在智能家居场景中,我们经常遇到这样的尴尬:
你说:"把灯打开。" ------ 它可以执行。
你说:"如果检测到漏水,就把水阀关了并发个通知。" ------ 它可能听不懂了。
你说:"有点冷,把空调调高一点。" ------ 它问你:"一点是多少?"
在物联网(IoT)时代,我们希望智能家居不仅仅是"遥控器",而是能听懂人话的"管家"。
我们测试了市面上几款主流大模型------它们的回答五花八门,有的直接调风速但忘了时间设置,有的创建了时间触发却丢失了条件判断,甚至还有把指令误解为"设定闹钟"的。真正能完美解析出"延时+条件+多参数"三重嵌套指令的模型,凤毛麟角。
今天,我们将通过一次完整的实战,展示如何基于 LLaMA Factory Online 平台,利用高质量数据清洗和微调,让轻量级的 Qwen3-4B 模型在智能家居垂直场景下,不仅能听懂"把风速调小一点"这种模糊指令,还能处理"检测到漏水即关闭水阀"的复杂链式操作。
效果对比:微调前 vs 微调后
在开始硬核教程前,我们先来看看微调后的模型到底变聪明了多少。
场景一:条件触发- 从"被动响应"到"主动感知"
场景描述:传统智能家居本质是"语音遥控器",用户不开口,设备不工作;微调后的模型具有主观能动性,它不仅仅是执行者,更是决策者,能够基于传感器数据(时间、温度、光线、气体浓度等)的变化,自主决策并触发相应的设备控制,如空调、新风、窗帘等设备,动态维持环境的最佳状态,实现真正的"空间智能"。
用户指令:"半小时后请把空气净化器的风速调大到3档位"
| 微调前后 | 原始数据集微调后的模型 | 优化后的数据集微调后的模型 |
|---|---|---|
| 模型输出 | {"mcp_type": "iot","function": "control_device", "params": {"device_id": "purifier_bedroom_01", "level": 3}, "confirm": false} | {"mcp_type": "sensor_trigger", "function": "create_automation", "params": {"trigger": {"type":"time_delay", "minutes":30}, "action": {"device_id": "purifier_bedroom_01", "arg": {"op": "control_device", "level":3}}}, "confirm": false} |
| 分析与评价 | 指令解读:mcp_type: IoT 控制消息。function: 设置风速。params: {设备ID,挡位:3}评价:缺少延时条件,缺少相对调整量(delta),设备端无法确定要"设为多少"或"调多少"。 | 指令解读:mcp_type: IoT 控制消息。function: 设置风速。params: {触发条件:30分钟后,动作:给出设备ID,风速减小1。}评价:触发条件完整,风速相对调整量完整。 |
场景二:链式操作-从"单点控制"到"逻辑编排"
场景描述:通过微调优化模型的逻辑推理与任务规划能力,将单一的指令转化为一系列具有逻辑依赖关系的设备协同动作。用户无需逐个下达指令(如"打开电视"、"拉上窗帘"、"调暗灯光"),只需表达最终目的,中间的步骤由模型自动补全。
用户指令:"当检测到漏水时,关闭水阀并发送通知"
| 微调前后 | 原始数据集微调后的模型 | 优化后的数据集微调后的模型 |
|---|---|---|
| 模型输出 | {"mcp_type": "iot", "function": "handle_emergency", "params": {"device_id": "water_heater_01", "action": "emergency_stop"}, "confirm": false} | {"mcp_type": "sensor_trigger", "function": "create_automation", "params": {"trigger": {"water_leak_sensor_01": "leak"}, "action": {"device_id": "water_valve_main_01", "arg": {"status": "close"}}, {"device_id": "notifier_01", "arg": {"message": "检测到漏水,请立即处理"}}}} |
| 分析与评价 | 指令解读:mcp_type: IoT 控制消息。function: 处理紧急情况。params: {给出水阀ID,动作:紧急停止}评价:缺少发送通知的动作。 | 指令解读:mcp_type: 条件触发类型。function: 创建自动化。params: {触发条件:传感器检测到漏水,动作:关闭水阀,发送通知}评价:触发条件完整,步骤完整。 |
场景三:模糊指令-从"机械匹配"到"意图理解"
场景描述:将用户口语化、情绪化甚至表述不清的指令准确解析并映射为具体的设备控制参数,用户不再需要记忆特定的唤醒词或参数(如"空调调到24度"),而是可以用人类自然的交流方式(如"我有点冷"、"这里太吵了")与系统对话。由微调后的模型赋能的系统不再是冷冰冰的机器,而是能听懂"言外之意"的贴心管家,极大地提升了交互的流畅度和用户的满意度。
用户指令:"三楼空调温度调小一點"
| 微调前后 | 原始数据集微调后的模型 | 优化后的数据集微调后的模型 |
|---|---|---|
| 模型输出 | {"mcp_type": "iot", "function": "set_temperature", "params": {"device_id": "ac_bedroom_01"}, "confirm": false} | {"mcp_type": "iot", "function": "set_temperature", "params": {"device_id": "ac_bedroom_01", "delta": -1}} |
| 分析与评价 | 指令解读:mcp_type: IoT 控制消息。function: 设置温度。params: {空调ID}评价:用户指令为"调小一点",未要求具体温度,为模糊指令;模型输出缺失调小温度的动作。 | 指令解读:mcp_type: IoT 控制消息。function: 设置温度。params: {设备ID,温度调低一度}评价:满足用户指令,温度减小1度。 |
环境准备:搭建端到端的AI训练流水线
本实践包含智能家居"数据处理-基础模型选型-参数调优-微调训练-模型效果评估"完整链路,需要单独创建一个python环境,并配置需要的工具。
1.下载 SmartHome 压缩文件
该文件中包含后续处理数据、模型功能测试等步骤所需的数据集和脚本。
进入 LLaMA Factory Online 平台,创建实例(选择CPU资源2核即可),选择"VSCode处理专属数据"或"Jupyter处理专属数据"。进入工作空间后,新建终端,执行下面指令下载并解压文件。
bash
# 进入目标目录
cd /workspace
# 下载压缩文件
wget "http://llamafactory-online-assets.oss-cn-beijing.aliyuncs.com/llamafactory-online/docs/v2.0/documents/Practice/smart_home/SmartHome.tar.gz"
# 解压到该目录
tar -xzf SmartHome.tar.gz -C /workspace2.新建终端,逐条执行下面指令配置环境
csharp
# 创建自己的虚拟环境
conda create -n smarthome-lightllm-chat python=3.10 -y
# 激活环境
conda activate smarthome-lightllm-chat
# 安装必要的包
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn vllm torch ipykernel pandas partial_json_parser websockets3.模型部署前期准备
bash
# 下载lightllm的最新源码 需要挂VPN
git clone https://github.com/ModelTC/lightllm.git
cd lightllm点击下载requirements.txt文件(🔗s1.llamafactory.online/llamafactor...
perl
pip install -r requirements.txt
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu126
# 安装lightllm
python setup.py install💡提示
● 环境准备→步骤2 中,执行下载 lightllm 的源码前,需要挂VPN。
● 后续步骤在执行代码时,若提示模块不存在,可在终端运行对应的 pip install module name 命令,通常能解决该问题。
数据重塑:从"原始日志"到"标准教材"
Garbage In, Garbage Out。在本次实践中,我们发现原始的 SmartHome_Dataset 存在大量问题(如缺少 function 字段、条件判断失效等)。直接扔进模型训练,效果惨不忍睹。
| 指令类型 | 数量 | 问题 |
|---|---|---|
| iot-基础控制 | 12747 条 | 格式需规范、缺少 function 字段、模糊指令操作失效 |
| sensor_trigger-条件判断 | 3803 条 | 条件判断失效 |
| chain-链式操作 需执行多个动作 | 475 条 | 链式操作失效 |
| sql-查询操作 | 381 条 | - |
| 复杂场景:一设备,多参数 | 328 条 | - |
| optimization | 284 条 | - |
后续计划补充数据类型:
| 指令类型 | 数量 | 来源说明 |
|---|---|---|
| 复杂场景-延时执行+条件判断+多设备联动 | 55 | AI大模型生成+人工标注 |
| 异常指令 | 500 | 智能家居历史交互日志 |
我们做了这三件事,让数据"变废为宝":
- 统一数据格式
修复了大量损坏的 JSON 结构,将所有数据转为标准 Alpaca 格式,确保每条数据都有清晰的instruction(用户指令)和output(标准JSON响应)。
①数据格式标准化。采用 Alpaca 格式,适配单轮指令任务。
json
{
"instruction": "用户指令(如"打开客厅空调")",
"input": "额外输入(可选,如设备状态)",
"output": "JSON格式响应(含mcp_type、function、params字段)"
}💡提示
● 由于多轮对话复杂,超出本任务需求,故排除 ShareGPT 格式。
②在"output"中补全缺失的字段"function"。
进入"SmartHome"文件夹,新建终端,激活 Python 环境 smarthome-lightllm-caht ,在命令行输入以下指令运行脚本,完成数据集的"funcion"字段补全。
bash
python3 code/function_fixed.py \
-i dataset/smart_home.json \
-o dataset/training_data_output.json \
-r dataset/missing_function_report.csv
💡提示
● python3 后要写:脚本文件的路径
-i 后写:待处理数据集的路径
-o 后写:处理后的数据集存储路径
-r 后写:输出的处理报告的存储路径
用户需要把相应的路径替换成自己的真实路径。
● 补全function的思路为:
读取文件中 "instruction","input","output" 的样本,解析 output 里的 JSON 字符串;如果缺少 "function" 字段,就根据 instruction 文本 + device_id 前缀 + params 里的键自动补全一个合适的函数名(如 set_light_settings、set_humidifier_settings 等),然后把修改后的对象再写回到 output。
2.定义条件触发与自动化联动逻辑
这是这是智能家居实现"无感智能"的核心。我们不仅教会模型理解"如果...就..."的简单条件,更灌输了设备自主感知环境并协同联动的复杂场景逻辑。
● 核心理念升级:触发条件并非仅来自用户指令,更多源于设备自身对环境的持续监测(如传感器检测到PM2.5超标、摄像头识别到家人回家、时钟到达预设时间)。模型的任务是理解这些"环境事件",并规划出正确的设备联动响应。
● 场景化规则制定:
○ 环境自适应:例如,"trigger": {"pm25": {">": 75}} 对应 "action" 为 "打开新风系统", "关闭空调内循环"。这模拟了空气净化设备基于空气质量自主决策的互动。
○ 节能与舒适联动:例如,"trigger": {"ac_status": "on"} 可触发 "action" "关闭窗户", "检查室内CO2浓度",体现了空调开启后,智能空间自动维持密闭环境并监控空气健康度的逻辑。
○ 链式场景触发:一个触发条件可启动一连串设备动作。例如,"trigger": {"time": "22:00", "motion_bedroom": "no_motion_30min"} 可触发完整的"睡眠模式":关闭主灯、调暗夜灯、调节空调至睡眠温度、启动助眠白噪音。
3.解决条件判断失效问题
针对条件判断失效的问题,使用以下规则改写。累计修改样本1,510 条。
①命中"instruction"中"条件+动作"的指令(如果/若/当/當/的话/的話/分钟后/分鐘後/小时后/小時後):
json
"mcp_type": "sensor_trigger",
"function": "create_automation",
"params": {
"trigger": { ... },
"action": { "device_id": "<原始device_id>", "arg": "<来自power/turn_on|turn_off>" }
}②相对时间(如"一小时/一小時/半小时/半小時/五分鐘/十分钟/...后"):
sql
trigger 写成:{"time_after": "NhNmNs"},并支持中文数字转换,
例:
一小时/一小時 → "1h"
半小时/半小時 → "30m"
五分钟/五分鐘 → "5m"
十分钟/十分鐘 → "10m"③绝对时间(如"十点三十分/10:30/十點半/十點十分"):
css
trigger 写成:{"time": "HH:MM"}(24小时制标准化)④比较条件(温度/湿度/PM2.5/CO₂/电量等 + 大于/小于/≥/≤/...):
json
"trigger": {
"temperature" | "humidity" | "pm25" | "co2" | "battery": { "operator": ">/</>=/<=", "value": <数值> }
}4.解决链式操作失效问题
命中"instruction"中连续操作的指令(如:"先...后.../并且/...然后"等),将"output"的"params"统一为:
json
"params":{
"trigger":{ }, 没有触发条件,"trigger"为空。
"action": [{"device_id": " ", "command": "", "arg":{ }}, {"device_id": "", "command":" ", "arg":{ }}]}5.解决模糊指令操作失效问题
命中"instruction"中表达模糊的指令(如:"调低一点" "加强" "调弱" "小一点"等),将"output"的"params"统一为:
json
"params":{
"trigger":{ }, 没有触发条件,"trigger"为空。
"action": {"device_id": " ", "command": "", "arg":{ }}}
其中:"arg" 参数,使其体现出明确的控制如:改成自动模式,或者 加参数"delta"5.补充数据类型:复杂场景和异常指令
复杂场景------智能家居的复杂场景通常涉及多设备、多传感器、多协议的协同工作,结合用户行为、环境变化和个性化需求,提供智能化的生活体验。例如:
● 睡眠模式,涉及环境光传感器、智能窗帘、空调控制、音响系统等; "instruction": "准备睡觉时,关闭所有灯光,调低卧室空调温度,播放助眠音乐。"
● 老人/儿童看护模式,涉及运动传感器、摄像头、语音助手等。 "instruction": "监测老人的活动,若超过30分钟未检测到移动,发送提醒。"
异常指令------指令由于格式不正确、设备不支持、指令不明确等原因导致执行失败。我们希望在实际应用中,系统应能够识别这些错误指令,并提供相应的错误信息和建议。 例如:
python
{
"instruction": "今天天气怎么样",
"input": "",
"output": "{"error": "NOT_A_CONTROL_COMMAND", "message": "这是天气查询,不是设备控制", "suggestion": "请使用天气应用查询"}"
},经过上述处理步骤,我们将 12,000+ 条原始数据精简优化为 9,352 条高质量数据,涵盖基础控制、条件判断、链式操作、复杂场景和异常指令等场景。实验证明,数据质量 > 数据数量,精准修复比盲目增广有效得多。
模型选型:4B模型如何战胜7B选手?
智能家居交互要求轻量级、快响应、高精度的大模型,来适配边缘设备。面对众多模型,我们设定了严苛的选型标准:参数量适中、指令跟随能力强、结构化输出精准。
候选池中有三大模型:
● Llama-2-7B-Chat:名声在外,但7B参数对边缘设备不够友好
● SmolLM2-1.7B-Instruct:足够轻量,但能力捉襟见肘
● Qwen3-4B-Instruct:折中之选,但实力未知
我们需要对比它们在智能家居控制任务上的表现。核心评判指标为:
● Schema通过率:生成的JSON格式是否规范、字段是否齐全
● Slot-F1值:设备ID、档位、时间等关键参数抽取是否准确
● 推理延迟:单次响应速度
1.验证集准备。本实践选择Smart Home Command Dataset(🔗huggingface.co/datasets/yo...
2.vLLM 批量验证。使用 vLLM 对大语言模型(Llama-2-7B-Chat,Qwen3-0.6B-Base,Qwen3-4B-Instruct)进行批量验证,并对比它们在智能家居控制任务上的表现。新建终端,逐条执行以下命令。
bash
cd /workspace/SmartHome/code
conda activate smarthome-lightllm-chat
python select_1.py运行完后的结果如下图所示:

💡提示
● 脚本select_1.py中的数据读取路径要修改为您当前的验证集保存路径。
● 若运行过程中报错"缺少某个module",运行指令 pip install {module的名字}
该验证脚本的主要思路如下所示:
● 使用 vLLM 库对每个模型执行批量推理,从验证数据集中逐条输入指令,获得模型生成的结构化 JSON 输出。
● 校验JSON输出结构的合法性。
● 使用 JSON Schema 自动验证格式。自定义一个 JSON Schema,并利用 Python 的 jsonschema 库对每条输出进行校验。
● 输出与期望结果对比。 将模型生成的具体内容与验证集中每条样本的 expected_events 期望结果进行对比,以评估模型在内容层面的准确性。每条样本的 expected_events 列出该指令正确的执行动作列表(每个包含应执行的动作类型、设备ID、参数等)。
最终,三个模型对比结果如下表所示:
| 候选模型 | 参数规模 | Schema通过率 | Slot-F1 | 推理延迟 | 微调显存占用 | 边缘部署友好度 |
|---|---|---|---|---|---|---|
| Qwen3-4B-Instruct | 4B | 96% | 0.675 | 413.1ms | 12.4GB | ⭐⭐⭐⭐⭐ |
| Llama-2-7B-Chat | 7B | 13.7% | 0.095 | 538.3ms | 20GB | ⭐⭐ |
| SmolLM2-1.7B-Instruct | 1.7B | 0% | 0.016 | 220.1ms | 5.1GB | ⭐⭐⭐⭐ |
结果令人意外:4B的 Qwen3 在参数规模、推理延迟等方面不仅大幅领先7B的 Llama2,其 96% 的Schema通过率意味着它几乎能"一次成型"输出标准指令格式。这说明,模型能力不只看参数量,指令微调潜力同样关键。因此,Qwen3-4B-Instruct 被选定为本次微调的基模型。
科学调优:找到学习效率的"黄金参数"
有了好学生和好教材,还需要科学的"教学方法"。我们针对LoRA微调中的三个关键参数展开实验:
实验设计:3因素×3水平,共27组参数组合对比
● LoRA rank:16、32、64(控制模型微调容量)
● 学习率:1e-5、3e-5、5e-5(控制学习速度)
● Batch size:2、4、8(控制单步学习样本量)
我们跟踪每组参数训练的损失曲线和最终"高级功能通过率"(条件+链式指令),筛选最优组合:
| 实验组 | LoRA rank | 学习率 | Batch Size | 高级功能通过率 | loss后期波动幅度(训练稳定性) |
|---|---|---|---|---|---|
| exp1 | 16 | 1e-5 | 2 | 55.6% | 0.068(波动较大) |
| exp8 | 32 | 3e-5 | 4 | 55.6% | 0.055(稳定收敛) |
| exp15 | 32 | 5e-5 | 4 | 44.4% | 0.05(后期过拟合) |
| exp22 | 64 | 3e-5 | 4 | 44.4% | 0.05(后期过拟合) |
💡提示
● 测试完一个实验模型的通过率后,要起另一个服务测试下一个模型时,需要关闭当前进程(可以直接关机,重新启动实例)。
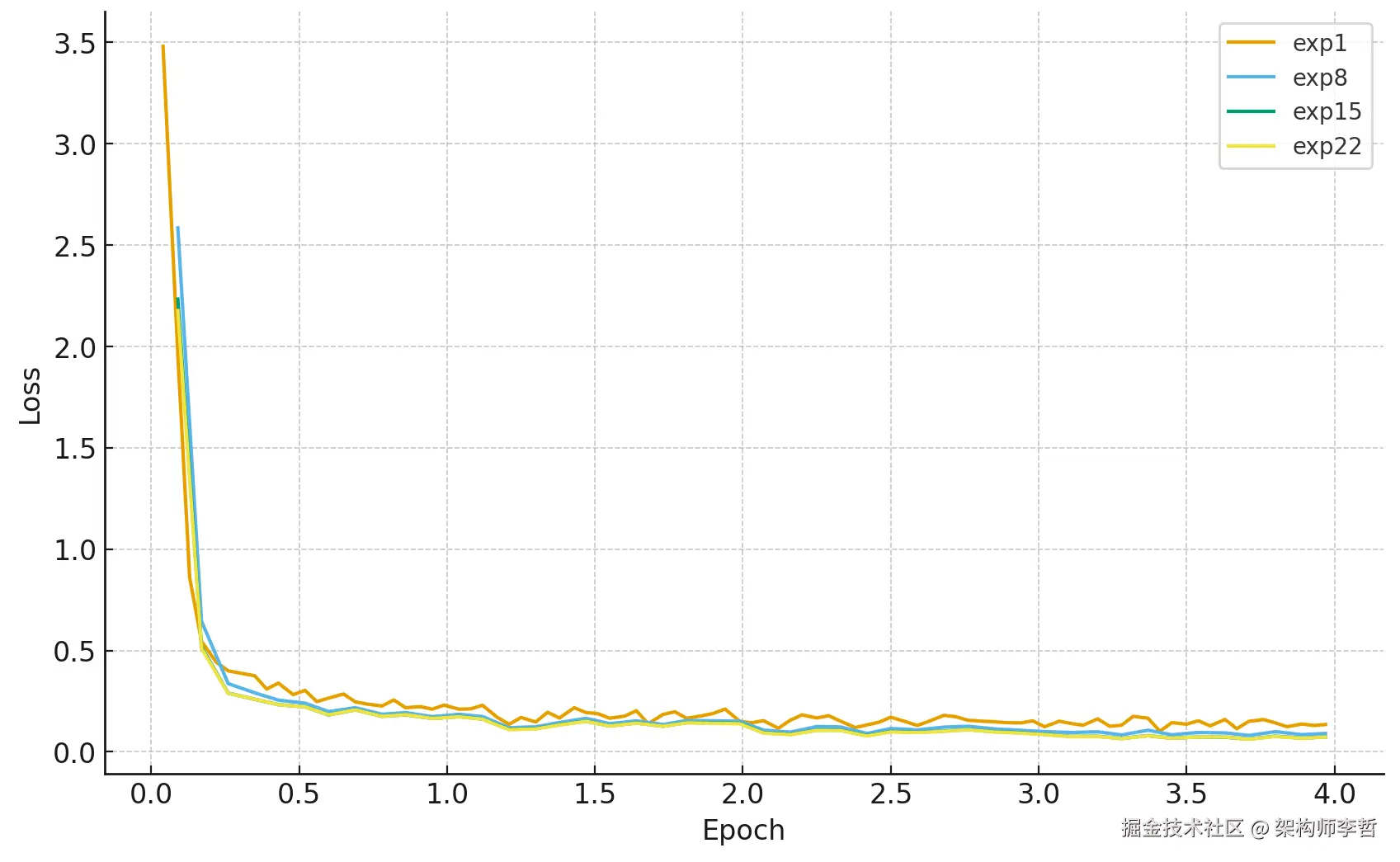
参数选择不是"越大越好",而是要在效果、速度和成本间找到精妙平衡。最终,我们锁定了这套"黄金参数":
| 参数项 | 设定值 | 关键解读 |
|---|---|---|
| LoRA Rank | 32 | 性价比最优解。Rank=64 虽能提升1%准确率,但显存占用激增2GB(从 16GB→18GB),不符合 "边缘设备轻量化" 目标。 |
| Learning Rate | 3e-5 | 1e-5 收敛太慢(4 epoch 未达最优),5e-5 容易震荡。3e-5 配合 Cosine 调度器最为稳定。 |
| Batch Size | 4 | 配合梯度累积(Gradient Accumulation Steps=4),有效批次大小为16,稳定训练。 |
| Epochs | 4 | 经验表明,3轮欠拟合,5轮过拟合,4轮为最优平衡点。 |
平台实战:三步完成从训练到部署
基于选定的 Qwen3-4B-Instruct 模型和调优后的参数,我们在 LLaMA-Factory Online 平台上的操作变得异常简单:
第一步:配置训练任务
选择基础模型和数据集,进行参数配置:
● 基础模型:平台内置的 Qwen3-4B-Instruct
● 数据集:处理好的 smart_home_fixed.json
● 关键参数:LoRA rank=32,学习率=3e-5,epoch=4,Batch Size=4
● 训练资源:1张 H800(约2.5小时完成训练)
| 参数 | 取值 | 选择依据 |
|---|---|---|
| lora参数 | ||
| lora_rank | 32 | 4B模型 + 中等任务复杂度,平衡性能与效率 |
| lora_alpha | 64 | 经验值:2×lora_rank,保证梯度更新幅度 |
| lora_dropout | 0.05 | 防止过拟合,适配中小样本量 |
| target_modul | q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj | 覆盖注意力层与 FFN 层,最大化微调效果 |
| bias | none | 减少参数数量,降低过拟合风险 |
| 训练参数配置 | ||
| num_train_epochs | 4 | 3 轮欠拟合、5 轮过拟合,4 轮为最优平衡点 |
| per_device_train_batch_size | 4 | 80GB 显存适配,避免 OOM |
| gradient_accumulation_steps | 4 | 有效批次 = 4×4=16,模拟大批次训练 |
| learning_rate | 3e-5 | 经 Grid Search 验证(1e-5 收敛慢、5e-5 震荡) |
| lr_scheduler_type | cosine | 余弦退火 + 0.1 warmup_ratio,稳定收敛 |
| weight_decay | 0.01 | 抑制过拟合,保护预训练权重 |
| fp16 | true | 节省 50% 显存,提速 30% |
| gradient_checkpointing | True | 再省 30% 显存,代价是训练时间增加 10% |
| evaluation_strategy | steps | 每 200 步评估,及时发现过拟合 |
| load_best_model_at_end | True | 保存最优模型,避免训练后期退化 |
第二步:模型评估验证
训练完成后,可在 LLaMA-Factory Online 上对模型进行全面评估,并查看评估任务的基本信息、日志及结果:
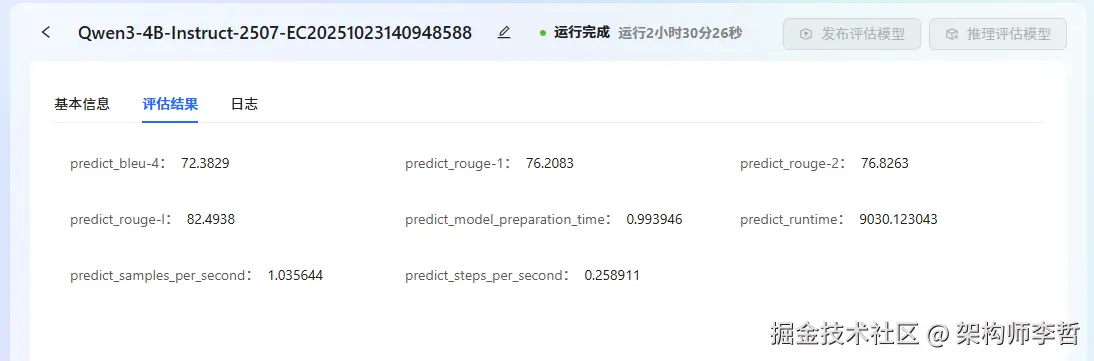
评估结果解读:
● predict_bleu-4: 72.3829,生成文本在短语层面与参考有良好重合,精确度较好。
● predict_rouge-1: 76.2083,关键词覆盖良好,模型能命中参考中的大量关键字。
● predict_rouge-2: 76.8263,局部短语连贯性较好,短语搭配合理。
● predict_rouge-l: 82.4938,整体段落结构很接近参考。
总结:模型生成质量较好(BLEU/ROUGE 都在 70~82 范围,尤其 ROUGE-L 表现很强),但推理吞吐/速度一般(samples/sec ≈1),适合以质量为主的离线或低并发在线场景;若用于高并发在线服务需进一步做推理优化。
第三步:一键对话测试
在"模型对话"界面选择微调后的模型,即可实时体验复杂指令解析:
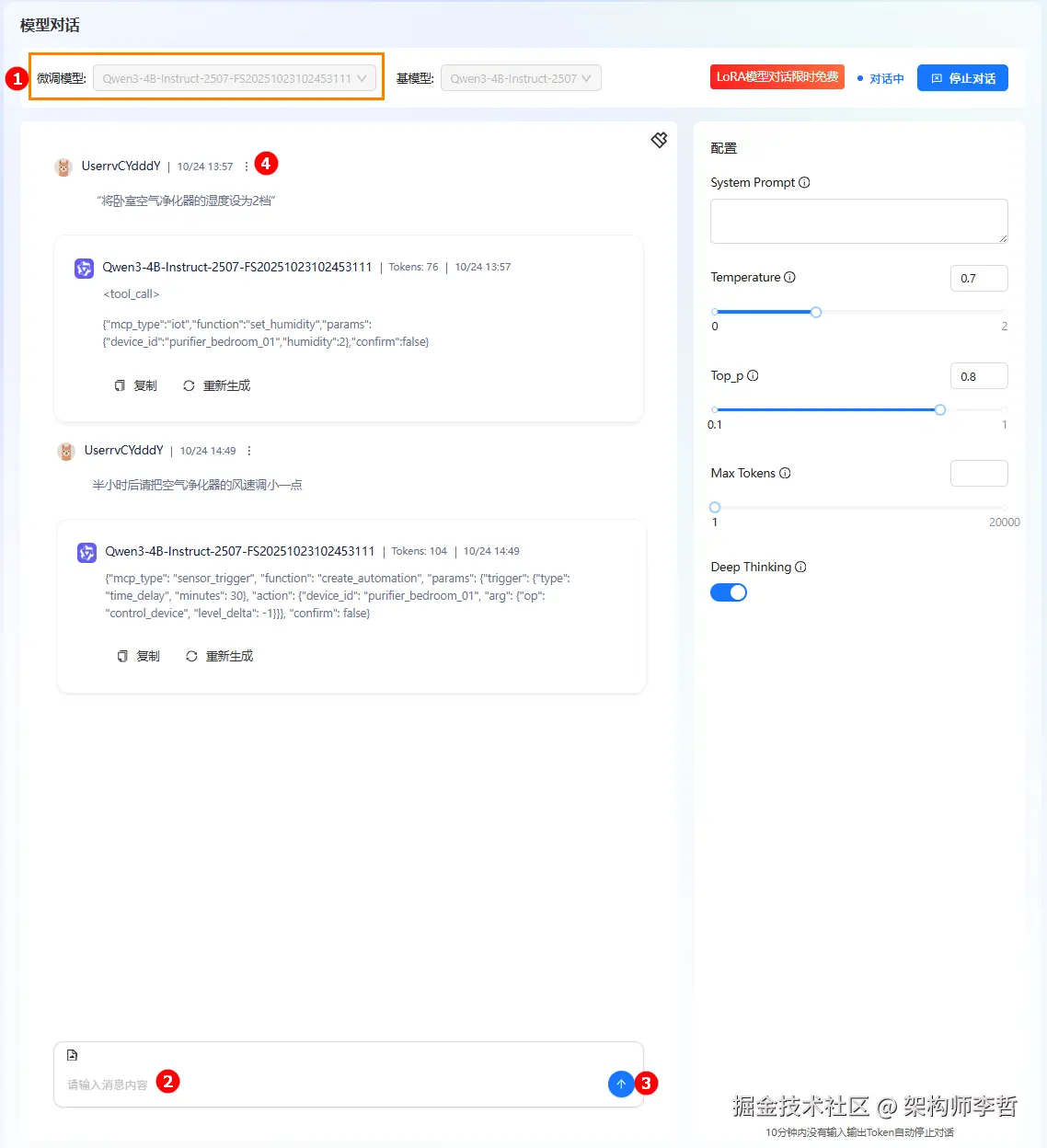
模型输出结果解读:
| 用户指令 | "将卧室空气净化器的湿度设为2档" | "半小时后请把空气净化器的风速调小一点" |
|---|---|---|
| 模型输出 | {"mcp_type": "iot","function": "set_humidity", "params": {"device_id": "purifier_bedroom_01", "humidity": 2}, "confirm": false} | {"mcp_type": "sensor_trigger", "function": "create_automation", "params": {"trigger": {"type":"time_delay", "minutes":30}, "action": {"device_id": "purifier_bedroom_01", "arg": {"op": "control_device", "level_delta":-1}}}, "confirm": false} |
| 指令解读 | mcp_type:IoT 控制消息function:设置湿度params:{设备ID,湿度挡位:2} | mcp_type:IoT 控制消息function:创建自动化风速控制params:{触发条件:30分钟后,动作:{给出设备ID,风速减小1。}} |
效果总结:从"大概理解"到"精准执行"
微调前后的差异,通过量化指标和典型场景对比一目了然:
场景一:条件触发性指令
用户指令:"半小时后请把空气净化器的风速调大到3档位"
微调前:模型仅将其识别为简单的风速设置("control_device", "level": 3),完全忽略了"半小时后"这一核心时间条件,导致指令被立即执行。❌
微调后:模型精准识别出"时间延迟触发"的意图,输出完整的自动化创建指令("sensor_trigger", "create_automation"),包含 "time_delay" 触发条件与具体动作,实现了真正的"条件执行"。✅场景二:链式操作型指令
csharp
用户指令:"当检测到漏水时,关闭水阀并发送通知"
微调前:模型仅输出一个紧急处理动作("handle_emergency", "emergency_stop"),遗漏了"发送通知"这一关键步骤,应对措施不完整。❌
微调后:模型正确解析出"传感器触发"与"多步骤动作"的复合结构,输出的 params 中包含完整的触发条件("water_leak_sensor_01": "leak")和一个有序动作列表(关闭水阀、发送通知),逻辑严谨。✅场景三:模糊型指令
csharp
用户指令:"三楼空调温度调小一点"
微调前:模型只能识别出设备(空调)和操作(设置温度),但在 params 中缺失具体的调整参数,无法执行。❌
微调后:模型准确理解了"调小一点"的相对性模糊表达,在参数中增加了 "delta": -1 字段,明确指示"在现有温度基础上降低1度",实现了符合用户预期的精准控制。✅可以看到,相较于基模型(Schema通过率<20%),微调后的模型在复杂指令解析上实现了质的飞跃。
| 测试类型 | 测试用例 | 通过率 |
|---|---|---|
| 基础功能 | 打开客厅灯、关闭卧室空调等5条 | 100% |
| 高级功能 | 如果卧室温度低于18度就开启暖气、离家模式等18条 | 88% |
总结:AI落地智能家居的三重突破
本次实践成功验证了一条高效构建垂直领域专用模型的技术路径,实现了三重突破:
● 轻量化突破:仅用4B参数模型,在边缘设备友好条件下,达到了接近甚至超越通用大模型的垂直场景精度。证明了"小模型+精调优"路径的可行性。
● 精准化突破:通过系统化的数据工程,让模型真正理解家居场景下的条件逻辑、时间概念和模糊表达,输出标准化、可执行的设备控制指令。
● 场景化突破:不仅覆盖基础控制,更深度适配了智能家居特有的条件触发、场景联动、异常处理等复杂需求,让AI真正融入家庭场景。
更重要的是,通过 LLaMA-Factory Online 平台,我们将原本需要数周的专业微调流程,压缩到了"几个小时+几次点击"的标准化操作。模型选型、数据准备、参数调优、训练评估的全流程,都可在可视化界面中完成。
智能家居的终极目标是"无感智能"------设备理解人的意图,而非人学习设备的操作。今天,我们通过大模型微调技术向这个目标迈出了坚实一步。当每个家庭都能拥有理解上下文、支持复杂指令的个性化AI管家时,真正的智能生活才刚刚开始。