文章目录
- [Ⅰ. 运行时数据区(内存布局)](#Ⅰ. 运行时数据区(内存布局))
- [Ⅱ. JVM 运行流程](#Ⅱ. JVM 运行流程)
-
- [⭐ 大致流程](#⭐ 大致流程)
- [一、类加载(Class Loading)](#一、类加载(Class Loading))
- [二、执行引擎(Execution Engine)](#二、执行引擎(Execution Engine))
- [三、运行时数据区(Runtime Data Area)](#三、运行时数据区(Runtime Data Area))
- [四、本地接口(Native Interface)](#四、本地接口(Native Interface))
- [五、垃圾回收(Garbage Collection, GC)](#五、垃圾回收(Garbage Collection, GC))
- [Ⅲ. 类加载 `Class Loading`](#Ⅲ. 类加载
Class Loading)

Ⅰ. 运行时数据区(内存布局)
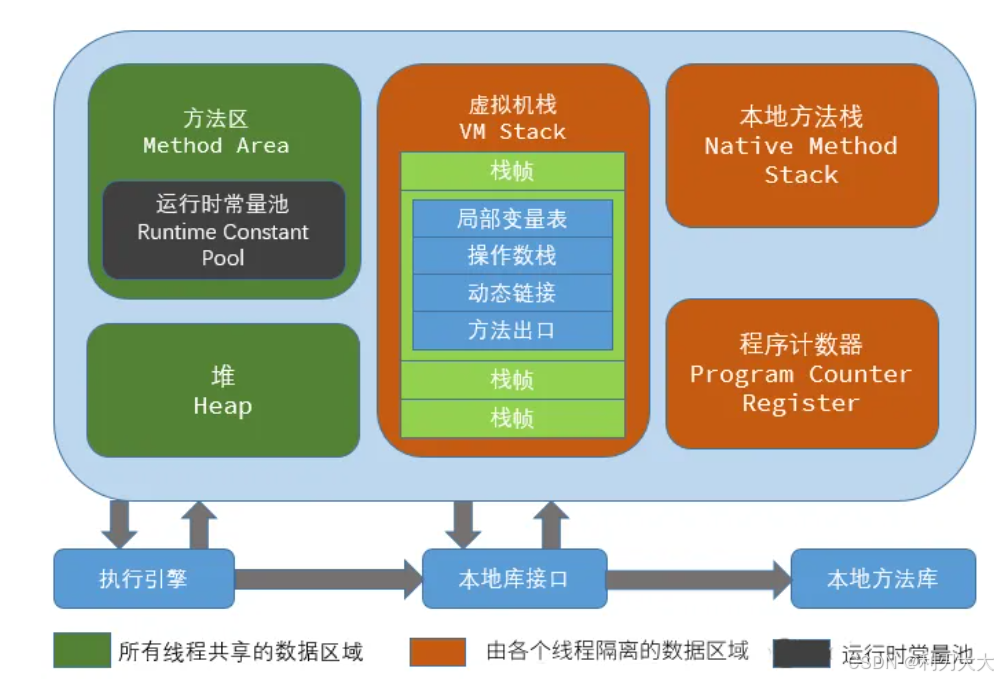
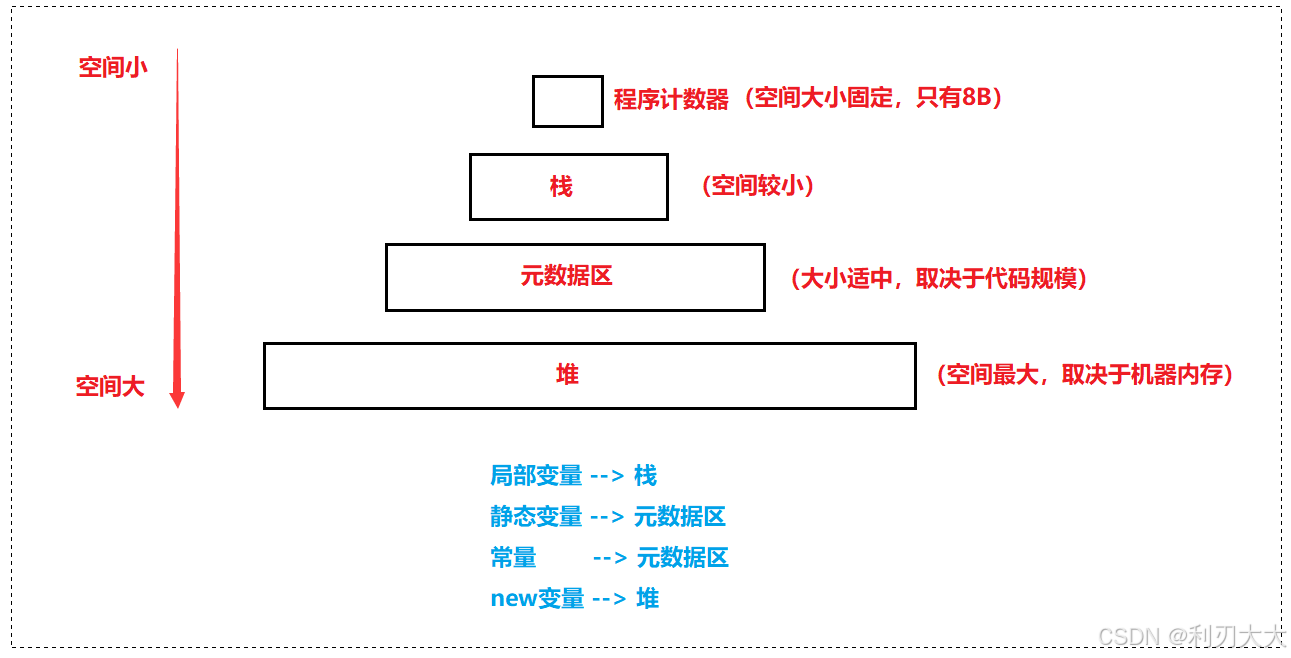
一个 Java 程序对应一个 JVM ,而一个 JVM 对应一套数据区!
-
程序计数器 (
PC Register) :这只是一个很小的内存空间,保存着下一条执行的指令的地址。- 它是 每个线程私有 的,属于线程隔离的数据。
- 如果正在执行的是
native方法,则这个值是未定义的。 - 它的存在是为了解决线程切换后能恢复到正确的执行位置,因此对多线程执行非常关键。
-
虚拟机栈 (
JVM Stack):存放了方法调用的关系。- 虚拟机栈是线程私有的。
JVM栈中每一个元素,称为栈帧 (Stack Frame),每个方法在调用时都会创建一个新的栈帧。比如:局部变量,当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。JVM会抛出如StackOverflowError和OutOfMemoryError,都和该区域有关。- 栈帧中包含:
- 局部变量表
- 操作数栈
- 动态连接
- 方法返回地址
- 其他信息,保存的都是与方法执行时相关的一些信息。
-
本地方法栈 (
Native Method Stack) :用于支持Native方法的调用。- 本地方法栈是线程私有的。
