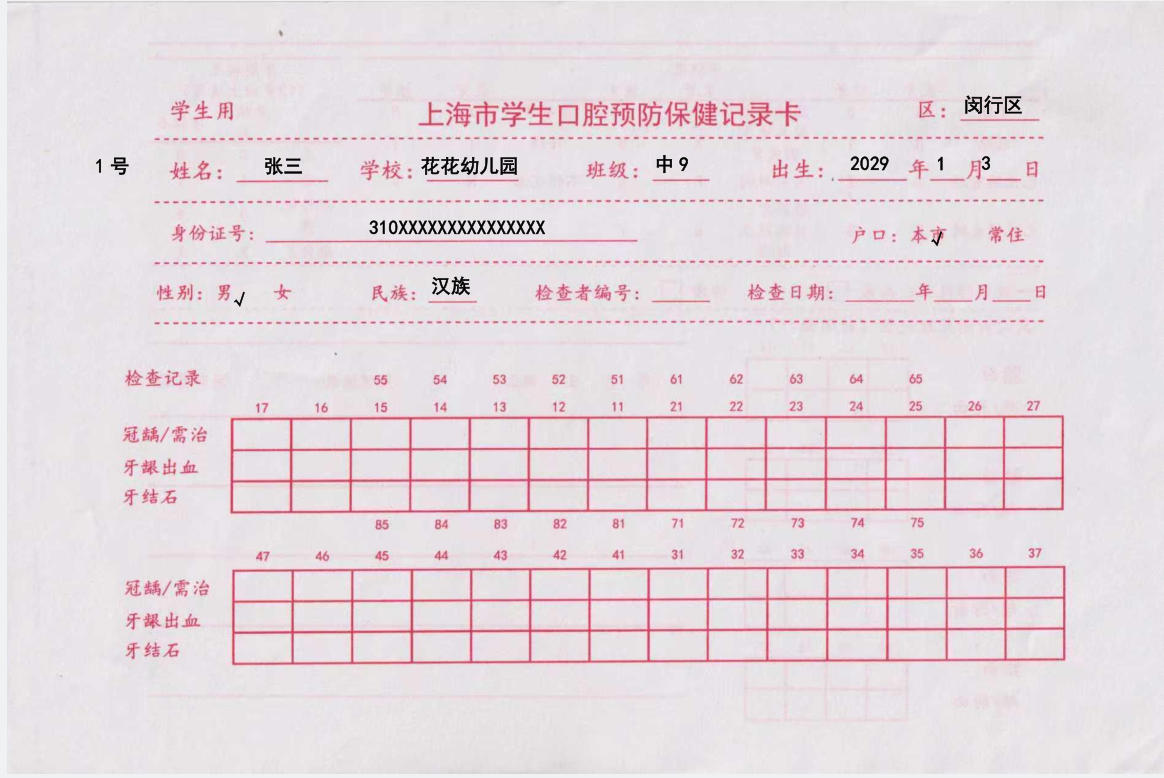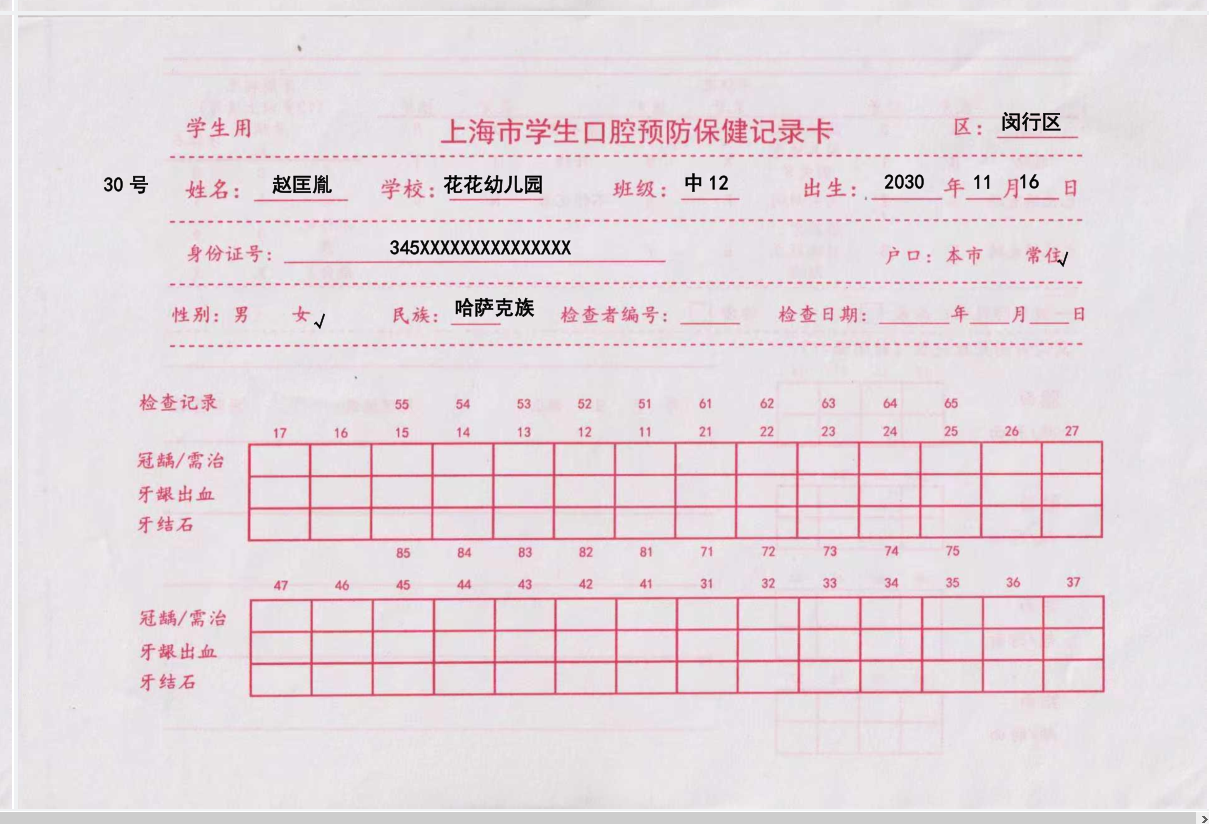
背景需求

本学期的涂氟单来了,需要手写幼儿信息

上学期做了中2班的涂氟单
代码拿来复制一份
去年打印后,模版的位置有不同,所以今年需要再重新调整一下文本框的位置

一、扫描图片
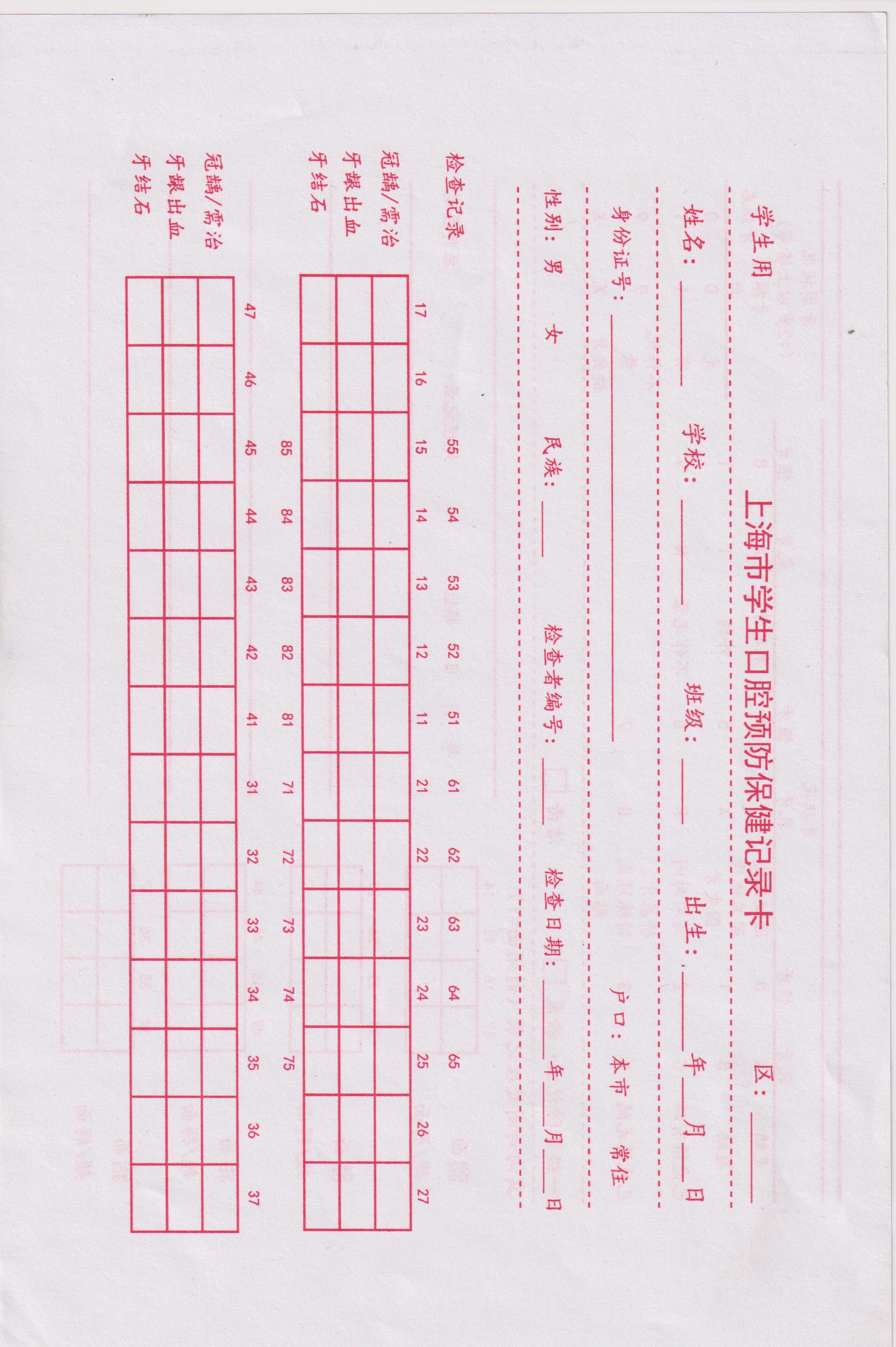

二、新的模版贴入WORD内
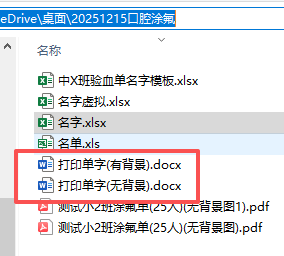
制作有背景模版,并调整文本框位置(上移几下)
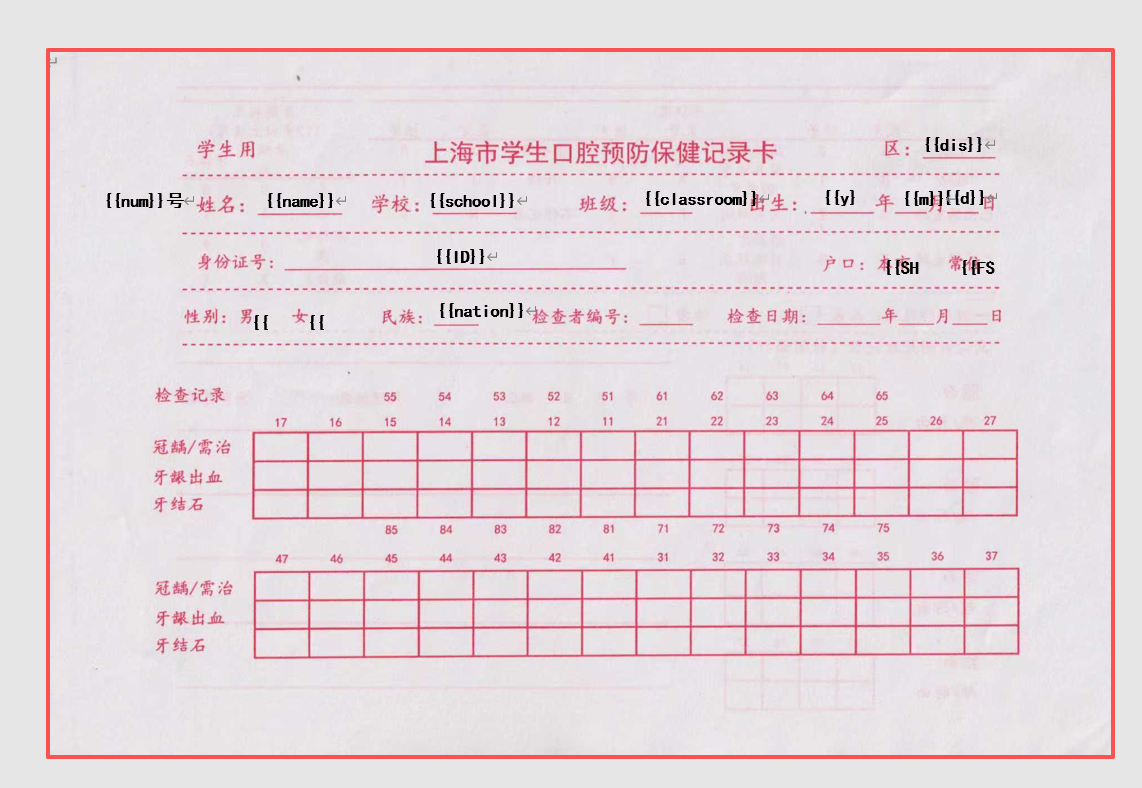
去掉背景,变成无背景模版

班级幼儿信息
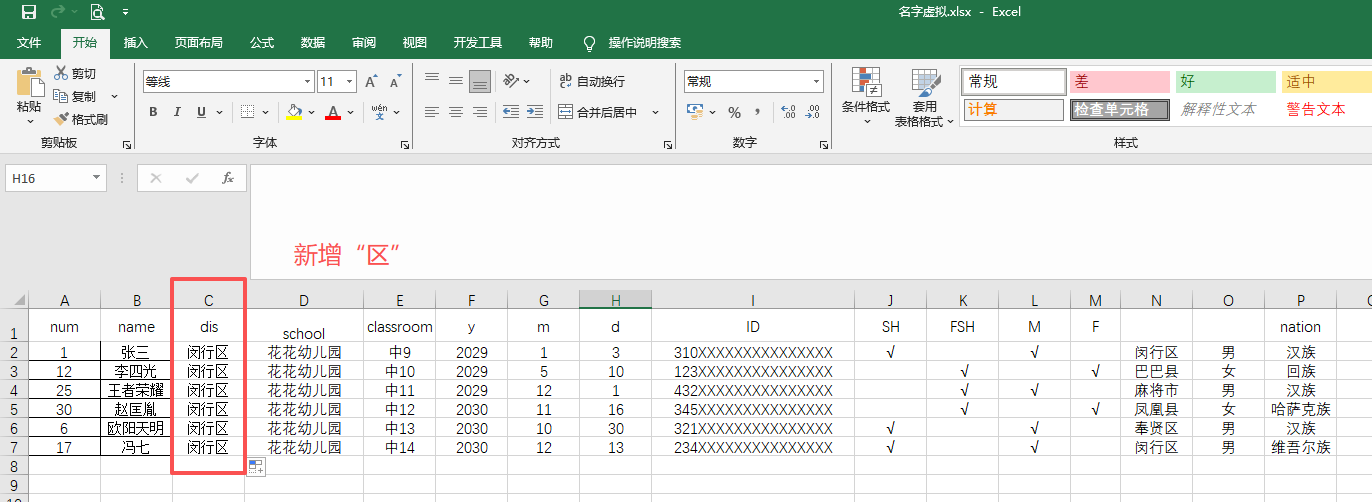
读取EXCLE,填写WORD文字占位符,制作PDF
python
# -*- coding:utf-8 -*-
'''
目的:口腔检查涂氟单(一个班级单独打印)
作者:deepseek,阿夏
日期:20251215
'''
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
# numnum = int(input('请输入班级号(如4):\n'))
l = 2
# int(input('1、有背景图、2、无背景图\n'))
zpath = r'C:\Users\jg2yXRZ\OneDrive\桌面\20251215口腔涂氟' + "\\"
