论文题目:Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge Distillation (通过知识蒸馏提高GAN效率的双重方法)
会议:ECCV2024
摘要:在本文中,我们通过提出两种新颖的方法来解决压缩生成对抗网络(gan)以在资源约束环境中部署的挑战:高效压缩的分布匹配(DiME)和通过知识交换和学习的网络交互压缩(NICKEL)。DiME采用基础模型作为嵌入核进行高效的分布匹配,利用最大均值差异进行有效的知识蒸馏。NICKEL采用交互式压缩方法,增强了学生生成器和鉴别器之间的通信,实现了平衡稳定的压缩过程。我们用FFHQ数据集对StyleGAN2架构进行了综合评估,结果表明我们的方法是有效的,在压缩率分别为95.73%和98.92%的情况下,NICKEL和DiME的FID得分分别为10.45和15.93。值得注意的是,我们的方法即使在99.69%的极端压缩率下也能保持生成质量,大大超过了以前最先进的性能。这些发现不仅表明我们的方法能够显著降低GAN的计算需求,而且还为在资源有限的环境中部署高质量的GAN模型铺平了道路。
项目地址:https://github.com/SangyeopYeo/NICKEL_AND_DIME
代码使用教程:
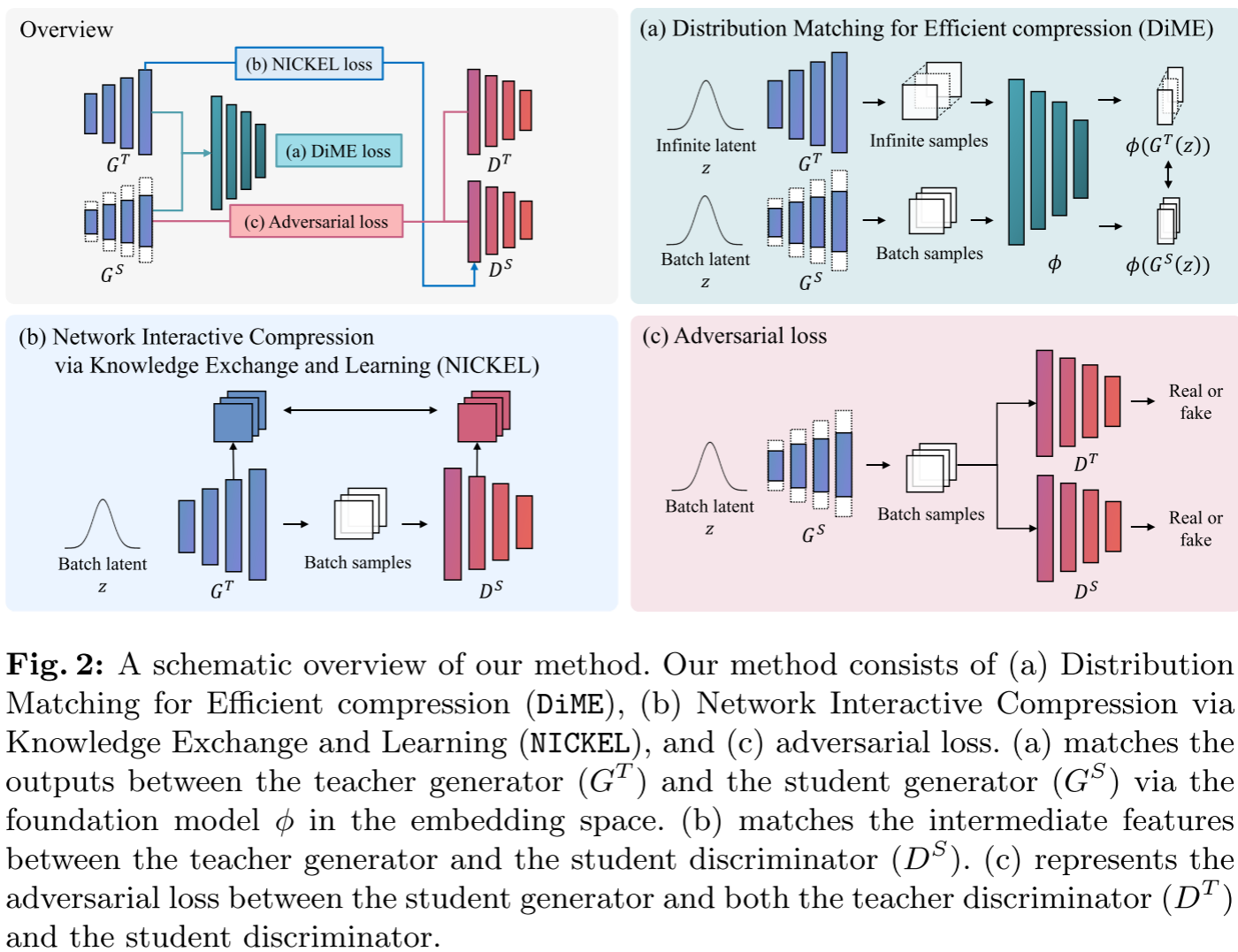
NICKEL & DiME: 双管齐下的GAN高效压缩方法
论文标题:Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge Distillation
作者:Sangyeop Yeo, Yoojin Jang, Jaejun Yoo (UNIST)
发表会议:ECCV 2024
📌 引言:为什么需要压缩GAN?
生成对抗网络(GANs)在图像生成领域取得了令人瞩目的成就。从StyleGAN系列到BigGAN,这些模型能够生成以假乱真的高质量图像。与扩散模型相比,GAN的一大优势在于其快速的推理速度,这使其在实时应用场景中具有独特价值。
然而,现实很骨感:以StyleGAN2为例,其完整模型需要约30M参数和45B FLOPs的计算量。这样的资源消耗让它难以在手机、嵌入式设备等边缘计算场景中部署。
那么,能否像压缩分类网络那样压缩GAN呢?答案是:传统方法行不通。
🔍 问题剖析:为什么GAN压缩如此困难?
1. 知识蒸馏范式的本质差异
论文通过一张清晰的对比图揭示了问题的核心:
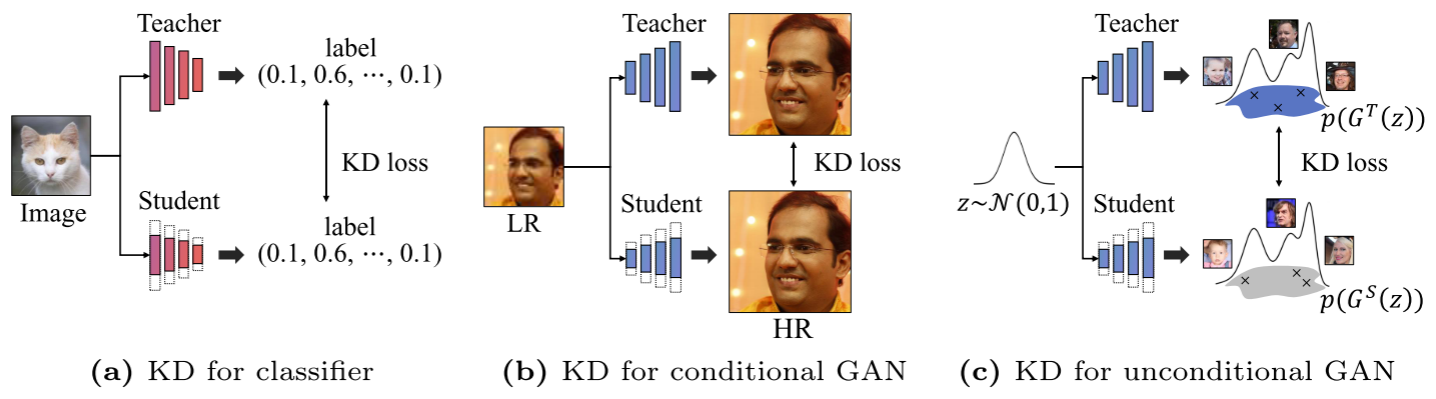
| 任务类型 | 蒸馏目标 | 输出空间 | 匹配方式 |
|---|---|---|---|
| 分类任务 | 标签分布 | 低维(类别数) | 实例匹配 |
| 条件GAN | 输出图像 | 高维(图像) | 实例匹配(结构相似) |
| 无条件GAN | 输出分布 | 高维(图像) | 分布匹配 |
对于分类任务,教师和学生对同一输入应该给出相同的预测。对于条件GAN(如超分辨率),给定同一低分辨率输入,教师和学生应该输出结构相似的高分辨率图像。
但无条件GAN完全不同!给定同一个随机噪声z,教师和学生不需要生成相同的图像 。我们关心的是两个生成器的输出分布是否一致,而非单个样本的一致性。这使得传统的实例级知识蒸馏方法失效。
2. 生成器-判别器的脆弱平衡
GAN训练本质上是一个极小极大博弈。生成器和判别器需要维持Nash均衡状态。当我们压缩生成器时:
- 压缩后的生成器能力下降
- 判别器相对变得"过强"
- 均衡被打破,训练变得不稳定
论文通过实验展示了这一现象:当压缩率达到98.92%时,判别器的logits严重偏离0(理想均衡状态),导致训练崩溃。
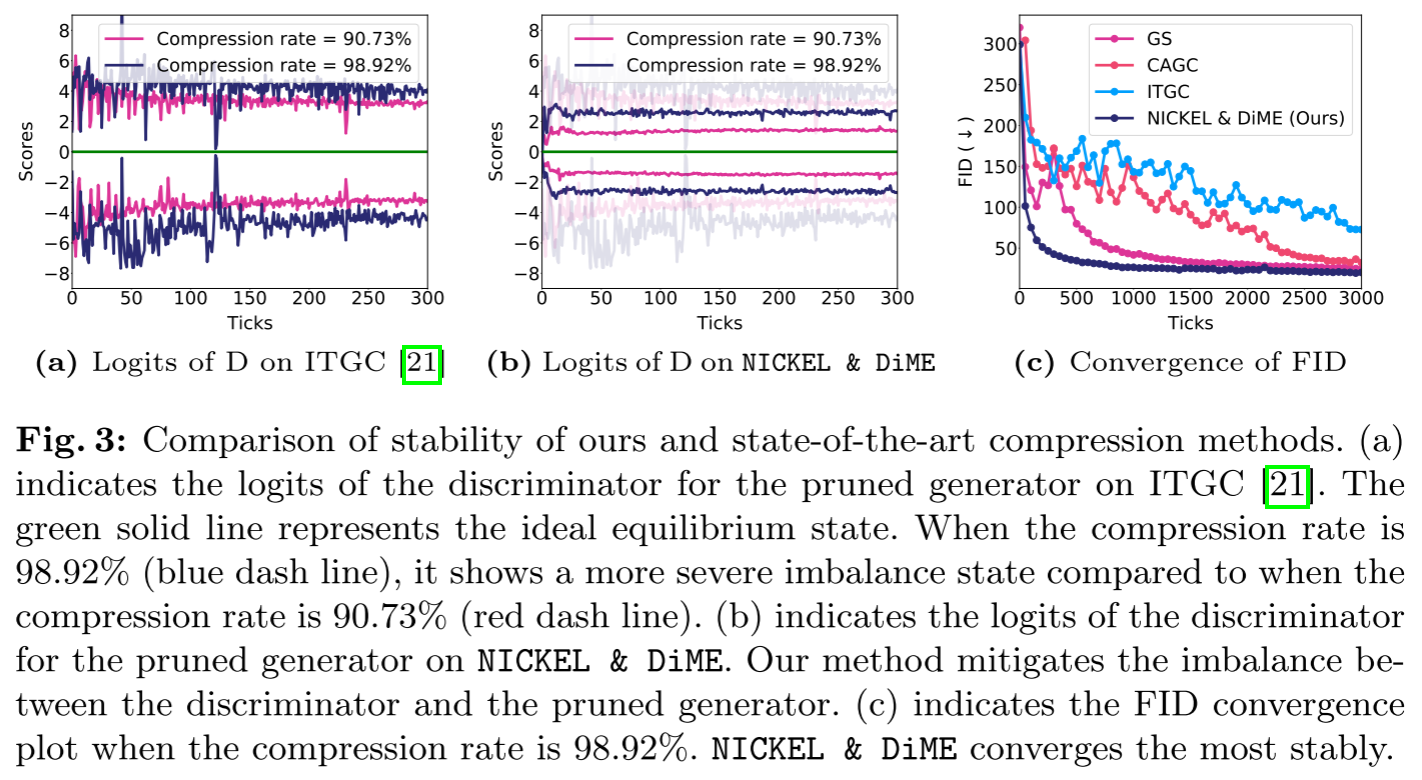
3. 现有方法的局限
- GAN Slimming (GS):统一优化框架,但在高压缩率下性能急剧下降
- CAGC:需要人工标注内容区域,成本高
- ITGC:使用能量模型和MCMC采样,计算代价大
- StyleKD:仅适用于StyleGAN架构
💡 解决方案:DiME + NICKEL 双剑合璧
论文提出了两个互补的方法:DiME 负责高效的分布匹配蒸馏,NICKEL负责稳定训练过程。
方法一:DiME --- 基于基础模型的分布匹配
核心思想:利用预训练的视觉基础模型(DINO、CLIP)作为特征嵌入器,在嵌入空间中进行分布匹配。
技术细节
-
为什么选择基础模型?
直接在像素空间匹配高维图像会导致严重的性能下降。前人工作已经尝试使用感知损失、频域损失等嵌入空间。本文选择DINO和CLIP,因为它们:
- 在大规模数据上预训练,具有强大的特征提取能力
- 在多种下游任务中展现出优秀的泛化性
- 可视为"特征核",将图像映射到再生核希尔伯特空间(RKHS)
-
MMD损失函数
知识蒸馏损失定义为:
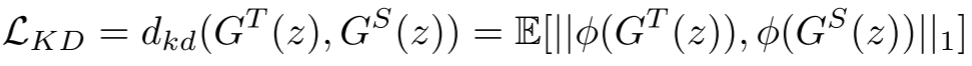
其中
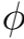 是基础模型的特征提取器,G^T和G^S分别是教师和学生生成器。
是基础模型的特征提取器,G^T和G^S分别是教师和学生生成器。这本质上是最大均值差异(MMD)准则,当
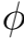 是特征核时,特征空间的匹配等价于原始分布的匹配。
是特征核时,特征空间的匹配等价于原始分布的匹配。 -
全局特征策略
这是DiME的一个精妙设计。由于batch size的限制,每次只能采样有限的样本,这会引入采样误差:
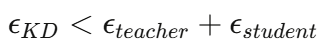
-
但教师生成器G^T的分布是固定的 !因此可以预先用大量样本(论文中用20000个样本)计算其统计量(称为"全局特征"),使
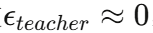 ,从而减少总体采样误差。
,从而减少总体采样误差。
方法二:NICKEL --- 交互式知识交换与学习
核心思想:不仅让学生生成器学习教师生成器的知识,还让学生判别器学习教师生成器的语义知识。
设计动机
Lee等人GGDR发现:判别器可以从生成器中学习语义知识,进而提供更有意义的反馈信号。但GGDR有两个问题:
- 训练初期,生成器接近随机初始化,无法提供有意义信息
- 在GAN压缩中,学生生成器G\^S的容量有限,能提供的知识也有限
NICKEL的解决方案:让学生判别器D\^S直接从教师生成器G\^T学习!
技术细节
NICKEL损失定义为:
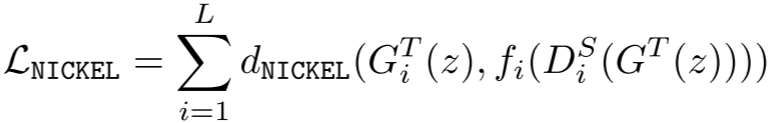
其中:
- G_i^T(z):教师生成器第i层的特征图
- D_i^S(G^T(z)):学生判别器第i层对教师生成图像的特征图
- f_i:用于匹配特征图尺寸的线性变换
- d_NICKEL:使用小波损失,擅长捕捉语义信息
NICKEL的优势
- 即时可用:从训练一开始,D^S就能从G^T学到丰富的语义知识
- 知识更丰富:G^T的知识远超$G^S
- 稳定性提升:缓解了G^S和D^S之间的不平衡
整体训练目标
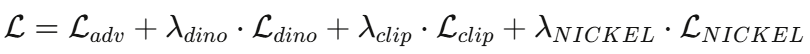
其中超参数分别为20,15,10。
📊 实验结果:全方位碾压SOTA
主实验:StyleGAN2 on FFHQ
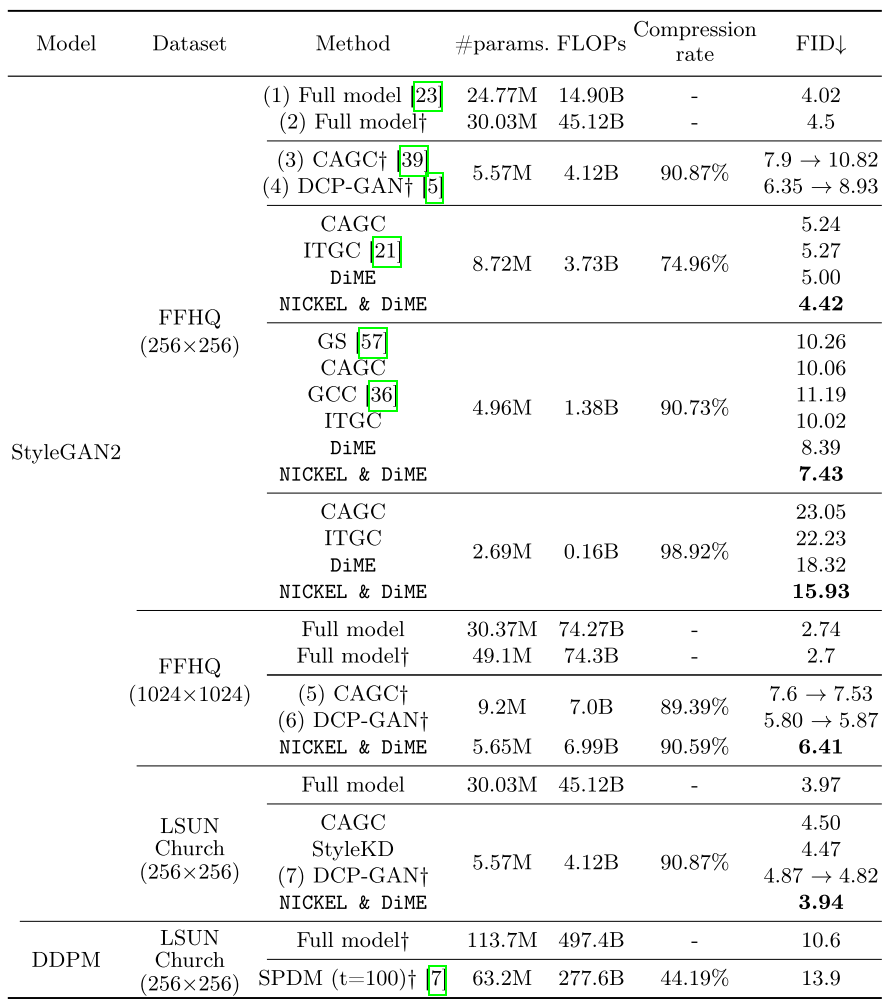
| 压缩率 | 方法 | FID↓ | 备注 |
|---|---|---|---|
| 0% (Full) | StyleGAN2 | 4.02 | 基线 |
| 74.96% | NICKEL & DiME | 4.42 | 仅9.68%性能下降 |
| 74.96% | ITGC | 5.27 | |
| 90.73% | NICKEL & DiME | 7.43 | 11倍压缩 |
| 90.73% | ITGC | 10.02 | |
| 98.92% | NICKEL & DiME | 15.93 | 93倍压缩 |
| 98.92% | ITGC | 22.23 | |
| 99.69% | NICKEL & DiME | 29.38 | 321倍压缩 |
| 99.69% | ITGC | 164.92 | 训练崩溃 |
