注:该文用于个人学习记录和知识交流,如有不足,欢迎指点。
一、指针和内存大小对齐是什么?
1. 内存分配时的指针对齐(必须):也称为内存对齐
- 结论 :malloc/posix_memalign 等分配函数返回的指针,必须对齐(无例外)。
- 核心依据 :
① 硬件底层:CPU 无法安全 / 高效访问非对齐地址(x86 性能暴跌,ARM 直接崩溃);
② C 语言标准强制要求,所有合规的内存分配函数都需满足。 - 补充:默认对齐粒度(32 位系统 8 字节,64 位 16 字节),posix_memalign 可手动指定更大粒度(如内存池可用 32 / 64字节)。
2. 内存访问时的指针对齐(看场景)
- 结论:访问指针不是 "绝对必须对齐",取决于「数据类型 + CPU 架构」。
- 核心依据 :
- 访问 char(1 字节):任何地址都满足 1 字节对齐,无需额外要求;
- 访问 int(4 字节)/double(8 字节):x86 非对齐可访问但性能暴跌(可能跨缓存行),ARM 非对齐直接崩溃;
- 本质:对齐要求 = CPU "原生访问粒度"(如 char对应1字节,int 对应 4 字节,double 对应 8 字节)。
3. 内存大小对齐(非必须,纯优化)
- 结论:内存大小无需强制对齐,仅高性能场景(内存池 / SIMD/DMA)需要。
- 核心依据 :
- 普通场景:malloc (4) 大小就是 4 字节,系统靠 "内部碎片" 管理,不影响访问;
- 优化场景:大小对齐到缓存行(32/64 字节),能让内存块结束地址落在对齐边界,后续分配无碎片,且数据不跨缓存行。
4. 缓存行与内存访问的关系(性能补充)
- 结论:缓存行是 "缓存↔内存" 的传输单位(32/64 字节),和 "指针 / 大小对齐" 是互补关系,而非冲突。
- 核心依据 :
① CPU 访问内存时,先按缓存行批量加载数据到缓存(不管数据大小,比如读 1 字节 char 也会加载整行);
② 再从缓存按 "数据类型粒度"(如 char1 字节、int4 字节)读取到 CPU,对齐的指针能让这一步无额外拆分开销。
总结
- 分配指针:必须对齐(硬件 + 标准要求);
- 访问指针:char 随便,int/double 建议对齐(x86 慢、ARM 崩);
- 内存大小:不用对齐,高性能场景对齐到缓存行更优;
- 缓存行:批量加载数据的单位,对齐能让缓存访问无额外开销。
疑问:
问1:原生访问粒度是什么?
| 核心维度 | 具体说明 |
|---|---|
| 定义 | CPU 从缓存 / 内存读取单个基础数据类型时,硬件层面的最小字节单位(由 CPU 架构 + 数据类型决定)。 |
| 本质 | CPU 指令操作数据的 "天然粒度",是硬件级的访问规则,而非软件层面的优化。 |
| 典型示例(x86) | char→1 字节、int→4 字节、double→8 字节(和数据类型的大小 / 对齐要求完全一致)。 |
| 关键关联 | 访问指针需匹配对应数据类型的原生访问粒度(即对齐),否则 x86 性能可能暴跌、ARM 直接崩溃; |
tips:对齐表示是整数倍的意思
问2:内存分配时的指针对齐,跟内存访问时的指针对齐规则不同:
| 对比维度 | 内存分配时的指针对齐 | 内存访问时的指针对齐 |
|---|---|---|
| 规则目标 | 兜底性要求,保证指针适配所有数据类型的访问基础 | 精准性要求,仅匹配当前访问的数据类型需求 |
| 对齐粒度 | 统一粗粒度(32 位 8 字节 / 64 位 16 字节,或手动指定如 32 字节) | 按需细粒度(char=1 字节、int=4 字节、double=8 字节,随数据类型变化) |
| 强制程度 | 绝对强制(malloc/posix_memalign 等函数必满足,违反则分配失败 / 行为未定义) | 非绝对强制(在x86中): -char 无对齐限制; -int/double 非对齐访问不导致程序崩溃: 比如x86中: char arr1024; *(int*)(&arr1) = 5; |
| 违规后果 | 直接导致内存分配失败(如 posix_memalign 返回错误码)或指针不可用 | x86:仅性能暴跌(针对 int/double,可能存在跨行读取); ARM:直接崩溃(针对 int/double); char 无任何后果 |
问3:结构体中隐含的指针对齐
- 成员级对齐:结构体每个成员按自身类型的对齐要求对齐(如 int→4 字节、double→8 字节),编译器会在成员间补 "填充字节";
