引言
在机器学习数据预处理环节,降维绝对是绕不开的核心技术之一,而主成分分析(PCA)作为降维领域的扛把子,更是面试和项目中的高频考点。今天这篇文章,我们就从为什么需要PCA讲起,一步步拆解原理、推导关键公式,最后用Python实战落地,确保零基础也能看懂,看完就能用!
一、PCA 核心思想:用少数关键特征替代多数冗余特征
高维数据的痛点很明显:特征过多导致计算量大、存在多重共线性(特征间高度相关)、可视化困难。PCA 的核心解决思路是:降维不减信息
- 找到数据中 "方差最大" 的方向(主成分),这些方向能最大程度保留数据的分布特征。
- 用前 k 个方差最大的主成分,替代原始的 n 个特征(k<<n),实现维度压缩。
- 本质是将原始数据从 n 维空间,投影到 k 维的 "主成分空间",投影后数据的信息损失最小。
**举个通俗例子:**用 "身高 + 体重" 描述人的体型,两个特征存在相关性。PCA 可以找到一个新特征(比如 "体型指数"),这个特征能涵盖身高和体重的核心信息,用 1 个特征替代 2 个特征,这就是降维。
二、PCA 数学原理:3 个关键步骤
PCA 的数学基础是方差、协方差矩阵、特征值分解,无需深入推导公式,记住核心步骤即可:
1. 数据标准化(必须要完成的一个步骤)
原始特征的量纲可能不同(比如身高用 cm,体重用 kg),会影响方差计算。需将所有特征转换为 "均值为 0,方差为 1" 的标准正态分布:
标准化后的值 = (原始值 - 特征均值) / 特征标准差2. 计算协方差矩阵
协方差矩阵用于描述特征间的相关性:
- 对角线元素:单个特征的方差(值越大,该特征越重要)。
- 非对角线元素:两个特征的协方差(值为 0 表示无关,正值正相关,负值负相关)。
3. 特征值分解与主成分选择
对协方差矩阵做特征值分解,得到:
- 特征值:对应主成分的方差大小(特征值越大,该主成分越重要)。
- 特征向量:对应主成分的方向(数据投影的方向)。
选择前 k 个最大的特征值对应的特征向量,构成投影矩阵,将原始数据乘以该矩阵,即可得到降维后的 k 维数据。
三、Python 实战:用 sklearn 实现 PCA(鸢尾花数据集案例)
接下来用经典的鸢尾花数据集(4 个特征)演示 PCA 降维 ,目标是将 4 维数据降到 2 维,方便可视化。
1. 环境准备
确保安装了必要库:
python
pip install numpy pandas matplotlib scikit-learn
2. 完整代码(带注释)
python
# 1. 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 2. 加载数据
iris = load_iris()
X = iris.data # 原始数据:4个特征(花萼长、花萼宽、花瓣长、花瓣宽)
y = iris.target # 标签:3类鸢尾花
# 3. 数据标准化(关键步骤)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 标准化后的数据
# 4. 初始化PCA模型,降维到2维
pca = PCA(n_components=2) # n_components:目标维度
