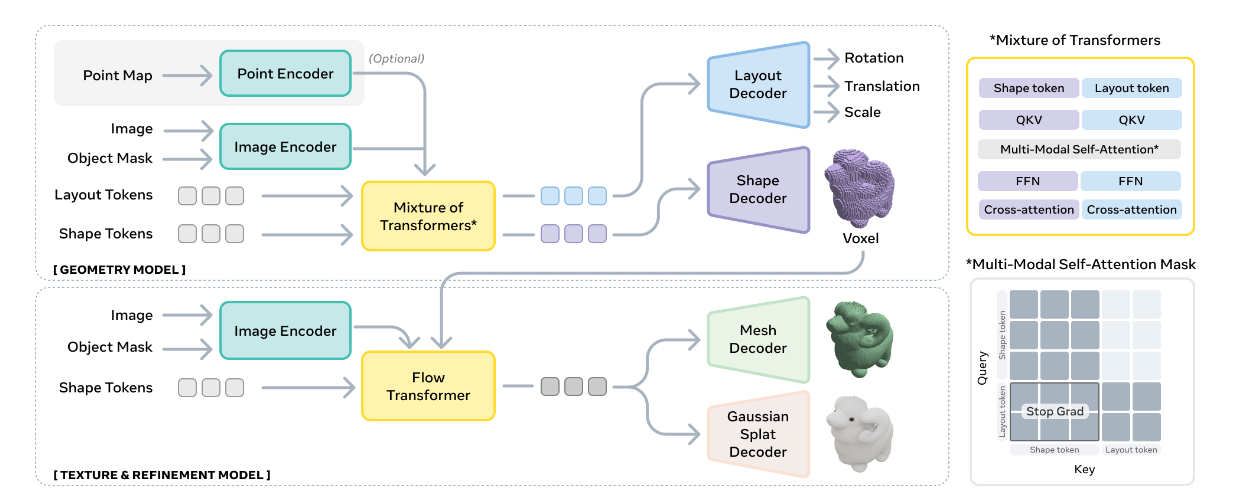
图4|SAM 3D 的整体架构:上方为负责预测粗略形状与布局的 Geometry 模型;右侧展示了双流 Transformer 的信息交互方式;底部为 Texture & Refinement 模型,它在粗几何基础上补充更高分辨率的细节与纹理
多阶段训练策略:从 synthetic 到自然图像的真正迁移
SAM 3D 的训练流程借鉴了大模型(LLM)的"分阶段训练"思路:
● synthetic 预训练:学习基础几何与纹理表达
● mid-training:让模型适应真实世界背景与遮挡
● 后训练 SFT:从 MITL 生成的数据中获得真实物体感知能力
● DPO:直接对齐人类"偏好",压制常见错误(如无底 mesh、奇怪对称性)
● distillation:让推理速度从几十步优化到几步
每一步都带来清晰可见的性能提升,最终形成稳定的真实世界建模能力。
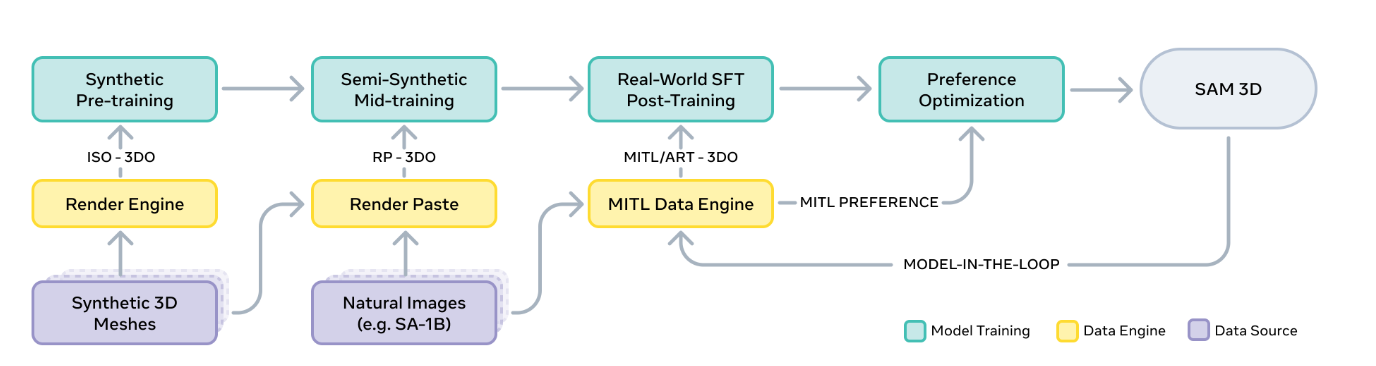
图5|SAM 3D 的多阶段训练方式。模型会按照由浅入深的顺序,逐步接触更复杂的数据与模态,实现真实场景下的稳定重建能力
单图 → 多物体 → 全场景:真正意义上的 3D Reconstruction Foundation Model
和传统"单物体重建"不同,SAM 3D 能直接输出整个场景的多物体组合:
● 每个物体都有独立的 mesh 与 texture
● 能预测物体布局
● 最终得到可组合、可编辑的完整场景 3D 资产
这意味着它不仅能重建一个杯子,还能重建:
