编者按: 当一项技术的参数指标成为行业焦点,我们是否容易落入"数字迷信"的陷阱?在大语言模型竞相宣传"百万级上下文窗口"的今天,更长是否真的意味着更强?我们今天为大家带来的这篇文章,作者的核心观点是:上下文窗口的长度并不能完全代表模型的实际能力,真正决定模型在长文本场景下表现的是其背后的架构设计与技术权衡。
文章系统梳理了当前主流大模型在处理长上下文时所采用的不同技术路径 ------ 从优化后的精确注意力机制(如 GPT-5、Mistral)、稀疏或混合注意力机制(如 Claude、Gemini),到彻底脱离注意力范式的状态空间模型(如 Mamba),并深入剖析了每种架构在记忆持久性、推理深度与计算效率之间的权衡。
作者 | Phuoc Nguyen
编译 | 岳扬
在过去三年中,大语言模型(LLMs)的上下文窗口已从几千个 token 扩展至数十万量级 ------ 在某些系统中甚至达到数百万。Gemini 2.5、Claude 4.5 Sonnet、GPT-5 Pro 和 Llama 4 Scout 均宣称具备百万 token 级别的处理能力。乍看之下,这似乎意味着模型能够"记住"并跨整本书籍、整个代码仓库或数小时的对话进行推理。然而实际上,实际情况要复杂得多。
更长的上下文窗口并不保证更深层次的推理能力或更为准确的记忆能力。 每种架构 ------ Transformer、稀疏/混合架构、混合专家模型(MoE)或状态空间模型(Mamba),与上下文的交互方式各有不同。理解这些差异有助于开发者根据实际需求选择合适的模型,而不是简单地认为所有"百万 token 上下文"的系统都表现一致。
01 为什么只看上下文长度这个数字并不能完整判断模型的实际能力
原始的 Transformer(Vaswani 等人,2017)会对每一对 token 执行自注意力机制,理论上具备全局感知能力。然而,这种二次方复杂度(O(n²))使得序列长度增长时计算量极速增加。
现代长上下文系统通过工程技巧突破了这一限制 ------ 但这些技巧也改变了模型的"思考"方式。
实证测试(如 LongBench、RULER 2025)表明,即使宣称支持 1M-token 输入的模型,也很少能在超过其一半长度的上下文中维持高精度的推理能力。在实际使用中,"有效上下文"通常在达到上下文窗口长度宣传值上限的 30%--60% 时,就会出现记忆衰减。造成这一现象的原因因架构而异。
02 长上下文背后的架构技术
截至 2025 年底,大多数旗舰模型的上下文窗口已稳定在 128k 至 2M token 之间。然而,LongBench 和 RULER 等基准测试持续显示,模型的"有效上下文" (真正能不丢信息、不乱推理的上下文长度),往往仅为它们被宣传的最大值的一半左右。这一差距直接源于不同架构设计理念的分歧。
当前的大模型生态已分化为若干独特的架构谱系,各自在推理深度、记忆持久性和计算效率之间做出不同的权衡。 下表总结了 2025 年底部分主流基础模型的上下文窗口情况。
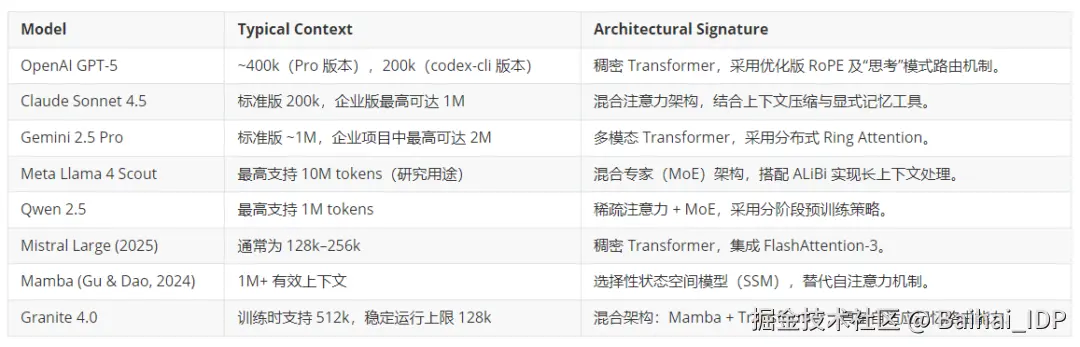
03 大语言模型是如何具体处理和利用其长上下文窗口的
要理解这些行为,我们需要深入其技术细节。模型的性能表现并非完全不可预测的魔法,其实是工程师为了解决"规模扩展"这个根本难题,被迫做出各种技术权衡后,直接导致的结果。
3.1 内存消耗减少的注意力机制
原始的自注意力机制允许每个 token 查看其他所有 token,其计算复杂度随序列长度呈二次方增长。这种计算复杂度上的陡增,使得处理几千 token 以上的上下文变得极其昂贵。现代架构通过以下几种方式克服这一限制:
