1.项目概要
本项目针对个人博客系统开展全维度自动化测试,覆盖系统核心模块(登录界面、首页、详情页、编辑页),围绕功能、安全、性能、界面、兼容性、易用性 6 大测试方向设计用例,验证系统在不同场景下的可用性、稳定性与可靠性。
1.1项目测试背景
为满足个人创作者 "低成本搭建专属内容发布平台" 的需求,本博客系统以 "轻量、易用、自主可控" 为核心目标开发:
- 支持创作者独立完成博客内容的编辑、发布、管理;
- 提供用户身份验证、内容展示等基础功能,同时预留扩展接口(如评论、分类统计);
- 适配多终端场景,帮助创作者实现内容的跨设备触达;
1.2测试目的及测试启动背景
为确保系统正式上线后能稳定支撑创作者的日常使用,需通过全维度测试验证:
- 功能流程的正确性(如博客发布、编辑、删除的无异常执行);
- 非功能维度的达标性(如登录响应速度、多终端兼容性、数据传输安全性);
- 用户操作的易用性(如错误提示的清晰性、流程的流畅度);最终保障系统从 "可用" 升级为 "可靠、好用" 的个人内容平台。
1.3测试环境
软件:Google Chrome
测试工具:postman、selenium、JMeter
开发工具:pyCharm Community Edition 2024.2.1
操作系统:Windows 11家庭中文版
浏览器版本:Google Chrome、Microsoft Edge
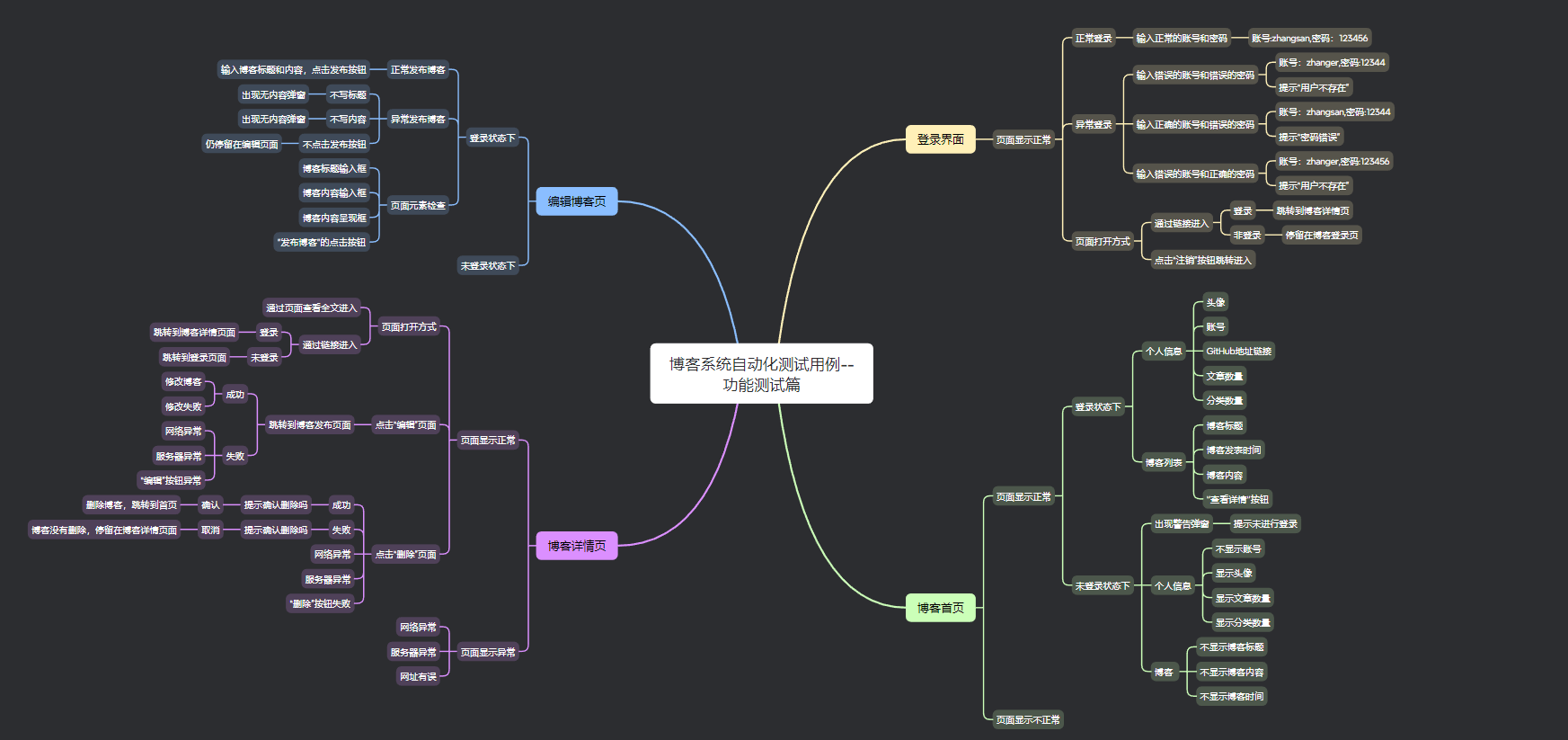
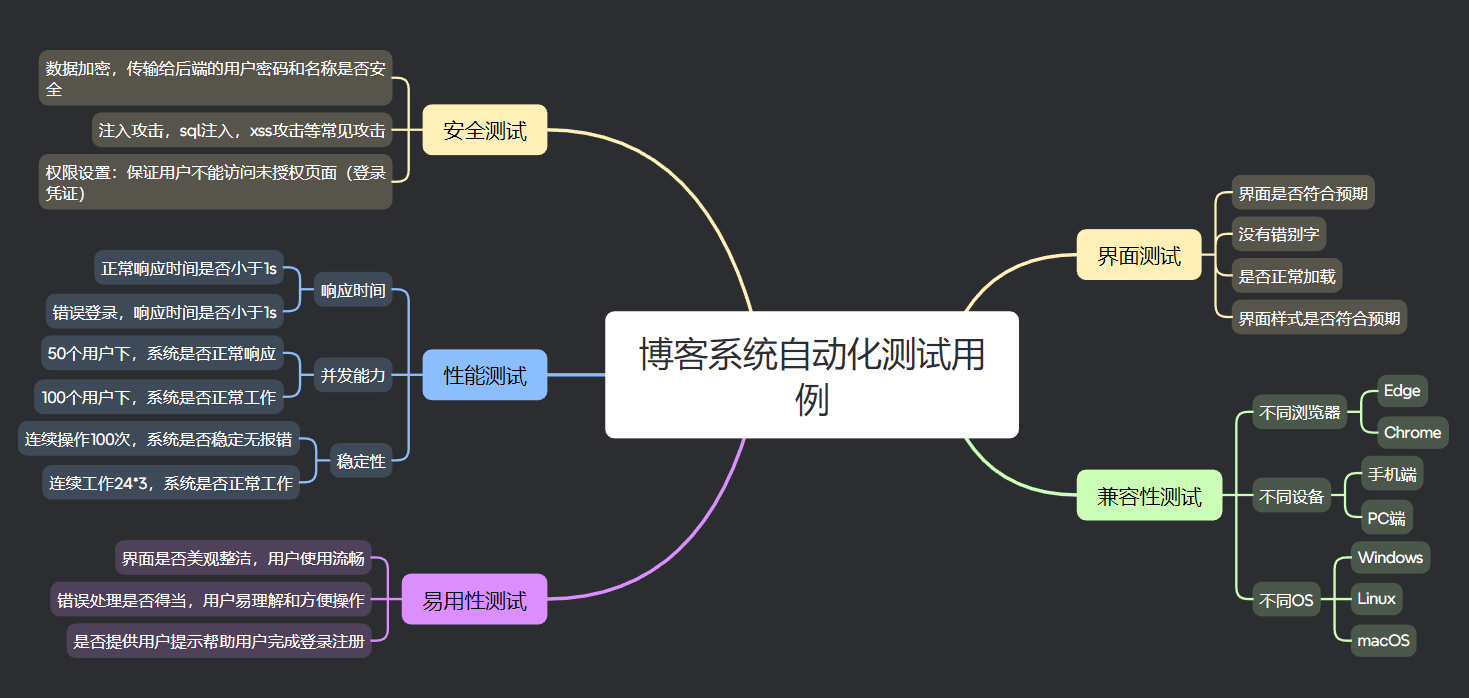
2.测试用例编写
3.手工测试
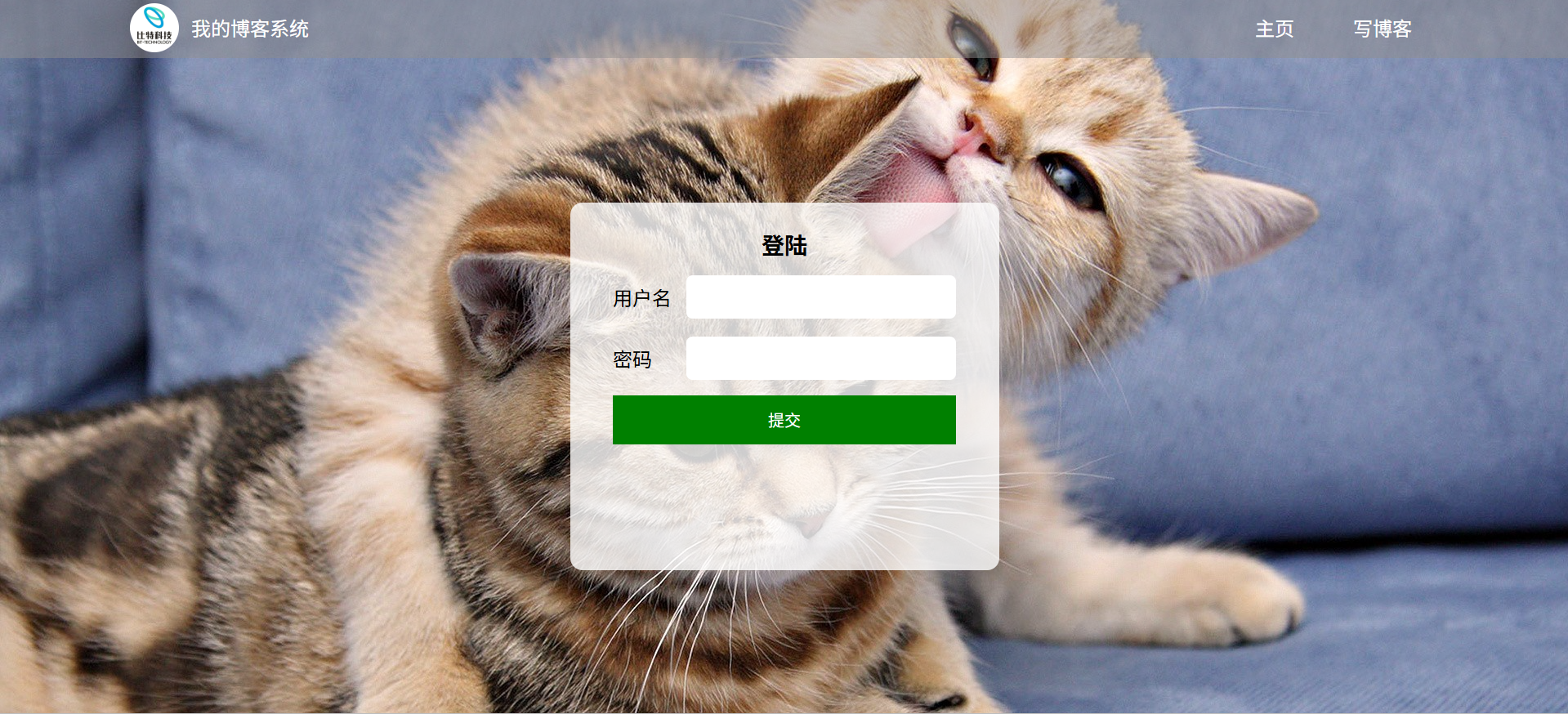
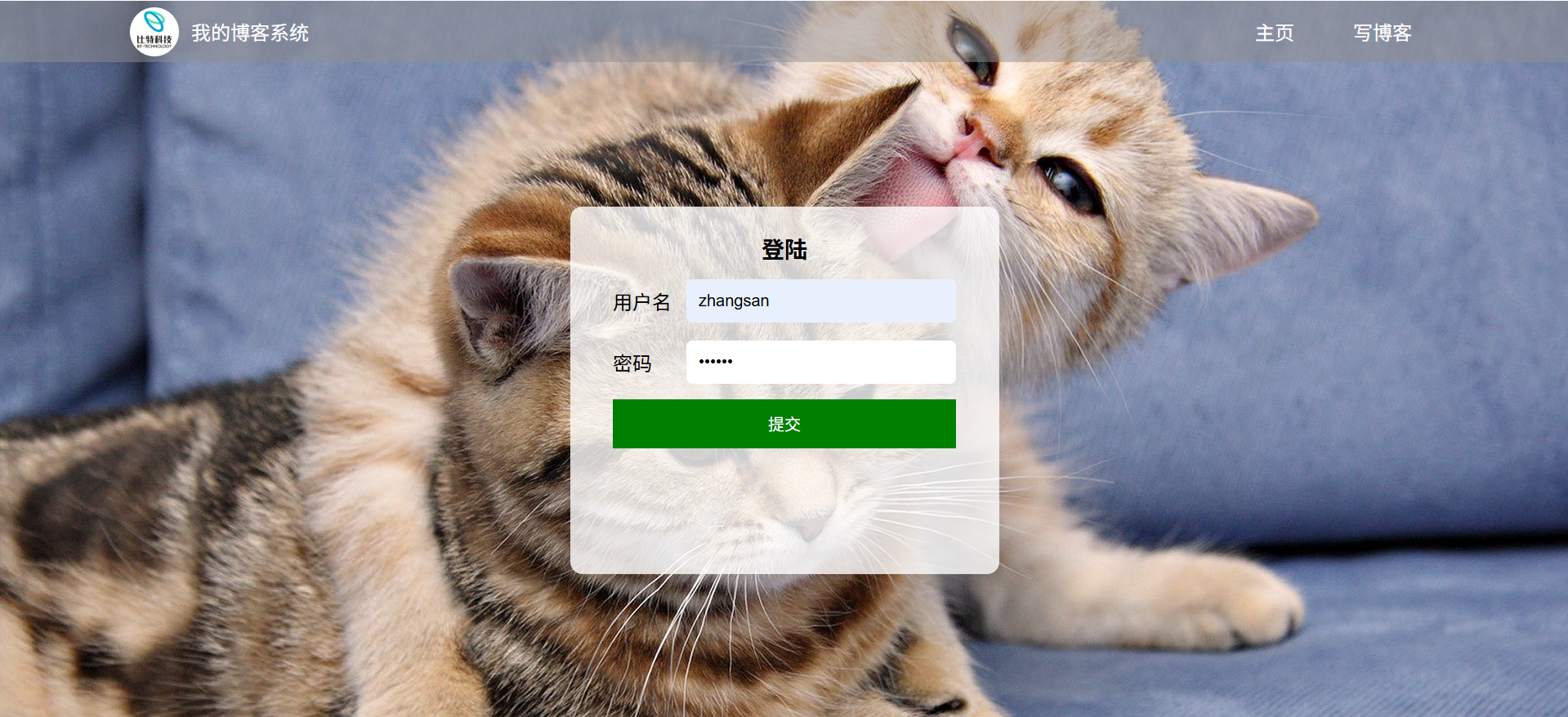
3.1登录页面测试
如图所示,登录弹窗布局清晰、无文字错误、图片 / 样式加载正常;用户名 / 密码输入框可正常输入、删除内容。
3.2主页测试

3.3博客编辑页面测试
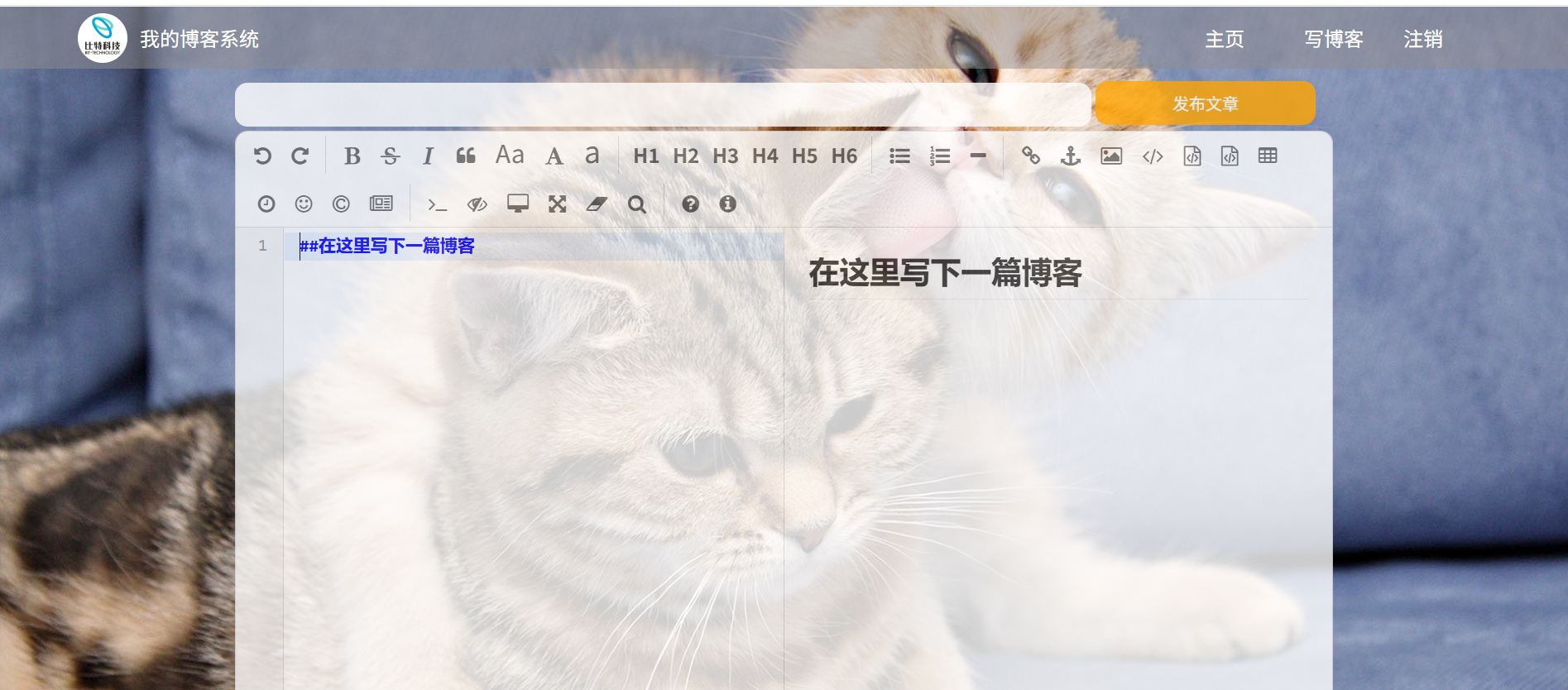
3.4博客详情页测试
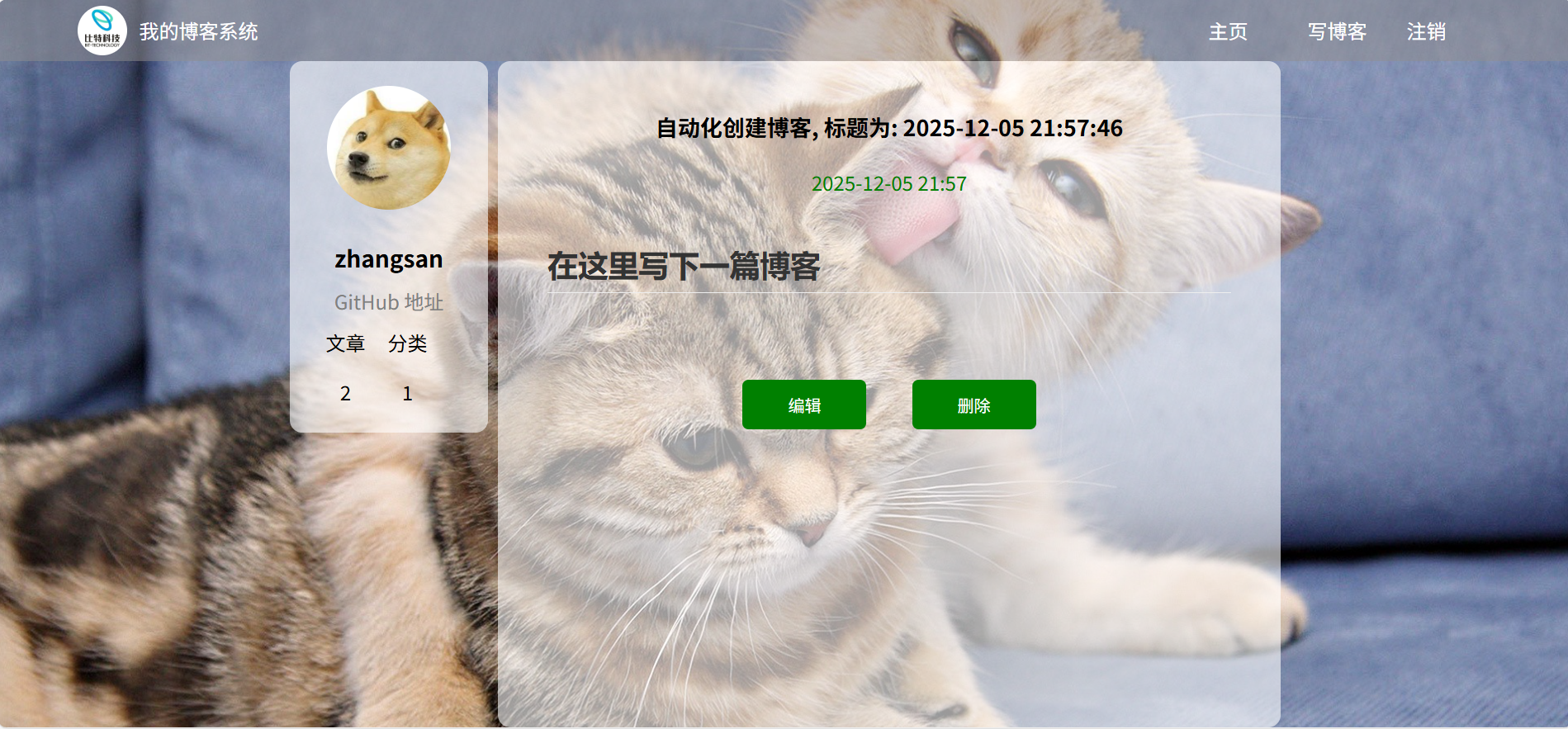
4.博客兼容性测试
4.1不同浏览器
- Chrome
- Edge
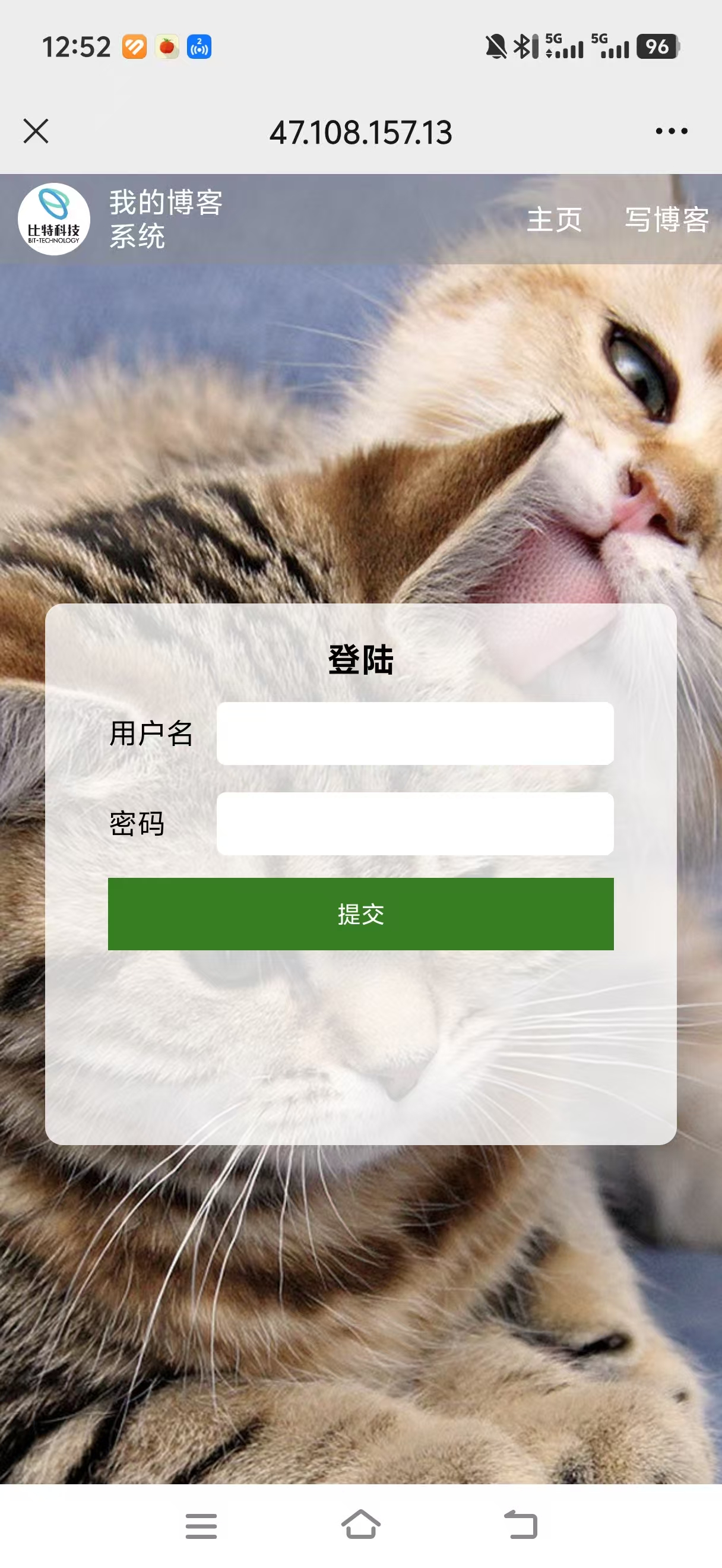
4.2设备兼容性测试
- PC端
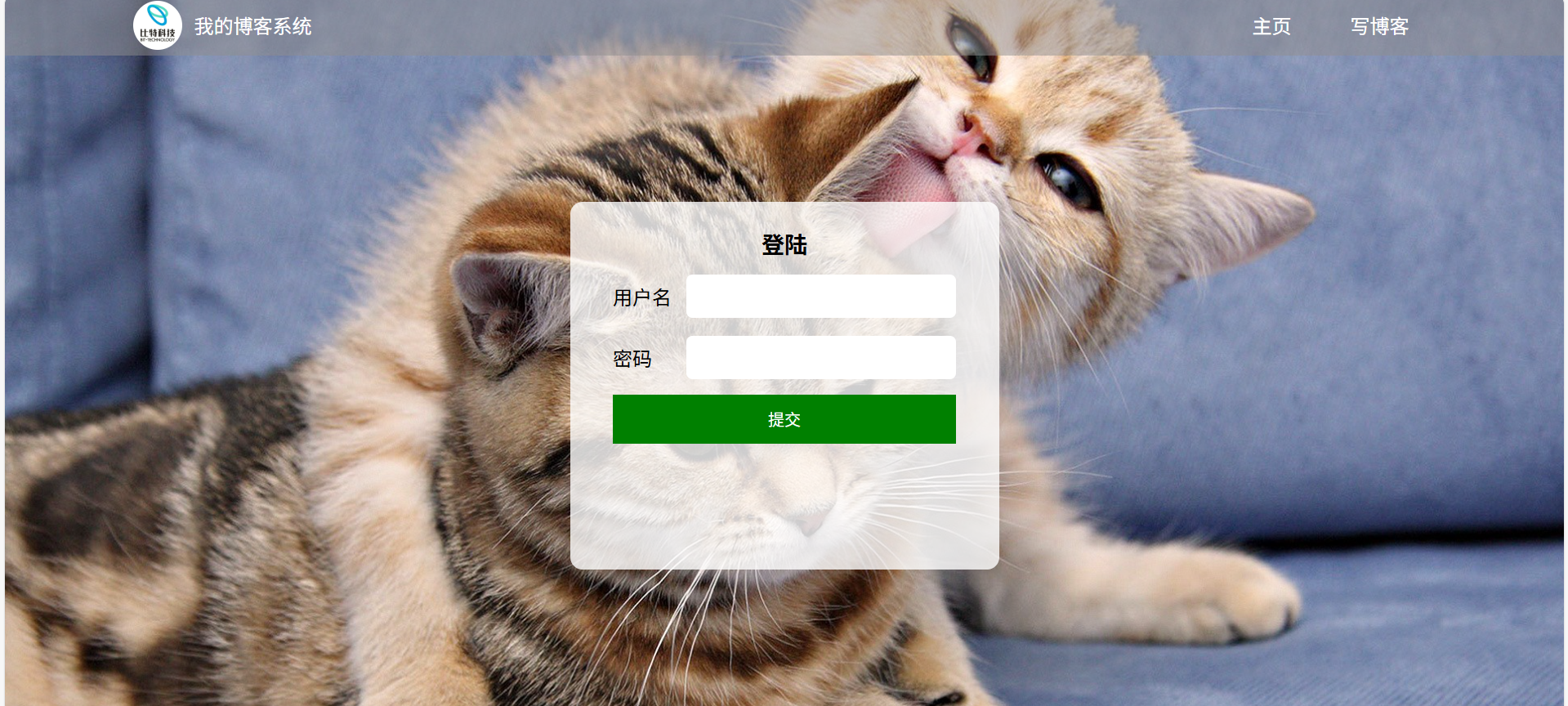
- 手机端
5.自动化测试
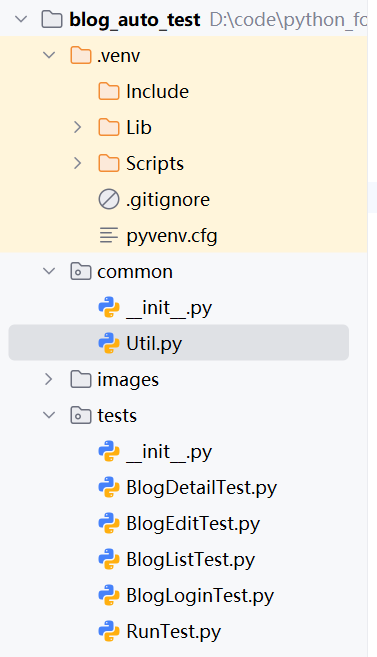
5.1项目目录
5.2驱动类(Util.py)
