TL;DR
- 场景:Logstash 通过 Filter(重点 grok)把非结构化日志实时解析成结构化字段,便于后续写入 ES。
- 结论:Filter 顺序决定结果;grok 最强但最吃性能;用 rubydebug 做快速回归验证配置正确性。 -产出:两套可跑配置(stdin 提取日期、stdin 解析 Nginx access log)+ 常见故障定位/修复清单。

版本矩阵
| 项目 | 说明 |
|---|---|
| 已验证说明 | Logstash 7.3.0 |
| 示例路径与命令 | 基于 /opt/servers/logstash-7.3.0 |
| filter/grok 基础用法 | grok { match => { "message" => "..." } } + 命名捕获字段 |
| rubydebug 调试输出 | stdout { codec => rubydebug } 用于查看字段是否按预期生成 |
| -t 配置检查 | bin/logstash -f ... -t 用于启动前语法/插件检查 |
Filter插件
Logstash 是一个开源的服务器端数据处理管道工具,由 Elastic 公司开发和维护。它常用于从多种异构数据源(如日志文件、数据库、消息队列等)收集、处理并将数据规范化后发送到指定存储位置(如 Elasticsearch、MongoDB 等)。其架构主要包含三个核心组件:Input、Filter 和 Output,其中 Filter 插件是最具灵活性和功能强大的部分。
