在当今竞争激烈的求职市场中,"面试"往往是求职者最大的拦路虎。作为一名全栈开发者,我一直在思考:能否利用最新的 AIGC 能力,打造一个能够 "从简历优化到模拟面试" 的全流程辅助工具?
于是,AI Interviewer(AI 面试官) 项目应运而生。本项目旨在通过技术手段,为用户提供一个低成本、高效率的面试演练环境。
一、项目架构与技术栈
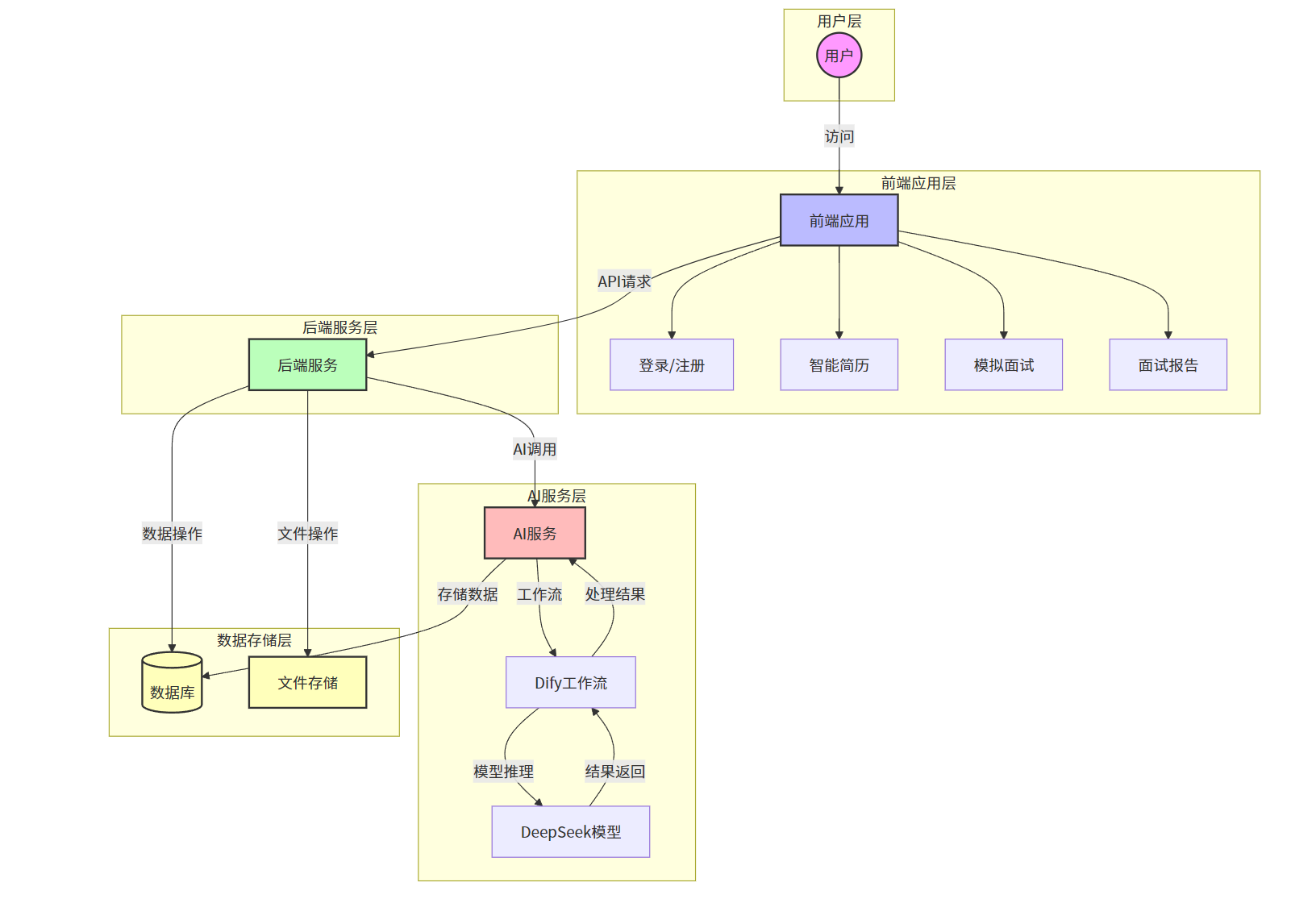
1.系统分层架构
本项目采用经典的前后端分离架构,通过 RESTful API 进行通信,并引入了专门的 AI 编排层(AI Orchestration Layer)来处理复杂的 LLM 逻辑。
-
表现层 (Presentation Layer): 基于 Vue 3 + Element Plus 构建现代化用户界面
-
业务逻辑层 (Application Layer): Django REST Framework 实现核心业务逻辑
-
数据持久层 (Data Layer): MySQL 数据库存储用户信息和面试记录
-
AI 编排层 (AI Orchestration Layer): 基于 Dify 平台实现 AI 工作流编排
系统架构与业务流程图
2. 核心技术栈
| 分类 | 技术 | 版本 | 用途 |
|---|---|---|---|
| 前端框架 | Vue | 3.x | 核心框架,使用 Composition API |
| 状态管理 | Pinia | 2.x | 管理用户状态和简历数据 |
| UI 组件 | Element Plus | 2.x | 提供现代化界面组件 |
| HTTP 客户端 | Axios | 1.x | 处理 API 请求和响应拦截 |
| 后端框架 | Django | 5.2 | Web 应用框架 |
| API 框架 | Django REST Framework | 3.x | 构建 RESTful API |
| 数据库 | MySQL | 8.x | 数据持久化 |
| 认证 | SimpleJWT | 5.x | 无状态 Token 认证 |
| AI 平台 | Dify | 最新 | AI 工作流编排和模型集成 |
| AI 模型 | DeepSeek V3 | 最新 | 生成式 AI 能力 |
3. 项目框架详细结构
①前端架构 (Vue 3 + TypeScript)
前端项目采用 Vue 3 的 Composition API 和 TypeScript 构建,具有清晰的模块化结构:
fontend/
├── src/
│ ├── api/ # API 接口定义
│ ├── assets/ # 静态资源(CSS、图片、字体)
│ ├── router/ # 路由配置
│ ├── stores/ # Pinia 状态管理
│ ├── unit/ # 工具函数(如 request.ts)
│ ├── views/ # 页面组件
│ │ ├── Mock.vue # 模拟面试页面
│ │ └── Resume.vue # 简历编辑页面
│ ├── App.vue # 根组件
│ └── main.ts # 应用入口
├── index.html # HTML 模板
├── vite.config.ts # Vite 配置
