上文我们讲到参数C,lr=LogisticRegression(C=0.01)
其实这里的参数不仅仅有还有很多参数
1.其他参数

Penalty:正则化的方式,上述我们讲逻辑函数的说过,有两种,L1和L2两种。使用L2时只有三种优化算法(这里的优化是指优化逻辑回归)支持L2,lbfgs,newton-cg,sag
很多参数都是默认的,所以平时使用的时候并不需要特意去写

其中我们的C=1/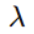 ,也就是上文损失函数中的,所以C越大惩罚力度越小,C越小惩罚力度越大。
,也就是上文损失函数中的,所以C越大惩罚力度越小,C越小惩罚力度越大。
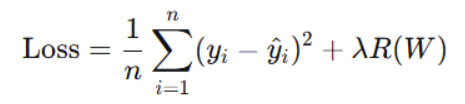
还有一个max_iter:算法收敛最大迭代次数,默认是100,其实就是欠拟合的时候就设置大一点

2.C值的选择
平时我们写代码,设定另一个C值,运行代码,并输出预测集的召回率
然后在设置一个C值运行代码,输出预测集召回率
......多次这样去找到一个优化最好的C值
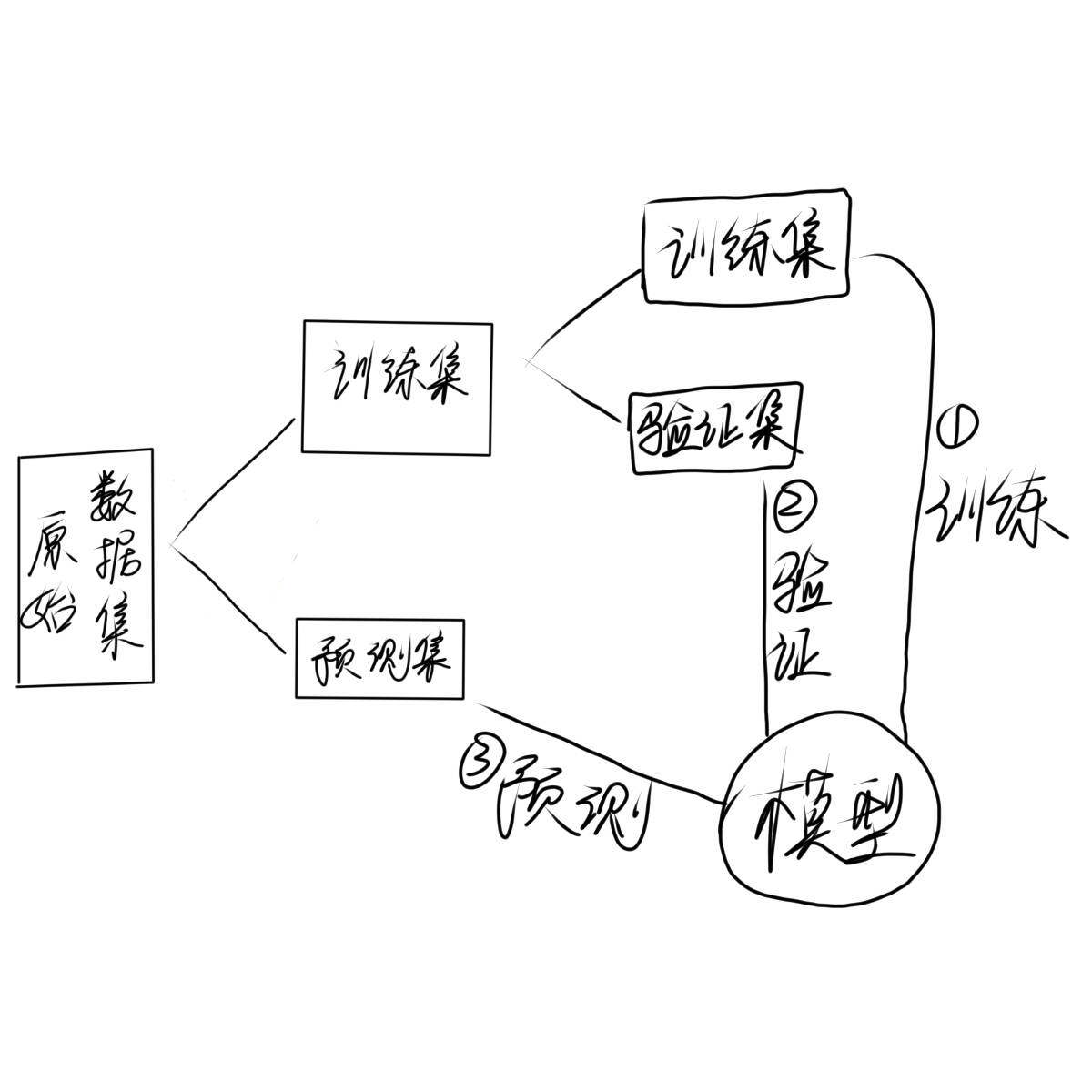
想法是正确的但是用测试集一点一点的推测c值,这就相当于把测试集当训练集了,这样是不行的,测试集只能用来最后测试,结果是一锤定音的
所以这时候我们需要一个验证集,验证集可以来自于训练集的一部分,用验证机去反复验证哪个c值更优,所以代码中我们会用到循环语句。
3.k折交叉验证
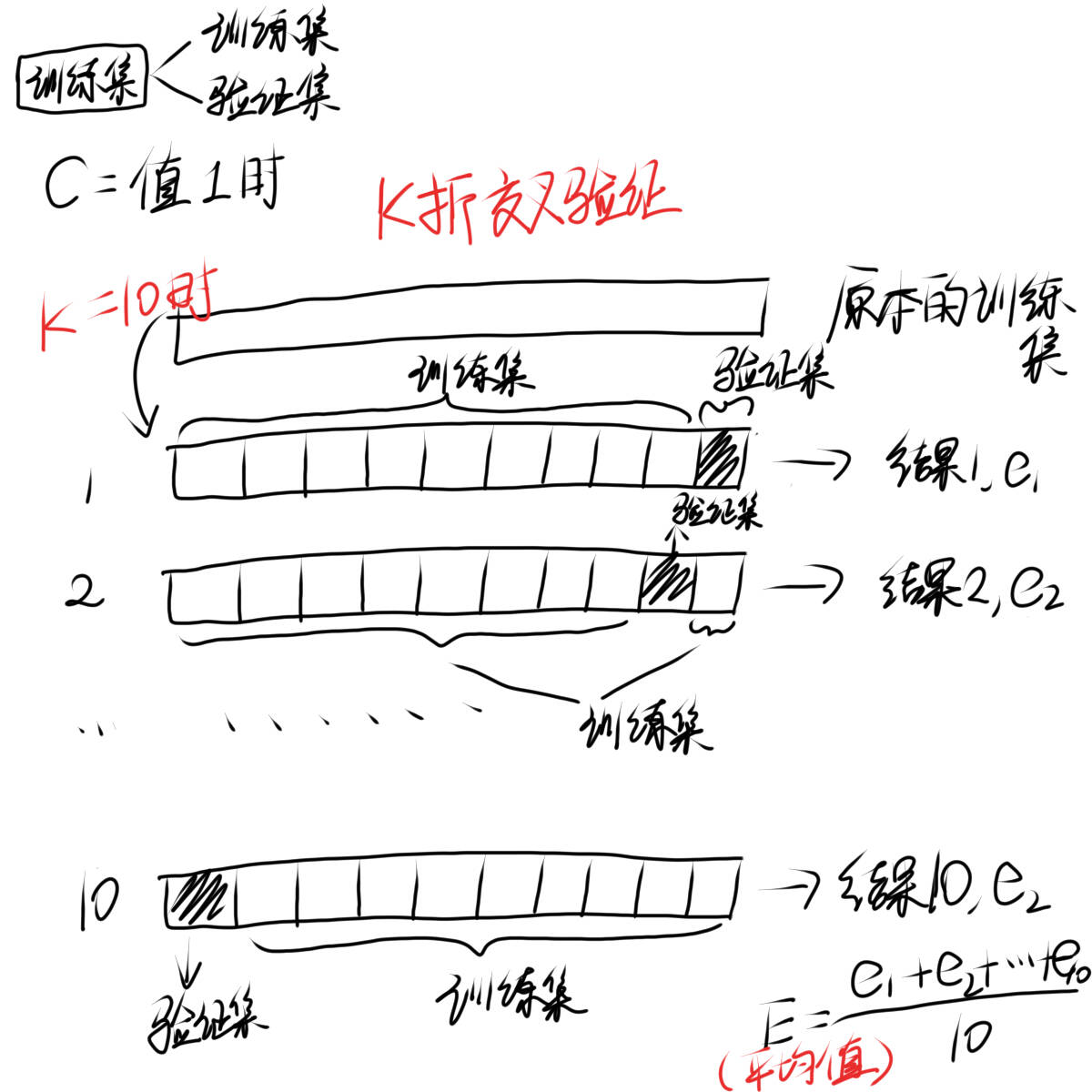
如果训练集拿出一部分作为验证集,这样我们训练集和之前比就会变少,是否会导致训练不到位?所以在验证c最优c值的时候我们采用k折交叉验证
k取值多少我们就把原来的训练集分为几份,c取某个值的时候每一份依次做验证集,这样就保证了分出去当验证集的数据也能当训练集训练模型,分成几份就会得到几个结果,把结果求平均值就可以作为该c值下的结果
去多个c值,把每一次c值得到的结果进行比较,选出最优c值
4.找出最优c值,提高召回率的实现
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split#专门用来对数据集进行切分的函数
from sklearn.linear_model import LogisticRegression#逻辑回归的类,所有的算法都封装再这个类里面
from sklearn import metrics