- 本地方法栈与虚拟机栈的作用类似,只不过保存的内容是
Native方法的局部变量。 - 底层是
C/C++实现的。 - 在有些版本的
JVM实现中(例如HotSpot),本地方法栈和虚拟机栈是一起的。
-
堆 (
Heap) :JVM中最大的内存区域,保存使用new创建的对象实例。- 堆是线程共享的。
- 堆的生命周期:堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁。
- 堆是垃圾回收器的主要工作场所。
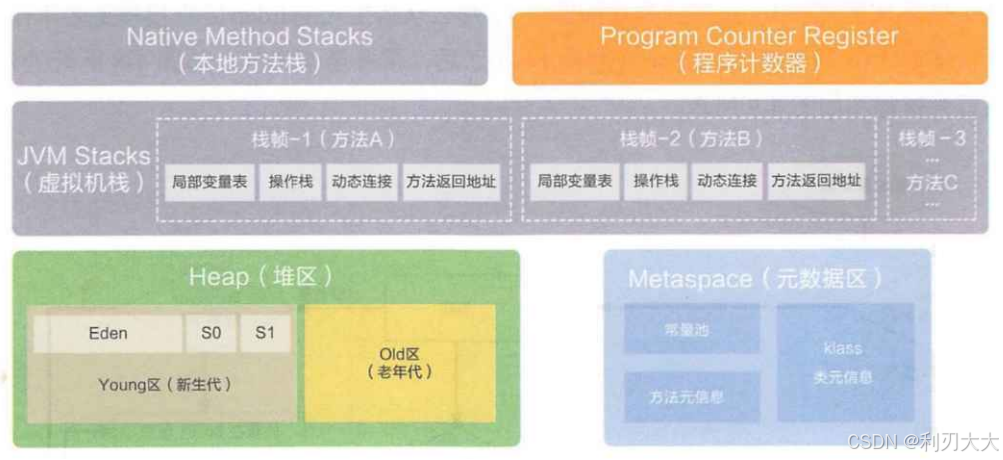
- 堆细分为:新生代 (一个
Eden、两个Survivor) 和 老年代 - 堆中每个对象不只是包含字段值,在每个对象的开头还保存了对象头结构 ,用来管理对象运行时信息的元数据容器,每个
Java对象在内存中分为三部分:- 对象头 (
Header):存储锁状态、GC 分代年龄、哈希码等 - 实例数据 (
Instance Data):对象的字段值 - 对齐填充 (
Padding):补齐内存对齐
- 对象头 (
-
方法区 (
Method Area) :存储类的元数据信息 (对象实例存放在堆中,方法区只是存放类的元数据)-
方法区是线程共享的。
-
实际上在
Java8以后,方法区被 "元数据区" 替代,从原来的 "堆内存" 中移到 "本地内存" 中。
C+-------------------------------+ | 操作系统分配的总内存(物理RAM)| +-------------------------------+ | | | +------------------+ | | +--------v------+ +--------------v------------------+ | JVM 管理区域 | | JVM 外部使用但不直接管理(本地内存)| | | | | | - 堆(heap) | | - 元空间(Metaspace) | | - 栈(stack) | | - DirectBuffer / JNI 内存 | | - 程序计数器 | | - JIT 编译缓存 / 线程内部结构 | +--------------+ +----------------------------------+-
存储内容包括:
- 类的结构信息(字段、方法、接口、访问修饰符等等)
- 静态变量
- 运行时常量池(字面量、符号引用)
- JIT 编译后的代码(在某些实现中)
-
Ⅱ. JVM 运行流程
⭐ 大致流程
JVM 执行流程大概如下所示:

口诀: 编译成 class,加载做五步,解释+JIT,运行靠内存,回收靠 GC。
一、类加载(Class Loading)
类加载是 JVM 把 .class 文件(字节码)加载进内存,并在内存中生成一个 Class 对象的 全过程,包括下面三个主要阶段:
- 加载 :通过类加载器 把字节码读进来,生成
Class对象。 - 链接:分为验证、准备、解析三个子阶段。
- 初始化 :执行
<clinit>静态代码块和静态变量赋值。
二、执行引擎(Execution Engine)
JVM 核心部件,负责执行字节码:
- 解释执行:将字节码一行一行解释为机器指令。
- 即时编译 (JIT):将热点代码编译为本地机器码,提高性能。
三、运行时数据区(Runtime Data Area)
JVM 内存模型,运行时管理所有数据:
| 区域 | 作用描述 |
|---|---|
| 方法区(Method Area) | 存储类的信息(类元数据)、常量、静态变量等 |
| 堆(Heap) | 存储对象实例,是垃圾回收的主要区域 |
| 虚拟机栈(Stack) | 每个线程私有,存储方法调用的信息(帧栈)、局部变量等 |
| 本地方法栈 | 为执行 native 方法准备 |
| 程序计数器(PC) | 每个线程私有,记录当前线程所执行的字节码行号 |
四、本地接口(Native Interface)
JVM 可以调用本地语言(如 C、C++)写的函数,依赖 JNI(Java Native Interface)。
五、垃圾回收(Garbage Collection, GC)
- 自动管理堆内存,回收无用对象
- 分代回收:新生代、老年代
- 常见算法:标记-清除、复制、标记-整理等
Ⅲ. 类加载 Class Loading
一个类在什么时候触发 "加载" 呢❓❓❓
① 构造某个类的实例时
② 调用类的静态方法/静态成员时
③ 使用子类时,也会触发父类的加载
对于一个类来说,它的生命周期是这样子的:
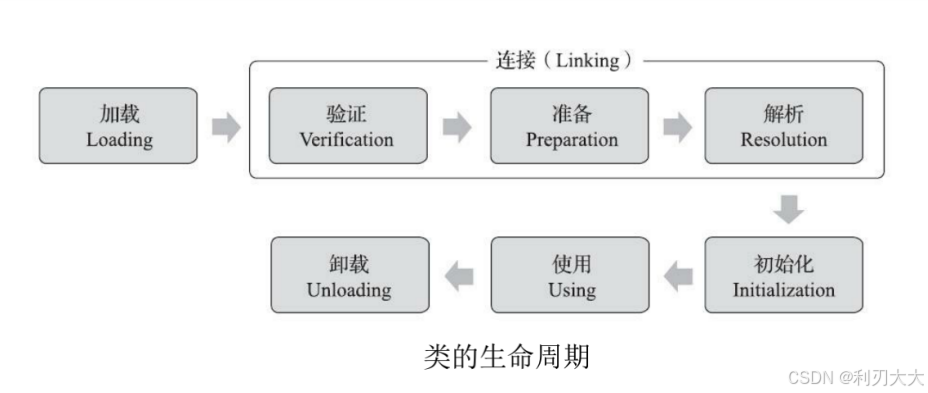
其中前五步是固定的顺序,也是类加载的过程!
一、类加载过程
