1.索引的概念
索引是数据库系统中提升数据检索效率的关键组成部分,它通过创建特定的数据结构来加速数据查找,从而显著减少系统响应时间
2.索引的基本原理与数据结构
实现索引有多种数据结构,这里重点介绍 B+树 这种结构
2.1** B+树 **
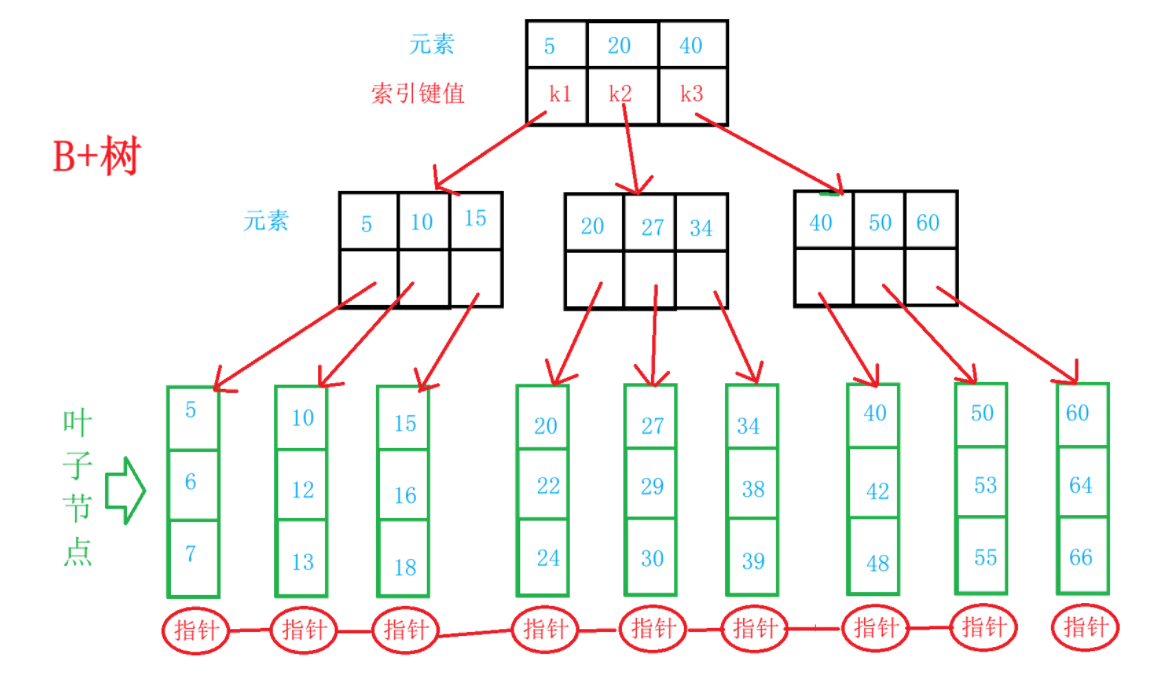
2.1.1 特点
**1)**B+树 是一种平衡树,其所有的叶子节点构成一个有序的链表,便于范围查询;
**2)**B+树 的叶子节点存储数据;非叶子节点存储索引键值;
**3)**根节点到任意叶子节点的路径长度相同,可以确保数据访问的一致性和快速性;
**4)**即使数据量增加,数据检索路径的长度也能保持相对稳定,从而实现高效的数据访问;
2.1.2 为什么数据库(如 MySQL)酷爱 B+树
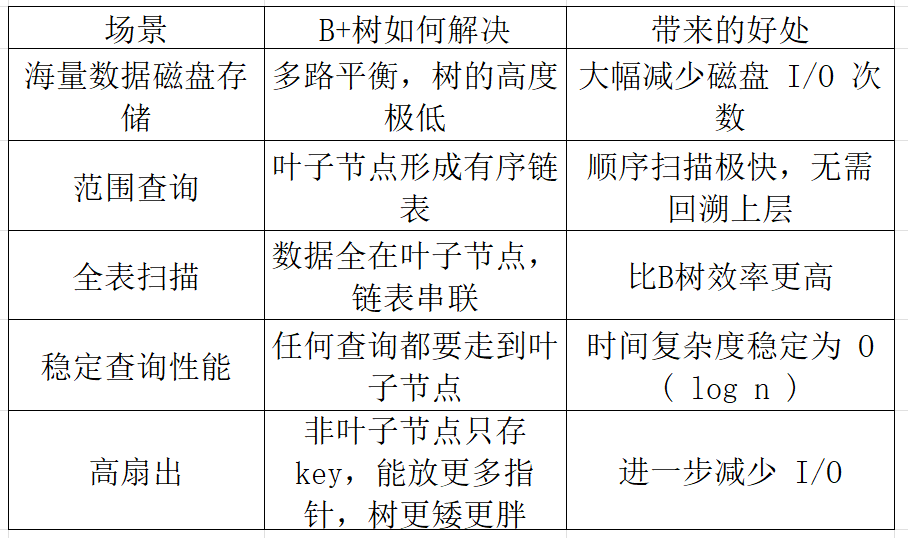
可以这么近似理解:想象一本超级厚的电话簿(数据库表)。平衡树(尤其是B+树)就像这本电话簿的智能目录:它不是简单分章节(那可能不均匀),而是构建了一个多级的、自动平衡的索引结构。找 " 张三 " 时,它让你快速跳过无关章节(减少磁盘读取),并且找到 " 张三 " 后,紧挨着的 " 李四 " 也能瞬间定位(范围查询高效)。这就是它成为数据库引擎心脏的原因!