from sklearn.model_selection import cross_val_score
'''绘制混淆矩阵'''#混淆矩阵的实现可以用大模型搜索,不做讲述
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment = 'center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
'''数据预处理'''
#把没用的信息删去,保留矩阵在data中
data=pd.read_csv(r"E:\filedata\creditcard.csv")
data['Amount']=pd.DataFrame(scale(data['Amount']))#把Amount列也进行标准化
data=data.drop(['Time'],axis=1)#用不到的Time列删去
'''训练集使用采样数据,测试举使用原始数据集进行预测'''
X_data=data.drop('Class',axis=1)#前面我们已经处理过数据了
Y_data=data.Class
x_train, x_test, y_train, y_test = train_test_split(X_data, Y_data, test_size=0.3, random_state=1000)#随机种子
scores =[]#不同的c参数在验证集下的评分
c_s =[0.01,0.1,1,10,100]#参数
for i in c_s:
lr = LogisticRegression(C= i, penalty = 'l2', solver='lbfgs', max_iter=1000)
#这里的cv=8就是k=8,分八份
score = cross_val_score(lr,x_train, y_train, cv=8,scoring='recall')#交叉验证
# scoring:可选"accuracy"(精度)、recall(召回率)、roc_auc(roc值)、neg_mean_squarel
score_mean=sum(score)/len(score)#求平均值
scores.append(score_mean)#将不同的c参数的结果添加到scores列表中
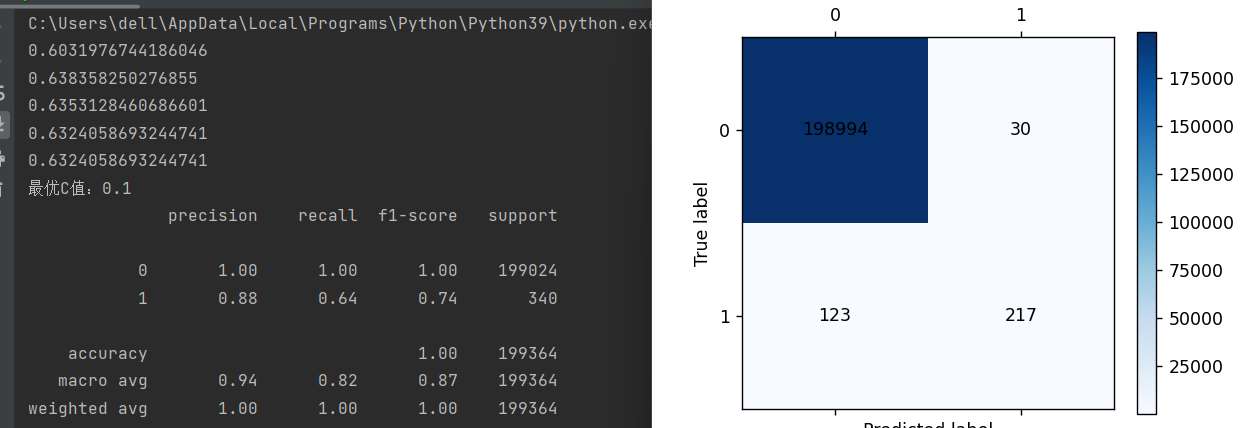
print(score_mean)#输出该值
best_c= c_s[np.argmax(scores)]#选出最优值