- 加载(Loading)
JVM根据类的 "全限定名",委托给类加载器去加载该类 ,并遵循 双亲委派模型- 然后类加载器从
.class文件中读取字节流 - 最后
JVM将字节流解析为Class对象,放入方法区中(这不等于立即解析所有内容)
- 验证(Verification)
- 确保类的字节码是合法的,防止恶意代码执行:
- 文件格式验证(确保这是一个 "能看懂" 的
.class文件,不是乱写的二进制) - 元数据验证(确保类的结构层次是 "符合 Java 语义的")
- 字节码验证(防止非法操作、恶意字节码,比如篡改局部变量、栈顶数据,
JVM崩溃) - 符号引用验证(为解析阶段提前做准备,避免运行时解析失败)
- 文件格式验证(确保这是一个 "能看懂" 的
- 确保类的字节码是合法的,防止恶意代码执行:
- 准备(Preparation)
- 为类的 静态变量 分配内存,并设置 默认初始值 (不是代码中的赋值)。比如
static int a = 10;只分配内存,初始化为默认值0,而还没到赋值为10的阶段。
- 为类的 静态变量 分配内存,并设置 默认初始值 (不是代码中的赋值)。比如
- 解析(Resolution)
- 将常量池中的 符号引用 (如类名、字段名)转换为实际的 直接引用 (内存地址),即对常量进行初始化。
- 初始化(Initialization)
- 执行类的构造方法(类构造器),即静态变量赋值、静态代码块执行等。
二、.class 文件的结构
.class 文件是一个 以字节为单位的严格二进制格式 的结构体,包含类的所有元信息 、方法字节码 、常量池等。如下所示:
c
ClassFile {
u4 magic; // 魔数,标识文件的类型
u2 minor_version; // 次版本号
u2 major_version; // 主版本号
u2 constant_pool_count; // 常量池数量
cp_info constant_pool[]; // 常量池,包括字符串、类名、方法名、字段名等,最核心的部分
u2 access_flags; // 访问标志(public, abstract, final等)
u2 this_class; // 当前类的索引(指向常量池)
u2 super_class; // 父类索引(指向常量池)
u2 interfaces_count; // 实现接口数量
