如果你在2025年关注过AI,你可能已经注意到,每个人都在谈论智能体。这是有充分理由的。AI智能体可以处理从简单的日常任务到企业级复杂的多智能体工作流程的所有事务。
而这仅仅是个开始。我们即将见证这个领域涌现更多创新。
如果您是初次来到这里,我是玛丽娜。我是亚马逊的高级应用科学家,专注于生成式AI领域,今天我将为您详细剖析关于构建和使用AI智能体所需了解的一切。
我对这个主题进行了深入研究。我参加了一系列不同的课程,阅读了相关书籍,并构建了自己的智能体。我的研究笔记最终长达约150页,而我已将所有这些内容提炼成一篇文章呈现给你。
以下是我们将如何进行拆解:
**首先,了解基础知识。**什么是AI智能体,其核心概念有哪些,以及你实际上可以在哪些地方使用它们?如果你想在不编写任何代码的情况下开始试验,我们还将介绍一些无代码选项。
**然后是中级水平。**我们将深入探讨构建和评估解决实际问题的多智能体系统。我将演示一个我开发的智能体系统,它目前每周能为我节省几个小时的工作时间。
**那么接下来。**在生产环境中构建可靠的智能体系统究竟需要什么?
最后,还有一个额外的章节,供那些想要深入了解Claude Code等工具实际底层工作原理的开发者参考。
无论你是一个只想自动化自己工作流程某些部分的非技术人员,还是正在为公司构建生产级AI系统,这篇文章都有适合你的内容。
让我们深入探讨。
初学者
什么是智能体?
好的,让我们从基础开始:究竟什么
是
AI 智能体?
这是最简单的思考方式。想象一下,你需要写一篇文章。如果你使用传统的大语言模型(LLM)提示,你基本上会说:"嘿,ChatGPT,给我写一篇关于如何开始健身的文章",然后它就会从头到尾一次性写完整个内容。
但这可不是你我实际写文章的方式,对吧?我们不会一下子就写出完美的初稿。我们会先规划、列提纲、做些研究,写出一份杂乱的初稿,然后反复阅读并修改。这是一个过程。
这就是能动AI的作用。与其要求AI在一次线中完成所有任务,不如让它像人类一样迭代工作。
按回车键或点击以查看全尺寸图像

那么这实际上是什么样子呢?
让我们继续以论文为例。以下是智能体处理该问题的方式:
首先,从大纲开始。在着手写作之前先理清结构。主要观点有哪些?怎样的顺序才合理?
然后它会确定需要从大纲中获取哪些信息,并实际获取这些信息。
它可能会搜索网络、从应用程序编程接口(API)获取数据、下载相关资源,然后利用这些信息撰写文章的初稿。
按回车键或点击以查看全尺寸图像
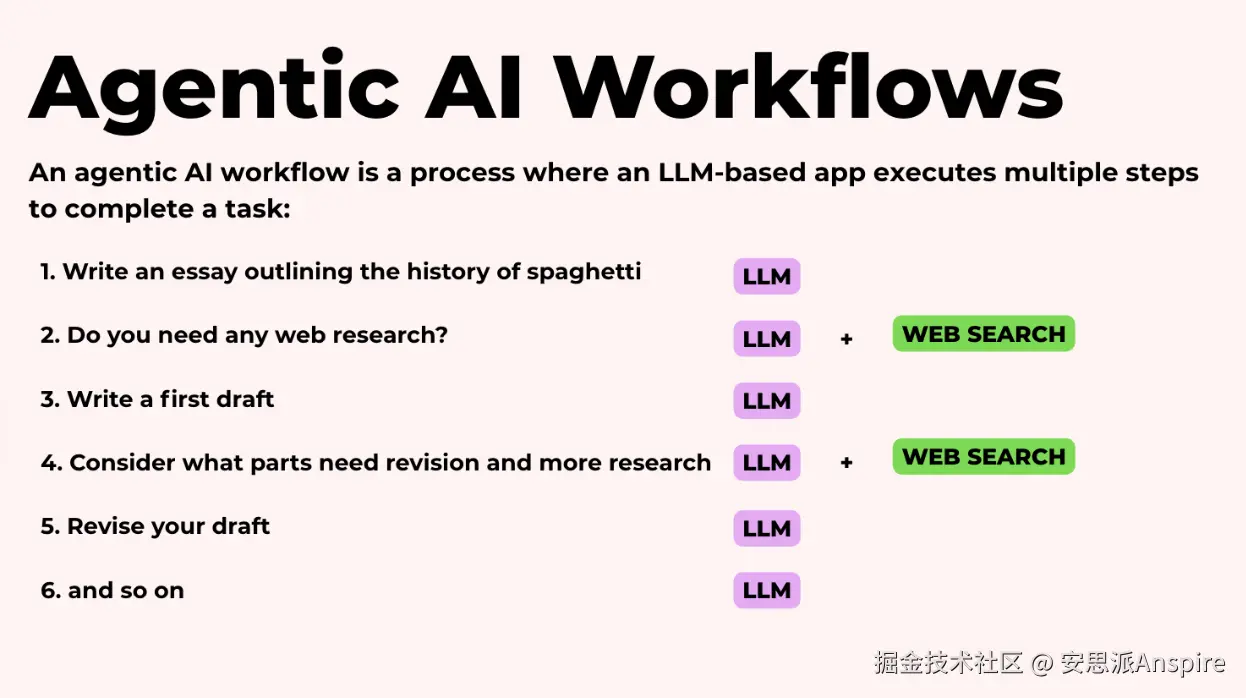
但巧妙之处在于,它并不止于此。智能体还会反思自己的工作,并进行修订,比如强化薄弱论点、补充缺失信息或优化行文流畅度。
这就是人们所说的ReAct循环。模型会思考下一步该做什么,然后采取行动(通常是调用一个工具,我们稍后会详细讨论),观察结果,然后要么给你一个答案,要么循环回去再次思考。
按回车键或点击以查看全尺寸图像
这种方法之所以有效,是因为每一轮处理都会增加深度。你会得到更强的推理能力、更少的幻觉,以及更好的组织性,而这些都是你试图一次性完成所有事情时会失去的东西。
这种方法在任何需要细致、准确工作并进行适当溯源的地方都能很好地发挥作用。你可以想想法律研究领域,在那里你需要引用具体案例;医疗保健文档领域;或者客户支持系统领域,在回复之前需要查询账户详情。
当然,额外的专业化和准确性会带来复杂性方面的成本。这就引出了一个显而易见的问题:究竟什么样的任务才值得专门构建智能体来完成?
智能体擅长处理哪些类型的任务?
有些任务对智能体有意义,而有些则没有。让我们来看一些例子,从最简单到最复杂。
一个真正简单的智能体系统示例可能是从发票中提取关键字段,然后将其保存到数据库中。像这样具有明确、可重复流程的任务非常适合智能体。
中等复杂程度的任务可能是回复客户电子邮件。座席会查询订单、查看客户记录,并起草回复内容供人工审核。
再上一个级别是成熟的客服代表,负责处理诸如"你们有蓝色牛仔裤库存吗?"或"我该如何退货?"之类的问题。对于退货,客服代表需要核实购买情况,查看政策,确认是否允许退货,然后逐步完成整个退货流程,而这个流程有很多步骤。客服代表必须弄清楚这些步骤是什么,而不仅仅是照本宣科。
思考哪些用例适合智能体的一个有用方法是使用一个有两个轴的矩阵:复杂性和精确性。
有些问题既复杂程度高,又需要高精度,比如填写纳税申报单。
其他任务虽然复杂,但不需要绝对的准确性。在这种情况下,你可以考虑做一些事情,比如撰写和检查课堂笔记的摘要。
按回车键或点击以查看全尺寸图像
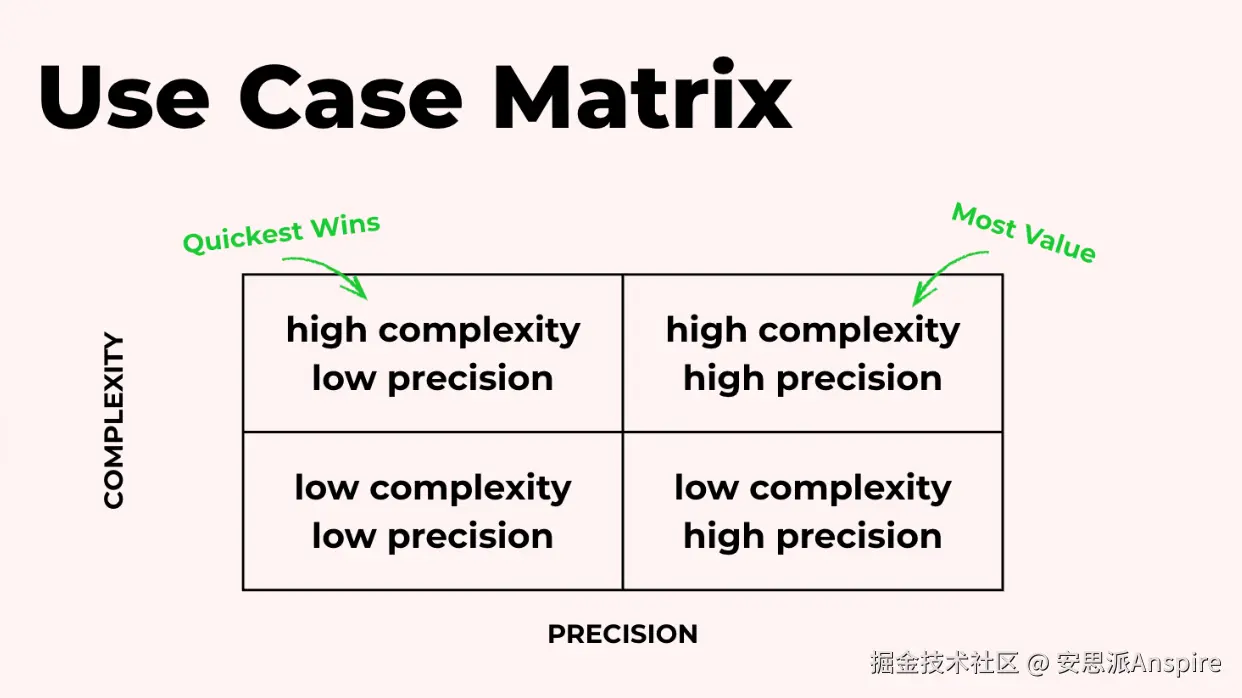
最大的价值往往来自高复杂度的工作,而最快的早期成果往往出现在低精度的方面。这就是为什么高复杂度、低精度的象限通常是明智的起点。你可以通过自动化处理棘手的事情获得助力,而不会每次都因需要完美的输出而受阻。
综上所述,当任务需要迭代、研究或多步骤流程时,智能体确实能大放异彩。从能够容忍稍低精度的复杂任务入手往往是明智之举。
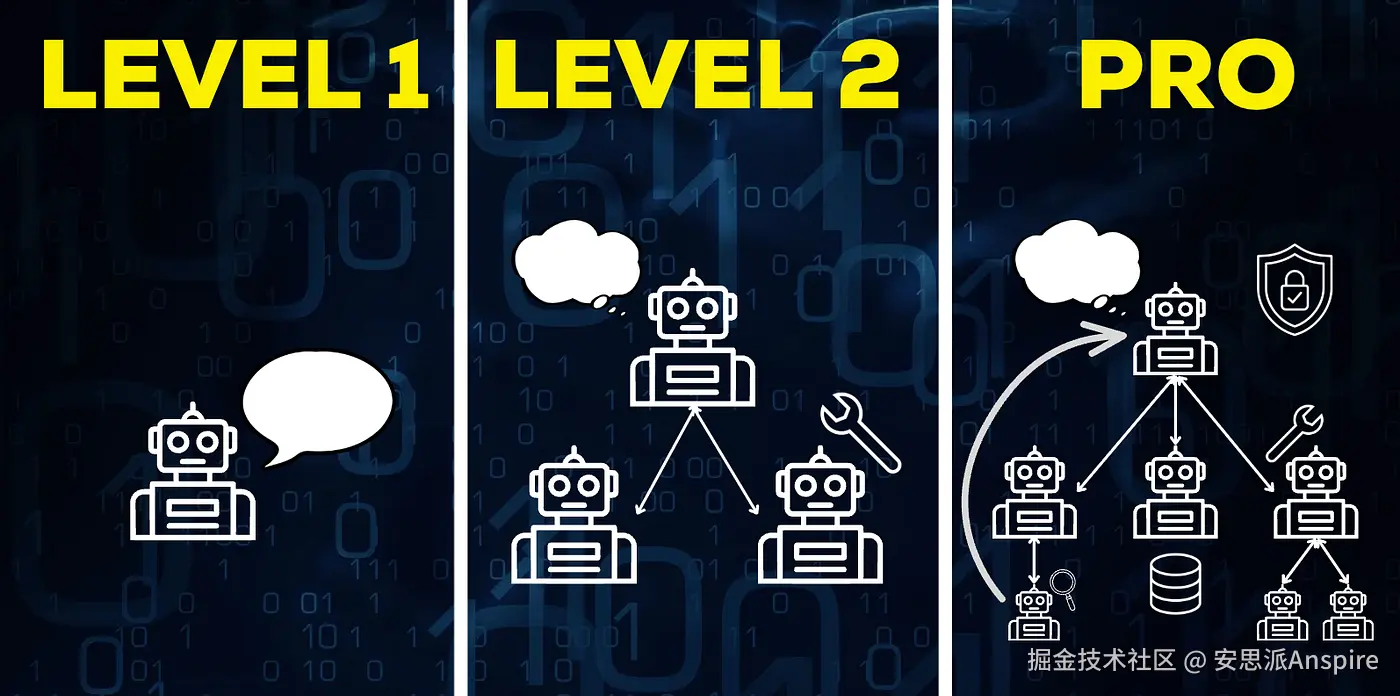
自主能力谱系
好了,既然你已经了解了智能体的用途,那我们就来谈谈如何实际构建它们。你需要做出的第一个重大决策是,你想赋予智能体多大的自主性?
把这想象成一个光谱。
按回车键或点击以查看全尺寸图像

一方面,你有脚本化的智能体,其中的每一步都是硬编码的。就拿我们写论文的例子来说,可能是先生成搜索词,调用网络搜索,抓取网页,然后撰写论文。完成。它是确定性的、可预测的,并且易于控制。模型唯一的工作就是生成实际文本,因为其他一切都由你决定。