X_pca = pca.fit_transform(X_scaled) # 执行PCA降维
# 5. 查看结果
print("原始数据维度:", X.shape) # 输出:(150, 4)
print("降维后数据维度:", X_pca.shape) # 输出:(150, 2)
# 查看各主成分的方差解释比例(重要!评估降维效果)
print("各主成分方差解释比例:", pca.explained_variance_ratio_)
print("累计方差解释比例:", sum(pca.explained_variance_ratio_)) # 通常保留80%以上
# 6. 可视化降维结果
plt.figure(figsize=(8, 6))
colors = ['red', 'green', 'blue']
labels = iris.target_names
for i in range(3):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], c=colors[i], label=labels[i], alpha=0.8)
plt.xlabel('主成分1(PC1)')
plt.ylabel('主成分2(PC2)')
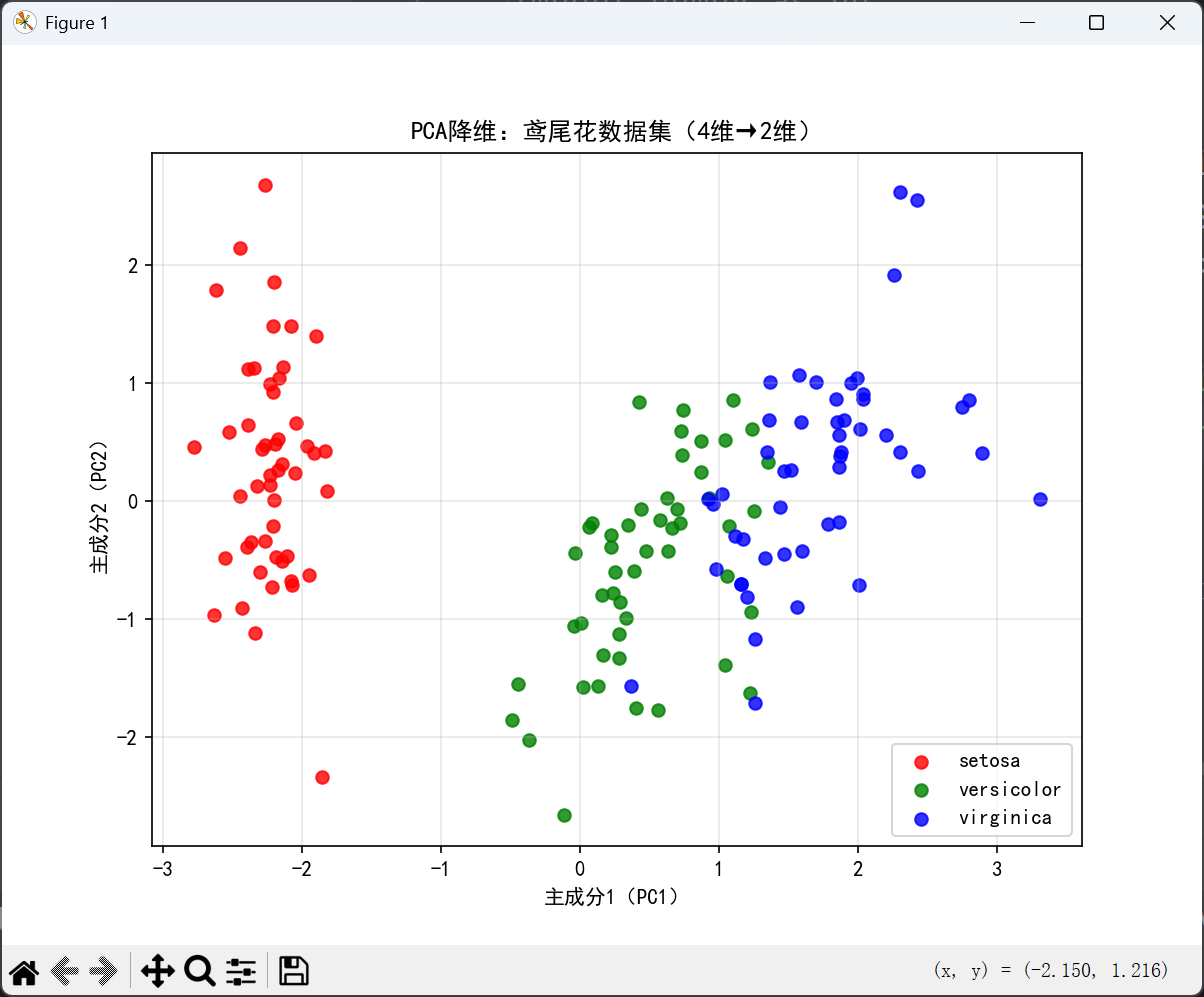
plt.title('PCA降维:鸢尾花数据集(4维→2维)')
plt.legend()
plt.grid(alpha=0.3)
plt.show()总结:
这段代码使用主成分分析(PCA)对经典的鸢尾花数据集进行降维处理,并将其可视化。
具体过程如下:
首先导入必要的库,包括数值计算(numpy)、数据处理(pandas)、绘图(matplotlib)以及机器学习相关模块。然后加载鸢尾花数据集,该数据集包含150个样本,每个样本有4个特征(花萼和花瓣的尺寸)和对应的3种类别标签。
关键步骤是对数据进行标准化处理,通过StandardScaler使每个特征的均值为0、方差为1,消除不同特征量纲的影响。接着初始化PCA模型,将原始的4维数据降维到2维。降维后打印结果显示数据维度从(150,4)变为(150,2),并展示各主成分的方差解释比例,这反映了降维后保留的原始信息量。
最后通过散点图将降维结果可视化,用不同颜色区分三类鸢尾花,横纵坐标分别代表第一和第二主成分。通过这种降维,我们能够在二维平面上直观观察原本四维数据的分布模式,同时保留了原始数据的主要变异信息。累计方差解释比例显示两个主成分保留了原始数据绝大部分的信息量,说明这种降维是有效的。
3. 结果解读
- 降维后数据从 4 维变为 2 维,累计方差解释比例约 97%(说明保留了原始数据 97% 的信息)。
- 可视化图中,3 类鸢尾花在 2 维空间中边界清晰,证明 PCA 降维后仍保留了分类的核心信息。
四、关键技巧:如何选择最佳 k 值(主成分个数)
选择 k 值的核心是 "平衡降维效果和信息保留",推荐 2 种方法:
1. 方差解释比例法(最常用)