- 经过优化的精确注意力机制(Optimized Exact Attention) :Mistral 和 GPT-5 等模型并未改变注意力计算的数学本质,而是采用如 FlashAttention-3(GPT-5 据推测使用了该技术)等优化内核。该技术通过"分块"(tiling)大幅减少对 GPU 高带宽内存的慢速读写操作,使精确计算注意力在长达 256k token 甚至更长的序列上变得可行。
- 稀疏或混合注意力机制(Sparse or Hybrid Attention)(例如 Claude、Gemini) :这类架构会动态压缩或摘要部分上下文,以控制内存增长。具体实现大多属于商业机密,但学术研究版本(如 Longformer)表明,稀疏或混合注意力机制能够在序列增长时丢弃或聚合不那么重要的信息,从而维持主题连贯性并降低计算开销。
- 分布式精确注意力机制(Distributed Exact Attention) :对于可扩展系统,Ring Attention(Liu, 2023)能将计算负载分布到多个加速器组成的集群上。每个设备负责计算序列中某一片段的注意力,并将结果以环形的方式传递给下一个设备,从而实现对数百万 token 的精确注意力计算。据传 Google Gemini 1.5 采用了这种方法1,但由于其未公开专有架构,我们无法确认。这种架构在生产环境中的一个有趣特性是支持确定性计算模式(deterministic compute mode),有助于开发者获得更强的一致性保障。
其影响体现为一种明确的权衡:"使用精确注意力机制的模型(exact attention models)"适合需要极高准确性的精细任务(如法律审阅),而"分布式模型(distributed models)"适合需要处理海量数据的批量任务(如大型媒体文件分析)。
3.2 为适应更长上下文而对位置编码方法进行扩展的方案
Transformer 模型本身不具备顺序感知能力。位置编码用于告诉模型每个 token 所处的位置,但所选用的方法会产生强大且可预测的 biases(译者注:biases 指模型在处理信息时,会系统性地更重视某些位置(比如开头、结尾),而相对忽视另一些位置(比如中间)。)。
- 旋转位置嵌入(Rotary Position Embeddings, RoPE) :Llama 4 采用 RoPE,以相对方式编码位置信息。为了处理比训练数据更长的序列,它们使用 RoPE 缩放(RoPE scaling)技术,对位置值进行"拉伸"。虽然这能防止模型因位置混淆而"回绕"(wrap around),却降低了远距离 token 之间的位置分辨率,直接加剧了"中间迷失"(lost in the middle)问题 ------ 即上下文中间部分的细节常被忽略或错误回忆。
- 带线性偏置的注意力(Attention with Linear Biases, ALiBi) :ALiBi 最初通过在注意力分数上施加与 token 距离成比例的线性惩罚来实现位置感知,如今 ALiBi 已成为主流的位置编码方案。它通过数学设计,强制模型更关注文本中较新的内容,但这种"近期偏好(recency bias)"是可控且平滑的,使得模型能够稳定地处理比训练时更长的序列。Mistral 系列模型即采用了 ALiBi,并结合使用了 FlashAttention 库。
这或许可以解释:在长问答任务中,GPT-5 可能能正确关联两个相距较远的事实,却对中段信息产生幻觉性补充;而某个 Llama 变体则可能完全忽略提示词开头的内容,只关注结尾部分。
3.3 稀疏与分块注意力机制(Sparse and Chunked Attention)
为避免完整的 O(n²) 复杂度的注意力计算,Longformer 或 BigBird 等架构采用稀疏模式(例如分块或滑动窗口),而分块方法将长序列切割成片段,并在处理后续片段时携带并利用之前片段的"状态(译者注:模型对该块内容的理解和记忆。)"(例如 GLM-4 中的 Retentive Transformer)。Claude 4 的混合方案则会动态压缩较旧的上下文。