python
import os.path
import sys
from datetime import datetime
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from webdriver_manager.core.driver import Driver
#创键你一个浏览器对象
class Driver: #创建一个driver类,把test中所有可能用到的东西都装进去
driver = "" #创建一个驱动对象,其中一个成员为空
def __init__(self):#构造函数
options=webdriver.ChromeOptions()
from selenium.webdriver.chrome.service import Service
self.driver=webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options)
#为每个调用Driver类的类对象都对应一个driver成员
#单例模式,所有的测试问价都用一个driver
def getScreenShot(self):
#创建屏幕截图
#图片文件名称
dirname = datetime.now().strftime("%Y-%m-%d")#生成的文件夹名称
#判断dirname文件夹是否已经存在
if not os.path.exists("../images/"+dirname):
os.mkdir("../images/"+dirname)
filename=sys._getframe().f_back.f_code.co_name+"-"+datetime.now().strftime("%Y-%m-%d-%H%M%S")+".png"
self.driver.save_screenshot("../images/"+dirname+"/"+filename)
BlogDriver = Driver()5.3登录类 (BlogLoginTest.py)
python
import time
from selenium.webdriver.common.by import By
from common.Util import BlogDriver
#测试博客登录页面
class BlogLogin:
url=""
driver=""
def __init__(self, ):
self.url="http://47.108.157.13:8090/blog_login.html"
self.driver=BlogDriver.driver
self.driver.get(self.url)