u2 interfaces[]; // 接口表
u2 fields_count; // 字段数量
field_info fields[]; // 字段表
u2 methods_count; // 方法数量
method_info methods[]; // 方法表
u2 attributes_count; // 属性数量
attribute_info attributes[]; // 属性表(如源码信息、注解、行号表等)
}三、类加载器
类加载器(ClassLoader)是类加载机制的核心,本质上就是一个 "负责读取类的字节流并交给 JVM 转换为 Class 对象" 的工具。
JVM 提供了 三种主要的类加载器:
| 类加载器 | 作用 |
|---|---|
| Bootstrap ClassLoader | 启动类加载器:加载 java 核心类库 |
| Extension ClassLoader | 扩展类加载器:加载拓展目录下的类(jdk 自带但不是标准约定的库) |
| Application ClassLoader | 应用类加载器:加载你写的代码和第三方库类 |
四、双亲委派模型(Parent Delegation Model)
在类加载的加载阶段 ,JVM 会根据类的全限定名 ,通过类加载器加载该类。类加载器在加载类时默认遵循 "双亲委派模型",即优先让父类加载器尝试加载类,只有在父加载器无法加载时,才由当前加载器尝试加载。
原则:从下往上委托,然后先父后子,从上往下加载 。
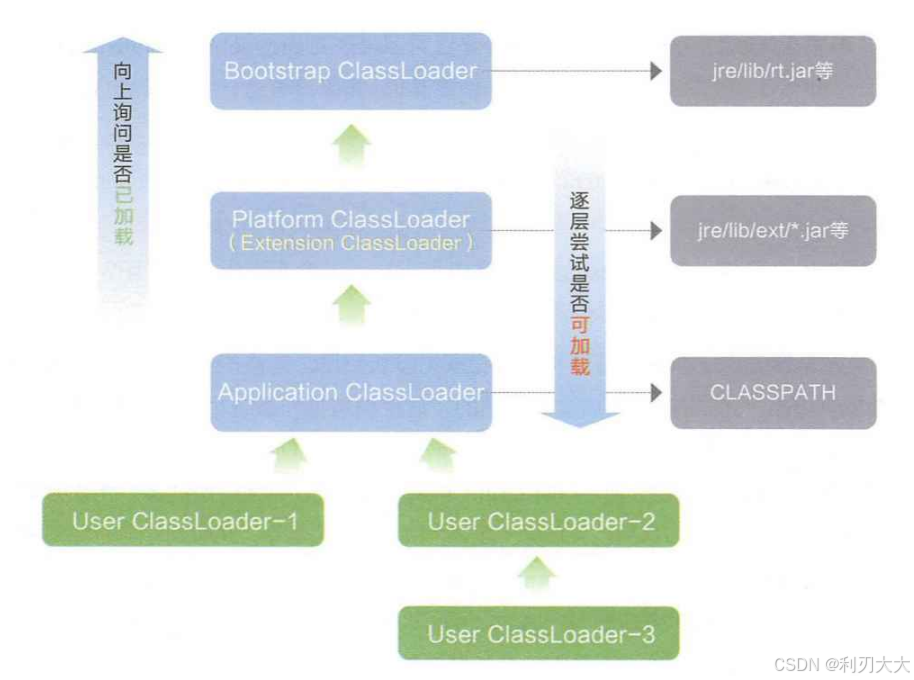
过程如下所示:
- 当前类加载器先将请求委托给父类加载器,注意是层层委托上去,直到最高层加载器。
- 然后从最高层父类加载器开始加载
class文件,如果加载不到,则一层一层往下尝试是否能进行加载。
这样子做是为了保证:
java.lang.Object、String这类核心类一定由 启动类加载器 加载,避免用户自定义的类覆盖核心类 ,提升安全性。- 比如用户伪造了一个
java.lang.String,但加载器是从上往下的,此时会先加载父类中的java.lang.String,而不会加载到用户伪造的那个版本!
- 比如用户伪造了一个
- 避免类的重复加载 。
- 比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。