🐼什么是列表
redis中的列表有点像C++中的deque,我们暂且把它当做顺序表/链表来使用就行。
假设现在有a、b、c、d、e 五个元素从左到右组成了⼀个有序的列表,列表中的每个字符串称为元素(element),⼀个列表最多可以存储 2 - 32^1个元素。在 Redis 中,可以对列表两端插⼊(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。如图所示
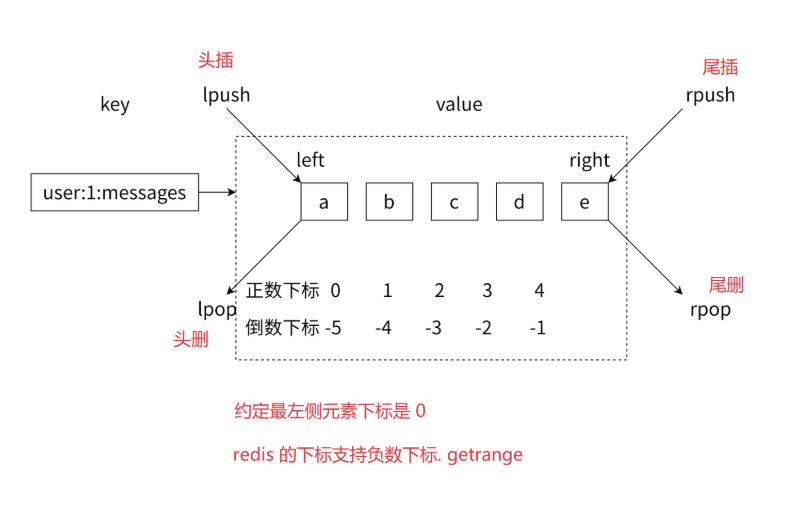
列表中可以有重复元素
🐼列表的操作
🌻LPUSH
将⼀个或者多个元素从左侧放⼊(头插)到 list 中。相当于头插
bash
LPUSH key element [element ...]时间复杂度:只插⼊⼀个元素为 O(1), 插⼊多个元素为 O(N), N 为插⼊元素个数.
返回值:插⼊后 list 的⻓度
🌻LPUSHX
在 key 存在时,将⼀个或者多个元素从左侧放⼊(头插)到 list 中。不存在,直接返回
也就是只有key存在才继续插入,这个X表示的是exists
cpp
LPUSHX key element [element ...]🌻RPUSH
将⼀个或者多个元素从右侧放⼊(尾插)到 list 中。
cs
RPUSH key element [element ...]时间复杂度:只插⼊⼀个元素为 O(1), 插⼊多个元素为 O(N), N 为插⼊元素个数.
返回值:插⼊后 list 的⻓度
🌻RPUSHX
在 key 存在时,将⼀个或者多个元素从右侧放⼊(尾插)到 list 中
cpp
RPUSHX key element [element ...]时间复杂度:只插⼊⼀个元素为 O(1), 插⼊多个元素为 O(N), N 为插⼊元素个数.
返回值:插⼊后 list 的⻓度。
🌻LRANGE
获取从 start 到 end 区间的所有元素,左闭右闭
这个接口具有"鲁棒性",即你越粗鲁,我就越棒!