└── package.json # 依赖管理核心文件说明:
-
main.ts: 应用初始化,配置 Pinia、Router 和 Element Plus -
App.vue: 根组件,定义应用的基本布局 -
request.ts: 统一 API 请求封装,处理拦截器和错误 -
Mock.vue: AI 模拟面试的核心页面组件
②后端架构 (Django)
后端采用 Django 的多应用架构,每个应用负责特定的业务功能:
backend/
├── user/ # 用户管理模块
├── resumes/ # 简历管理模块
├── questions/ # 题目管理模块
├── interviews/ # 面试会话模块
├── createre/ # 简历创建模块
├── ai_assistant/ # AI 助手模块
├── backend/ # 项目配置
│ ├── settings.py # Django 配置
│ └── urls.py # 主路由
└── manage.py # Django 管理命令核心配置说明:
-
settings.py: 配置应用、数据库、认证、CORS 等 -
INSTALLED_APPS: 注册所有 Django 应用 -
MIDDLEWARE: 中间件配置(CORS、认证等) -
DATABASES: 数据库连接配置
③数据库架构
系统采用了关系型数据库 MySQL 结合 JSONField 的混合存储模式,以适应灵活的 AI 数据结构。
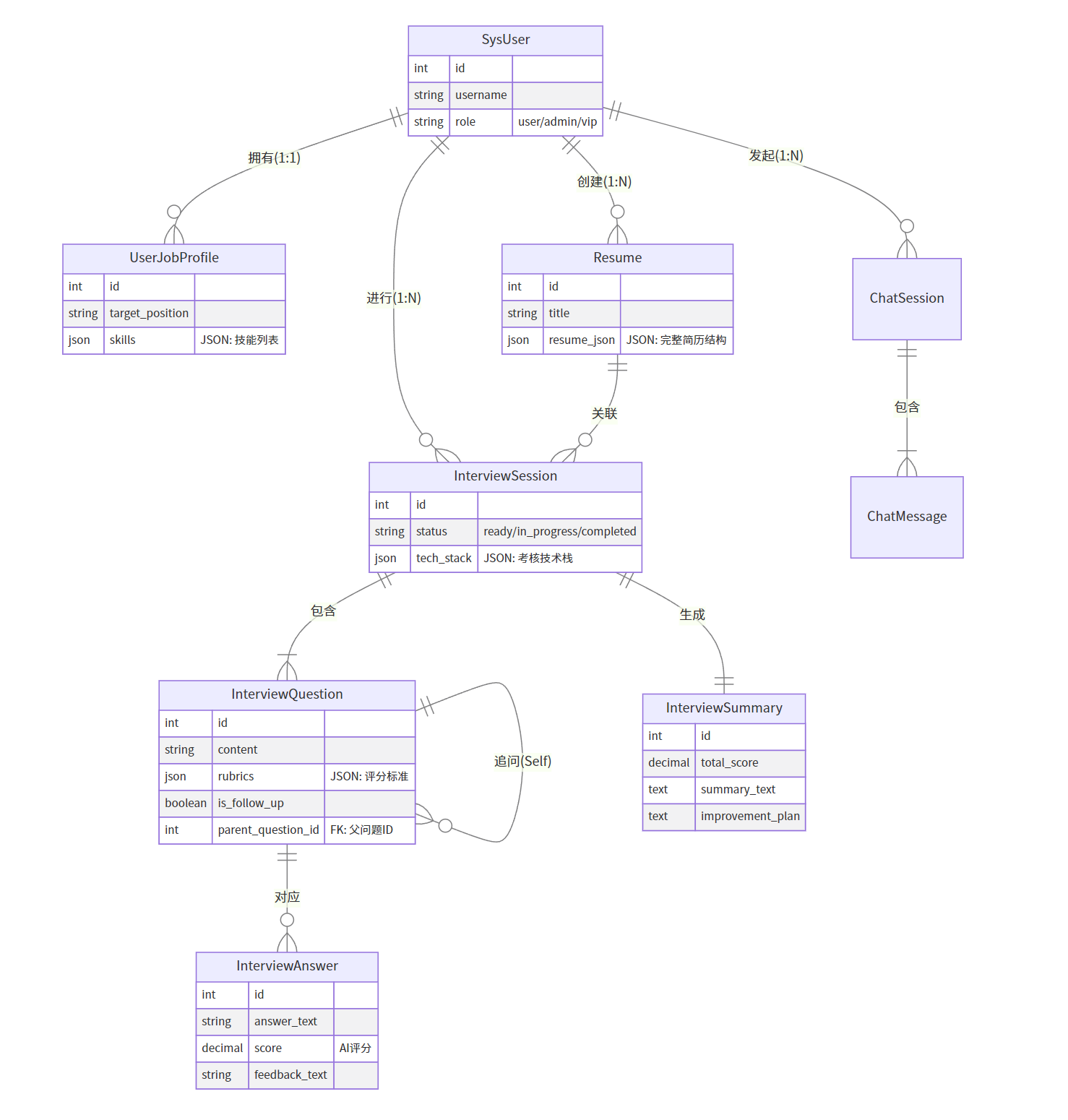
关键设计亮点:
-
SysUser & UserJobProfile (用户画像):
-
采用
OneToOne关联将鉴权信息 (SysUser) 与求职档案 (UserJobProfile) 分离。 -
UserJobProfile中使用JSONField存储skills(技能标签),支持灵活的标签扩展。
-
-
Resume (简历中心):
- 核心字段
resume_json存储完整的结构化简历(个人信息、经历、教育等),避免了传统 EAV (Entity-Attribute-Value) 模型的复杂连表查询,同时完美契合前端 JSON 数据结构,实现 "Read-Modify-Write" 的闭环。
- 核心字段
-
Interview System (面试核心):
-
InterviewSession : 作为一次面试的聚合根,记录状态 (
status) 和技术栈上下文 (tech_stack)。 -
InterviewQuestion : 设计了
parent_question自关联字段,天然支持 "追问 (Follow-up)" 场景,形成树状的问题结构。 -
Rubrics in JSON : 将 AI 生成的复杂评分标准 (
passing_criteria,red_flags等) 直接存为 JSON,既保证了数据完整性,又方便后续评分逻辑直接读取,无需再次解析。
-
-
AI Assistant (助手):
- 独立的
ChatSession和ChatMessage表,支持多轮对话记录的持久化。
- 独立的
4. 相关技术知识介绍
①Vue 3 Composition API
