自动驾驶技术的核心诉求是让车辆在复杂动态的交通环境中,实现感知、决策与控制的闭环协同。传统模块化方案通过拆分感知、预测、规划、控制等独立模块实现功能,但模块间的信息割裂导致其在长尾场景(如突发的救护车避让、道路施工临时管制)和人机交互场景中表现脆弱。近年来,多模态大语言模型(MLLM)的爆发式发展,推动了视觉 - 语言 - 动作(Vision-Language-Action, VLA)范式的出现 ------ 这种将视觉感知、自然语言理解与控制指令融合于单一模型的架构,为解决自动驾驶的 "可解释性" 与 "动作闭环" 难题提供了全新思路。
本文将对首篇全面覆盖自动驾驶领域 VLA 范式的综述论文《A Survey on Vision-Language-Action Models for Autonomous Driving》进行深度精读,系统拆解 VLA4AD(Vision-Language-Action for Autonomous Driving)的技术演进、架构设计、数据集、训练评估方法、核心挑战与未来方向。
原文链接:https://arxiv.org/pdf/2506.24044
代码链接:https://github.com/JohnsonJiang1996/Awesome-VLA4AD
沐小含持续分享前沿算法论文,欢迎关注...
一、自动驾驶技术的四阶段演进
论文将自动驾驶技术的发展划分为四个核心范式,清晰展现了从 "模块化拆分" 到 "多模态融合闭环" 的演进逻辑,下图展示了三个核心范式(除了经典模块化流水线范式)。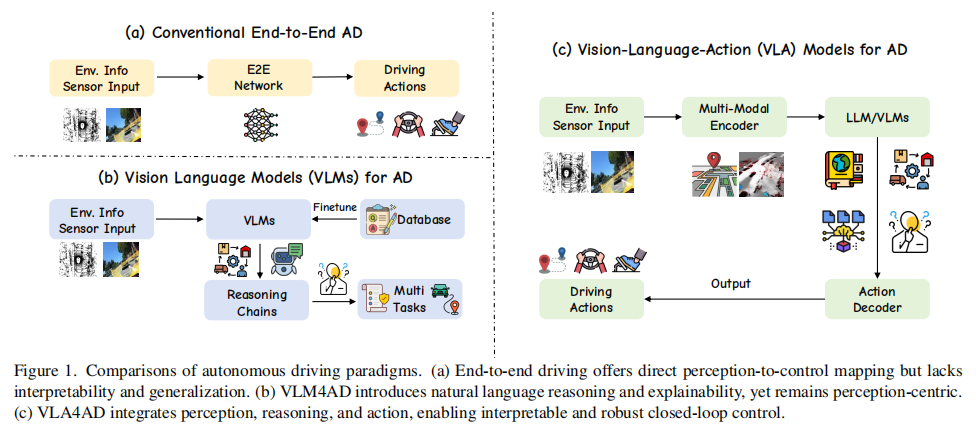
图 1 自动驾驶范式对比:(a) 端到端方案直接映射感知到控制,但缺乏可解释性;(b) VLM4AD 引入语言推理,但未闭环动作;(c) VLA4AD 融合感知、推理、动作,实现可解释的闭环控制。
1.1 经典模块化流水线(Classical Modular Pipelines)
这是自动驾驶的早期主流方案,以 DARPA 城市挑战赛中的车辆为代表,将驾驶任务严格拆分为感知、预测、规划、控制四个独立模块:
- 感知模块:通过 LiDAR、雷达、摄像头等传感器识别道路目标(如车辆、行人、交通灯);
- 预测模块:基于历史轨迹预测其他交通参与者的未来行为;
- 规划模块:通过有限状态机或图搜索生成可行路径;
- 控制模块:通过 PID 或 MPC 算法执行转向、油门、刹车指令。
优势 :模块化设计便于单独调试、测试和优化,在工业界得到广泛应用;缺陷:模块间信息割裂,上游误差会逐级传播(如感知漏检会导致规划决策失误),且难以处理需要跨模块推理的长尾场景。
1.2 端到端自动驾驶(End-to-End Autonomous Driving)
为解决模块化方案的信息损失问题,端到端方案直接将原始传感器数据映射为控制指令,跳过手工设计的中间模块(如图 1 (a) 所示):
- 核心逻辑:以 "视觉 - 动作(VA)" 为核心,通过神经网络学习从传感器输入到驾驶动作的端到端映射;
- 代表性方法:
- UniAD:基于栅格化表示(语义图、占用图等)实现多任务融合,但计算开销大;
- VAD:采用全向量化场景表示,以更高效率实现端到端规划;
- PolarPoint-BEV:通过极坐标点编码优化 BEV 表示,增强对不同距离目标的关注度;
- 优化方向:为缓解数据稀疏性和解空间过大问题,部分方法引入中间监督(如集成感知 - 预测任务)、图结构建模(GraphAD)、稀疏架构(SparseAD)等。
优势 :减少模块间误差传播,简化系统设计;缺陷:
- 语义脆弱性:对罕见场景泛化能力差;
- 推理不透明:决策过程难以解释,不利于安全审计;
- 缺乏语言交互能力:无法理解人类自然语言指令。
1.3 自动驾驶视觉语言模型(VLMs for Autonomous Driving)
为增强端到端模型的可解释性和泛化能力,研究者将视觉语言模型(VLM)引入自动驾驶,形成 "视觉 - 语言(VL)" 融合方案(如图 1 (b) 所示):
- 核心逻辑:通过大规模图文预训练,让模型学习 "像素 - 文本" 的对齐关系,既能完成感知任务,又能生成自然语言解释;
- 典型应用:
- 场景解释:如描述 "救护车正在超车,需避让";
- 决策 justification:如解释 "因红灯亮起而停车";
- 长尾场景泛化:利用 VLM 的常识知识识别罕见目标(如施工标志、特殊车辆)。
优势 :提升可解释性和零样本泛化能力;缺陷:仍为 "感知 - centric",语言输出与控制指令松耦合 ------ 模型仅能解释场景,无法直接生成驾驶动作,且存在语言幻觉(如虚构 hazards)或口语指令误解问题,未解决 "动作鸿沟"(action gap)。
1.4 自动驾驶视觉 - 语言 - 动作模型(VLA4AD)
这是当前最前沿的范式,将视觉感知、语言理解、动作控制融合于单一政策网络(如图 1 (c) 所示),实现 "感知 - 推理 - 动作" 的闭环:
- 核心突破:引入 "动作头(Action Head)",让语言不仅用于解释,更直接指导决策和控制;
- 三大核心能力:
- 遵循自由形式指令:如 "避让救护车""在超市门口停车";
- 生成决策理由:实时输出自然语言解释(如 "前方有行人横穿,减速避让"),便于事后验证;
- 长尾场景推理:利用互联网规模的图文预训练知识,处理未见过的场景(如道路临时施工、行人手势指挥)。
技术驱动因素:
- 数据支撑:nuScenes、Impromptu VLA 等大规模多传感器数据集提供丰富监督;
- 模型效率优化:LoRA 等低秩适配技术、TS-VLM 等 token 缩减设计降低大模型部署开销;
- 合成数据与交互数据集:SimLingo、NuInteract 等支持在仿真环境中测试语言条件下的驾驶行为。
二、VLA4AD 的核心架构设计
VLA4AD 的架构核心是 "多模态输入 - 跨模态融合 - 动作输出" 的端到端流水线,论文将其拆解为三大模块:多模态输入与语言指令、核心架构模块、驾驶输出,具体如下:
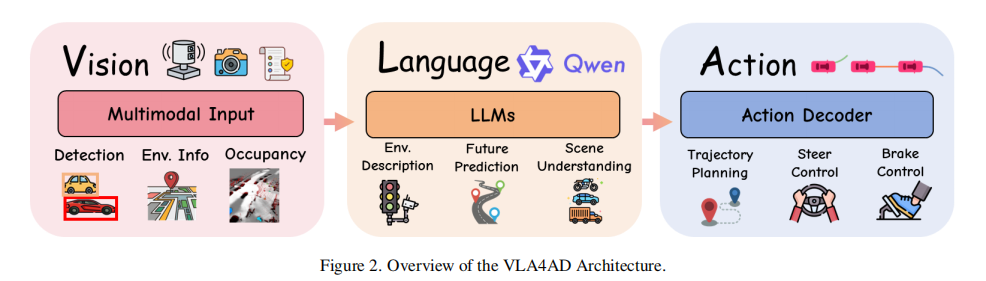