即使超出区间了,也尽可能返回已有的区间,有点像python
cpp
LRANGE key start stop使用0, -1 可以获取List的所有元素
返回值:指定区间的元素。
🌻LPOP
从 list 左侧取出元素(即头删)
cpp
LPOP key时间复杂度:O(1)
返回值:取出的元素或者 nil。
🌻RPOP
从 list 右侧取出元素(即尾删)
返回值:取出的元素或者 nil。注意区分获取元素和删除元素的区别。不要妄想以删除元素来获取元素的返回值
cpp
RPOP key时间复杂度:O(1)
🌻LINDEX
获取从左数第 index 位置的元素
cpp
LINDEX key index时间复杂度:O(N) 这里注意,因为底层实现并不是数组,在获取元素时,需要遍历,但也不慢~
返回值:取出的元素或者 nil。
🌻LINSERT
在特定位置插⼊元素。
cpp
LINSERT key <BEFORE | AFTER> pivot element时间复杂度:O(N)
返回值:插⼊后的 list ⻓度。
注意如果有多个基准值pivot,那么就会从左往右找到第一个基准值的特定位置插入
🌻LLEN
获取 list ⻓度。
🌻lrem
Removes the first count occurrences of elements equal to element from the list stored at key
cpp
LREM key count element规则如下:
cpp
count > 0: Remove elements equal to element moving from head to tail.
count < 0: Remove elements equal to element moving from tail to head.
count = 0: Remove all elements equal to element.🌻LTRIM
删除给定区间之外的所有元素。也就是保留start-stop之间的元素,包括边界,其他元素删除。
trim是修剪的意思,
cpp
LTRIM key start stop时间复杂度为O(N)
这里的ACL是针对Redis 6.0以上版本才有的,说白了就是给每个命令打上标签,允许用户执行哪些命令,不允许你操作哪些命令
🌻LSET
和lindex类似,只不过lindex是查找指定下标的元素,lset是指定下标的元素,并设置。
cpp
LSET key index element时间复杂度为O(N),由于List内部编码不是数组,所以这里时间复杂度不是O(1),但是这个操作也不是你想象的那么慢,也挺快的,相比于MySQL还是快得多。
下面来说一下阻塞版本命令
阻塞这个概念和我们当时学习基于条件变量的生产者消费者模型阻塞队列中的阻塞的意思是一致的。