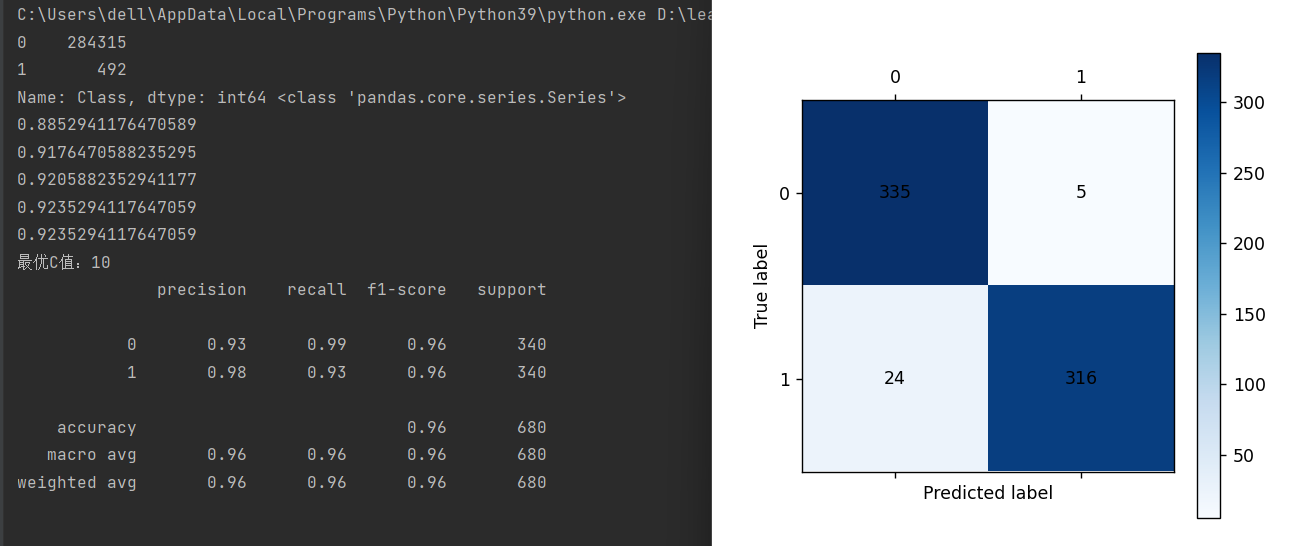
print('最优C值:{}'.format(best_c))#输出最优c值
lr=LogisticRegression(C=best_c,penalty='l2',max_iter=1000)#定义逻辑回归
lr.fit(x_train,y_train)#进行模型训练
train_pre=lr.predict(x_train)#训练集自测
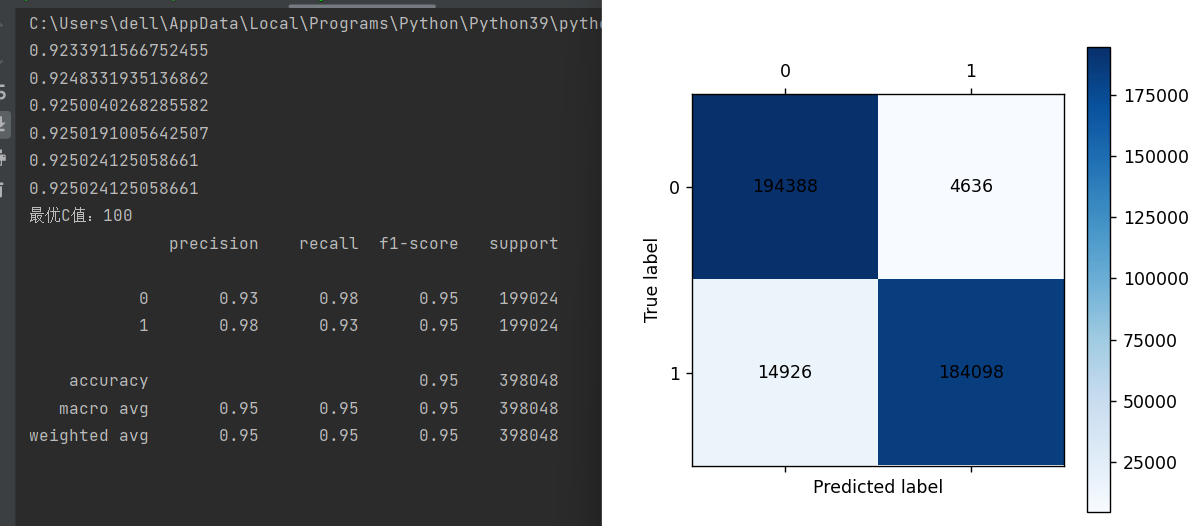
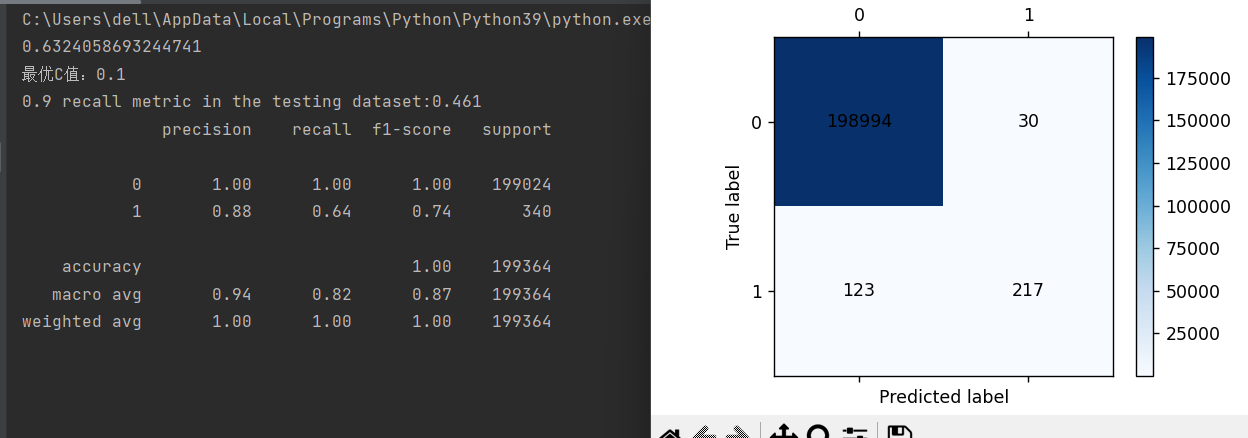
print(metrics.classification_report(y_train,train_pre))
cm_plot(y_train,train_pre).show()
testpre=lr.predict(x_test)#预测集预测
complete=lr.score(x_test,y_test)
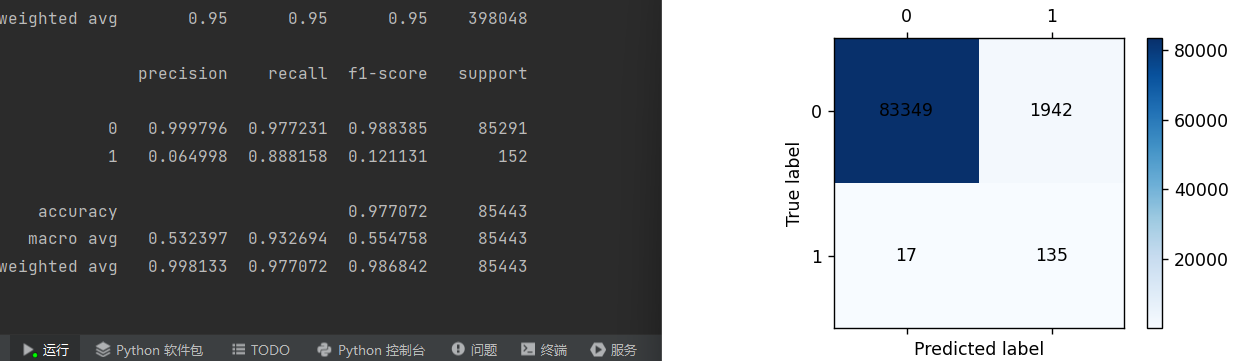
print(metrics.classification_report(y_test,testpre,digits=6))
cm_plot(y_test,testpre).show()和上篇博客中代码用同样的数据但是更改了c值并找到了最优c值,训练召回率和预测召回率都提升了。
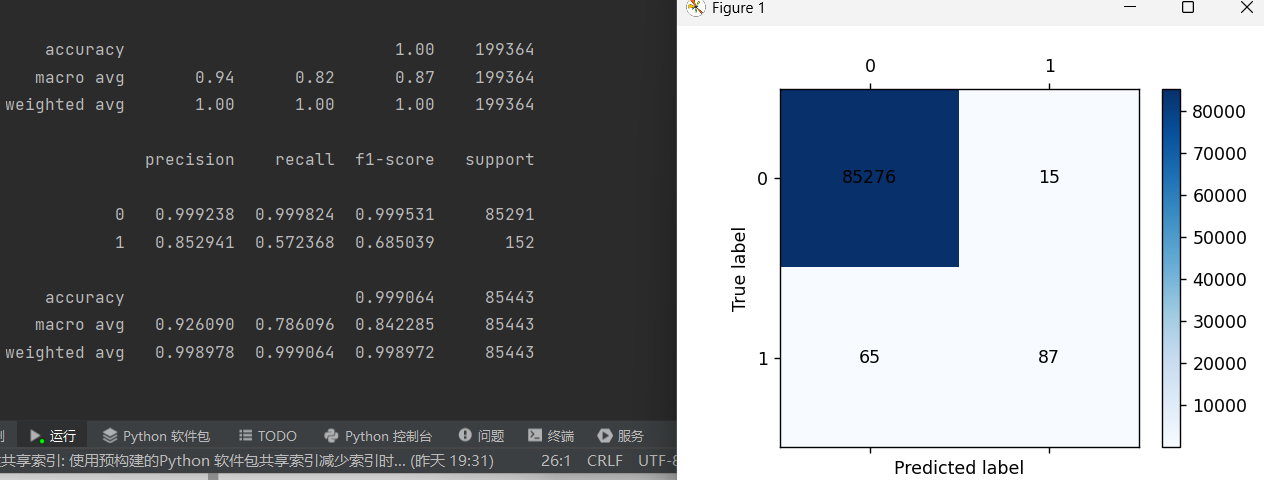
交叉验证不仅能用于逻辑回归,有不确定值都可以使用交叉验证
4.调整阈值增加召回率
除了找到最优c值能增加我们的召回率,我们也可以改变阈值进行
本来值为0.3......被归为0类的,在改变阈值后就属于1类了,这也算是强制实施了"宁可错杀也不放过"的原则
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split#专门用来对数据集进行切分的函数
from sklearn.linear_model import LogisticRegression#逻辑回归的类,所有的算法都封装再这个类里面
from sklearn import metrics
from sklearn.model_selection import cross_val_score
def cm_plot(y, yp):#混淆矩阵的绘制