- 整体级对齐:结构体总大小向上对齐到 "最大成员对齐数" 的整数倍,保证结构体数组访问时每个元素都对齐
cpp
#include <stdio.h>
#include <stddef.h> // 用于offsetof宏验证偏移量
// 核心结构体:数组前/后都补填充,结构体末尾也补填充
struct AlignFullExample {
// 成员1:char(触发数组前填充)
char c; // 对齐数=1,占0x00(1字节)
// 数组前补3字节填充(0x01~0x03)→ 让int数组满足4字节对齐
// 核心:int数组(前后都有填充)
int arr[2]; // 对齐数=4,起始0x04,占0x04~0x0B(2×4=8字节,内部连续无填充)
// 数组后补4字节填充(0x0C~0x0F)→ 让double满足8字节对齐
// 成员2:double(触发数组后填充)
double d; // 对齐数=8,起始0x10,占0x10~0x17(8字节)
// 成员3:char(触发结构体末尾填充)
char e; // 对齐数=1,起始0x18,占0x18(1字节)
// 结构体末尾补7字节填充(0x19~0x1F)→ 让总大小对齐到最大对齐数8
};
int main() {
// 验证各成员的内存偏移量(起始地址)
printf("=== 成员偏移量(字节)===\n");
printf("char c : %zu\n", offsetof(struct AlignFullExample, c));
printf("int arr[2] : %zu\n", offsetof(struct AlignFullExample, arr));
printf("double d : %zu\n", offsetof(struct AlignFullExample, d));
printf("char e : %zu\n", offsetof(struct AlignFullExample, e));
// 验证结构体总大小
printf("=== 结构体总大小 ===\n");
printf("AlignFullExample size: %zu 字节\n", sizeof(struct AlignFullExample));
return 0;
}sizeof(struct AlignFullExample )会得到 32 !
问4:CPU跨缓存行读取时什么意思?
当你要访问的数据跨越了两个缓存行的边界 时,CPU 需要从内存加载两个缓存行才能拿到完整数据,这种情况就叫 "跨行读取"。
举例(缓存行 = 64 字节):
- 缓存行 1 范围:0x1000 ~ 0x1040 (不含0x1040)
- 缓存行 2 范围:0x1040 ~ 0x1080
- 若要访问的数据是 "0x103C ~ 0x1043"(比如一个 8 字节的 double,0x103C 不对齐8字节:x86不会崩溃,ARM会崩溃),这个数据同时占了缓存行 1 和缓存行 2 → CPU 必须加载这两个缓存行,就是 "跨行读取"。
- 若要访问的数据是 "0x103C ~ 0x1040"(比如一个 4 字节的 int,0x103C 对齐4字节:x86和ARM都不会崩溃),这个数据同时占了缓存行 1 和缓存行 2 → CPU 必须加载这两个缓存行,就是 "跨行读取"。
cpp
#include <stdio.h>
#include <stdint.h>
// 强制按64字节对齐(保证起始地址是64的整数倍,先锚定缓存行边界)
__attribute__((aligned(64))) char buf[128];
int main() {
// 1. 确定缓存行边界:buf起始地址=0x1000(64字节对齐),
// 缓存行1:0x1000 ~ 0x1040,缓存行2:0x1040 ~ 0x1080
// 2. 取跨缓存行的对齐地址:0x103C(4字节对齐,满足int访问要求)
uint32_t* ptr = (uint32_t*)(buf + 60); // buf+60 = 0x1000 + 60 = 0x103C
// 3. 跨行读取:ptr指向的int(4字节)范围是0x103C ~ 0x1040,
// 前3字节在缓存行1(0x103C~0x1040),最后1字节在缓存行2(0x1040)
*ptr = 0x12345678; // 写入操作,触发跨行读取+写入
printf("写入值:0x%x\n", *ptr); // 读取验证
return 0;
}二、内存池是什么?