Vue 3 的 Composition API 是一种新的组件逻辑组织方式,相比 Options API 具有以下优势:
-
更好的逻辑复用: 通过 Composable 函数提取和复用逻辑
-
TypeScript 支持: 更好的类型推断和类型检查
-
更灵活的代码组织: 按功能组织代码,而不是按选项(data、methods 等)
-
更小的打包体积: Tree-shaking 友好,只打包使用的功能
核心概念:
-
ref(): 创建响应式数据(基本类型) -
reactive(): 创建响应式对象(引用类型) -
computed(): 创建计算属性 -
watch(): 监听数据变化 -
onMounted(): 生命周期钩子
②Django REST Framework
Django REST Framework (DRF) 是 Django 的扩展,用于快速构建 Web API:
-
序列化: 将 Django 模型转换为 JSON 格式
-
视图: 基于函数或类的视图,处理 API 请求
-
认证: 支持多种认证方式(JWT、Token、Session 等)
-
权限: 细粒度的权限控制
-
分页: 处理大量数据的分页返回
-
文档: 自动生成 API 文档
核心组件:
-
Serializer: 数据序列化/反序列化 -
ViewSet: 基于类的视图,提供标准 CRUD 操作 -
Router: 自动生成 API 路由 -
Permission: 权限控制类
③JWT 认证
JSON Web Token (JWT) 是一种无状态的认证机制:
-
组成: Header(算法信息)、Payload(用户信息)、Signature(签名)
-
优势: 无状态、可跨域、便于分布式系统使用
-
工作流程: 用户登录 → 服务器生成 JWT → 客户端存储 → 请求时携带 → 服务器验证
在本项目中,使用 rest_framework_simplejwt 库实现 JWT 认证,并通过 Axios 拦截器自动管理 Token。
④ Dify AI 编排平台
Dify 是一个开源的 AI 应用开发平台,用于构建和部署 AI 应用:
-
工作流编排: 可视化设计 AI 工作流
-
模型集成: 支持多种大语言模型
-
API 生成: 自动生成 API 接口
-
监控分析: 跟踪 AI 应用的使用情况
本项目使用 Dify 编排复杂的 AI 逻辑,如动态题库生成和面试评分,降低了开发难度。
二、核心功能模块
1.智能简历中心
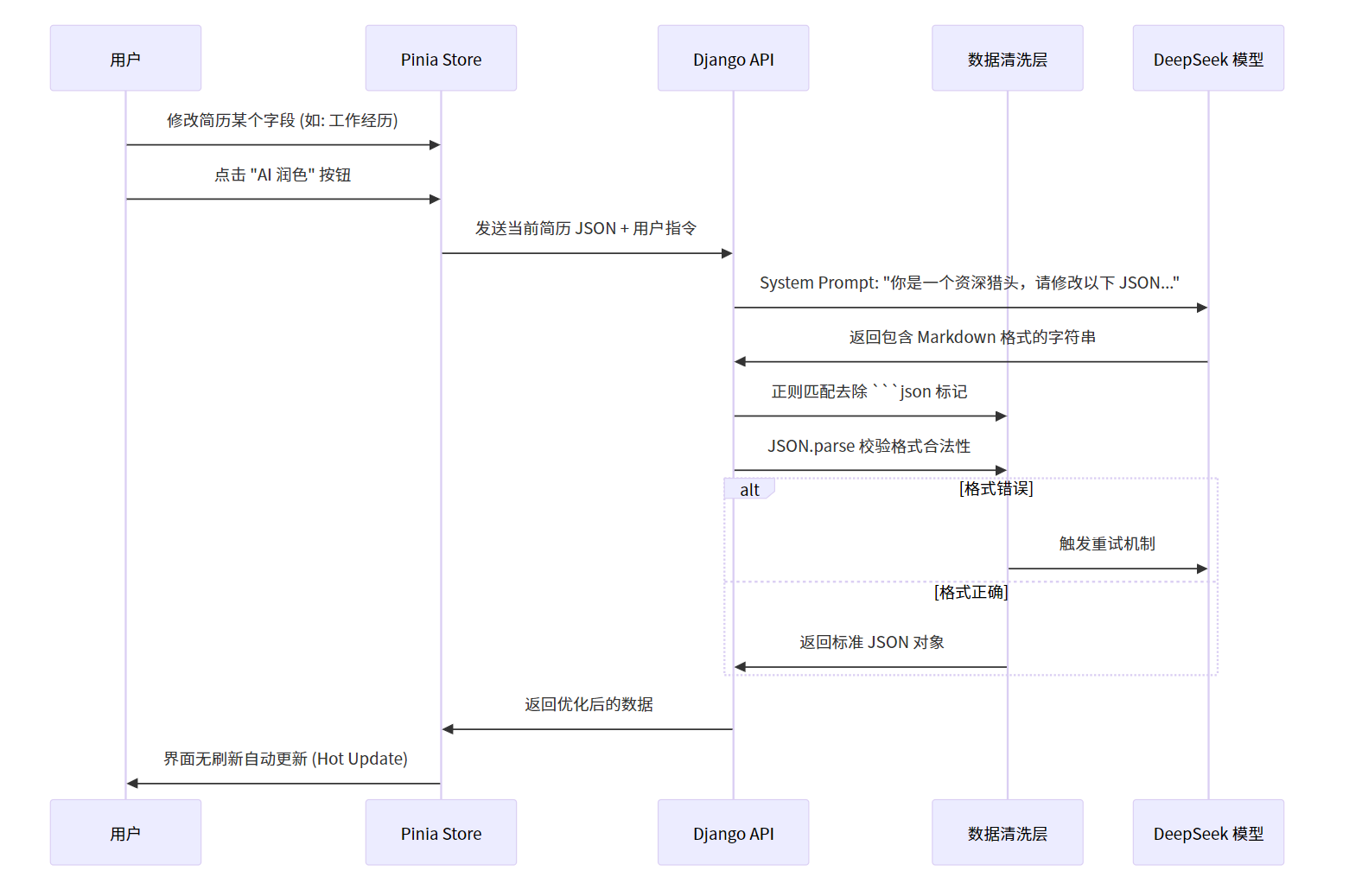
①AI 简历智能润色与结构化解析
技术难点 :如何让 AI 理解非结构化的文本并精准修改指定字段,同时不破坏 JSON 格式? 解决方案 :采用 "JSON Schema 约束 + 正则清洗" 的双重保障机制。
实现流程图:
②JSON 驱动的简历结构设计
我们采用了 JSON 驱动的简历结构,将简历数据标准化为如下格式:
{
"personal_info": { "name": "...", "target_position": "前端工程师" },
"experience": [
{
"company": "科技公司",
"title": "高级开发",
"description": "1. 负责核心架构设计...\n2. 优化首屏加载..."
