目录
[3.1.Milvus Lite](#3.1.Milvus Lite)
[3.2.Milvus Standalone](#3.2.Milvus Standalone)
[3.2.1.运行 Milvus](#3.2.1.运行 Milvus)
[3.2.2.Milvus Web UI](#3.2.2.Milvus Web UI)
[4.3.2.主键(primary key)](#4.3.2.主键(primary key))
1.Milvus--简介
Milvus 于 2019 年创建,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习 (ML) 模型生成的大量嵌入向量。它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
作为专门为处理输入向量查询而设计的数据库,它能够对万亿规模的向量进行索引。与现有的关系数据库主要处理遵循预定义模式的结构化数据不同,Milvus 是自下而上设计的,旨在处理从非结构化数据转换而来的嵌入向量。
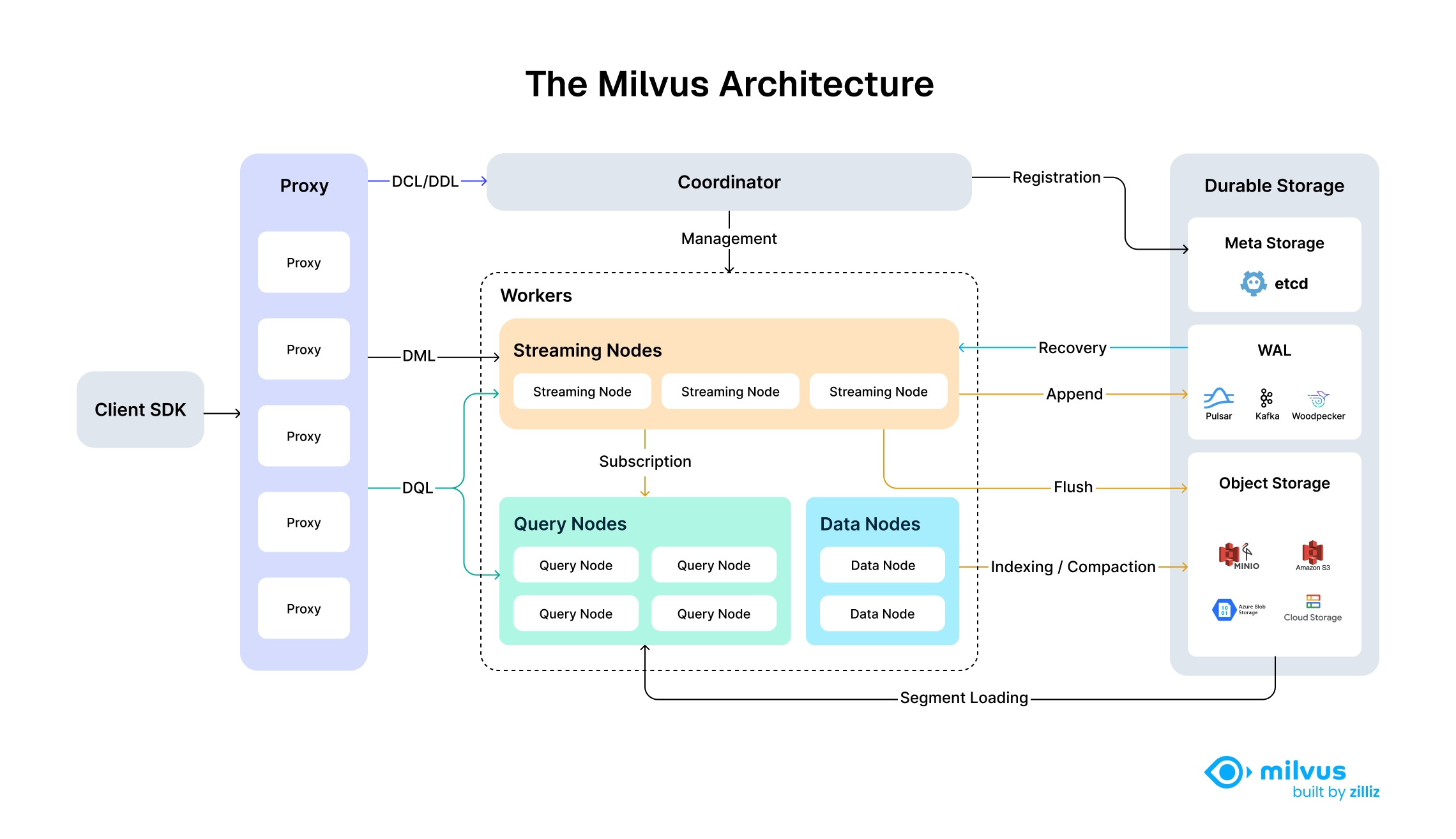
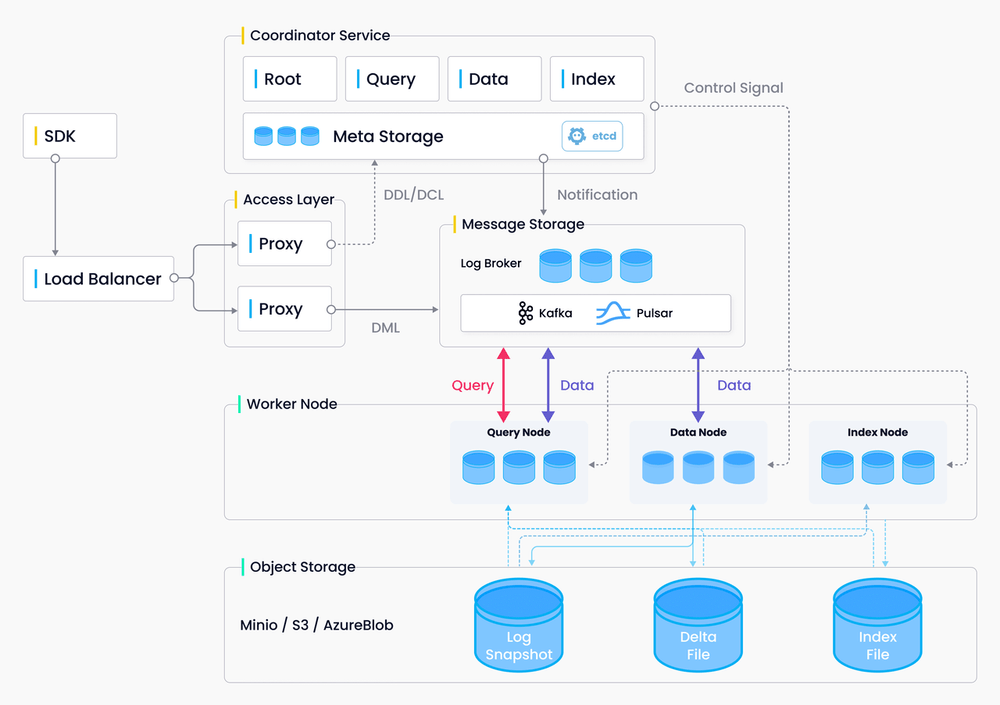
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。
免费版的好像可以创建一个数据库,且数据七天挂起(可恢复)
2.Milvus--架构
反正架构设计数据传输和数据库的设计和存储,比较复杂,看看就行了
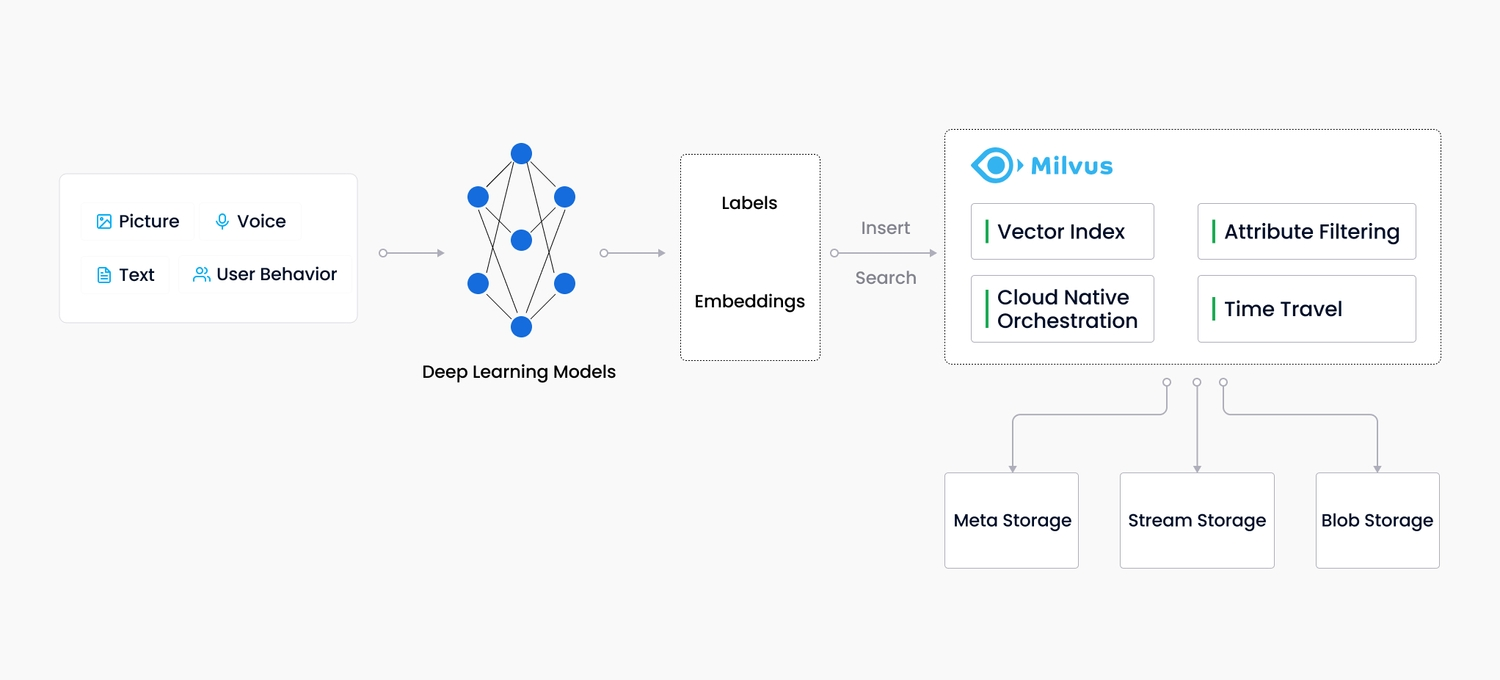
熟悉一下 Embeddings 检索的基本原理
| 类别 | 术语 | 简明定义与说明 |
|---|---|---|
| 核心概念 | Collections | 相当于关系数据库中的"表",用于存储和管理实体。 |
| 实体(Entity) | 行,由多个字段组成,代表现实世界对象;每个实体有唯一主键(可自定义或 AutoID)。 | |
| 字段(Field) | 列;支持标量字段(int, string)和向量字段(dense/sparse vector)。 | |
| 模式(Schema) | 定义 Collection 的结构,包括字段、主键是否自动递增(AutoID)、描述等。 | |
| 动态模式(Dynamic Schema) | 允许插入未在 Schema 中预定义的新字段,实现无 Schema 写入。 | |
| 向量(Vector) | 非结构化数据(图像、文本等)的嵌入表示;Milvus 2.4+ 支持密集向量和稀疏向量。 | |
| 非结构化数据 | 图像、视频、文本等无固定格式数据,通过 AI 模型转为向量存入 Milvus。 | |
| 主键与 ID | AutoID | 主键字段的属性,启用后由系统根据时间戳自动生成唯一 ID。 |
| 索引与搜索 | 索引(Index) | 为加速向量相似性搜索而构建的数据结构;支持多种类型(IVF, HNSW 等)。 |
| 自动索引 | Milvus 根据经验自动选择最优索引类型和参数,适合无需精细调参的场景。 | |
| 度量类型(Metric Type) | 定义向量相似度计算方式:L2(欧氏距离)、IP(内积)、COSINE(余弦)、二元等。 | |
| 搜索(Search) | 基于向量执行相似性搜索的 API。 | |
| 查询(Query) | 使用布尔表达式对标量字段进行过滤的 API。 | |
| 过滤搜索 | 向量搜索 + 标量条件过滤(如 category == "cat")。 |
|
| 混合搜索 | Milvus 2.4+ 支持对多个向量字段同时搜索并融合结果。 | |
| 范围搜索 | 查找与目标向量距离在指定范围内的结果。 | |
| 数据组织 | 分区(Partition) | 对 Collection 的逻辑划分,减少读取时扫描的数据量。 |
| 分区键(Partition Key) | 按字段值自动分片,使相同键值的数据落在同一分区,加速带该字段过滤的查询。 | |
| 碎片(Shard) | 基于主键哈希的物理分片,用于分散写入负载,提升写吞吐。 | |
| 分段(Segment) | 存储实体的数据文件;分为"成长段"(接收新数据)和"封存段"(只读,存对象存储)。 | |
| 流与日志 | 通道(Channel) | Milvus 流架构的核心单元,分 PChannel(物理)和 VChannel(虚拟)。 |
| PC 通道(PChannel) | 物理通道,对应 Woodpecker 管理的一个 WAL 流。 | |
