目录
[3.1 位图的初始化](#3.1 位图的初始化)
[3.2 位图的成员函数](#3.2 位图的成员函数)
[3.3 位图的位操作](#3.3 位图的位操作)
[4.1 位图的结构](#4.1 位图的结构)
[4.2 位图的初始化](#4.2 位图的初始化)
[4.3 位图的位设置](#4.3 位图的位设置)
[4.4 位图的其他操作](#4.4 位图的其他操作)
[4.5 源码](#4.5 源码)
[5.1 问题一](#5.1 问题一)
[5.2 问题二](#5.2 问题二)
[5.3 问题三](#5.3 问题三)
[3.1 布隆过滤器的结构](#3.1 布隆过滤器的结构)
[3.2 布隆过滤器的插入](#3.2 布隆过滤器的插入)
[3.3 布隆过滤器的测试](#3.3 布隆过滤器的测试)
[3.4 布隆过滤器的删除](#3.4 布隆过滤器的删除)
[3.5 源码](#3.5 源码)
[4.1 优点](#4.1 优点)
[4.2 缺点](#4.2 缺点)
一、位图
1、位图的引入
首先我们来看一道面试题:
给40亿 个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中?
我们可能会提出以下思路:
- 遍历直接查找。
- 排序+二分查找。
- 利用红黑树或哈希表,即 set 与 unordered_set 查找。
但是以上方法明显是错误的,因为对于 40亿 个整型来说有 160亿 byte,需要大概 16G 的内存空间 (1 G = 1024 MB = 1024 ∗ 1024 KB = 1024 ∗ 1024 ∗ 1024 byte ≈ 10亿 byte )。我们不可能直接向内存申请这么大的空间,即使放在文件/磁盘中每次处理一小部分效率也是极低的,因为存在磁盘读取效率低,分查找又需要随机访问下标。为了解决这个问题,就要用到我们接下来要将的位图 ------ bitset。
2、位图的概念
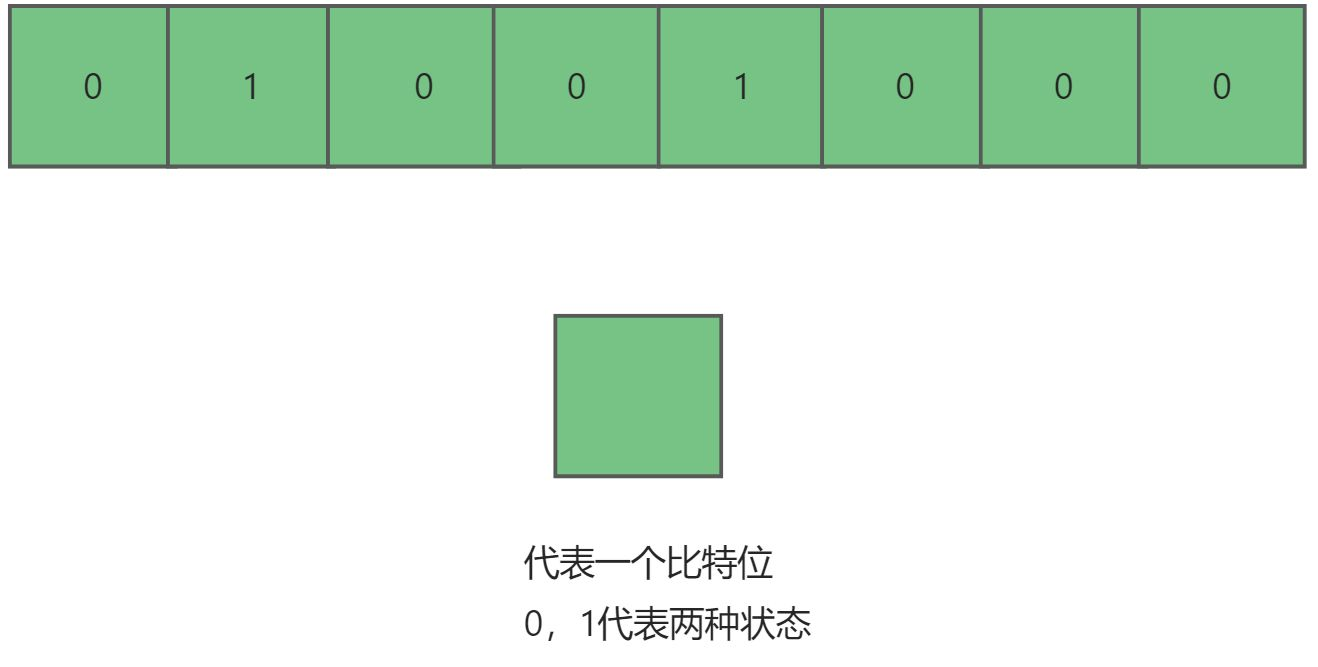
位图 (bitset),就是用一个个比特位来存放某种状态 ,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
然后解决上面这道问题,我们就可以利用二进制序列中的 0 和 1 代表某个无符号整数是否存在,其中无符号整数的最大值是 2^32 − 1,即需要 4294967295 个比特位,大概 512MB 空间,这个空间大小就是我们可以接受的。
其中 C++ 就为了我们提供了一个位图的模版类------位图。
3、位图的使用
3.1 位图的初始化
位图的初始化需要调用去构造函数,一般而言我们常用的就是以下几个接口。
cpp
void Test1()
{
//创建一个8位的位图,其所有位默认为0
bitset<8> bit1;//000000000
//创建一个16位的位图,其所有位设置为1
bitset<16> bit2(0xffff);//1111111111111111
//利用字符串初始化
bitset<8> bit3(string("10010010"));//10010010
}3.2 位图的成员函数
以下是位图的常见的成员函数,并且位图一般都重载了流插入 << 以及流提取 >> 运算符。
| 成员函数 | 功能 |
|---|---|
| set | 设置指定位或所有位 |
| reset | 清空指定位或所有位 |
| flip | 反转指定位或所有位 |
| test | 获取指定位的状态 |
| count | 获取被设置位的个数 |
| size | 获取可以容纳的位的个数 |
| any | 如果有任何一个位被设置则返回 true |
| none | 如果没有位被设置则返回 true |
| all | 如果所有位都被设置则返回 true |
| 返回对应位置的比特位数字 |
cpp
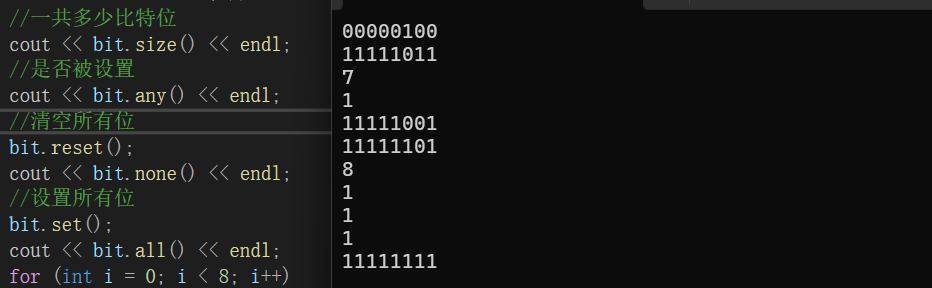
void Test2()
{
bitset<8> bit;
bit.set(2); //设置第2位
cout << bit << endl; //00000100
bit.flip(); //反转所有位
cout << bit << endl; //11111011
//被设置的个数
cout << bit.count() << endl;
//获取指顶位的状态
cout << bit.test(5) << endl;
bit.reset(1); //清空第1位
cout << bit << endl; //11111001
bit.flip(2); //反转第2位
cout << bit << endl; //11111101
//一共多少比特位
cout << bit.size() << endl;
//是否被设置
cout << bit.any() << endl;
//清空所有位
bit.reset();
cout << bit.none() << endl;
//设置所有位
bit.set();
cout << bit.all() << endl;
for (int i = 0; i < 8; i++)
{
//获取指定位的状态
cout << bit[i];
}
cout << endl;
}
3.3 位图的位操作
除此之外,位图还重载了大多数移位操作符方便我们使用.