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment = 'center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv(r"E:\filedata\creditcard.csv")
data['Amount']=pd.DataFrame(scale(data['Amount']))#把Amount列也进行标准化
data=data.drop(['Time'],axis=1)#用不到的Time列删去
X_data=data.drop('Class',axis=1)
Y_data=data.Class
x_train, x_test, y_train, y_test = train_test_split\
(X_data, Y_data, test_size=0.3, random_state=1000)#随机种子
scores =[]#不同的c参数在验证集下的评分
c_s =[0.01,0.1,1,10,100]#参数
for i in c_s:#第1词循环的时候C=0.01,5个逻辑回归模型
lr = LogisticRegression(C= i, penalty = 'l2', solver='lbfgs', max_iter=1000)
score = cross_val_score(lr,x_train, y_train, cv=8,scoring='recall')#交叉验证
# scoring:可选"accuracy"(精度)、recall(召回率)、roc_auc(roc值)、neg_mean_squarel
score_mean=sum(score)/len(score)#交又验证后的值召回率#里面保存了所有的交叉验证召回率
scores.append(score_mean)#将不同的c参数分别传入模型,分别看看哪个模型效果更好,我们选c
print(score_mean)
best_c= c_s[np.argmax(scores)]
print('最优C值:{}'.format(best_c))
lr=LogisticRegression(C=best_c,penalty='l2',max_iter=1000)
lr.fit(x_train,y_train)
'''修改逻辑回归中的阈值'''#先训练在进行修改阈值操作
thresholds=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
recalls=[]
for i in thresholds:
y_pre=lr.predict_proba(x_test)