| VChannel | 虚拟通道,对应一个 Collection 的一个分片(shard)。 | |
| 流服务(Stream Service) | 基于 WAL 构建,支持流式写入、故障恢复、数据订阅等。 | |
| 日志快照(Binlog) | 记录数据变更的二进制日志,分 Insert/Delete/DDL 三类。 | |
| WAL storage | 先写日志机制,确保数据持久性和一致性。 | |
| MemoryBuffer | Woodpecker 轻量模式,数据暂存内存后刷入对象存储,适合小规模批量写入。 | |
| QuorumBuffer | Woodpecker 高可用模式,三副本法定写入,适合低延迟、高可靠场景。 | |
| 性能与算法 | Knowhere | Milvus 向量执行引擎,集成 Faiss/Hnswlib/Annoy,支持 CPU/GPU 异构计算。 |
| Cardinal | Zilliz Cloud 开发的高性能向量搜索算法,比 Knowhere 快数倍至一个数量级,自适应多场景。 | |
| 工具与生态 | Attu | Milvus 官方一体化 Web 管理 UI,降低运维复杂度。 |
| Birdwatcher | 调试工具,连接 etcd 实时监控 Milvus 状态,支持 etcd 备份与故障排查。 | |
| PyMilvus | 官方 Python SDK,支持 ORM 和 MilvusClient 两种使用方式。 | |
| Milvus CLI | 命令行工具,基于 PyMilvus,支持交互式操作。 | |
| 批量编写工具(Bulk Writer) | SDK 提供的数据预处理工具,将原始数据转为 Milvus 兼容格式。 | |
| 批量插入(Bulk Insert) | API 支持单次请求导入多个文件,优化大数据集写入性能。 | |
| Kafka-Milvus 连接器 | 将 Kafka 流数据导入 Milvus 的 Sink Connector。 | |
| Spark-Milvus 连接器 | 实现 Apache Spark 与 Milvus 的无缝集成,结合 ML 与向量搜索。 | |
| Milvus 备份 | 数据备份工具,用于灾难恢复。 | |
| Milvus CDC | 变更数据捕获工具,同步源/目标 Milvus 实例的增量数据。 | |
| Milvus 迁移 | 开源工具,支持从其他数据源迁移到 Milvus 2.x。 | |
| 部署模式 | Milvus 单机版 | 所有组件运行于单进程,适合开发/测试。 |
| Milvus 集群 | 分布式部署,支持高可用、水平扩展。 | |
| 高级功能 | 嵌入(Embedding) | Milvus 内置支持调用嵌入模型(如 text2vec),简化向量化流程。 |
| 稀疏向量 | 大部分元素为零的向量(如 SPLADE),适用于关键词感知和可解释性场景。 | |
| 内存映射(MMap) | 将数据文件映射到内存,支持超大集合(但性能随超出内存而下降)。 | |
| 商业产品 | Zilliz Cloud | Milvus 的托管云服务,提供企业级功能、优化性能和全托管运维。 |
| 依赖组件 | 依赖程序 | Milvus 依赖 etcd(元数据)、MinIO/S3(对象存储)、Pulsar/Kafka(旧版日志)或 Woodpecker(新版 WAL)。 |
- Collection: 包含一组 Entity,可以理解为关系型数据库中的表。
- Entity: 包含一组 Field,可以理解为关系型数据库中的行。
- Field:可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。可以理解为关系型数据库中的字段。
- Partition:分区,针对 Collection 数据分区存储多个部分,每个分区又可以包含多个段。
- Segment:分段,一个 Partition 可以包含多个 Segment。一个 Segment 可以包含多个 Entity。在搜索时,会搜索每个 Segment 合并后返回结果。
- Sharding:分片,将数据分散到不同节点上,充分利用集群的并行计算能力进行写入,默认情况下,单个 Collection 包含 2 个分片。
- Index:索引,可以提高数据搜索的速度。但一个向量字段仅支持一种索引类型。
Milvus 架构的基本骨架
3.Milvus--安装
Milvus 是一个高性能、可扩展的向量数据库。它支持各种规模的用例,从在 Jupyter 笔记本中本地运行的演示到处理数百亿向量的大规模 Kubernetes 集群。
目前,Milvus 有三种部署选项:Milvus Lite、Milvus Standalone 和 Milvus Distributed。