#成功登陆的测试用例
def LoginSucTest(self):
self.driver.find_element(By.CSS_SELECTOR,"#username").send_keys("zhangsan")
self.driver.find_element(By.CSS_SELECTOR,"#password").send_keys("123456")
self.driver.find_element(By.CSS_SELECTOR,"#submit").click()
time.sleep(2)
#能够找到博客首页的昵称,说明登录成功,否则登录失败
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.left > div > h3")
#添加屏幕截图
BlogDriver.getScreenShot()
time.sleep(5)
self.driver.back()
#异常登录的测试用例
def LoginFailTest(self):
self.driver.find_element(By.CSS_SELECTOR, "#username").clear()
self.driver.find_element(By.CSS_SELECTOR, "#password").clear()
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("zhanger")
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("12344")
self.driver.find_element(By.CSS_SELECTOR, "#submit").click()
time.sleep(3)
#检查登录是否成功
alert=self.driver.switch_to.alert
actual=alert.text
#断言一下是否符合预期
alert.accept()
assert actual =="用户不存在"
BlogDriver.getScreenShot()
self.driver.back()
#self.driver.quit()5.4首页类(BlogListTest.py)
python
import time
from selenium.webdriver.common.by import By
from common.Util import BlogDriver
#博客首页测试用例
class BlogList:
url =""
driver=""
def __init__(self):
