TL;DR
- 场景:从 MySQL 增量同步结构化数据到 Logstash;同时集中采集 Linux/设备 Syslog 日志并解析。
- 结论:JDBC 适合"按表/按 SQL 拉取+增量位点";Syslog 适合"网络日志流入+Grok/Date 解析",两者瓶颈分别在 DB/查询与网络/解析。
- 产出:两套可跑通的 Logstash 7.3.0 配置(jdbc.conf、syslog.conf)+ 增量追踪与 rsyslog 转发链路。

版本矩阵
| 组件/工具 | 配置说明 |
|---|---|
| Logstash 7.3.0 | 配置路径与命令均以 /opt/servers/logstash-7.3.0 为基准;-t 校验通过截图已体现 |
| MySQL Connector/J | 使用 jdbc.conf 配置,驱动版本为 8.0.19;MySQL 8 推荐使用 com.mysql.cj.jdbc.Driver(兼容性与时区/SSL 参数更明确) |
| MySQL(示例表 user) | 通过 tracking_column => "id" + id > :sql_last_value 实现增量;适配自增/单调递增列 |
| rsyslog(Linux) | 在 /etc/rsyslog.conf 中增加 *.* @@host:port 实现 TCP 转发;需执行 systemctl restart rsyslog 生效 |
| Logstash tcp/udp input | syslog.conf 采用 tcp {} + udp {} 监听 6789 端口,并使用 grok 解析"类 syslog"消息(非 syslog input 插件直配) |
基本介绍
Logstash 的 JDBC 和 Syslog 是两种功能各异的 Input 插件,它们分别针对不同的数据源进行优化设计,在数据处理流程中扮演着关键角色。下面将详细阐述它们的技术特性、应用场景及典型配置:
JDBC 插件深入解析
-