图 3 VLA4AD 模型演进:从左到右依次为(1)语言仅作为解释器;(2)模块化 VLA,语言指导规划;(3)端到端 VLA,直接映射输入到动作;(4)推理增强型 VLA,融合工具使用和 CoT 推理。
2.1 多模态输入与语言指令
VLA4AD 需要同时捕捉环境状态和人类意图,输入包含三类关键信息:
(1)视觉数据(Visual Data)
- 演进路径:从单目前视摄像头→立体摄像头→多视角环视系统,逐步提升空间覆盖能力;
- 表示形式:
- 原始图像:直接输入神经网络处理;
- 结构化表示:通过 BEV(鸟瞰图)投影将 2D 图像转换为 3D 空间特征,便于空间推理;
- 动态适配:部分模型(如 DynRsl-VLM)可根据场景动态调整输入分辨率,平衡实时性和细节捕捉。
(2)其他传感器数据(Other Sensor Data)
- 几何传感器:LiDAR(提供精确 3D 结构)、雷达(测速)、GPS(定位);
- 动态传感器:IMU(惯性测量单元,捕捉车辆运动状态)、 proprioceptive 数据(转向角、油门、加速度,用于行为预测和闭环控制);
- 融合目标:构建 "空间 - 时间" 统一表示,弥补单一传感器的局限性(如 LiDAR 抗雨雾能力强,摄像头语义识别优)。
(3)语言输入(Language Inputs)
语言是人机交互和常识推理的核心,其形式随技术演进不断丰富:
- 基础指令:导航命令(如 "下个路口左转""红灯停车");
- 环境查询:交互式问题(如 "现在变道安全吗?""当前限速多少?");
- 任务级描述:交通规则解析、高层目标定义(如 "避开施工区域,选择最短路线");
- 高级形式:多轮对话、思维链(CoT)提示、工具增强语言接口,甚至语音输入(通过语音识别转换为文本)。
2.2 核心架构模块
核心模块负责将多模态输入融合为统一特征,并映射到动作空间,包含三大组件:
(1)视觉编码器(Vision Encoder)
- 骨干网络:采用自监督预训练模型(如 DINOv2、ConvNeXt-V2、CLIP)提取视觉特征;
- 3D 增强:部分模型引入点云编码器(如 PointVLA)或体素模块(3D-VLA),直接处理 LiDAR 的 3D 点云数据;
- 多尺度融合:通过语言引导的注意力机制,让视觉编码器聚焦于与任务相关的区域(如 "救护车""行人")。
(2)语言处理器(Language Processor)
- 基础模型:采用预训练大语言模型(如 LLaMA2、GPT 系列、Qwen)处理文本输入;
- 适配策略:
- 指令微调:通过 Visual Instruction Tuning 注入驾驶领域知识;
- 高效适配:采用 LoRA 等低秩更新技术,在不微调全部参数的情况下适配大模型;
- 检索增强:如 RAG-Driver,通过检索记忆库中的历史驾驶案例,辅助当前决策。
(3)动作解码器(Action Decoder)
动作解码器是 VLA4AD 与 VLM4AD 的核心区别,负责将融合特征映射为驾驶动作,主流实现方式有三种:
- 自回归 Tokenizer:将离散动作或轨迹关键点序列化为 token,逐次预测(如连续转向角离散为多个 token);
- 扩散模型头(Diffusion Heads):如 DiffVLA、Diffusion-VLA,通过扩散过程生成连续控制指令,适合处理不确定性场景;
- 分层控制器:如 ORION,由语言规划器生成子目标(如 "100 米后变道"),再由低 - level PID/MPC 控制器执行具体动作;
- 其他形式:Flow-matching、策略梯度(如 GRPO、DPO)等,用于强化学习优化的场景。
2.3 驾驶输出(Driving Outputs)
输出形式反映模型的抽象层次和应用场景,主要分为两类:
(1)低级别动作(Low-Level Actions)
- 直接输出:转向角、油门、刹车等原始控制信号;
- 表示形式:连续值或离散 token;
- 优势:细粒度控制,可直接对接车辆执行器;
- 缺陷:对感知误差敏感,缺乏长时域规划能力。
(2)轨迹规划(Trajectory Planning)
- 输出形式:BEV 或车辆坐标系下的未来轨迹(如未来 5 秒的路径点序列);
- 执行方式:通过 MPC 等下游规划器将轨迹转换为控制信号;
- 优势:稳定性强,可整合多模态上下文进行长时域推理(如预测 5 秒后车辆位置并规划避障路径)。
三、VLA4AD 的技术演进脉络
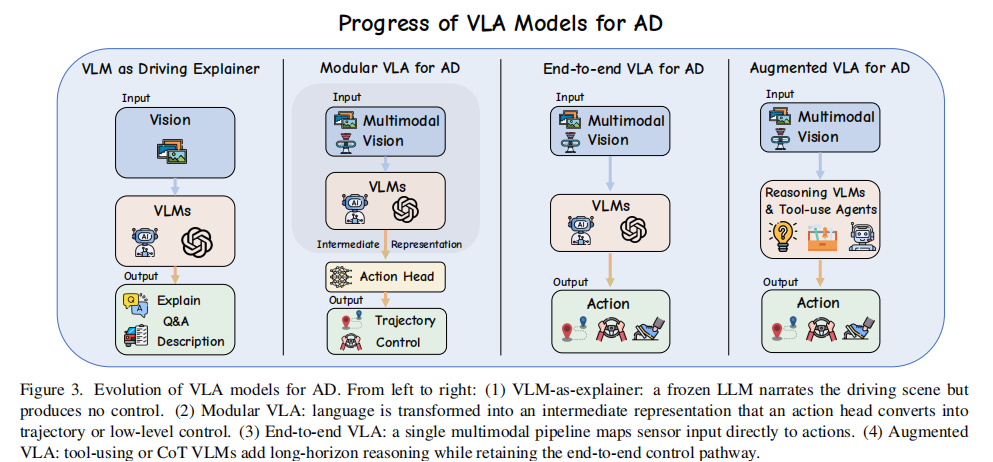
论文将 VLA4AD 的发展划分为四个阶段,清晰展现了 "语言从被动解释到主动决策核心" 的演进过程,如图所示:
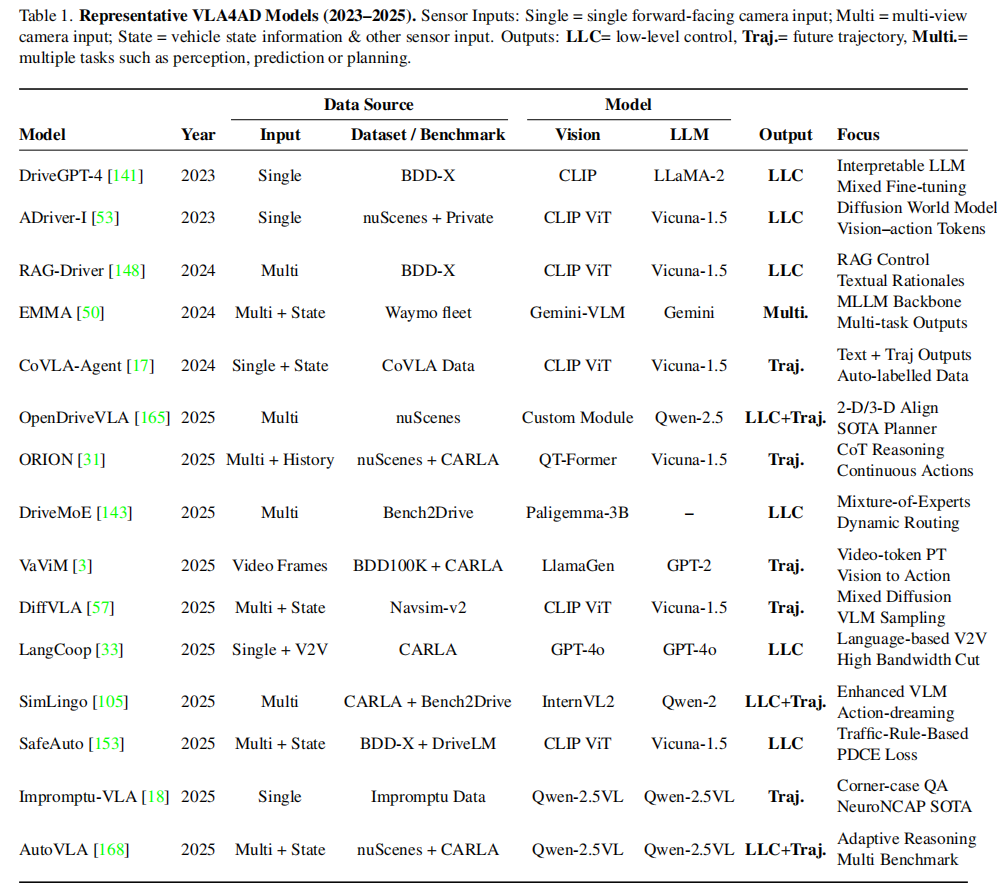
文中总结了2023-2025年期间具有代表性的VLA4AD模型(下表),阐述了其输入模态、语言整合方式、动作输出形式、评估所用数据或环境及其核心贡献。
3.1 前 VLA 阶段:语言模型作为解释器(Pre-VLA: Language Model as Explainer)
- 核心定位:语言仅用于场景解释,不参与决策;
- 典型方案:如 DriveGPT-4,通过冻结的 VLM(如 CLIP)提取视觉特征,再由 LLM 生成场景描述(如 "前方有行人横穿马路")或动作标签(如 "减速");
- 缺陷:
- 语言与控制脱节:实际驾驶动作仍由传统 PID 控制器执行,语言仅为 "附加解释";
- latency 问题:每帧生成长文本解释导致实时性差;
- 冗余计算:通用视觉编码器关注与驾驶无关的细节(如路边广告)。
- 优化方向:TS-VLM 通过文本引导的软注意力池化聚焦关键区域,DynRsl-VLM 动态调整输入分辨率,提升效率。
3.2 模块化 VLA4AD(Modular VLA4AD)
- 核心突破:语言成为规划模块的输入,直接指导决策,但仍依赖多阶段流水线;
- 典型方案:
- OpenDriveVLA:融合摄像头 / LiDAR 数据与文本路线指令(如 "在教堂处右转"),生成中间 waypoint(如 "20 米后右转,随后直行"),再转换为轨迹;