桌子上的杯子 + 旁边的书 + 背后的椅子
并能从任意视角重新渲染。这几乎将单图 3D 带到了"生成式场景建模"的新阶段。

图6|与主流单图像 3D 重建方法的对比。基于 SA-3DAO 的艺术家标注几何作为参考,SAM 3D 在单物体形状重建上展现出更高的完整度与稳定性。对比方法包括 Trellis、Hunyuan3D-2.1、Direct3D-S2 与 Hi3DGen

在真实世界的评测中,SAM 3D 的整体表现呈现出非常突出的领先趋势。无论是在重建单个物体,还是在复杂场景中恢复多个物体的几何、纹理与布局,它都显著优于以往方法。在人类偏好测试中,SAM 3D 的重建结果被压倒性地选择为更自然、更接近真实物体,尤其是在真实图片的遮挡、远距离拍摄或杂乱背景下,它能够恢复出更完整的三维结构,而其他方法常出现形状断裂、不闭合或丢失细节的问题。
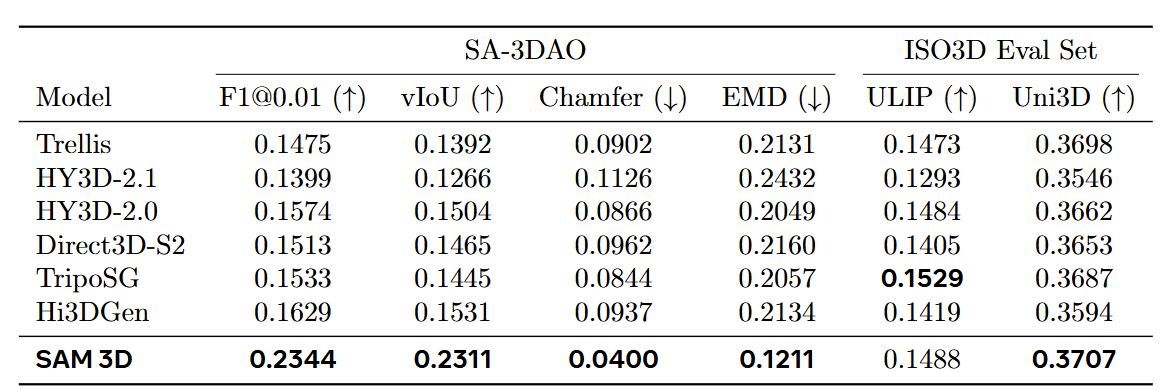
图7|单物体 3D 形状对比实验。SAM 3D 在真实自然图像(SA-3DAO)上的几何精度显著领先,同时在 ISO3D 上也展现出良好表现。TripoSG 使用了更高分辨率的 mesh,在感知类指标上有额外加成
即使将所有方法的几何统一替换成 SAM 3D 的结果,仅比较纹理生成,人类依旧明显更偏好 SAM 3D 的纹理,表明其材质恢复同样具备优势。