核心功能:
- 支持主流关系型数据库:MySQL (5.7+)、PostgreSQL (9.6+)、Oracle (12c+)、SQL Server (2016+)等
- 基于 JDBC 4.2 规范实现,使用数据库官方提供的 JDBC 驱动
- 支持增量数据采集:通过
sql_last_value参数记录最后处理位置
-
典型应用场景:
- 数据仓库的 ETL 流程
- 业务系统数据库变更监控
- 将传统数据库数据导入 Elasticsearch 集群
- 示例:电商订单数据实时同步
sql
SELECT * FROM orders WHERE update_time > :sql_last_value- 关键配置参数:
ruby
input {
jdbc {
jdbc_driver_library => "/path/to/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/ecommerce"
jdbc_user => "logstash"
jdbc_password => "securepassword"
schedule => "* * * * *" # 每分钟执行
statement => "SELECT * FROM products WHERE last_modified > :sql_last_value"
use_column_value => true
tracking_column => "last_modified"
}
}Syslog 插件技术细节
-
协议支持:
- RFC3164 (旧版 BSD syslog)
- RFC5424 (新版结构化syslog)
- 支持 TCP/UDP 两种传输协议
-
网络配置选项:
- 端口绑定:默认 514 (UDP) / 6514 (TCP)
- 支持 TLS 加密传输
- 可配置多个监听端口实现多租户隔离
-
典型部署模式:
- 网络设备日志收集(路由器/交换机)
- Linux 系统日志集中管理