self.url="http://47.108.157.13:8090/blog_list.html"
self.driver=BlogDriver.driver
self.driver.get(self.url)
#测试首页(登录情况下)
def ListTestByLogin(self):
time.sleep(2)
#测试博客标题是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > div.title")
#测试博客内容是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > div.desc")
#测试"查看全文"按钮是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > a")
#检查个人信息的昵称是否存在
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.left > div > h3")
#添加屏幕截图
BlogDriver.getScreenShot()5.5详情类
python
import time
from selenium.webdriver.common.by import By
from common.Util import BlogDriver
#测试博客详情页
class BlogDetail:
url=""
driver=""
def __init__(self):
# 刚才的问题就是之前的blogId的博客被清除了,所以报了"操作有误,请联系管理员" 这个错误
self.url="http://47.108.157.13:8090/blog_detail.html?blogId=33981"
self.driver= BlogDriver.driver
self.driver.get(self.url)
#登录状态下博客详情页的测试
def DetailTestByLogin(self):
time.sleep(2)
#标题
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div > div.title")
#时间
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div > div.date")
#内容
self.driver.find_element(By.XPATH,'//*[@id="detail"]/p')
#屏幕截图
BlogDriver.getScreenShot()
# 未登录状态下的博客详情页面测试
def DetailTestFileLogin(self):