实际影响:稀疏设计在智能体(agentic)工作流中表现突出 ------ 子智能体可分别处理不同片段,进行分层摘要,有效减少了多步骤规划等长程任务中的信息干扰。它们在软件工程中也十分高效,例如分析大型代码库时无需完整重载上下文。
04 超越注意力机制:状态空间模型的崛起
有一类新型架构正在彻底脱离注意力机制的范式。其中最引人注目的是 Mamba(Gu & Dao, 2024),它用选择性状态空间模型(Selective State Space Model, SSM)取代了自注意力机制。Mamba 并不会逐一比较每对 token,而是维护一个不断演化的隐状态,作为对过去 token 的压缩记忆,并选择性地更新该状态 ------ 学习何时覆盖、何时保留信息。
这种方法实现了线性时间处理 ------ 每个 token 的处理时间为常数,使 Mamba 的实际扩展复杂度达到 O(n)。在实际应用中,这意味着它能以恒定的内存消耗处理数百万 token,即便是 GPT-5 或 Gemini 等经过高度优化的 Transformer 也难以做到这一点。
与需要显式计算 token 间关系的注意力机制不同,Mamba 的选择性扫描机制(selective scan)更像一个动态滤波器,自主决定将哪些历史信息向前传递。Mamba 不会像 Transformer 那样存储一张清晰的、记录着所有词元之间关系的"地图",而是维持着一段对序列进行持续压缩而形成的"记忆流"。这种设计使 Mamba 在"大海捞针"式检索、流式数据处理和序列化问答等任务中表现卓越 ------ 在这些场景中,持久的记忆能力比精细的关系推理更为关键。
然而其优势伴随相应代价。由于内部状态经过压缩,Mamba 有时会丢失细节,在复杂的多跳推理任务中表现吃力。目前,新兴的混合架构【如 IBM 的 Granite 4.0,以及 Gemini 2.5 Pro(可能)】已开始探索将 Mamba 式的循环记忆与 Transformer 推理层结合,以期兼顾记忆稳定性和逻辑深度。
Granite 4.0 混合模型实际上采用了 9:1 的 Mamba-2 模块与 Transformer 模块比例。其核心理念是:由 Mamba 以轻量高效的方式处理宏观上下文和长程记忆,而周期性插入的 Transformer 层则负责处理精细的关系推理任务。

05 推理深度 vs. 上下文广度
研究一再证实,仅靠更长的上下文长度并不能保证稳定的推理能力。Liu 等人(2023)揭示了"中间迷失"(lost in the middle)效应:模型的记忆呈现系统性的 U 型曲线 ------ 过度强调最近的和最开始的 token,却忽视了提示词中间部分的信息。这一现象后来被称为上下文衰减(context rot),即便在 2025 年的模型架构中依然存在,只是缓解手段有所演进。IBM 的 Granite 4.0 模型(IBM, 2025)引入了分层记忆路由和混合注意力层,能够显式地在数十万 token 的上下文中保持每个 token 的重要性(译者注:即哪些信息更值得保留和关注),初步展现出超越标准 Transformer 的稳定性。
- Dense Transformers(如 GPT-5 和 Mistral)
它们的失败往往在于毫厘之差,而非千里之谬。由于它们进行完整注意力计算,很少完全崩溃,其错误通常表现为微妙的事实幻觉 ------ 例如,第 50,000 个 token 中的某个细节几乎能被正确回忆,却在关键数字或名称上出错。
- Compression-Hybrids(如 Claude 4.5)