- 容器环境日志采集(Docker syslog驱动)
- 示例:防火墙日志处理
ruby
input {
syslog {
port => 5514
type => "firewall"
syslog_field => "syslog_message"
}
}- 高级功能 :
- 支持自定义消息解析模式
- 可配置时区转换
- 提供消息优先级(PRI)解析
两种插件在性能调优方面也存在差异:JDBC 插件需要关注数据库连接池配置和批处理大小,而 Syslog 插件则需要优化网络缓冲区设置和并发处理能力。实际部署时,建议根据数据量级和延迟要求进行针对性调优。
JDBC Input 插件
JDBC 插件用于从关系型数据库中提取数据,特别适用于将结构化的业务数据导入到 ELK(Elasticsearch, Logstash, Kibana)堆栈中。它支持定时调度和增量提取,适合数据同步和 ETL 场景。
主要功能:
- 数据库连接:使用 JDBC 驱动来连接各种数据库(例如 MySQL、PostgreSQL、Oracle、SQL Server 等)。
- SQL 查询:允许用户通过 SQL 查询语句选择数据,支持复杂的查询条件。
- 增量提取:可以配置"追踪列"(tracking column),基于某一列(如自增 ID 或时间戳)实现增量数据拉取,避免重复导入。
- 定时调度:可以设置定时任务,定期查询和同步数据库的数据。
- 错误重试机制:可以处理连接错误并自动重试,确保数据采集的稳定性。
Syslog Input 插件
Syslog 插件用于接收基于 Syslog 协议传输的日志数据。Syslog 是一种广泛使用的日志协议,特别是在网络设备和 Linux/Unix 操作系统中。Logstash 的 Syslog 插件能够监听特定的端口,接收和解析这些日志。
主要功能:
- 协议支持:支持 Syslog 协议,包括 RFC 3164 和 RFC 5424 格式的日志。
- 多种传输方式:支持通过 TCP 和 UDP 协议接收日志,适应不同的传输需求。