设置n_components为 0 到 1 之间的数值(比如 0.95),表示保留 95% 的信息,让 PCA 自动选择 k 值,运行下面的代码之后将直接生成展示累计方差解释比例随主成分数量变化的可视化图表:
python
# 1. 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 2. 加载数据
iris = load_iris()
X = iris.data # 原始数据:4个特征(花萼长、花萼宽、花瓣长、花瓣宽)
y = iris.target # 标签:3类鸢尾花
# 3. 数据标准化(关键步骤)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 标准化后的数据
# 4. 使用方差解释比例法自动选择k值,并可视化累计方差解释比例
# 计算所有主成分的方差解释比例
pca_full = PCA() # 不指定k值,计算所有可能的主成分
pca_full.fit(X_scaled)
# 计算累计方差解释比例
cumulative_variance = np.cumsum(pca_full.explained_variance_ratio_)
# 绘制累计方差解释比例图
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, 'bo-', linewidth=2, markersize=8)
plt.axhline(y=0.95, color='r', linestyle='--', alpha=0.7, label='95% 方差阈值')
plt.axvline(x=np.argmax(cumulative_variance >= 0.95) + 1, color='g', linestyle='--', alpha=0.7, label='最佳k值')
# 标记95%阈值对应的点
k_95 = np.argmax(cumulative_variance >= 0.95) + 1
plt.scatter(k_95, cumulative_variance[k_95-1], s=200, c='red', zorder=5,
label=f'k={k_95} (95%方差)')
plt.xlabel('主成分数量 (k)', fontsize=12)
plt.ylabel('累计方差解释比例', fontsize=12)
plt.title('累计方差解释比例 vs 主成分数量', fontsize=14)
plt.grid(True, alpha=0.3)
plt.legend()
plt.xticks(range(1, len(cumulative_variance) + 1))
# 在图中添加文本信息
plt.text(len(cumulative_variance), 0.5,
f'自动选择 k={k_95}\n保留方差:{cumulative_variance[k_95-1]:.3f}',
bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow", alpha=0.7))