内存池(Memory Pool)是一种预分配 + 复用的内存管理机制:
- 程序启动 / 初始化阶段,提前向操作系统申请一块连续的大块内存(内存池);
- 后续程序需要分配内存时,直接从内存池中 "切割" 小块使用,无需频繁调用系统调用(如
malloc/free、new/delete); - 内存释放时,并非立即归还给操作系统,而是放回内存池的空闲列表,供后续复用;
- 当内存池耗尽时,可按需扩容(再次向系统申请大块内存);程序退出时,一次性释放整个内存池。
本质是将 "频繁的小内存系统调用" 转化为 "用户态的内存块复用",核心目标是提升效率、减少碎片。
三、内存池解决了什么问题?
频繁使用malloc/free等原生内存分配方式会带来以下问题,内存池可针对性解决:
| 问题类型 | 原生分配的痛点 | 内存池的解决方案 |
|---|---|---|
| 内存碎片 | 频繁分配 / 释放不同大小的内存块,会导致内存空间被分割成大量不连续的小碎片(外部碎片),即使总空闲内存足够,也无法分配大块连续内存 | 预分配大块连续内存,内部按规则分割 / 复用,避免内存空间碎片化;定长池甚至可完全消除外部碎片 |
| 分配效率低 | malloc/free需要陷入内核态(系统调用),且需遍历空闲链表、计算分配位置,频繁调用开销极大 |
内存池的分配 / 释放是用户态操作(仅操作空闲链表指针),无需内核态切换,效率提升 10~100 倍 |
| 缓存友好性差 | 原生分配的内存地址随机,CPU 缓存命中率低 | 预分配的连续内存更符合 CPU 缓存的局部性原理,提升内存访问速度 |
| 内存泄漏难排查 | 原生分配的内存分散,难以跟踪分配 / 释放轨迹 | 内存池可统一管理所有分配的内存块,便于统计、监控、排查泄漏 |
| 分配粒度失控 | 原生分配可能因对齐、元数据占用导致实际分配内存大于需求(如分配 1B 实际占 8B) | 可定制化分配粒度(如定长池严格按固定大小分配),减少内存浪费 |
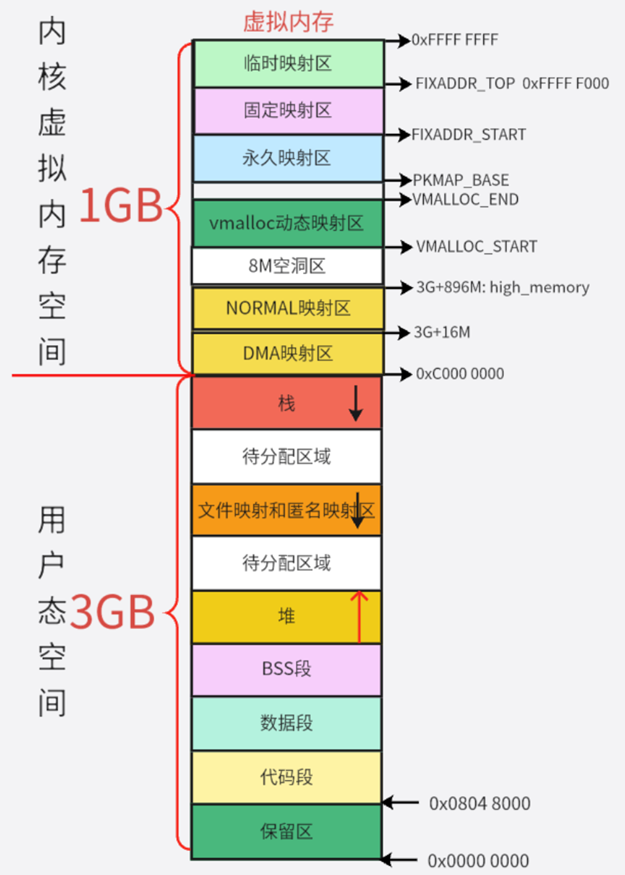
虚拟内存:
四、内存池的实现