}
],
"education": [...],
"skills": [{"name": "Vue3", "level": "精通"}],
"certificates": [...]
}这种设计的优势在于:
-
AI 读写极其高效 :LLM 天生擅长处理 JSON,当我们要求 AI "优化工作经历" 时,只需将
experience数组发送给 AI,它就能精准地只修改描述文字,而不会破坏版式。 -
样式与内容解耦 :用户只负责填空,排版由 CSS 统一控制。我们利用
@media print媒体查询,隐藏了侧边栏和按钮,重新定义了容器宽度,使得网页可以直接被浏览器打印为完美的 A4 PDF。
③AI 智能润色与回填机制
在 backend/createre/views.py 中,我们实现了一个 AIEditView,它不仅是简单的 API 转发,更是数据清洗层:
-
Prompt 约束:System Prompt 强制要求 AI "只返回 JSON,不要废话"。
-
格式清洗 :代码会自动去除 AI 可能包裹的 Markdown 代码块标记(
json ...),防止前端解析失败。 -
乐观 UI 更新 :前端采用 Pinia 进行状态管理,AI 返回数据后,直接通过
$patch批量更新 Store,实现无刷新秒级渲染。
④ 默认简历生成与权限控制
系统会为新用户自动生成一份完整的默认简历模板,包含所有必要字段和示例内容。这种设计极大地降低了用户的使用门槛,让用户可以直接开始编辑而无需从头开始。
在 ResumeViewSet 中,我们实现了严格的权限控制:
def get_queryset(self):
"""
只返回当前用户的简历
"""
return Resume.objects.filter(user=self.request.user).order_by('-updated_at')这种设计确保了用户只能访问和编辑自己的简历,保护了用户数据的安全性和隐私性。
2.AI 模拟面试系统
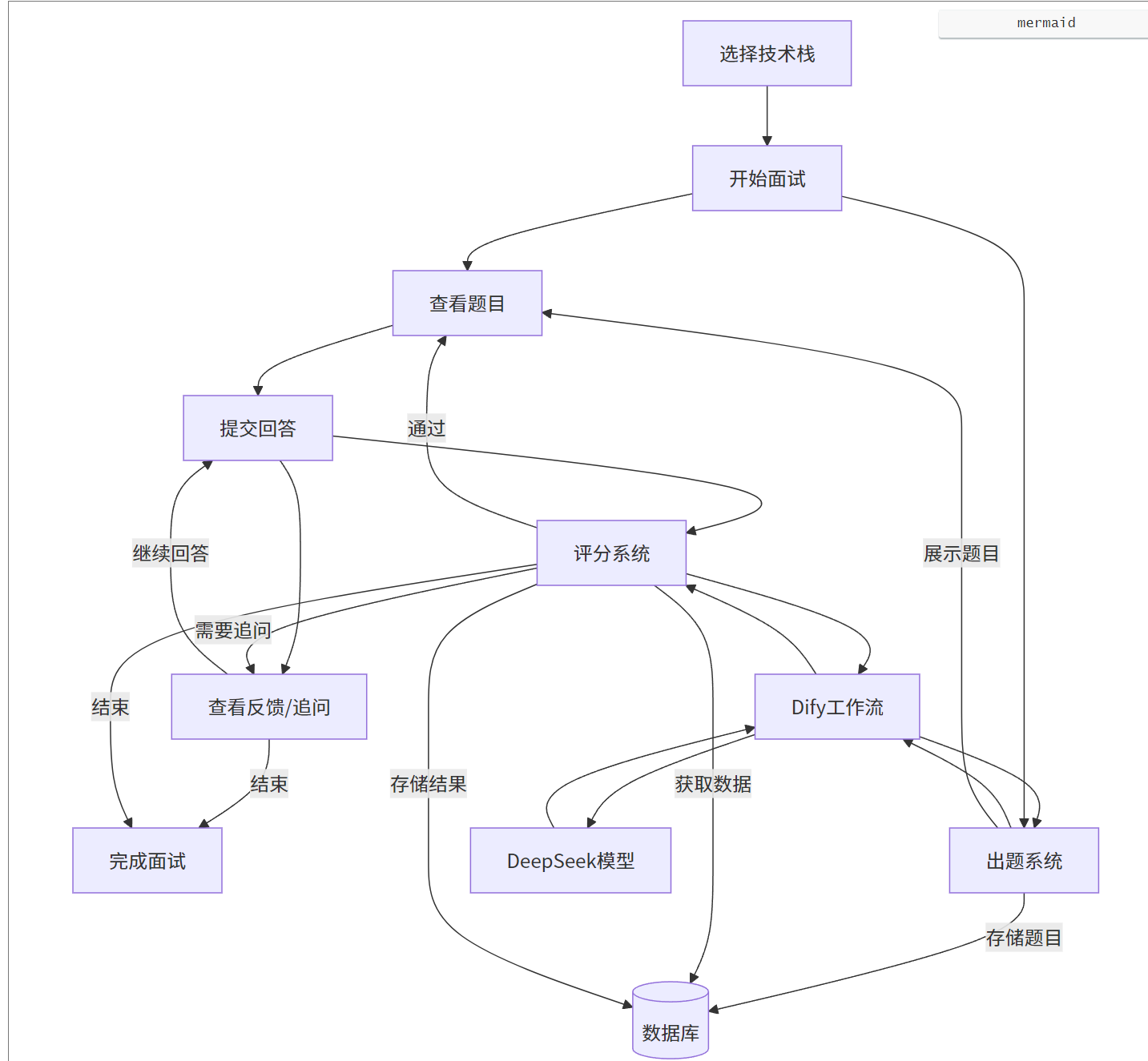
①动态题库生成与上下文管理
面试不是一次性的问答,而是一个Context-Aware(上下文感知) 的多轮对话。我们在后端 (backend/interviews/utils) 封装了两个核心 AI 客户端:
动态题库生成与上下文管理流程图:
-
QuestionGenerator (出题官):
-
根据用户的技术栈(如 "Vue3 + Django"),动态生成符合当前难度的面试题。
-
它不仅生成题目,还同时生成 "评分标准 (Rubrics)" ,包含
passing_criteria(及格标准)、advanced_criteria(优秀标准)和red_flags(扣分项),存入数据库供后续评分使用。 -
通过
DifyWorkflowClient与 Dify 平台集成,实现了复杂的 AI 工作流调用。
-
-
AnswerEvaluator (面试官/判卷人):
-
当用户提交回答(文本或语音转文字)后,该模块会被触发。
-
它会将 当前题目 + 评分标准 + 用户回答 打包发送给 Dify 工作流。
-
Chain of Thought (思维链) :AI 会先进行分析(Analysis),打分(Score),然后判断是否需要追问(Follow-up)。如果用户回答得模棱两可,AI 会自动生成一个追问问题,通过前端呈现给用户。