Filter 插件负责对传入的数据进行深度处理和转换,它位于 Logstash 管道的中间环节。具体工作流程是:首先接收来自输入 (Input) 的原始数据,然后通过一系列过滤器进行解析、增强和变换操作,最终将处理后的结构化数据传递给输出 (Output)。常见的 Filter 插件包括:
- grok - 使用正则表达式解析非结构化日志数据
- mutate - 修改字段内容,如重命名、删除或替换
- date - 解析日期字段并转换为标准时间戳
- geoip - 根据IP地址添加地理位置信息
- kv - 解析键值对格式的数据
Logstash 之所以在数据处理领域表现强悍,主要归功于其丰富多样的 Filter 插件生态系统。通过灵活组合不同的过滤器,我们可以实现复杂的ETL(提取-转换-加载)流程。例如,一个典型的日志处理流程可能包含:先用grok解析原始日志格式,然后用date处理时间戳,最后用mutate清理不必要的字段。这种模块化设计使得Logstash能够适应各种复杂的数据处理需求,将原始的非结构化数据转换为易于分析和查询的结构化格式。
在实际应用中,Filter 插件的组合使用可以实现诸如:日志标准化、数据脱敏、字段类型转换、多数据源关联等高级功能,这大大提升了数据的可用性和价值。
Filter 插件的功能
Filter 插件的核心任务是对日志或事件进行处理和转化,提供数据增强、清理和重新格式化的功能。它能够:
- 提取结构化数据:从非结构化数据中提取特定字段(如 JSON、CSV 等格式的日志)。
- 格式化数据:将字段转换为特定的数据类型或格式,例如将字符串转换为时间戳、数字等。
- 增强数据:通过添加额外信息或进行查询、匹配等操作来丰富日志数据(例如添加地理位置信息)。
- 过滤数据:根据特定条件筛选出需要或不需要的数据。
Filter 的注意事项
