
前言
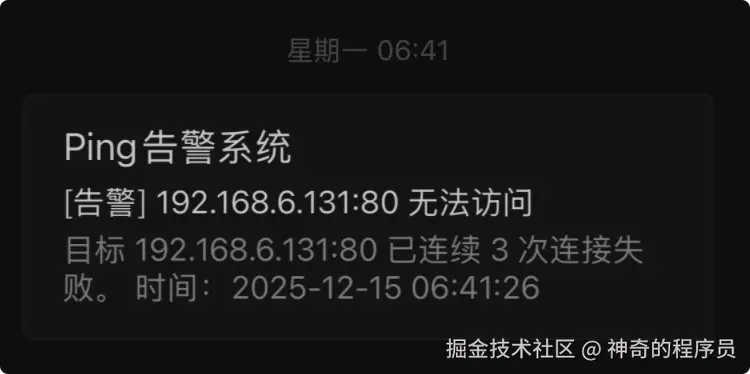
12月15号早上,一觉醒来,拿起手机看到我的邮箱收到了内网服务无法访问的告警邮件,本以为只是简单的服务卡死,将服务器重启后就去上班了。
后来,陆续有好友联系我说网站挂了。
定位问题
晚上下班回家后,尝试将电脑断电重启,发现pve只能存活2分钟左右,然后整个系统卡死,无法进行任何操作。首先,我想到的是:会不会某个vm虚拟机或者ct容器影响到宿主机了。
因为系统只能存活几分钟,在执行禁用操作的时候,强制重启了好几次服务器。当所有的服务都停止启动后,卡死的问题依旧存在。
翻日志
没辙了,这已经不是简单的软件问题了,只好翻日志,看报错信息了。
bash
nvme nvme0: I/O timeout, aborting如上所示,日志中出现了好几条I/O超时消息,顿感不妙,该不会硬盘坏了吧....
找到原因
找了一圈方案,大部分都说这个错误是nvme硬盘的通病,他有一个省电模式,在某些硬件+内核的组合下会导致控制器假死。
解决方案也很简单,找到GRUB的配置文件,关闭他的自动睡眠和省电模式,在pve中这个文件位于/etc/default/grub,打开这个文件后,找到GRUB_CMDLINE_LINUX_DEFAULT属性,添加两个值:
- nvme_core.default_ps_max_latency_us=0
- pcie_aspm=off
bash
GRUB_CMDLINE_LINUX_DEFAULT="quiet nvme_core.default_ps_max_latency_us=0 pcie_aspm=off"保存文件后,执行:update-grub 命令,随后重启整个pve主机。
VM无法启动
pve启动卡死的问题解决了,现在又有了新的问题。启动我那台跑了整个网站服务的vm虚拟机时,出现了如下所示的错误:
bash
mount: mounting /dev/sda3 /dev/sda3 on /sysroot failed: No error information
Mounting root failed.
initramfs emergency recovery shell launched.
这下坏事了,linux的根分区无法挂载了😭,应该是刚才频繁的卡死,我不断的启动pve,容器不停的启动、强制终止导致盘里这块区域的数据受损了,处于半死不活状态了。
从备份中还原
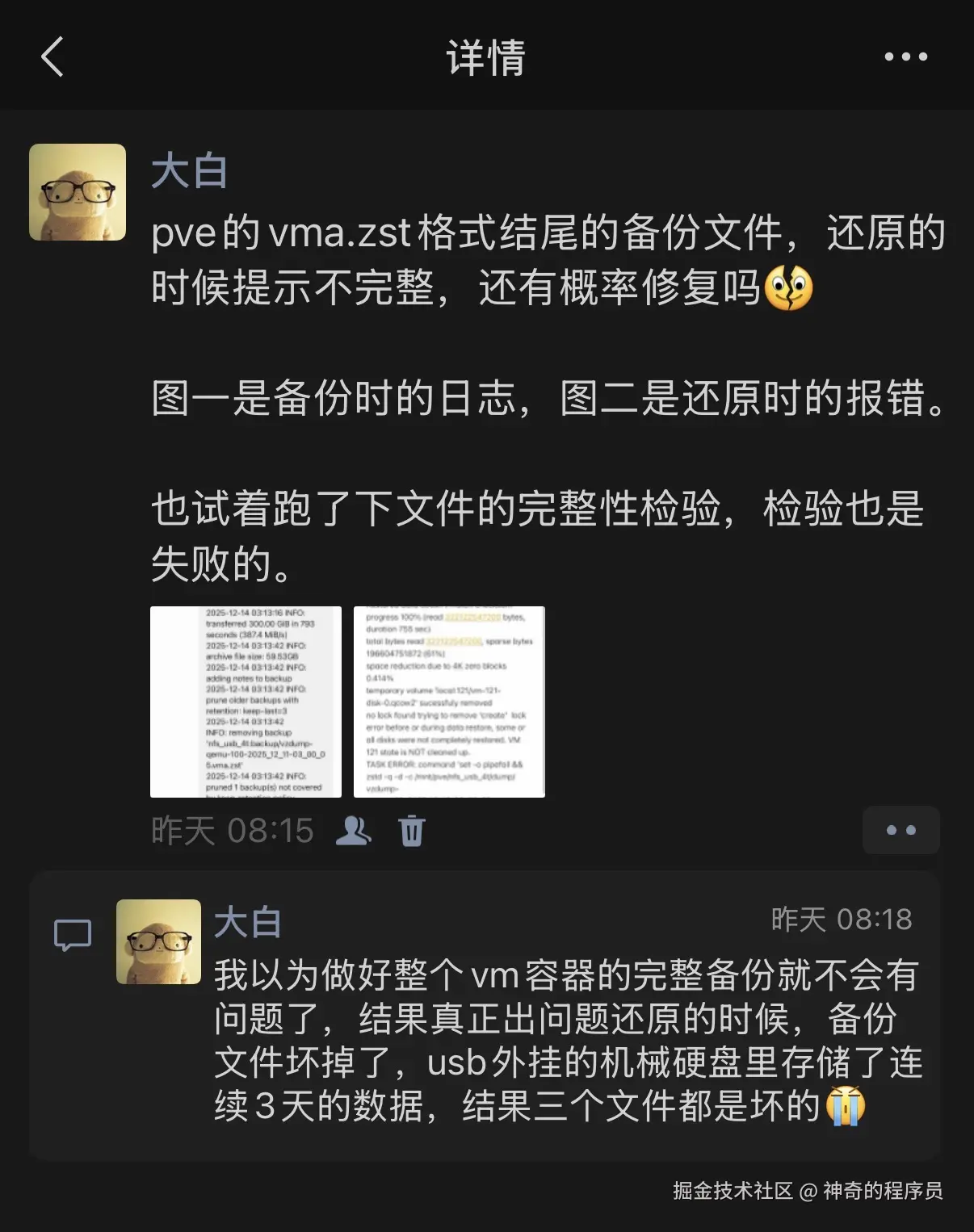
幸好我之前设置了vm容器的整机备份,连续备份并存储3天,全部放在了内网另一台机器的机械硬盘中,通过网络挂载到pve上的。