2.2 其他数据结构
**1)**哈希索引:哈希索引通过哈希函数将数据映射到存储位置,提供极快的等值查询速度;但哈希索引不适合范围查询,并且在大型数据集上可能会面临高碰撞率问题,这会影响查询效率
**2)**分页索引结构:用于 XML 数据库,通过划分结点集合直接定位查询结果,避免重复遍历路径
**3)**H-T-tail 混合索引机制:为嵌入式数据库设计,注重内存空间效率。其核心是结合哈希表(H)、树结构(T)和尾部索引(Tail),通过行存索引辅助列存查询,优化更新与扫描性能
3.索引的分类与应用
3.1 聚簇索引
3.1.1 特点:
1)物理排序:聚簇索引将数据行按照索引列的值进行物理排序,使相邻数据行在磁盘上相邻存储,从而提升范围查询和排序效率
2)唯一性:一个表只能有一个聚簇索引,因为它直接关联数据的物理存储顺序
3)覆盖索引:叶子节点直接存储数据,无需回表即可满足查询
3.1.2 常见类型
1)主键索引:主键索引是聚簇索引的默认形式
2)唯一非空列索引:当表未定义主键时,数据库可能选择唯一非空列作为聚簇索引
3.2 非聚簇索引
3.2.1 特点
1) 索引与数据分离:1.存储结构:非聚簇索引通常使用 B+树作为其物理存储结构
2.查找过程:查询时需先通过索引找到主键值再通过主键回表获取完整数据
**2)**多索引支持:单表可以创建多个非聚簇索引
**3)**覆盖索引:叶子节点存储完整数据行,可避免回表操作,直接返回查询结果
**4)**空间效率:索引结构占用空间较小,适合内存受限环境;维护成本低,插入/删除时只需要更新索引树,不影响数据物理顺序
3.2.2 常见类型