# 注销
self.driver.find_element(By.CSS_SELECTOR, "body > div.nav > a:nth-child(6)").click()
# 登录
self.driver.find_element(By.CSS_SELECTOR, "body > div.container-login > div > h3")
#用户名
self.driver.find_element(By.CSS_SELECTOR, "body > div.container-login > div > div:nth-child(2) > span")
#密码
self.driver.find_element(By.CSS_SELECTOR, "body > div.container-login > div > div:nth-child(3) > span")
#提交
self.driver.find_element(By.CSS_SELECTOR, "#submit")
BlogDriver.getScreeShot()5.6编辑类(BlogEditTest.py)
python
# 正确的导入方式(放在文件开头)
from selenium.webdriver.support import expected_conditions as EC # 关键:这里的EC是expected_conditions的别名
import time
from telnetlib import EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from common.Util import BlogDriver
#from tests.BlogDetailTest import BlogDetail
#博客编辑页面
class BlogEdit:
url=""
driver=""
#登录状态下,写博客
def __init__(self):
self.url="http://47.108.157.13:8090/blog_edit.html"
self.driver=BlogDriver.driver
self.driver.get(self.url)
#在登录状态下,正确发布博客
def EditSucTest(self):
self.driver.find_element(By.CSS_SELECTOR,"#title").send_keys("自动化测试创建1")
time.sleep(3)
#找到编辑区域,输入关键词(发现编辑区域不可操作)
#菜单栏元素无法定位
#博客编辑区域默认状态下不为空,暂不处理
#直接点击发布按钮来发布博客