| 特性 | Milvus Lite | Milvus Standalone(单机版) | Milvus Distributed(分布式版) |
|---|---|---|---|
| 本质 | 嵌入式 Python 库(SQLite 式) | 单机 Docker 容器服务 | Kubernetes 上的云原生分布式系统 |
| 安装方式 | pip install pymilvus 无需独立服务 | docker compose up 运行官方镜像 | Helm Chart 部署到 K8s 集群 |
| 数据持久化 | 本地文件(如 ./demo.db) |
本地磁盘或挂载卷 | 分布式对象存储(MinIO/S3) + etcd + 消息队列(Woodpecker/Pulsar) |
| API 兼容性 | ✅ 完全兼容 Milvus Client API | ✅ 与 Lite 和 Distributed API 一致 | ✅ 完全兼容 |
| 推荐最大规模 | 几百万向量(< 5M) | 约 1 亿向量(100M) | 1 亿 ~ 数百亿向量 |
| 硬件要求 | 极低(笔记本即可) | 中高(建议 32--128GB 内存 + SSD) | 高(多节点 K8s 集群,可弹性扩展) |
| 典型使用场景 | - Jupyter 快速原型 - RAG 演示 - 边缘设备本地搜索 - 教学/实验 | - MVP 产品验证 - 小规模生产(PMF 阶段) - 中小型 RAG 系统 - 内部工具 | - 大型企业生产系统 - 高并发向量搜索 - 百亿级知识库 - SLA 要求高的服务 |
| 是否支持迁移 | ✅ 可通过工具导出数据迁移到 Standalone | ✅ 可作为 Distributed 的开发/测试环境 | --- |
| 适用项目阶段 | 探索 / 原型阶段 | 早期生产 / PMF 验证阶段 | 规模化 / 成熟业务阶段 |
3.1.Milvus Lite
使用 Milvus Lite 在本地运行 Milvus。Milvus Lite 是Milvus 的轻量级版本,Milvus 是一个开源向量数据库,通过向量嵌入和相似性搜索为人工智能应用提供支持。
Milvus Lite 目前支持以下环境:
-
Ubuntu >= 20.04(x86_64 和 arm64)
-
MacOS >= 11.0(苹果硅 M1/M2 和 x86_64)
-
不支持windows
pip install pymilvus
pip install -U pymilvus[milvus-lite]
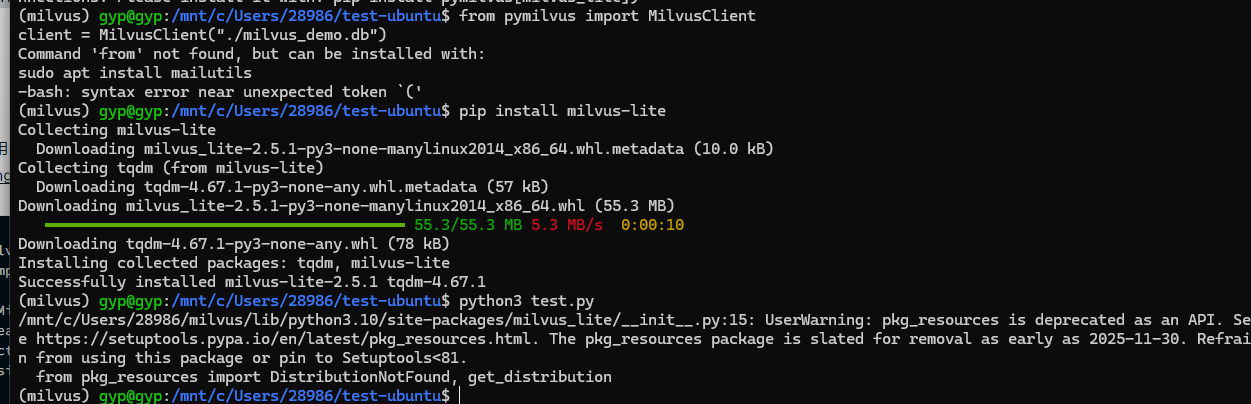
创建数据库:
from pymilvus import MilvusClient
client = MilvusClient("./milvus_demo.db")
简单测试:
python
from pymilvus import MilvusClient
import numpy as np
client = MilvusClient("./milvus_demo.db")
client.create_collection(
collection_name="demo_collection",
dimension=384 # The vectors we will use in this demo has 384 dimensions
)
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
vectors = [[ np.random.uniform(-1, 1) for _ in range(384) ] for _ in range(len(docs)) ]
data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ]
res = client.insert(
collection_name="demo_collection",
data=data
)
res = client.search(
collection_name="demo_collection",
data=[vectors[0]],
filter="subject == 'history'",
limit=2,
output_fields=["text", "subject"],
)
print(res)
res = client.query(
collection_name="demo_collection",
filter="subject == 'history'",