(一)等长内存池
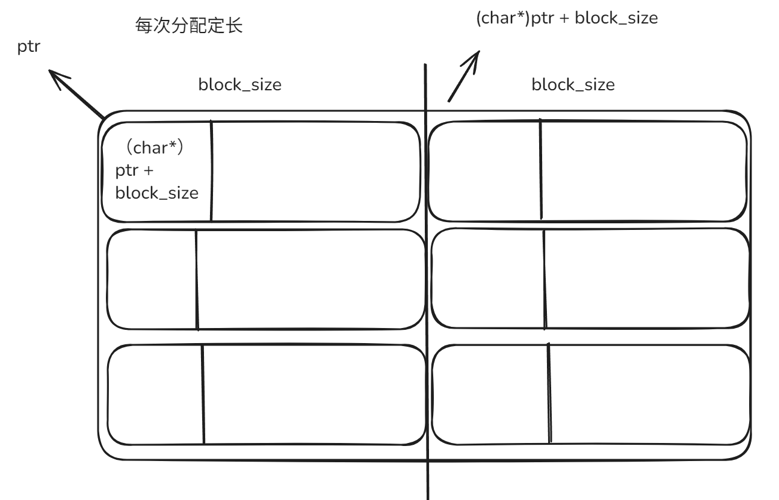
- 频繁分配 / 释放固定大小的对象(如链表节点、线程池任务、网络连接对象),是最简单、最高效的内存池实现。
- 每次分配相同大小的内存块
疑问:
问1:怎么知道下一块可用内存的地址?
内存块的前8/4个字节(指针大小)存放下一块可用的内存块起始地址。
cpp
*(char **)ptr = (char*)ptr + block_size;问2:释放完的内存块如何再次使用?
释放完之后,将当前内存块的首部指向free_ptr,然后将free_ptr指向当前内存块
cpp
void memp_free(mempool_t *m, void *ptr)
{
*(char **)ptr = m->free_ptr;
m->free_ptr = (char *)ptr;
m->freecount++;
}问3:block_size 应该取多大?
答:依据内存对齐规则:取2的n次幂,最小取8。
(二)大小块分配的内存池
- 小块:小于内存页(MP_PAGE_SIZE:4096)
- 大块:大于等于内存页,直接调用malloc分配
malloc会直接调用mmap分配整页内存(无碎片、管理简单)。
1. 内存地址对齐:
cpp
/**
* 指针对齐宏:将指针p按alignment字节对齐(转换为size_t计算后转回void*)
* 作用:保证分配的内存地址是对齐数的整数倍,提升访问效率
*/
#define mp_align_ptr(p, alignment) (void *)((((size_t)p) + (alignment - 1)) & ~(alignment - 1))2. 内存分配大小对齐:(指针对齐了,内存大小的分配也跟着对齐了,毕竟后面也用不到)
cpp
/**
* 数值对齐宏:将数值n向上取整到alignment的整数倍
* 原理:(n + 对齐数-1) 抵消余数,再 & ~(对齐数-1) 清零余数位
* 示例:mp_align(24,32) = (24+31) & ~31 = 55 & 0xffffffe0 = 32