cpp
void Test3()
{
bitset<8> bs1(string("10101010"));
bitset<8> bs2(string("10101010"));
bs1 >>= 1;
cout << bs1 << endl; //01010101
cout << (bs1 & bs2) << endl; //00000000
cout << (bs1 | bs2) << endl; //11111111
cout << (bs1 ^ bs2) << endl; //11111111
bs2 |= bs1;
cout << bs2 << endl; //11111111
}
4、实现bitset
4.1 位图的结构
位图本质是⼀个直接定址法的哈希表,每个整型值映射⼀个 bit 位,位图提供控制这个 bit 的相关接口。
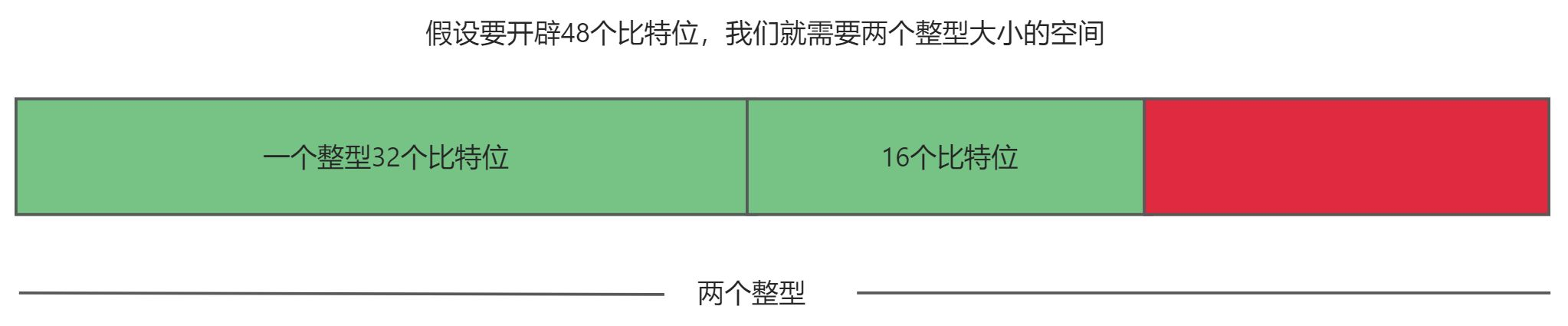
接下来我们来实现一下 bitset 的基本功能,首先 bitset 被定义为模版类,有一个非类型模版参数 N,单位为比特位。然后成员变量我们可以利用一个整型数组来实现,一个整型有 32 个比特位,所以一般需要 N/32+1 个整型。
bit 映射关系:实现中需要注意的是,C/C++ 没有对应位的类型,只能看 int/char 这样整形类型,我们再通过位运算去控制对应的比特位。比如我们数据存到 vector 中,相当于每个 int 值映射对应的 32 个值,比如第⼀个整形映射 0-31 对应的位,第⼆个整形映射 32-63 对应的位,后面的以此类推,那么来了⼀个整形值 x,i = x / 32;j = x % 32;计算出 x 映射的值在 vector 的第 i 个整形数据的第 j 位。
cpp
template<size_t N>
class bitset
{
public:
//构造函数
bitset();
//设置位
void set(size_t pos);
//清空位
void reset(size_t pos);
//反转位
void flip(size_t pos);
//获取位的状态
bool test(size_t pos);
//获取可以容纳的位的个数
size_t size();
//获取被设置位的个数
size_t count();
//判断位图中是否有位被设置
bool any();
//判断位图中是否全部位都没有被设置
bool none();
//判断位图中是否全部位都被设置
bool all();
private:
vector<int> _bits; //位图
};4.2 位图的初始化
位图初始化即通过构造函数将开辟的整型空间的比特位全部设为 0,即整型设为 0。
cpp
//构造函数
bitset()
{
_bits.resize(N / 32 + 1, 0);
}4.3 位图的位设置
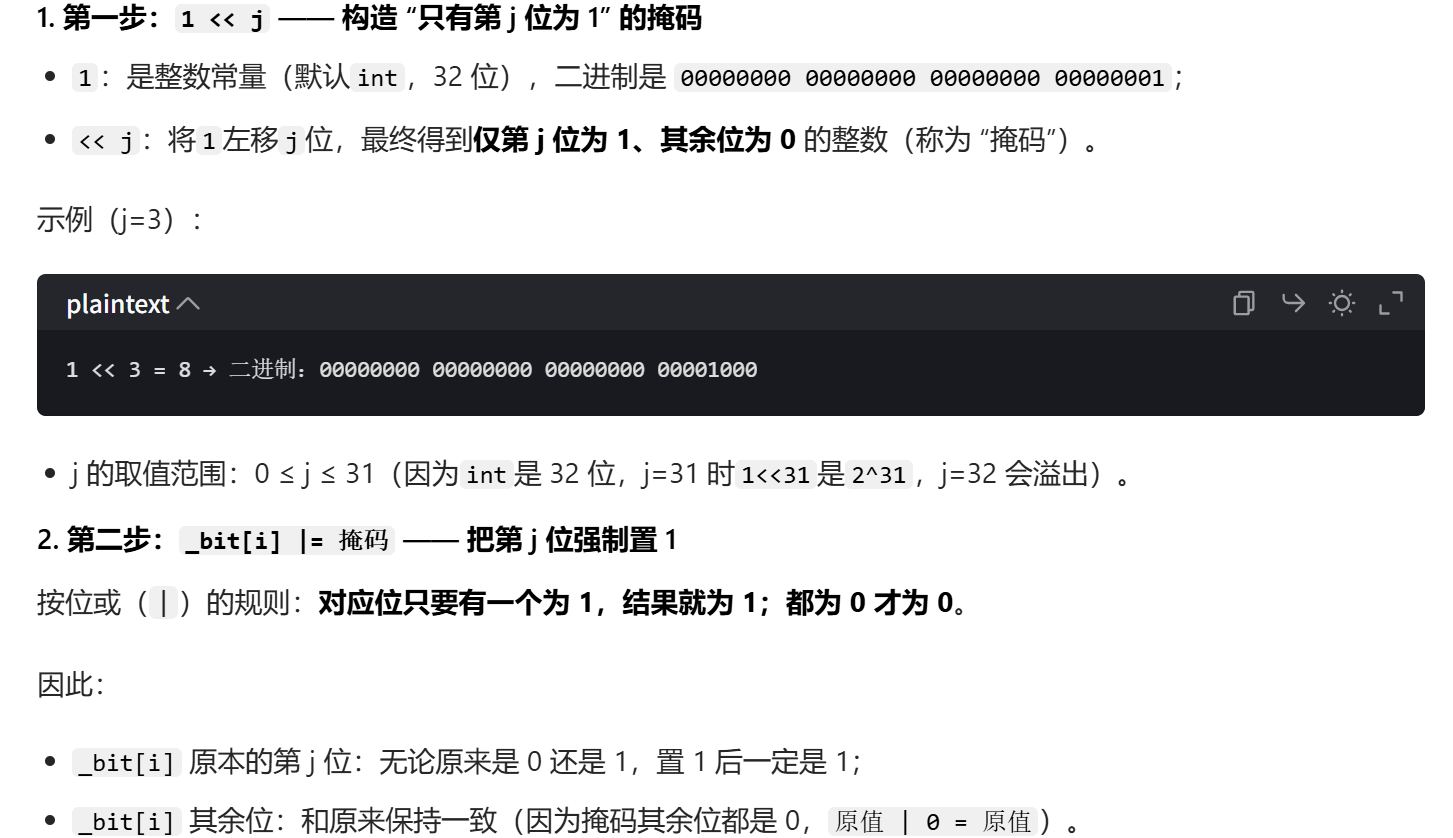
位图我们可以先通过 N % 32 计算修改的整型位置 i,然后通过 N % 32 得到修改的比特位的位置 j。最后通过对应的位运算改变对应比特位的状态。
其中将对应比特位设置为 1 的运算为 _bit i |= ( 1 << j )。
cpp
//设置位
void set(size_t pos)
{
assert(pos < N);
int i = pos / 32;//第几个整型
int j = pos % 32;//第几个比特位
_bits[i] |= (1 << j);
}
其中将对应比特位设置为 0 的运算为 _bits i &= ~( 1 << j )。
cpp
//清空位
void reset(size_t pos)
{
assert(pos < N);
int i = pos / 32;//第几个整型
int j = pos % 32;//第几个比特位
_bits[i] &= ~(1<< j);
}其中将对应比特位翻转的运算为 _bits i ^= ( 1 << j )。
cpp
void flip(size_t pos)
{
assert(pos < N);
int i = pos / 32;//第几个整型
int j = pos % 32;//第几个比特位
_bits[i] ^= (1 << j);
}其中将对应比特位的状态运算为 _bits i & ( 1 << j )。
cpp
//获取位的状态
bool test(size_t pos)
{
assert(pos < N);
int i = pos / 32;//第几个整型
int j = pos % 32;//第几个比特位
if (_bits[i] & (1 << j))
{
return true;
}
return false;
}4.4 位图的其他操作
首先是获得位图的容量,直接返回对应的模版参数即可。
cpp
//获取可以容纳的位的个数
size_t size()
{
return N;
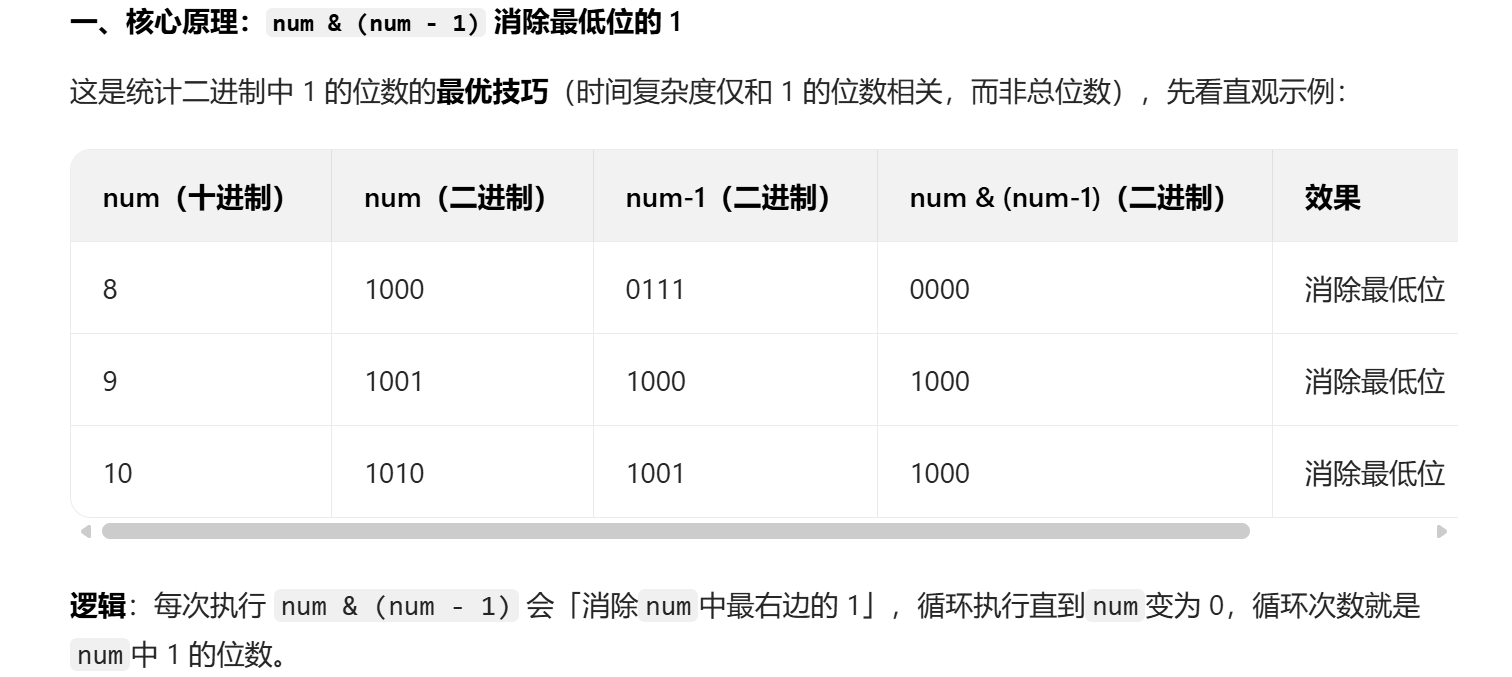
}接下来我们可以获取设置的位数,首先我们得知道 num & ( num - 1 )能将二进制最右侧的1去掉。
cpp
//获取被设置位的个数
size_t count()
{
size_t cnt = 0;
for (int i = 0; i < N / 32 + 1; i++)
{
//取每个整数
int num = _bits[i];
while (num)
{
num = num & (num - 1);
++cnt;
}
}
return cnt;
}
接下来就是判断位图中有没有位被设置,即判断每个整型是否为 0,为 0 就没被设置,非 0 就已被设置。
cpp
//判断位图中是否有位被设置
bool any()
{
for (int i = 0; i < N / 32 + 1; i++)
{
int num = _bits[i];
if (num != 0)
{
return true;
}
}
return false;
}
cpp
//判断位图中是否全部位都没有被设置
bool none()
{
return !any();
}接下来我们判断是否全部位都被设置,我们可以先判断前 N 个是否设置如果全部被设置,那么其按位取反一定等于 0,再取第 N+1 的每个比特位看是否为 1。
cpp
//判断位图中是否全部位都被设置
bool all()
{
//前N个数
for (int i = 0; i < N / 32 ; i++)
{