- 顺序执行:Filter 插件的顺序非常重要,Logstash 会按配置文件中的顺序依次执行每个插件。因此,确保顺序符合数据处理逻辑。
- 性能优化:在处理大规模日志时,某些复杂的 Filter(如 grok)可能影响性能,需要结合其他插件(如 mutate)优化处理流程。
- 测试和调试:使用 stdout { codec => rubydebug } 或类似工具测试 Filter 结果,确保数据处理符合预期。
grok正则表达式
grok正则表达式是Logstash非常重要的一个环境,可以通过grok非常方便的将数据拆分和索引。 语法格式:
shell
(?<name>pattern)
?<name>表示要取出里面的值,pattern就是正则表达式控制台数据收集
需求描述
收集控制台输入数据,采集日期时间出来。
编写配置
shell
cd /opt/servers/logstash-7.3.0/config
vim filter.conf写入的如下:
shell
input {stdin{}}
filter {
grok {
match => {
"message" => "(?<date>\d+\.\d+)\s+"
}
}
}
output {stdout{codec => rubydebug}}写入的内容如下图所示: 
检查配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/filter.conf -t执行的结果如下图所示: 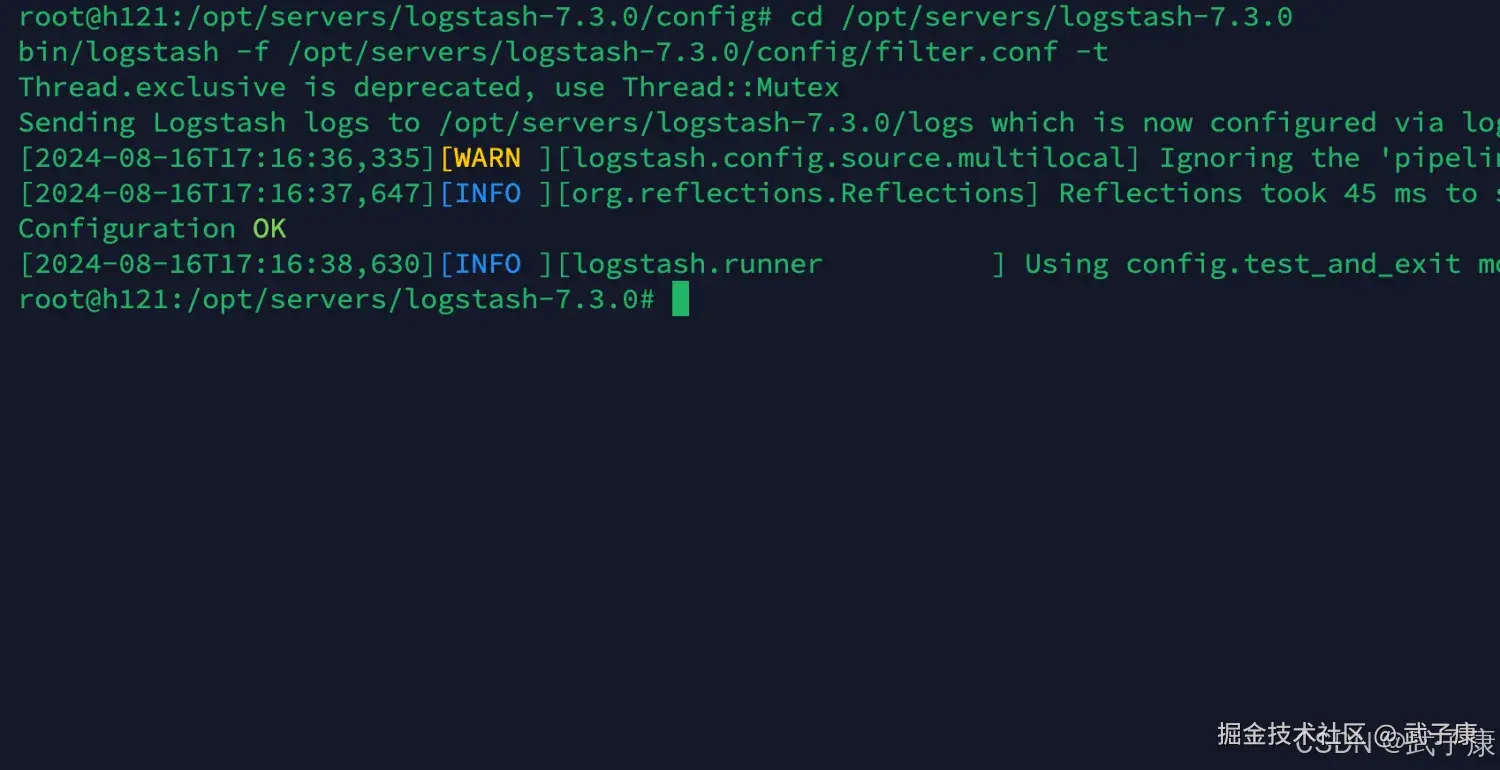
启动服务