*/
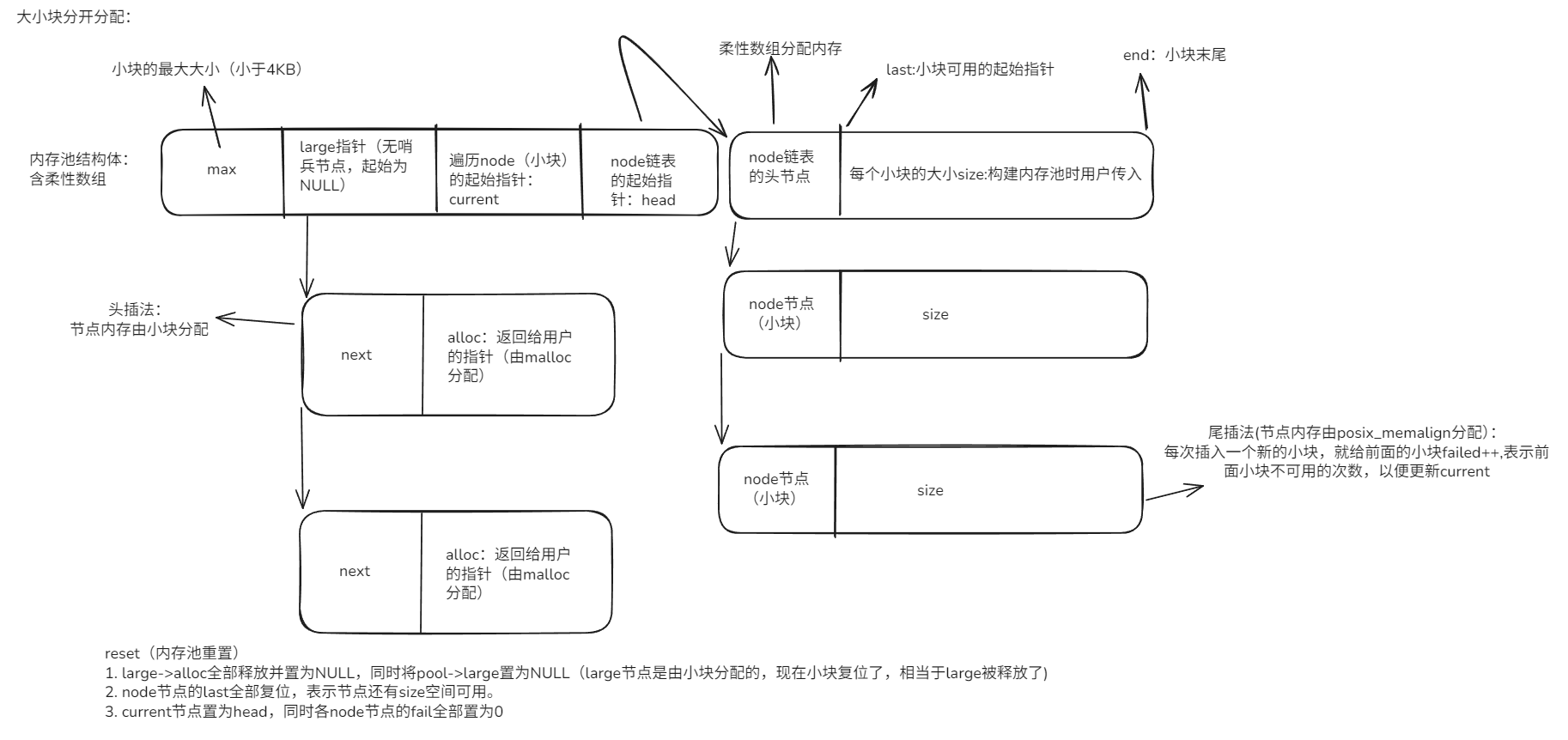
#define mp_align(n, alignment) (((n) + (alignment - 1)) & ~(alignment - 1))3. 小块结构体
| 字段名 | 字段类型 | 核心含义 |
|---|---|---|
last |
unsigned char * |
当前内存页中已分配内存的末尾地址(下一次小内存分配的起始位置) |
end |
unsigned char * |
当前内存页的结束地址 (内存页最大可用地址,end - last为剩余可用空间) |
next |
struct mp_node_s * |
链表指针,串联多个小内存页(首个页不足时新建页) |
failed |
size_t |
当前小块分配失败次数(没有足够的可用空间提供给外部):失败>4 次时,后续遍历小块分配跳过小块(提升遍历效率) |
4. 大块结构体
| 字段名 | 字段类型 | 核心含义 |
|---|---|---|
next |
struct mp_large_s * |
链表指针,串联所有大内存块管理节点(复用节点,避免频繁 malloc/free) |
alloc |
void * |
指向通过malloc分配的大内存块(>4095 字节)的起始地址 |
大块结构体创建所需内存由小块提供, alloc指向的内存由malloc提供
5. 内存池结构体
| 字段名 | 字段类型 | 核心含义 |
|---|---|---|
max |
size_t |
小内存块最大阈值(取创建时指定size和4095的较小值) |
current |
struct mp_node_s * |
指向当前可分配小内存的页节点(优化分配效率,避免从头遍历) |
large |
struct mp_large_s * |
指向大内存块管理链表的头节点 |
head[0] |
struct mp_node_s |
柔性数组,指向首个小内存页节点(内存池创建时初始化的第一个页) |
疑问:
问1:指针要对齐?
