一、什么是机器学习
机器学习就是利用数学中的公式总结出数据中的规律
二、KNN算法
1、什么是KNN算法
全称是k-nearest neighbors,通过寻找k个距离最近的数据,来确定当前数据值的大小或类别。是机器学习中最为简单和经典的一个算法。
2、距离计算公式


3、KNN算法的优缺点
1)优点:
1.简单,易于理解,易于实现,无需训练;
2.适合对稀有事件进行分类;
3.对异常值不敏感。
2)缺点︰
1.样本容量比较大时,计算时间很长;
⒉.不均衡样本效果较差;
三、KNN算法--sklearn
1、sklearn是什么
Sklearn (Scikit-Learn) 是基于 Python 语言的第三方机器学习库。它建立在 NumPy, SciPy, Pandas 和 Matplotlib库 之上,里面的 API 的设计非常好,所有对象的接口简单,很适合新手上路。
2、sklearn的安装
在命令提示符输入:pip install scikit-learn==1.0.2即可

3、sklearn库中提供的参数
class sklearn.neighbors.KNeighborsClassifier ( n_neighbors=5 , weights='uniform' , algorithm='auto' , leaf_size=30 , p=2 , metric='minkowski' , metric_params=None , n_jobs=None , **kwargs )
n_neighbors:k值,邻居的个数,默认为5(是关键参数)
weights : 权重项,默认uniform 方法。
Uniform:所有最近邻样本的权重都一样。【一般使用这一个】
Distance:权重和距离呈反比,距离越近的样本具有更高的权重。【确认样本分布情况,混乱使用这种形式】
metric : 用于树的距离度量
四、案例
1)宿舍分配案例
通过网盘分享的文件:datingTestSet2.txt
链接: https://pan.baidu.com/s/1Le_1ZRWI7lAG8kpfzgxONw 提取码: yg57
原因:现在有很多大学里出现室友矛盾,假如室友可以选择: 大学里面 ,对于校方,把类型相同的学生放在一个寝室,在基于大二大三大四的
任务:现已存在一个数据文件datingTestSet2.txt ,为历年大学生的调查问卷表
第1列:每年旅行的路程
第2列:玩游戏所有时间百分比
第3列:每个礼拜消耗零食的重量
第4列:学生所属的类别,1表示爱学习,2表示一般般,3表示爱玩。 目的为学生在大学中挑选室友的信息
想要知道每年旅行路程、玩游戏每天所占百分比、每个礼拜消耗零食的重量分别为75136,13.147394,0.428964的学生所属的类别
python
import matplotlib.pyplot as plt
import numpy as np
data=np.loadtxt('datingTestSet2.txt',delimiter="\t")
a=data[data[:,-1]==1]
b=data[data[:,-1]==2]
c=data[data[:,-1]==3]
fig=plt.figure()
ax=plt.axes(projection="3d")
ax.scatter(a[:,0],a[:,1],a[:,2],c='r',marker="o")
ax.scatter(b[:,0],b[:,1],b[:,2],c='g',marker="^")
ax.scatter(c[:,0],c[:,1],c[:,2],c='b',marker="+")
ax.set(xlabel="x",ylabel="y",zlabel="z")
plt.show()
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
data=np.loadtxt('datingTestSet2.txt',delimiter="\t")
x=data[:,:-1]
y=data[:,-1]
a=KNeighborsClassifier(n_neighbors=5)
a.fit(x,y)
print(a.predict([[75136,13.147394,0.428964]]))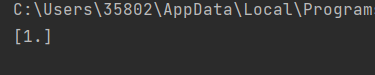
n_neighbors=5代表当这个学生的75136,13.147394,0.428964带入到训练集中进行测试,找到在于这个点最近的5个点中,所含类别最多的一类,输出结果为1,说明5个点中类别为1的点比较多
缺点:由于每年旅行路程、玩游戏每天所占百分比、每个礼拜消耗零食的重量的数据有的很大,有的很小,就会导致,当某个很大的那个数据没有发生很大的改变,而比较的小数据发生了大的改变时,变化的也不是很明显,所以,这个时候就可以使用标准化来统一一下数据的范围
1、归一化
就是把除了最后一列的数据,其他数据都变成零到一以内的数
2、z标准化