file_path = zpath + r'\零时Word'
# 二、遍历excel,逐个生成word(form.docx是前面的模板)
try:
os.mkdir(file_path)
except:
pass
# 读取Excel文件
IDcard = pd.read_excel(zpath + '名字虚拟.xlsx')
# 获取总人数(不包括标题行)
total_people = IDcard.shape[0]
print(f"Excel中共有 {total_people} 人")
num = IDcard["num"]
name = IDcard["name"]
school = IDcard["school"]
classroom = IDcard["classroom"] # 去掉换行符
y = IDcard["y"]
m = IDcard["m"]
d = IDcard["d"]
ID = IDcard["ID"]
SH = IDcard["SH"]
FSH = IDcard["FSH"]
M = IDcard["M"]
F = IDcard["F"]
dis=IDcard["dis"]
# 尝试这样读取
nation = IDcard["nation"]
# 遍历excel行,逐个生成
for i in range(total_people):
# python
print(IDcard["nation"].head()) # 查看前几行nation数据
print(IDcard["nation"][i]) # 在循环内打印当前处理的nation值
context = {
"num": str(num[i]),
"dis":dis[i],
"name": name[i],
"school": school[i],
"classroom": classroom[i],
"y": y[i],
"m": m[i],
"d": d[i],
"ID": ID[i],
"SH": SH[i],
"FSH": FSH[i],
"M": M[i],
"F": F[i],
"nation": nation[i],
}
if l == 1:
tpl = DocxTemplate(zpath + '打印单字(有背景).docx')
elif l == 2:
tpl = DocxTemplate(zpath + '打印单字(无背景).docx')
tpl.render(context)
tpl.save(file_path + fr'\{num[i]:02}.docx')
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = file_path + fr'\{num[i]:02}.docx'
outputFile = file_path + fr'\{num[i]:02}.pdf'
# 先创建不存在的文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
time.sleep(2)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并
import os
from PyPDF2 import PdfFileMerger