y_pre=pd.DataFrame(y_pre)
y_pre=y_pre.drop([0],axis=1)
y_pre[y_pre[[1]]>i]=1#预测的概率大于i,0.1,0.2预测的标签设置为1
y_pre[y_pre[[1]]<=i]=0#当预测的概率小于等于i,预测标签设置0
recall=metrics.recall_score(y_test,y_pre[1])
recalls.append(recall)
print("{} recall metric in the testing dataset:{:.3f}".format(i,recall))
#训练集自测
train_pre=lr.predict(x_train)
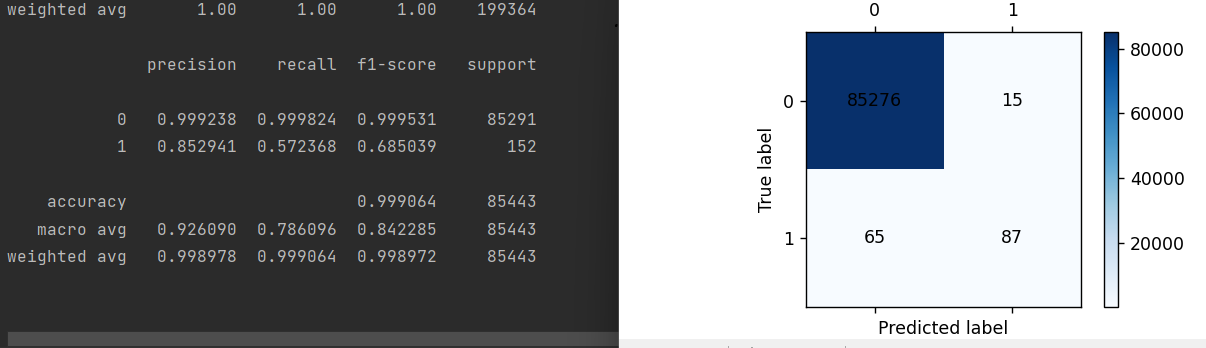
print(metrics.classification_report(y_train,train_pre))
cm_plot(y_train,train_pre).show()
#测试集预测
testpre=lr.predict(x_test)
complete=lr.score(x_test,y_test)
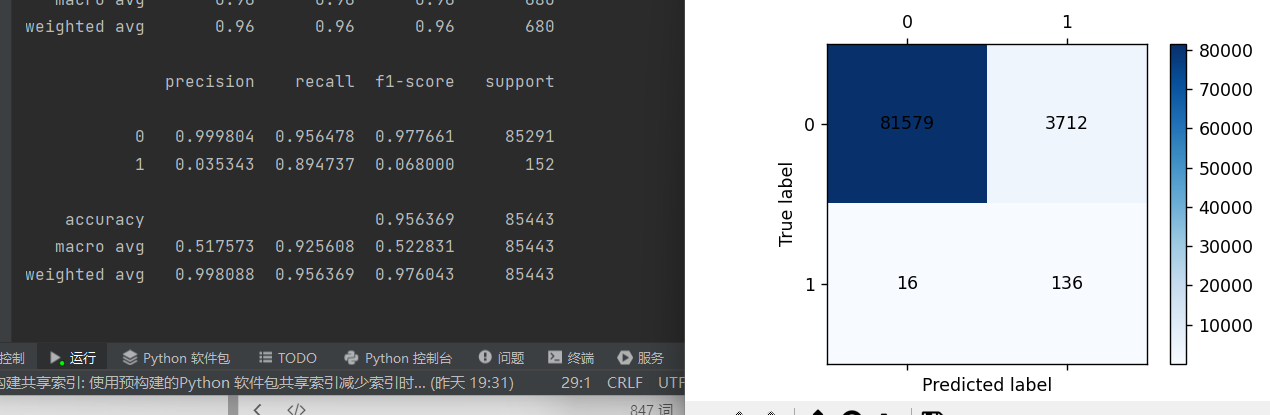
print(metrics.classification_report(y_test,testpre,digits=6))
cm_plot(y_test,testpre).show()从结果也可以看出,这样也能提高召回率
5.将不均衡的数据处理均衡增加召回率
1)下采样
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split#专门用来对数据集进行切分的函数
from sklearn.linear_model import LogisticRegression#逻辑回归的类,所有的算法都封装再这个类里面
from sklearn import metrics
from sklearn.model_selection import cross_val_score
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment = 'center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv(r"E:\filedata\creditcard.csv")