- 日志解析:自动解析 Syslog 消息的头部字段,例如时间戳、主机名、程序名等。
- 网络监听:可以通过监听指定的 IP 和端口,持续接收并处理来自网络的 Syslog 日志。
JDBC插件
JDBC插件可以采集某张数据库表当中的数据到Logstash当中来
准备数据
sql
CREATE TABLE `user` (
`id` bigint(20) NOT NULL,
`user_name` varchar(25) DEFAULT NULL,
`gender` varchar(20) DEFAULT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY(`id`)
) ENGINE=InnoDB DEFAULT CHRASET=utf8;
INSERT INTO `user` VALUES(1, 'zhangsan', 'male', '2024-08-16 00:00:00');
INSERT INTO `user` VALUES(2, 'lisi', 'female', '2024-08-16 00:00:00');目前我们的MySQL服务器是在 h122 节点上的(之前给Hive和HBase等业务使用的),现在我们需要到 h122 数据库中,执行上述的SQL指令。 我这里使用Navicat执行, 执行结果如下图所示: 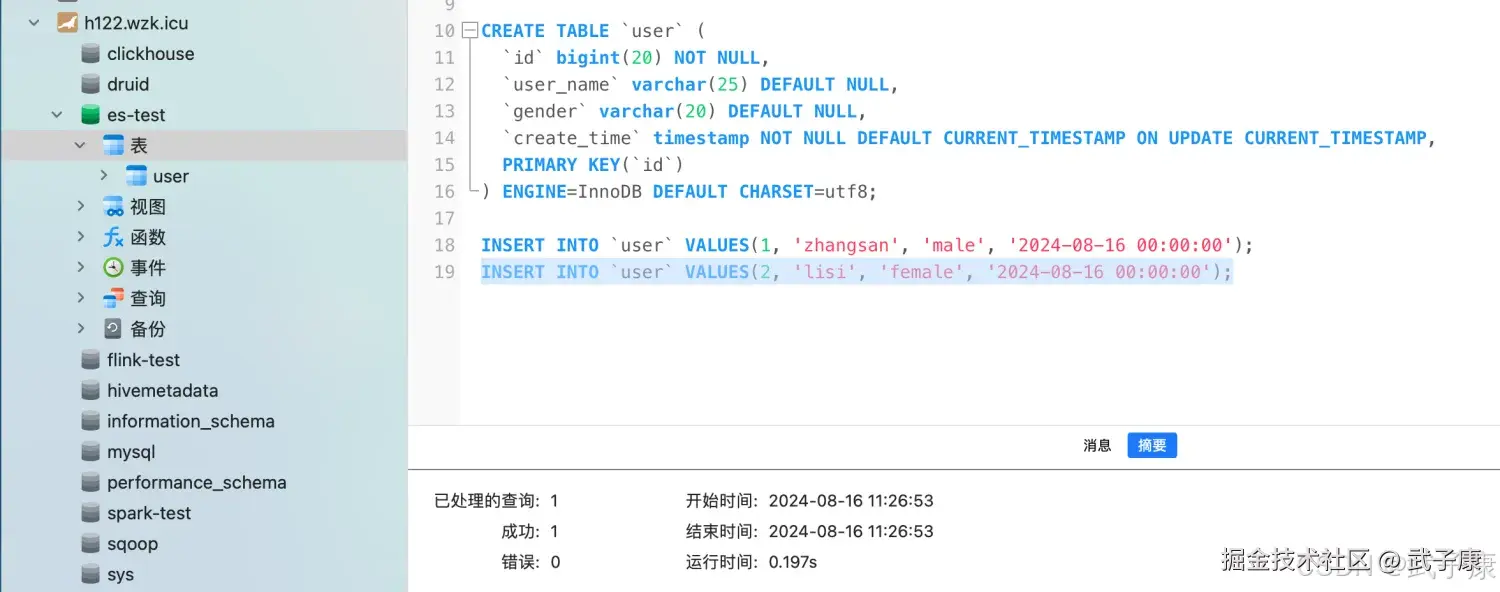
编写配置
shell
cd /opt/servers/logstash-7.3.0/config
vim jdbc.conf写入如下的内容(这里注意些自己的环境,我的环境和你的不一样):
shell
input {
jdbc {
jdbc_driver_library => "/opt/servers/mysql-connector-java-8.0.19.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://h122.wzk.icu:3306/es-test"