- CoVLA-Agent:将视觉 / LiDAR 特征与文本提示融合,通过 MLP 将动作 token(如 "左转")映射为轨迹;
- DriveMoE:采用混合专家(Mixture-of-Experts)架构,通过语言线索动态选择子规划器(如 "超车专家""跟车专家");
- SafeAuto:引入形式化逻辑表达的交通规则,验证并否决语言驱动的不安全规划。
- 优势:减少语言与动作的语义鸿沟,提升决策透明度;
- 缺陷:多阶段流水线导致 latency 增加,模块间误差传播风险仍存在。
3.3 端到端 VLA4AD(Unified End-to-End VLA4AD)
- 核心突破:将感知、语言理解、动作生成整合为单一可微分网络,实现 "输入→输出" 的直接映射;
- 典型方案:
- EMMA:在 Waymo 数据上训练大规模 VLM,联合执行目标检测和运动规划,共享特征表示;
- SimLingo/CarLLaVA:基于 LLaVA 在 CARLA 仿真环境中微调,引入 "动作梦境(action dreaming)" 技术 ------ 通过改变语言指令生成多样化轨迹,强化语言与动作的耦合;
- ADriver-I:通过扩散模型学习 latent 世界模型,预测动作对应的未来摄像头帧,实现 "通过想象后果进行规划";
- DiffVLA:融合稀疏(waypoint)和稠密(占用栅格)扩散预测,生成符合文本描述的安全轨迹。
- 优势:低 latency,无模块间误差传播,传感器 - 动作映射更直接;
- 缺陷:长时域推理能力弱,决策解释性不足。
3.4 推理增强型 VLA4AD(Reasoning-Augmented VLA4AD)
- 核心突破:将 LLM/VLM 置于控制闭环中心,引入记忆、思维链(CoT)推理,强化长时域规划和交互能力;
- 典型方案:
- ORION:结合 QTFormer 记忆模块(存储数分钟的观测和动作历史)与 LLM,生成轨迹和对应的自然语言解释;
- Impromptu VLA:在 8 万条长尾场景数据上训练,学习 "先推理后动作" 的逻辑 ------ 先 verbalize 决策路径(如 "前方施工,需减速并变道至左侧车道"),再生成动作;
- AutoVLA:将连续轨迹 token 化为离散 "驾驶 token",通过自回归 transformer 融合 CoT 推理和轨迹规划,在 nuPlan 和 CARLA 上实现 SOTA 闭环成功率。
- 优势:具备长时域推理、多轮交互和可解释性,接近人类驾驶决策逻辑;
- 挑战:需平衡 LLM 推理 latency 与 30Hz 以上的实时控制需求,且需验证语言推理的逻辑一致性。
四、VLA4AD 的数据集与基准测试
高质量数据集是 VLA4AD 发展的基础,论文整理了当前主流数据集,覆盖 "真实场景 - 仿真场景""普通场景 - 长尾场景""感知 - 推理 - 动作" 全维度,具体如下表所示(表 2):

数据集核心特点总结
- 真实性与仿真互补:BDD100K、nuScenes 提供真实场景多样性,CARLA-based 数据集(如 Bench2Drive)支持安全的长尾场景测试;
