1 前言
关于大模型的博客,笔者分为了两个系列:车企量产 + 科研论文。希望有兴趣的朋友能够从笔者的大模型博客系列当中收获一些知识或者idea。
车企量产:
《自动驾驶大模型---大疆车载(卓驭科技)之GenDrive》
科研论文:
《自动驾驶---阿里巴巴之AutoDrive-R²(VLA)大模型》
在传统的自动驾驶端到端框架中,底层认知过程未得到充分解决。尽管大型语言模型(LLM)能够提升理解和推理能力,但将其集成到自动驾驶系统中面临两大挑战:
(1)LLM 的高计算需求与自动驾驶车辆所需的高效性之间始终存在显著矛盾;
(2)尽管 LLM 可以生成高质量的语义推理结果,但如何将高层文本推理映射到自动驾驶车辆的低层轨迹规划仍是一个待解决的难题。
2 DSDrive
为应对这些问题,香港科技大学研究团队提出了 DSDrive,一种精简的端到端范式,旨在将自动驾驶车辆的推理与规划整合到统一框架中。
DSDrive 利用紧凑型 LLM,通过蒸馏方法保留更大规模视觉语言模型(VLM)增强的推理能力。为有效对齐推理与规划任务,我们进一步开发了航点驱动的双头协调模块,该模块同步数据集结构、优化目标和学习过程。通过将这些任务集成到统一框架中,DSDrive 在结合详细推理洞察的同时锚定规划结果,从而增强端到端流程的可解释性和可靠性。
最最重要的一点:
DSDrive 在++闭环仿真++ **中经过全面测试,其性能与基准模型相当,甚至在许多关键指标上表现更优,同时模型体积更紧凑。**此外,DSDrive 的计算效率(以推理过程中的时间和内存需求衡量)显著提升。因此,这项工作展现了轻量化系统在为自动驾驶提供可解释且高效解决方案方面的潜力,具有重要的研究价值和应用前景。
2.1 架构
架构中包含两个主要组件:一个是在第(1)节中详细阐述的推理模型,另一个是在第(2)节中概述的端到端(E2E)驾驶模型。推理模型采用大型视觉语言模型(VLM),而驾驶模型则使用紧凑型大语言模型(LLM)。并且将知识蒸馏作为学习机制,使紧凑型驾驶模型能够从视觉语言模型(VLM)中习得推理能力。
(1)VLM
由于 Qwen2.5-VLmax 是一款旨在处理多种任务的通用型视觉语言模型(VLM),我们设计了结构化的思维链(CoT)策略,以提升其在自动驾驶(AD)领域的专用性,具体考虑如下:
- 场景理解:通过分析天气、时段、道路类型、路面状况等要素,掌握驾驶环境信息。
- 关键目标描述:详细说明关键目标的名称、位置、特征,以及其对自车行驶可能构成的潜在风险。
- 驾驶策略规划制定:制定周密的驾驶策略,以高效应对当前场景。
- 可解释性说明生成:针对所做的驾驶决策与动作,生成人类可理解的解释。
目前,视觉语言模型(VLM)的输出主要集中在高层级推理层面。但在自动驾驶(AD)中,规划任务通常涉及为轨迹规划及后续车辆控制预测路径点(waypoints)。对于通用型 VLM 而言,精准预测目标路径点以实现精确操控是一项重大挑战,这主要是因为空间定位一直是这类模型公认的短板。因此,需要额外的策略来填补自动驾驶中抽象推理与具体规划任务之间的差距。