int num = ~_bits[i];
if (num != 0)
{
return false;
}
}
//第N+1个数
for (size_t j = 0; j < N % 32; j++)
{
if ((_bits[N/32 - 1] & (1 << j)) == 0)
return false;
}
return true;
}4.5 源码
cpp
#include <vector>
#include <assert.h>
namespace tata
{
template <size_t N>
class bitset
{
public:
// 构造函数
bitset()
{
_bits.resize(N / 32 + 1, 0);
}
// 设置位
void set(size_t pos)
{
assert(pos < N);
int i = pos / 32; // 第几个整型
int j = pos % 32; // 第几个比特位
_bits[i] |= (1 << j);
}
// 清空位
void reset(size_t pos)
{
assert(pos < N);
int i = pos / 32; // 第几个整型
int j = pos % 32; // 第几个比特位
_bits[i] &= ~(1 << j);
}
// 反转位
void flip(size_t pos)
{
assert(pos < N);
int i = pos / 32; // 第几个整型
int j = pos % 32; // 第几个比特位
_bits[i] ^= (1 << j);
}
// 获取位的状态
bool test(size_t pos)
{
assert(pos < N);
int i = pos / 32; // 第几个整型
int j = pos % 32; // 第几个比特位
if (_bits[i] & (1 << j))
{
return true;
}
return false;
}
// 获取可以容纳的位的个数
size_t size()
{
return N;
}
// 获取被设置位的个数
size_t count()
{
size_t cnt = 0;
for (int i = 0; i < N / 32 + 1; i++)
{
int num = _bits[i];
while (num)
{
num = num & (num - 1);
++cnt;
}
}
return cnt;
}
// 判断位图中是否有位被设置
bool any()
{
for (int i = 0; i < N / 32 + 1; i++)
{
int num = _bits[i];
if (num != 0)
{
return true;
}
}
return false;
}
// 判断位图中是否全部位都没有被设置
bool none()
{
return !any();
}
// 判断位图中是否全部位都被设置
bool all()
{
for (int i = 0; i < N / 32; i++)
{
int num = ~_bits[i];
if (num != 0)
{
return false;
}
}
for (size_t j = 0; j < N % 32; j++)
{
if ((_bits[N / 32 - 1] & (1 << j)) == 0)
return false;
}
return true;
}
private:
vector<int> _bits; // 位图
};
}5、经典面试题
5.1 问题一
给定 100亿 个整数,设计算法找到只出现 一次 的整数?
首先数据量达到 100亿,肯定使用位图,然后我们分析,可以将每个整数分为三种状态 :没有出现过,出现过一次,出现两次及其上 。这时我们不可能用一个位图解决,因为一个位图只能表示两个状态,所以我们可以用两个位图来表示。其中 00 表示没有出现过,01 表示只出现过一次,10 表示出现过两次及其以上:
cpp
template<size_t N>
class bitTwo
{
public:
void set(size_t x)
{
//00->01
if (!_bit1.test(x) && !_bit2.test(x))
{
_bit2.set(x);
}
//01->10
else if(!_bit1.test(x) && _bit2.test(x))
{
_bit1.set(x);
_bit2.reset(x);
}
}
void PrintOnce()
{
for (int i = 0; i < N; i++)
{
//01
if (_bit2.test(i) == true)
{
cout << i << " ";
}
}
cout << endl;
}
private:
bitset<N> _bit1;
bitset<N> _bit2;
};5.2 问题二
⼀个文件有 100亿 个整数,1G 内存,设计算法找到出现次数 不超过2次 的所有整数
这题目和上题一样只不过需要四种状态,两个 bitset 也能表示四种状态修改一下即可。
cpp
template<size_t N>
class TwoBitSet
{
public:
void Set(size_t n)
{
bool bit1 = b1.test(n);
bool bit2 = b2.test(n);
if (!bit1 && !bit2)//00->01
{
b2.set(n);
}
else if (!bit1&&bit2)//01->10
{
b1.set(n);
b2.reset(n);
}
else//10->11 11->11
{
b1.set(n);
b2.set(n);
}
}
int get_count(size_t n)//检测出现次数
{
bool bit1 = b1.test(n);
bool bit2 = b2.test(n);
if (!bit1 && !bit2)
{
return 0;//没出现
}
else if (!bit1 && bit2)
{
return 1;//出现1次
}
else if (bit1 && !bit2)
{
return 2;//出现2次
}
else
{
return 3;//出现3次及以上
}
}
private:
Bit_Set<N> b1;
Bit_Set<N> b2;//封装
};5.3 问题三
给两个文件 ,分别有 100亿 个整数,我们只有 1G 内存,如何找到两个文件的交集?
我们提出以下两种解决方法:
方案一:
- 首先,依次读取第一个文件中的所有整数,将其映射到一个位图。这个位图需要有 2 ^ 32 个比特位,即 512MB 内存。
- 然后,读取第二个文件中的所有整数,逐个判断其是否在位图中。如果在,则说明该整数是两个文件的交集之一;如果不在,则不是交集。
方案二:
- 第一步,依次读取第一个文件中的所有整数,将其映射到位图 1。同样,位图 1 有2 ^ 32 个比特位,占用 512M 内存。
- 第二步,依次读取第二个文件中的所有整数,将其映射到位图 2。位图 2 也占用512M内存,两个位图刚好满足1G内存的限制。
- 第三步,将位图 1 和位图 2 进行与操作,结果存储在位图 1 中。此时,位图 1 当中映射的整数就是两个文件的交集。
cpp
// 位图类:处理32位无符号整数的映射(0~4294967295)
class Bitmap {
public:
Bitmap() {
// 2^32位 = 134217728个unsigned int(每个占4字节,共512MB)
_bits.resize(1 << 27, 0); // 1<<27 = 134217728
}
// 标记整数x存在
void set(uint32_t x) {
size_t idx = x / 32; // 计算对应的unsigned int索引
size_t bit = x % 32; // 计算对应的位
_bits[idx] |= (1U << bit); // 置1
}
// 判断整数x是否存在
bool test(uint32_t x) const {
size_t idx = x / 32;
size_t bit = x % 32;
return (_bits[idx] & (1U << bit)) != 0;
}
private:
vector<unsigned int> _bits;
};
// 拆分大文件:将文件按整数范围拆分为多个小文件(避免一次性读入100亿数据)
void split_file(const string& input_path, const string& output_prefix) {
ifstream in(input_path, ios::binary);
if (!in.is_open()) {
throw runtime_error("Failed to open input file");
}
uint32_t x;
while (in.read(reinterpret_cast<char*>(&x), sizeof(x))) {
// 按x的高8位拆分(共256个小文件,每个文件对应16777216个整数)
uint8_t high8 = static_cast<uint8_t>(x >> 24);
string output_path = output_prefix + "_" + to_string(high8) + ".bin";
ofstream out(output_path, ios::binary | ios::app);
out.write(reinterpret_cast<char*>(&x), sizeof(x));
}
}
// 方案一:找两个文件的交集
void find_intersection(const string& file1_prefix, const string& file2_prefix, const string& output_path) {
ofstream out(output_path, ios::binary);
if (!out.is_open()) {
throw runtime_error("Failed to open output file");
}
// 遍历所有拆分后的小文件(共256个)
for (int i = 0; i < 256; ++i) {
string file1_path = file1_prefix + "_" + to_string(i) + ".bin";
string file2_path = file2_prefix + "_" + to_string(i) + ".bin";
// 步骤1:加载第一个小文件到位图
Bitmap bitmap;
ifstream in1(file1_path, ios::binary);
if (in1.is_open()) {
uint32_t x;
while (in1.read(reinterpret_cast<char*>(&x), sizeof(x))) {
bitmap.set(x);
}
}
// 步骤2:读取第二个小文件,判断是否在位图中(是则写入交集)
ifstream in2(file2_path, ios::binary);
if (in2.is_open()) {
uint32_t x;
while (in2.read(reinterpret_cast<char*>(&x), sizeof(x))) {
if (bitmap.test(x)) {
out.write(reinterpret_cast<char*>(&x), sizeof(x));
}
}
}
}
}
int main() {
try {
// 1. 拆分两个大文件(假设原文件是file1.bin、file2.bin)
split_file("file1.bin", "split_file1");
split_file("file2.bin", "split_file2");
// 2. 找交集,结果写入intersection.bin
find_intersection("split_file1", "split_file2", "intersection.bin");
cout << "交集计算完成,结果已写入intersection.bin" << endl;
} catch (const exception& e) {
cerr << "Error: " << e.what() << endl;
return 1;
}
return 0;
}
cpp
// 方案二:两个位图做与操作
void find_intersection_v2(const string& file1_prefix, const string& file2_prefix, const string& output_path) {
ofstream out(output_path, ios::binary);
for (int i = 0; i < 256; ++i) {
string file1_path = file1_prefix + "_" + to_string(i) + ".bin";
string file2_path = file2_prefix + "_" + to_string(i) + ".bin";
Bitmap bitmap1, bitmap2;
// 加载文件1到位图1
ifstream in1(file1_path, ios::binary);
if (in1.is_open()) {
uint32_t x;
while (in1.read(reinterpret_cast<char*>(&x), sizeof(x))) {
bitmap1.set(x);
}
}
// 加载文件2到位图2
ifstream in2(file2_path, ios::binary);
if (in2.is_open()) {
uint32_t x;
while (in2.read(reinterpret_cast<char*>(&x), sizeof(x))) {
bitmap2.set(x);
}
}
// 位图1和位图2做与操作,结果写入文件
// (需给Bitmap类加"按位与"接口,遍历_bits数组做&操作)
for (uint32_t x = i * 16777216; x < (i+1)*16777216; ++x) {
if (bitmap1.test(x) && bitmap2.test(x)) {
out.write(reinterpret_cast<char*>(&x), sizeof(x));
}
}
}
}二、布隆过滤器
1、布隆过滤器的引入
在我们注册游戏或者社交账号时,我们可以自己设置昵称,但为了保证每个用户昵称的唯一性,我们必须检测输入的昵称是否被使用过,这本质其实就是一个 key 的模型。一般而言,我们有两种解决方案:
方案一:
用红黑树或者哈希表存储相关数据,当判断一个数据是否存在时,可以极快的效率在红黑树或哈希表中查找。
方案二:
用位图将存储相关数据,虽然位图只能存储整型数据,但我们可以通过一些哈希算法将字符串转换成整型,比如 BKDR 哈希算法。这种方法同样也能以极快的效率查找数据。
但是这两种方案其实都有一些缺点,当数量太大时因为红黑树与哈希表要存储相关信息,内存会不足,而如果用位图存储,虽然节约了大量空间,但是一个无符号整数最大值为 4294967295,而字符串的种类却是无限的,以无限对有限,无论哪种哈希算法都必然会导致哈希冲突。
所以为了解决这个问题,就有人提出一种结构 ------ 布隆过滤器。
2、布隆过滤器的概念
布隆过滤器 是由布隆(Burton Howard Bloom)在 1970 年提出的一种紧凑型的、比较巧妙的概率型数据结构 ,特点是高效地插入和查询 ,可以用来告诉你 "某样东西一定不存在或者可能存在",它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。其具有以下几个特点:
- 布隆过滤器是位图的变形与延伸,虽无法避免哈希冲突,但可降低误判概率。
- 在布隆过滤器中,当一个数据映射到位图时,会使用多个哈希函数将其映射到多个比特位。判断数据是否在位图中,需依据这些哈希函数计算对应的比特位,若这些比特位全为 1,则判定数据存在,否则判定数据不存在。
- 布隆过滤器采用多个哈希函数进行映射,目的是降低哈希冲突概率。单个哈希函数产生冲突的概率可能较大,而多个哈希函数同时产生冲突的概率则较小。
- 布隆过滤器在判断一个数据是否存在时,如果存在,可能出现误判,但是如果不存在,那一定没有误判。
比如说我们分别将 tata1,tata2,tata3 利用三个哈希函数映射进位图中,其分布可能为:
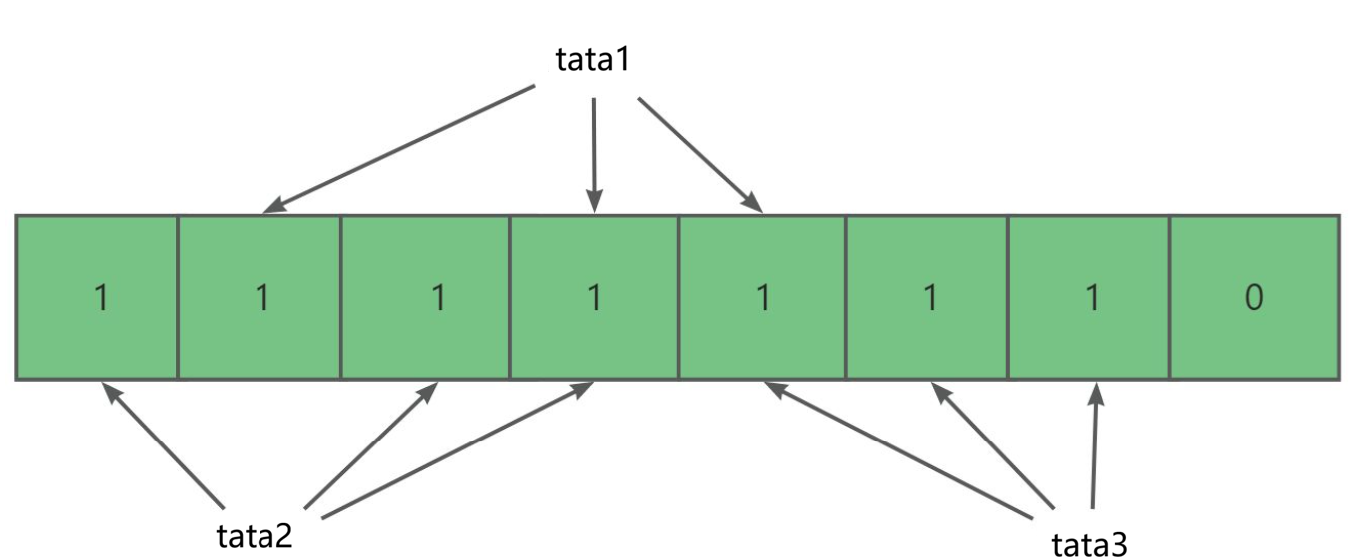
其中 tata1,tata2,tata3 这三个字符串都没有发生冲突。而如果三个哈希函数的计算结果都相同的话,那就可能造成哈希冲突,比如接下来的 tata1 与 tata2。
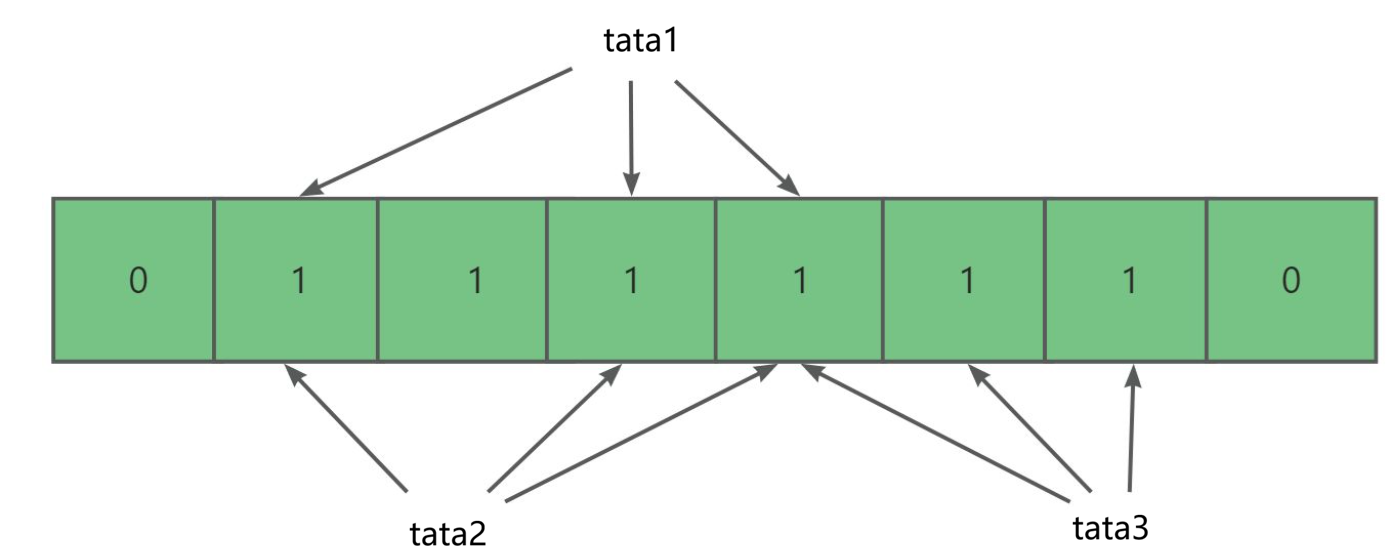
其中如果某个位置是 0 的话,那该数据一定不存在因为没有任何数据指向这个位置。
为了降低布隆过滤器的误判率,有人就对布隆过滤器的长度与哈希函数的个数做了研究。得到一个公式:

其中 k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数 ,p 为误判率。
如果使用的哈希函数为 3 个,那么根据公式 m ≈ 4n,也就是说当布隆过滤器的长度是插入元素个数的 4倍 时误差最小。
以上两个公式的推导过程尤其复杂,这里放两篇博客链接布隆过滤器(Bloom Filter)- 原理、实现和推导 和 布隆过滤器BloomFilter 举例说明+证明推导。
3、布隆过滤器的实现
3.1 布隆过滤器的结构
首先布隆过滤器肯定是一个模版类,有一个非类型模版参数控制长度,默认处理的对象为 string。默认也提供三个哈希函数,其成员变量也是一个位图。
首先我们需要几个哈希函数,这里我们就简单的以字符串的哈希函数为例。这里有几个比较好的字符串哈希函数。各种字符串Hash函数-clq-博客
cpp
struct HashFuncBKDR
{
/// @detail 本 算法由于在Brian Kernighan与Dennis Ritchie的《The C
//Programming Language》
// ⼀书被展⽰⽽得 名,是⼀种简单快捷的hash算法,也是Java⽬前采⽤的字符串的Hash
//算法累乘因⼦为31。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 31;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// 由Arash Partow发明的⼀种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >>
5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// 由Daniel J. Bernstein教授发明的⼀种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};
template<size_t N>
class Bit_Set
{
public:
Bit_Set()
{
bitmap.resize(N / 32 + 1);
}
//将第N个数据标记为1
void set(size_t n)
{
int i = n / 32;
int j = n % 32;
bitmap[i] |= (1 << j);
}
//将第N个数据标记为0
void reset(size_t n)
{
int i = n / 32;
int j = n % 32;
bitmap[i] &= (~(1 << j));
}
//查看第N个数据是否标记
bool test(size_t n)
{
int i = n / 32;
int j = n % 32;
return bitmap[i] & (1 << j);
}
private:
std::vector<int> bitmap;
};
template<size_t N,
size_t X=6,
class K=string,
class Hash1= HashFuncBKDR,
class Hash2= HashFuncAP,
class Hash3= HashFuncDJB>
class Bloom
{
public:
void Set(const K& key)
{
size_t b1 = Hash1()(key) % M;
size_t b2 = Hash2()(key) % M;
size_t b3 = Hash3()(key) % M;//三个哈希函数映射的值
b.set(b1);
b.set(b2);
b.set(b3);//标记
}
bool Test(const K& key)
{
size_t b1 = Hash1()(key) % M;
size_t b2 = Hash2()(key) % M;
size_t b3 = Hash3()(key) % M;//三个哈希函数映射的值
if (!b.test(b1))//只要有一个没标记就返回0说明不在
{
return 0;
}
if (!b.test(b2))//只要有一个没标记就返回0说明不在
{
return 0;
}
if (!b.test(b3))//只要有一个没标记就返回0说明不在
{
return 0;
}
return true;//可能存在误判
}
// 获取公式计算出的误判率
double getFalseProbability()
{
double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);
return p;
}
private:
static const size_t M = X * N;
Bit_Set<M> b;
};
cpp
template<size_t N, class K=string,class Hash1=BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
public:
//成员函数
private:
bitset<N> _bit;
};3.2 布隆过滤器的插入
布隆过滤器的插入即通过不同的哈希函数计算对应的下标,然后进行相应的映射关系。
cpp
//成员函数
void set(const K& key)
{
//计算机对应的下标
size_t hashi1 = Hash1()(key)% N;
size_t hashi2 = Hash2()(key)% N;
size_t hashi3 = Hash3()(key)% N;
_bit.set(hashi1);
_bit.set(hashi2);
_bit.set(hashi3);
}3.3 布隆过滤器的测试
cpp
void Test()
{
qcj::Bloom<10> b;
b.Set("孙悟空");
b.Set("猪八戒");
b.Set("唐僧");
cout << b.Test("孙悟空") << endl;;
cout << b.Test("猪八戒") << endl;;
cout << b.Test("唐僧") << endl;
cout << b.Test("沙僧") << endl;;
cout << b.Test("猪八戒1") << endl;;
}
cpp
void TestBloomFilter2()
{
srand(time(0));
const size_t N = 100000;
/* Bloom<N> bf; */
Bloom<N, 3> bf;
/* Bloom<N, 10> bf; */
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
//std::string url = "https://www.baidu.com/s?ie=utf8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=ln2&fenlei=256&rsv_pq=0x8d9962630072789f & rsv_t = ceda1rulSdBxDLjBdX4484KaopD % 2BzBFgV1uZn4271RV0PonRFJm0i5xAJ % 2FDo & rqlang = en & rsv_enter = 1 & rsv_dl = ib & rsv_sug3 = 3 & rsv_sug1 = 2 & rsv_sug7 = 100 & rsv_sug2 =0 & rsv_btype = i & inputT = 330 & rsv_sug4 = 2535";
//std::string url = "猪⼋戒";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.Set(str);
}
// v2跟v1是相似字符串集(前缀⼀样),但是后缀不⼀样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v1.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v1)
{
if (bf.Test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不⼀样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v1.push_back(url);
}
size_t n3 = 0;
for (auto& str : v1)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
cout << "公式计算出的误判率:" << bf.getFalseProbability() << endl;
}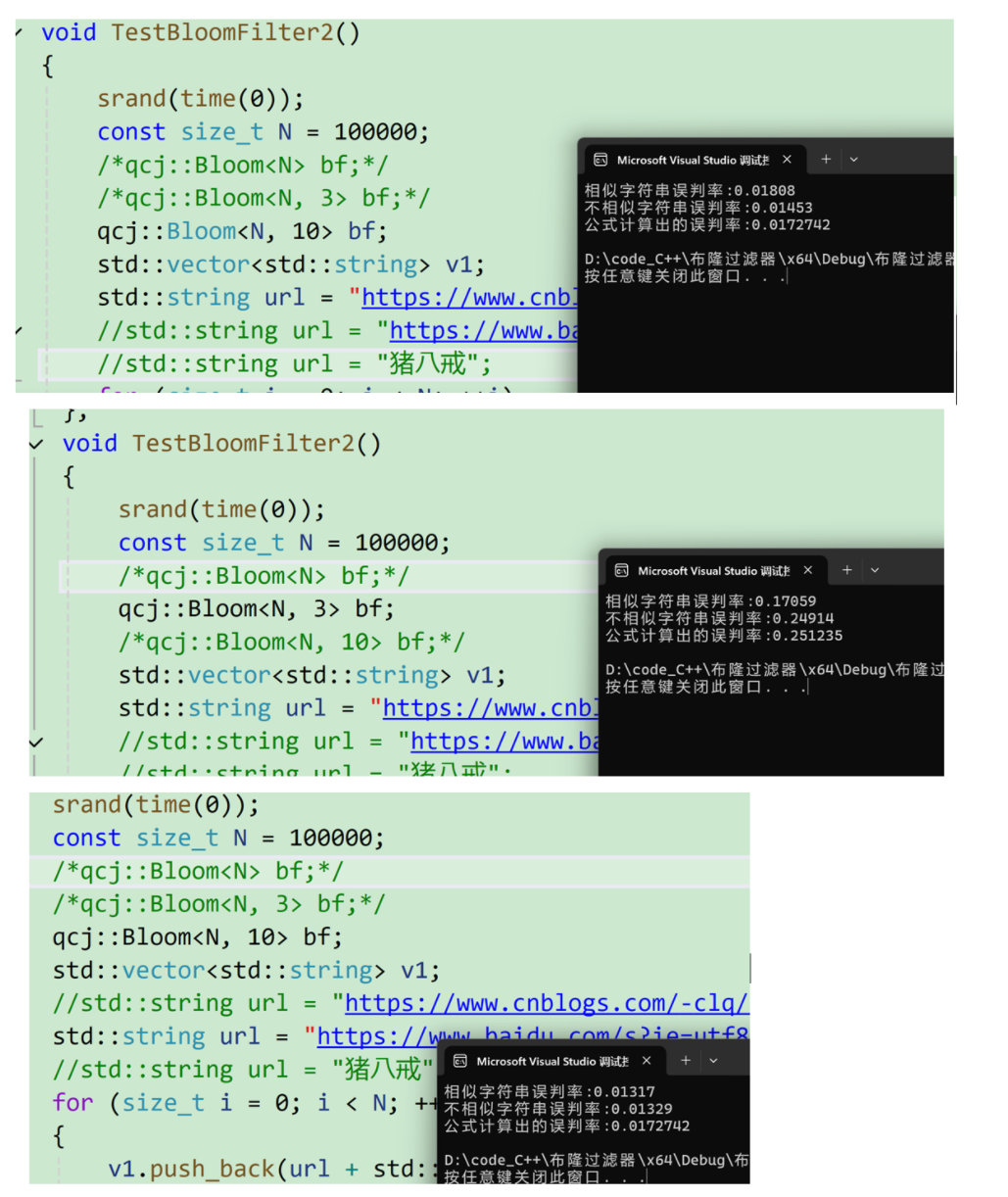
可以发现这里我们公式算的还是非常的准的。

3.4 布隆过滤器的删除
布隆过滤器一般不能直接支持删除工作,原因是删除一个元素可能影响其他元素,如删除猪八戒可能导致孙悟空查找不到,等同于也被误删,因为二者可能在多个哈希函数计算出的比特位上有重叠。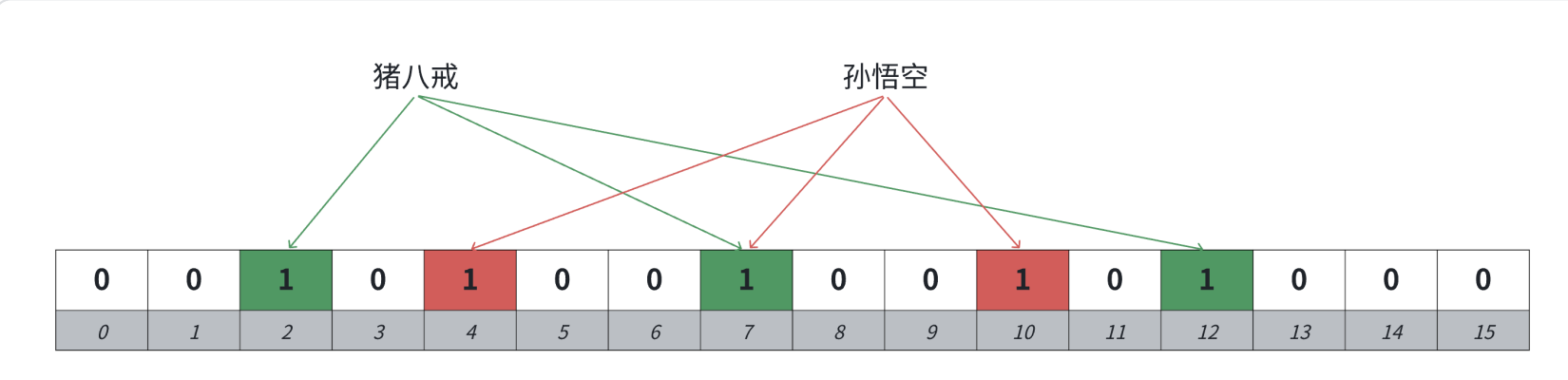
如果一定要支持删除操作的话,一种支持删除的方法是将布隆过滤器的每个比特位扩展成小计数器(一个下标对应多个比特位),插入元素时给相应位置计数器加一,删除时减一,以多占用几倍存储空间为代价实现删除操作。但是仍然会存在几个问题:
- 如果你的位数给的不合适,可能某一次次数更新之后就会溢出,造成计数回绕(计数器值增加到达其最大范围后,再次增加会导致计数器值重新回到初始状态)。
- 并且查找一个元素的时候无法确认该元素是否真的存于布隆过滤器中。因为我们删除一个元素的时候一定要确保它是存在的,再去删除(减去对应位置的次数),不存在是不能删除的,但是判断一个元素是否在布隆过滤器中是可能误判的。所以我们在删除一个元素的时候无法确认它是否存在
所以一般而言,布隆过滤器的删除操作是不可行的。
3.5 源码
cpp
#pragma once
#include<bitset>
struct BKDRHash
{
size_t operator()(const string& s)
{
size_t value = 0;
for (auto ch : s)
{
value = value * 131 + ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t value = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
value ^= ((value << 7) ^ s[i] ^ (value >> 3));
}
else
{
value ^= (~((value << 11) ^ s[i] ^ (value >> 5)));
}
}
return value;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
if (s.empty())
return 0;
size_t value = 5381;
for (auto ch : s)
{
value += (value << 5) + ch;
}
return value;
}
};
template<size_t N, class K=string,class Hash1=BKDRHash,
class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
public:
//成员函数
void set(const K& key)
{
//计算机对应的下标
size_t hashi1 = Hash1()(key)% N;
size_t hashi2 = Hash2()(key)% N;
size_t hashi3 = Hash3()(key)% N;
_bit.set(hashi1);
_bit.set(hashi2);
_bit.set(hashi3);
}
bool test(const K& key)
{
size_t hashi1 = Hash1()(key) % N;
size_t hashi2 = Hash2()(key) % N;
size_t hashi3 = Hash3()(key) % N;
if (!_bit.test(hashi1)||!_bit.test(hashi2)||!_bit.test(hashi3))
{
//一定不存在
return false;
}
return true;//可能存在误判
}
private:
bitset<N> _bit;
};4、布隆过滤器的优缺点
4.1 优点
- 时间复杂度低:增加和查询元素的时间复杂度为 O(K)(K 为哈希函数个数且一般较小),与数据量大小无关。
- 便于硬件并行运算:哈希函数相互之间没有关系。
- 保密优势:不需要存储元素本身,在保密要求严格的场合有很大优势。
- 空间优势:在能承受一定误判时,比其他数据结构有很大的空间优势。
- 可表示全集:数据量很大时可以表示全集,其他数据结构不能。
- 可进行运算:使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
4.2 缺点
- 存在误判率:有假阳性,不能准确判断元素是否在集合中,可通过建立白名单补救。
- 不能获取元素本身。
- 一般情况下不能删除元素,采用计数方式删除可能会存在计数回绕问题。
5、布隆过滤器的应用场景
一般而言使用布隆过滤器的前提是,布隆过滤器的误判不会对业务逻辑造成影响。以下是布隆过滤器的具体使用场景:
在电商平台的商品推荐系统中,当用户浏览商品时,系统会根据用户的历史浏览记录和购买行为进行个性化推荐。
假设用户的历史浏览记录和购买行为数据存储在数据库中,直接遍历数据库进行推荐计算会非常耗时,影响用户体验。这时可以使用布隆过滤器,将用户已经浏览过或购买过的商品 ID 全部添加到布隆过滤器当中。
当用户打开某个商品页面时,系统首先在布隆过滤器中查找该商品 ID。如果在布隆过滤器中查找后发现该商品 ID 不存在,说明用户没有浏览过或购买过这个商品,可以将其作为潜在的推荐商品进行初步推荐,避免了磁盘 IO。
如果在布隆过滤器中查找后发现该商品 ID 存在,此时还需要进一步访问磁盘,复核用户是否真的浏览过或购买过该商品,因为布隆过滤器可能会有误判。
由于大部分情况下,系统推荐给用户的商品都是用户没有接触过的,所以在布隆过滤器中查找后通常都是找不到的,此时就避免了进行磁盘 IO。而只有在布隆过滤器误判或用户忘记自己浏览过或购买过某个商品的情况下,才需要访问磁盘进行复核。
- 爬虫系统中 URL 去重:在爬虫系统中,为了避免重复爬取相同的 URL,可以使用布隆过滤器来进行 URL 去重。爬取到的 URL 可以通过布隆过滤器进行判断,已经存在的 URL 则可以直接忽略,避免重复的网络请求和数据处理。
- 垃圾邮件过滤:在垃圾邮件过滤系统中,布隆过滤器可以用来判断邮件是否是垃圾邮件。系统可以将已知的垃圾邮件的特征信息存储在布隆过滤器中,当新的邮件到达时,可以通过布隆过滤器快速判断是否为垃圾邮件,从而提高过滤的效率。
