一、高可用的HA
单点故障的问题是无法避免的问题,如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)-只能用于开发或测试环境。
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
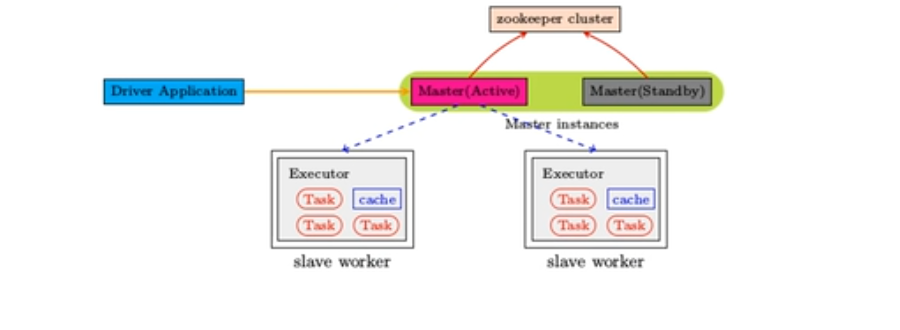
ZooKeeper提供了一个LeaderElection机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active
的,其他的都是Standby。当Active的Master出现故障时,另外的一个StandbyMaster会被选举出来。由于集群的信息