其失败源于过度谨慎。其优势在于保持主题连贯性,弱点则是经过对齐微调的模型可能将大量用户提供的文本(如整部小说)误判为受版权保护的内容,从而导致礼貌地拒绝回答。
- Sparse and Multimodal models(如 Gemini 2.5)
它们具备近乎完美的事实回忆能力。主要的失败点往往来自模型外围的安全机制:在处理数百万多模态 token 时,一个过于敏感的安全过滤器可能在噪声中产生误报,导致响应被提前中止。
- Mixture-of-Experts models(如 Llama 4 和 Qwen)
这类模型可能会因为出现"指令漂移"或"不断输出重复内容"而失效。当复杂查询逼近上下文极限时,专家路由机制可能开始失灵,导致模型"迷失位置",转而输出通用的或重复的内容。
- State-Space Models(如 Mamba)
Mamba 带来了一种新型的失效模式。由于它将信息存储为连续的内部状态,错误通常表现为信息压缩损失,而非直接的幻觉。模型可能准确记得某事实曾在序列早期出现,但在转述时进行了不精确的简化或改写。这种特性使其在超长上下文中极为稳定,但在需要精细分析推理(尤其是依赖上下文的消歧任务)时偶尔不够精确。
同样属于 SSM(State-Space Models) 范畴的,还有 IBM 的 Granite 4.0 系列,它代表了一种"稠密-稀疏混合"架构,结合了混合专家模型与自适应压缩的特性。它并非纯粹将 token 路由到不同专家,而是采用分层聚合和长期记忆层,来减少远距离信息传递中的梯度衰减。

架构选择直接决定了用户所能体验到的"长上下文"的实际效果
06 实际权衡与使用场景
以下是针对不同架构选择的一些应用场景建议:
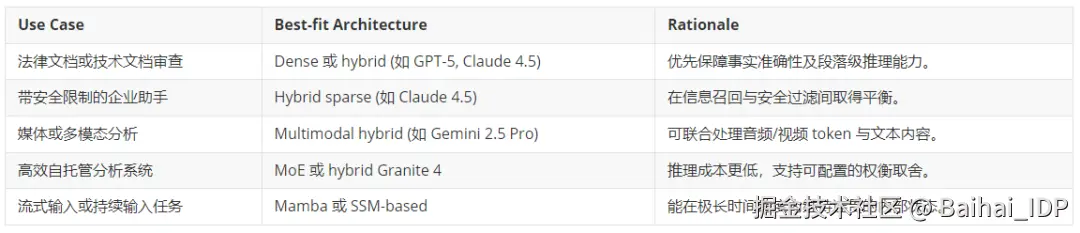
07 未来发展方向:更智能,而非更长
截至2025年末,上下文扩展的重点已非单纯增加词元数量,而是更注重让每个 token 都有意义。高效利用上下文需要结合架构设计(architectural design)、数据扩展(data scaling)和程序化推理(procedural reasoning)。
未来的系统很可能融合这些方向 ------ 用状态空间模型保证持久记忆,用注意力机制保障精度,再通过条件推理提升整体效率。
开发者应在不同架构间进行测试比较,而非仅关注上下文窗口大小。如果模型的内在偏好(inductive biases)(比如重视局部连贯性、压缩远距离信息)与任务特性相匹配,一个 128k 上下文窗口大小的稀疏模型完全可能胜过 1M 的密集模型。归根结底,上下文能力是架构特性的体现,而不仅仅是计算量(或算力规模)的堆砌结果。
References
Gu, A., & Dao, T. (2024). Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752.
Liu, N. F., Röttger, P., Misra, K., Yu, J., & Levy, O. (2023). Lost in the middle: How language models use long contexts. arXiv:2307.03172
International Business Machines Corporation. (2025, October 2). IBM Granite 4.0: Hyper-efficient, high-performance hybrid models. IBM Newsroom. Retrieved from www.ibm.com/new/announc...
END
本期互动内容 🍻
❓文章指出"长上下文竞赛的重点正从'记多长'转向'如何记'"。你是否认同这是未来的主要技术方向?你认为业界接下来最需要突破的架构瓶颈是什么?
文中链接
原文链接: