在强化学习(RL)中,我们总是把策略函数写成 πθ(a∣s)\pi_\theta(a|s)πθ(a∣s)。
这短短的一个 θ\thetaθ,掩盖了无数的工程细节。
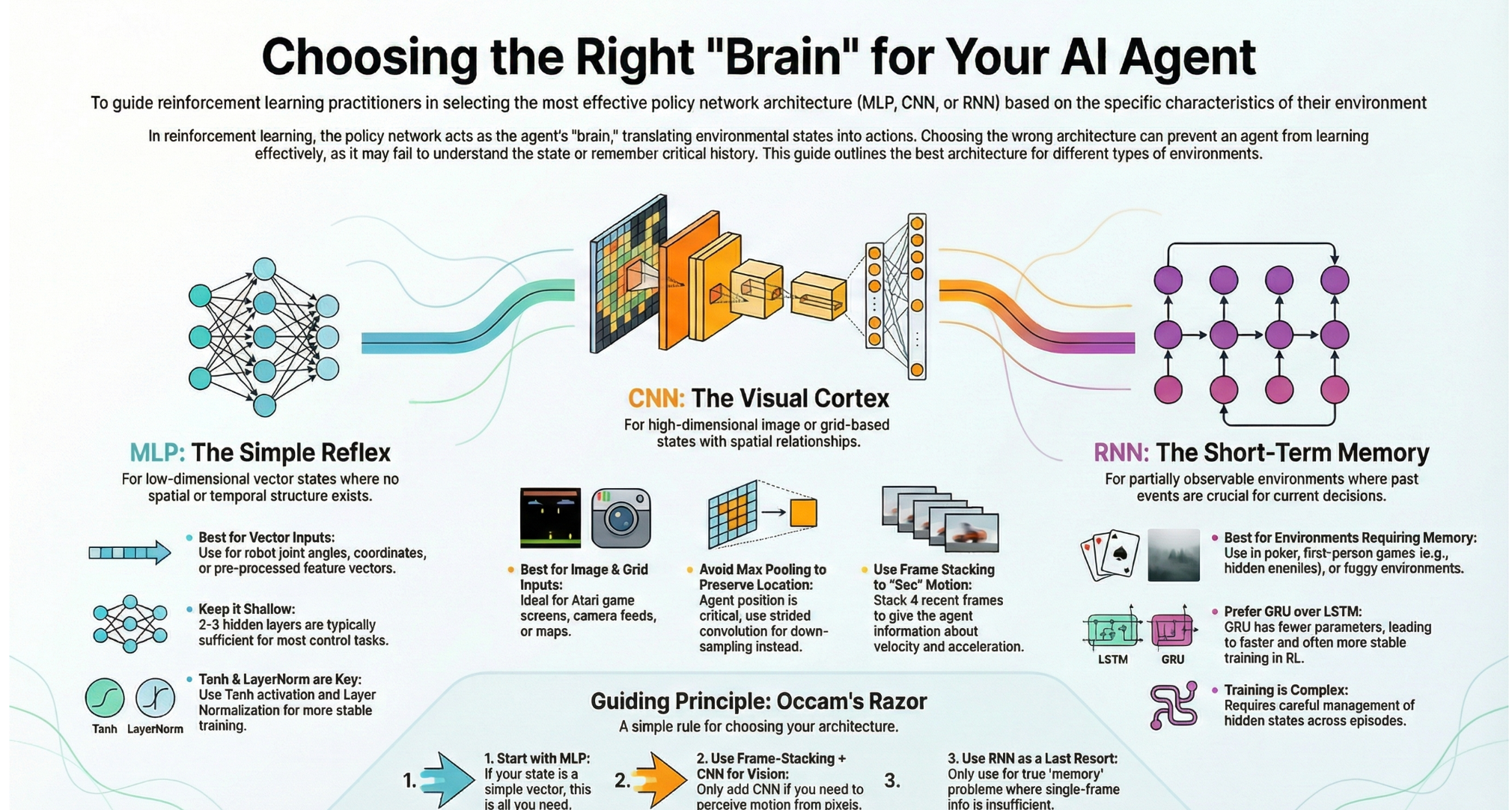
策略网络(Policy Network)的本质,是一个 特征提取器(Feature Extractor)加上一个决策头(Decision Head)。它的核心任务非常明确:
- 读懂环境 :从原始的状态 sss 中提取有用的信息。
- 做出决策 :将这些信息映射为动作 aaa 的概率分布。
你的 Agent 是天才还是弱智,很大程度上取决于你给它装了一个什么样的"大脑"。是简单的线性感知机?还是复杂的视觉皮层?亦或是拥有长短期记忆的海马体?
今天,我们来聊聊卷积(CNN)、全连接(MLP)和循环(RNN)在 RL 中的生存法则。
一、MLP(多层感知机):简单粗暴的"直觉反射"
1. 适用场景
- 状态(State):低维向量。例如:机器人的关节角度、速度、位置坐标、股票因子的数值。
- 特点:状态特征之间没有明显的空间结构或时间依赖。
2. 设计哲学
当你的输入已经是由物理引擎计算好的特征向量(Feature Vector)时,你不需要花哨的结构。MLP 是最稳健的选择。
设计要点:
- 不要太深 :不同于计算机视觉(CV)动辄上百层的 ResNet,RL 中的 MLP 通常很浅。2 到 3 层隐藏层(每层 64 到 256 个神经元)通常就足够解决 MuJoCo 或简单的控制任务。
- 激活函数 :
- ReLU:标准选择,但在 RL 中有时会导致"死神经元"问题。
- Tanh:在 PPO/TRPO 等连续控制策略中,Tanh 往往比 ReLU 表现更好。因为它是有界的(-1 到 1),且梯度更平滑。
- Layer Normalization:强烈建议加上。RL 的数据分布是非平稳的(Non-stationary),LayerNorm 能极大地稳定训练。
3. 代码直觉
python
# 一个标准的 MLP 策略网络骨架
class MLPPolicy(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, 64),
nn.Tanh(), # RL中 Tanh 常常优于 ReLU
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, action_dim)
)二、CNN(卷积神经网络):Agent 的"视觉皮层"
1. 适用场景
- 状态(State):高维图像、网格地图。例如:Atari 游戏画面、星际争霸的小地图、自动驾驶的摄像头输入。
- 特点 :输入具有空间局部相关性(Spatial Locality)。像素点 (0,0) 和 (0,1) 的关系比 (0,0) 和 (100,100) 的关系更紧密。
2. 设计哲学
如果把图像展平直接喂给 MLP,参数量会爆炸,且丢掉了空间信息。你需要 CNN 来提取特征。
RL 中的 CNN 与 CV 中的 CNN 有何不同?
- 慎用 Max Pooling(池化层) :
在图像分类(如猫狗识别)中,不管是左上角的猫还是右下角的猫,都是猫。这就是平移不变性 ,Pooling 对此很有帮助。
但在 RL 中,位置至关重要 !Pong 游戏中,球在左边你要往左跑,球在右边你要往右跑。Pooling 会丢失精确的位置信息。- 替代方案 :使用 Strided Convolution(步长卷积) 来降维,而不是 Pooling。
- Nature CNN 架构 :
DQN 论文中提出的经典架构至今仍是标杆:- Conv1: 32 filters, size 8x8, stride 4
- Conv2: 64 filters, size 4x4, stride 2
- Conv3: 64 filters, size 3x3, stride 1
- Flatten -> MLP Head
3. 帧堆叠(Frame Stacking)
一张静态图片无法告诉 Agent 速度 和加速度 。
如果只给一张 Pong 的截图,你不知道球是往左飞还是往右飞。
解决方案 :将最近的 4 帧图像叠加在一起,作为一个通道数为 4 的输入 (4,84,84)(4, 84, 84)(4,84,84)。这样 CNN 就能在通道维度上"看见"运动。
三、RNN/LSTM/GRU:解决"失忆症"
1. 适用场景
- 状态(State):部分可观测(POMDP)。例如:第一人称射击游戏(你看不到背后的敌人)、扑克牌(你需要记住对手之前的下注习惯)、即时战略游戏的迷雾。
- 特点 :当前的观测 oto_tot 不足以包含决策所需的所有信息,决策依赖于历史轨迹。
2. 设计哲学
当环境不仅是关于"现在",而是关于"过去"时,MLP 和 CNN 就失效了。你需要记忆。