-
②题目生成的技术实现
在 QuestionGenerator 类中,我们实现了一系列数据清洗和处理逻辑,确保 AI 返回的内容符合预期格式:
python
def generate_questions(self, tech_stack: str) -> Dict[str, Any]:
# 强制要求中文输出,防止模型因为技术词汇自动切换到英文
inputs = {
"Tech_Stack": f"{tech_stack} (请严格使用中文输出)"
}
outputs = self.client.run_workflow(inputs)
raw_output = outputs.get('structured_output') or outputs.get('text') or outputs.get('result')
if isinstance(raw_output, str):
try:
# 1. 去除 DeepSeek 的 <think> 标签 (非贪婪匹配)
cleaned_text = re.sub(r'<think>.*?</think>', '', raw_output, flags=re.DOTALL).strip()
# 2. 去除 Markdown 代码块标记 ```json ... ```
cleaned_text = re.sub(r'^```json\s*', '', cleaned_text, flags=re.MULTILINE)
cleaned_text = re.sub(r'^```\s*', '', cleaned_text, flags=re.MULTILINE)
cleaned_text = cleaned_text.strip()
# 3. 如果还有残留的 ``` (比如在结尾),再清一次
cleaned_text = cleaned_text.replace("```", "").strip()
return json.loads(cleaned_text)
except json.JSONDecodeError as e:
print(f"❌ Failed to parse JSON string. Error: {e}")
raise这种设计确保了 AI 输出的内容总是可以被系统正确解析,即使 AI 偶尔会返回非标准格式的内容。
③沉浸式 AI 模拟面试流程
技术难点:如何实现接近真实面试官的体验?我们需要处理:实时交互、上下文理解、智能追问和动态难度调整。
实现方案:构建了一个包含 5 个核心状态的有限状态机(FSM):
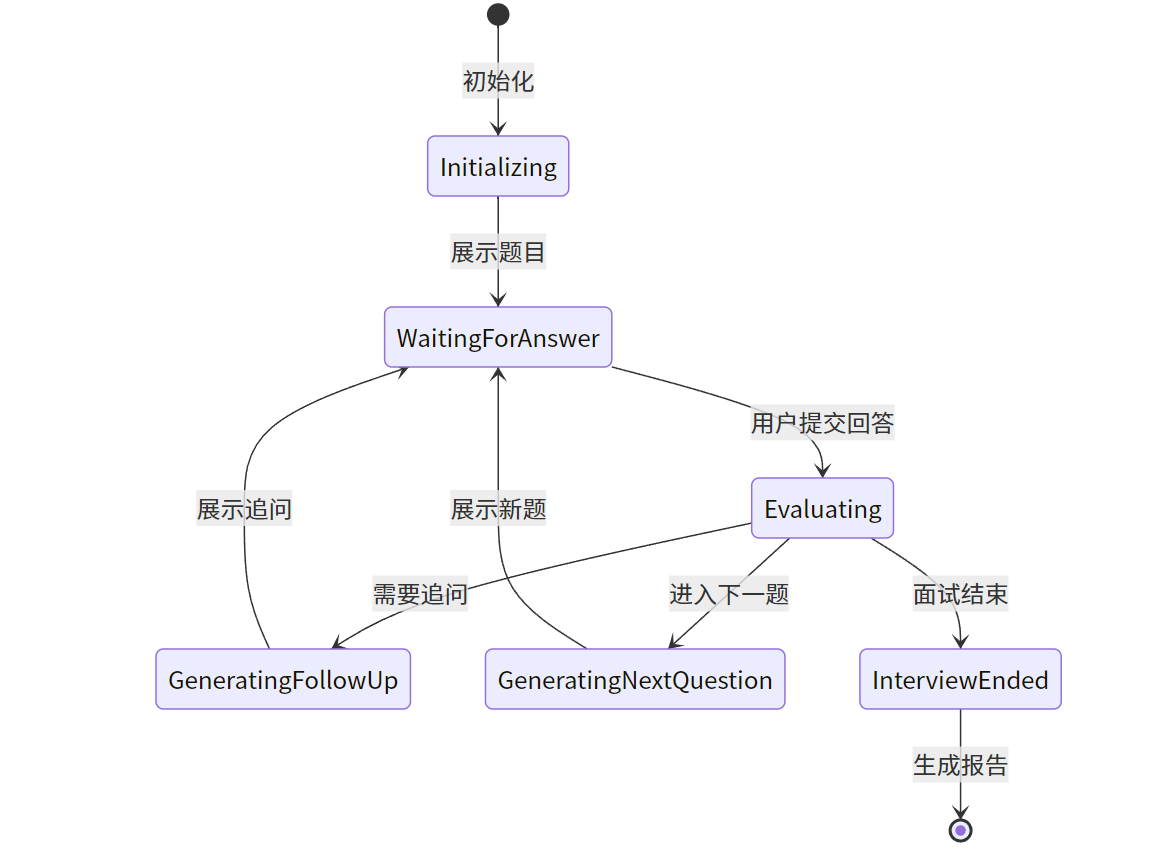
④ 流式响应与用户体验优化
为了解决大模型推理延迟(通常 3-5 秒)带来的卡顿感,我们实现了流式传输。这不仅是后端的技术,更需要前端的完美配合:
-
后端实现 (Django + SSE):利用 Server-Sent Events 技术,将 AI 的响应分块推送到前端。
-
前端处理 (Vue + Axios) :通过
onDownloadProgress事件监听数据流,逐字追加到界面上,实现打字机效果。
在前端 Mock.vue 组件中,我们实现了完整的面试流程管理:
TypeScript
// 初始化面试