1. 极致提升 CPU 访问效率(内存池的核心诉求)
内存池的典型场景是「高频分配、高频访问」(比如 Nginx 每秒处理数万请求,每个请求都要分配 / 访问内存),而 CPU 访问内存的效率完全依赖地址对齐:
- CPU 读取内存不是 "逐字节",而是按「缓存行 / 字长」批量读取(比如 64 位 CPU 一次读 8 字节,AVX2 指令一次读 32 字节);
- 若指针地址是 32 字节对齐(MP_ALIGNMENT=32):CPU 一次就能读取完整的 32 字节数据,无需拼接;
- 若地址不对齐:CPU 需要读 2 次内存,再拼接数据,耗时翻倍(高频场景下,这个损耗会被无限放大)。
举个具体例子(缓存行为32字节的情况下):
- 地址 = 0x1000(32 对齐):读 32 字节 → 1 次完成;
- 地址 = 0x1008(非 32 对齐):读 32 字节需要从 0x1008 读到 0x1028 → 跨 2 个 32 字节块,CPU 读 2 次 + 拼接,耗时翻倍。
2. 满足硬件 / 指令的强制要求
内存池常被用于需要和硬件交互的场景(如网络编程、音视频处理):
- SIMD 指令(如 Intel AVX2、ARM NEON):强制要求内存地址是 32/64 字节对齐,否则指令执行失败;
- DMA 控制器(网卡 / 磁盘 IO):从内存读取数据时,要求地址是 32 字节对齐,否则拒绝传输;
- 多核缓存:对齐的地址更容易命中 CPU 缓存(缓存行通常是 32/64 字节),进一步提升性能。
- 不对齐访问:ARM会崩溃
如果指针地址不对齐,这些硬件 / 指令会直接报错,程序崩溃 ------ 这不是 "性能问题",而是 "可用性问题"。
问2:alignment的取值:
| 维度 | 8 字节对齐 (malloc默认) | 16 字节对齐 | 32 字节对齐 | 64 字节对齐 |
| CPU 访问效率 | 满足 64 位 CPU 基础字长(8 字节),普通访问高效;但跨缓存行概率高 | 匹配部分 CPU 缓存行(16 字节),缓存命中率略高 | 匹配主流 CPU 缓存行(32 字节),缓存命中率最高(数据小于32字节时,无跨行) | 匹配高端 CPU 缓存行(64 字节),极致缓存效率;但小数据也占整行 |
| 内存利用率 | 最高(碎片最少):分配 10 字节仅浪费 6 字节 | 较高:分配 10 字节浪费 6 字节,24 字节浪费 8 字节 | 中等:分配 10/24 字节均浪费 22 字节 | 最低(碎片最多):分配 10/24/32 字节均浪费 54/40/32 字节 |
| 硬件兼容性 | 仅满足基础要求(x86 普通程序);不支持 SIMD / 高端 DMA | 支持部分 ARM 架构 / 简单 DMA;不支持 AVX2 | 支持主流 SIMD(AVX2)、DMA(网卡 / 磁盘)、ARM 高性能场景 | 支持极致硬件(AVX512、高端显卡 / AI 芯片);兼容性最全 |
| 代码复杂度 | 无额外复杂度 | 无额外复杂度 | 无额外复杂度 | 无额外复杂度 |
| 典型适用场景 | 普通小程序、嵌入式低内存场景 | 一般高性能程序(如普通后台服务) | 主流高性能组件(Nginx/Redis/ 数据库) | 极致高性能场景(AI / 音视频编解码 / 高频金融交易) |
|---|
问3:内存分配的大小必须要对齐吗?