data['Amount']=pd.DataFrame(scale(data['Amount']))#把Amount列也进行标准化
data=data.drop(['Time'],axis=1)#用不到的Time列删去
value_count=pd.value_counts(data['Class'])#统计各类别的个数
print(value_count,type(value_count))#输出各类别个数
X_data=data.drop('Class',axis=1)
Y_data=data.Class
x_train, x_test, y_train, y_test = train_test_split\
(X_data, Y_data, test_size=0.3, random_state=1000)#随机种子
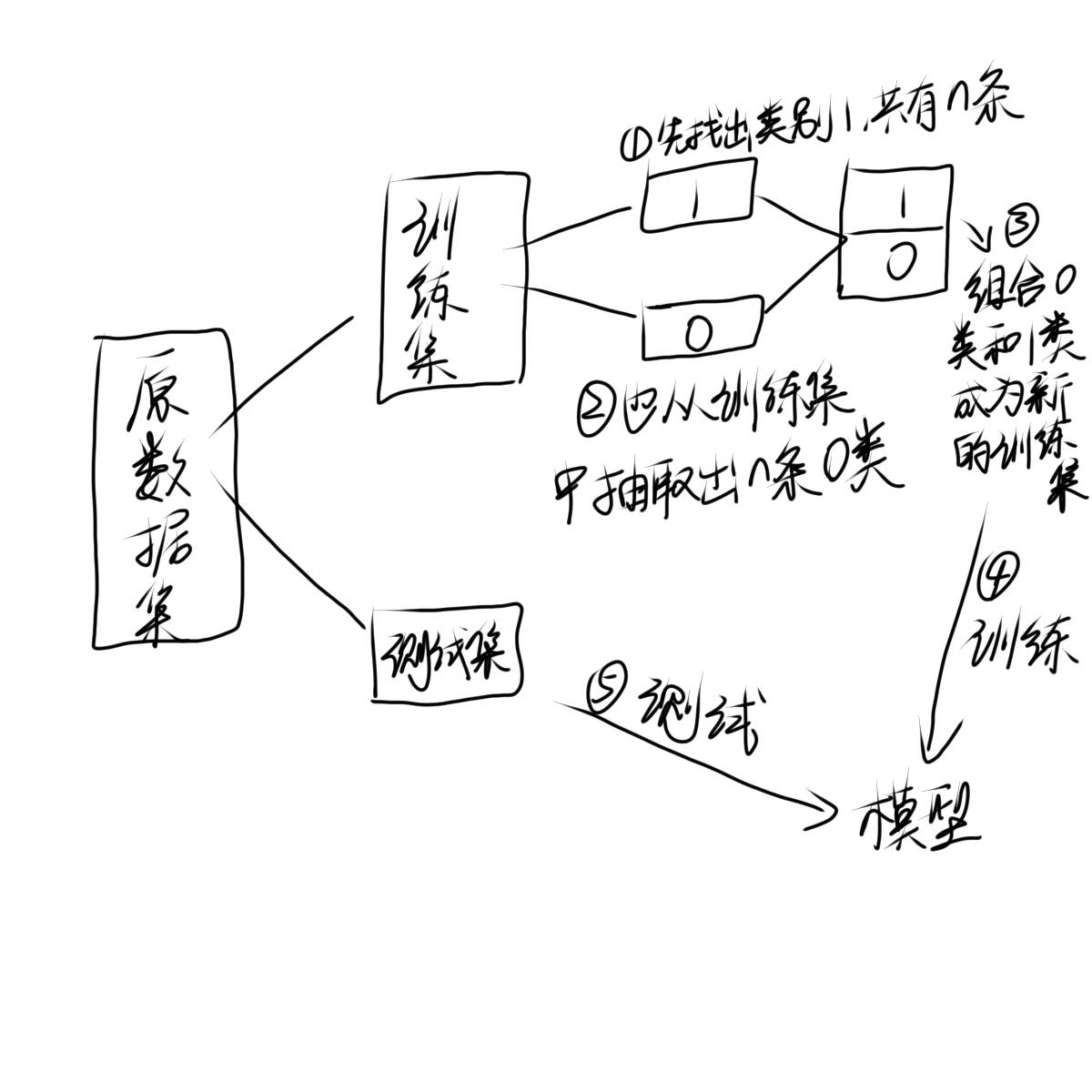
x_train['Class']=y_train#将训练集加上class列
data_train1=x_train把加上class列的数据集定义为训练集
datanumber0=data_train1[data_train1['Class']==0]#抽取所有类别为0的数据
datanumber1=data_train1[data_train1['Class']==1]#抽取所有类型为1的数据
datanumber0=datanumber0.sample(len(datanumber1))#注意这里应该是类别0=类别1
#因为类别数据少,如果是类别1=类别0,那么将会报错显示数据集不够
data_train2=pd.concat([datanumber0,datanumber1])
#将抽取出条数相等的0类和1类组合作为我们的训练集
X=data_train2.drop('Class',axis=1)#对处理好的数据集进行数据和类别的划分
Y=data_train2.Class
scores =[]#加上交叉验证
c_s =[0.01,0.1,1,10,100]#参数
for i in c_s:
lr = LogisticRegression(C= i, penalty = 'l2', solver='lbfgs', max_iter=1000)
score = cross_val_score(lr,X, Y, cv=5,scoring='recall')#交叉验证
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best_c= c_s[np.argmax(scores)]