在list中有两个阻塞命令:blpop 和 brpop 。
cpp
BLPOP key [key ...] timeout
BRPOP key [key ...] timeout他俩是 lpop 和 rpop 的阻塞版本,和对应非阻塞版本的作⽤基本⼀致,在列表中有元素的情况下,阻塞和非阻塞表现是⼀致的。lpop和blpop都会头删,立即返回该元素。
如图:
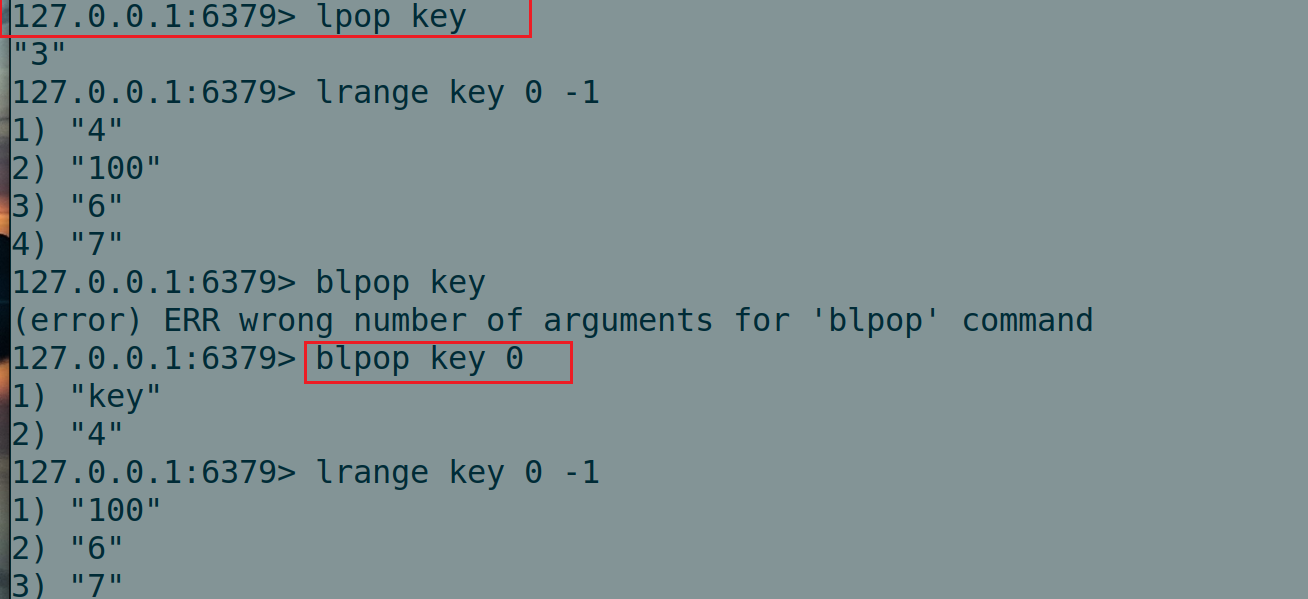
唯一区别就是:
但如果列表中没有元素,非阻塞版本lpop 会理解返回 nil,但阻塞版本会根据timeout,阻塞⼀段时间,期间 Redis 可以执⾏其他命令,但要求执行该命令的客互端会表现为阻塞状态。这段时间一旦有key插入元素,立即头删得到元素返回
如图:

命令中如果设置了多个键,那么会从左向右进⾏遍历键,⼀旦有⼀个键对应的列表中可以弹出元
素,命令立即返回。也就是监测多个key,哪个key一旦插入,立即弹出元素返回!
如图:
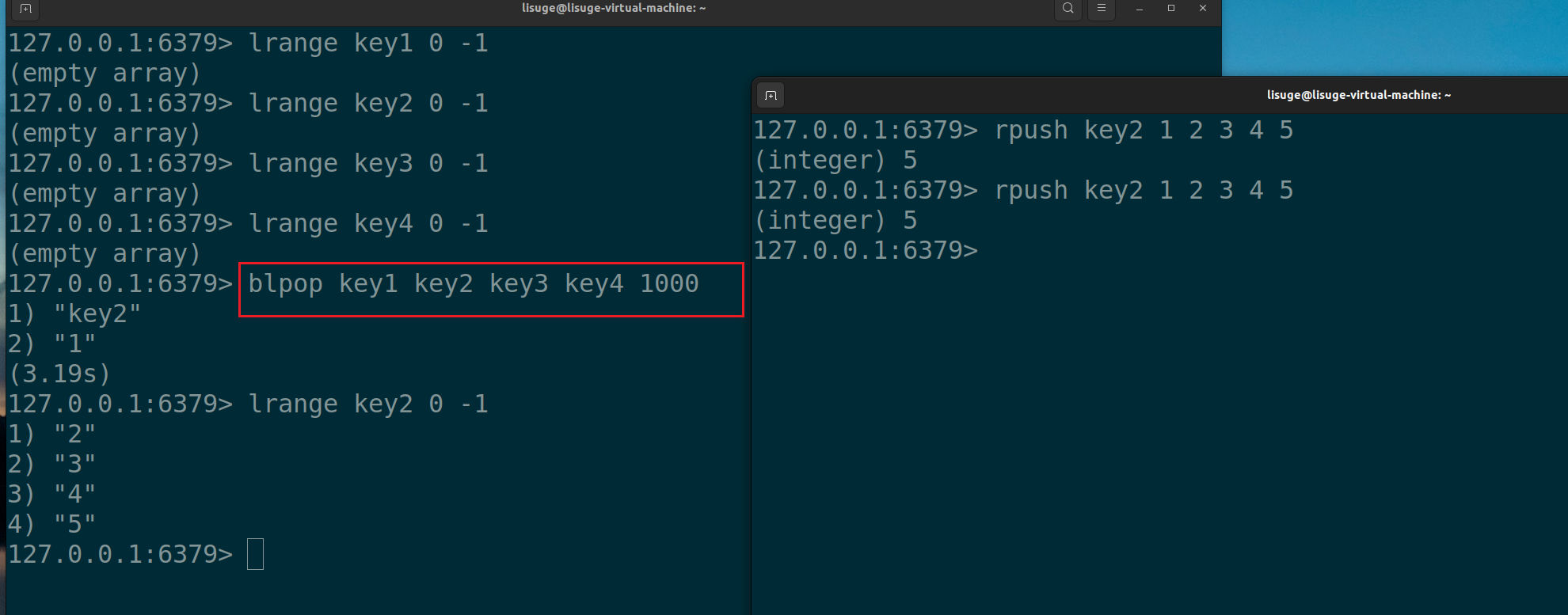
当key2插入,立马头删返回,不在监测其他key了
如果多个客互端同时多⼀个键执⾏ pop,则最先执⾏命令的客⼾端会得到弹出的元素,其他客户端按顺序依次弹出
如图:
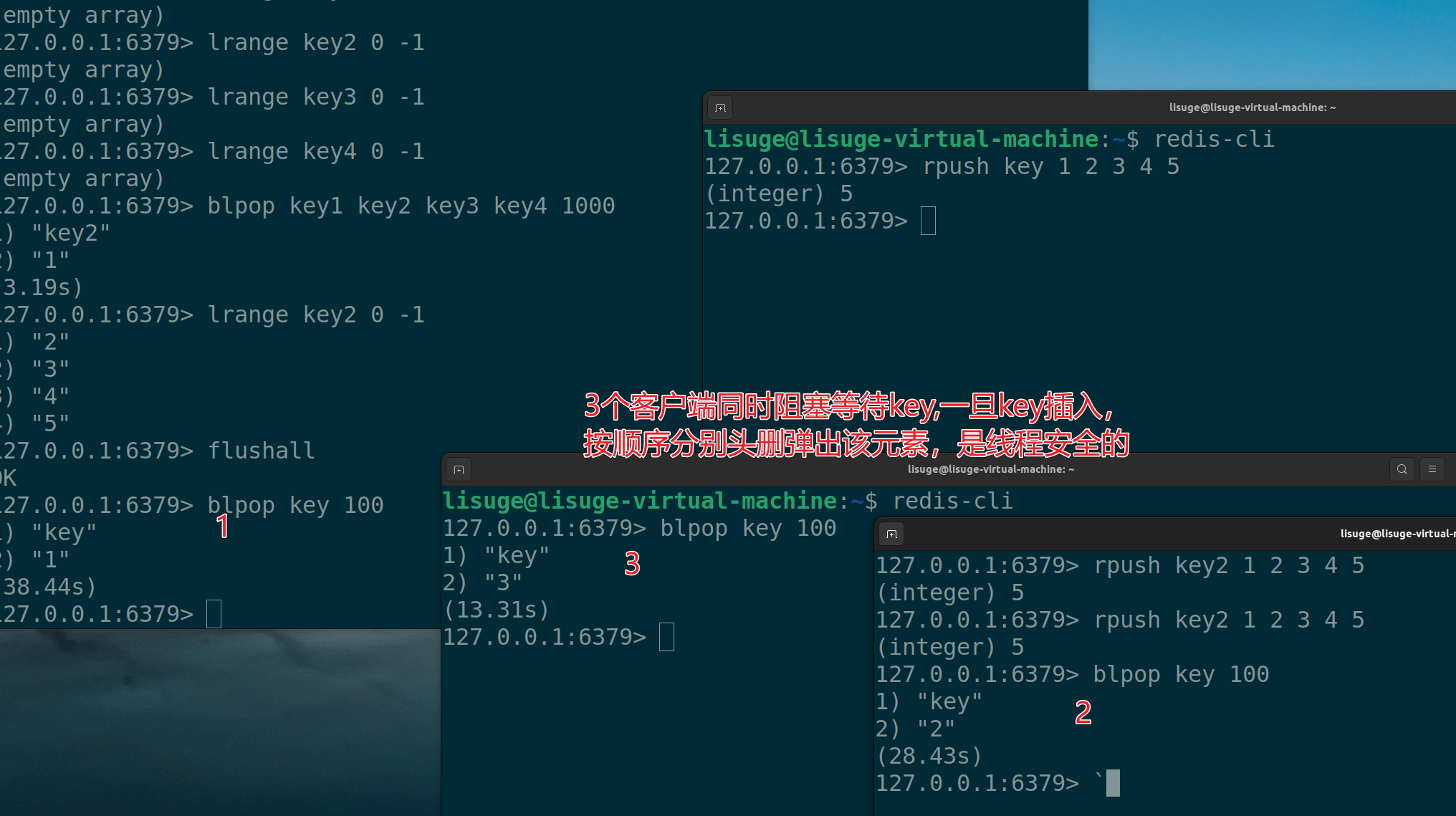