使用from sklearn.preprocessing import scale
python
import pandas as pd #为什么? numpy可以读二维数据 和
# pandas表格类型的数据
#读取数据
"""
train_data:训练集
test_data:测试集
"""# numpy:数组形式来读取数据,pandas:以表格的形式来读取数据,
train_data = pd.read_excel("鸢尾花训练数据.xlsx")
test_data = pd.read_excel("鸢尾花测试数据.xlsx")
"""
处理训练集数据;
数据重排;变量与标签分离.
"""
train_X = train_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
train_y = train_data[['类型_num']]#加入了中阔号返回的是2维
"""
标准化语法 归一化:0~1:是对每一个列(特征)进行归一化
Z-Score标准化 -1~1,
"""
from sklearn.preprocessing import scale#对输入的数据进行减去均值并除以标准差的操作,从而将数据转换为均值为0、标准差为1的分布。这个操作可以使得不同特征之间的尺度一致,避免因为某些特征的尺度过大或者过小而影响模型的训练效果。
data = pd.DataFrame() #空的表格数据对象
data['萼片长标准化'] = scale(train_X['萼片长(cm)']) #series 列数据
data['萼片宽标准化'] = scale(train_X['萼片宽(cm)'])
data['花瓣长标准化'] = scale(train_X['花瓣长(cm)'])
data['花瓣宽标准化'] = scale(train_X['花瓣宽(cm)'])
#数据开始做了一次 预处理,目标:为了让每个特征的数据都在差不多大小的范围内。
"""
使用sklearn库中的KNN模块
"""
from sklearn.neighbors import KNeighborsClassifier
#【1~10】
knn = KNeighborsClassifier(n_neighbors=5) #最好是奇数
knn.fit(train_X, train_y)#到这里训练就已经结束。
train_predicted = knn.predict(train_X)#,自测预测
score= knn.score(train_X, train_y)#最总的分。先将data数据传入模型进行预测,得到预测结果,将预测结果和train_y进行比较
"""
使用测试集数据进行测试
"""
test_X = test_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
test_y = test_data[['类型_num']]
"""
标准化语法
Z-Score标准化
"""
from sklearn.preprocessing import scale
data_test = pd.DataFrame() #传入新的数据,从来没有传入到模型中的
a = test_X['萼片长(cm)']
data_test['萼片长标准化'] = scale(test_X['萼片长(cm)']) #存在一点小问题。
data_test['萼片宽标准化'] = scale(test_X['萼片宽(cm)'])
data_test['花瓣长标准化'] = scale(test_X['花瓣长(cm)'])
data_test['花瓣宽标准化'] = scale(test_X['花瓣宽(cm)'])
#预测结果
test_predicted = knn.predict(test_X)
score= knn.score(test_X, test_y)#将测试的特征传入进来,内部会自动将特征传入模型进行预测,得到预测结果y',
print(score)knn.fit(tarin_x,train_y):是用来训练train_x和train_y的数据
knn.predict(train_x)进行自测
knn.score(train_x,train_y):将自测的train_x对应的train_y与当为train_x时,训练集所给出的y值进行比较,计算出所占的百分比
knn.predict(test_x)对真实值进行测试
knn.score(test_x,test_y):将测试的test_x对应的test_y与当为test_x时,训练集所给出的y值进行比较,计算出所占的百分比
注:当进行测试时,训练集的内容不能当作被测试的对象
通过网盘分享的文件:鸢尾花测试数据.xlsx
链接: https://pan.baidu.com/s/1OqAmlnbM0CiIc0zJXH8D6Q 提取码: xiaj
通过网盘分享的文件:鸢尾花训练数据.xlsx
链接: https://pan.baidu.com/s/1EvhUQ2aqCMm1IqThLgUn0Q 提取码: pbr4