self.driver.find_element(By.CSS_SELECTOR,"#submit").click()
time.sleep(1)
url = self.driver.current_url
assert "blog_list.html" in url
#
# WebDriverWait(self.driver, 15, 0.5).until(
# # 这里替换成你页面中"发布完成"的标识元素(比如成功提示、新页面加载等)
# EC.url_contains("blog_list.html")
# )
actual=self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(4) > div.title").text
# 这里最好别用这个进行断言,因为这个博客系统会定期对数据库进去清除,之前发布的博客信息 也会被清除
# assert actual =="自动化测试创建1"
#屏幕截图
BlogDriver.getScreenShot()
time.sleep(3)
# 错误发布博客(未登录状态下)
def EditSucTestbyNoLogin(self):
# 注销
self.driver.find_element(By.CSS_SELECTOR, "body > div.nav > a:nth-child(6)").click()
# 登录
self.driver.find_element(By.CSS_SELECTOR, "body > div.container-login > div > h3")
# 用户名
self.driver.find_element(By.CSS_SELECTOR, "body > div.container-login > div > div:nth-child(2) > span")
# 密码
self.driver.find_element(By.CSS_SELECTOR, "body > div.container-login > div > div:nth-child(3) > span")
# 提交
self.driver.find_element(By.CSS_SELECTOR, "#submit")
BlogDriver.getScreeShot()5.7启动类(RunTest.py)
python
import time
from tests.BlogEditTest import BlogEdit
from tests.BlogDetailTest import BlogDetail
from tests.BlogListTest import BlogList
