NGO-XGBoost回归,基于北方苍鹰算法(NGO)优化XGBoost的数据回归预测,多变量输入单输入,Matlab适合小白新手 程序已经调试好,无需更改代码替换数据集即可运行数据格式为excel 1、运行环境要求MATLAB版本为2018b及其以上 2、评价指标包括:R2、MAE、MSE、RMSE等,图很多,符合您的需要 3、代码中文注释清晰,质量极高 4、测试数据集,可以直接运行源程序。 替换你的数据即可用 适合新手小白 5、 保证源程序运行,
最近在研究数据回归预测的时候,发现了一个超棒的组合------基于北方苍鹰算法(NGO)优化XGBoost的回归模型,而且用Matlab实现,对小白新手极其友好。今天就来和大家分享一下这个有趣的项目。
运行环境
这里要求Matlab版本为2018b及其以上。为啥呢?其实新版本往往修复了不少老版本的bug,并且在性能上有一定提升,对新算法和函数的支持也更友好。所以,大家要是还没升级的话,不妨升一下级哦。
评价指标
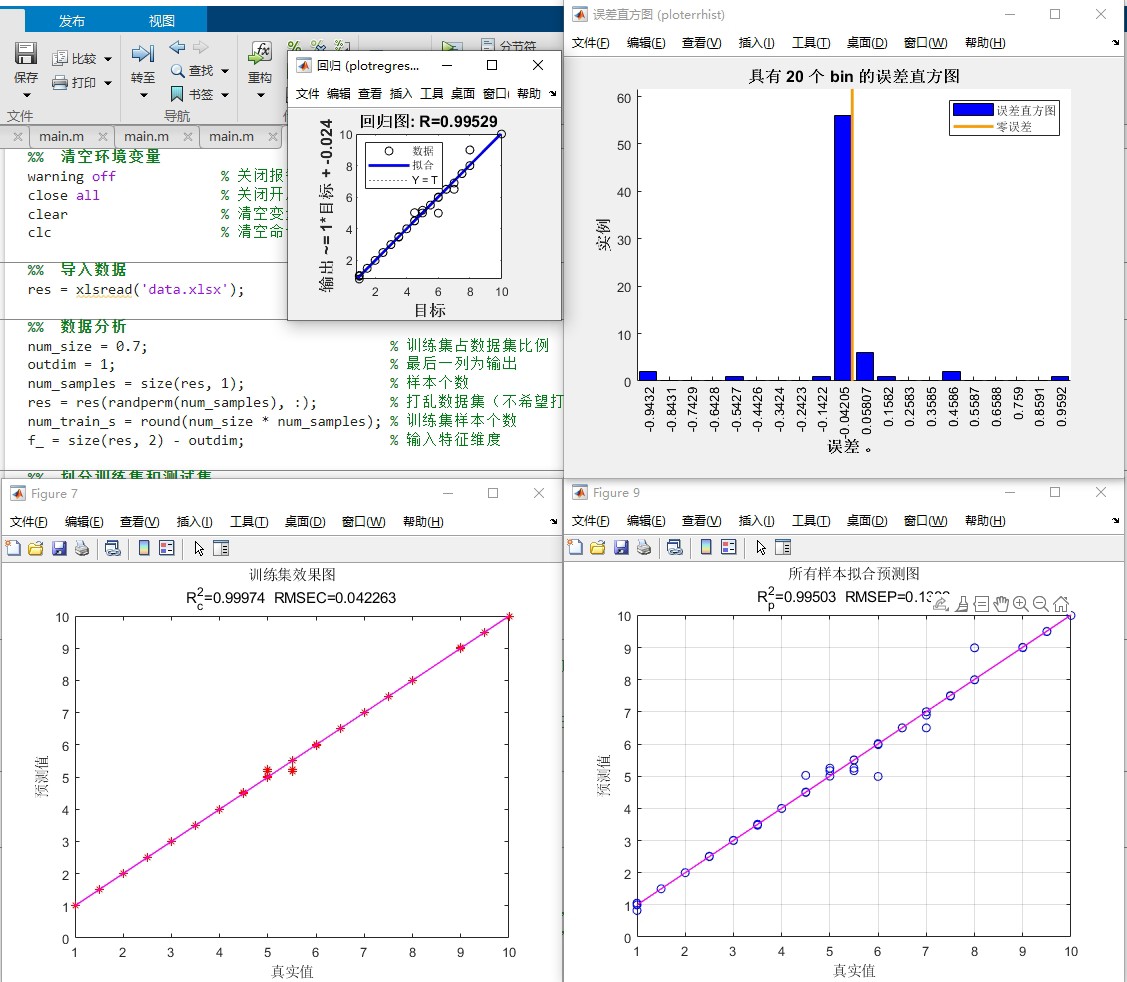
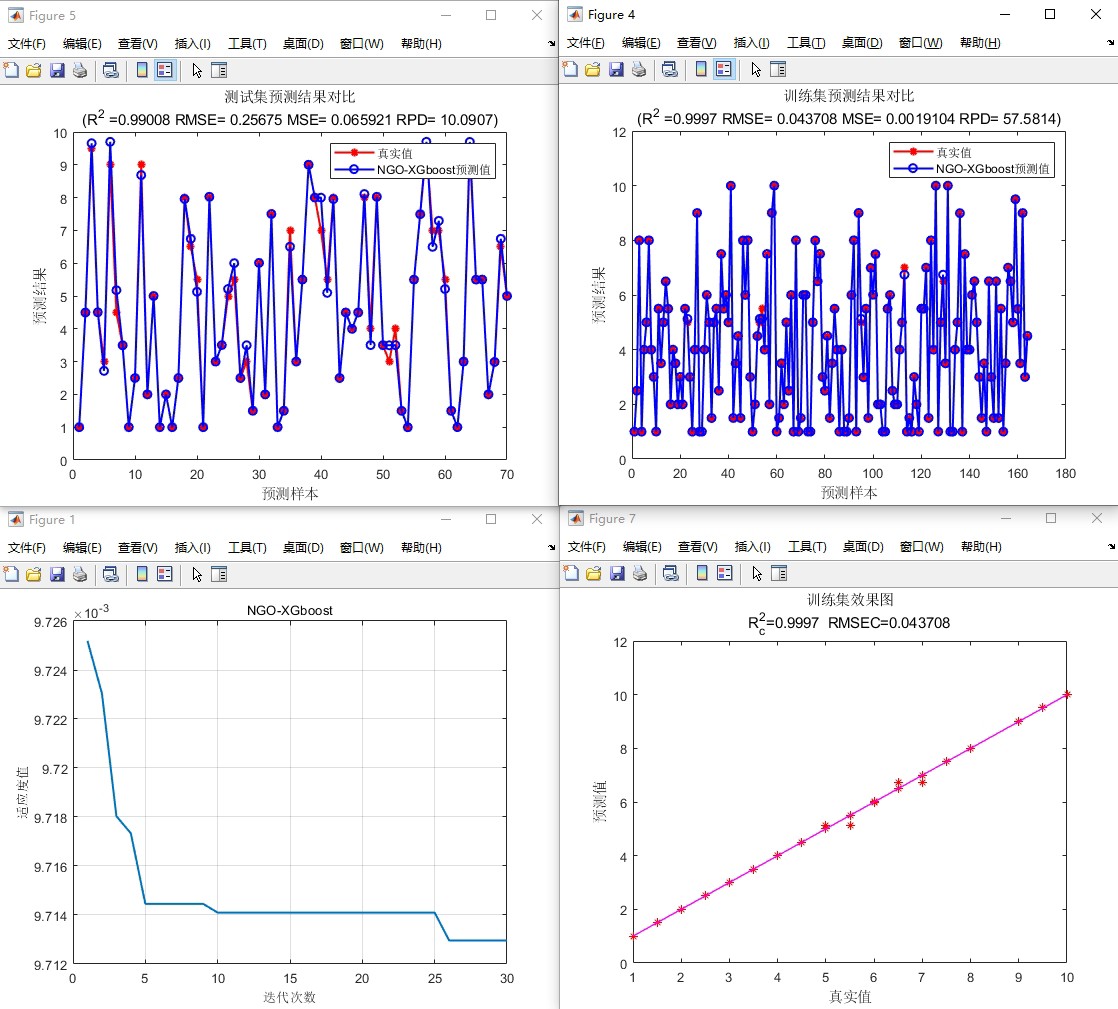
这个项目用到的评价指标有R2、MAE、MSE、RMSE等。这些指标在评估回归模型性能时非常重要。
- R2(决定系数):它衡量的是模型对数据的拟合优度,取值范围在0到1之间,越接近1表示模型拟合效果越好。可以简单理解为,它告诉我们模型能解释数据波动的比例。