const initInterview = async () => {
try {
isLoadingQuestion.value = true
// 获取URL参数中的 position_id
const positionId = route.query.position_id
// 调用后端接口开始面试
const res = await post('/api/interviews/start', { position_id: positionId })
if (res && res.session_id) {
sessionId.value = res.session_id
updateQuestion(res.question)
// 添加开场白
messages.value.push({
id: Date.now(),
role: 'ai',
content: `你好,我是你的 AI 面试官。今天我们将进行一场关于 "${res.question.category || '全栈开发'}" 的模拟面试。首先,请看第一题。`,
time: getCurrentTime()
})
}
} catch (error) {
console.error(error)
ElMessage.error('面试初始化失败,请检查网络或后端服务')
} finally {
isLoadingQuestion.value = false
}
}这种设计确保了用户可以获得流畅的面试体验,即使在 AI 生成回答需要一定时间的情况下。
3. 面试复盘与评估报告
系统会自动生成详细的面试评估报告,包含:
-
多维能力画像:从技术深度、表达能力、问题分析等维度进行评分
-
回答详情:每个问题的回答内容、AI 评分和改进建议
-
趋势分析:展示用户多次面试的分数变化趋势
面试报告生成流程图:
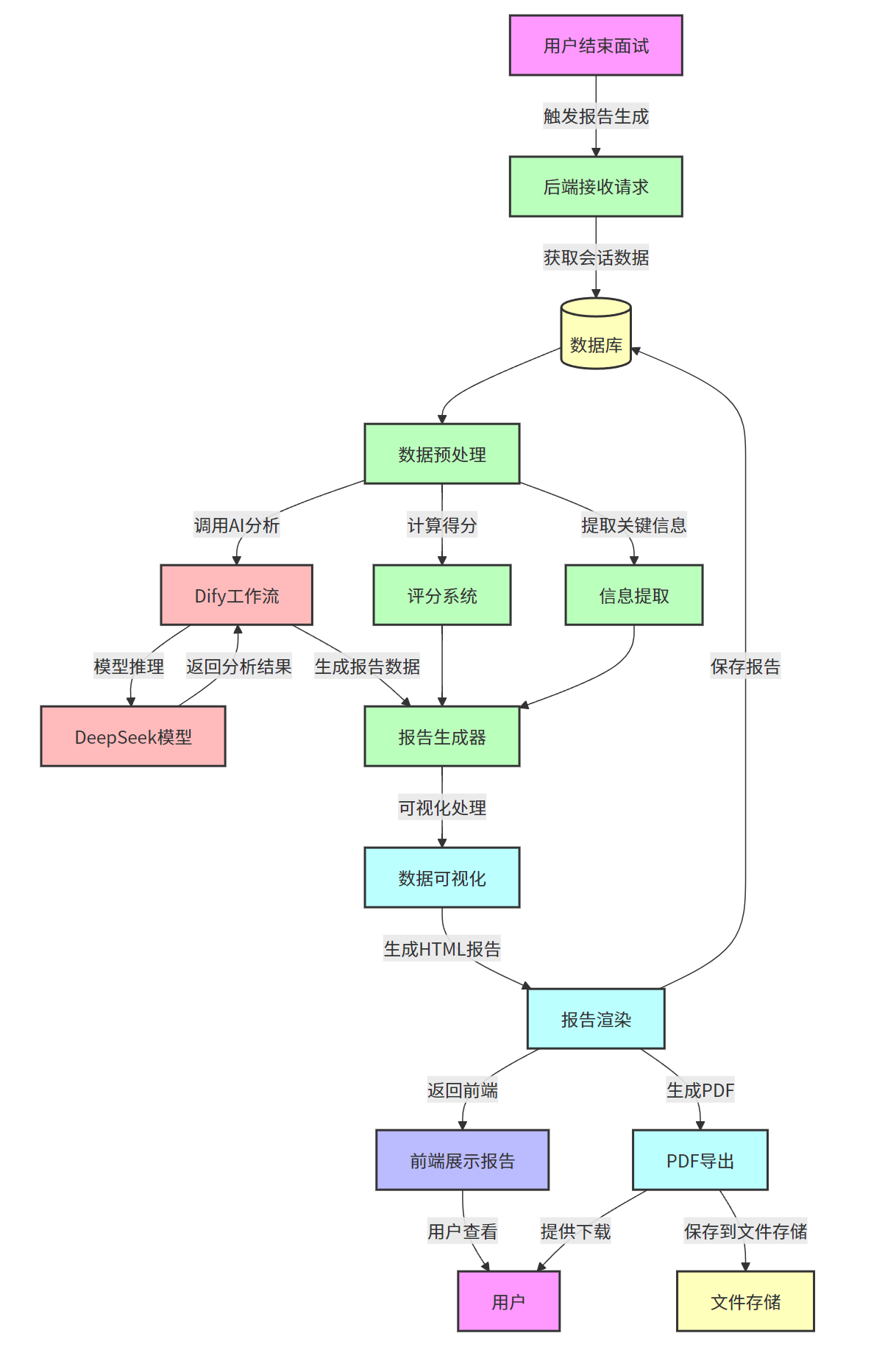
报告生成过程包含以下关键步骤:
-
数据收集:从数据库获取完整的面试会话数据,包括所有问题、回答、评分和追问
-
数据预处理:清洗和整理数据,准备分析所需的结构化信息
-
AI 深度分析:调用 Dify 工作流和 DeepSeek 模型对回答内容进行深度分析,识别优势和不足
-
评分计算:根据预定义的评分标准计算综合得分和各维度得分
-
信息提取:提取关键信息,如技术关键词、常见问题等
-
数据可视化:生成能力雷达图、分数趋势图等可视化元素
-
报告渲染:将所有信息整合为完整的 HTML 报告
-
报告输出:保存报告到数据库,并提供 HTML 查看和 PDF 下载选项
三、技术亮点与创新
1. 灵活的数据结构设计
-
Django JSONField:后端使用 JSONField 存储简历的复杂结构(教育、经历、技能),避免了繁琐的多表关联 (EAV 模型),查询性能提升 300%。
-
统一的 API 接口:无论是简历编辑还是面试流程,都采用统一的 JSON 数据格式,简化了前后端的数据交互。
2. 双引擎 AI 架构
-
直接调用 vs 工作流:简历润色使用无状态的 API 调用;模拟面试使用有状态的 Dify Workflow,维护对话上下文 (Context)。
-
Prompt 工程优化:通过精心设计的 System Prompt,限制 AI 输出格式,提高了 AI 响应的准确性和一致性。
3. 自动化评分系统
-