target_path = file_path
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
if l == 1:
file_merger.write(zpath + fr'\(测试){classroom[0]}班涂氟单({total_people}人)(虚拟有背景图).pdf')
elif l == 2:
file_merger.write(zpath + fr'\测试{classroom[0]}班涂氟单({total_people}人)(虚拟无背景图).pdf')
file_merger.close()
print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(file_path) #递归删除文件夹,即:删除非空文件夹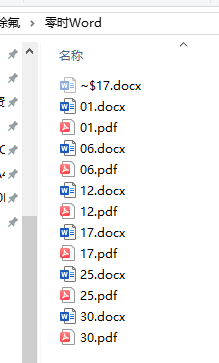
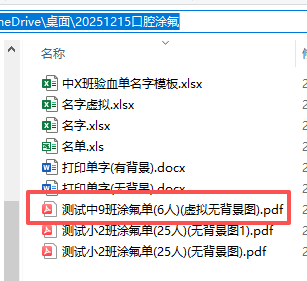



虽然看上去占位符和图片背景是对应了,但是实际打印不一样,所以为了调整位置,我反复打印了无数次。
一分园电脑,需要正面(打印面)向下,题目向上
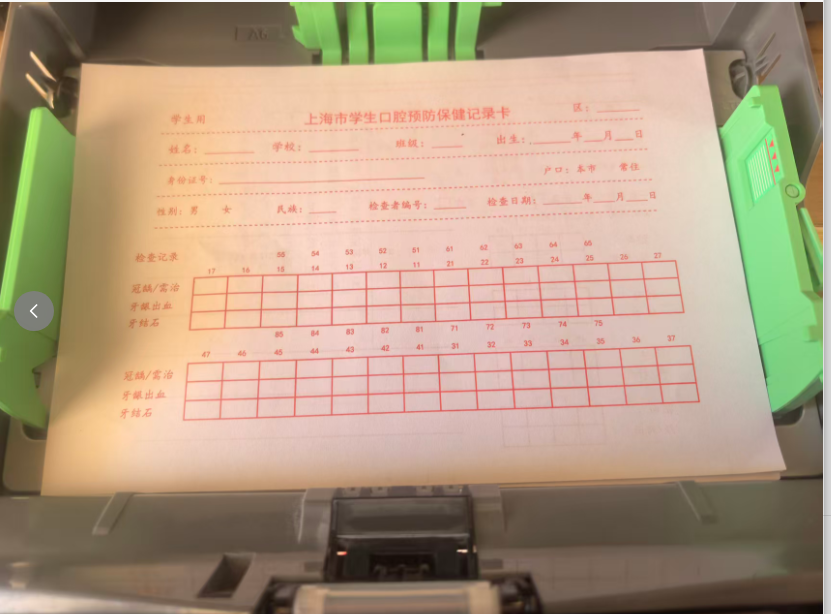
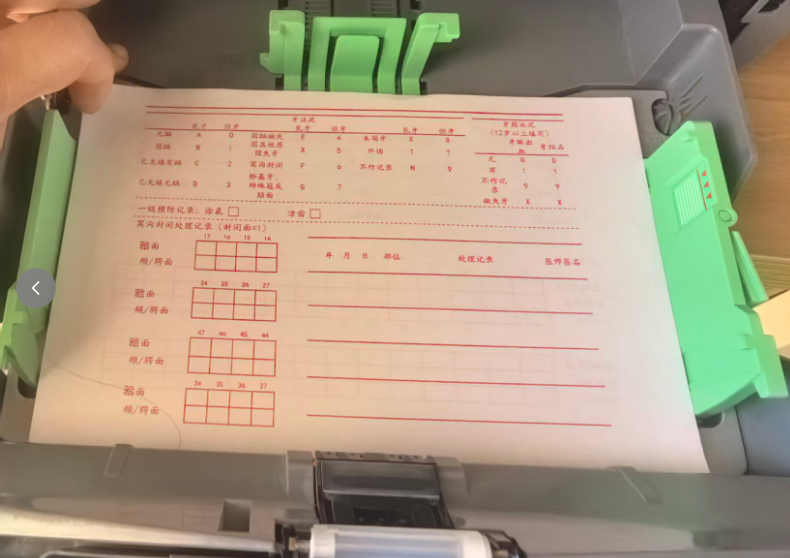
打印1张,做测试。文字全部靠下了,需要向上调整
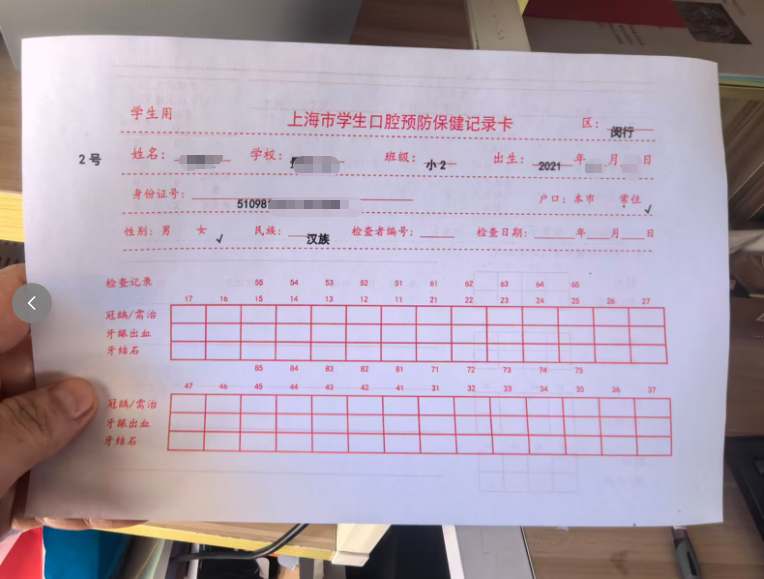
反复调整位置,打印了多次。