jdbc_user => "hive"
jdbc_password => "hive@wzk.icu"
use_column_value => "true"
clean_run => "false"
record_last_run =>"true"
tracking_column => "id"
schedule => "* * * * *"
last_run_metadata_path => "/opt/servers/es/.Logstash_user_jdbc_last_run"
statement => "SELECT * from user where id > :sql_last_value;"
}
}
output{
stdout{
codec=>rubydebug
}
}检查配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/jdbc.conf -t执行结果如下图所示: 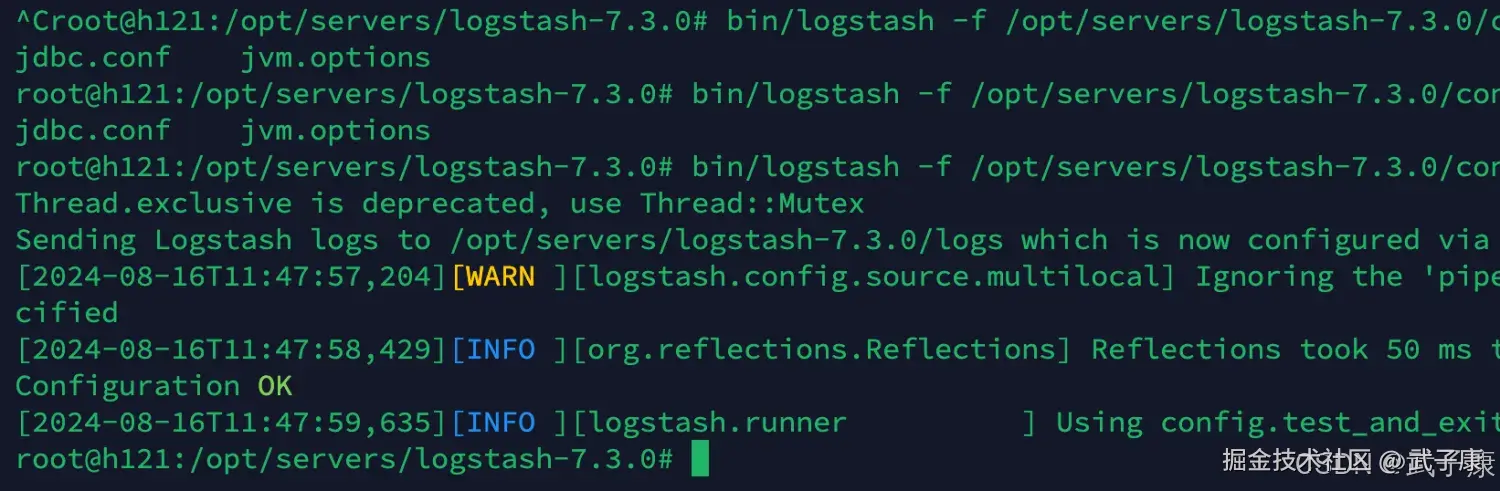
启动服务
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/jdbc.conf启动结果如下图所示: 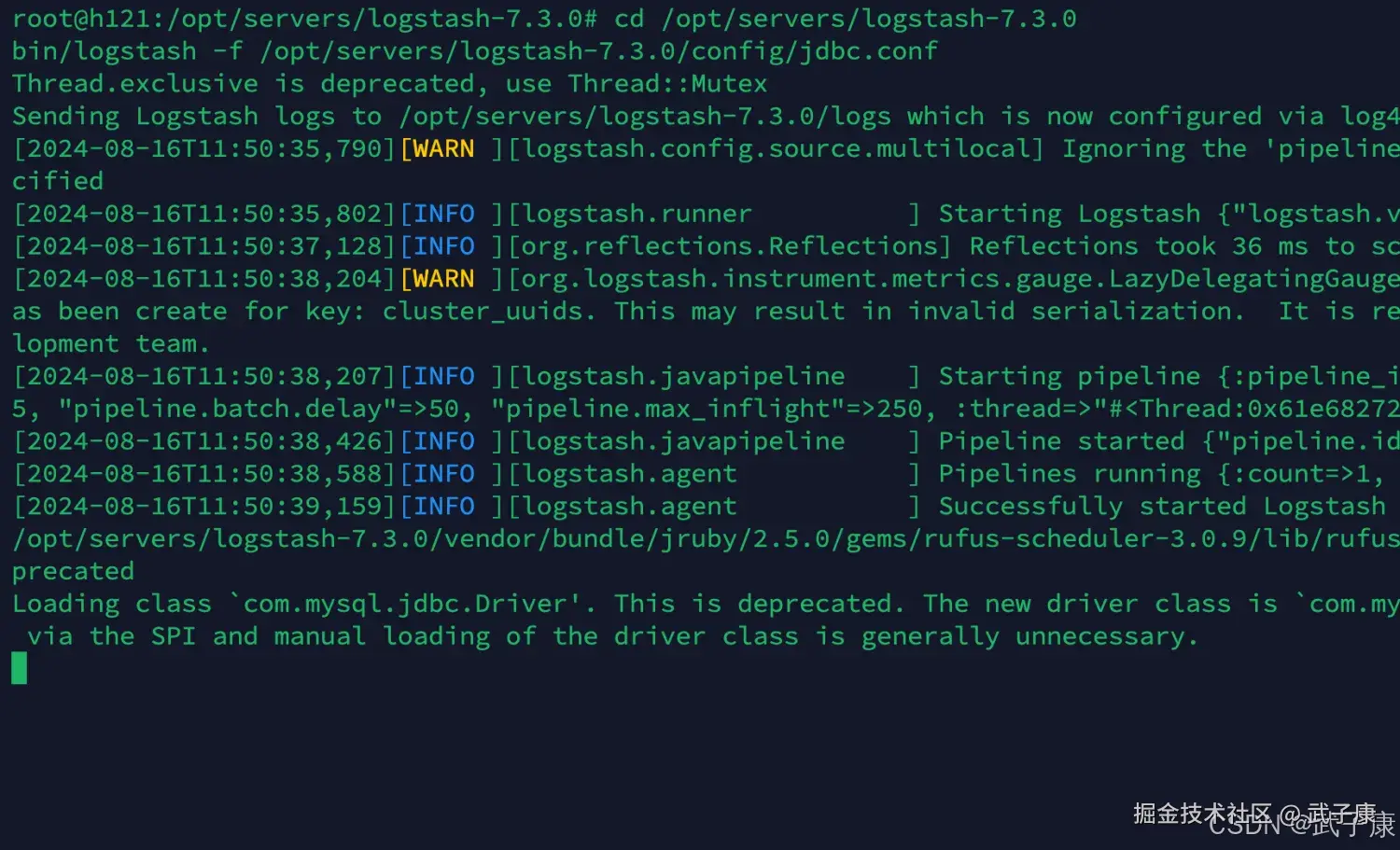 可以看到获取到了对应的数据:
可以看到获取到了对应的数据: 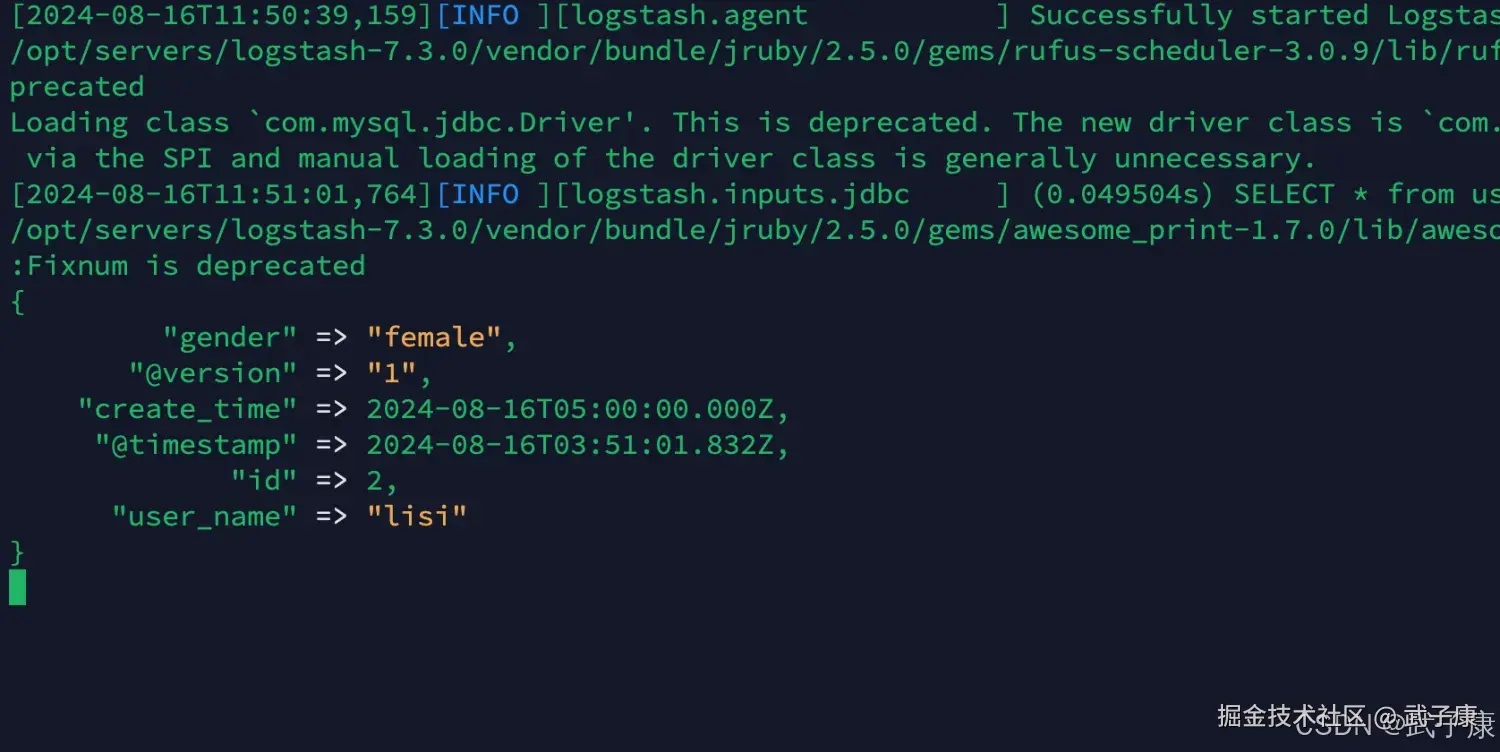
发送数据
现在向数据库中写入数据,就可以发现Logstash监听到了:
sql
INSERT INTO `user` VALUES(3, 'wangwu', 'female', '2024-08-16 00:00:00');对应的Logstash的变化: 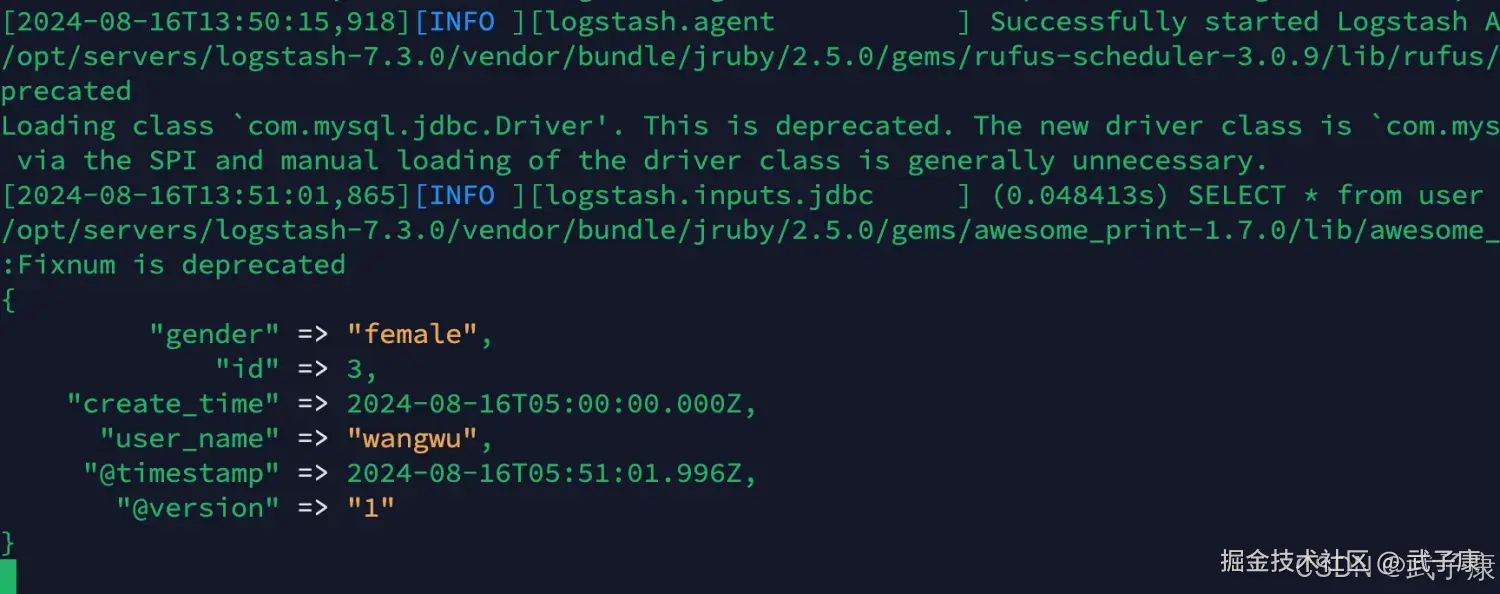