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/filter.conf在控制台输入: "hello world",可以看到结果如下图所示: 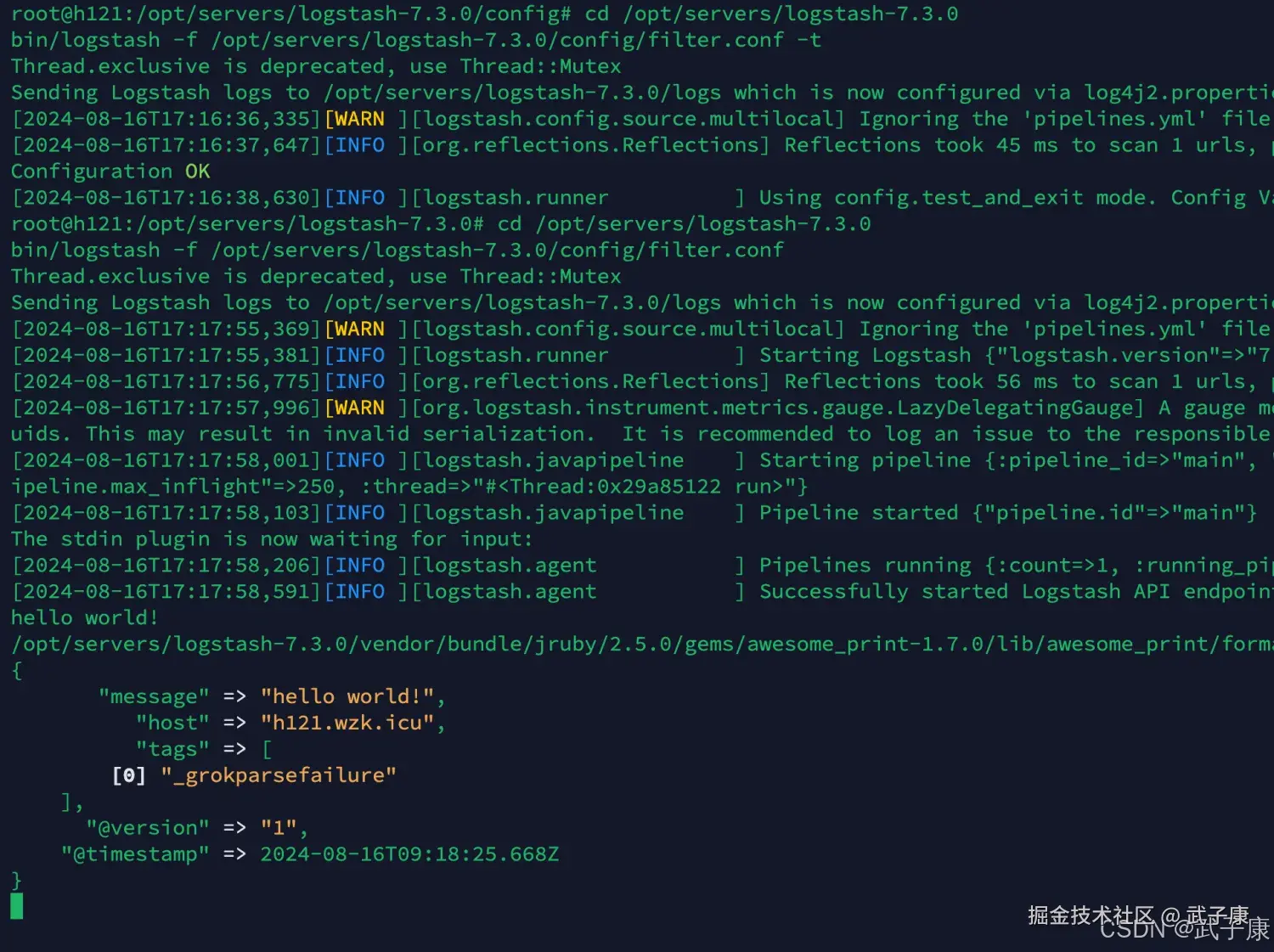
grok收集Nginx日志
需求描述
Nginx的访问日志通常采用CLF(Common Log Format)或扩展的CLF格式,这是一种非结构化的文本数据。典型的日志条目包含以下信息:
shell
36.157.150.1 - - [05/Nov/2019:12:59:28 +0800] "GET
/phpmyadmin_8c1019c9c0de7a0f/js/get_scripts.js.php?scripts%5B%5D=jquery/jquery-
1.11.1.min.js&scripts%5B%5D=sprintf.js&scripts%5B%5D=ajax.js&scripts%5B%5D=keyhandler.js&scr
ipts%5B%5D=jquery/jquery-ui-
1.11.2.min.js&scripts%5B%5D=jquery/jquery.cookie.js&scripts%5B%5D=jquery/jquery.mousewheel.j
s&scripts%5B%5D=jquery/jquery.event.drag-2.2.js&scripts%5B%5D=jquery/jquery-ui-timepickeraddon.js&scripts%5B%5D=jquery/jquery.ba-hashchange-1.3.js HTTP/1.1" 200 139613 "-"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/45.0.2454.101 Safari/537.36"这个日志记录包含以下关键字段:
- 客户端IP地址
- 访问时间戳(包含时区)
- HTTP请求方法(GET/POST等)
- 请求的URL路径和查询参数
- HTTP协议版本
- 响应状态码
- 响应大小(字节数)
- 引用来源
- 用户代理信息
传统的数据处理流程是:
- 使用Hadoop MapReduce或Apache Spark等大数据处理框架
- 编写解析代码将非结构化日志转换为结构化数据
- 处理大规模数据时,这个过程可能耗时数小时甚至更久
更高效的解决方案是使用Logstash的grok功能:
- Grok是一种强大的日志解析引擎,内置120+种常用模式
- 可以定义自定义模式来匹配特定的日志格式
- 对于Nginx日志,可以使用以下grok模式:
css
%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} (?:%{NUMBER:bytes}|-) (?:%{QS:referrer}|-) %{QS:useragent}- 处理流程:
- 配置Logstash输入插件读取Nginx日志文件
- 使用grok过滤器解析日志内容
- 输出结构化数据到Elasticsearch或其他存储系统
这种方法相比传统大数据处理方案的优势:
- 实时处理能力:日志产生后立即处理
- 资源消耗低:不需要启动大规模计算集群
- 配置灵活:可以随时调整解析规则
- 与ELK(Elasticsearch, Logstash, Kibana)生态无缝集成
典型应用场景:
- 实时监控网站访问情况
- 快速识别异常请求
- 即时分析用户行为