print('最优C值:{}'.format(best_c))
lr=LogisticRegression(C=best_c,penalty='l2',max_iter=1000)
lr.fit(X,Y)
train_pre=lr.predict(X)
print(metrics.classification_report(Y,train_pre))
cm_plot(Y,train_pre).show()
testpre=lr.predict(x_test)
complete=lr.score(x_test,y_test)
print(metrics.classification_report(y_test,testpre,digits=6))
cm_plot(y_test,testpre).show()很明显我们的召回率大幅度提升
2)过采样
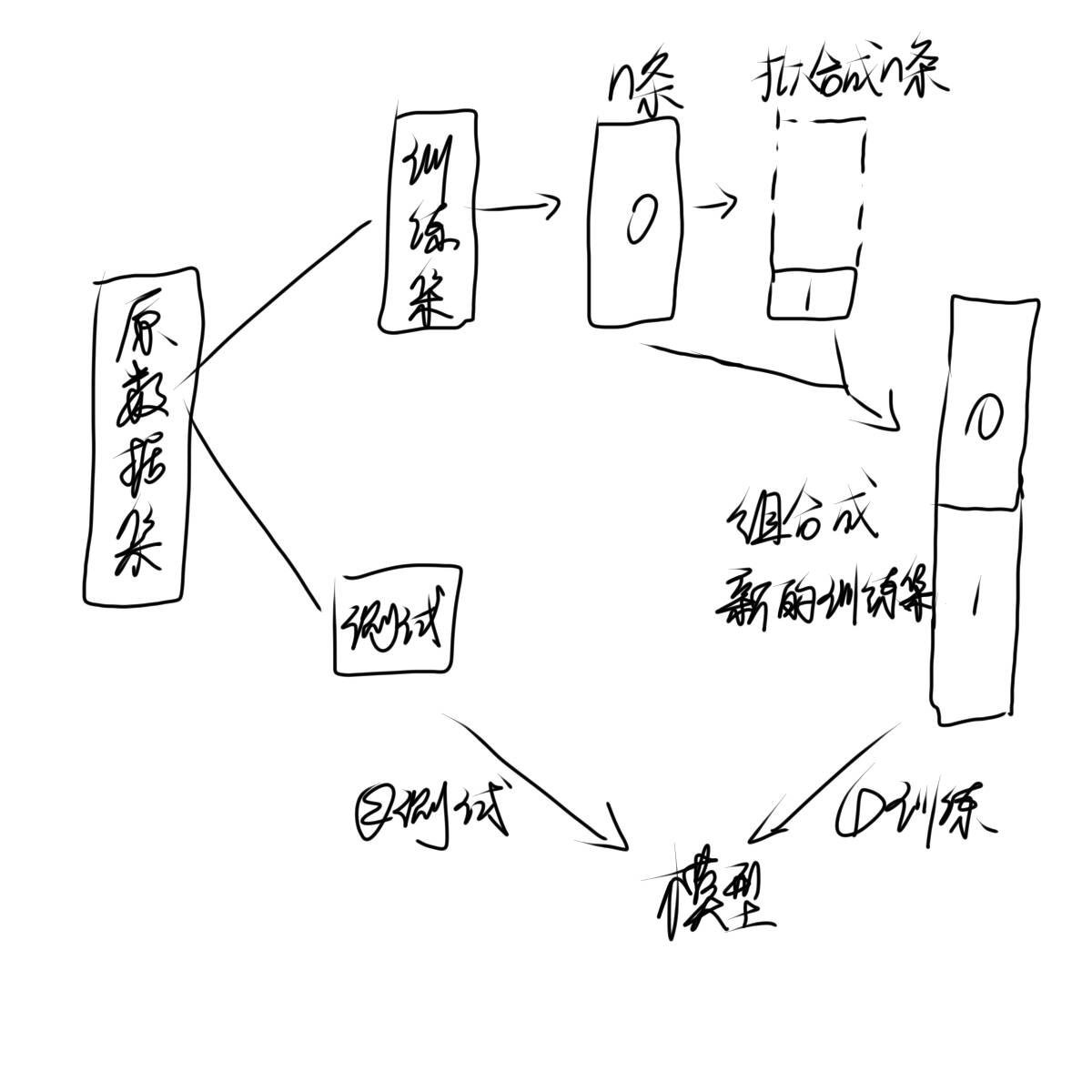
如何拟合数据,我们需要用到一个函数:smote类
拟合数据无非就是在同一类中挑选俩个数据取中间的一些值,就像我们knn算法中,相同一类在一起那我们在同一类的内部拟合数据自然也就是这类的,拟合数据就是这样一个过程。
在使用之前我们需要下载一个第三方库imblearn然后调用smote类,调用前先初始化一个对象
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split#专门用来对数据集进行切分的函数
from sklearn.linear_model import LogisticRegression#逻辑回归的类,所有的算法都封装再这个类里面
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from imblearn.over_sampling import SMOTE#第三方库imblearn
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment = 'center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv(r"E:\filedata\creditcard.csv")
data['Amount']=pd.DataFrame(scale(data['Amount']))#把Amount列也进行标准化
data=data.drop(['Time'],axis=1)#用不到的Time列删去