本以为一切都会很顺利,还原的时候出现了错误, zstd 解码时,发现压缩块损坏,导致还原失败。
bash
_15-03_00_03.vma.zst : Decoding error (36) : Corrupted block detected vma: restore failed - short vma extent (2801635 < 3801600) /bin/bash: line 1: 2131 Exit 1 zstd -q -d -c /mnt/pve/nfs_usb_4t/dump/vzdump-qemu-100-2025_12_15-03_00_03.vma.zst
于是,我又尝试了另外两个备份,结果都无法还原,全部都是相同的错误。当初做备份的时候,想着我都整机备份了,而且保存了3天的备份,总不可能三个全坏吧。
bash
progress 99% (read 318901321728 bytes, duration 722 sec)
_13-03_00_02.vma.zst : Decoding error (36) : Restored data doesn't match checksum progress 100% (read 322122547200 bytes, duration 755 sec) total bytes read 322122547200, sparse bytes 196604751872 (61%) space reduction due to 4K zero blocks 0.414% temporary volume 'local:121/vm-121-disk-0.qcow2' sucessfuly removed no lock found trying to remove 'create' lock error before or during data restore, some or all disks were not completely restored. VM 121 state is NOT cleaned up. TASK ERROR: command 'set -o pipefail && zstd -q -d -c /mnt/pve/nfs_usb_4t/dump/vzdump-qemu-100-2025_12_13-03_00_02.vma.zst | vma extract -v -r /var/tmp/vzdumptmp10764.fifo - /var/tmp/vzdumptmp10764' failed: exit code 1现在狠狠的打脸了,我手里目前只有2023年11月迁移技术栈时,那份docker compose的初始数据。相当于我丢失了2年的数据,这我是不能接受的。