**1)**唯一索引:可以确保数据库表中指定列或组合的值具有唯一性,防止重复数据插入,但不作为聚簇索引
**2)**普通索引:无唯一性约束,用于加速查询
**3)**联合索引:由多个列组合而成的索引,提升多列查询效率
**4)**全文索引:用于文本搜索,支持模糊匹配
3.3 辅助理解
3.3.1 聚簇索引(Clustered Index):图书馆的书架
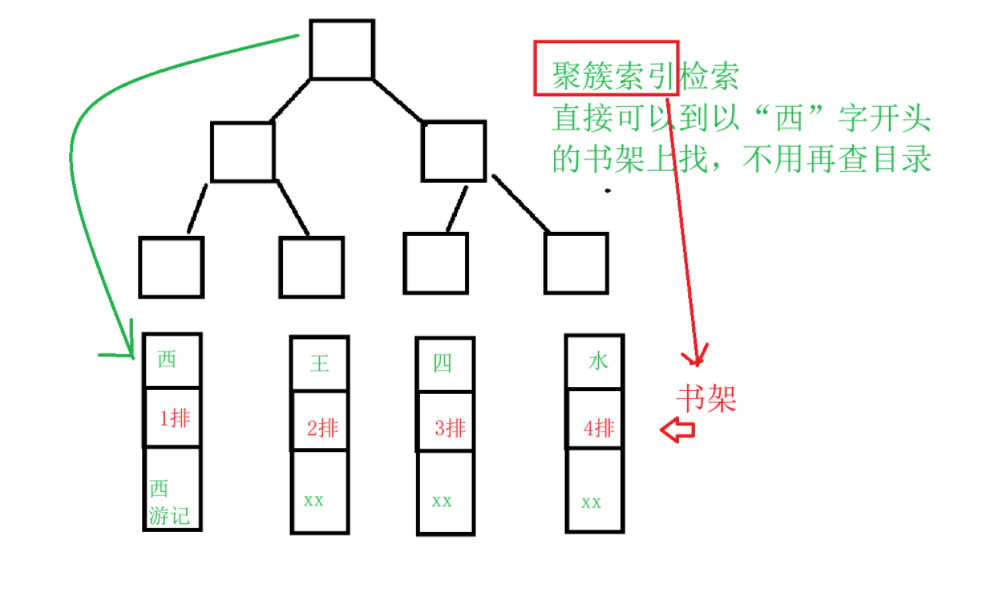
1)场景:图书馆按书名首字母(聚簇索引)排书架,每本书直接放在书架上(数据行即索引)。
2)操作
-
查找《西游记》:直接找到 " 西 " 开头的书架,无需再查目录(覆盖索引)。
-
优势:
-
高效:按书名顺序存储,支持范围查询
-
唯一性:每排书架只能放一本《西游记》(主键唯一)。
-
3.3.2 非聚簇索引(Non-Clustered Index):图书馆的目录
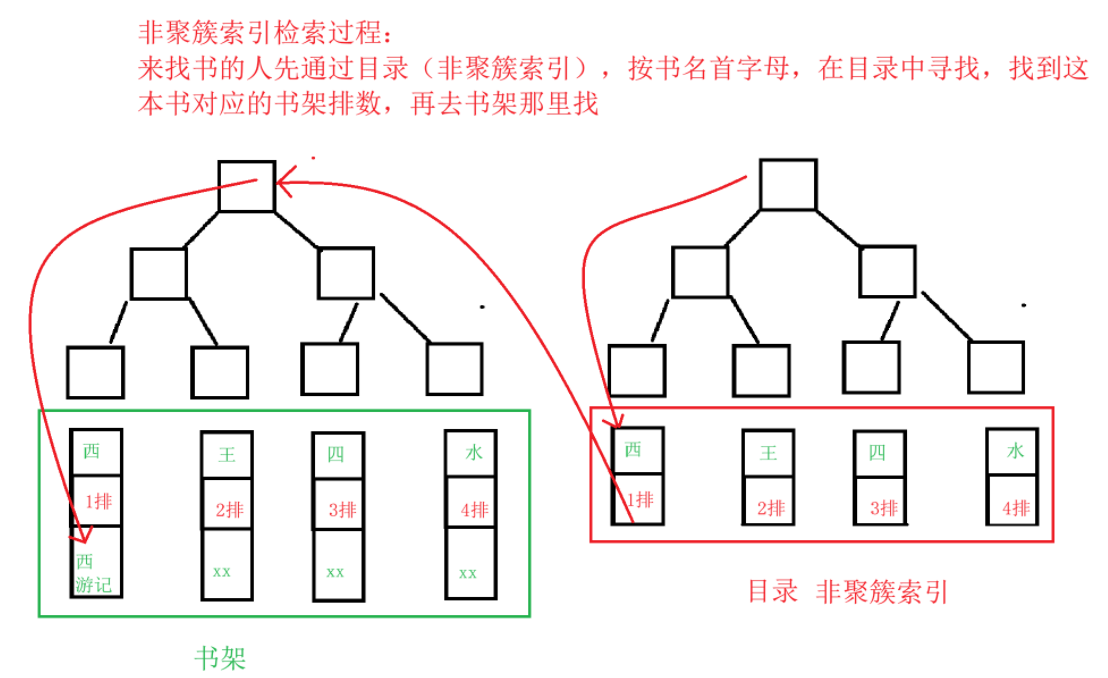
1)场景:图书馆有独立的目录(非聚簇索引),按书名首字母名排目录,目录里存书名和书架号(主键值)。
2)操作:
-
查找《西游记》:先查目录找到书名和书架号(非聚簇索引),再回书架取书(回表)。
-
优势:
-
灵活:可创建多个目录(如按作者、按出版年份)。
-
适用场景:快速定位书。
-
4.补充知识点
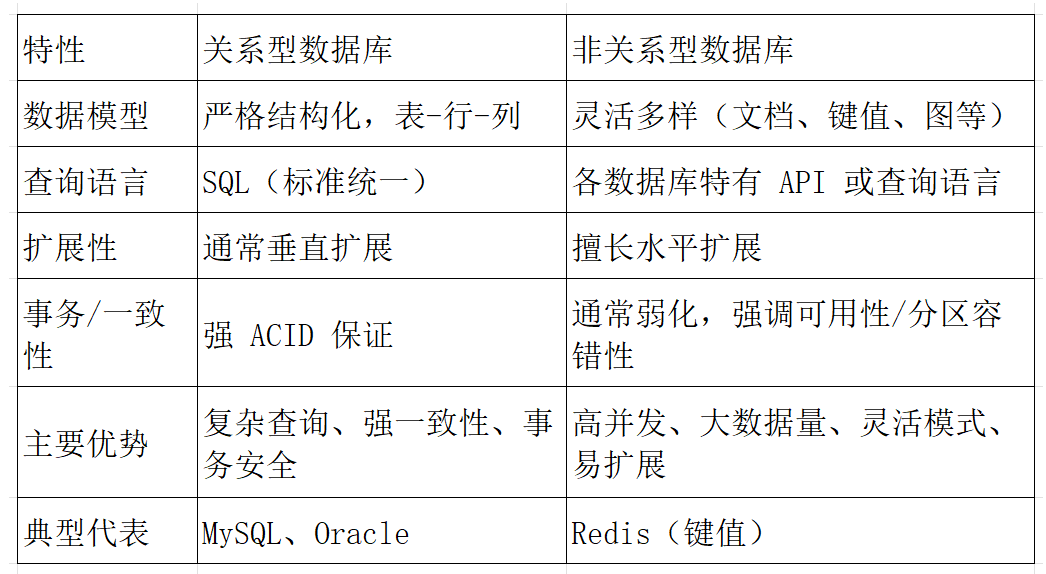
4.1 关系型数据库和非关系型数据库
4.2 平衡树
4.2.1 概念
平衡树是一种能自动保持左右子树 " 身高 " 接近的二叉搜索树,核心目标是避免树结构退化成链表,让查找、插入、删除表操作稳定在**O ( log n )**的时间复杂度
4.2.2 为何需要"平衡"?