output_fields=["text", "subject"],
)
print(res)
res = client.delete(
collection_name="demo_collection",
filter="subject == 'history'",
)
print(res)3.2.Milvus Standalone
前提条件:
-
安装 Python 3.8+。
3.2.1.Docker Compose 运行 Milvus
在 PowerShell 或 Windows 命令提示符中运行以下命令,为 Milvus Standalone 下载 Docker Compose 配置文件并启动 Milvus。
1.下载配置文件:
python
Invoke-WebRequest https://github.com/milvus-io/milvus/releases/download/v2.6.7/milvus-standalone-docker-compose.yml -OutFile docker-compose.yml2.打开docker desktop
3.启动:
python
docker compose up -d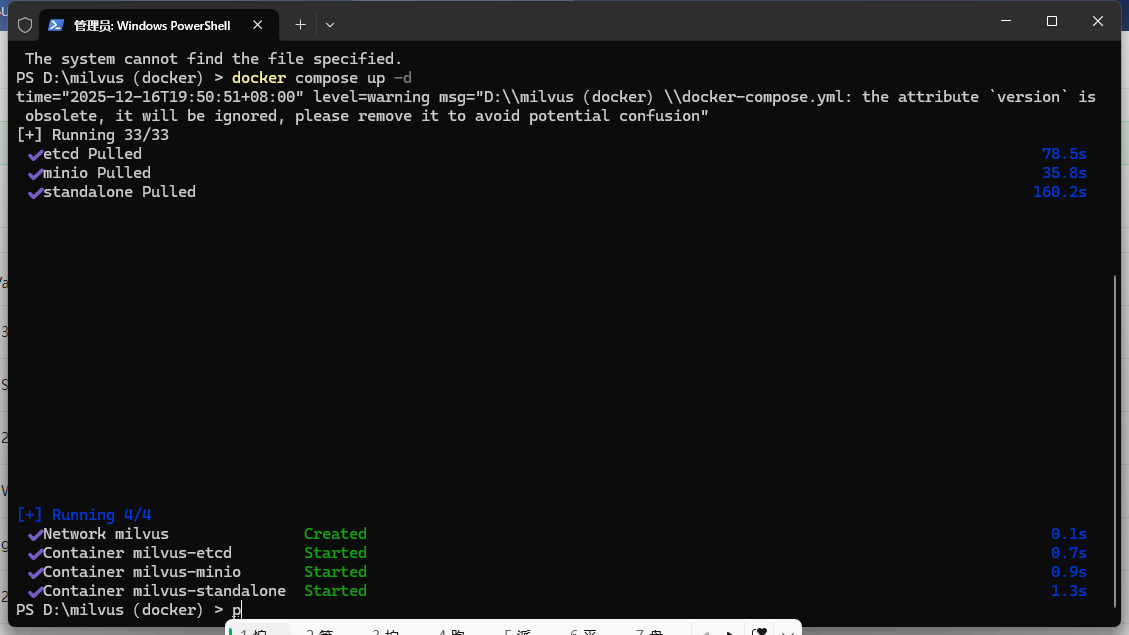
根据网络连接情况,下载用于安装 Milvus 的映像可能需要一段时间。名为milvus- standalone 、milvus-minio 和milvus-etcd的容器启动后,你可以看到
-
milvus-etcd 容器不向主机暴露任何端口,并将其数据映射到当前文件夹中的volumes/etcd。
-
milvus-minio 容器使用默认身份验证凭据在本地为端口9090 和9091 提供服务,并将其数据映射到当前文件夹中的volumes/minio。
-
milvus-standalone 容器使用默认设置为本地19530 端口提供服务,并将其数据映射到当前文件夹中的volumes/milvus。

3.2.2.Milvus Web UI
Milvus Web UI 是 Milvus 的图形化管理工具。它以简单直观的界面增强了系统的可观察性。您可以使用 Milvus Web UI 观察 Milvus 组件和依赖关系的统计和指标,检查数据库和 Collections 的详细信息,并列出详细的 Milvus 配置。
从 v2.5.0 起,你可以在运行中的 Milvus 实例上使用以下 URL 访问 Milvus Web UI:
python
http://127.0.0.1:9091/webui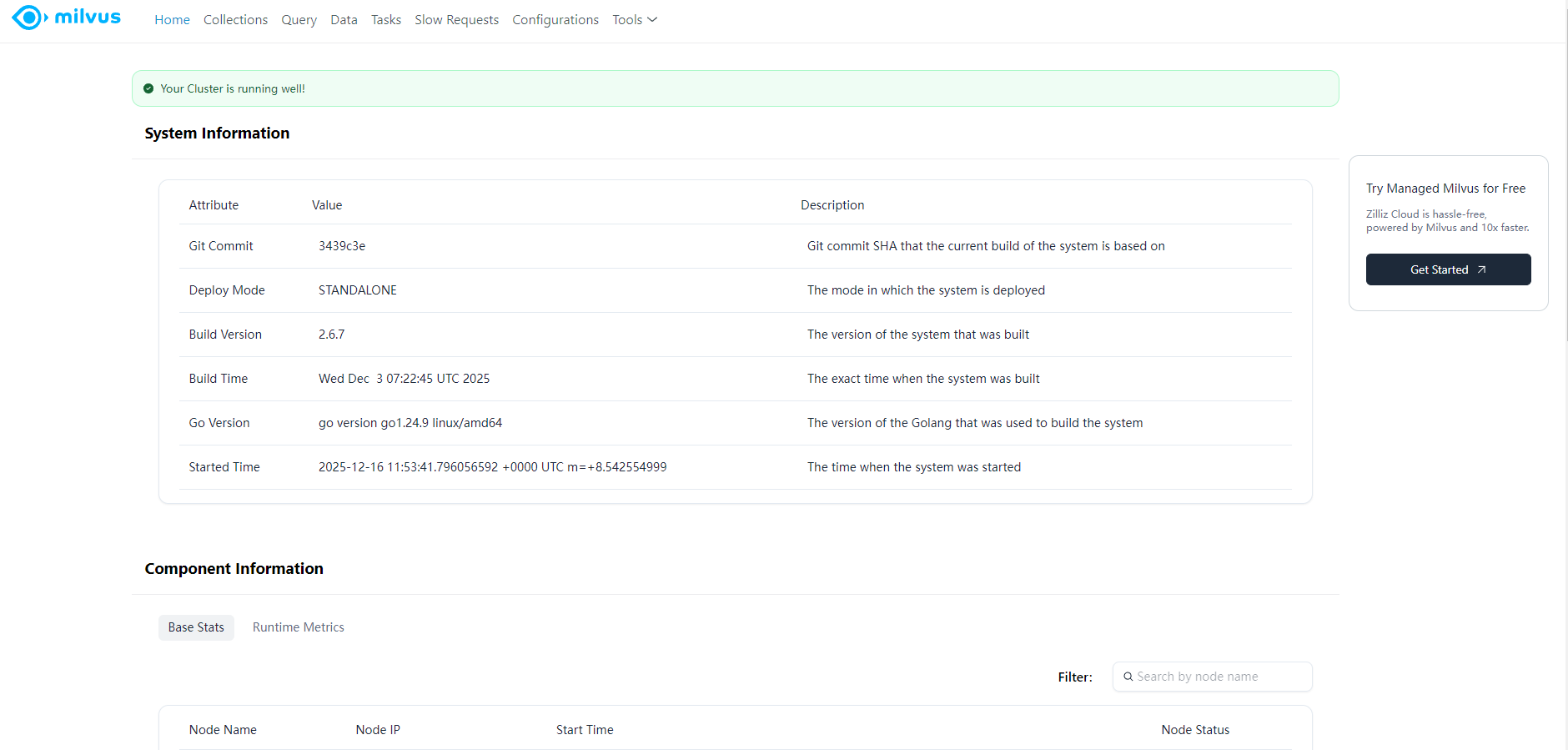
-
你可以找到关于当前运行的 Milvus 实例、其组件、连接的客户端和依赖关系的信息。
-
可查看 Milvus 当前的数据库和 Collections 列表,并检查其详细信息。
-
您可以查看收集到的查询节点和查询协调器在网段、通道、副本和资源组方面的统计数据。
-
您可以查看收集到的数据节点在网段和通道方面的统计数据。
-
可以查看 Milvus 中运行的任务列表,包括 Querycoord 调度器任务、压缩任务、索引构建任务、导入任务和数据同步任务。
-
可以查看 Milvus 中的慢请求列表,包括请求类型、请求持续时间和请求参数。
-
可以查看 Milvus 配置及其值的列表。
-
您可以从 Web UI 访问两个内置工具,即 pprof 和 Milvus 数据可视化工具。
4.Milvus--使用
python-sdk
4.1.连接
通过 URI 连接(禁用身份验证)
python
from pymilvus import MilvusClient
try:
client = MilvusClient(
"http://localhost:19530",
timeout=1000,
# db_name="milvus_demo",
)
print("连接成功")
except Exception as e:
print(e)
print("连接失败")4.2.数据库(database)
在 Milvus 中,数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,你可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据。例如,创建一个数据库用于存储用户 A 的数据,另一个数据库用于存储用户 B 的数据。
4.2.1.创建数据库
python
client.create_database(
db_name="my_database_1"
)#创建数据库
print("创建数据库成功!")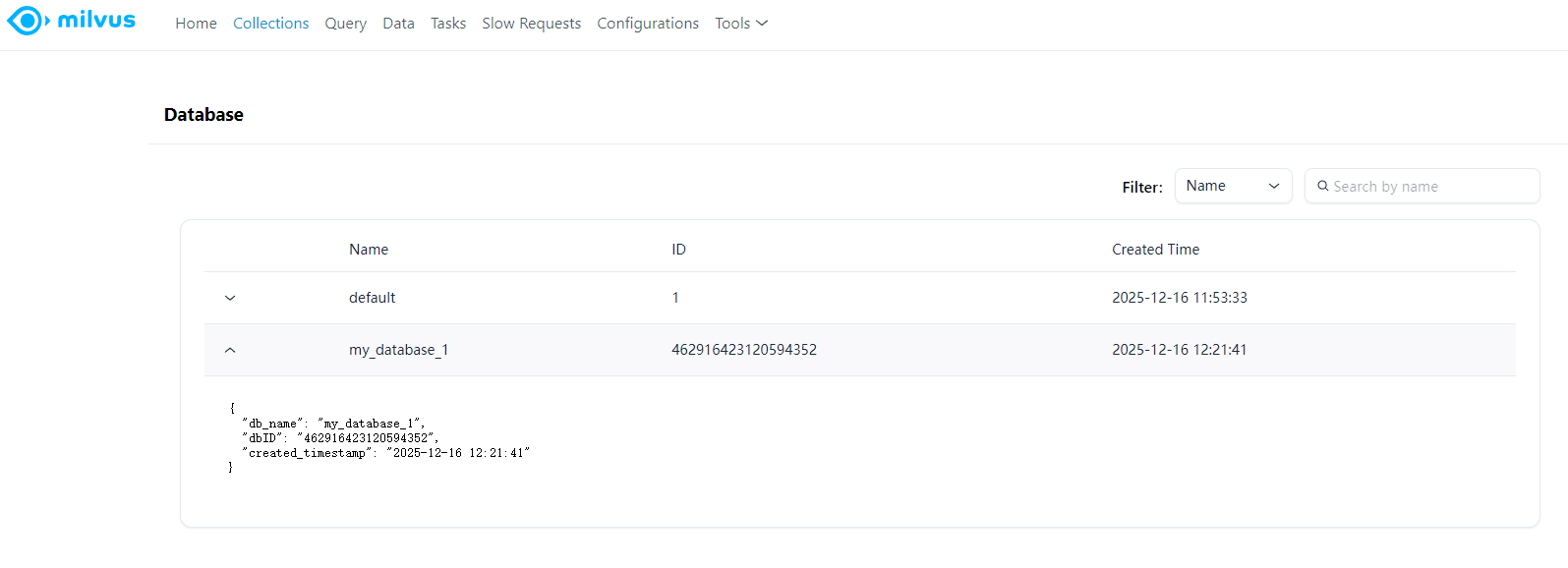