- 语言标注精细化:从简单描述(BDD-X)→ 思维链推理(Reason2Drive)→ 多轮交互(NuInteract),逐步提升语言与驾驶任务的耦合度;
- 任务覆盖全面:涵盖感知(检测)、推理(QA)、动作(轨迹 / 控制)全链路,支持端到端评估。
五、训练与评估策略
VLA4AD 的训练需同时满足 "驾驶安全" 和 "语言保真" 两大目标,评估则需覆盖控制性能、语言能力、鲁棒性等多维度。论文详细梳理了当前主流的训练范式和评估协议:
5.1 训练范式
(1)有监督模仿学习(Supervised Imitation Learning, IL)
- 核心逻辑:让模型模仿人类专家的驾驶行为,最小化控制信号或轨迹的 L2 损失或交叉熵损失;
- 典型应用:
- CoVLA-Agent:每帧同时学习未来路径和场景描述;
- CarLLaVA:在 SimLingo 的百万级仿真数据上进行行为克隆;
- 优势:训练稳定,易于规模化;
- 缺陷:泛化能力受限,对长尾场景(如事故、极端天气)缺乏监督;
- 改进方案:DAgger-style 噪声滚动、长尾场景增强。
(2)强化学习(Reinforcement Learning, RL)
- 核心逻辑:在仿真环境(CARLA、Bench2Drive)中通过试错学习,优化路线完成率、避撞、交通规则遵守等奖励;
- 典型应用:
- LangCoop:通过 RL 优化车辆间的语言协作(如路口会车时的意图沟通);
- SafeAuto:将交通规则作为硬约束或惩罚项,强化安全行为;
- 挑战:如何平衡 "驾驶奖励" 与 "语言保真度"------ 当前多冻结 LLM 仅优化控制部分,未充分利用文本与动作的联合梯度。
(3)多阶段训练(Multi-stage Training)
这是当前最主流的训练流程,分为四步:
- 预训练:在大规模图文 / 视频数据集上预训练视觉编码器(如 CLIP)和语言模型(如 LLaMA),学习通用多模态特征;
- 模态对齐:在 "图像 - 文本 - 动作" 配对数据上微调,通过跨模态对比损失绑定场景特征、语言提示和控制 token(如 DriveMonkey 在 NuInteract 上微调);
- 目标增强:注入长尾场景(如 SimLingo 的特殊场景)和规则约束,结合 RL 优化边缘案例性能;
- 模型压缩:通过 LoRA、混合专家(MoE)、师生蒸馏等方法,降低模型计算开销,适配车载硬件。
(4)关键优化点:语言与控制的平衡
- 联合损失:如 CoVLA-Agent 采用 L = L_traj + λL_cap,同时优化轨迹和文本生成;
- 交替更新:一批数据优化驾驶任务,下一批优化语言任务,避免梯度干扰;
- 冻结 LLM:仅训练轻量级适配器(Adapter),在保证语言流畅性的同时降低计算成本。
5.2 评估协议
VLA4AD 的评估需兼顾 "驾驶能力" 和 "语言能力",论文提出四大核心评估维度:
(1)闭环驾驶性能(Closed-loop Driving)
- 核心指标:路线完成率(CARLA/Bench2Drive)、违规次数(碰撞、闯红灯、偏离车道)、规则遵守度;