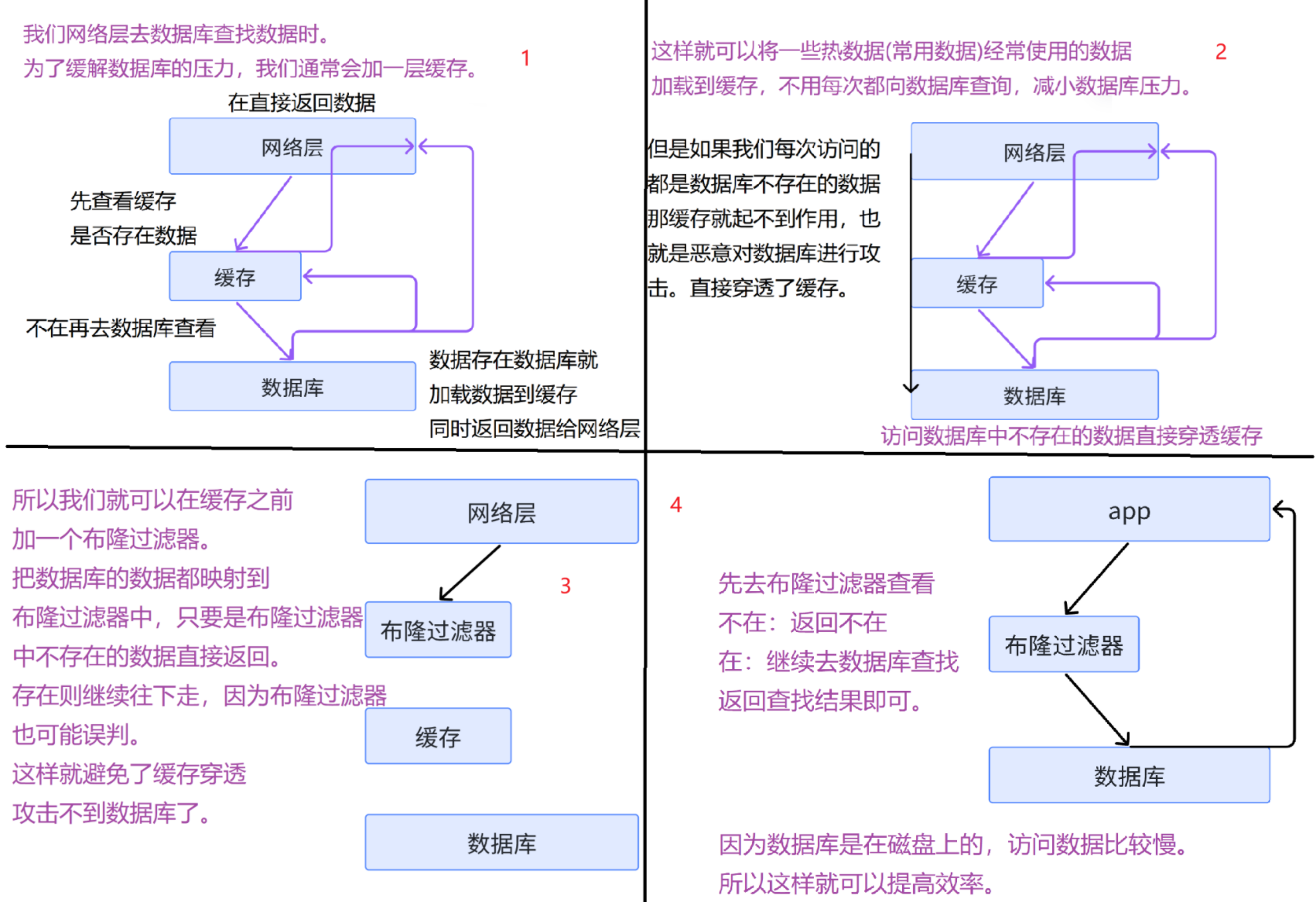
- 预防缓存穿透 :在分布式缓存系统中,布隆过滤器可以用来解决缓存穿透的问题。**缓存穿透是指恶意用户请求⼀个不存在的数据,导致请求直接访问数据库,造成数据库压力过大。**布隆过滤器可以先判断请求的数据是否存在于布隆过滤器中,如果不存在,直接返回不存在,避免对数据库的无效查询。
- 对数据库查询提效:在数据库中,布隆过滤器可以⽤来加速查询操作。例如:⼀个 app 要快速判断⼀个电话号码是否注册过,可以使用布隆过滤器来判断⼀个用户电话号码是否存在于表中,如果不存在,可以直接返回不存在,避免对数据库进行无用的查询操作。如果在,再去数据库查询进行二次确认。
三、海量数据处理问题
1、题目一(TopK)
100亿 个整数里面求 最大的 前100个。
这里我们建一个大小为 100 的小堆,再进行比较,把 100亿 个整数中比堆顶元素大的元素进堆即可,剩下的 100 个堆元素就是最大的 100 个数。再次不赘述topK算法了,详细可以了解篇博文:Top_K问题。
cpp
// 核心逻辑:从文件读取海量整数,找最大的前K个(K=100)
vector<uint64_t> findTopK(const string& filename, size_t K) {
// 小顶堆:priority_queue默认是大顶堆,greater<>改为小顶堆
priority_queue<uint64_t, vector<uint64_t>, greater<uint64_t>> min_heap;
ifstream in(filename, ios::binary);
if (!in.is_open()) {
cerr << "读取数据失败:文件打开失败" << endl;
return {};
}
uint64_t num;
// 按二进制读取每个整数(边读边处理,不加载全部数据到内存)
while (in.read(reinterpret_cast<char*>(&num), sizeof(num))) {
if (min_heap.size() < K) {
// 堆未满,直接入堆
min_heap.push(num);
} else {
// 堆已满,仅当当前数>堆顶(堆中最小)时,替换堆顶
if (num > min_heap.top()) {
min_heap.pop();
min_heap.push(num);
}
}
}
in.close();
// 提取堆中结果(小顶堆中是前K大的数,但顺序是从小到大)
vector<uint64_t> topK;
while (!min_heap.empty()) {
topK.push_back(min_heap.top());
min_heap.pop();
}
// 反转后变为从大到小
reverse(topK.begin(), topK.end());
return topK;
}2、题目二(哈希切分法)
给两个文件 ,分别有 100亿 个query(字符串 ),我们只有 1G 内存,如何找到两个文件交集
- 分析:假设平均每个 query 字符串 50byte,100亿 个 query 就是 5000亿 byte,约等于 500G ( 1G 约等于 10亿多 Byte )
哈希表/红黑树等数据结构肯定是无能为力的。
解决方案1
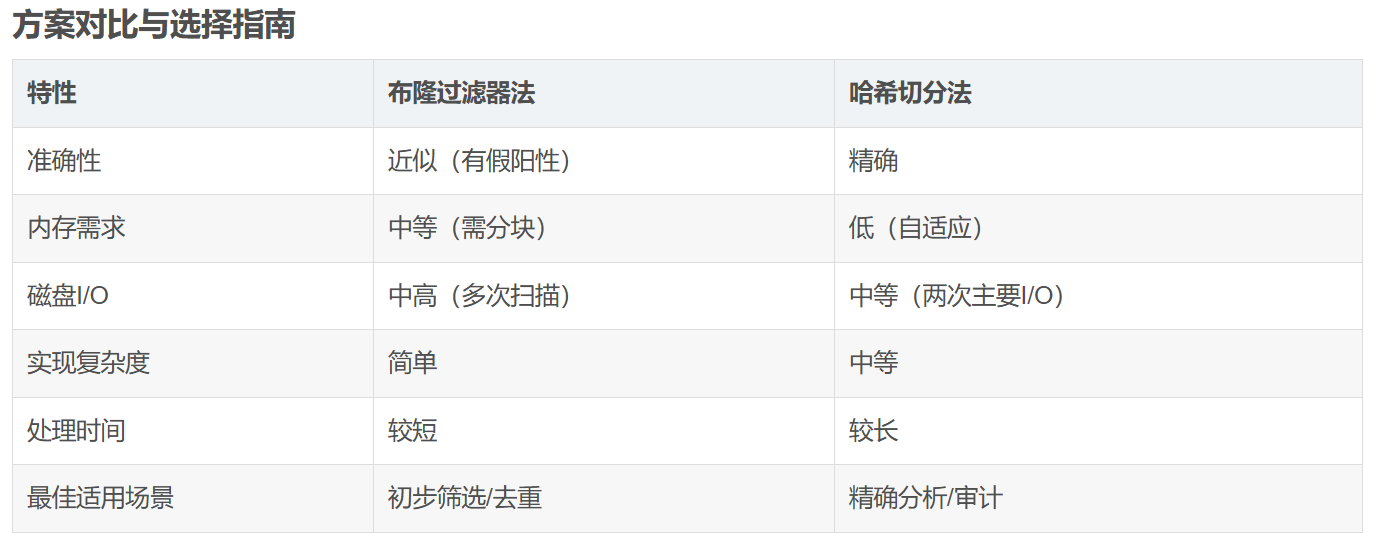
- 这个首先可以用布隆过滤器解决,⼀个文件中的 query 放进布隆过滤器,另⼀个文件依次查找,在的就是交集,问题就是找到交集不够准确 ,因为在的值可能因为哈希冲突导致误判的,但是交集一定被找到了。
所以这种方法还是难以满足我们的需求。
解决方案2
- 哈希切分:首先内存的访问速度远大于硬盘,大文件放到内存搞不定,那么我们可以考虑切分为小文件,再放进内存处理。但是不要平均切分,因为平均切分以后,每个小文件都需要依次暴力处理,效率还是太低了。
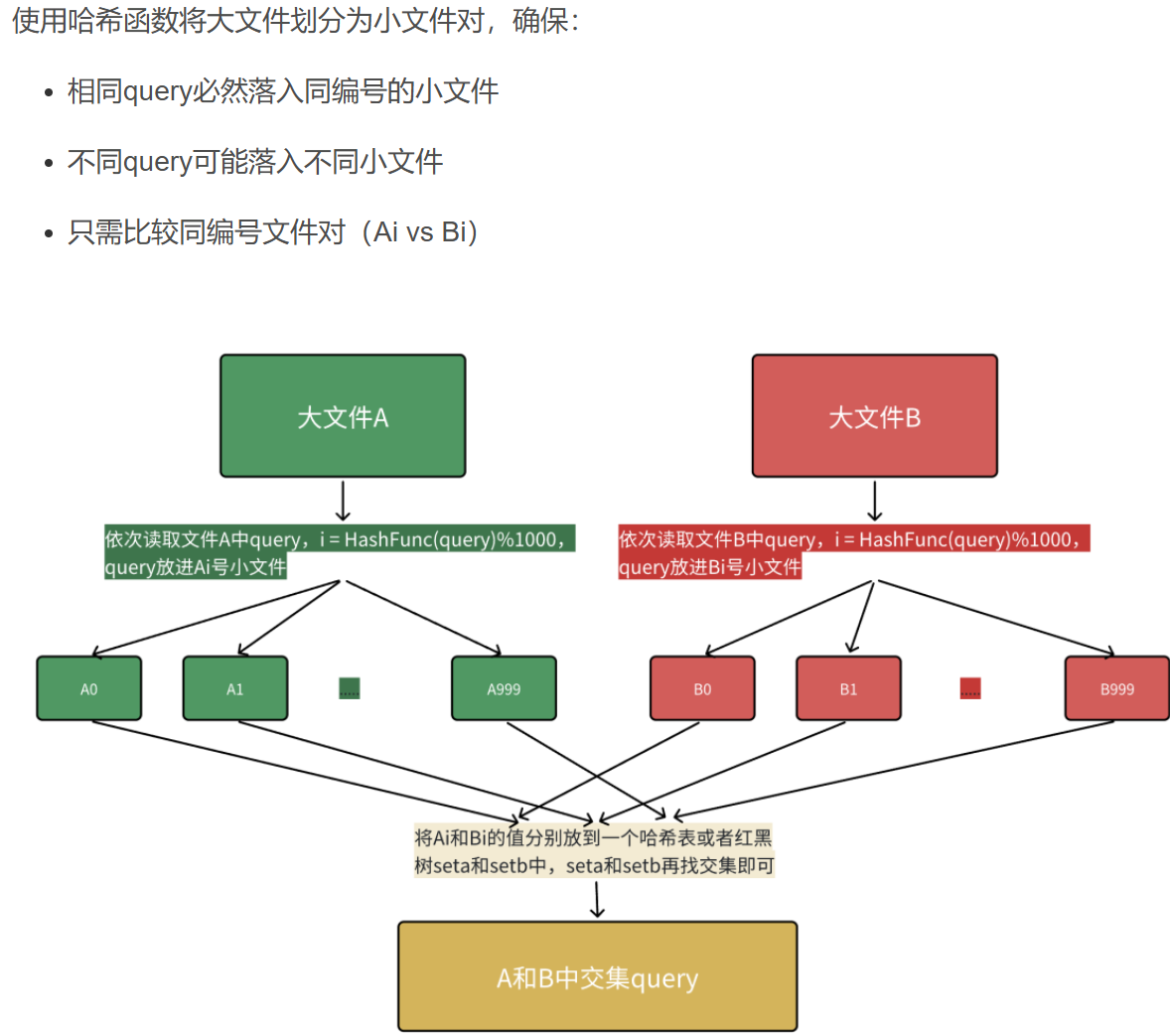
可以利用哈希切分,依次读取文件中 query,i = HashFunc(query)%N,N 为准备切分多少份小文件,N 取决于切成多少份,内存能放下,query 放进第 i 号小文件,这样 A 和 B 中相同的 query 算出的 hash 值 i 是⼀样的,相同的 query 就进入的编号相同的小文件就可以编号相同的我文件直接找交集,不用交叉找,效率就提升了。
本质是相同的 query 在哈希切分过程中,一定进入的同一个小问件 Ai 和 Bi,不可能出现 A 中的的 query 进入 Ai,但是 B 中的相同 query 进入了和 Bj 的情况,所以对 Ai 和 Bi 进行求交集即可,不需要 Ai 和 Bj 求交集。(本段表述中 i 和 j 是不同的整数)
哈希切分的问题就是每个小文件不是均匀切分的,可能会导致某个小文件很大内存放不下。我们细细分析⼀下某个小文件很大有两种情况:
- 这个小文件中大部分是同⼀个 query。
- 这个小文件是有很多的不同 query 构成,本质是这些 query 冲突了。针对情况1,其实放到内存的 set 中是可以放下的,因为 set 是去重的。针对情况2,需要换个哈希函数继续⼆次哈希切分。所以本体我们遇到大于 1G 小文件,可以继续读到 set 中找交集,若 set insert 时抛出了异常 ( set 插⼊数据抛异常只可能是申请内存失败了,不会有其他情况 ),那么就说明内存放不下是情况2,换个哈希函进行⼆次哈希切分后再对应找交集。




# 适用场景
- 需要精确结果的场景
- 用户行为分析
- 基因组数据比对
- 安全审计日志分析


3、题目三
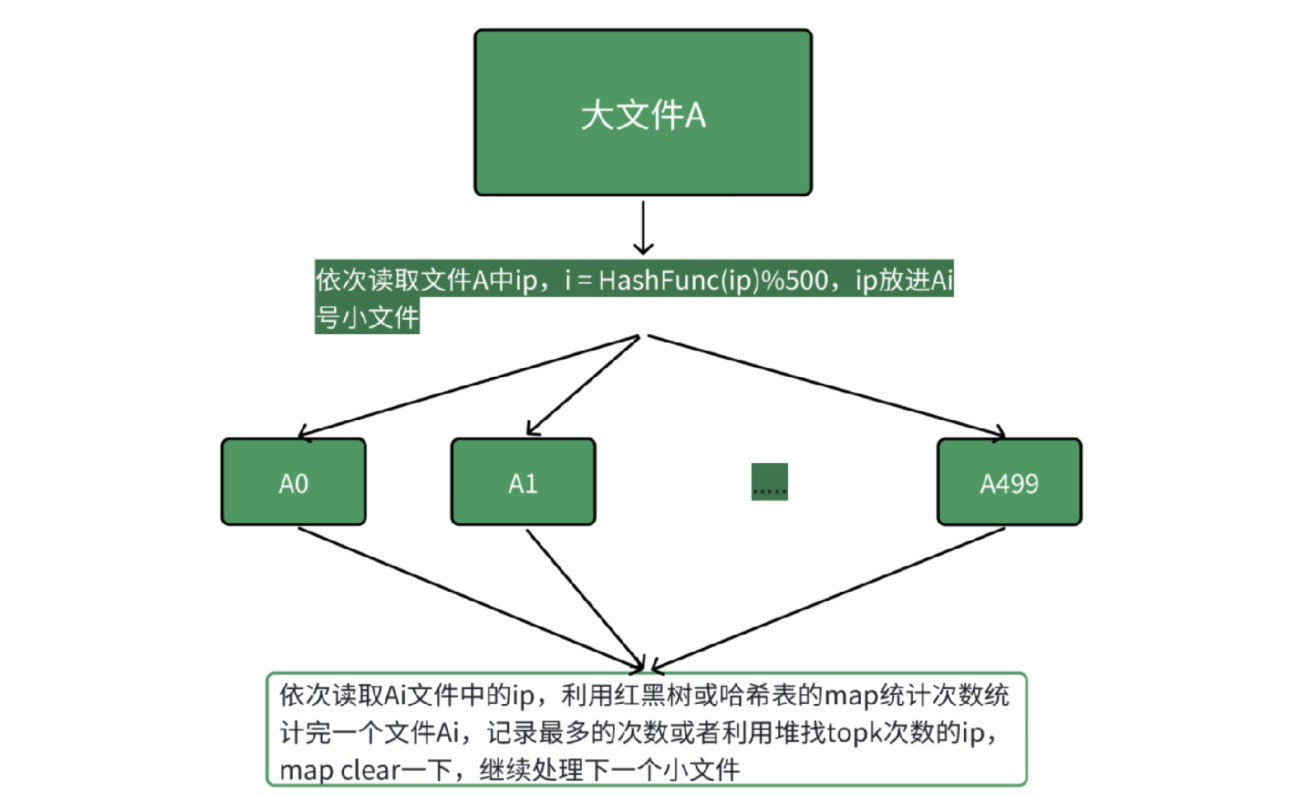
给⼀个超过 100G 大小的 log file, log中存着 ip 地址, 设计算法找到出现次数最多的 ip 地址、查找出现次数 前10 的 ip 地址
解题思路与上题类似:
- 读取日志文件中的每个 IP 地址
- 使用哈希函数计算:i = HashFunc(IP) % 500,将 IP 分配到对应的 Ai 小文件中
- 对每个小文件使用 map<string, int> 统计 IP 出现次数
- 在统计过程中记录出现次数最多的 IP 或 top10 IP
核心原理:
- 相同 IP 通过哈希处理后必定进入同一个小文件
- 不会出现同一个 IP 分散在多个小文件的情况
- 因此对小文件统计的 IP 频率是准确的