GRU vs LSTM:
在 RL 中,GRU (Gated Recurrent Unit) 通常比 LSTM 更受欢迎。
- 参数更少:训练更快。
- 收敛更好:RL 的样本本来就噪声大,复杂的 LSTM 容易过拟合或难以训练。
训练难点:
RNN 在 RL 中的训练极其痛苦。
- 序列长度:你需要把一整段 Episode(或截断的一段)喂进去。
- 隐藏状态管理:在采样时,你需要维护每个 Environment 的 hidden state,并在 Episode 结束时重置它。
- R2D2 / DRQN:这些算法专门优化了带 RNN 的训练过程。
四、网络输出头(The Head):决策的出口
无论前面的骨干网络(Backbone)是 MLP、CNN 还是 RNN,最后都需要一个"头"来输出动作。
1. 离散动作空间 (Discrete)
- 比如:上、下、左、右。
- 输出:Linear 层输出维度 = 动作数量。
- 激活:Softmax(输出概率分布)。
- 采样:根据 Categorical 分布采样。
2. 连续动作空间 (Continuous)
- 比如:方向盘转动角度 (-1.0 到 1.0)。
- 输出 :通常输出两个向量:
- 均值 (Mu):经过 Tanh 激活,映射到动作范围。
- 标准差 (Log_Std):通常是独立的可学习参数,或者由网络输出(经过 Softplus 保证为正)。
- 采样 :构建高斯分布(Gaussian Distribution),从中采样,然后用
tanh压缩。
五、终极缝合怪:多模态架构
现代复杂的 RL 任务(如机器人管家)往往是多模态的。
- 眼睛:RGB 摄像头 (CNN)
- 身体:关节传感器 (MLP)
- 任务:自然语言指令 "去把蓝色的杯子拿来" (Transformer/Embedding)
设计思路:
- 分治(Divide):用 CNN 处理图像,用 MLP 处理传感器数据,用 Embedding 处理文本。
- 融合(Conquer):将它们提取出的特征向量(Embedding)拼接(Concatenate)在一起。
- 决策:将拼接后的向量喂给一个最终的 MLP 决策头。
Features=ConcatCNN(Image),MLP(Sensor) \text{Features} = \text{Concat} \\text{CNN}(\\text{Image}), \\text{MLP}(\\text{Sensor}) Features=ConcatCNN(Image),MLP(Sensor)
π(a∣s)=MLPHead(Features) \pi(a|s) = \text{MLP}_{\text{Head}}(\text{Features}) π(a∣s)=MLPHead(Features)
结语:没有最好的架构,只有最适合的
设计策略网络时,请遵循奥卡姆剃刀原则 :如无必要,勿增实体。
- 能用 MLP 解决的,绝不上 CNN。
- 能用 Frame Stacking 解决的(通过堆叠几帧感知速度),绝不上 RNN。
- 只有当环境完全无法通过单帧信息判断状态时(严重的 POMDP),才考虑 LSTM/GRU 或 Transformer。
RL 的训练本身已经极其不稳定了,不要让复杂的网络架构成为压死骆驼的最后一根稻草。简单,往往就是最强。
给读者的总结表
| 场景 | 推荐架构 | 关键技巧 |
|---|---|---|
| MuJoCo / 机器人关节控制 | MLP | 2-3层,Tanh 激活,LayerNorm |
| Atari / 像素游戏 | CNN | 慎用 Pooling,使用 stride 卷积,Frame Stacking |
| FPS / 迷雾环境 / 扑克 | CNN + GRU | 维护 Hidden State,处理变长序列 |
| 多模态输入 | Hybrid | 各自提取特征后 Concat,再过 MLP |
| 星际争霸 / Dota 2 | Transformer | Attention 机制处理海量单位实体 |