折腾到这里,我一看时间,已经凌晨1:30了,明天还要上班,带着郁闷的心情去睡觉了。
强行提取数据
睡醒后,不愿接受这个现实,想到改造的那个练习英语单词的开源项目,这1年多时间下来,平均的日活跃人数已经有40多个了,数据库存储8w多条单词数据了😑,太难受了😭
实在是想不到什么好法子了,只好在v站和朋友圈都发了求助帖。
找到方案
在此,感谢v站老哥DylanC,给了我一组关键词。

晚上回家后,开始找资料,问GPT,经过一番折腾总算是把数据提取出来了。
跳过校验
从上述的错误日志中能看出,我在还原的时候已经读了99%的数据了,只是文件的完整性校验过不了,我的vm虚拟机里一整个全是docker compose编排的服务(mysql、redis、java、nginx等),理论上是比较好找回的。
pve的定时备份采用的是vzdump服务,备份出来的产物是.vma.zst格式的,他的本质是:
- zstd 压缩
- 内部是
vma归档 - 包含:
qemu-server.confdisk-drive-scsi0.raw
知道这些后,我们先把网络存储中的备份文件拷贝到pve主机的/var/lib/vz/dump目录,执行下述命令,忽略校验,强行解压。
bash
zstd -d -c --no-check vzdump-qemu-100-2025_12_13-03_00_02.vma.zst \
| vma extract -v - ./extract.partial等待一段时间后,程序执行结束,你会发现报错依然存在,但是这不影响已经读取的数据,cd到./extract.partial目录,你应该能看到xxx.conf和xxx.raw文件,然后看下.raw后缀文件的空间占用,只要不是太小(占用<1GB),那么这份数据基本是没问题的,磁盘的 RAW 文件也算是被解出来了。
挂载RAW磁盘
为了防止数据遭到破坏,我们需要做只读挂载,命令如下:
bash
losetup -fP /var/lib/vz/dump/extract.partial/disk-drive-scsi0.raw然后,执行命令查看结果。
bash
losetup -a
lsblk执行后,应该能看到类似loop0、loop0p1、loop0p2这样的数据,找到那块空间跟你在extract.partial目录下看到的空间差不多大小的盘。

挂载分区
首先,我们通过下述命令来创建一个挂载点:
bash
mkdir -p /mnt/rescue随后,尝试挂载分区(loop0p1、loop0p2....等),找你的根分区,如果你运气好,p1就挂载成功了,那就不需要挂载其他的了。
我的根分区是p3,那么我挂载p3即可。
bash
mount -o ro,norecovery /dev/loop0p3 /mnt/rescue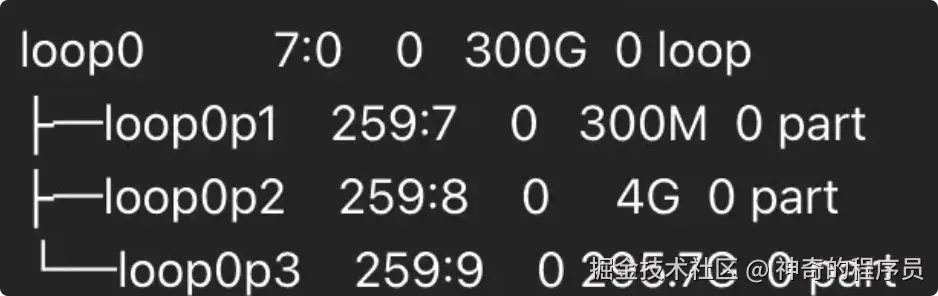
如果失败的话,代表它不是文件系统,需要继续尝试挂载其他分区,直到成功为止。
bash
umount /mnt/rescue 2>/dev/null
mount -o ro,norecovery /dev/loop0p2 /mnt/rescue最后,查看挂载点里是否有你的数据。
bash
ls /mnt/rescue不出意外的话,你应该能看到类似下图所示的内容。

文件成功恢复,接下来要做的就是把这些文件拷贝到安全的地方即可。
写在最后
至此,文章就分享完毕了。
我是神奇的程序员,一位前端开发工程师。
如果你对我感兴趣,请移步我的个人网站,进一步了解。