- MAE(平均绝对误差):计算预测值与真实值之间误差的绝对值的平均值,它能直观地反映预测值与真实值之间的平均误差大小。
- MSE(均方误差):计算预测值与真实值之间误差的平方的平均值,因为对误差进行了平方,所以它对较大的误差更为敏感。
- RMSE(均方根误差):就是MSE的平方根,它和MAE类似,但由于对误差进行了平方再开方,同样对大误差更敏感,而且和预测值的单位相同,便于理解误差的实际大小。
代码部分与分析
下面来看部分核心代码及分析,这里就以数据读取和XGBoost模型训练为例(实际完整代码需根据数据集和具体需求调整)。
matlab
% 读取数据,这里假设数据保存在excel文件中,文件名为'data.xlsx'
data = readtable('data.xlsx');
% 将表格数据转换为数值矩阵,方便后续处理
dataMatrix = table2array(data);
% 提取自变量(多变量输入)和因变量(单输出)
X = dataMatrix(:, 1:end - 1); % 假设最后一列是因变量,前面的列为自变量
Y = dataMatrix(:, end);
% 划分训练集和测试集,这里采用70%的数据作为训练集,30%作为测试集
cv = cvpartition(Y, 'HoldOut', 0.3);
trainIndex = training(cv);
testIndex = test(cv);
X_train = X(trainIndex, :);
Y_train = Y(trainIndex);
X_test = X(testIndex, :);