X_data=data.drop('Class',axis=1)
Y_data=data.Class
x_train, x_test, y_train, y_test = train_test_split\
(X_data, Y_data, test_size=0.3, random_state=1000)#随机种子
oversampler=SMOTE(random_state=0)#初始化smote对象
X,Y=oversampler.fit_resample(x_train,y_train)
#fit_resample会对数据中数据少的类型自动识别这里就不需要分别挑出1和0类了
#对原来的训练集特征和标签也就是这里的x_train,y_train进行识别拟合数据,返回新的特征和标签
#这里也不需要组合起来了,因为没有分开类1和类0,这些数据始终都是在一起的
#注意这里拟合过整个训练集数据条数增加了一倍,数据多,训练自然就不会因为数据过少而欠拟合
#但是同时我们运行速度也会变慢
scores =[]
c_s =[0.01,0.1,1,10,100,1000]#参数
for i in c_s:
lr = LogisticRegression(C= i, penalty = 'l2', solver='lbfgs', max_iter=1000)
score = cross_val_score(lr,X, Y, cv=5,scoring='recall')#交叉验证
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best_c= c_s[np.argmax(scores)]
print('最优C值:{}'.format(best_c))
lr=LogisticRegression(C=best_c,penalty='l2',max_iter=1000)
lr.fit(X,Y)
train_pre=lr.predict(X)
print(metrics.classification_report(Y,train_pre))
cm_plot(Y,train_pre).show()
testpre=lr.predict(x_test)
complete=lr.score(x_test,y_test)
print(metrics.classification_report(y_test,testpre,digits=6))
cm_plot(y_test,testpre).show()过采样也能把召回率提升到零点九多