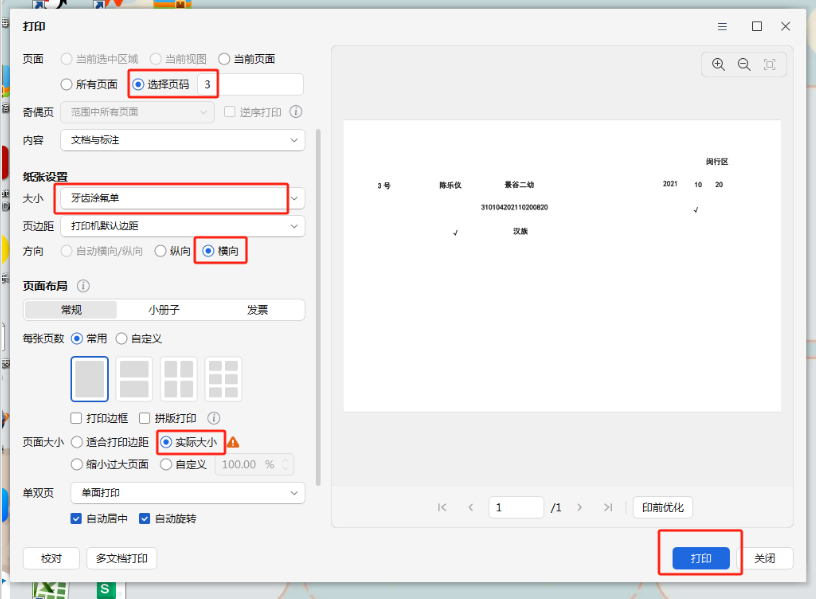
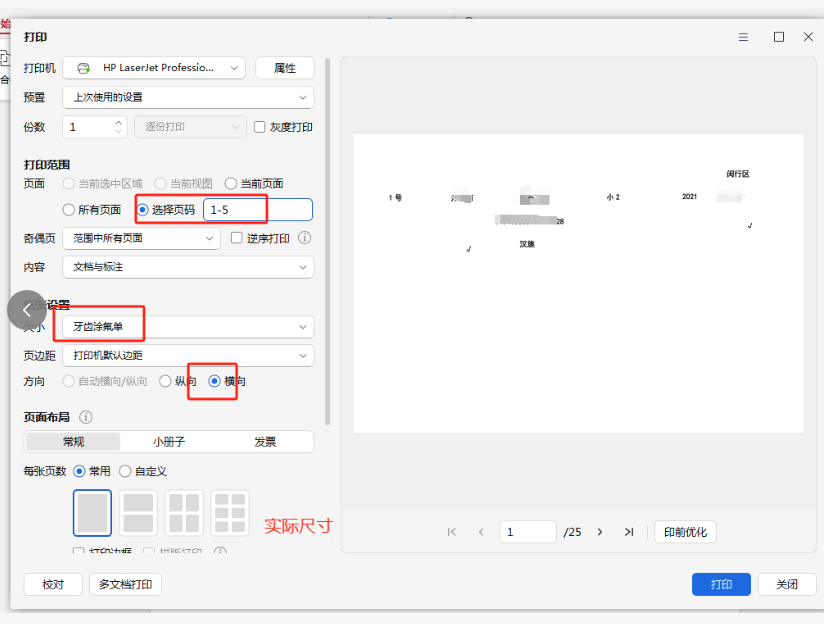
分园的电脑自定义尺寸只能设置一个,要么是15*15,要么是14*21CM,我用适合打印边距、实际大小、自定义105%都打印了一次
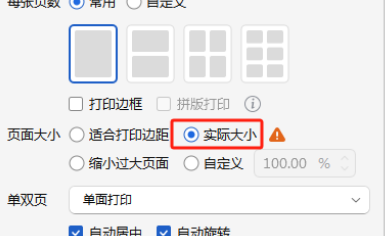
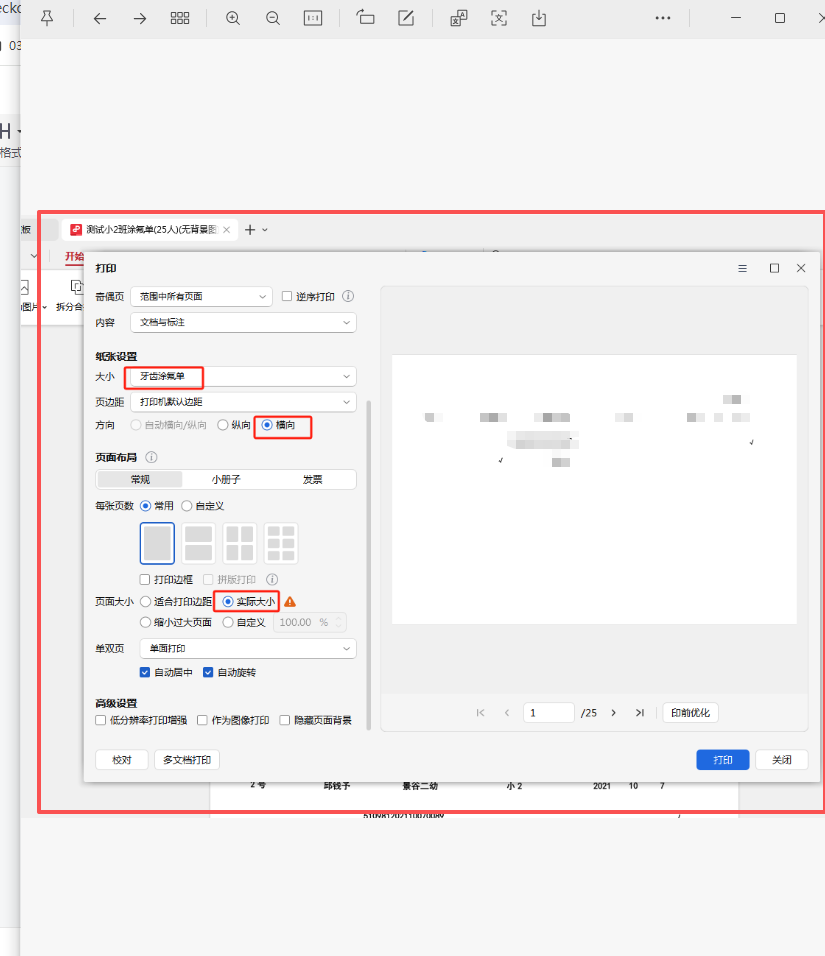
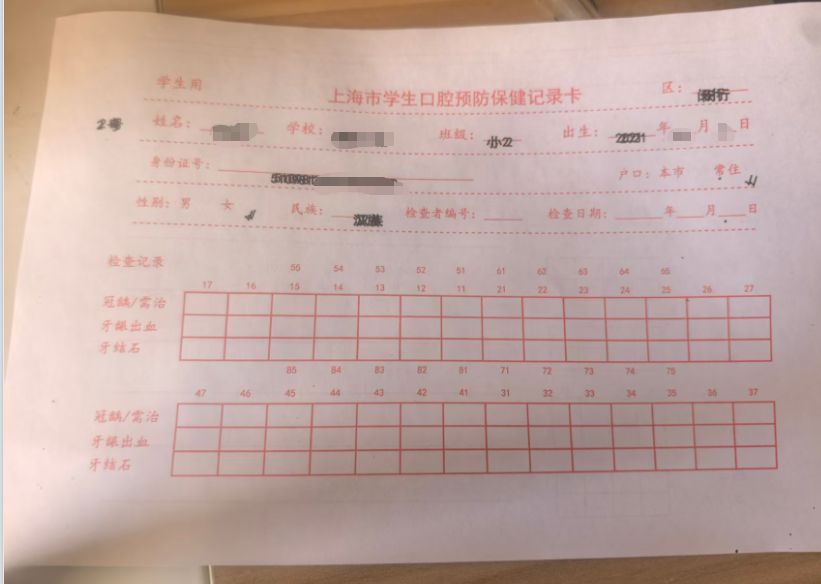

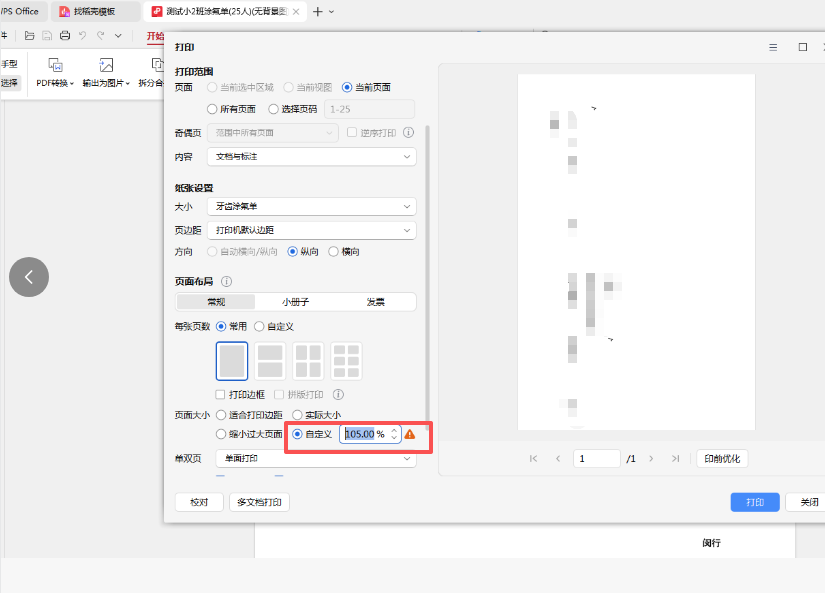

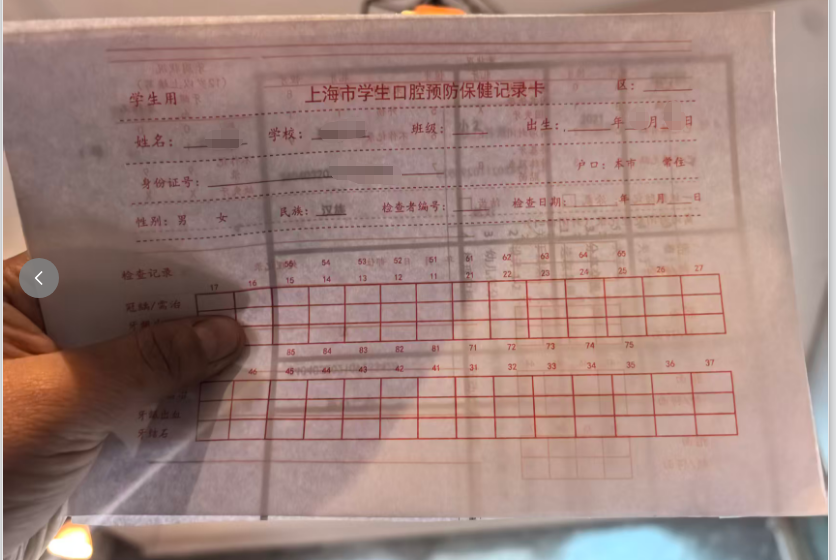
结果,文字都没有在横线上,都在横线下面。所以还是去总园用扫描仪扫描图片。做正确的模版
总园大班电脑,
我已经忘记了纸张正面摆放,搜索CSDN看看原来的记录


总园大班打印机的纸张摆放形式:正面(打印面)向上,标题向左。
不断测试:
1、一定要选择自定义的纸张尺寸(原来设置过的,有记录)
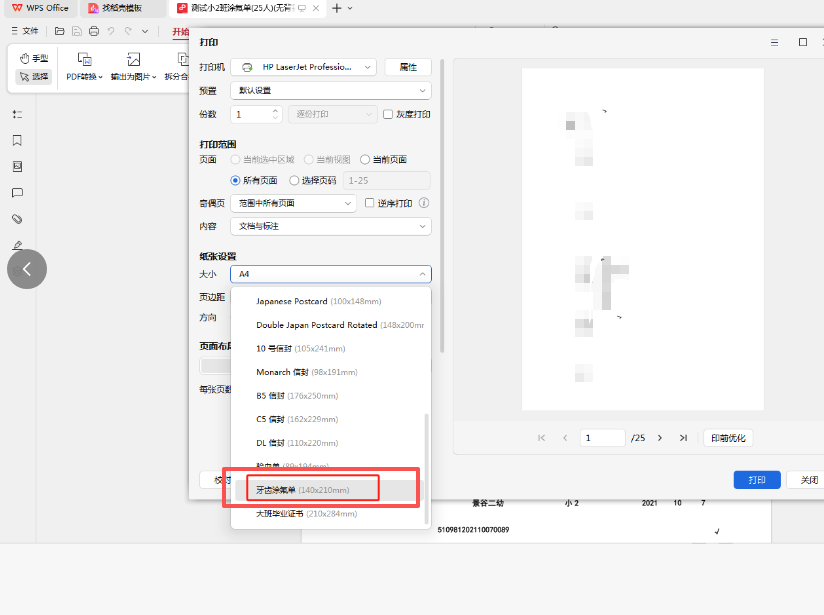




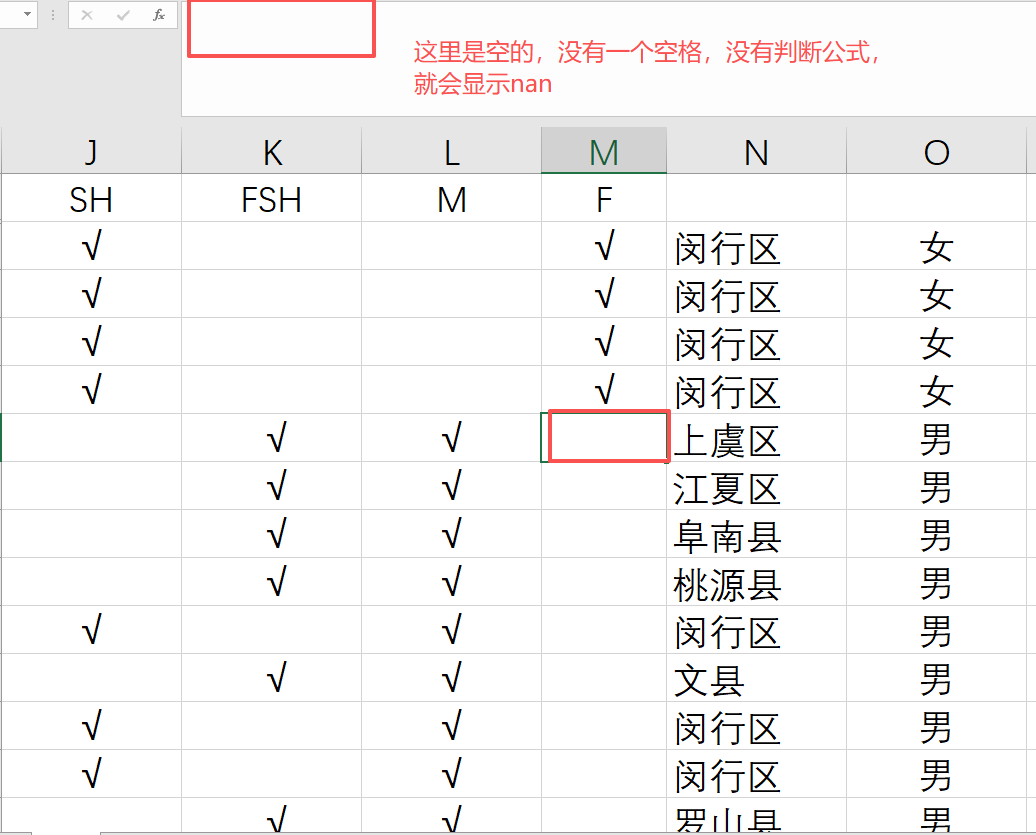
存在问题:男孩的单子上面,女部分写了nan

因为这里的空里面是完全空,没有一个空格,就会显示nan

如果添加了公式,内部就不是空,就不会打印任何内容
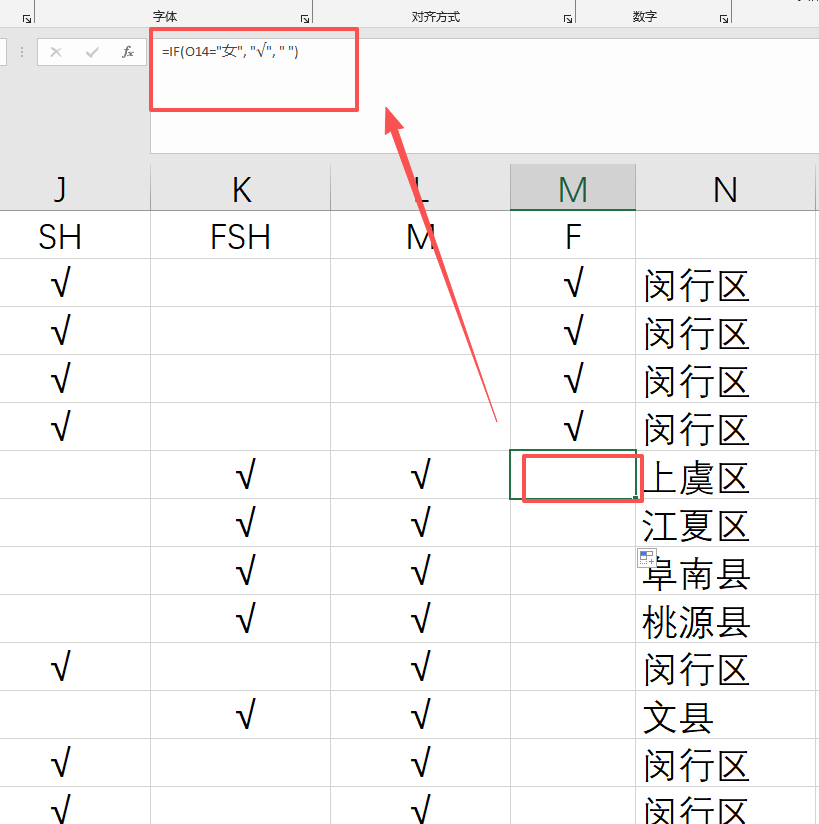
