引子
我之前写过几篇手写Raft的文章,陆陆续续讲了很多Raft的原理:
最近准备写开源JobFlow,又深入研究了Nacos:
借这个机会,把Raft做个总结吧。分成两篇:
- 第一篇:Nacos到底是AP还是CP?一文说清楚(本篇)
- 第二篇:深入JRaft:Nacos配置中心的性能优化实践
这一篇我们聚焦核心问题,用大白话把Nacos的设计逻辑讲清楚。
一、直接回答:Nacos既是AP也是CP
很多人问:"Nacos到底是AP还是CP?"
答案是:看你用哪个功能。
erlang
Nacos的架构设计
├── 服务注册中心
│ ├── 临时实例(默认)→ AP模式
│ │ 协议:Distro
│ │ 特点:高可用,最终一致
│ │ 占比:99%的使用场景
│ │
│ └── 持久化实例 → CP模式
│ 协议:Raft
│ 特点:强一致,可能不可用
│ 占比:1%的特殊场景
│
└── 配置中心 → CP模式
协议:Raft
特点:强一致,数据不能错
占比:100%大部分人用Nacos做服务注册,用的都是临时实例(AP模式),根本没用到Raft。
只有配置中心和少量持久化实例才用Raft(CP模式)。
面试时怎么回答?
arduino
面试官:Nacos是AP还是CP?
如果直接回答"CP"或"AP":20分
正确回答:
"Nacos的服务注册中心,默认使用临时实例,是AP模式,
通过Distro协议实现最终一致性,保证高可用。
配置中心使用Raft协议,是CP模式,保证强一致性。
另外也支持持久化实例,同样走Raft协议,
适用于数据库、消息队列等基础设施的注册。"
这样回答:80分接下来我们深入讲讲为什么这么设计。
二、CAP理论:5分钟讲清楚
在讲Nacos之前,必须先理解CAP理论。
CAP是什么?
CAP是分布式系统的铁律,由三个单词首字母组成:
- C (Consistency) :一致性
- 所有节点在同一时间看到相同的数据
- 读取操作总能读到最新写入的值
- A (Availability) :可用性
- 任何请求都能得到响应
- 不管成功还是失败,总要给个答复
- P (Partition tolerance) :分区容错
- 网络分区时系统仍能工作
- 部分节点之间通信中断,系统照常运行
CAP定理
分布式系统最多只能同时满足两个。
但实际上,网络分区(P)是一定会发生的,你没法避免。所以真正的选择是:
css
当网络分区发生时,你选C还是A?CP系统:宁可不可用,也不能数据错
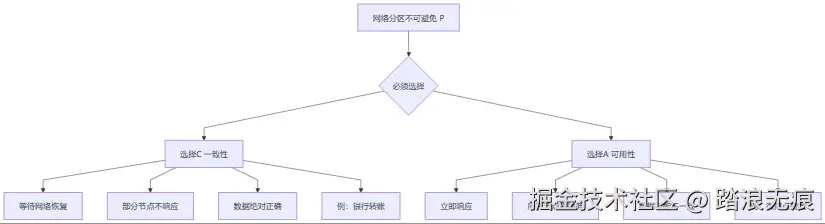
diff
典型场景:银行转账
发生网络分区:
- 杭州机房:有客户A的账户
- 北京机房:有客户B的账户
- 两个机房之间网络断了
如果选择C(一致性):
- 拒绝服务:"系统维护中,请稍后再试"
- 等网络恢复后再转账
- 保证不会出现"扣了A的钱,但B没收到"
代表技术:Raft、ZooKeeper、etcdAP系统:宁可数据不一致,也要继续服务
diff
典型场景:微博点赞
发生网络分区:
- 杭州机房:显示1000个赞
- 北京机房:显示1002个赞
- 两个机房之间网络断了
如果选择A(可用性):
- 继续服务,各机房独立计数
- 杭州的用户看到1000赞
- 北京的用户看到1002赞
- 等网络恢复后再同步(最终一致)
代表技术:Distro、Gossip、Cassandra关键理解
markdown
不是"AP系统不一致",而是"暂时不一致"。
AP系统保证:
1. 任何时候都能服务(可用)
2. 最终会一致(最终一致性)
3. 不一致的时间窗口很短(通常1-2秒)
CP系统保证:
1. 数据任何时候都一致(强一致)
2. 可能拒绝服务(不可用)
3. 不一致的时间窗口为0三、微服务注册为什么选AP?
