目录
[1. 引言](#1. 引言)
[2. 方法](#2. 方法)
[2.1 模型架构(Architecture)](#2.1 模型架构(Architecture))
[2.2 预训练(Pre-training)](#2.2 预训练(Pre-training))
[2.3 监督微调(Supervised Fine-Tuning, SFT)](#2.3 监督微调(Supervised Fine-Tuning, SFT))
[2.4 强化学习(Reinforcement Learning, RL)](#2.4 强化学习(Reinforcement Learning, RL))
[3. 实验](#3. 实验)
[3.1 基线模型对比](#3.1 基线模型对比)
[3.2 推理性能对比](#3.2 推理性能对比)
该论文由 MiniCPM团队发表,一个参数规模为 8B 的多模态大语言模型(MLLM),专注于提升训练和推理效率,同时保持高性能。论文的核心贡献是通过模型架构、数据策略和训练方法的创新,解决了 MLLM 在视觉编码、文档知识学习和推理效率方面的瓶颈。模型在 OpenCompass评估中超越了 GPT-4o-latest 和 Qwen2.5-VL 72B 等模型,并在视频理解基准 VideoMME 上以更低的 GPU 内存(46.7%)和推理时间(8.7%)实现 SOTA 性能。
论文:2509.18154 MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
1. 引言
问题背景
MLLM(如 GPT-4o、Qwen2.5-VL)在文本、图像和视频理解上快速发展,但面临三大效率瓶颈:
- 视觉编码产生过多令牌,导致计算开销大(如视频编码需 1536-3072 个令牌);
- 文档数据依赖外部解析器,易出错且数据工程复杂;
- 强化学习(RL)提升长推理能力,但导致输出冗长,影响效率。
解决方案
- 统一 3D-Resampler 架构,以高效压缩图像和视频特征(视频压缩率达96x)。
- 统一文档知识与 OCR 学习范式,无需外部解析器,通过动态视觉扰动统一知识推理和文本识别。
- 混合 RL 后训练策略,支持短/长推理模式,互补提升性能并减少训练样本(仅需 33.3% 长推理样本)。
性能亮点
8B 参数模型在 OpenCompass 上得分 77.0,超越 GPT-4o-latest(75.4)和 Qwen2.5-VL 72B(76.1);在 VideoMME 上用 9.9% 推理时间实现等效性能。
贡献
开源 MiniCPM-V 4.5,支持高效视频理解、可控推理、鲁棒 OCR 和文档解析。
2. 方法
论文分为架构、预训练、SFT 和 RL 四个部分。
2.1 模型架构(Architecture)

为了解决 MLLM 中的图像和视频编码效率瓶颈,作者将2DResampler扩展到3D-Resampler,联合压缩视频的时空信息。
整体结构:轻量视觉编码器 + 统一3D-Resampler + LLM解码器,支持高分辨率图像和视频,支持短/长推理模式。
统一3D-Resampler:
- 图像处理:
采用 LLaVA-UHD 分块策略,对于每幅图像,根据输入分辨率估计出理想的切片数,选择切片分辨率与视觉编码器预训练设置偏差最小的划分。切片的纵横比越接近预训练设置(最小化偏差),确保切片分辨率与预训练最匹配。对每个切片使用2D空间位置嵌入增强的可学习查询(Query),再通过交叉注意力为每个切片生成固定长度的序列。整体流程为:输入图像 → 分区成切片 → 视觉编码器提取特征 → 3D-Resampler(图像模式下退化为 2D)压缩 → 输出紧凑令牌序列 → 喂入 LLM 解码器。
- 图像分区:任意分辨率和纵横比的图像(如W_I × H_I),设置视觉编码器的预训练输入分辨率W_v x H_v(如224x224)。计算理想切片数,N = ⌈ (W_I × H_I) / (W_v × H_v) ⌉,即将任意的图像切分为固定预训练输入分辨率大小的块数。将N分解为mxn≈N的候选分区,使用分数函数 S = -log(W_I × n)/(H_I × m) - log(W_v / H_v) 选择最佳(m*, n*),以最小化每个切片图像块分辨率与预训练设置的偏差。图像切片后,输出m* × n* 个切片,每个切片分辨率接近预训练设置,并保留原生纵横比(无填充或扭曲)。
- 特征压缩:对每个切片的视觉特征,使用少量可学习查询(Queries,如64个)结合2D 空间位置嵌入(捕捉切片内的相对位置),通过跨注意力与切片特征交互,将每个切片视觉特征压缩成固定长度序列的视觉特征表示,即使用学习到的Queries代替切片的视觉特征。传统的压缩方法采用MLP + pixel unshuffle 是像素级操作,具有固定压缩率。但Resampler是通过查询进行驱动的,可灵活调整查询数,实现更高的压缩率,对输入形状完全无关。
- 视频处理:
- 视频分包:为了处理视频中的大量冗余数据,使用时空联合压缩策略,以实现更高的压缩率。将视频沿着时间维度切分为包,每个包中都是相邻的视频帧,其中包含大量的冗余信息,这些信息可以在联合建模的时候被识别并进行压缩。
- 联合时空建模:为了进行联合时空建模,通过交叉注意力将每个包中视觉编码器的帧特征重新采样为固定长度的特征序列,就像图像处理中的压缩表示方法一样。最终视频的特征表示通过拼接所有的所有包(packages)的令牌序列获得。对每个视频最多采样 1080 帧,最大帧率为 10。在训练过程中,随机增加包大小和帧率以提高鲁棒性。
优势:统一图像/视频编码,知识从图像转移到视频(e.g., 视频 OCR 无需额外数据)。训练效率高,仅需轻量 SFT 升级 2D 到 3D。
2.2 预训练(Pre-training)
预训练的目的是通过渐进的、多阶段的策略,建立模型的基础能力。
策略:三阶段渐进式:
阶段1:仅训练 2D-Resampler(冻结其他),用图像-描述数据对齐模态。
阶段2:解冻视觉编码器,用 OCR 丰富数据提升感知能力(冻结 LLM)。
阶段3:端到端训练所有参数,用高质量数据(文本、图像-文本交织、视频),采用Warmup-Stable-Decay学习率方案,衰减阶段添加知识密集数据。
预训练数据:
图像描述:LAION-2B、COYO 等 + 精选的中文网络数据,CLIP 过滤不相关的图像-文本对,Capsfusion 重新生成完整的描述,提升知识流畅性。
图像-文本交织:上下文学习和多图像理解使用Common Crawl、OmniCorpus、MINT-IT数据很关键,删除图像损坏或图文比例不平衡的样本,进一步使用相关性过滤来确保有意义的多模态关联,并使用知识密度过滤来为预训练的最终衰减阶段选择高质量的子集。
OCR:通过合成数据OCR数据(自然场景 + HTML 渲染)以增强文本识别能力。
文档:收集网络科学论文、教科书文档,提高知识密度。
视频描述:收集WebVid、Vript、OpenVid等视频数据 + 补充详细视频字幕描述,以增强视频推理能力。
统一文档知识与 OCR 学习范式:
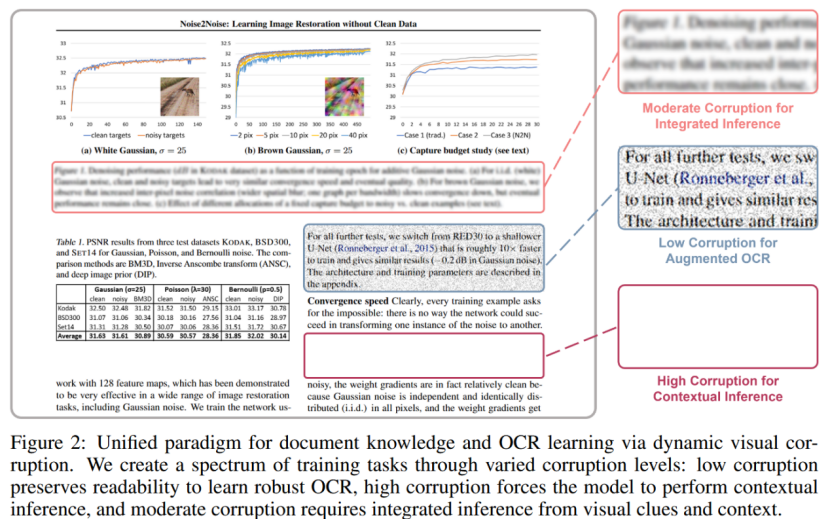
大多数 MLLM 依赖于外部解析器将文档 PDF 转换为交错的图像文本序列以进行训练,该过程通常会引入结构错误,或者需要大量的数据工程工作来修复故障情况。更强的图像增强虽然可创建更多样化、更难的样本,以带来更强大的OCR功能,但过度增强可能会使文本难以区分。强迫模型从这种难以区分的视觉输入中生成真实文本通常会导致幻觉问题。
方法:为了克服这两个挑战,使用一种统一的训练范式,直接从文档图像中学习,使用它们的原始文本作为基本ground truth。主要见解是: 文档知识获取和文本识别之间的主要区别在于图像中文本的可见性。将这两种功能统一为一个学习目标:从损坏的文档图像中预测原始文本。通过动态破坏具有不同损坏级别的文本区域,模型学会在精确文本识别(当文本可区分时)和多模态基于上下文的知识推理(当文本被严重模糊或屏蔽时)之间自适应且正确地切换,如图 2 所示。这消除了对外部解析器的依赖,并防止过度增强的OCR数据产生幻觉。
洞见:通过动态扰动文本区域(低/中/高Corruption水平),统一文本识别(低Corruption)和上下文推理(高Corruption)。
- 低Corruption:鲁棒 OCR。
- 中Corruption:整合视觉线索与上下文。
- 高Corruption:纯多模态知识推理。
优势:避免外部解析器噪声,防止过度增强导致幻觉;同一批次混合任务,提升数据利用率。
关键:基础技能用异质数据构建(选择性冻结参数);动态扰动统一多目标学习。
2.3 监督微调(Supervised Fine-Tuning, SFT)
有监督微调用于激活模型在广泛任务上的能力,并为强化学习做好准备。此外,现阶段将2D-Resampler扩展为统一的3D-Resampler,以提高视频数据的压缩效率。
策略:首先训练一般的交互能力,然后培养高级推理和时间理解的专业技能。
- 阶段1 :此阶段激活预训练期间获得的广泛知识,并将其与人类指令保持一致。通过对高质量指令响应数据的多样化组合进行微调,该模型可以提高多模态交互的熟练程度。为了防止纯文本性能下降并提高训练稳定性,在训练混合数据中包含 10% 的高质量纯文本数据。
- 阶段2:在前一阶段的通用基础上,培养支持长推理模式、高帧率和长视频理解的专业技能。首先,通过将 Long-CoT 预热指令引入 SFT 数据来解锁高级推理。鼓励模型执行明确的逐步思考过程,结合反思和回溯等认知模式,这对长推理模式很重要。其次,通过将架构从2D升级到 3D-Resampler 并引入高帧率和长视频数据来增强其时序内容理解。
SFT数据:
- STEM数据:为提升模型在STEM领域的能力,从学校精选多学科问题(涵盖物理、化学、生物、金融、计算机科学等),保留过滤视觉依赖(无图像信息就无法解决)和高一致性检查(人工审核或交叉验证答案正确性)后的样本。对剩余的样本使用强大的MLLM生成干净的推理过程,确保响应逻辑清晰。