plt.tight_layout()
plt.show()
# 使用95%阈值自动选择k值
pca_auto = PCA(n_components=0.95)
X_pca_auto = pca_auto.fit_transform(X_scaled)
print(f"自动选择的k值:{pca_auto.n_components_}")
print(f"累计方差解释比例:{sum(pca_auto.explained_variance_ratio_):.4f}")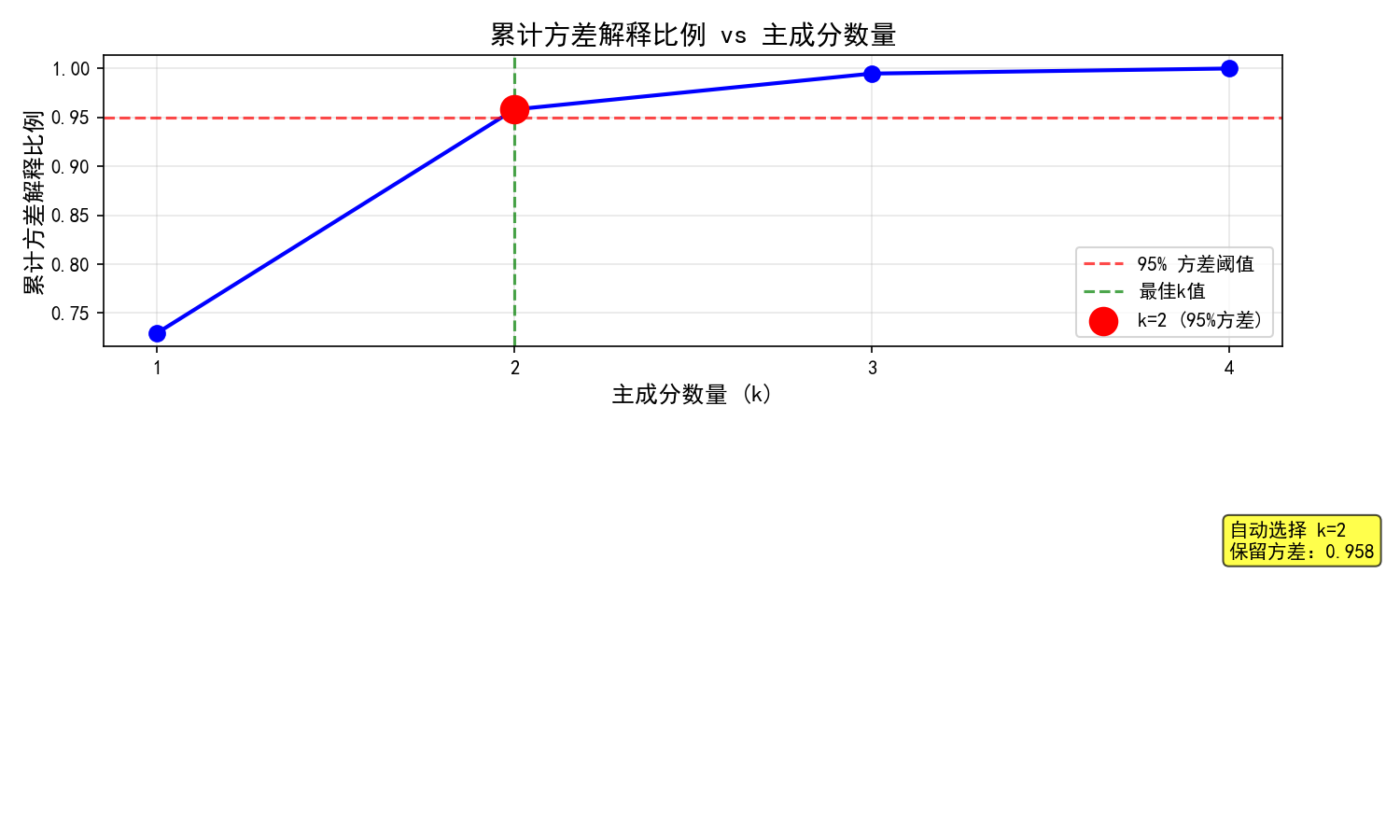
2. 特征值碎石图法
绘制特征值随主成分个数的变化曲线,选择 "曲线拐点" 对应的 k 值(拐点后特征值增长缓慢,信息增益不大)
python
# 1. 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 2. 加载数据
iris = load_iris()
X = iris.data # 原始数据:4个特征(花萼长、花萼宽、花瓣长、花瓣宽)
y = iris.target # 标签:3类鸢尾花
# 3. 数据标准化(关键步骤)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 标准化后的数据
# 4. 特征值碎石图法 - 绘制特征值随主成分个数的变化曲线
pca_full = PCA() # 不指定k,计算所有主成分
pca_full.fit(X_scaled)
# 获取特征值(方差大小)
eigenvalues = pca_full.explained_variance_
# 创建图形
plt.figure(figsize=(12, 5))
# 子图1:特征值碎石图
plt.subplot(1, 2, 1)
plt.plot(range(1, len(eigenvalues) + 1), eigenvalues, 'bo-', linewidth=2, markersize=8)
plt.xlabel('主成分序号', fontsize=12)
plt.ylabel('特征值(方差)', fontsize=12)
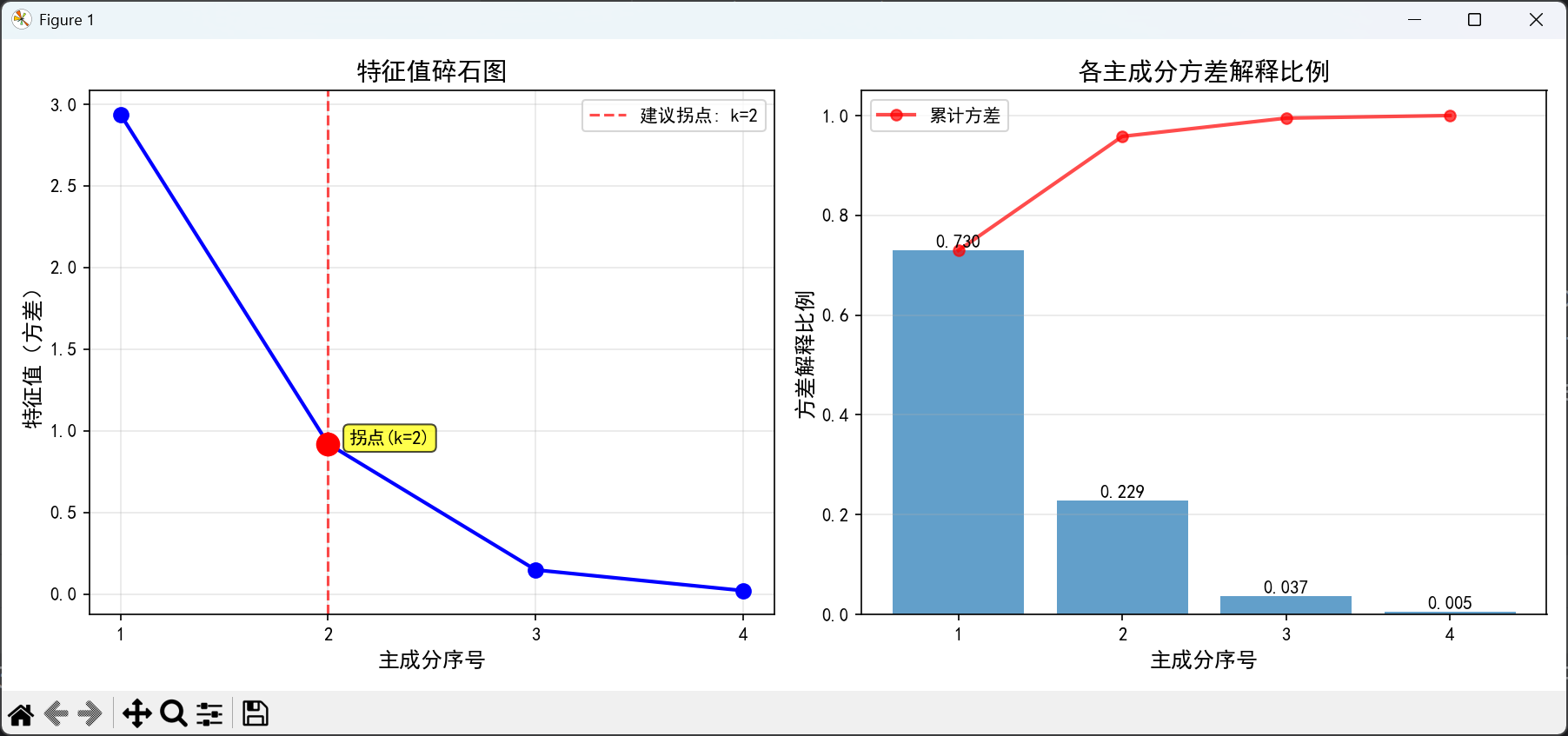
plt.title('特征值碎石图', fontsize=14)
plt.grid(True, alpha=0.3)
plt.xticks(range(1, len(eigenvalues) + 1))
# 计算二阶差分找到"拐点"(特征值变化最平缓的点)
if len(eigenvalues) > 2:
# 计算特征值的变化率(一阶差分)
first_diff = np.diff(eigenvalues)
# 计算变化率的变化(二阶差分)来找到拐点
second_diff = np.diff(first_diff)
# 找到二阶差分最大(变化最平缓)的点作为拐点建议
if len(second_diff) > 0:
inflection_point = np.argmax(second_diff) + 2 # +2 因为二阶差分比原序列短2个元素
plt.axvline(x=inflection_point, color='r', linestyle='--', alpha=0.7, label=f'建议拐点: k={inflection_point}')
# 标记拐点
plt.scatter(inflection_point, eigenvalues[inflection_point - 1], s=150, c='red', zorder=5)
# 添加拐点说明
plt.text(inflection_point + 0.1, eigenvalues[inflection_point - 1],
f'拐点(k={inflection_point})', fontsize=10,
bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow", alpha=0.7))
plt.legend()
# 子图2:特征值贡献率(方差解释比例)条形图
plt.subplot(1, 2, 2)
explained_ratio = pca_full.explained_variance_ratio_
bars = plt.bar(range(1, len(explained_ratio) + 1), explained_ratio, alpha=0.7)
plt.xlabel('主成分序号', fontsize=12)
plt.ylabel('方差解释比例', fontsize=12)
plt.title('各主成分方差解释比例', fontsize=14)
plt.grid(True, alpha=0.3, axis='y')
plt.xticks(range(1, len(explained_ratio) + 1))
# 在柱状图上添加数值标签
for i, (bar, ratio) in enumerate(zip(bars, explained_ratio)):
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2., height,
f'{ratio:.3f}', ha='center', va='bottom', fontsize=10)
# 添加累计方差线
cumulative_ratio = np.cumsum(explained_ratio)
plt.plot(range(1, len(cumulative_ratio) + 1), cumulative_ratio, 'ro-',
markersize=6, linewidth=2, alpha=0.7, label='累计方差')
plt.legend()
plt.tight_layout()
plt.show()
# 5. 输出关键信息
print("=" * 50)
print("特征值碎石图分析结果:")
print("=" * 50)
print(f"所有特征值: {eigenvalues}")
print(f"特征值解释比例: {explained_ratio}")