不是必须的,只需满足指针对齐(内存对齐)就可以让大部分系统不崩溃了。这里只是提供接口,代码中实际上未使用。
五、代码实现:
1. 等长分配
cpp
// ===============================等长分配===============================
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MEM_PAGE_SIZE 0x1000 //
typedef struct mempool_s
{
int blocksize;
int freecount;
char *free_ptr;
char *mem;
} mempool_t;
// sdk --> varchar(32);
//
// 2^n, page_size 4096, block_size: 16, 32, 64, 128
int memp_create(mempool_t *m, int block_size)
{
if (!m)
return -1;
m->blocksize = block_size;
m->freecount = MEM_PAGE_SIZE / block_size;
m->mem = (char *)malloc(MEM_PAGE_SIZE); //
if (!m->mem)
{ // NULL
return -2;
}
memset(m->mem, 0, MEM_PAGE_SIZE); //
m->free_ptr = m->mem;
int i = 0;
char *ptr = m->mem;
for (i = 0; i < m->freecount; i++)
{
*(char **)ptr = ptr + block_size;
ptr = ptr + block_size;
}
*(char **)ptr = NULL;
return 0;
}
void memp_destory(mempool_t *m)
{
if (!m)
return;
free(m->mem);
}
void *memp_alloc(mempool_t *m)
{
if (!m || m->freecount == 0)
return NULL;
void *ptr = m->free_ptr;
m->free_ptr = *(char **)ptr;
m->freecount--;
return ptr;
}
void memp_free(mempool_t *m, void *ptr)
{
*(char **)ptr = m->free_ptr;
m->free_ptr = (char *)ptr;
m->freecount++;
}
// memp_strcpy
// memp_memcpy
int main()
{
mempool_t m;
memp_create(&m, 32);
char *p1 = memp_alloc(&m);
printf("memp_alloc : %p\n", p1);
sprintf(p1, "hello");
printf("%s\n", p1);
memp_free(&m, p1);
void *p2 = memp_alloc(&m);
printf("memp_alloc : %p\n", p2);
void *p3 = memp_alloc(&m);
printf("memp_alloc : %p\n", p3);
memp_free(&m, p2);
void *p4 = memp_alloc(&m);
printf("memp_alloc : %p\n", p4);
memp_free(&m, p2);
}2. 大小块分配
部分接口介绍:
mp_alloc:返回的地址是对齐的,对last指针取整了
mp_nalloc: 返回的地址不一定是对齐的
mp_alloc_large:使用malloc分配,对齐字节数默认为8
mp_memalign:使用posix_memalign分配,对齐字节数可指定
mp_reset_pool(内存池重置)
- large->alloc全部释放并置为NULL,同时将pool->large置为NULL(large节点是由小块分配的,现在小块复位了,相当于large被释放了)
- node节点(小块)的last全部复位,表示节点还有size空间可用。
- current节点置为head,同时各node节点的fail全部置为0
cpp
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
// =========================大小快分配===============================
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align(n, alignment) (((n)+(alignment-1)) & ~(alignment-1))
#define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
struct mp_large_s {
struct mp_large_s *next;
void *alloc;
};
struct mp_node_s {
unsigned char *last;
unsigned char *end;
struct mp_node_s *next;
size_t failed;
};
struct mp_pool_s {
size_t max;
struct mp_node_s *current;
struct mp_large_s *large;
struct mp_node_s head[0];
};
struct mp_pool_s *mp_create_pool(size_t size);
void mp_destory_pool(struct mp_pool_s *pool);
void *mp_alloc(struct mp_pool_s *pool, size_t size);
void *mp_nalloc(struct mp_pool_s *pool, size_t size);
void *mp_calloc(struct mp_pool_s *pool, size_t size);
void mp_free(struct mp_pool_s *pool, void *p);
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret) {
return NULL;
}
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
p->head->last = (unsigned char *)p + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}
void mp_destory_pool(struct mp_pool_s *pool) {