最令人印象深刻的是99.69%压缩率的结果:当模型被压缩到仅剩0.31%的原始计算量时,ITGC等方法完全崩溃(FID>160),而NICKEL & DiME仍然保持可接受的29.38!
跨架构、跨数据集验证
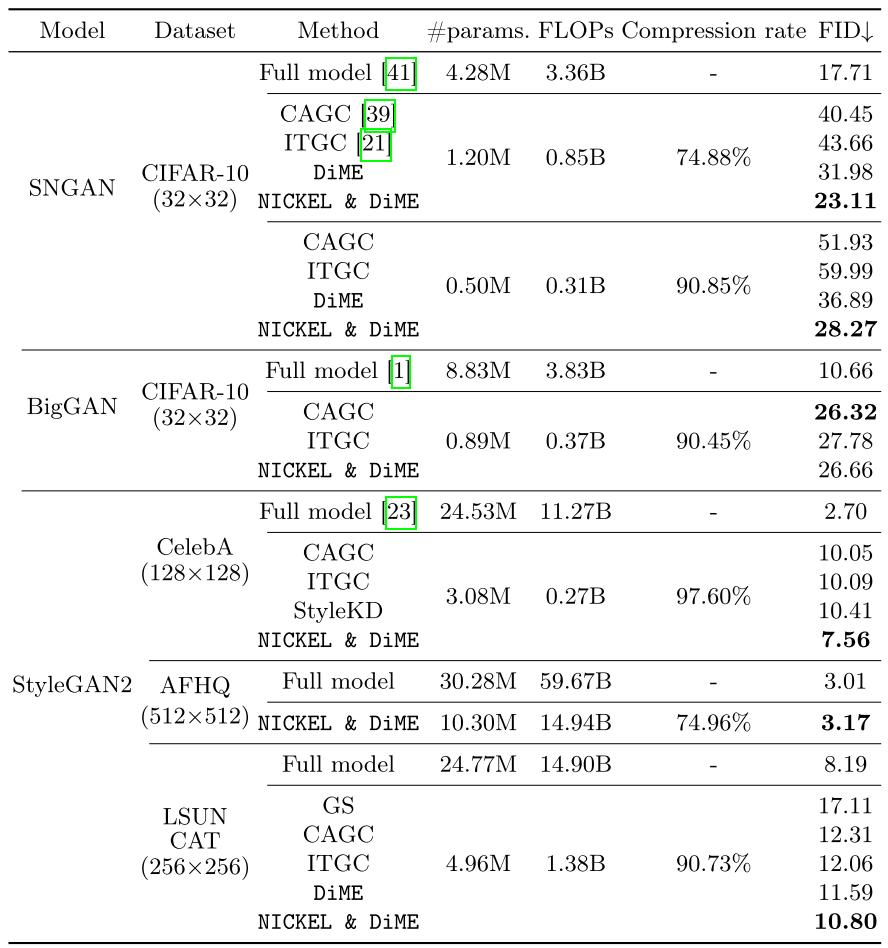
论文在SNGAN、BigGAN等架构以及CelebA、AFHQ、LSUN-CAT/Church等数据集上都验证了方法的有效性,展现出良好的泛化能力。
稳定性分析
论文通过判别器logits和FID收敛曲线展示了NICKEL & DiME的稳定性优势:
- ITGC在高压缩率下:判别器logits严重偏离0,训练极不稳定
- NICKEL & DiME:即使在98.92%压缩率下,仍维持较好的均衡状态
Precision vs Recall分析
- Precision(保真度):NICKEL & DiME在各压缩率下保持与完整模型相当的水平
- Recall(多样性):虽然所有方法的Recall都随压缩率下降,但NICKEL & DiME的下降最为缓和
🧪 消融实验:每个组件都不可或缺
| 配置 | FID |
|---|---|
| 仅CLIP嵌入(无全局特征) | 152.15 |
| 仅DINO嵌入(无全局特征) | 20.75 |
| DINO嵌入 + 全局特征 | 19.60 |
| DiME (DINO+CLIP+全局特征) | 18.32 |
| NICKEL & DiME | 15.93 |
关键发现:
- CLIP单独使用不稳定,但与DINO结合有增益
- 全局特征策略带来稳定的性能提升
- NICKEL在DiME基础上进一步提升2.4 FID
🎨 可视化结果
论文展示了在不同压缩率下生成的人脸和猫图像:
- 90.73%压缩率:生成质量高,多样性丰富,几乎看不出与完整模型的差距