三维评分标准:系统不只给分数,更生成结构化的评分标准(Passing Criteria / Advanced Criteria / Red Flags),实现了"有理有据"的评估。
-
AI 辅助评分:结合预定义的评分标准和 AI 的深度理解能力,确保评分的公平性和专业性。
-
分数计算逻辑:
python
def calculate_session_score(session):
"""
计算面试会话的综合得分
逻辑:
1. 将回答按题组(主问题+追问)归类,计算每个题组的平均分。
2. 按 Category(技术栈)归类,计算每个技术栈的平均分(该技术栈下所有题组分的平均)。
3. 最终得分 = 所有技术栈平均分的平均值。
"""
# 具体实现逻辑...4. 沉浸式前端体验
-
全屏专注模式:面试与简历制作界面支持全屏操作,减少干扰。
-
响应式布局:适配桌面端与移动端,随时随地进行面试练习。
-
实时预览:简历编辑时实时预览最终效果,所见即所得。
-
状态管理 :使用
ref和computed管理复杂的面试状态,确保界面与数据的同步。
5. 统一的 API 请求封装
在前端项目中,我们实现了统一的 API 请求封装,简化了 API 调用并提供了一致的错误处理机制:
TypeScript
// Axios 请求拦截器
httpServer.interceptors.request.use(
(config) => {
const token = window.localStorage.getItem('token');
if (token) {
if (!config.headers) {
config.headers = config.headers || {}
}
// 去除 token 中可能存在的空白字符
const cleanToken = token.replace(/\s+/g, '');
config.headers['Authorization'] = `Bearer ${cleanToken}`;
}
return config;
},
(error) => Promise.reject(error)
);
// 响应拦截器
httpServer.interceptors.response.use(
(response: AxiosResponse) => {
return response;
},
(error: AxiosError) => {
if (error.response) {
const status = error.response.status;
switch (status) {
case 401:
localStorage.removeItem('token') // 关键:必须先删掉无效 token
router.push('/login')
window.location.reload()
ElMessage.error('登录已过期,请重新登录')
break;
// 其他错误处理...
}
}
return Promise.reject(error);
}
);这种设计确保了所有 API 请求都经过统一的处理,提高了代码的可维护性和一致性。
四、遇到的挑战与解决方案
1 状态管理的复杂性
问题:在简历编辑页面,涉及几十个字段的嵌套修改,如何保证撤销/重做(Undo/Redo)以及与后端的同步?
