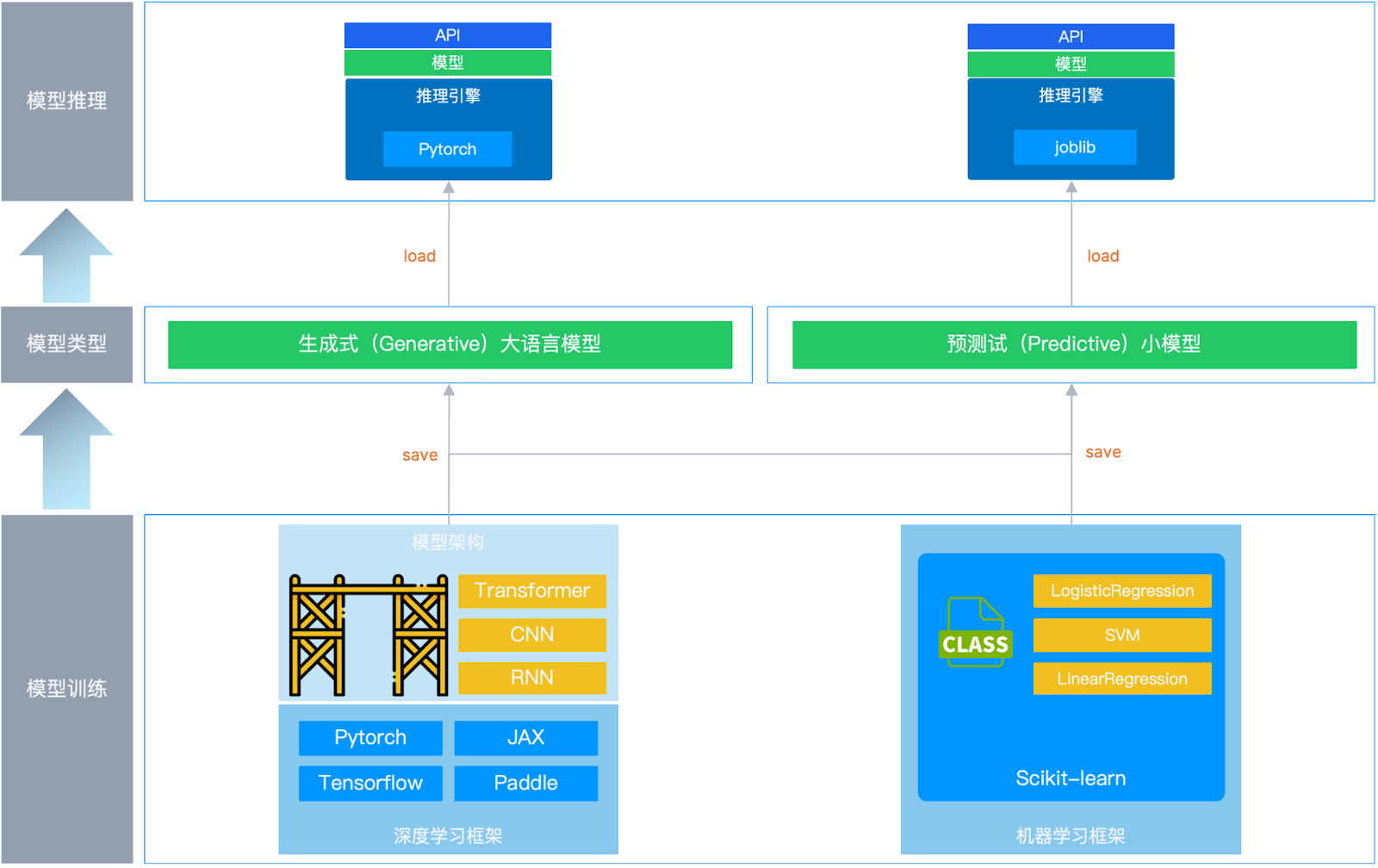
学习框架和推理引擎通常分别应用在 AI 大模型的训练和推理(运行)阶段。模型的核心任务是从大量数据中学习规律,完成特定预测或者生成任务,前者即"模型训练",后者即"模型运行"。在模型训练时,通常由工程师准备训练用的数据(训练集和测试集),由学习框架 调用数据以完成模型的训练。模型训练好后,工程师完成模型的分发并通过推理引擎将模型运行起来,用户通过 API 来调用这个模型,完成特定的任务。
举个例子:
- 游戏开发商通过各种工具**(学习框架)** 完成游戏**(模型)**的开发。
- 游戏开发商将开发好的游戏"烧录"到卡带或者在平台发布数字版游戏**(训练好的模型)**。
- 玩家使用兼容这个游戏的游戏主机**(推理引擎)** 来玩游戏**(使用模型)**。
对于不同的模型,使用的学习框架和推理引擎是有所区别的。
预测式(Predictive)小模型
这类模型参数较少、层数较浅,在解决如垃圾邮件检测的分类问题中,可使用诸如 Logistic Regression 这类的逻辑回归多元分类模型来实现预测任务。在训练时,通常借助 Python 中的 Scikit-learn(sklearn)机器学习框架来快速调用已经实现好的逻辑回归模型,通过 fit 方法完成训练。
- Scikit-learn:一个专门为机器学习设计的库,就像 os 或 math 一样,是 Python 生态中的标准工具之一。
- LogisticRegression :在 sklearn 中,它既可以说是一个"模型",也可以称作"算法",在代码层面表现为一个类(LogisticRegression)。*如:
from sklearn.linear_model import LogisticRegression
模型训练好后一般被保存成 joblib、pkl 等格式,通过采用推理引擎加载运行。此时推理引擎主要负责读取并加载训练好的模型文件、提供模型预测 API 接口、调用模型对象 predict 方法进行预测,并将预测结果返回给用户。
生成式(Generative)大模型
这类模型参数较多、层数较深,具有更强的表达能力和更高的准确度。在解决文本生成、摘要的问题中可使用诸如 CNN、RNN 和 Transformer 这类架构来实现生成任务。在训练过程中,可以借助 Pytorch、Tensorflow、JAX 等深度学习框架基于不同的模型架构(CNN、RNN 和 Transformer)实现生成式模型。
- Pytorch:一个专门为深度学习设计的库,就像 os 或 math 一样,是 Python 生态中的标准工具之一。
- Transformer:与上面的 LogisticRegression 不同,它并不是一个已经实现好的模型 ,而是一个实现模型的框架,类似于脚手架,通过 Pytorch 中实现的"类"(import torch.nn as nn) 按照这个框架可以实现一个高性能的模型。
模型训练好后一般被保存成 safetensors、gguf 等格式,采用 vllm、sglang、llama.cpp 等推理引擎。这类推理引擎更为复杂,除了提供 API 接口并读取/加载模型,还会循环调用模型对象 forward() 方法逐步生成 Token、管理 KV-Cache 缓存,并将生成结果实时返回给用户。
可以通过如下图示再了解下整个过程:
更多 AI 知识科普、AI 大模型落地方案与 AI 基础设施建设实践,欢迎阅读往期博客:
AI 模型落地关键概念解读:推理引擎/ModelOps/MaaS/AI Agent...
AI实践分享|以MCP简化IT运维管理,生成定制化报表(附操作演示)
SmartX AI 基础设施新增昇腾 NPU 与 MindIE 支持能力:方案与评测