,包括Worker,Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新job的提交,对
于正在进行的job没有任何的影响。加入Zookeeper的集群整体架构如下图所示。
二、搭建步骤
2.1务必确保Zookeeper 和 HDFS 均已经启动!
【如果没有配置过zookeeper的同学可以看我的上一篇文章】
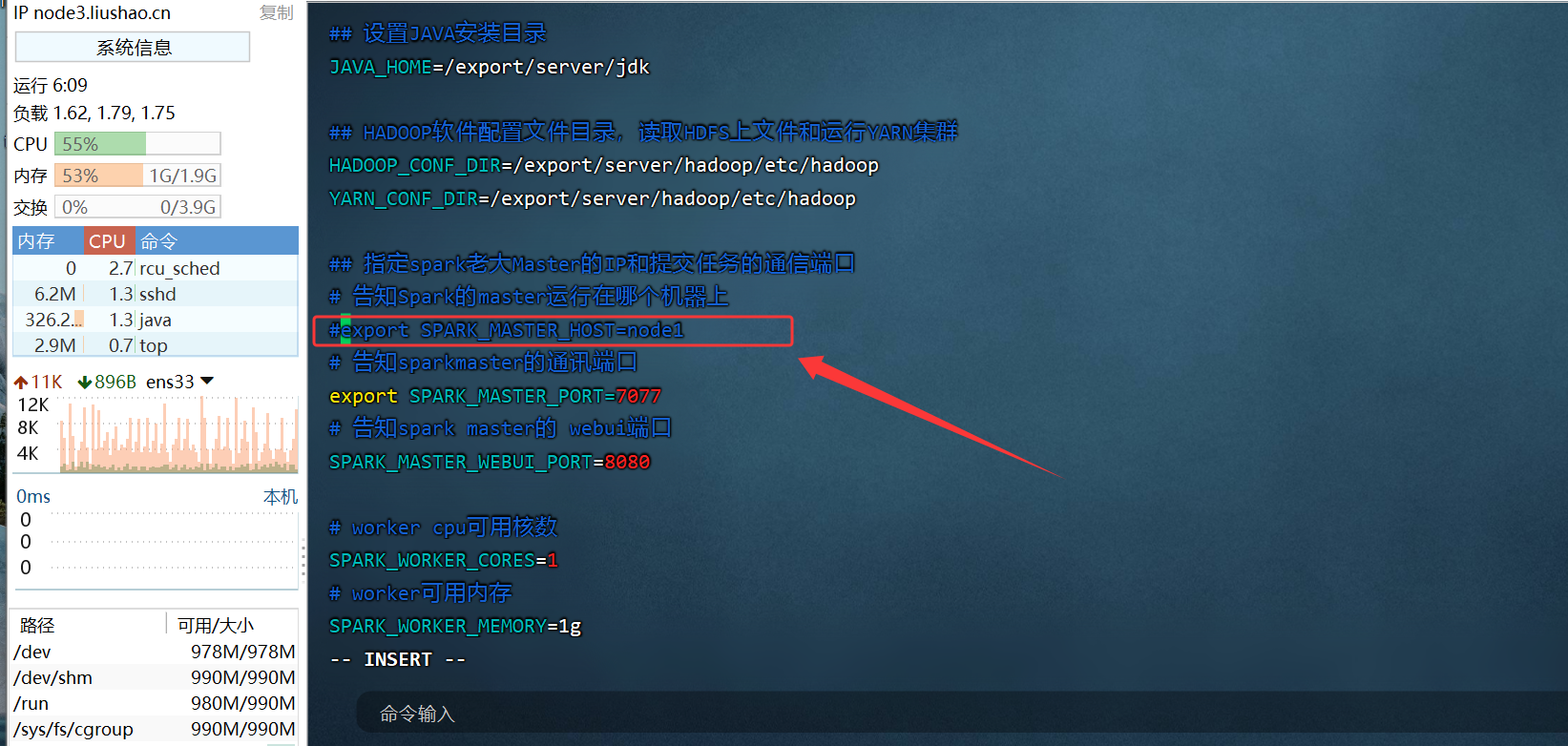
2.2先在spark-env.sh中, 删除: SPARK_MASTER_HOST=node1
原因: 配置文件中固定master是谁, 那么就无法用到zookeeper的动态切换master功能了.
