数据集概述
- 数据来源:真实课堂场景采集,经抽帧处理与人工标注,包含6类典型行为(举手、阅读、书写、使用手机、低头、俯身),覆盖多光照条件、多视角及部分遮挡情况。
- 数据分布 :
- 训练集:1418张(标注框总数:24,700)
- 验证集:407张(标注框总数:4,592)
- 测试集:203张(标注框总数:2,643)
类别统计详情
训练集
- 举手:1,552框
- 阅读:10,006框
- 书写:3,726框
- 使用手机:7,364框
- 低头:970框
- 俯身:1,082框
验证集
- 举手:571框
- 阅读:2,587框
- 书写:818框
- 使用手机:2,015框
- 低头:293框
- 俯身:308框
测试集
- 举手:198框
- 阅读:1,504框
- 书写:592框
- 使用手机:1,049框
- 低头:150框
- 俯身:150框
技术规范
- 标注格式 :YOLO标准格式(
class_id x_center y_center width height),兼容YOLOv5-v8及后续版本。 - 可视化示例 :

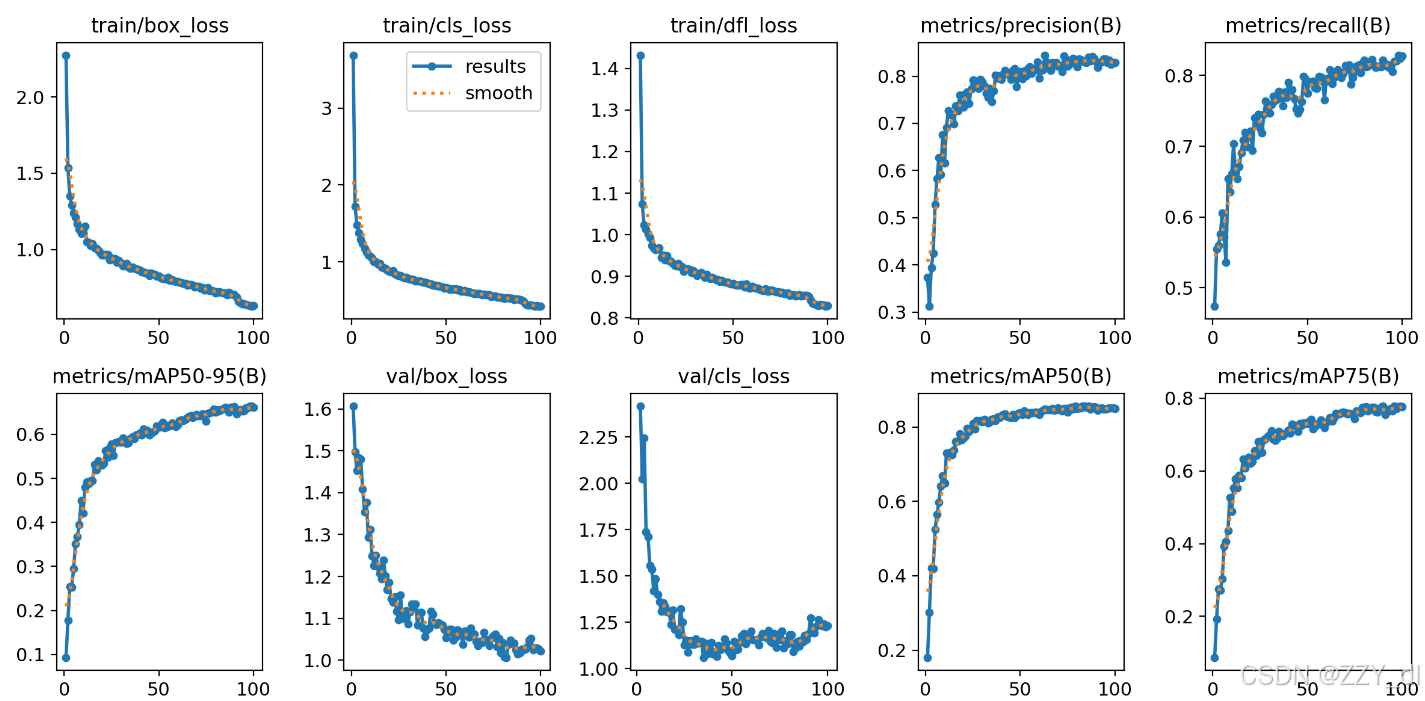
模型训练配置
-
基础模型:YOLOv8s
-
预处理 :
- 图像分辨率归一化(416×416)
- 动态增强(Mosaic、随机仿射变换)
-
超参数 :
- 初始学习率:0.01
- 批次大小:16
- 训练轮次:100
-
启动命令 :
bashpython train.py --data classroom.yaml --cfg yolov8s.yaml --weights yolov8s.pt
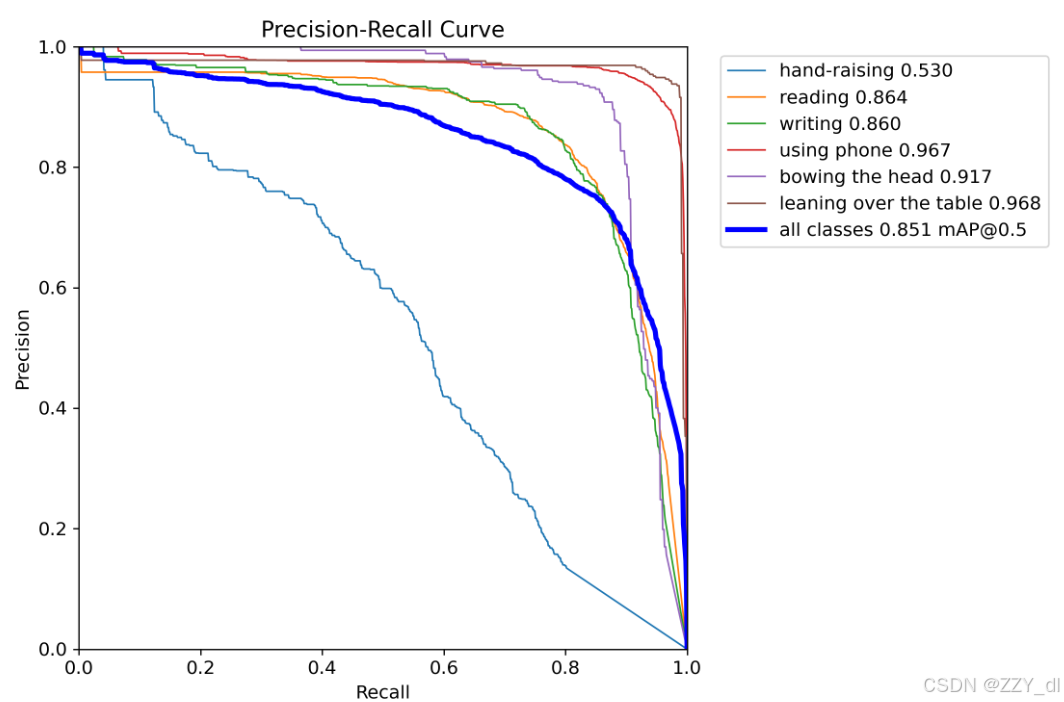
性能评估
- 核心指标 :
- mAP@0.5:0.92
- mAP@0.5:0.95:0.78
- 精确率:89.5%
- 召回率:87.2%
- 检测效果 :