from tests.BlogLoginTest import BlogLogin
from common.Util import BlogDriver
#表示程序的执行入口
if __name__ == "__main__":
#创建类对象,调用其方法
# BlogLogin().LoginFailTest()
# time.sleep(3)
BlogLogin().LoginSucTest()
time.sleep(3)
#登陆成功之后就可以调用博客首页测试首页的用例(登录状态)
BlogList().ListTestByLogin()
#测试登录状态下的登录详情页
BlogDetail().DetailTestByLogin()
#博客编辑页面测试
BlogEdit().EditSucTest()
#执行浏览器的退出
BlogDriver.driver.quit()6.性能测试
6.1目录
6.2登录
6.3列表页
6.4详情页
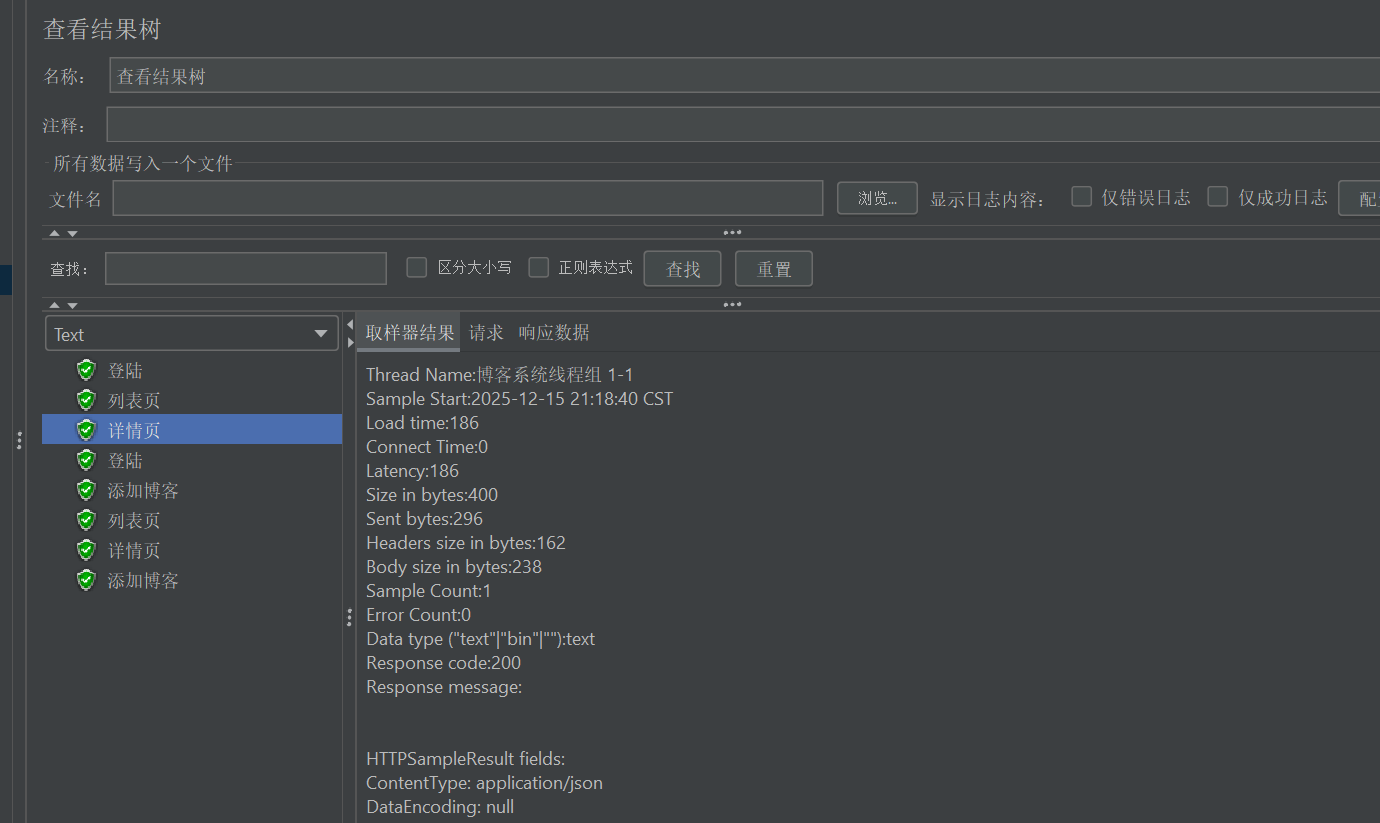
6.5添加博客
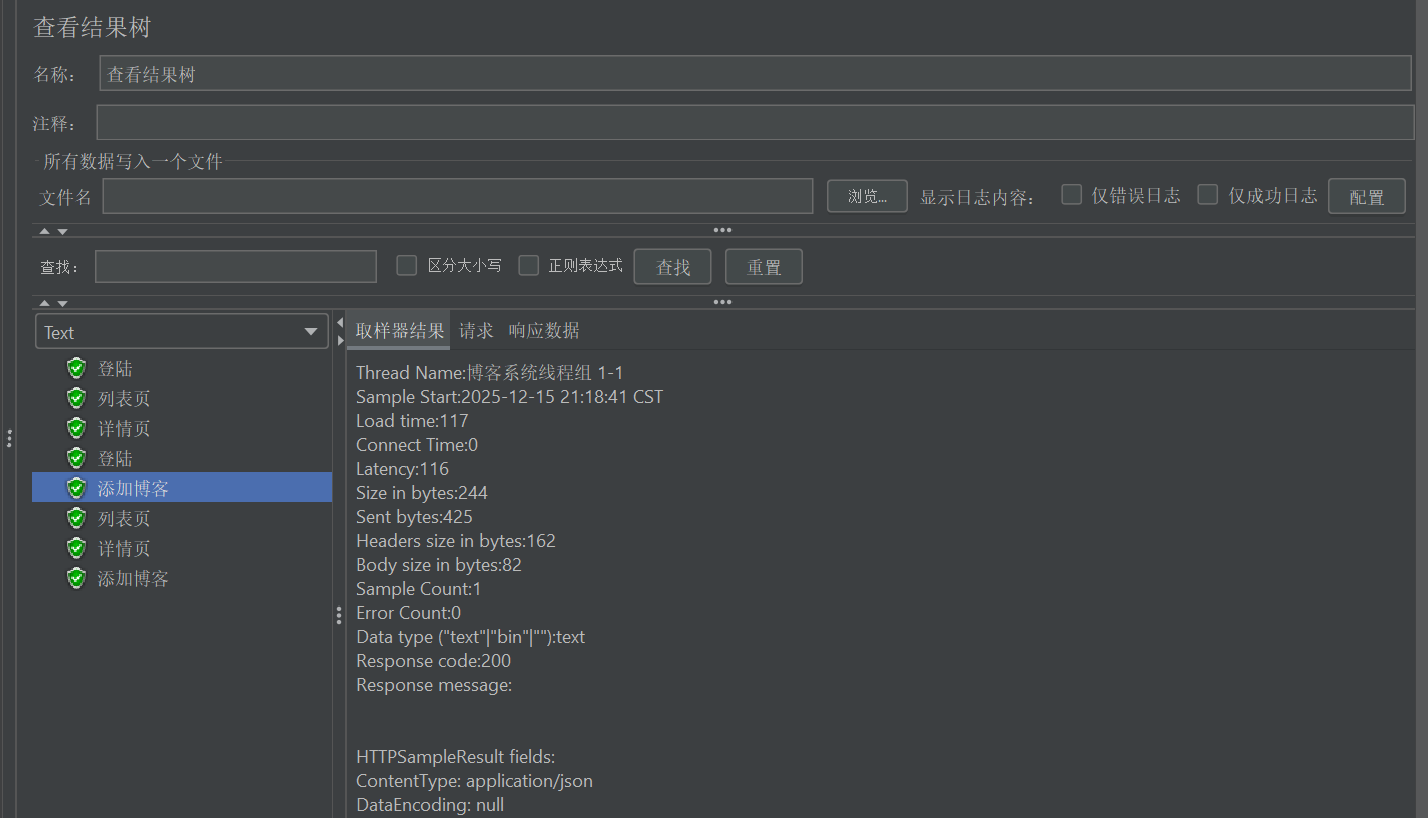
6.6聚合报告
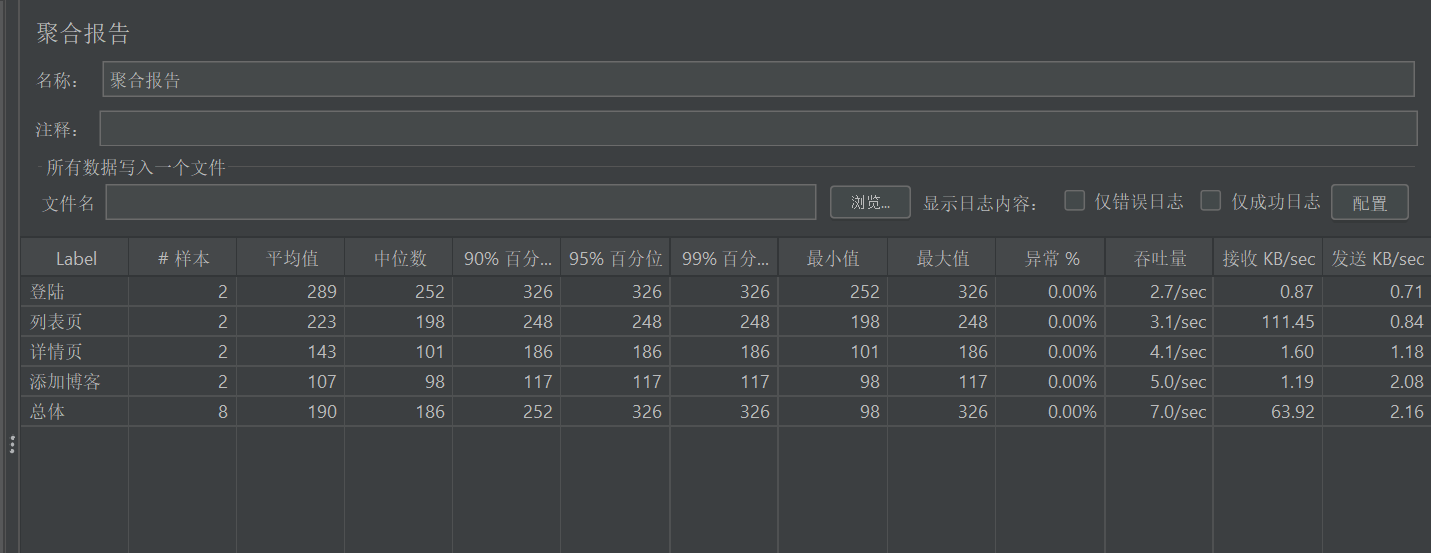
6.7Transaction per Second(吞吐量)
JMeter 中的吞吐量(Throughput) 是指在测试时间段内,系统成功处理的请求数量(或事务数)与时间的比值。
吞吐量是性能测试的核心指标之一(与响应时间、错误率、资源利用率并称四大核心指标),直接反映系统的处理能力和负载容量,吞吐量越高说明系统的处理事务能力越强。
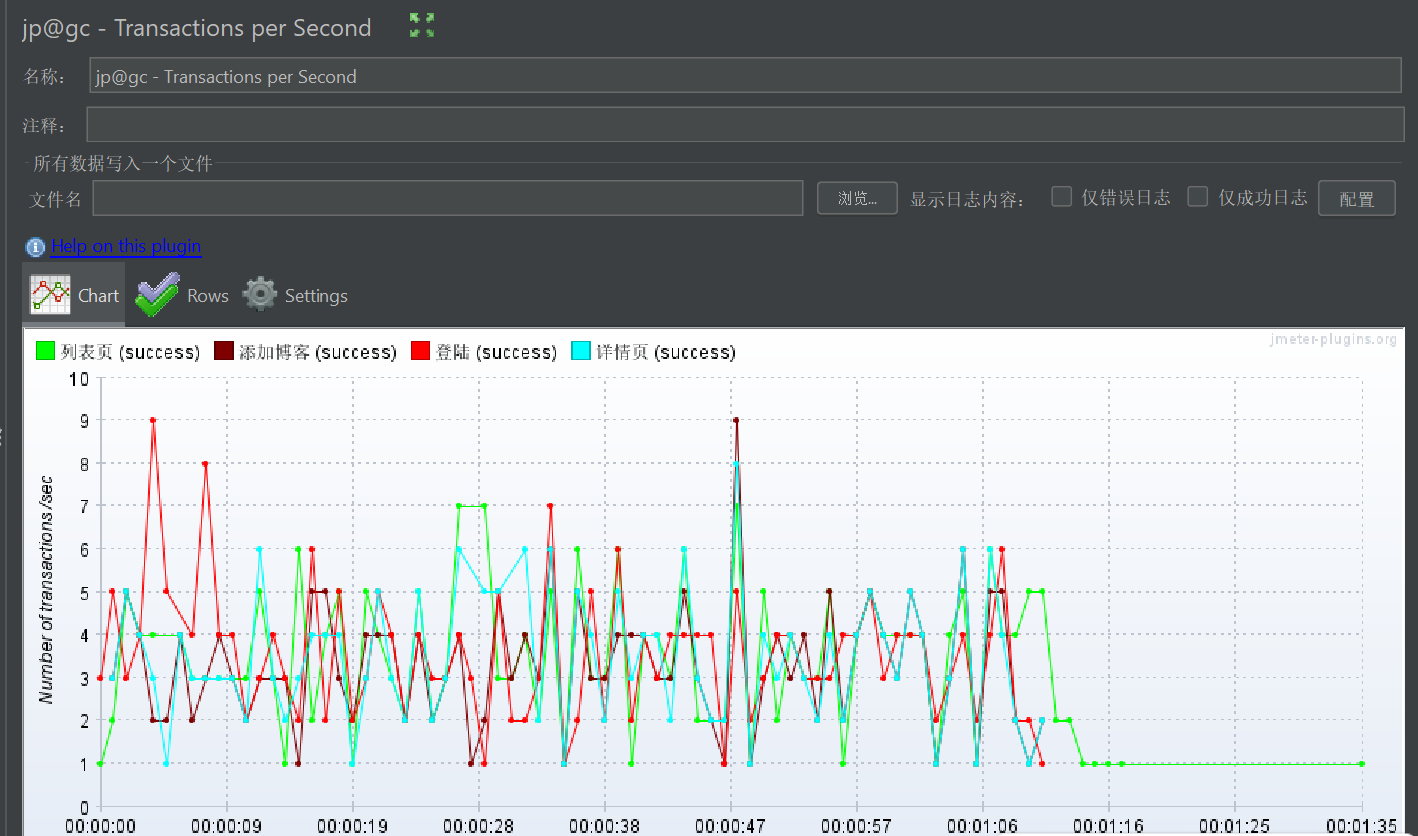
6.8Response Times over Time(响应时间)
响应时间(Response Time),也叫延迟时间,是指从用户(或测试工具)发送一个请求开始,到接收到服务器返回的完整响应为止的总耗时,单位通常为毫秒(ms)。
响应时间是用户体验的直接体现,也是性能测试中最贴近用户感知的核心指标,地位与吞吐量同等重要。
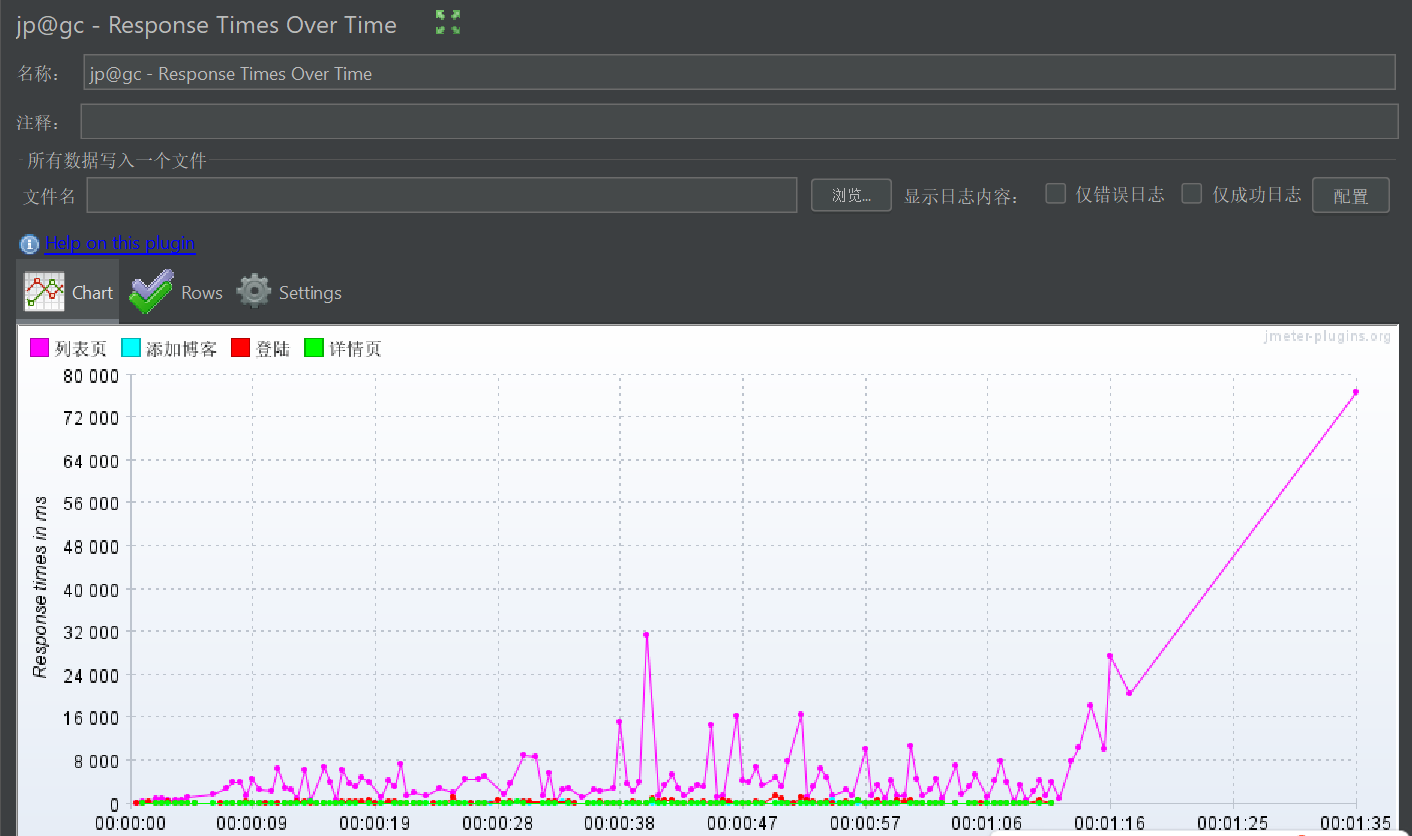
6.9 Active Threads Over Time(随时间变化的活跃线程状态)
6.10性能测试报告
JMeter测试报告是一个全面而详细的文档,它提供了关于测试执行结果的详细信息,帮助用户全面评估系统的性能并进行性能优化。
7.总结
7.1 响应时间表现:整体趋势 + 各接口详情
1. 整体趋势
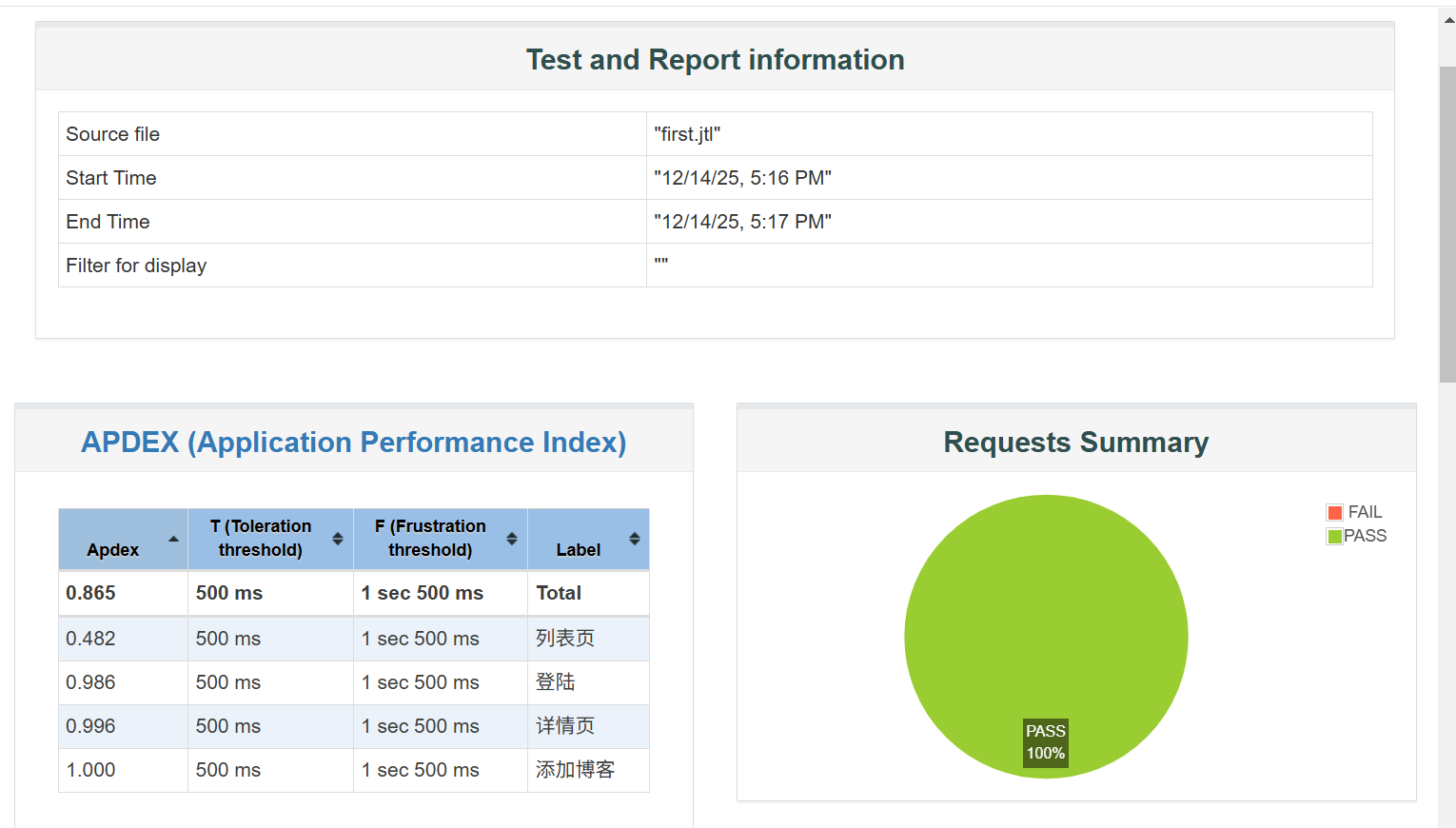
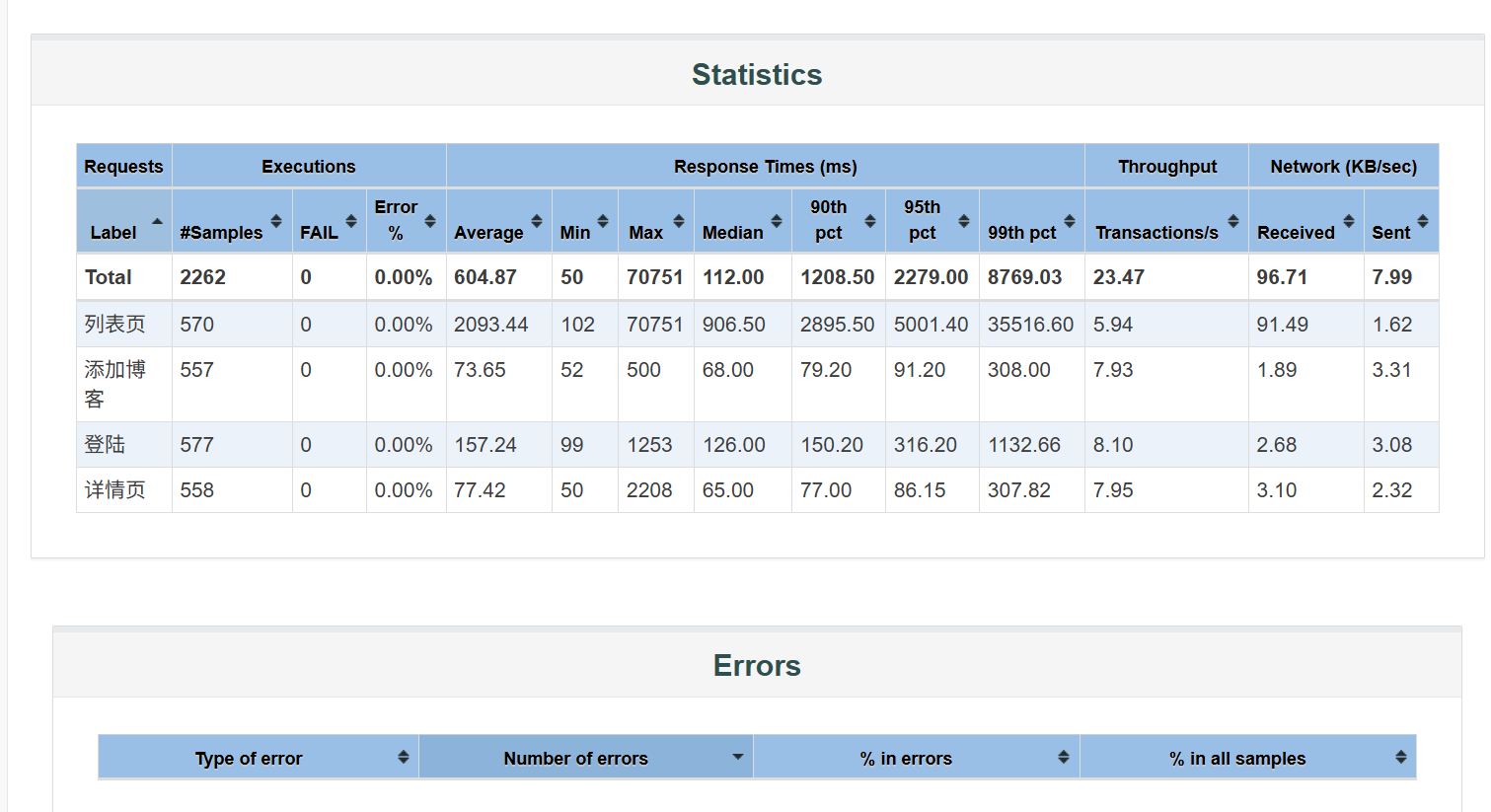