syslog插件
syslog机制负责记录内核和应用程序产生的日志信息,管理员可以通过查看日志记录,来掌握系统状况,默认系统已经安装了rsyslog,直接启动即可。
编写配置
创建新脚本,syslog.conf
shell
cd /opt/servers/logstash-7.3.0/config
vim syslog.conf写入如下的内容:
shell
input {
tcp {
port => 6789
type => "syslog"
}
udp {
port => 6789
type => "syslog"
}
}
filter {
if [type] == "syslog" {
grok {
match => {
"message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}"
}
add_field => {
"received_at" => "%{@timestamp}"
"received_from" => "%{host}"
}
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
stdout {
codec => rubydebug
}
}写入的内容如下图所示: 
检查配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/syslog.conf -t执行结果如下图所示: 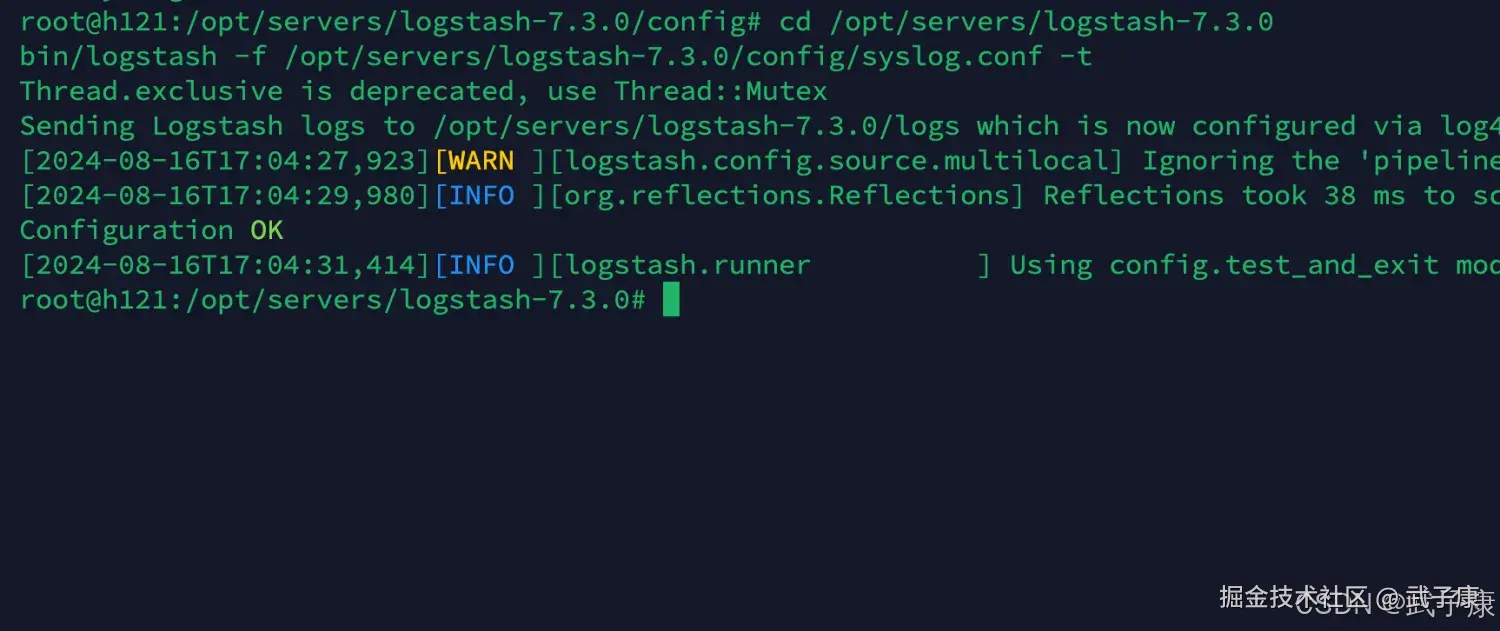
启动服务
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/syslog.conf执行结果如下图所示: 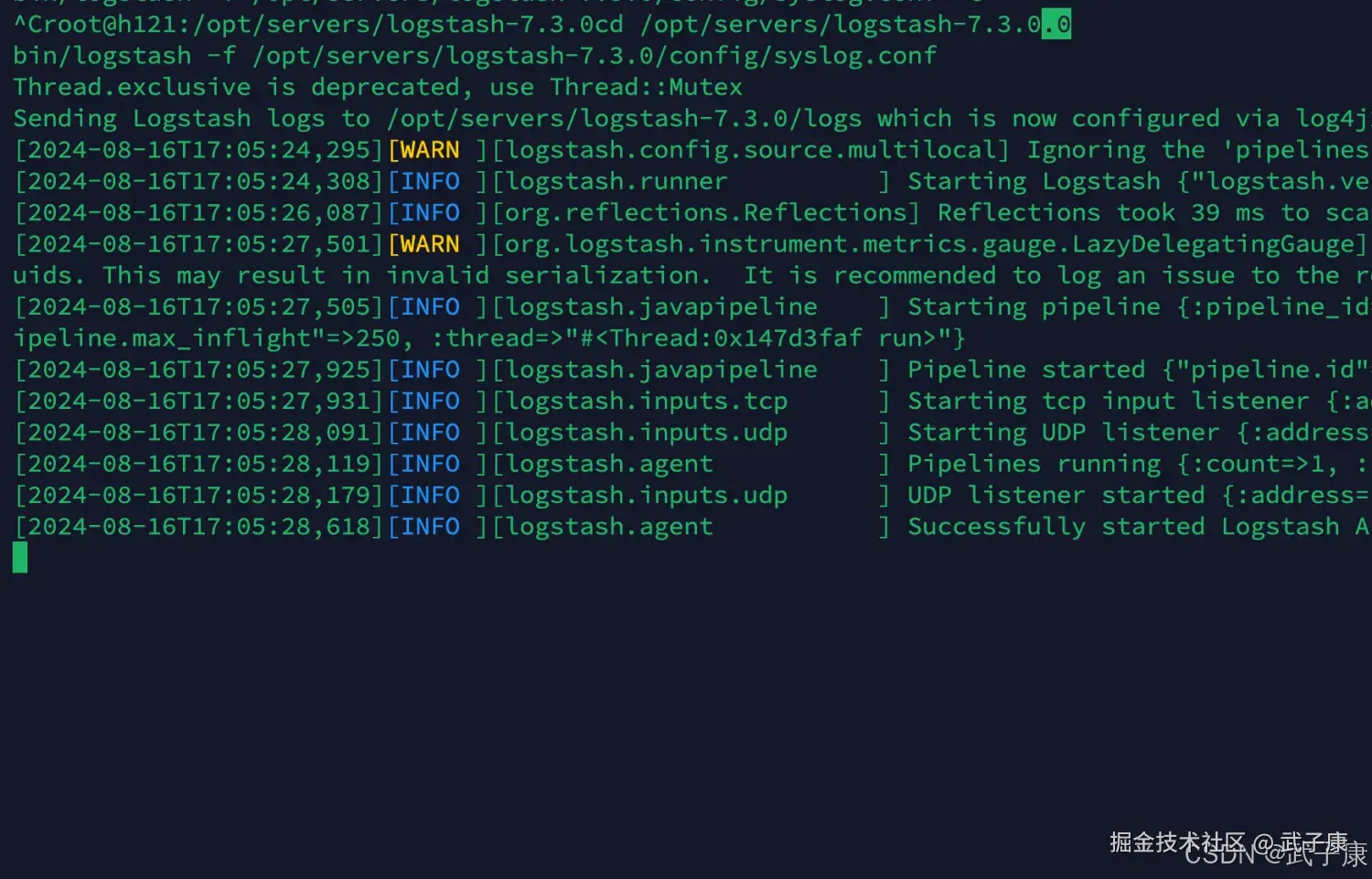
发送数据
修改系统日志配置文件
shell
vim /etc/rsyslog.conf添加一行配置:
shell