print(f"累计解释比例: {cumulative_ratio}")
# 基于"拐点法则"建议的k值
if len(eigenvalues) > 2:
print(f"\n基于碎石图拐点法则建议的k值: {inflection_point}")
print(f"前{inflection_point}个主成分的累计方差解释比例: {cumulative_ratio[inflection_point - 1]:.4f}")
# 对比"肘部法则"(特征值 > 1 的标准)
k_elbow = sum(eigenvalues > 1)
print(f"基于特征值>1的肘部法则建议的k值: {k_elbow}")
print(f"前{k_elbow}个主成分的累计方差解释比例: {cumulative_ratio[k_elbow - 1]:.4f}")
# 6. 使用建议的k值进行PCA降维
print("\n" + "=" * 50)
print("使用建议k值进行PCA降维:")
print("=" * 50)
if len(eigenvalues) > 2:
# 使用拐点建议的k值
k_suggested = inflection_point
pca_suggested = PCA(n_components=k_suggested)
X_pca_suggested = pca_suggested.fit_transform(X_scaled)
print(f"使用k={k_suggested}降维后维度: {X_pca_suggested.shape}")
print(f"累计方差解释比例: {sum(pca_suggested.explained_variance_ratio_):.4f}")
else:
print("数据维度太少,无法计算拐点")这段代码运行后会生成一个包含两个子图的图表:
左图(特征值碎石图):
-
展示每个主成分对应的特征值(方差)大小
-
通过红色虚线标记建议的"拐点"位置
-
使用二阶差分方法自动识别特征值变化最平缓的点
右图(方差解释比例):
-
显示每个主成分解释的方差比例
-
使用红色折线显示累计方差解释比例
-
柱状图上标明了具体的数值
五、PCA 的适用场景与局限性
适用场景
- 高维数据降维(如图像处理、文本分类中特征维度极高的场景)。
- 数据可视化(将高维数据降到 2D/3D,方便观察数据分布)。
- 数据去噪(保留方差大的主成分,过滤方差小的噪声)。
局限性
- 对异常值敏感(异常值会影响方差计算,需提前处理)。
- 线性降维(仅能捕捉数据的线性关系,无法处理非线性结构,此时可考虑 LDA、t-SNE 等算法)。
- 主成分缺乏可解释性(新特征是原始特征的线性组合,无法直接对应实际业务含义)。
六、总结
PCA 是机器学习中最基础且实用的降维算法,核心是 "通过方差最大化保留关键信息"。掌握它的原理和实操,能有效解决高维数据的处理难题。
本文的代码可直接复制运行,建议大家尝试更换数据集(如 MNIST、波士顿房价数据集),感受 PCA 在不同场景下的效果。如果在使用中遇到问题,欢迎在评论区交流!