Y_test = Y(testIndex);
% 训练XGBoost回归模型
model = TreeBagger(100, X_train, Y_train, 'Method', 'regression'); 在这段代码里:
readtable函数用于读取excel文件的数据,Matlab对表格数据的处理很方便,table格式能很好地保存不同类型的数据。table2array将表格数据转换为数值矩阵,因为后续很多算法操作需要数值矩阵格式的数据。- 通过索引的方式提取自变量
X和因变量Y,这种方式很直观,只要明确数据的排列方式就行。 cvpartition函数用来划分训练集和测试集,HoldOut方法简单直接,按照设定的比例划分数据,这里70%的数据用于训练模型,30%用于测试模型性能。- 最后使用
TreeBagger训练XGBoost回归模型,这里设置了100棵树,'Method','regression'表明这是一个回归模型。
数据集与程序运行
这个项目已经把程序调试好了,大家只要替换数据集就可以运行。数据格式是excel,非常方便获取和整理。测试数据集也包含在源程序里,直接运行源程序,把自己的数据替换进去就能用,真的是新手小白的福音。而且代码里中文注释清晰,质量极高,在运行过程中要是遇到什么问题,看看注释说不定就能解决啦。
总之,这个基于NGO - XGBoost的回归预测项目,从运行环境、评价指标到代码实现以及数据集使用,都为新手考虑得很周到。希望大家能通过这个项目,对数据回归预测有更深入的了解,赶紧动手试试吧!