*.* @@h121.wzk.icu:6789写入的效果如下图所示: 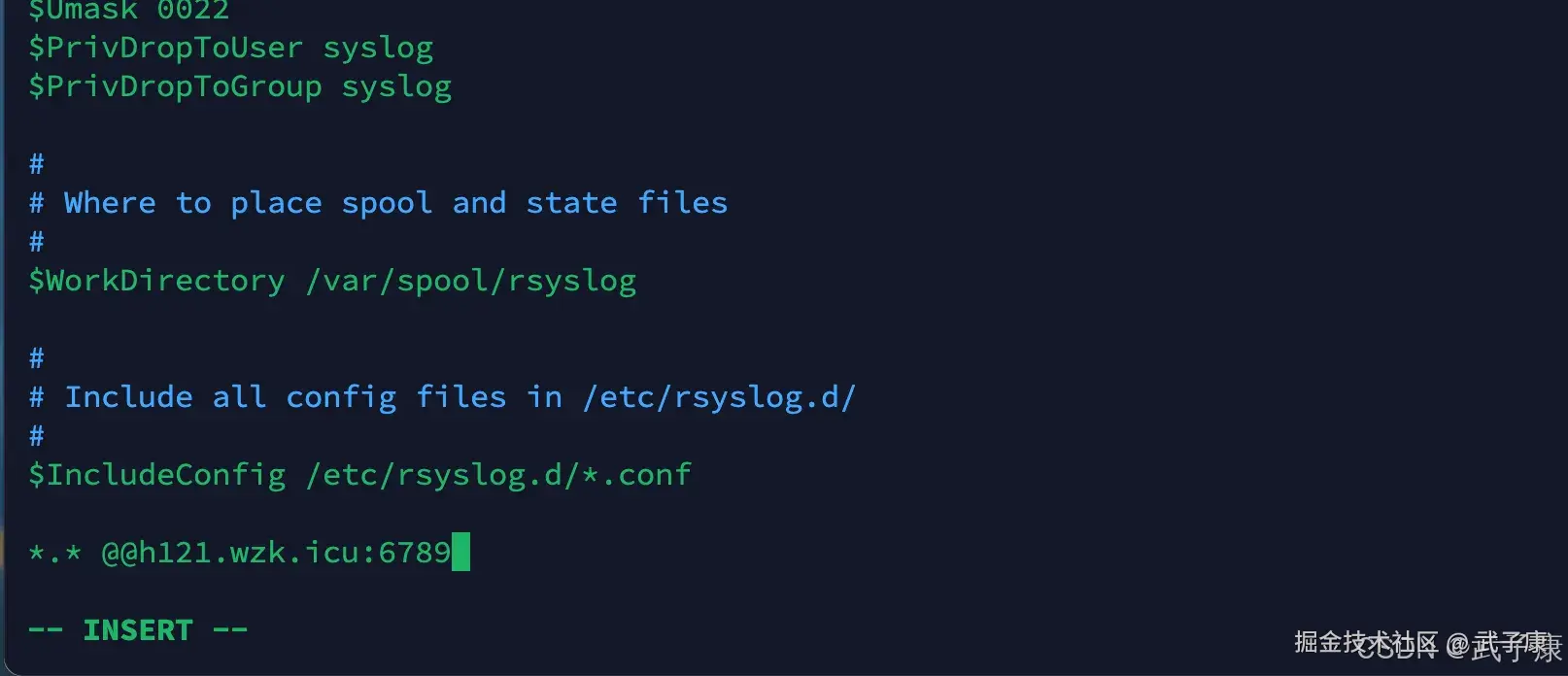 重启系统日志服务
重启系统日志服务
shell
systemctl restart rsyslog查看数据,可以看到如下的效果:
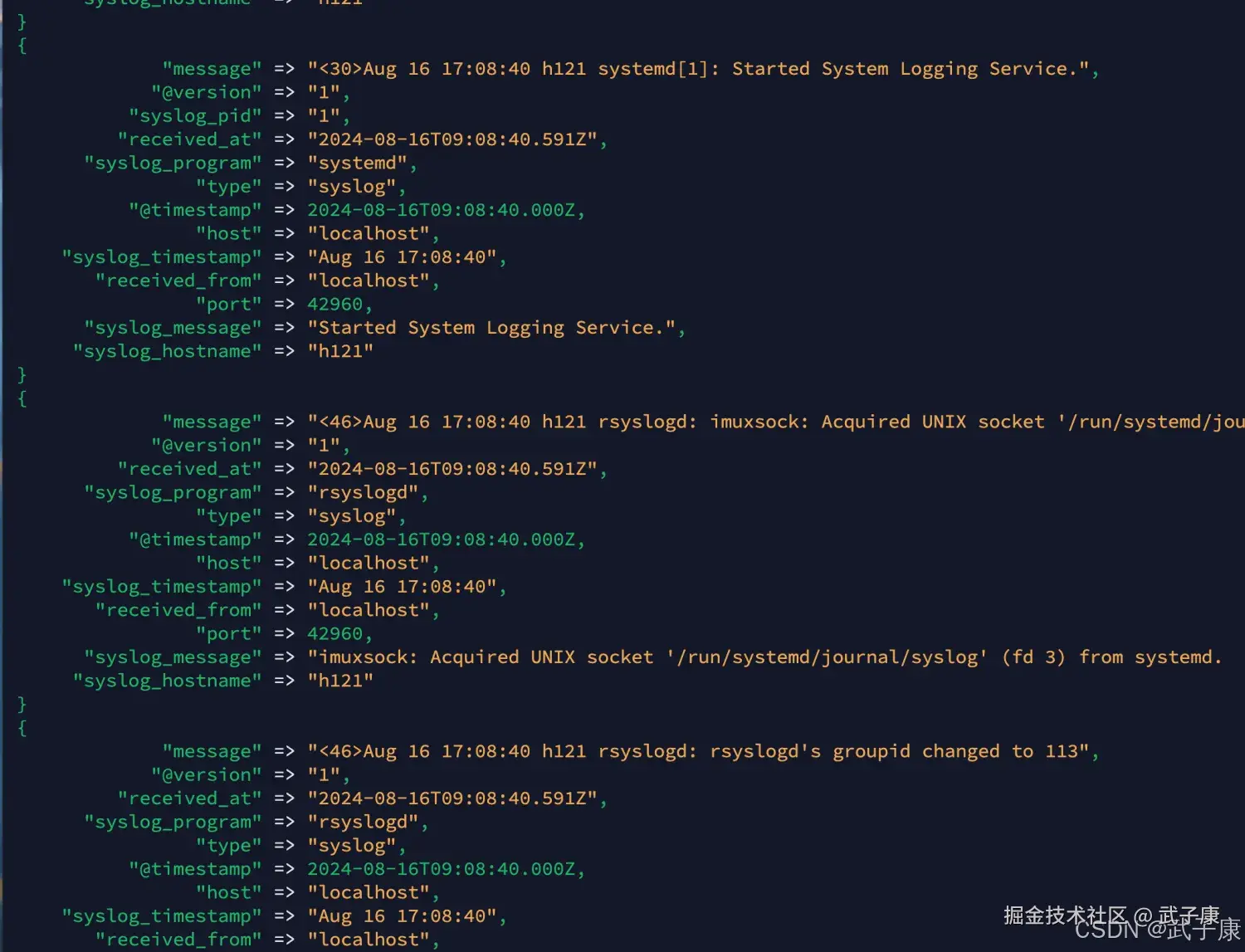
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| JDBC 启动报驱动类找不到(ClassNotFound) | jdbc_driver_library 路径不对 / jar 不存在 / 类名不匹配 | Logstash 启动日志里看 Java::...ClassNotFoundException;确认 jar 实际路径 | 校正 jar 路径;MySQL 8 用 com.mysql.cj.jdbc.Driver;确保 jar 对 logstash 进程可读 |
| JDBC 能连库但不拉数据 | statement 条件与 sql_last_value 初始值不匹配;或追踪列非单调 | 打印 stdout 观察是否有 event;检查 last_run_metadata_path 内容 | 首次全量:临时 clean_run => true 或改 SQL 允许全量;确保 tracking_column 单调递增(id/时间戳) |
| 增量位点不更新/重启后重复拉取 | last_run_metadata_path 无写权限/路径不存在;record_last_run 配置不生效 | 查看该路径文件是否生成与更新时间;Logstash 日志搜 last_run | 创建目录并授权;将 record_last_run/clean_run/use_column_value 改为布尔值;固定部署用户与路径 |