2.3在spark-env.sh中, 在尾行增加下面的配置:
bash
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"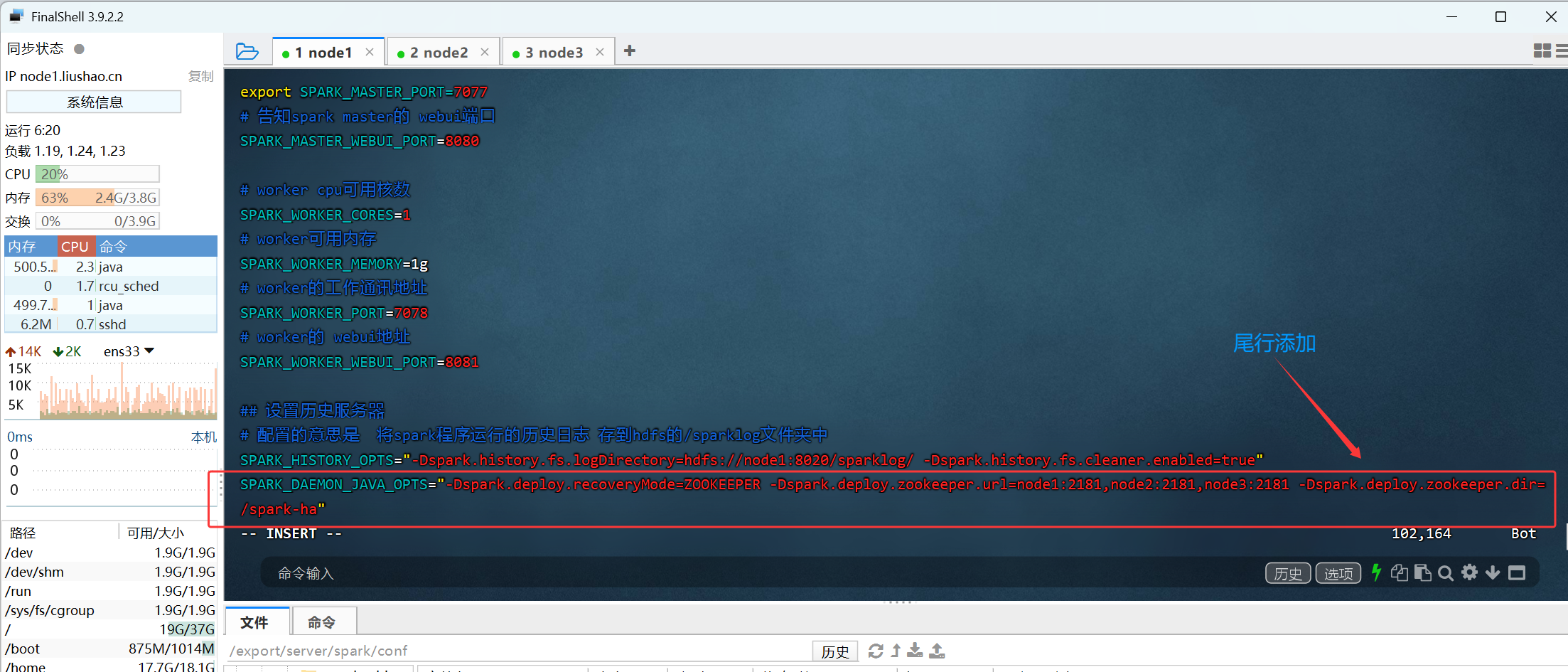
2.4将spark-env.sh 分发到每一台服务器上
bash
scp spark-env.sh node2:/export/server/spark/conf/
scp spark-env.sh node3:/export/server/spark/conf/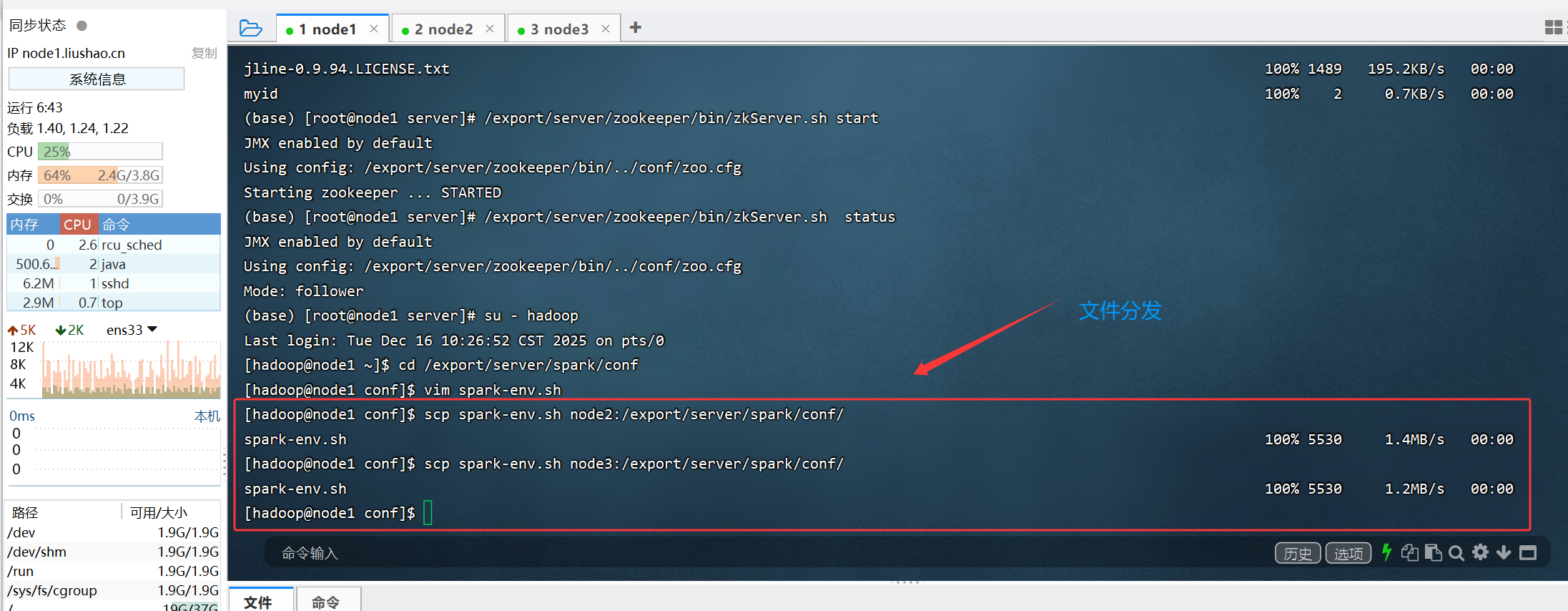
2.5先停止Standalone模式
bash
[hadoop@node1 conf]$ cd ..