在物体布局任务中,无论是 SA-3DAO 这样的真实自然图像集合,还是 Aria Digital Twin 这类带有深度信息的评价集,SAM 3D 的布局预测始终更接近专业 3D 艺术家的结果,优于传统的 pipeline(如 3D 形状 + Megapose 或 FoundationPose)以及其他联合建模方法,表现为旋转角度更准确、尺寸比例更合理、物体位置更贴合实际拍摄场景。更重要的是,随着数据引擎(MITL)不断迭代,模型表现呈现持续的稳定提升,几乎每扩大一轮真实世界数据,模型都能获得更加明显的增益。
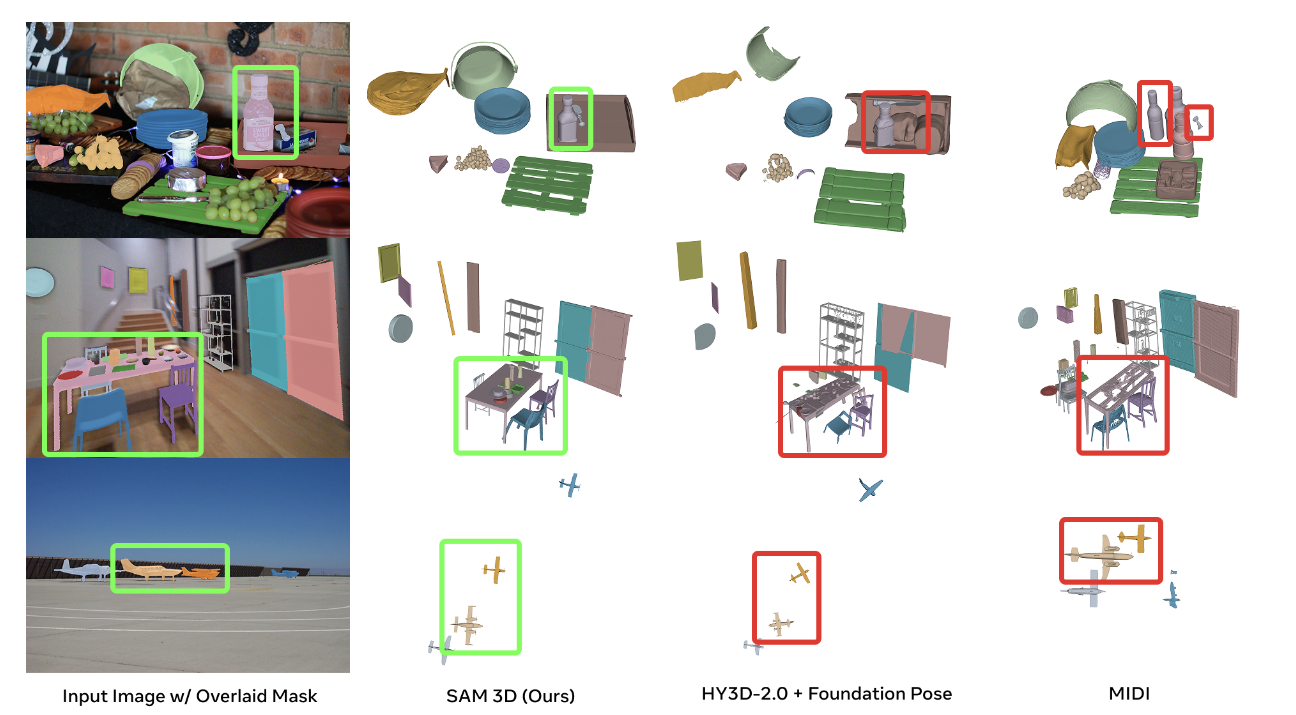
图8|与其他方法的场景级 3D 重建对比。SAM 3D 能从单张图像生成完整的多物体场景几何,在复杂真实场景中明显优于现有方法
总体来看,无论从主观偏好、几何指标、纹理质量、还是多物体布局准确性,SAM 3D 都在真实场景中展现出前所未有的强大重建能力
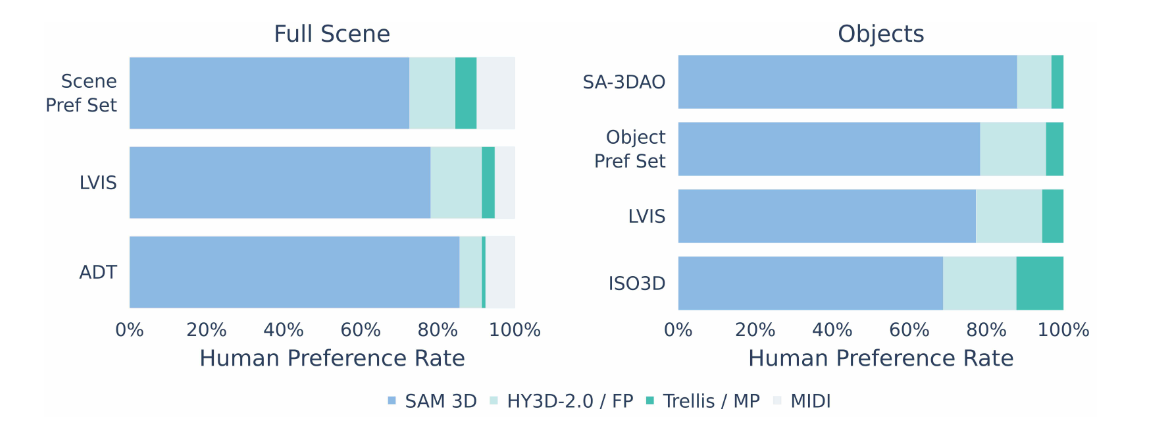
图9|场景级与物体级的人类偏好测试。无论是单物体还是场景整体,SAM 3D 的重建结果都被人类显著地更常选中,体现其更贴近真实视觉感知

SAM 3D 的出现,标志着单图 3D Reconstruction 正式跨过关键门槛:
从"只能在干净场景里玩"--------走向"在真实自然图像中稳定可用"
这背后不是模型结构的花活,而是一个成熟的方向:
数据引擎 + 分阶段训练
正在成为 3D、视觉、机器人方向的新范式。随着代码、权重与在线 Demo 的发布,这个模型有望加速 AR/VR、机器人、影视资产生成、游戏开发等一系列三维应用的落地。
那么你觉得,未来的 3D 生成模型,会不会像 LLM 一样成为新的"通用基础设施"?