- 长尾知识数据:为了解决模型在罕见的问题上表现差,通过Wikipedia 合成多模态指令,过滤视觉依赖,注入长尾知识,提升泛化能力。例如,从 Wikipedia 页面提取文本+图像,生成问题如"基于这张图,解释这个罕见物种的栖息地"。长尾知识注入减少模型在边缘案例的失败率,提升整体知识密度。使用 Wikipedia 确保事实准确性和多样性,避免合成数据的幻觉问题。
- Long-CoT数据:启用长链式思考(Long Chain-of-Thought, Long-CoT)模式,培养模型的推理模式(reasoning patterns),如反思(reflection)和回溯(backtracking)。这为复杂任务准备,支持 SFT Stage 2 的长推理激活,而非简单模式记忆。OpenThoughts + 自建数据,使用挑战性的问题有利于发展强大的推理能力,多阶段验证(正确性、事实核查、重复过滤)。
- 关键见解:聚焦挑战问题有利于模型的推理能力提升。
2.4 强化学习(Reinforcement Learning, RL)
RL阶段旨在增强推理性能,实现可控推理模式,提高可信度。为了提供有效的通用领域奖励,将针对简单canses的规则验证奖励与针对复杂答案的RLPR的基于一般概率的奖励相结合,并添加校准的偏好奖励。采用这种混合强化学习策略,可以在短推理和长推理模式之间灵活切换。同时进一步整合RLAIF-V以减少幻觉。
数据:包含四个领域的高质量样本(人类循环清洗):
- 数学:从学术来源收集多模态问题,其包含视觉感知和推理过程,通过清洗标签错误提升数据集质量。
- 文档/表格/图表:真实数据+合成数据集,提升复杂场景推理能力。
- 通用推理:从 VisualWebInstruct 等数据源收集涵盖逻辑和多学科推理任务的各种问题,这些数据表现出更复杂的参考答案风格,许多问题都有多个子问题,以进一步提升推理能力。
- 指令跟随:合并来自 Llama-Nemotron-Post-Training 数据集 和 MulDimIF 数据集的纯文本指令,以提升泛化。
奖励质量控制:RL的有效性高度依赖数据质量,关注两个不同方面的质量控制
- 标签准确:对于每个数据集,维护一个小子集来检查标签准确性并进行人机循环清理过程以保持较高的标签准确性。
- 奖励准确:人工制定的规则很难解决自然语言的复杂性,对简单答案用规则验证(98% 准确),对复杂用 RLPR 概率奖励。
- 奖励覆盖:添加偏好奖励(RM,仅对最终答案),引导模型向人类偏好响应对齐。
混合 RL:
- 支持短(高效)/长(复杂)推理模式(提示控制)切换,短推理模式针对快速回答,长推理模式针对复杂问题发出明确的逐步跟踪,通过提示控制(prompt-controlled),允许用户或系统灵活选择(如"简短回答" vs. "详细思考")。
- 混合优化:在 rollout 过程中随机切换两种模式(randomly alternate),联合优化。使用 GRPO(Gaussian Process Reinforcement Learning 或类似变体作为优化器。移除 KL 散度损失(KL loss)和熵损失(entropy loss),以提升训练稳定性(improve stability),避免模式崩溃或过拟合。
- 优势:互补泛化,减少长推理样本(一半即可),训练令牌成本降 70.5%。