- 安全审计和攻击检测
安装插件
shell
cd /opt/servers/logstash-7.3.0
bin/logstash-plugin install Logstash-filter-grok可以看到安装结果如下图所示: 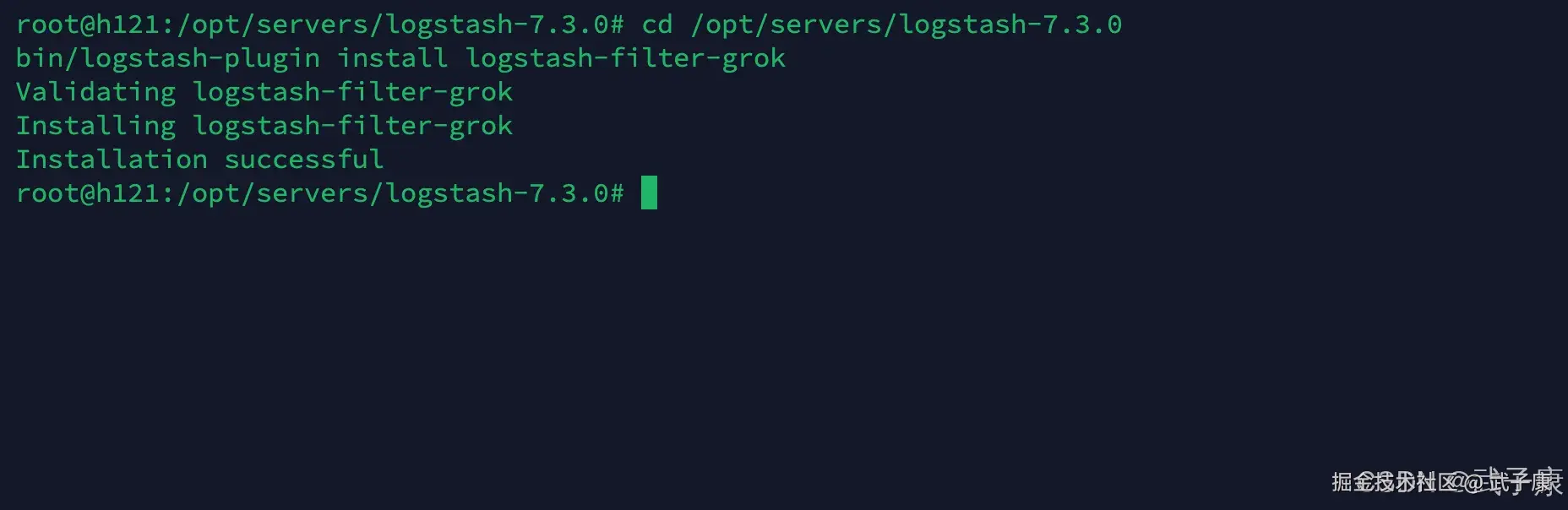
编写配置
定义Logstash的配置文件如下,我们从控制台输入Nginx的日志数据,然后经过Filter的过滤,将我们的日志文件转换为标准的数据格式:
shell
cd /opt/servers/logstash-7.3.0/config
vim monitor_nginx.conf写入的内容如下:
shell
input {
stdin {}
}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} \- \- \[%{HTTPDATE:time_local}\] \"(?:%{WORD:method} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent}"
}
}
}
output {
stdout {
codec => rubydebug
}
}写入的内容如下图所示: 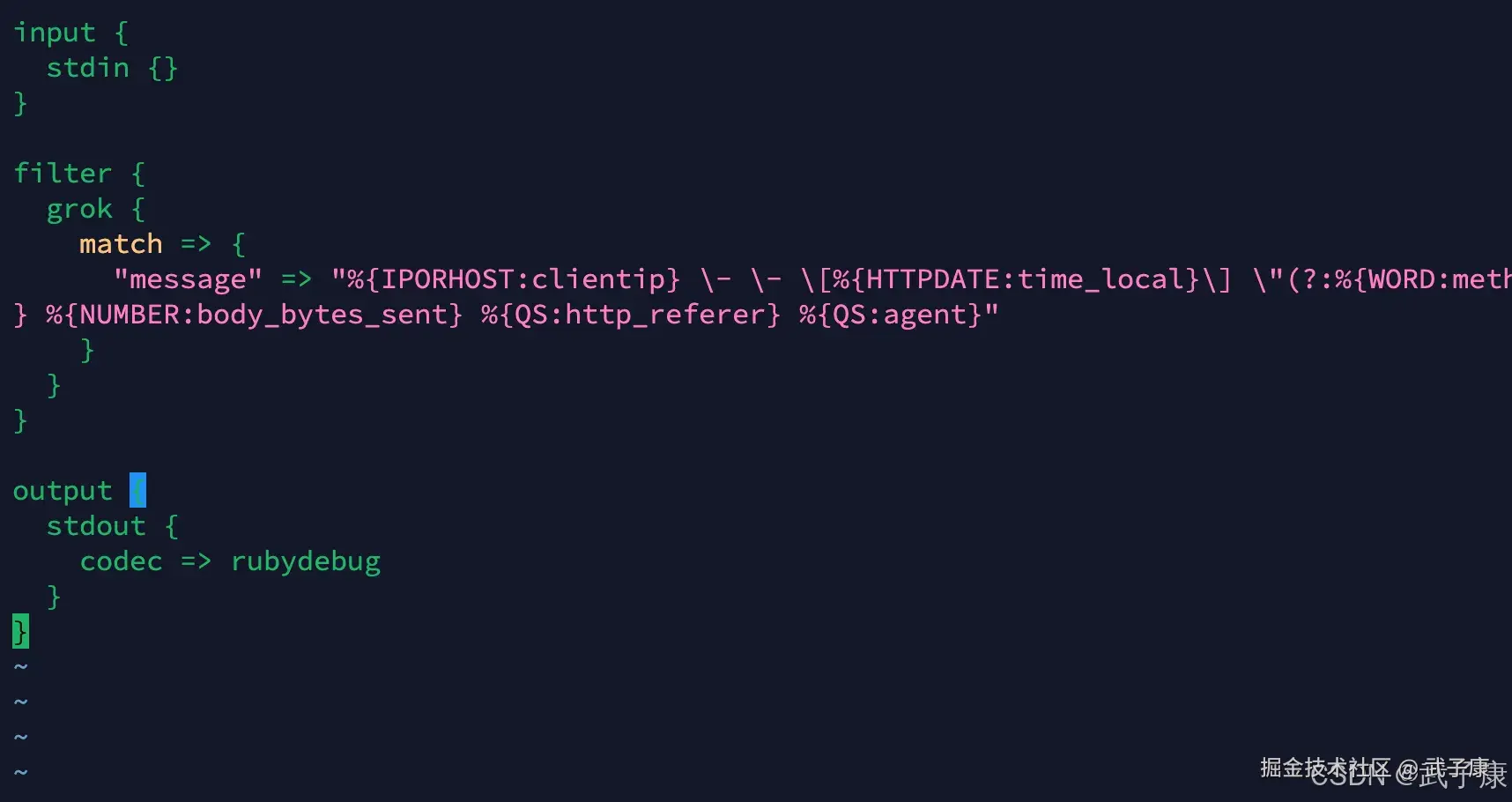
检查配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/monitor_nginx.conf -t检查结果如下图所示: 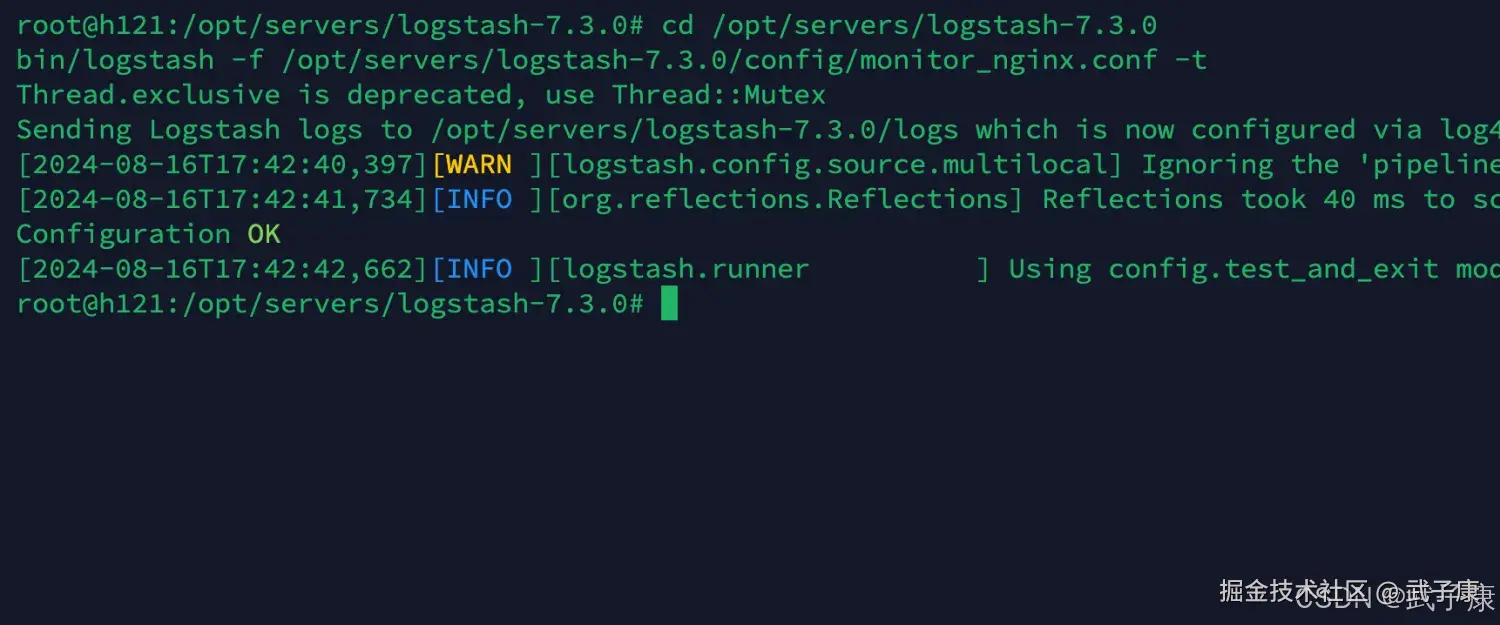