struct mp_node_s *h, *n;
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
h = pool->head->next;
while (h) {
n = h->next;
free(h);
h = n;
}
free(pool);
}
void mp_reset_pool(struct mp_pool_s *pool) {
struct mp_node_s *h;
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
pool->large = NULL;
for (h = pool->head; h; h = h->next) {
h->last = (unsigned char *)h + sizeof(struct mp_node_s);
h->failed = 0; //新增
}
pool->current = pool->head; // 新增
}
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *h = pool->head;
size_t psize = (size_t)(h->end - (unsigned char *)h);
int ret = posix_memalign((void **)&m, MP_ALIGNMENT, psize);
if (ret) return NULL;
struct mp_node_s *p, *new_node, *current;
new_node = (struct mp_node_s*)m;
new_node->end = m + psize;
new_node->next = NULL;
new_node->failed = 0;
m += sizeof(struct mp_node_s);
m = mp_align_ptr(m, MP_ALIGNMENT);
new_node->last = m + size;
current = pool->current;
for (p = current; p->next; p = p->next) {
if (p->failed++ > 4) { //
current = p->next;
}
}
p->next = new_node;
pool->current = current ? current : new_node;
return m;
}
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void *p = malloc(size);
if (p == NULL) return NULL;
size_t n = 0;
struct mp_large_s *large;
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
if (n ++ > 3) break;
}
large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_memalign(struct mp_pool_s *pool, size_t size, size_t alignment) {
void *p;
int ret = posix_memalign(&p, alignment, size);
if (ret) {
return NULL;
}
struct mp_large_s *large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
// return mp_memalign(pool, size, alignment); 指定 posix_memalign 的分配内存地址对齐的字节数,malloc默认对齐8
}
void *mp_nalloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m+size;
return m;
}
p = p->next;
} while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
void *mp_calloc(struct mp_pool_s *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) {
memset(p, 0, size);
}
return p;
}
// 仅支持大块释放
void mp_free(struct mp_pool_s *pool, void *p) {
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (p == l->alloc) {
free(l->alloc);
l->alloc = NULL;
return ;
}
}
}
int main(int argc, char *argv[]) {
int size = 1 << 12;
struct mp_pool_s *p = mp_create_pool(size);
int i = 0;
for (i = 0;i < 10;i ++) {
void *mp = mp_alloc(p, 512);
// mp_free(mp);
}
//printf("mp_create_pool: %ld\n", p->max);
printf("mp_align(123, 32): %d, mp_align(17, 32): %d\n", mp_align(24, 32), mp_align(17, 32));
//printf("mp_align_ptr(p->current, 32): %lx, p->current: %lx, mp_align(p->large, 32): %lx, p->large: %lx\n", mp_align_ptr(p->current, 32), p->current, mp_align_ptr(p->large, 32), p->large);
int j = 0;
for (i = 0;i < 5;i ++) {
char *pp = mp_calloc(p, 32);
for (j = 0;j < 32;j ++) {
if (pp[j]) {
printf("calloc wrong\n");
}
printf("calloc success\n");
}
}
//printf("mp_reset_pool\n");
for (i = 0;i < 5;i ++) {
void *l = mp_alloc(p, 8192);
mp_free(p, l);
}
mp_reset_pool(p);
//printf("mp_destory_pool\n");
for (i = 0;i < 58;i ++) {
mp_alloc(p, 256);
}
mp_destory_pool(p);
return 0;
}