brpop和blpop操作完全一致,只不过是阻塞尾删,这里不再赘述。
最后一张图总结一下列表类型的操作:
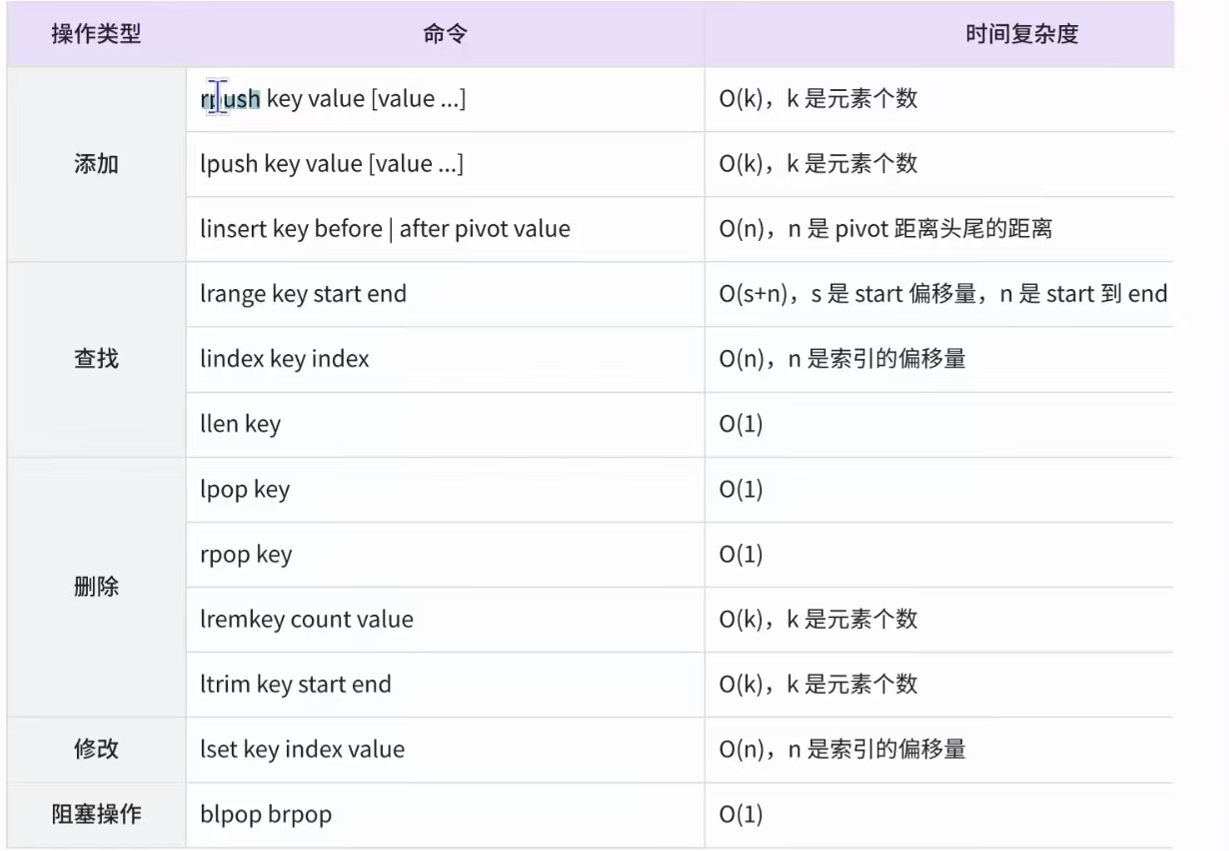
在操作list时,头插头删或者尾插尾删效率都是很高的。就可以把list当做一个栈/队列来使用。
如果使用rpush,lpop,那么就是队列
如果使用lpush, rpop那么就是栈
🐼List内部编码
列表类型的内部编码有两种
ziplist(压缩列表),ziplist 来作为列表的内部编码实现来减少内存消耗,当元素个数较少,且每个元素的大小较小时会采取这种方式
linkedlist(链表),当列表类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ linkedlist 作为列表的内部实现
不过现在redis中都采用quiklist,quicklist结合了ziplist和linkedlist的优点:
整体还是一个链表,只不过链表中的每一个节点为压缩列表,每个列表节点,都不让他太大,同时把多个压缩列表连接起来
🐼使用场景
✅作为数组这样的结构,来存储多个元素。
假设我们现在有一个班级表和学生表,一个班级可以有多个学生,我们就可以把班级id作为key,学生的身份作为list的数组的值,进行存储。
如:
cpp