- 典型优化:DiffVLA 通过 PDMS 层将违规率降低 50%。
(2)开环预测性能(Open-loop Prediction)
- 核心指标:轨迹 L2 误差、碰撞率(nuScenes 挑战)、目标达成率(指令条件下)、辅助感知任务的 mAP/IoU、 latency/FPS;
- 效率优化:TS-VLM 通过 token 池化将计算量降低 90%。
(3)语言能力(Language Competence)
- 核心指标:
- 指令跟随准确率(SimLingo 的 Action-Dreaming 基准);
- 自动评估:BLEU、CIDEr(NuInteract、DriveLM);
- 逻辑一致性:Reason2Drive 的推理链一致性评分;
- 人工评估:BDD-X 风格决策理由的人类打分。
(4)鲁棒性与压力测试(Robustness & Stress)
- 测试场景:传感器扰动(模糊、遮挡、延迟)、对抗性提示(如口语化指令、多语言混合)、分布外场景(未见过的交通标志、天气);
- 典型方法:DynRsl-VLM 分析分辨率动态调整对鲁棒性的影响。
评估现状:当前评估多为单维度独立测试(如 CARLA 评估控制,NuInteract 评估语言),缺乏统一的 "AI 驾照" 式基准 ------ 需同时融合控制可靠性、语言保真度和人机协同能力。
六、核心挑战与未来方向
6.1 亟待解决的六大挑战
(1)鲁棒性与可靠性(Robustness & Reliability)
- 核心问题:LLM 可能产生语言幻觉(如虚构障碍物)、误解口语指令;模型在传感器噪声(雨雾、眩光)和长尾场景下稳定性差;
- 未解决问题:缺乏 "社会合规" 驾驶政策的形式化验证(如如何平衡 "避让行人" 与 "不影响后车")。
(2)实时性能(Real-time Performance)
- 核心矛盾:视觉 Transformer+LLM 的计算开销大,需满足车载硬件≥30Hz 的实时控制需求;
- 潜在方案:token 缩减(TS-VLM)、硬件感知量化、事件触发推理(仅在场景变化时激活大模型)。
(3)数据与标注瓶颈(Data & Annotation Bottlenecks)
- 核心问题:"图像 + 控制 + 语言" 三模态标注稀缺且昂贵(如 Impromptu VLA 需 8 万条人工标注 clip);非英语方言、交通口语、法律相关表述的覆盖不足;
- 缓解方向:合成数据(SimLingo)、弱监督 / 自监督学习。
(4)多模态对齐(Multimodal Alignment)
- 核心问题:当前模型以摄像头为中心,LiDAR、雷达、HD 地图、时序状态的融合不充分;缺乏时间一致的异模态融合框架;
- 现有尝试:BEV 点云投影、3D token 适配器、ORION 的语言历史总结。
(5)多智能体社会复杂性(Multi-agent Social Complexity)
- 核心问题:密集交通场景下,车辆间如何通过 "交通语言" 高效协作?如何防范恶意消息攻击?