奖励塑造:R = R_acc + R_format + R_rep + 0.5 * 标准化 R_rm,即基于规则验证的准确性、确保响应格式的一致性、惩罚无意义的重复以减少冗长、以及来自人类偏好数据的辅助奖励模型(RM)进行训练。
RLAIF-V:扩展到视频,反馈收集(分解声明 + 偏好对),用 DPO 训练,减少视觉幻觉。
关键:规则 + 概率奖励覆盖多样任务;混合 RL 提升跨模式泛化。
3. 实验
3.1 基线模型对比
与各种强基线模型进行比较:(1)最先进的开源模型,以Qwen2.5-VL 72B为代表; (2) 具有可比参数大小的强大模型,包括参数匹配的竞争对手,例如 InternVL3(8B) 和 GLM-4.1V(9B); (3) 前沿专有模型,例如最新的 GPT-4o,对比结果如下。
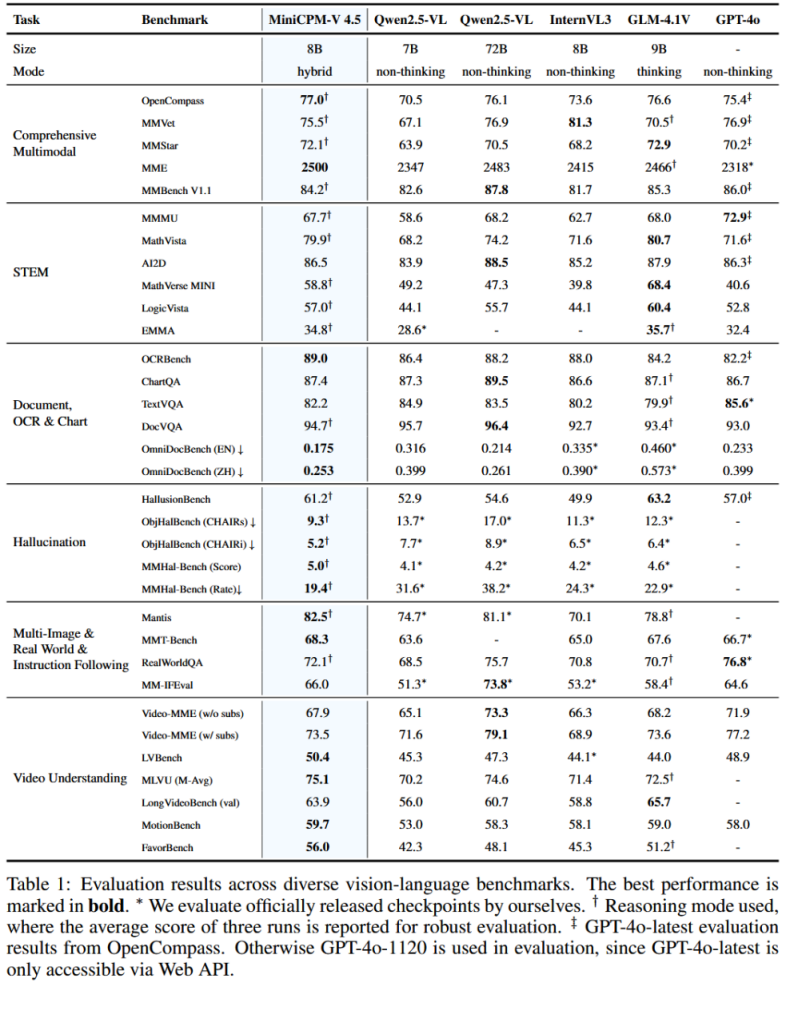
以仅 8B 参数超越专有模型 GPT-4o-latest(75.4)和开源大模型 Qwen2.5-VL 72B(76.1),证明了模型的紧凑设计和高效训练方法(如混合 RL 的提升泛化能力)。这体现了Cooking Efficient MLLMs的核心,即在低资源下实现高泛化,适用于多样任务如多图像推理和真实应用场景。
参数效率与领先性:以 8B 参数超越 72B 模型和专有 API(如 GPT-4o-latest),体现了三大创新的协同:架构压缩减少令牌开销,数据范式提升知识/OCR 鲁棒性,训练策略优化推理模式和可信度。
广度与深度:覆盖 20+ 基准,平均领先开源模型 5-10 分,减少幻觉 20-30%,支持高帧/长视频和多语言文档。
实际影响:这些优势使模型更易扩展(如开源代码/模型),推动 MLLM 在教育、文档处理和视频分析的应用。未来可进一步优化极长视频或更多模态。
3.2 推理性能对比

图像理解:使用 OpenCompass 基准,这是一个综合多模态评估框架,覆盖 STEM、文档/OCR、幻觉检测、多图像推理等子任务。指标包括平均分数(Avg Score,↑表示越高越好)、推理时间(Time,↓表示越低越好)。
视频理解:使用 VideoMME 基准,专注于视频多模态评估(e.g., 字幕和无字幕场景)。额外指标包括 GPU 内存消耗(Mem,↓表示越低越好)。
模型比较:聚焦"thinking models"(支持长/短推理模式),包括开源模型。最佳结果用粗体标记,强调性能-效率权衡。
优势:
- 高性能前提下的低成本:模型在 OpenCompass 基准(综合图像理解)上获得 77.0 的平均分数,领先 30B 以下模型(如 GLM-4.1V-9B-thinking 的 76.6),仅用 7.5 小时完成评估,是 GLM-4.1V 的 42.9%。在 VideoMME 基准(视频理解)上,分数 73.5(接近 GLM-4.1V 的 73.6),但推理时间仅 0.26 小时(GLM-4.1V 的 9.9%,Qwen2.5-VL-7B 的 8.7%),GPU 内存仅 28G(Qwen2.5-VL 的 46.7%,最低值)。
- 优势体现:与其他模型(如 Qwen2.5-VL8.3B/GLM-4.1V10.3B)相比,MiniCPM-V4.5参数更小(8.7B)但分数更高或相当,同时资源消耗显著降低。使模型更适合部署,如资源受限环境(如边缘设备或大规模推理)。