理解了CAP,我们看看为什么微服务注册要用AP模式。
微服务的场景
假设你的电商系统:
diff
用户服务:10个实例
订单服务:20个实例
商品服务:15个实例
每天:
- 凌晨发版重启:45个实例重启
- 高峰期扩容:新增10个实例
- 低峰期缩容:下线5个实例
- 偶尔宕机:1-2个实例挂掉
平均每小时有几十次实例上下线如果用CP模式会怎样?
markdown
场景:订单服务的一个实例宕机
CP模式的处理流程:
1. Nacos检测到实例下线
2. 需要通过Raft协议更新注册信息
3. Leader节点发起日志复制
4. 等待过半节点确认(50-100ms)
5. 确认后,所有节点才更新注册表
问题:
- 慢:每次上下线都要走共识
- 阻塞:写操作会等待
- 风险:Nacos集群网络分区导致服务不可用
最严重的:
如果Nacos集群自己发生网络分区
→ 无法达成共识
→ 拒绝所有注册/心跳
→ 整个系统瘫痪AP模式的处理方式
markdown
场景:订单服务的一个实例宕机
AP模式的处理流程:
1. Nacos某个节点检测到(心跳超时)
2. 立即更新本地注册信息(1-2ms)
3. 异步通知其他Nacos节点(不等待)
4. 客户端在1-2秒内拉取到最新信息
优势:
- 快:直接写本地内存
- 不阻塞:不等其他节点响应
- 高可用:即使Nacos网络分区也能各自服务
最重要的:
微服务调用有重试机制
→ 即使短暂拿到过期的注册信息
→ 调用失败后会重试其他实例
→ 影响很小临时实例的工作原理
sequenceDiagram
participant S as 服务实例
participant N1 as Nacos节点1
participant N2 as Nacos节点2
participant N3 as Nacos节点3
participant C as 调用方
Note over S,N1: 1. 服务注册
S->>N1: 注册实例信息
N1->>N1: 写入本地内存(1-2ms)
N1-->>S: 注册成功
par 异步同步
N1->>N2: 异步同步实例信息
N1->>N3: 异步同步实例信息
end
Note over S,N1: 2. 心跳保活
loop 每5秒
S->>N1: 发送心跳
N1->>N1: 更新lastBeat时间
end
Note over S,N1: 3. 实例下线
S->>S: 进程崩溃,停止心跳
Note over N1: 15秒后
N1->>N1: 检测到心跳超时
N1->>N1: 标记实例不健康
par 异步通知
N1->>N2: 通知实例下线
N1->>N3: 通知实例下线
end
Note over C: 4. 调用方拉取
C->>N2: 查询服务列表
N2-->>C: 返回健康实例列表
临时实例的时间线
r
T + 0秒:服务启动,注册到Nacos
T + 5秒:发送第一次心跳
T + 10秒:发送第二次心跳
T + 15秒:服务宕机,停止心跳
T + 30秒:Nacos检测到15秒没心跳
标记实例为"不健康"
但不删除(给恢复的机会)
T + 45秒:Nacos检测到30秒没心跳
删除实例
关键时间点:
- 5秒:心跳间隔
- 15秒:标记不健康的阈值
- 30秒:删除实例的阈值为什么微服务适合AP?
markdown
微服务的特点:
1. 实例频繁上下线
- 发版、重启、扩缩容
- 一天几十次很正常
2. 调用有容错机制
- 重试
- 熔断
- 降级
3. 短暂不一致可以接受
- 拿到过期的实例信息
- 调用失败重试就行
- 1-2秒后数据就一致了
所以:
- 高可用 > 强一致
- 选择AP模式四、配置中心为什么选CP?
配置和服务注册完全不同,配置错了是致命的。
配置不一致的灾难
diff
场景:数据库连接池配置
如果使用AP模式,可能出现:
Nacos节点1的配置:
datasource.url=jdbc:mysql://192.168.1.100:3306/db
Nacos节点2的配置:
datasource.url=jdbc:mysql://192.168.1.200:3306/db
结果:
- 部署在杭州机房的应用实例
从Nacos节点1拉取配置
连到数据库A(192.168.1.100)
- 部署在北京机房的应用实例
从Nacos节点2拉取配置
连到数据库B(192.168.1.200)
后果:
- 同一个订单,杭州看到的状态是"待支付"
- 北京看到的状态是"已支付"
- 数据完全混乱
- 系统故障
这是不可接受的!CP模式的配置写入
sequenceDiagram
participant C as 客户端
participant L as Nacos Leader
participant F1 as Nacos Follower1
participant F2 as Nacos Follower2
C->>L: 发布配置
Note over L: 1. 写入本地日志
L->>L: append log
Note over L,F2: 2. 并行复制
par 复制到所有Follower
L->>F1: 复制日志
L->>F2: 复制日志
end
F1->>F1: 写入日志
F1-->>L: 确认
F2->>F2: 写入日志
F2-->>L: 确认
Note over L: 3. 过半确认,提交
L->>L: commit log
Note over L: 4. 应用到配置数据
L->>L: apply to config store
L-->>C: 发布成功
Note over L,F2: 5. 推送配置变更
par 通知所有应用实例
L->>F1: 推送新配置
L->>F2: 推送新配置
end
CP模式的处理流程
markdown
写配置的完整流程:
1. 客户端提交配置变更
POST /nacos/v1/cs/configs
dataId: application.yml
content: server.port=8080
2. Leader收到请求
- 写入本地日志文件
- 分配日志索引:index=12345
3. 并行复制给Follower
- Leader → Follower1
- Leader → Follower2
- 异步发送,但要等响应
4. 等待过半确认(阻塞)
- 3个节点需要2个确认
- 可能等50-100ms
- 超时5秒后失败
5. 过半确认后提交
- 标记日志为已提交
- 应用到配置数据库
6. 返回客户端成功
7. 推送配置给应用
- 所有订阅该配置的应用
- 实时收到变更通知配置中心的特点
markdown
配置的特点:
1. 变更不频繁
- 一天可能就改几次
- 不像服务实例一天上下线几十次
2. 可以接受写入慢一点
- 50-100ms可以接受
- 不需要像注册那样毫秒级
3. 绝对不能不一致
- 宁可写入失败(503错误)
- 也不能不同节点配置不一样
4. 需要可靠性
- 配置要持久化
- 重启不能丢
- 历史可追溯
所以:
- 强一致 > 高可用
- 选择CP模式五、Raft协议5分钟讲清楚
Nacos的配置中心用的是Raft协议。理解Raft是理解Nacos的基础。
Raft的核心思想
用一句话总结:
arduino
通过"过半确认",保证所有节点按相同顺序执行相同操作这句话有三个关键词:
- 过半确认:多数派原则
- 相同顺序:日志索引保证
- 相同操作:日志内容一致
Raft的三大机制
1. Leader选举
diff
Raft集群中任何时候只有一个Leader
Leader的职责:
- 接收客户端请求
- 负责日志复制
- 决定何时提交
选举规则:
- 日志最新的节点优先当选
- 必须获得过半选票
- 通过Term(任期号)区分新老Leader
为什么日志要最新?
→ 保证新Leader一定有所有已提交的数据
→ 否则已提交的数据可能丢失选举过程:
graph TD
A[Follower检测心跳超时] --> B[转为Candidate]
B --> C[Term+1]
C --> D[给自己投票]
D --> E[向其他节点请求投票]
E --> F{收到过半选票?}
F -->|是| G[成为Leader]
F -->|否| H[继续等待或重新选举]
G --> I[发送心跳维持地位]
E --> J{收到更高Term的消息?}
J -->|是| K[转回Follower]
2. 日志复制
Leader收到写请求后:
markdown
1. 写入本地日志
LogEntry {
index: 100 // 日志位置
term: 5 // 任期号
command: "PUT name=alice" // 具体操作
}
2. 并行复制给Follower
- Leader发送AppendEntries RPC
- 携带日志内容
3. 等待过半确认
- 3节点需要2个确认
- 5节点需要3个确认
4. 过半后提交
- 标记日志为已提交
- 应用到状态机
5. 返回客户端成功关键的一致性检查:
yaml
Leader发送日志时,会带上"前一条日志"的信息:
AppendEntriesRequest {
prevLogIndex: 99
prevLogTerm: 5
entries: [
{index: 100, term: 5, command: "..."}
]
}
Follower收到后:
1. 检查本地日志[99]
2. 如果term也是5 → 接受,追加日志[100]
3. 如果term不是5 → 拒绝,说明日志冲突
为什么这样检查?
→ 递归保证:如果99一致,说明1-98都一致
→ 如果100一致,说明1-99都一致
→ 保证整个日志序列一致3. Term机制
ini
Term(任期)是Raft的逻辑时钟
作用1:区分新老Leader
旧Leader: term=5
新Leader: term=6
旧Leader看到term=6 → 自动降级为Follower
作用2:防止脑裂
两个Candidate同时选举
→ term高的会赢
→ term低的会失败
作用3:拒绝过期请求
收到term=5的请求
当前term=6
→ 直接拒绝
规则:
- 每次选举term+1
- 收到更高term的消息 → 立即更新自己的term
- 拒绝处理更低term的请求过半确认的数学
diff
为什么要过半?
3节点集群:
- 需要2个节点确认(包括Leader自己)
- 容忍1个节点故障
5节点集群:
- 需要3个节点确认
- 容忍2个节点故障
N节点集群:
- 需要(N/2 + 1)个节点确认
- 容忍(N-1)/2个节点故障
为什么不是全部确认?
→ 任何一个节点故障就不可用了
为什么不是1/3确认?
→ 可能出现数据不一致
过半是最优解:
→ 容错能力和一致性的平衡点Raft保证的安全性
markdown
核心保证:已提交的数据永不丢失
怎么保证?
1. 选举限制
- 只有日志最新的节点才能当选
- 新Leader一定有所有已提交的数据
2. 提交规则
- 只能提交当前term的日志
- 旧term的日志通过新日志间接提交
3. 日志匹配
- 通过prevLogIndex/prevLogTerm检查
- 发现冲突就删除重建
结果:
- 所有节点最终日志完全一致
- 已提交的数据在任何节点都能读到
- 即使发生Leader切换也不会丢数据六、Nacos的双模式对比
现在我们理解了AP和CP,也理解了Raft,来看看Nacos的两种模式。
临时实例 vs 持久化实例
java
// 注册临时实例(默认)
Instance instance = new Instance();
instance.setIp("192.168.1.100");
instance.setPort(8080);
instance.setEphemeral(true); // 临时实例
namingService.registerInstance("user-service", instance);
// 注册持久化实例
Instance instance = new Instance();
instance.setIp("192.168.1.100");
instance.setPort(3306);
instance.setEphemeral(false); // 持久化实例
namingService.registerInstance("mysql-service", instance);详细对比
| 维度 | 临时实例(AP) | 持久化实例(CP) |
|---|---|---|
| 协议 | Distro | Raft |
| 写入速度 | 1-2ms | 50-100ms |
| 一致性 | 最终一致(1-2秒) | 强一致(实时) |
| 保活方式 | 客户端发心跳 | Server主动检查 |
| 实例下线 | 心跳停止自动删除 | 需要显式删除 |
| 数据持久化 | 否,重启丢失 | 是,持久化到磁盘 |
| 网络分区 | 各自继续服务 | 少数派不可用 |
| 适用场景 | 微服务实例 | 数据库、消息队列 |
| 使用占比 | 99% | 1% |
什么时候用持久化实例?
markdown
适合持久化实例的场景:
1. 数据库实例
- MySQL、PostgreSQL、Redis
- 实例不会频繁上下线
- 需要准确的健康检查
- 地址信息必须准确
2. 消息队列
- RocketMQ、Kafka
- Broker地址不能错
- 需要持久化保存
3. 其他基础设施
- Elasticsearch集群
- 配置中心本身
特点:
- 实例稳定,很少变化
- 地址信息必须准确
- 重启后仍需要保留注册信息
markdown
不适合持久化实例的场景:
1. 普通微服务
- Spring Boot应用
- 频繁发版重启
- 实例动态扩缩容
2. 短生命周期应用
- Kubernetes Pod
- Serverless函数
- 临时任务
特点:
- 实例频繁上下线
- 允许短暂不一致
- 调用方有重试机制实际使用建议
diff
经验法则:
默认用临时实例
- 99%的微服务场景
- 除非有特殊需求
只在这些情况用持久化实例:
- 数据库、缓存、MQ等基础设施
- 实例地址几乎不变
- 需要准确的健康检查
- 必须保证数据强一致
如果不确定用哪个:
→ 用临时实例就对了七、常见面试问题
Q1:为什么Nacos不全用Raft?
markdown
如果服务注册也用Raft:
缺点:
1. 写入慢
- 每次注册/心跳都要过半确认
- 原来1-2ms,现在50-100ms
2. 可用性差
- Nacos集群网络分区时可能不可用
- 影响所有微服务
3. 吞吐量低
- Leader成为瓶颈
- 无法支撑大规模集群
优点:
1. 强一致性
- 所有节点数据完全一致
权衡:
- 微服务注册:不需要强一致,需要高可用 → AP
- 配置中心:必须强一致,可以牺牲部分可用 → CPQ2:如果过半节点都宕机了怎么办?
markdown
场景:3节点集群,2个节点宕机
Raft的处理:
- 拒绝所有写入(无法达成共识)
- 已有的配置可以读取
- 等待节点恢复
临时方案:
1. 紧急扩容
- 快速启动新节点加入集群
- 等新节点追上数据
2. 降级到单节点模式
- 仅紧急情况
- 有数据丢失风险
- 需要专业人员操作
预防措施:
- 部署5节点(容忍2个故障)
- 跨机房部署
- 做好监控告警
- 备份配置数据Q3:Distro协议和Raft协议的本质区别?
markdown
Distro(AP):
- 设计目标:高可用
- 写入方式:直接写本地,异步同步
- 数据一致:最终一致,允许短暂不一致
- 故障处理:各自独立服务
- 性能:极快(1-2ms)
Raft(CP):
- 设计目标:强一致
- 写入方式:Leader复制,等过半确认
- 数据一致:强一致,任何时候都一致
- 故障处理:少数派拒绝服务
- 性能:较慢(50-100ms)
选择依据:
- 数据能容忍短暂不一致吗?
- 能 → Distro
- 不能 → RaftQ4:为什么心跳超时是15秒?
diff
Nacos临时实例的时间参数:
心跳间隔:5秒
不健康阈值:15秒(3次心跳)
删除阈值:30秒(6次心跳)
设计考虑:
15秒不健康:
- 太短(如5秒)→ 网络抖动就误判
- 太长(如60秒)→ 故障发现太慢
- 15秒是平衡点
30秒删除:
- 给实例恢复的时间
- 防止短暂重启被删除
实际生产可调整:
spring.cloud.nacos.discovery:
heart-beat-interval: 5000
heart-beat-timeout: 15000
ip-delete-timeout: 30000Q5:Leader宕机后需要多久选出新Leader?
markdown
Raft选举时间线:
T+0秒:Leader宕机,停止发送心跳
T+5秒:某个Follower心跳超时
转为Candidate,发起选举
Term从5变为6
T+5.1秒:其他Follower收到投票请求
检查Candidate的日志是否最新
如果是,投票给它
T+5.2秒:Candidate收到过半选票
成为新Leader
开始发送心跳
T+5.3秒:其他Follower收到新Leader的心跳
确认新Leader
总耗时:约5秒
实际可能更快:
- 网络好的情况下1-2秒
- 可以调小election_timeout加速Q6:配置中心的写入性能如何?
markdown
性能数据(3节点集群):
写入延迟:
- P50: 20-50ms
- P99: 100-200ms
- P999: 500ms
吞吐量:
- 单Leader:500-1000 QPS
- 对于配置中心足够了
(配置变更频率很低)
性能瓶颈:
1. Leader单点
- 所有写入走Leader
2. 磁盘IO
- 每次写入要fsync
3. 网络延迟
- 需要等Follower响应
优化方向:
- 批量写入
- 异步刷盘
- SSD硬盘八、总结
核心要点
1. Nacos是AP还是CP?
diff
不是二选一,而是针对不同场景:
服务注册(临时实例):AP
- Distro协议
- 高可用优先
- 最终一致性
- 适合微服务
配置中心:CP
- Raft协议
- 强一致优先
- 可能不可用
- 适合配置管理
持久化实例:CP
- Raft协议
- 强一致优先
- 适合基础设施2. CAP理论的本质
arduino
不是"能不能同时满足CAP"
而是"网络分区时,选C还是A"
CP:宁可不可用,也不能数据错
AP:宁可暂时不一致,也要继续服务3. Raft的核心
diff
一句话:通过过半确认,保证所有节点按相同顺序执行相同操作
三大机制:
- Leader选举:日志最新的当选
- 日志复制:过半确认后提交
- Term机制:防止脑裂
安全保证:已提交的数据永不丢失4. 实际使用建议
diff
默认用临时实例:
- 99%的微服务场景
- 高可用,性能好
只在必要时用持久化实例:
- 数据库、MQ等基础设施
- 需要强一致性
配置中心必须用Raft:
- 配置错了是致命的
- 不能接受不一致写在最后
Nacos的设计很聪明:不追求"完美的一致性"或"绝对的可用性",而是根据业务特点选择合适的模式。
这也是分布式系统设计的核心思想:没有银弹,只有权衡。
如果你想深入了解Raft的实现细节、JRaft的性能优化、以及生产环境的最佳实践,欢迎继续阅读下一篇:
《深入JRaft:Nacos配置中心的性能优化实践》
参考资料
- Nacos官方文档:nacos.io/zh-cn/docs/...
- Raft论文:In Search of an Understandable Consensus Algorithm
- CAP理论:en.wikipedia.org/wiki/CAP_th...
本文完