在另一端,你有高度自主的智能体。现在,大语言模型(LLM)决定是否搜索谷歌、新闻网站或研究论文。它会确定要获取多少页面,是否转换PDF文件,以及是否进行反思和修正。它甚至可能编写新的函数并运行它们。这更强大,但也不可预测且更难控制。
实际上,大多数现实世界中的智能体处于中间状态,属于半自主智能体。智能体从你定义的工具中进行选择,并在你设定的规则范围内做出决策。
上下文工程
但是,智能体如何知道有哪些工具可用,或者如何做出决策呢?
这就是所谓的"上下文工程",即你决定代理拥有哪些信息。这包括任务背景、代理的角色、过去行动的记忆以及可用工具等内容。
如果将所有这些上下文信息整合在一起,这些信息会引导非确定性模型产生一致、高质量的输出。
按回车键或点击以查看全尺寸图像
这就是智能体中"智能"的实际基础。它不仅仅是模型,还在于你如何围绕它构建上下文。在整个课程中,我们将更多地讨论这些组成部分。
任务分解
一旦智能体有了其上下文,就该定义它应该执行的任务了。确定这些任务可以说是你在构建智能体方面要学习的最重要的事情。
从
你会
如何执行任务开始。然后针对每一步,问:"大语言模型能做这个吗?一小段代码能做吗?一个API能做吗?"如果答案是否定的,就把它拆分成更小的步骤,直到可以为止。
让我们继续以构建一个撰写论文的智能体为例。
思考一下你实际会如何写作,然后弄清楚AI可能会如何完成这项任务。它可能是这样的:
-
大纲使用大语言模型
-
使用大语言模型生成搜索词,然后调用搜索 API
-
使用工具获取页面
-
撰写初稿使用这些来源通过大语言模型(LLM)完成
-
自我批判使用大语言模型(LLM)对草稿进行反思并列出差距
-
并使用大语言模型(LLM)进行修订
每一步都很小、可核查且清晰。当输出结果不够好时,你确切地知道要改进哪一步。