lpush class_id_1 1 2 3 4 5 6 # 表示一班有 学生id为1,2,3,4,5,6的6名学生 ✅Redis 可以使用 lpush + brpop 命令组合实现经典的阻塞式生产者-消费者模型队列,生产者客互端使用lpush 从列表左侧插⼊元素,多个消费者客户端使用 brpop 命令阻塞式地从队列中 "争抢" 队首元素。通过多个客互端来保证消费的负载均衡和⾼可用性。
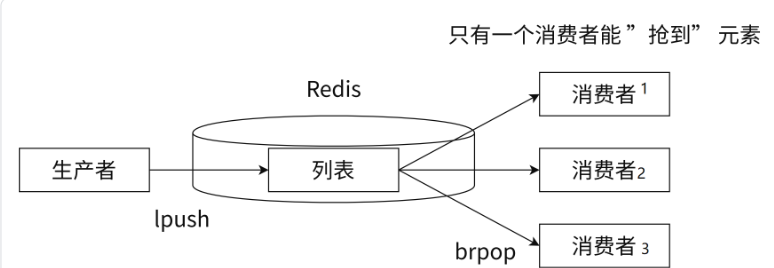
✅分频道的消息队列
通过不同的键模拟频道的概念,不同的消费者可以通过 brpop 不同的键值,实现订阅不同频道的理念。通过不同频道,来获取不同的数据,比如短视频抖音,就可以分为视频频道,声音频道,弹幕频道....实现数据之间的解耦合效果!如图:
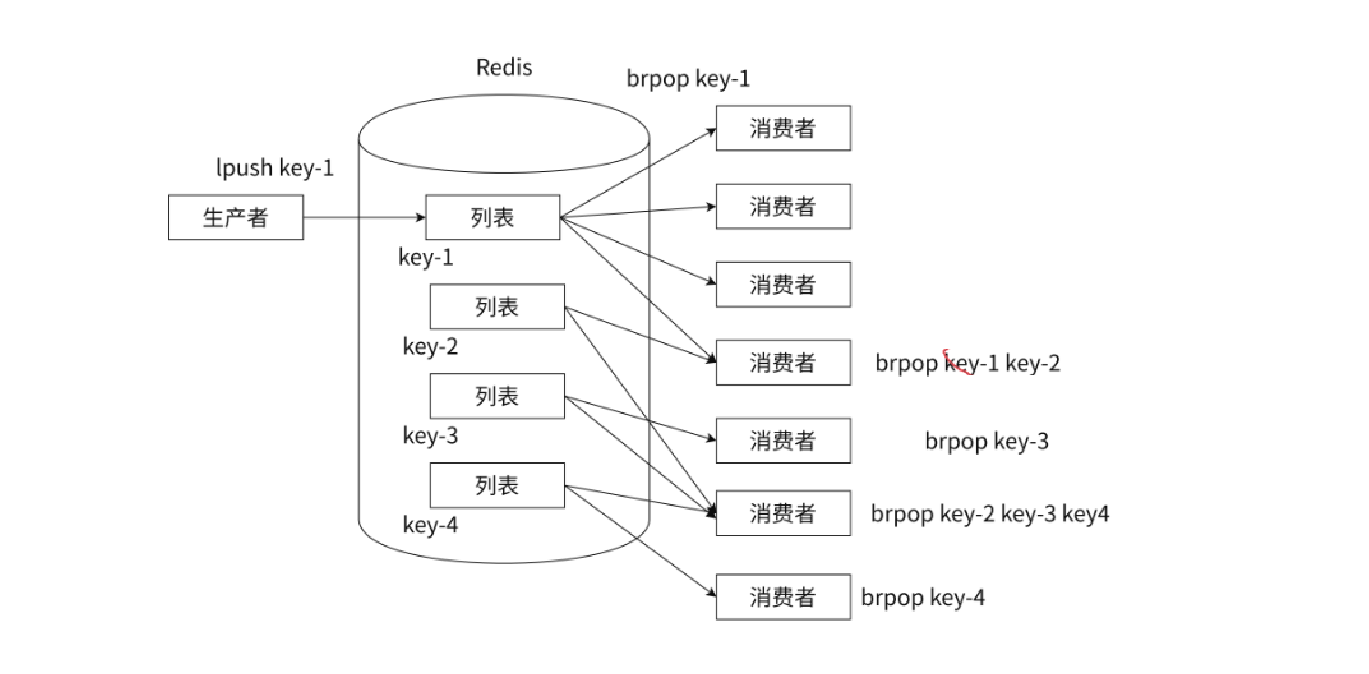
并且每个消费者可以订阅多个key!
✅订阅CSDN博客列表
我们CSDN上每个用户都有属于自已写的博客(你总共写的篇数),现需要分页展示⽂章列表。此时可以考虑使⽤列表,因为列表不但是有序的,同时⽀持按照索引范围获取元素
每篇博客使用哈希结构存储,例如微博中 3 个属性:title、timestamp、content:
那么一个用户所有的博客我们都能存储起来了:
cpp
hmset mblog:1 title xx timestamp 1476536196 content xxxxx #第一篇
...
hmset mblog:n title xx timestamp 1476536196 content xxxxx #第n篇我们以user:<uid>:mblogs 作为博客的键
由于一个用户写的博客数不止一篇,使用list那么我们就能维护好所有的mblog
cpp
lpush user:1:mblogs mblog:1 mblog:3往后,如果我们想获取用户写的前10篇博客,就能这么获取:
cpp
keylist = lrange user:1:mblogs 0 9
for key in keylist {
hgetall key
}不过上述可能存在两个实际问题:
-
就是如果这个用户写了1W篇博客,那么list的长度就是10000,那么如果我想获取到第5005篇博客,就需要花费很多时间,线性遍历。但是我们可以把1W篇博客采用10个list存储,这样遍历每一个list花费代价就低多了。
-
即如果每次分页获取的微博个数较多,比如要获取100篇,那么就需要执行100次 hgetall 操作,那么这个网络开销是很大的!此时可以考虑使用pipeline(流⽔线)模式批量提交命令,把这些hgetall命令作为一个网络命令获取,或者微博不采用哈希类型,而是使用序列化的字符串类型,使⽤ mget 获取,一次性获取。