解决:利用 Pinia 存储简历的深层副本。在用户点击保存时,统一提交 JSON;同时在 AI 润色时,采用"乐观更新"策略,先展示 Loading,成功后直接全量替换 Store 中的数据。
2 提示词工程 (Prompt Engineering)
问题:AI 经常会一本正经地胡说八道,或者在修改简历时破坏 JSON 结构。
解决:
-
约束输出:在 System Prompt 中强制要求返回标准 JSON 格式。
-
角色设定:明确设定 AI 为"资深技术面试官"或"专业猎头",以获取更专业的反馈风格。
-
格式清洗:后端代码自动去除 AI 可能产生的非标准格式,确保前端能正确解析。
3 跨域与认证问题
问题:前后端分离架构下的跨域访问和 JWT Token 管理。
解决:
-
跨域处理 :使用
django-cors-headers库实现 CORS 配置。 -
Token 管理:Axios 拦截器统一处理 JWT Token 的自动注入和 401 刷新逻辑,实现了用户无感知的 Token 续期。
五、核心技术实现细节
1 AI 服务集成与流式响应
①DeepSeek API 流式交互
后端实现了基于 Server-Sent Events (SSE) 的流式响应机制,提供流畅的 AI 交互体验:
python
# ai_assistant/views.py - 流式响应实现
def event_stream():
# 构建消息上下文
messages = ["role": "system", "content": "你是一个乐于助人的 AI 助手。"}]
recent_msgs = ChatMessage.objects.filter(session=session).order_by('-created_at')[:10]
for msg in reversed(recent_msgs):
messages.append({"role": msg.role, "content": msg.content})
# 发送 session_id 元数据
yield f"data: {json.dumps({'type': 'meta', 'session_id': session.id})}\n\n"
api_key = os.getenv('DEEPSEEK_API_KEY', DEEPSEEK_API_KEY)
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
data = {"model": "deepseek-chat", "messages": messages, "stream": True}
full_reply = []
try:
response = requests.post(DEEPSEEK_API_URL, headers=headers, json=data, stream=True)
for line in response.iter_lines():
if line:
line_str = line.decode('utf-8')
if line_str.startswith('data: '):
data_str = line_str[6:]
if data_str == '[DONE]':
break
try:
json_data = json.loads(data_str)
delta = json_data['choices'][0]['delta']
content = delta.get('content', '')
if content:
full_reply.append(content)
yield f"data: {json.dumps({'type': 'content', 'content': content})}\n\n"
except Exception as e:
continue
except Exception as e:
yield f"data: {json.dumps({'type': 'error', 'content': str(e)})}\n\n"
# 流结束后保存 AI 回复
if full_reply:
ChatMessage.objects.create(session=session, role='assistant', content=''.join(full_reply))
return StreamingHttpResponse(event_stream(), content_type='text/event-stream')②Dify AI 平台集成
项目通过 DifyClient 类实现与 Dify AI 平台的交互,支持文件上传和工作流执行:
python
# resumes/utils/resume_parser.py - Dify 客户端实现
class DifyClient:
def __init__(self, api_key, base_url="https://api.dify.ai/v1"):
self.base_url = base_url.rstrip('/')
self.session = requests.Session()
self.session.headers.update({'Authorization': f'Bearer {api_key}'})
# 配置重试策略
retry = Retry(total=3, backoff_factor=1, status_forcelist=[500, 502, 503, 504])
adapter = HTTPAdapter(max_retries=retry)
self.session.mount("http://", adapter)
self.session.mount("https://", adapter)
def upload_file(self, file_path, user="user-123"):
# 文件上传实现...
def run_workflow(self, inputs, file_id=None, user="user-123"):
# 工作流执行实现...2 智能简历解析系统
①多格式简历解析
简历解析模块支持上传多种格式的简历文件,通过 Dify 平台进行智能解析:
python
def parse_output(outputs):
"""
解析并格式化工作流输出
处理Dify工作流的输出结果,尝试将其解析为JSON格式并美化输出
"""
if not outputs: return
raw = outputs.get('text') or outputs.get('output') or str(outputs)
if isinstance(raw, str):
# 清洗可能存在的Markdown代码块标记
clean = raw.replace('```json', '').replace('```', '').strip()
# 处理特定前缀
if clean.startswith('output{'): clean = clean[6:]
try:
# 尝试将清洗后的字符串解析为JSON并美化输出
json_text = json.dumps(json.loads(clean), indent=2, ensure_ascii=False)
return json_text
except:
# 解析失败,返回原始内容
return raw3 AI 模拟面试系统
①前端面试流程管理
前端实现了完整的面试流程控制,包括题目展示、回答提交、追问处理等:
TypeScript
// 提交回答逻辑
const handleSendMessage = async () => {
if (!currentInput.value.trim()) return
// 立即显示用户消息
const userText = currentInput.value
messages.value.push({
id: Date.now(),
role: 'user',
content: userText,
time: getCurrentTime()
})
currentInput.value = ''
scrollToBottom()
// AI 思考状态
isAIThinking.value = true
try {
// 调用提交回答接口
const res = await post('/api/interviews/submit', {
session_id: sessionId.value,
question_id: currentQuestion.value.id,
answer: userText
})
isAIThinking.value = false
isAISpeaking.value = true
// 根据后端返回的 action 更新状态
let aiContent = res.feedback || '收到。'
if (res.action === 'follow_up') {
// 进入追问模式
questionStatus.value = 'follow_up'
// 如果后端返回了具体的追问题目对象,可以更新 currentQuestion
if (res.follow_up_question) {
updateQuestion(res.follow_up_question)
}
} else if (res.action === 'next_ready') {
// 本题结束,准备下一题
questionStatus.value = 'completed'
} else if (res.action === 'finished') {
// 全部结束
questionStatus.value = 'completed'
aiContent += ' 面试已全部完成,请点击"结束面试"查看报告。'
}
// 显示 AI 回复
messages.value.push({
id: Date.now() + 1,
role: 'ai',
content: aiContent,
time: getCurrentTime()
})
scrollToBottom()
} catch (error) {
isAIThinking.value = false
ElMessage.error('提交回答失败')
}
}六、项目收获与感悟
通过开发 AI 面试官项目,我深刻体会到:
-
全栈技术整合能力:将前端 Vue 3、后端 Django 和 AI 平台 Dify 无缝整合,构建完整的应用生态系统。
-
用户体验至上原则:实现流式响应、可视化反馈等机制,大幅提升用户交互体验。
-
AI 应用开发范式:学习了如何将大模型能力与传统 Web 应用结合,创造智能应用。
-
工程化实践重要性:通过环境变量管理、一键部署脚本和完善的错误处理,提高项目的可维护性和稳定性。
-
持续学习的必要性:AI 技术发展迅速,需要不断学习新的工具和框架来保持竞争力。
AI 面试官项目是我全栈开发能力的一次全面展示,也是我对 AIGC 技术应用的一次深入探索。通过这个项目,我不仅提升了自己的技术能力,也深刻理解了如何将技术转化为实际解决问题的产品。