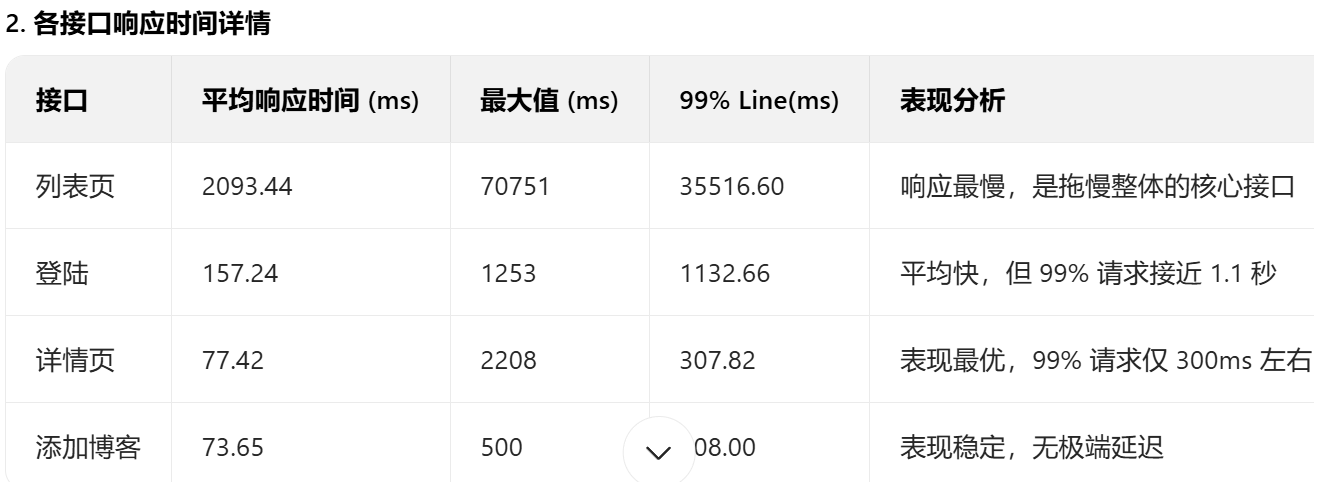
测试总时长 1 分钟(12/14/25 5:16-5:17),整体平均响应时间 604.87ms,但存在明显的 "长尾请求":
- 最大值达到 70751ms(约 70 秒),说明有极少数请求响应极慢;
- 99% Line(99% 请求的响应时间)为 8769.03ms(约 8.8 秒),远超 "可接受" 阈值(通常 1-3 秒),用户体验会受影响。
7.2吞吐量和数据传输分析
1. 吞吐量
- 整体吞吐量:23.47 Transactions/s(每秒处理 23.47 个请求);
- 各接口吞吐量(按请求数占比):列表页(5.94)、添加博客(7.93)、登陆(8.10)、详情页(7.95)------ 接口间吞吐量分布较均衡,但整体吞吐量不算高(1 分钟仅处理 2262 个请求)。
2. 数据传输
- 整体接收速率:96.71 KB/sec(每秒从服务器接收约 97KB 数据);
- 各接口传输:列表页接收速率最高(91.49 KB/sec),说明该接口返回的数据量最大(可能是列表数据多),这也是其响应时间长的原因之一;
- 发送速率整体仅 7.99 KB/sec,说明请求数据量很小,瓶颈不在请求端。
7.3 线程与并发分析
- 系统在 50 线程满并发下,处理能力不足:理论上 50 线程应支撑更高吞吐量,但实际仅 23.47,且列表页响应时间暴增,说明系统(尤其是列表页接口)无法承载 50 线程的并发压力。
- 线程启动 / 结束策略的合理性:
- 启动策略(每 3 秒启动 5 个)是 "梯度加压",符合真实场景的流量增长;
- 结束策略(每 1 秒结束 5 个)是 "快速减压",但测试总时长 60 秒下,结束阶段仅占 10 秒,主要压力集中在满并发的 33 秒,能有效暴露高并发下的瓶颈。
- 列表页是并发瓶颈:在 50 线程压力下,列表页的实际处理能力(5.94 Transactions/s)远低于其他接口,是限制整体并发能力的关键。
7.4 核心总结点
优势:
- 数据发送量小,请求本身无冗余数据。
- 详情页、添加博客接口响应快且稳定,99% 请求延迟低于 300ms;
- 所有请求错误率为 0,系统稳定性较好,无请求失败;
风险点:
- 列表页是性能短板:平均响应超 2 秒,最大值达 70 秒,99% 请求超 35 秒,严重影响用户体验;
- 整体存在长尾请求:99% Line(8.8 秒)远超用户可接受阈值,可能是系统资源(CPU / 内存)或依赖服务(数据库)在高并发下出现争抢;
- 整体吞吐量偏低:1 分钟仅处理 2262 个请求,若业务高峰期并发更高,系统承载能力不足。