启动配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/monitor_nginx.conf启动结果如下图所示: 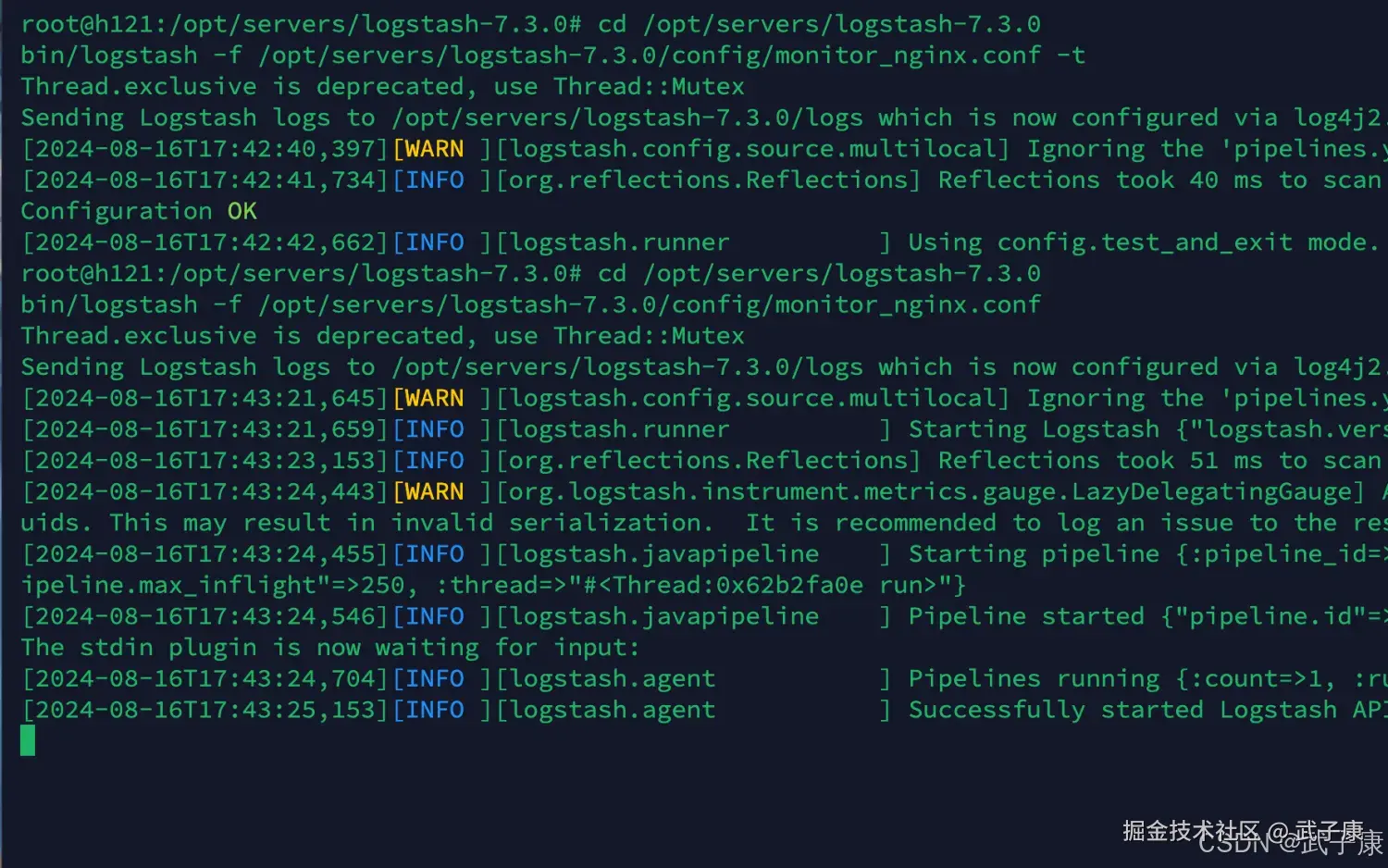
测试数据
在控制台中输入如下的数据:
shell
113.31.119.183 - - [05/Nov/2019:12:59:27 +0800] "GET
/phpmyadmin_8c1019c9c0de7a0f/js/messages.php?
lang=zh_CN&db=&collation_connection=utf8_unicode_ci&token=6a44d72481633c90bffcfd42f11e25a1
HTTP/1.1" 200 8131 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/45.0.2454.101 Safari/537.36"可以看到控制台解析出了内容如下所示: 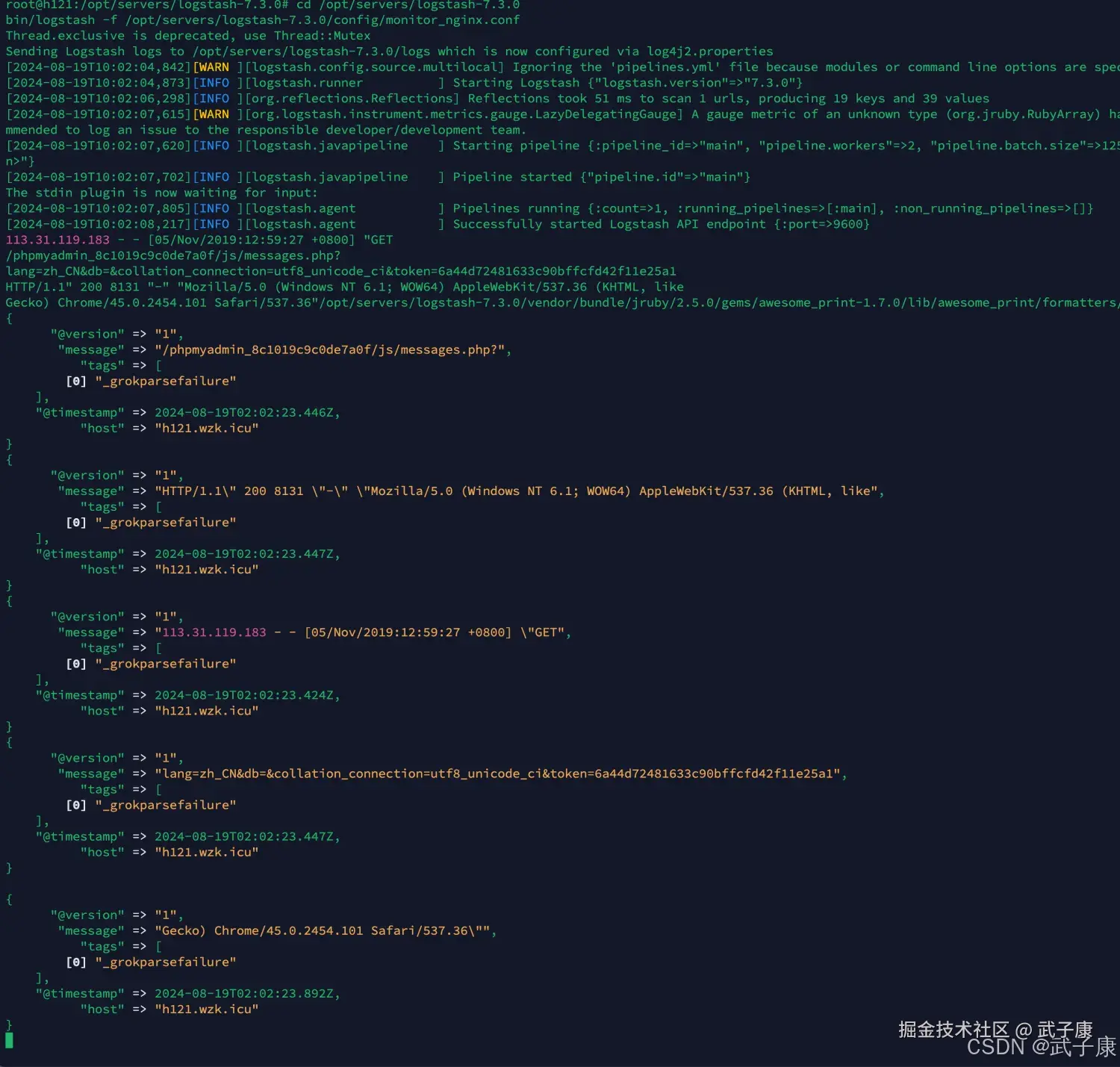
错误速查
| 症状 | 根因定位 | 修复方案 |
|---|---|---|
启动 -t 通过,但运行后字段没解析出来 |
grok 未命中(日志格式与 pattern 不一致、转义错误、空格/引号差异) | 看 rubydebug 输出里是否存在 _grokparsefailure tag;对照原始 message 调整 pattern:先用更宽松的 %{DATA} 分段定位,再逐段收紧;对 [ ] " - 做正确转义 |