重新做了一份,没有nan

我做了一套有背景的范例
python
# -*- coding:utf-8 -*-
'''
目的:口腔检查涂氟单(一个班级单独打印)
作者:deepseek,阿夏
日期:20251215
'''
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
# numnum = int(input('请输入班级号(如4):\n'))
l = 1
# int(input('1、有背景图、2、无背景图\n'))
zpath = r'C:\Users\jg2yXRZ\OneDrive\桌面\20251215口腔涂氟' + "\\"
file_path = zpath + r'\零时Word'
# 二、遍历excel,逐个生成word(form.docx是前面的模板)
try:
os.mkdir(file_path)
except:
pass
# 读取Excel文件
IDcard = pd.read_excel(zpath + '名字虚拟.xlsx')
# 获取总人数(不包括标题行)
total_people = IDcard.shape[0]
print(f"Excel中共有 {total_people} 人")
num = IDcard["num"]
name = IDcard["name"]
school = IDcard["school"]
classroom = IDcard["classroom"] # 去掉换行符
y = IDcard["y"]
m = IDcard["m"]
d = IDcard["d"]
ID = IDcard["ID"]
SH = IDcard["SH"]
FSH = IDcard["FSH"]
M = IDcard["M"]
F = IDcard["F"]
dis=IDcard["dis"]
# 尝试这样读取
nation = IDcard["nation"]
# 遍历excel行,逐个生成
for i in range(total_people):
# python
print(IDcard["nation"].head()) # 查看前几行nation数据
print(IDcard["nation"][i]) # 在循环内打印当前处理的nation值
context = {
"num": str(num[i]),
"dis":dis[i],
"name": name[i],
"school": school[i],
"classroom": classroom[i],
"y": y[i],
"m": m[i],
"d": d[i],
"ID": ID[i],
"SH": SH[i],
"FSH": FSH[i],
"M": M[i],
"F": F[i],
"nation": nation[i],
}
if l == 1:
tpl = DocxTemplate(zpath + '打印单字(有背景).docx')
elif l == 2:
tpl = DocxTemplate(zpath + '打印单字(无背景).docx')
tpl.render(context)
tpl.save(file_path + fr'\{num[i]:02}.docx')
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = file_path + fr'\{num[i]:02}.docx'
outputFile = file_path + fr'\{num[i]:02}.pdf'
# 先创建不存在的文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
time.sleep(2)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并
import os
from PyPDF2 import PdfFileMerger
target_path = file_path
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
if l == 1:
file_merger.write(zpath + fr'\(测试){classroom[0]}班涂氟单({total_people}人)(虚拟有背景图).pdf')
elif l == 2:
file_merger.write(zpath + fr'\测试{classroom[0]}班涂氟单({total_people}人)(虚拟无背景图).pdf')
file_merger.close()
print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(file_path) #递归删除文件夹,即:删除非空文件夹