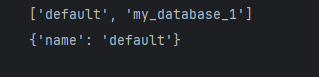
4.2.2.查看数据库
python
print(client.list_databases()#列出数据库
)
client.describe_database(#描述数据库
db_name="default"
)
4.2.3.数据库属性
每个数据库都有自己的属性,您可以在创建数据库时设置数据库属性(如创建数据库中所述),也可以更改和删除任何现有数据库的属性。
| 属性名称 | 类型 | 属性描述 |
|---|---|---|
database.replica.number |
整数 | 指定数据库的副本数量。 |
database.resource_groups |
字符串 | 以逗号分隔的列表形式列出的与指定数据库相关的资源组名称。 |
database.diskQuota.mb |
整数 | 指定数据库的最大磁盘空间大小(MB)。 |
database.max.collections |
整数 | 指定数据库中允许的最大 Collections 数量。 |
database.force.deny.writing |
布尔 | 是否强制指定的数据库拒绝写操作。 |
database.force.deny.reading |
布尔 | 是否强制指定的数据库拒绝读取操作。 |
4.2.4.删除数据库
python
# 创建数据库
client.create_database(
db_name="my_database_2",
properties={
"database.replica.number": 3
}
)
#更改数据库属性
client.alter_database_properties(
db_name="my_database_2",
properties={
"database.max.collections": 10
}
)
#删除数据库属性
client.drop_database_properties(
db_name="my_database_2",
property_keys=["database.max.collections"]
)
#切换数据库
client.use_database(
db_name="my_database_2"
)
#删除数据库
client.drop_database(
db_name="my_database_2"
)4.3.数据表(Collections)
在 Milvus 上,您可以创建多个 Collections 来管理数据,并将数据作为实体插入到 Collections 中。Collections 和实体类似于关系数据库中的表和记录
Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。
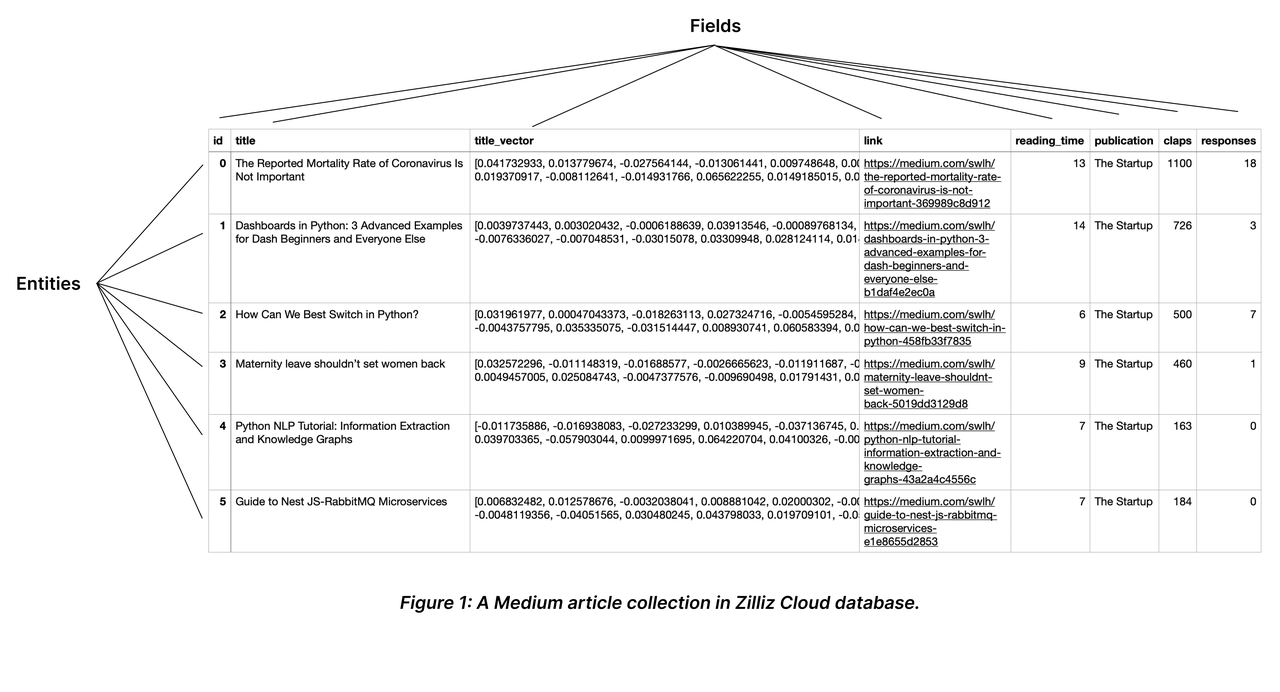
4.3.1.约束摘要(Schema)
在描述一个对象时,我们通常会提到它的属性,如大小、重量和位置。您可以将这些属性用作 Collection 中的字段。每个字段都有各种约束属性,例如向量字段的数据类型和维度。通过创建字段并定义其顺序,可以形成一个 Collections Schema。
您应在要插入的实体中包含所有 Schema 定义的字段。要使其中一些字段可选,可考虑启用动态字段。有关详情,请参阅动态字段。
python
from pymilvus import MilvusClient, DataType
# 连接到本地 Milvus 服务
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
# 创建集合结构(schema)
schema = MilvusClient.create_schema(
auto_id=False, # 主键由用户指定
enable_dynamic_field=True # 允许插入未定义的额外字段
)
# 添加主键字段
schema.add_field(field_name="my_id", datatype=DataType.INT64, is_primary=True)
# 添加向量字段(5维浮点向量)
schema.add_field(field_name="my_vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 添加字符串字段(最大长度512)
schema.add_field(field_name="my_varchar", datatype=DataType.VARCHAR, max_length=512)4.3.2.主键(primary key)
与关系数据库中的主字段类似,Collection 也有一个主字段,用于将实体与其他实体区分开来。主字段中的每个值都是全局唯一的,并与一个特定的实体相对应。
如上图所示,名为id 的字段是主字段,第一个 ID0 对应一个名为 "冠状病毒的死亡率并不重要"的实体。不会有其他实体的主字段为 0。
主字段只接受整数或字符串。插入实体时,默认情况下应包含主字段值。但是,如果在创建 Collections 时启用了AutoId,Milvus 将在插入数据时生成这些值。在这种情况下,请从要插入的实体中排除主字段值。
4.3.3.设置索引参数(可选)
在特定字段上创建索引可加快对该字段的搜索。索引记录了 Collections 中实体的顺序。如以下代码片段所示,您可以使用metric_type 和index_type 为 Milvus 选择适当的方式为字段建立索引,并测量向量嵌入之间的相似性。
在 Milvus 上,您可以使用AUTOINDEX 作为所有向量场的索引类型,并根据需要使用COSINE 、L2 和IP 中的一种作为度量类型。
metric_type(度量类型) :
定义如何计算两个向量之间的相似性或距离。常见选项:
L2:欧几里得距离(越小越相似)IP(Inner Product):点积(越大越相似,常用于归一化后的向量)COSINE:余弦相似度(衡量方向一致性)index_type(索引类型) :
定义使用哪种算法结构来加速搜索 ,例如
IVF_FLAT、HNSW、AUTOINDEX等。这两个参数共同决定了索引的构建方式和后续搜索的行为。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="my_id",
index_type="AUTOINDEX"
)
index_params.add_index(
field_name="my_vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)4.3.4.创建数据表
如果创建了带有索引参数的 Collection,Milvus 会在创建时自动加载该 Collection。在这种情况下,索引参数中提到的所有字段都会被索引。
以下代码片段演示了如何创建带索引参数的 Collections 并检查其加载状态。
python
client.create_collection(
collection_name="customized_setup_1",
schema=schema,
index_params=index_params
)
res = client.get_load_state(
collection_name="customized_setup_1"
)
print(res)4.3.5.设置数据表属性
您可以为要创建的 Collection 设置属性,使其适合您的服务。适用的属性如下。
1.设置分片数
分片是 Collections 的水平切片,每个分片对应一个数据输入通道。默认情况下,每个 Collections 都有一个分区。您可以在创建 Collections 时指定分片数量,以便更好地适应数据量和工作负载。
作为一般指导原则,在设置分片数量时应考虑以下几点:
- **数据大小:**通常的做法是每 2 亿个实体设置一个分区。也可以根据总数据量进行估算,例如,计划插入的数据量每 100 GB 就增加一个分区。
- **流节点利用率:**如果你的 Milvus 实例有多个流节点,建议使用多个分片。这样可以确保数据插入工作量分布在所有可用的流节点上,防止一些节点闲置,而其他节点超负荷工作。
python
client.create_collection(
collection_name="customized_setup_3",
schema=schema,
# highlight-next-line
num_shards=1
)2.启用 mmap
Milvus 默认在所有 Collections 上启用 mmap,允许 Milvus 将原始字段数据映射到内存中,而不是完全加载它们。这样可以减少内存占用,提高 Collections 的容量。有关 mmap 的详细信息,请参阅使用 mmap。
python
client.create_collection(
collection_name="customized_setup_4",
schema=schema,
# highlight-next-line
enable_mmap=False
)3.设置 Collections TTL
如果需要在特定时间段内删除 Collections 中的数据,可以考虑以秒为单位设置其 Time-To-Live (TTL)。一旦 TTL 超时,Milvus 就会删除 Collection 中的实体。删除是异步的,这表明在删除完成之前,搜索和查询仍然可以进行。
python
client.create_collection(
collection_name="customized_setup_5",
schema=schema,
# highlight-start
properties={
"collection.ttl.seconds": 86400
}
# highlight-end
)4.设置一致性级别
创建 Collections 时,可以为集合中的搜索和查询设置一致性级别。您还可以在特定搜索或查询过程中更改 Collections 的一致性级别。
python
client.create_collection(
collection_name="customized_setup_6",
schema=schema,
# highlight-next-line
consistency_level="Bounded",
)4.3.6.列出数据表
下面的示例演示了如何获取当前连接的数据库中所有集合的名称列表。
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.list_collections()
print(res)
res = client.describe_collection(
collection_name="quick_setup"
)
print(res)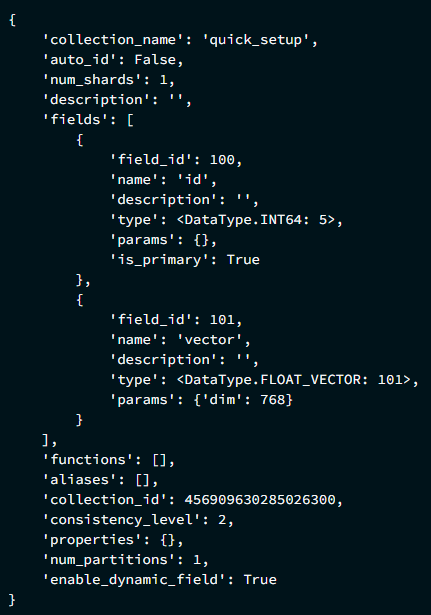
4.3.7.修改数据表
您可以按以下方式重命名一个 Collection。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.rename_collection(
old_name="my_collection",
new_name="my_new_collection"
)下面是设置属性:
python
#设置 Collections TTL
from pymilvus import MilvusClient
client.alter_collection_properties(
collection_name="my_collection",
properties={"collection.ttl.seconds": 60}
)
from pymilvus import MilvusClient
client.alter_collection_properties(
collection_name="my_collection",
properties={"mmap.enabled": True}
)
#删除属性
client.drop_collection_properties(
collection_name="my_collection",
property_keys=[
"collection.ttl.seconds"
]
)4.3.7.加载和释放
加载数据表是在集合中进行相似性搜索和查询的前提
加载 Collections 时,Milvus 会将索引文件和所有字段的原始数据加载到内存中,以便快速响应搜索和查询。在载入 Collections 后插入的实体会自动编入索引并载入。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.load_collection(
collection_name="my_collection"
)
res = client.get_load_state(
collection_name="my_collection"
)
print(res)释放:
python
client.release_collection(
collection_name="my_collection"
)
res = client.get_load_state(
collection_name="my_collection"
)
print(res)删除:
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.drop_collection(
collection_name="my_collection"
)4.3.8.一致性级别
Milvus 提供以下四种一致性级别(Consistency Levels):
- Strong(强一致性):读操作总能返回最新的写入结果,但性能开销大。
- Bounded(有限制一致性,默认):在可接受的延迟范围内保证数据一致性(例如,最多延迟几秒),兼顾性能与准确性。
- Eventually(最终一致性):写入后经过一段时间,所有节点最终会看到相同的数据;延迟可能较长,但吞吐高。
- Session(会话一致性):在同一客户端会话中,保证"读己之写"(即自己写的数据自己能立刻读到)。
- 存储与计算分离架构
Milvus 采用 存算分离(Storage-Compute Separation) 设计:
- 数据节点(Data Nodes)
→ 负责接收写入的流式数据,并将其持久化到 MinIO 或 S3 等对象存储中。 - 查询节点(Query Nodes)
→ 负责加载已持久化的数据(批量数据)和部分缓存的流数据,执行向量搜索等计算任务。
| 类型 | 说明 |
|---|---|
| 批量数据(Batch Data) | 已经被写入并持久化到对象存储(如 S3)的数据,稳定可靠,可被查询节点加载用于搜索。 |
| 流数据(Streaming Data) | 刚刚插入、尚未持久化到对象存储的数据,暂时只存在于内存或日志(如 Pulsar/Kafka)中。 |
python
client.create_collection(
collection_name="my_collection",
schema=schema,
# highlight-next-line
consistency_level="Bounded",#有限一致性
)
#搜索设置(向量)
res = client.search(
collection_name="my_collection",
data=[query_vector], # 查询向量(需为列表,即使只有一个)
limit=3, # 返回最相似的 3 个结果
search_params={"metric_type": "IP"}, # 使用内积(IP)作为相似度度量
consistency_level="Bounded" # 使用"有限制一致性"级别(默认)
)
#查询设置(标量)
# 执行标量过滤查询:从集合中检索满足条件的实体
res = client.query(
collection_name="my_collection", # 指定要查询的集合名称
filter='color like "red%"', # 过滤条件:color 字段以 "red" 开头(支持通配符 %)
output_fields=["vector", "color"], # 指定返回的字段(包括向量和颜色)
limit=3, # 最多返回 3 条匹配结果
consistency_level="Eventually" # 使用最终一致性级别(可能不包含最新写入的数据)
)4.4.分区管理(partition)
分区:partition
分区是一个 Collection 的子集。每个分区与其父集合共享相同的数据结构,但只包含集合中的一个数据子集。
创建一个 Collection 时,Milvus 也会在该 Collection 中创建一个名为**_default 的**分区。如果不添加其他分区,所有插入到 Collections 中的实体都会进入默认分区,所有搜索和查询也都在默认分区内进行。
您可以添加更多分区,并根据特定条件将实体插入其中。这样就可以限制在某些分区内进行搜索和查询,从而提高搜索性能。
一个 Collections 最多可以有 1,024个分区。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
#创建分区
client.create_partition(
collection_name="my_collection",
partition_name="partitionA"
)
#列出分区
res = client.list_partitions(
collection_name="my_collection"
)
print(res)
#检查分区
res = client.has_partition(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)加载分区
python
client.load_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
res = client.get_load_state(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
#释放分区
client.release_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
#删除分区
client.drop_partition(
collection_name="my_collection",
partition_name="partitionA"
)