| 每分钟调度不执行 | schedule 时区/cron 解析问题;进程未持续运行(前台退出) | Logstash 日志看是否打印 scheduler tick;确认进程存活 | 用标准 cron 表达式;保持进程常驻(systemd/守护进程);必要时加大日志级别 |
| 拉取速度慢/数据库压力大 | SQL 无索引、全表扫;批次太小/网络慢 | DB 侧看慢查询与执行计划;Logstash 侧看每轮耗时 | 给 tracking_column 建索引;只选必要字段;分批分页(statement + 主键范围);合理调度频率 |
| syslog 端口无数据 | rsyslog 未转发/防火墙拦截/目标主机不可达 | 目标机 ss -lntup 看 6789 是否监听;源机 tcpdump 抓包 | 放通 6789 TCP/UDP;确认 @@(TCP) 或 @(UDP);校验主机名解析与路由 |
| 收到数据但 grok 解析失败(_grokparsefailure) | 消息格式与 grok 模式不匹配(设备/系统差异) | stdout 里看原始 message;观察字段是否缺失 | 按实际日志改 grok;先宽松再收紧;为不同来源做分支匹配 |
| 时间戳不对/时区错乱 | date 匹配格式不全;源日志无年份/时区信息 | 看 @timestamp 与 syslog_timestamp;比对时区 | date 增加匹配格式;必要时补 timezone => "Asia/Shanghai";或在 rsyslog 侧输出 RFC3339 |
| UDP 丢日志 | UDP 天然不可靠;高峰期丢包/缓冲区不足 | 对比源端日志量与接收端事件量;系统丢包统计 | 关键日志改 TCP;提升内核缓冲区;降低单机解析压力(水平扩展/分流端口) |
| 端口冲突/启动失败 | 端口被占用或权限不足(低端口) | 启动日志提示 bind 失败;lsof -i :PORT | 更换端口;释放占用;避免使用 514 等特权端口或用能力授权/前置转发 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解