论文作者创新性地利用真值路径点(ground-truth waypoints),将推理过程与规划任务关联起来。该思路源于其它参考文献中的训练模板,该模板强调 "逐步思考后给出最终答案" 的模式。这种数据集设计要求明确呈现推理步骤,旨在避免模型通过 "捷径" 直接得出答案。在我们的研究中,此方法发挥了更关键的作用:通过在 "思考 - 作答" 过程中嵌入真值路径点,将规划任务无缝整合为推理过程的自然结果。
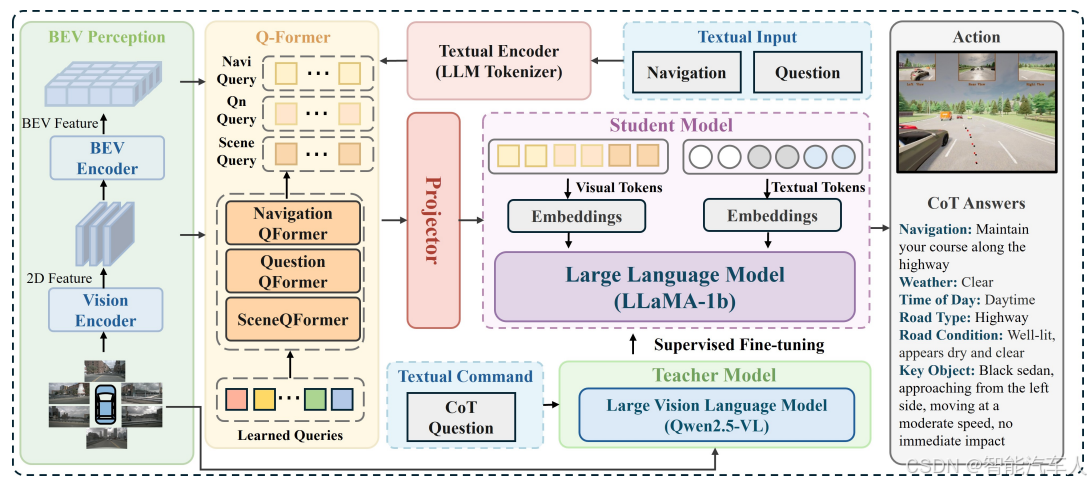
(2)End-to-end Model
驾驶模型处理多模态输入(包括视觉数据和文本信息),以输出预测路径点(Wpred)、预测答案(Apred)以及当前导航指令是否已完成的指示符(Cpred)。图像输入与导航指令均与推理模型的输入保持一致,确保整个框架的连贯性。推理模型的输入问题 Xvlm 由一系列关于自动驾驶(AD)子任务的问题构成,而驾驶模型中的问题文本 Xqn 则是 "思考并作答" 这类简洁的指令句。
如图所示,驾驶模型集成了多个专用组件,以实现全面的推理与规划功能,具体包括:(1)用于处理输入的视觉编码器与分词器,(2)用于对齐视觉特征与文本标记的 Q 转换器(Q-former),(3)大语言模型(LLM)主干网络,(4)采用推理与规划任务双头设计的多任务输出模块。
- 输入编码
- 视觉与文本模态对齐
- 大语言模型主干网络
- 多任务输出 :基于大语言模型输出的隐藏状态 H,驾驶模型设计了多任务输出结构,可同时实现多项功能:
- 生成规划轨迹(通过路径点预测转化为精确的车辆操控指令);
- 以自然语言解释驾驶决策背后的分步推理过程;
- 判断当前导航指令下的驾驶任务是否已完成。
(3)知识蒸馏
利用蒸馏法的紧凑 LLM:DSDrive 利用一种紧凑的 LLM,通过蒸馏方法保留更大尺寸视觉语言模型(VLM)增强的推理能力。这样可以在利用大型模型知识的同时,减少模型的计算量和存储空间,提高模型的运行效率。
2.2 实验结果
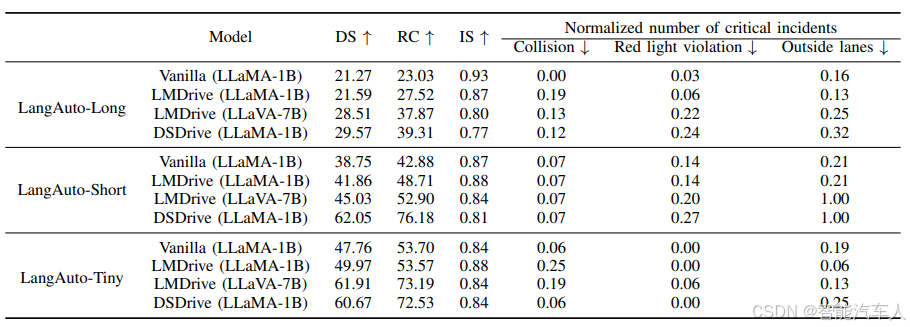
DSDrive 在闭环模拟中经过了全面测试,其性能与基准模型相当,在许多关键指标上甚至表现更优,同时模型尺寸更紧凑。此外,DSDrive 的计算效率(在推理过程中的时间和内存要求方面)得到了显著提高。
最大的贡献在于实现了闭环测试。
3 总结
本篇博客主要介绍了香港科技大学提出的DSDrive自动驾驶方案,主要还是依赖QWen多模态模型的能力,属于VLA那一派,但DSDrive是基于闭环测试做的实验,目前基于闭环实验的自动驾驶大模型很少,这一点还是值得肯定的。
至于模型的输入,输出以及结构,差别不是特别大,DSDrive还用了一个蒸馏,和理想小鹏的有些相似,确保模型部署能够提升推理的实时性。
参考文献:《DSDrive: Distilling Large Language Model for Lightweight End-to-End Autonomous Driving with Unified Reasoning and Planning》