- 研究方向:加密 V2V 通信、手势 - 文本对齐(如识别交警手势并转换为驾驶指令)。
(6)域适配与评估(Domain Adaptation & Evaluation)
- 核心问题:仿真到真实场景的迁移差距、跨地区交通规则适配(如左行 / 右行)、持续学习中的灾难性遗忘;缺乏统一的监管评估标准;
- 关键需求:定义覆盖控制、解释、协同的 "AI 驾驶考试"。
6.2 五大未来研究方向
(1)基础模型级驾驶模型(Foundation-scale Driving Models)
- 目标:构建类似 GPT 的 "驾驶基础模型",基于海量多传感器数据(行车记录仪、LiDAR、HD 地图、交通规则文本)自监督预训练;
- 能力:通过提示词或 LoRA 快速适配下游任务(如不同城市、不同车型),无需大规模微调。
(2)神经符号安全内核(Neuro-symbolic Safety Kernels)
- 思路:融合神经网络的灵活性与符号逻辑的可验证性 ------ 神经 VLA 模型输出结构化动作程序或 CoT 计划,由符号验证器执行安全检查;
- 案例:ORION 的语言记忆模块已初步具备结构化输出能力。
(3)车队级持续学习(Fleet-scale Continual Learning)
- 方案:部署的自动驾驶车队将长尾场景以 "语言摘要" 形式上传(如 "x 路口出现新型施工标志"),云端聚合后更新模型,再推送给车队;
- 优势:避免上传原始传感器数据,降低带宽开销,快速积累罕见场景知识。
(4)标准化交通语言(Standardised Traffic Language)
- 目标:设计类似航空 ICAO 术语的约束性交通语言(如 "我避让你""前方障碍物"),实现车辆间高效、无歧义协作;
- 技术路径:利用 MoE(DriveMoE)或 token 缩减 LM(TS-VLM)降低 V2V 通信带宽。
(5)跨模态社会智能(Cross-modal Social Intelligence)
- 目标:让车辆理解非语言社交信号(交警手势、行人挥手、车辆灯光示意),并生成人类可理解的响应(如灯光、显示屏提示、鸣笛);
- 实现思路:检索增强规划(如 RAG-Driver),融合实时感知、符号规则和上下文知识,对齐手势 - 语言 - 动作。
七、总结
论文核心结论如下:
- 技术演进逻辑:从模块化拆分→端到端映射→VLM 语言增强→VLA 多模态闭环,核心是解决 "信息割裂""动作鸿沟""可解释性不足" 三大痛点;
- 架构核心:以 "多模态输入 - 跨模态融合 - 动作输出" 为流水线,语言从被动解释升级为主动决策核心,思维链推理和记忆模块成为最新趋势;
- 关键支撑:大规模多模态数据集(如 nuScenes、Impromptu VLA)和高效模型适配技术(LoRA、MoE)是 VLA4AD 落地的基础;
- 核心挑战:鲁棒性、实时性、数据瓶颈、多模态对齐仍是制约大规模部署的关键;
- 未来愿景:构建 "可解释、可协作、可验证" 的自动驾驶系统,让车辆成为能与人类自然交互的智能体。
VLA4AD 作为自动驾驶与多模态大模型交叉的前沿领域,其发展需要计算机视觉、自然语言处理、机器人控制、交通工程等多学科的协同。随着基础模型能力的提升、数据集的丰富和评估标准的完善,VLA4AD 有望推动自动驾驶从 "封闭场景" 走向 "开放道路",实现真正的人机协同与社会合规。