-
问题: 普通二叉查找树如果插入顺序不当(如一直插入更大/更小的数),会退化成 " 歪脖子树 "(类似链表),查找效率暴跌至O(n)。
-
解决: 平衡树通过旋转操作(左旋、右旋、组合旋),在插入/删除节点时动态调整树的结构,确保任意节点的左右子树高度差不超过1(或满足其他平衡因子定义)。
4.2.3 关键特性:
-
自平衡: 插入/删除后自动检查并调整平衡,无需手动干预。
-
稳定高效: 保证最坏情况下的查找、插入、删除时间复杂度都是 O(log n),性能可预测。
-
有序性: 保持二叉查找树的性质(左子树 < 根 < 右子树)。
4.2.4 常见类型(知道名字就行,重点理解思想):
-
AVL 树: 最严格的平衡,通过平衡因子(左高-右高)保证高度差≤1。查找最快,但维护平衡的旋转操作可能更频繁。
-
红黑树: 广泛应用(如 Java HashMap、Linux 内核),通过颜色标记和规则实现近似平衡(确保最长路径 ≤ 2 倍最短路径)。插入删除效率通常比 AVL 更高。
-
B树 / B+树: 这才是数据库索引的明星!
-
B树: 多路平衡查找树(不是二叉树!一个节点可存多个 key 和指针)。减少磁盘 I/O 次数(关键!因为磁盘读块比内存慢得多)。适用于文件系统和部分数据库。
-
B+树: MySQL InnoDB 引擎的标准索引结构。 在 B树 基础上优化:
-
非叶子节点只存键,不存数据(让一个磁盘块能存更多索引,树更矮)。
-
所有数据记录都存在叶子节点,并按顺序链式链接。
-
优势: 范围查询超高效(顺序扫描叶子链表即可)、全表扫描更快(只需遍历叶子节点)、查询更稳定(都要查到叶子层)。
-
-
4.3 回表
4.3.1 什么是回表?
**1)**想象你在查字典:
-
第一步:查目录(索引)通过"拼音索引"快速找到"张"字所在的页码(主键 ID )。
-
第二步:翻到正文(回表)根据页码,回到字典正文(数据页) 找到 " 张 " 字的详细解释(完整数据行)。
2) 技术定义:
当SQL语句通过二级索引(非主键索引) 定位到目标数据的主键值后,还需根据主键值再次扫描聚集索引(主键索引) 才能获取完整数据行的过程。
4.3.2 为什么会发生回表?
-
二级索引的存储结构:
-
只存储索引字段的值 + 对应记录的主键值(不存完整数据!)。
-
例如索引
INDEX(name):存储的是(name值, 主键id)。
-
-
聚集索引的存储结构:
-
叶子节点直接存储完整数据行( InnoDB 引擎特性)。
-
主键索引即聚集索引。
-
触发条件:
查询语句需要的列未完全包含在使用的二级索引中(即存在 " 未被索引覆盖的列 " )。
4.3.3 回表为什么影响性能?
-
额外I/O 开销: 二级索引查找通常是内存操作(快),而回表需随机读取磁盘数据页(慢)。
-
随机访问: 根据主键回表是随机I/O(比顺序I/O 慢得多)。
-
数据量放大: 若二级索引筛选出大量行,每次回表都是一次磁盘寻址。
4.3.4 如何避免回表?
核心方案:索引覆盖,创建一个包含所有查询字段的索引,让二级索引的叶子节点直接包含所需数据,无需回表。