- 98.92%压缩率:质量略有下降,但仍保持自然的面部特征
- 99.69%压缩率:虽有可见的质量损失,但依然生成可辨识的人脸图像
这在实际应用中意义重大:在资源极其受限的场景下,仍能部署一个"可用"的GAN模型。
📝 总结与思考
核心贡献
- DiME:首次将基础模型作为特征核用于GAN知识蒸馏,配合全局特征策略实现高效的分布匹配
- NICKEL:首次提出通过判别器间接传递生成器知识的交互式压缩方法,显著提升训练稳定性
- 标准化基准:使用官方代码重新实现和评估,为未来研究提供公平比较基准
方法优势
- 不需要人工标注
- 不需要复杂的MCMC采样
- 架构无关,可应用于多种GAN
- 在极端压缩率下仍保持稳定
局限与未来方向
作者诚实地指出:
- 方法更侧重保真度,Recall在高压缩率下仍有明显下降
- 极端压缩下的不平衡问题虽有缓解,但未完全解决
未来可探索的方向:
- 设计专门维护生成多样性的损失函数
- 研究更鲁棒的生成器-判别器平衡策略
- 将方法扩展到扩散模型压缩
💭 个人思考
这篇论文的标题"Nickel and Diming Your GAN"很有意思------源自英语俚语"nickle and dime",意为"一点一点地节省"。这恰如其分地描述了论文的贡献:通过DiME和NICKEL两个互补的方法,一点一滴地榨取GAN压缩的潜力。
从技术角度看,本文有几个值得学习的点:
- 问题定义的准确性:清晰区分了无条件GAN压缩与其他任务的本质差异
- 工具选择的合理性:巧妙利用基础模型作为特征核,站在巨人肩膀上
- 理论与实践的结合:全局特征策略有坚实的统计学基础(大数定律)
- 系统性的实验验证:多架构、多数据集、多指标的全面评估
对于想要在边缘设备上部署GAN的研究者和工程师来说,这篇论文提供了一个强有力的工具。