[hadoop@node1 spark]$ sbin/stop-all.sh
node1: no org.apache.spark.deploy.worker.Worker to stop
node3: no org.apache.spark.deploy.worker.Worker to stop
node2: no org.apache.spark.deploy.worker.Worker to stop
no org.apache.spark.deploy.master.Master to stop
[hadoop@node1 spark]$ 2.6使用jps查看三个节点机器是否有Master和Worker
2.7在node1节点上启动Master 同时读取worker的配置去启动worker
bash
[hadoop@node1 spark]$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.liushao.cn.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node1.liushao.cn.out
node3: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.liushao.cn.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.liushao.cn.out
[hadoop@node1 spark]$ 2.8 在node2上启动备用的master
bash
[hadoop@node2 ~]$ cd /export/server/spark
[hadoop@node2 spark]$ sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node2.liushao.cn.out
[hadoop@node2 spark]$ 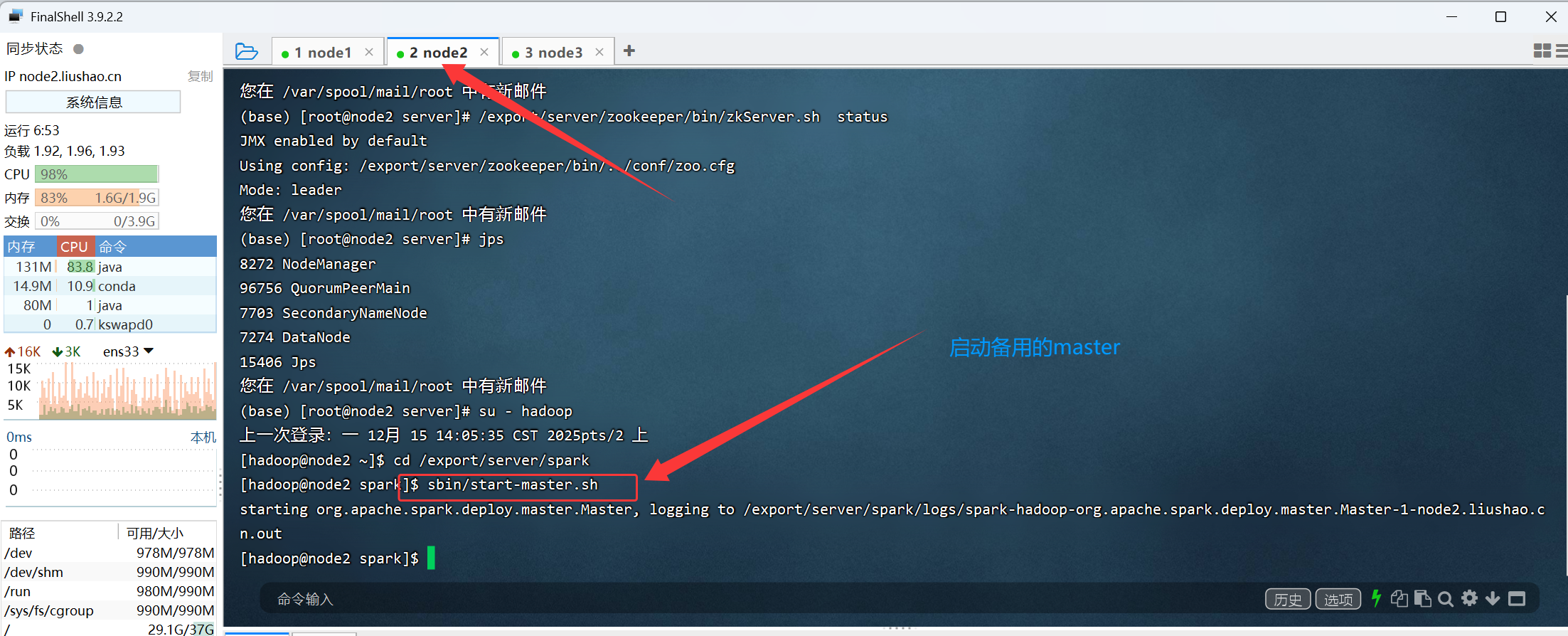
到此为止就启动了两个master节点 三个worker节点
切记使用jps查看启动进程