| 控制台输入多行 Nginx 日志时解析结果混乱 | stdin 每行一条 event,多行会拆成多个 message | 观察 rubydebug 中 message 是否被断行切开 确保测试输入为单行 access log;或改用 file 输入 + multiline(若确有多行事件需求) |
| grok 正则性能差,CPU 飙高/吞吐下降 | pattern 过于贪婪、回溯严重(DATA/GREEDYDATA 乱用),字段过多 | 开启 pipeline metrics/观察处理速率;逐步注释 filter 找瓶颈 减少 GREEDYDATA;拆成两段 grok;先用条件过滤缩小命中范围;固定分隔符优先用 NOTSPACE/WORD |
| 解析出的时间字段无法用于时间轴/排序 | 只提取字符串未做 date 规范化 | rubydebug 看字段类型仍是字符串 在 grok 后追加 date { match => ["time_local","dd/MMM/yyyy:HH:mm:ss Z"] target => "@timestamp" }(保持字段命名一致) |
bin/logstash-plugin install ... 安装失败或提示找不到插件 |
插件名大小写/拼写不规范或网络/仓库问题 | 查看安装输出错误;`bin/logstash-plugin list |
| Nginx grok 模式对少数字段(referer/agent)解析错位 | 引号内包含异常字符或字段缺失(-)导致匹配偏移 | 对比原始日志中 referer/agent 是否为 - 或包含引号 用非捕获分支兼容 -:(?:\%{QS:http_referer} |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解